 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Performance of a Deep Neural Network at Detecting North Atlantic Right Whale Upcalls
Jan 24, 2020
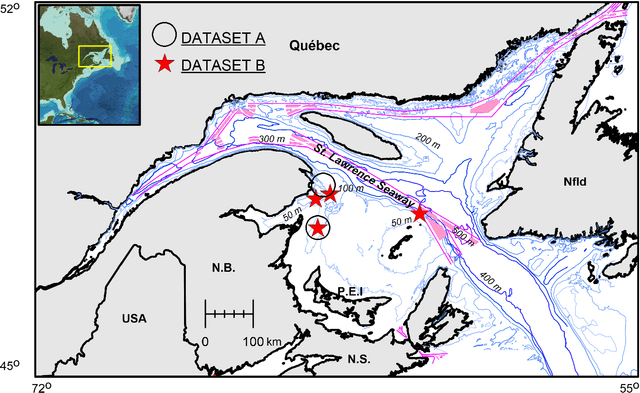
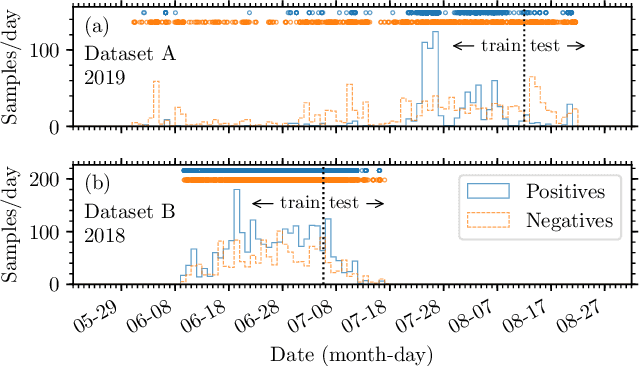
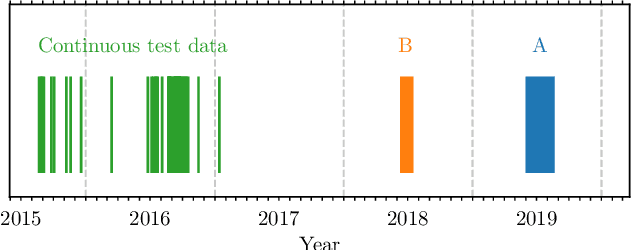
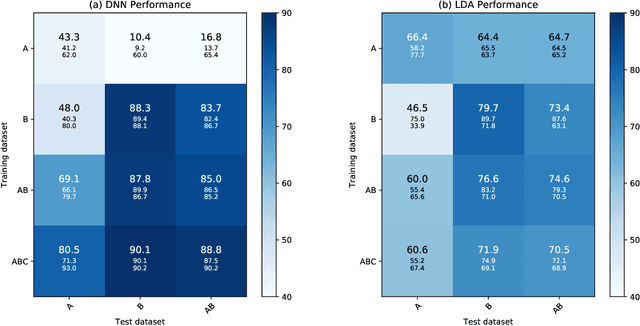
Passive acoustics provides a powerful tool for monitoring the endangered North Atlantic right whale (NARW), but improved detection algorithms are needed to handle diverse and variable acoustic conditions and differences in recording techniques and equipment. Here, we investigate the potential of Deep Neural Networks for addressing this need. ResNet, an architecture commonly used for image recognition, is trained to recognize the time-frequency representation of the characteristic NARW upcall. The network is trained on several thousand examples recorded at various locations in the Gulf of St. Lawrence in 2018 and 2019, using different equipment and deployment techniques. Used as a detection algorithm on fifty 30-minute recordings from the years 2015-2017 containing over one thousand upcalls, the network achieves recalls up to 80%, while maintaining a precision of 90%. Importantly, the performance of the network improves as more variance is introduced into the training dataset, whereas the opposite trend is observed using a conventional linear discriminant analysis approach. Our work demonstrates that Deep Neural Networks can be trained to identify NARW upcalls under diverse and variable conditions with a performance that compares favorably to that of existing algorithms.
