 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
Dec 22, 2019
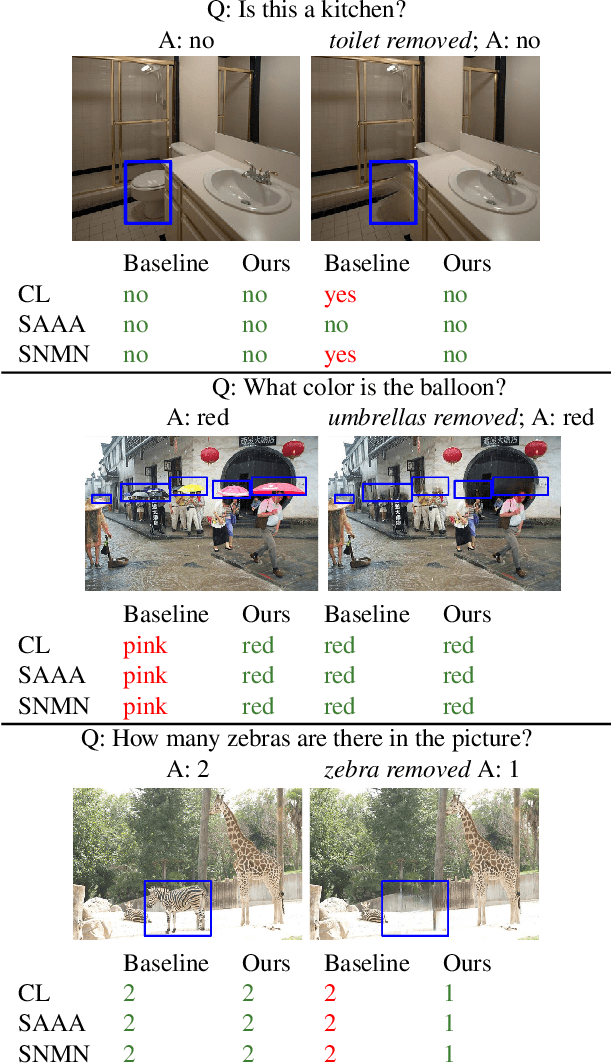

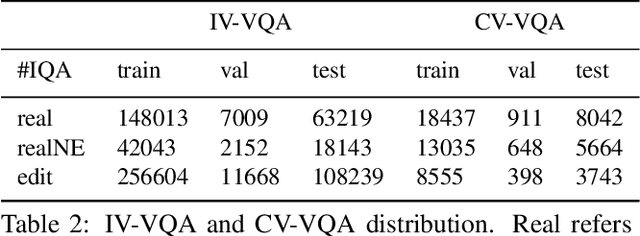

Despite significant success in Visual Question Answering (VQA), VQA models have been shown to be notoriously brittle to linguistic variations in the questions. Due to deficiencies in models and datasets, today's models often rely on correlations rather than predictions that are causal w.r.t. data. In this paper, we propose a novel way to analyze and measure the robustness of the state of the art models w.r.t semantic visual variations as well as propose ways to make models more robust against spurious correlations. Our method performs automated semantic image manipulations and tests for consistency in model predictions to quantify the model robustness as well as generate synthetic data to counter these problems. We perform our analysis on three diverse, state of the art VQA models and diverse question types with a particular focus on challenging counting questions. In addition, we show that models can be made significantly more robust against inconsistent predictions using our edited data. Finally, we show that results also translate to real-world error cases of state of the art models, which results in improved overall performance
PDE-based Group Equivariant Convolutional Neural Networks
Jan 24, 2020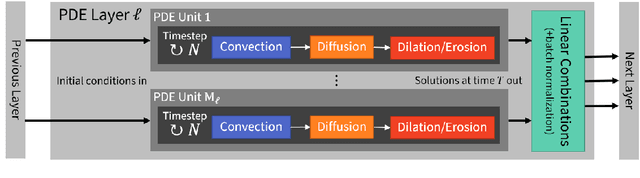
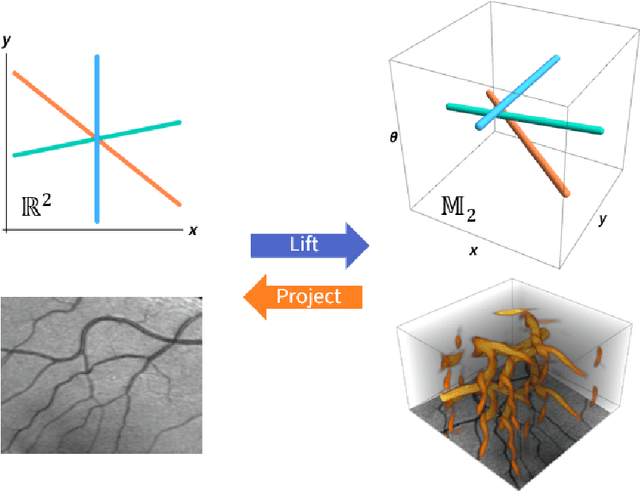
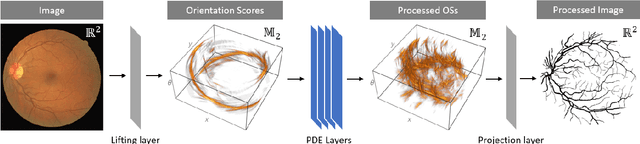
We present a PDE-based framework that generalizes Group equivariant Convolutional Neural Networks (G-CNNs). In this framework, a network layer is seen as a set of PDE-solvers where the equation's geometrically meaningful coefficients become the layer's trainable weights. Formulating our PDEs on homogeneous spaces allows these networks to be designed with built-in symmetries such as rotation equivariance instead of being restricted to just translation equivariance as in traditional CNNs. Having all the desired symmetries included in the design obviates the need to include them by means of costly techniques such as data augmentation. Roto-translation equivariance for image analysis applications is the example we will be using throughout the paper. Our default PDE is solved by a combination of linear group convolutions and non-linear morphological group convolutions. Just like for linear convolution a morphological convolution is specified by a kernel and this kernel is what is being optimized during the training process. We demonstrate how the common CNN operations of max/min-pooling and ReLUs arise naturally from solving a PDE and how they are subsumed by morphological convolutions. We present a proof-of-concept experiment to demonstrate the potential of this framework in increasing the performance of deep learning based imaging applications.
Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions
Nov 26, 2018