Asymmetric Rejection Loss for Fairer Face Recognition
Feb 09, 2020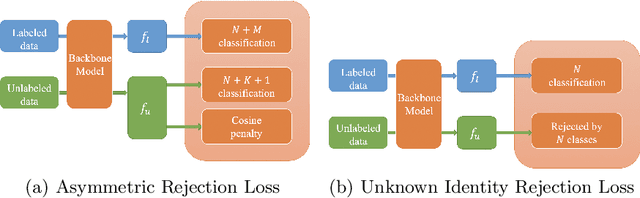
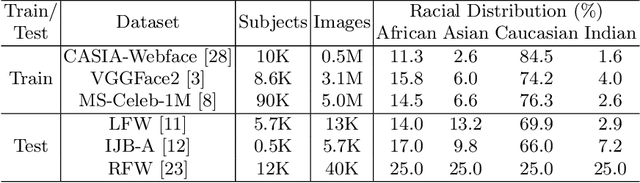
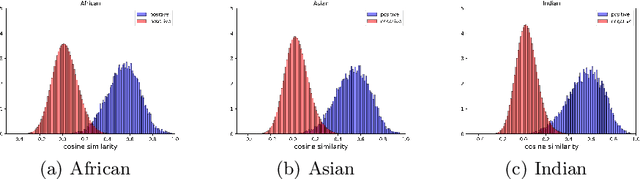
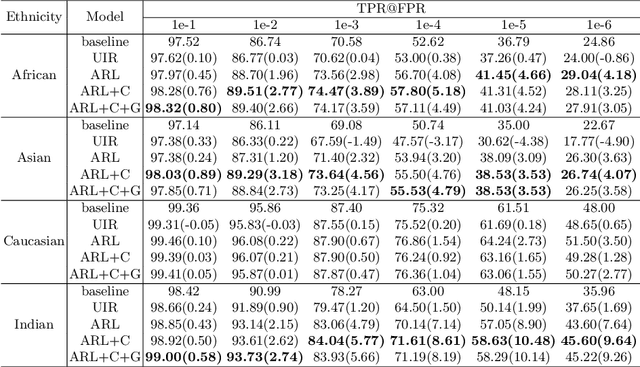
Face recognition performance has seen a tremendous gain in recent years, mostly due to the availability of large-scale face images dataset that can be exploited by deep neural networks to learn powerful face representations. However, recent research has shown differences in face recognition performance across different ethnic groups mostly due to the racial imbalance in the training datasets where Caucasian identities largely dominate other ethnicities. This is actually symptomatic of the under-representation of non-Caucasian ethnic groups in the celebdom from which face datasets are usually gathered, rendering the acquisition of labeled data of the under-represented groups challenging. In this paper, we propose an Asymmetric Rejection Loss, which aims at making full use of unlabeled images of those under-represented groups, to reduce the racial bias of face recognition models. We view each unlabeled image as a unique class, however as we cannot guarantee that two unlabeled samples are from a distinct class we exploit both labeled and unlabeled data in an asymmetric manner in our loss formalism. Extensive experiments show our method's strength in mitigating racial bias, outperforming state-of-the-art semi-supervision methods. Performance on the under-represented ethnicity groups increases while that on the well-represented group is nearly unchanged.
One Network for Multi-Domains: Domain Adaptive Hashing with Intersectant Generative Adversarial Network
Jul 01, 2019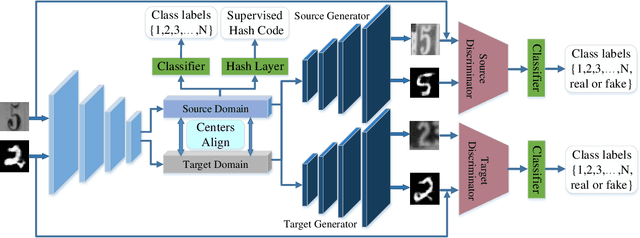
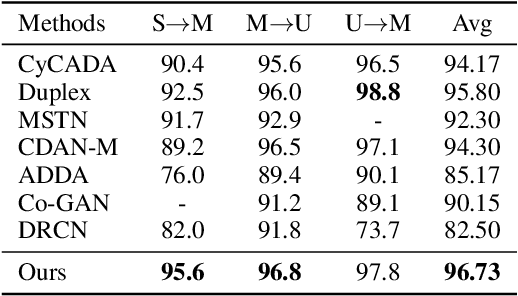
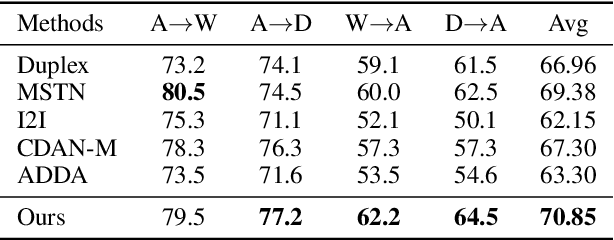

With the recent explosive increase of digital data, image recognition and retrieval become a critical practical application. Hashing is an effective solution to this problem, due to its low storage requirement and high query speed. However, most of past works focus on hashing in a single (source) domain. Thus, the learned hash function may not adapt well in a new (target) domain that has a large distributional difference with the source domain. In this paper, we explore an end-to-end domain adaptive learning framework that simultaneously and precisely generates discriminative hash codes and classifies target domain images. Our method encodes two domains images into a semantic common space, followed by two independent generative adversarial networks arming at crosswise reconstructing two domains' images, reducing domain disparity and improving alignment in the shared space. We evaluate our framework on {four} public benchmark datasets, all of which show that our method is superior to the other state-of-the-art methods on the tasks of object recognition and image retrieval.
Invisible Steganography via Generative Adversarial Networks
Oct 10, 2018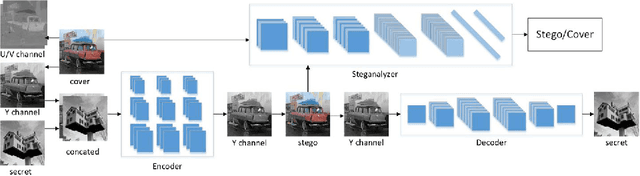

Nowadays, there are plenty of works introducing convolutional neural networks (CNNs) to the steganalysis and exceeding conventional steganalysis algorithms. These works have shown the improving potential of deep learning in information hiding domain. There are also several works based on deep learning to do image steganography, but these works still have problems in capacity, invisibility and security. In this paper, we propose a novel CNN architecture named as \isgan to conceal a secret gray image into a color cover image on the sender side and exactly extract the secret image out on the receiver side. There are three contributions in our work: (i) we improve the invisibility by hiding the secret image only in the Y channel of the cover image; (ii) We introduce the generative adversarial networks to strengthen the security by minimizing the divergence between the empirical probability distributions of stego images and natural images. (iii) In order to associate with the human visual system better, we construct a mixed loss function which is more appropriate for steganography to generate more realistic stego images and reveal out more better secret images. Experiment results show that ISGAN can achieve start-of-art performances on LFW, Pascal VOC2012 and ImageNet datasets.
Delineating Bone Surfaces in B-Mode Images Constrained by Physics of Ultrasound Propagation
Jan 07, 2020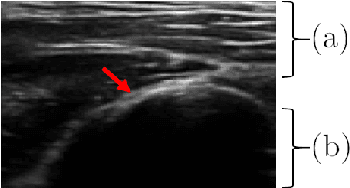
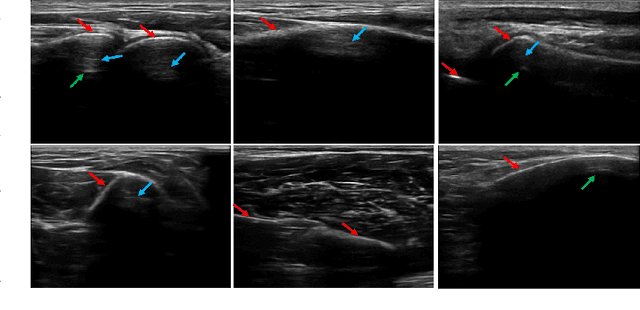
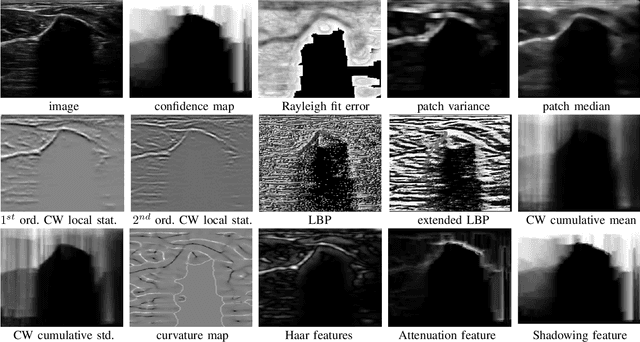
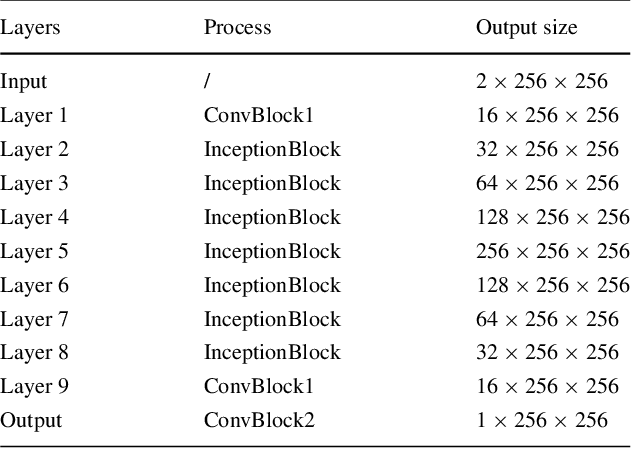
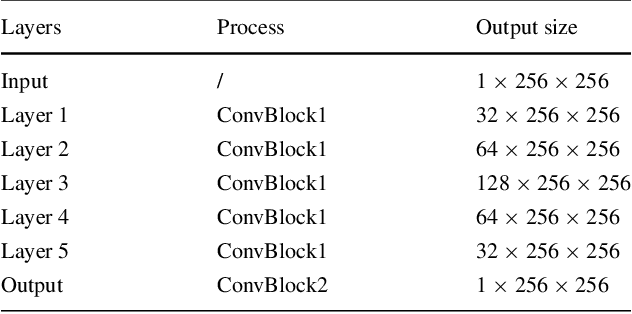
Bone surface delineation in ultrasound is of interest due to its potential in diagnosis, surgical planning, and post-operative follow-up in orthopedics, as well as the potential of using bones as anatomical landmarks in surgical navigation. We herein propose a method to encode the physics of ultrasound propagation into a factor graph formulation for the purpose of bone surface delineation. In this graph structure, unary node potentials encode the local likelihood for being a soft tissue or acoustic-shadow (behind bone surface) region, both learned through image descriptors. Pair-wise edge potentials encode ultrasound propagation constraints of bone surfaces given their large acoustic-impedance difference. We evaluate the proposed method in comparison with four earlier approaches, on in-vivo ultrasound images collected from dorsal and volar views of the forearm. The proposed method achieves an average root-mean-square error and symmetric Hausdorff distance of 0.28mm and 1.78mm, respectively. It detects 99.9% of the annotated bone surfaces with a mean scanline error (distance to annotations) of 0.39mm.
Dynamic texture and scene classification by transferring deep image features
Feb 01, 2015
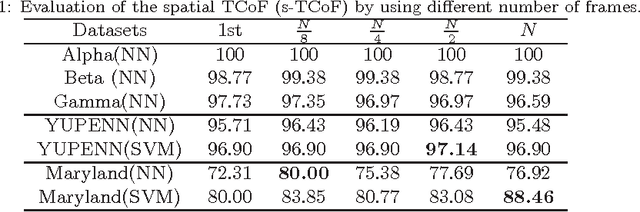
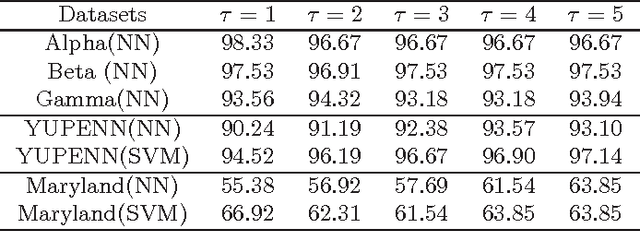
Dynamic texture and scene classification are two fundamental problems in understanding natural video content. Extracting robust and effective features is a crucial step towards solving these problems. However the existing approaches suffer from the sensitivity to either varying illumination, or viewpoint changing, or even camera motion, and/or the lack of spatial information. Inspired by the success of deep structures in image classification, we attempt to leverage a deep structure to extract feature for dynamic texture and scene classification. To tackle with the challenges in training a deep structure, we propose to transfer some prior knowledge from image domain to video domain. To be specific, we propose to apply a well-trained Convolutional Neural Network (ConvNet) as a mid-level feature extractor to extract features from each frame, and then form a representation of a video by concatenating the first and the second order statistics over the mid-level features. We term this two-level feature extraction scheme as a Transferred ConvNet Feature (TCoF). Moreover we explore two different implementations of the TCoF scheme, i.e., the \textit{spatial} TCoF and the \textit{temporal} TCoF, in which the mean-removed frames and the difference between two adjacent frames are used as the inputs of the ConvNet, respectively. We evaluate systematically the proposed spatial TCoF and the temporal TCoF schemes on three benchmark data sets, including DynTex, YUPENN, and Maryland, and demonstrate that the proposed approach yields superior performance.
CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning
Mar 06, 2019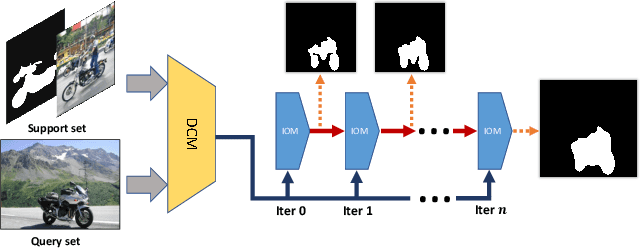
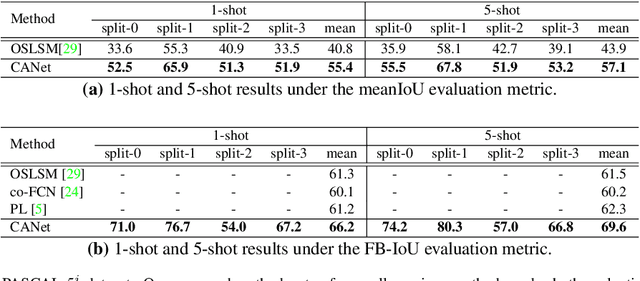
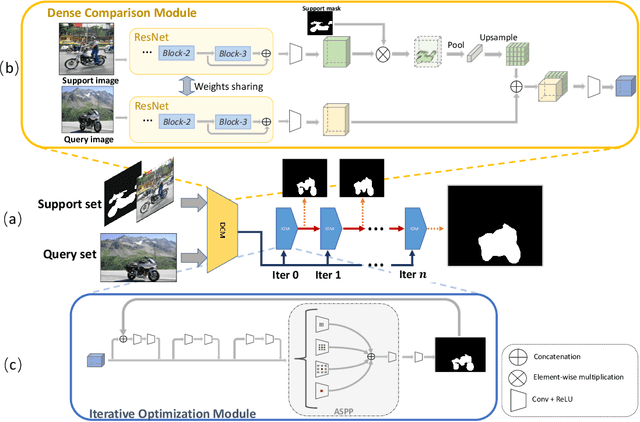

Recent progress in semantic segmentation is driven by deep Convolutional Neural Networks and large-scale labeled image datasets. However, data labeling for pixel-wise segmentation is tedious and costly. Moreover, a trained model can only make predictions within a set of pre-defined classes. In this paper, we present CANet, a class-agnostic segmentation network that performs few-shot segmentation on new classes with only a few annotated images available. Our network consists of a two-branch dense comparison module which performs multi-level feature comparison between the support image and the query image, and an iterative optimization module which iteratively refines the predicted results. Furthermore, we introduce an attention mechanism to effectively fuse information from multiple support examples under the setting of k-shot learning. Experiments on PASCAL VOC 2012 show that our method achieves a mean Intersection-over-Union score of 55.4% for 1-shot segmentation and 57.1% for 5-shot segmentation, outperforming state-of-the-art methods by a large margin of 14.6% and 13.2%, respectively.
Blink: Fast and Generic Collectives for Distributed ML
Oct 11, 2019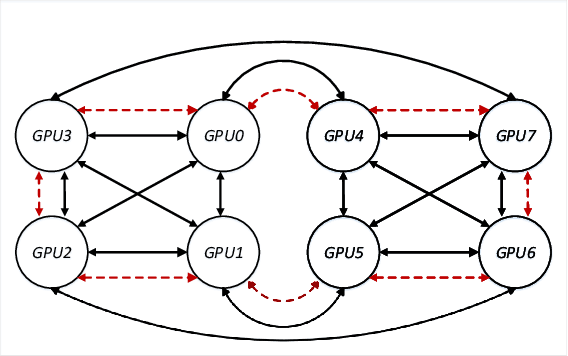
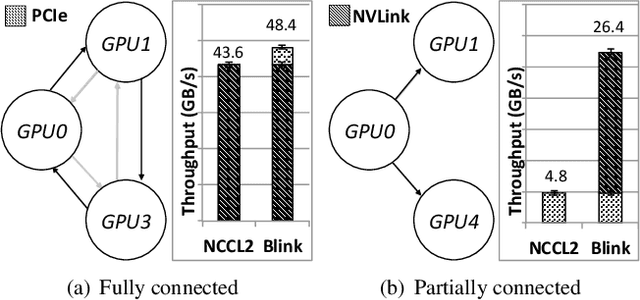
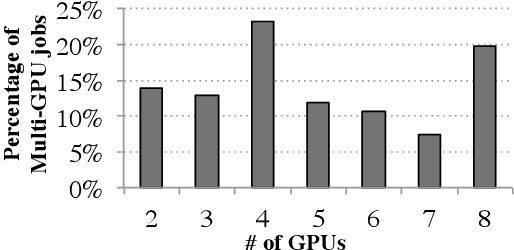
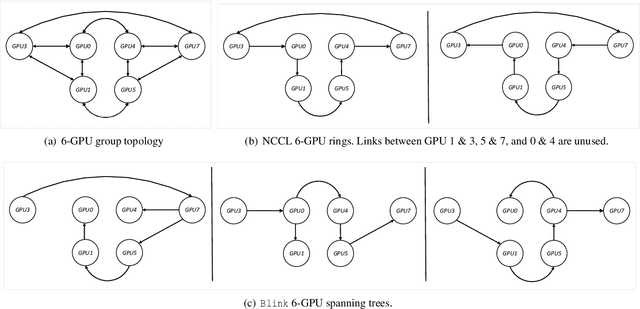
Model parameter synchronization across GPUs introduces high overheads for data-parallel training at scale. Existing parameter synchronization protocols cannot effectively leverage available network resources in the face of ever increasing hardware heterogeneity. To address this, we propose Blink, a collective communication library that dynamically generates optimal communication primitives by packing spanning trees. We propose techniques to minimize the number of trees generated and extend Blink to leverage heterogeneous communication channels for faster data transfers. Evaluations show that compared to the state-of-the-art (NCCL), Blink can achieve up to 8x faster model synchronization, and reduce end-to-end training time for image classification tasks by up to 40%.
Attend To Count: Crowd Counting with Adaptive Capacity Multi-scale CNNs
Aug 07, 2019
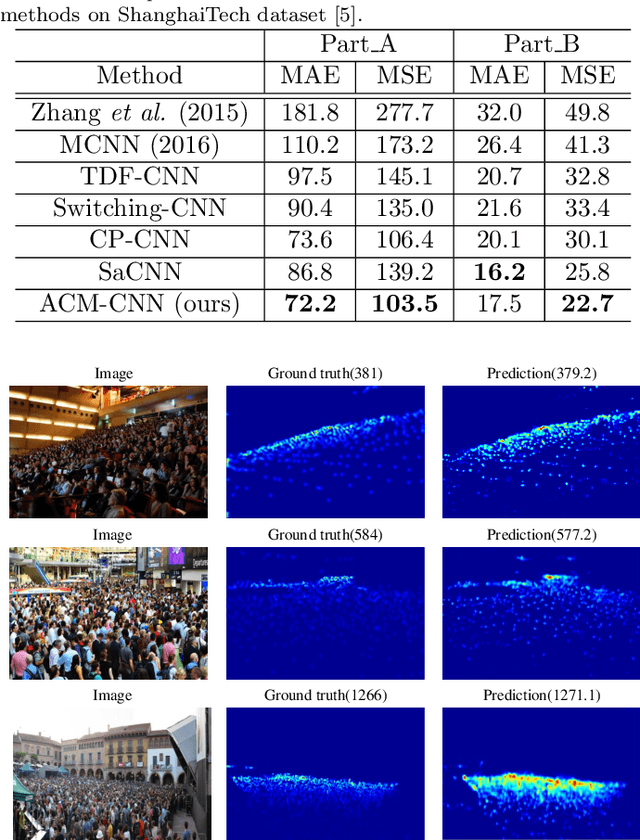
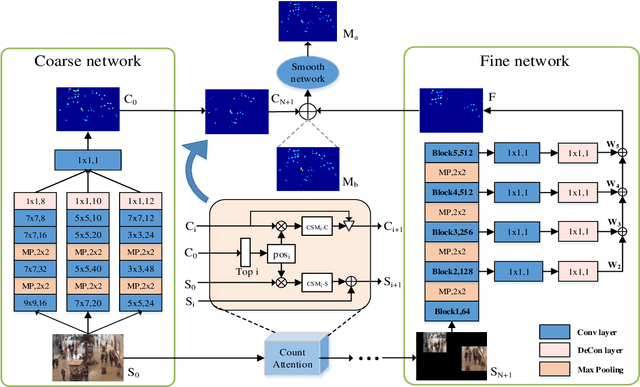
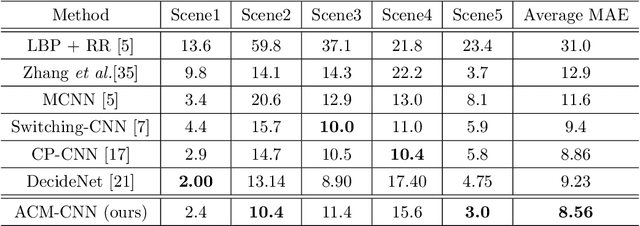
Crowd counting is a challenging task due to the large variations in crowd distributions. Previous methods tend to tackle the whole image with a single fixed structure, which is unable to handle diverse complicated scenes with different crowd densities. Hence, we propose the Adaptive Capacity Multi-scale convolutional neural networks (ACM-CNN), a novel crowd counting approach which can assign different capacities to different portions of the input. The intuition is that the model should focus on important regions of the input image and optimize its capacity allocation conditioning on the crowd intensive degree. ACM-CNN consists of three types of modules: a coarse network, a fine network, and a smooth network. The coarse network is used to explore the areas that need to be focused via count attention mechanism, and generate a rough feature map. Then the fine network processes the areas of interest into a fine feature map. To alleviate the sense of division caused by fusion, the smooth network is designed to combine two feature maps organically to produce high-quality density maps. Extensive experiments are conducted on five mainstream datasets. The results demonstrate the effectiveness of the proposed model for both density estimation and crowd counting tasks.
Cross-Resolution Person Re-identification with Deep Antithetical Learning
Oct 24, 2018
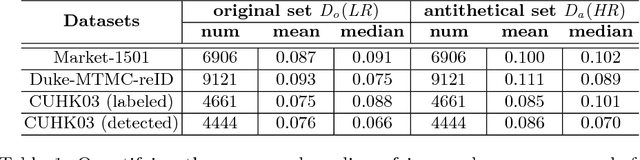
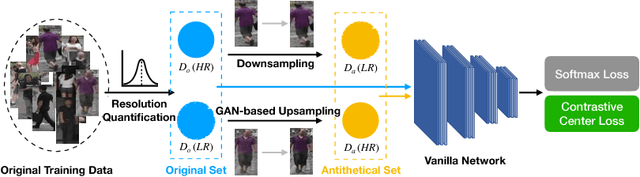
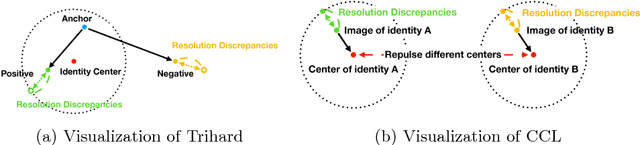
Images with different resolutions are ubiquitous in public person re-identification (ReID) datasets and real-world scenes, it is thus crucial for a person ReID model to handle the image resolution variations for improving its generalization ability. However, most existing person ReID methods pay little attention to this resolution discrepancy problem. One paradigm to deal with this problem is to use some complicated methods for mapping all images into an artificial image space, which however will disrupt the natural image distribution and requires heavy image preprocessing. In this paper, we analyze the deficiencies of several widely-used objective functions handling image resolution discrepancies and propose a new framework called deep antithetical learning that directly learns from the natural image space rather than creating an arbitrary one. We first quantify and categorize original training images according to their resolutions. Then we create an antithetical training set and make sure that original training images have counterparts with antithetical resolutions in this new set. At last, a novel Contrastive Center Loss(CCL) is proposed to learn from images with different resolutions without being interfered by their resolution discrepancies. Extensive experimental analyses and evaluations indicate that the proposed framework, even using a vanilla deep ReID network, exhibits remarkable performance improvements. Without bells and whistles, our approach outperforms previous state-of-the-art methods by a large margin.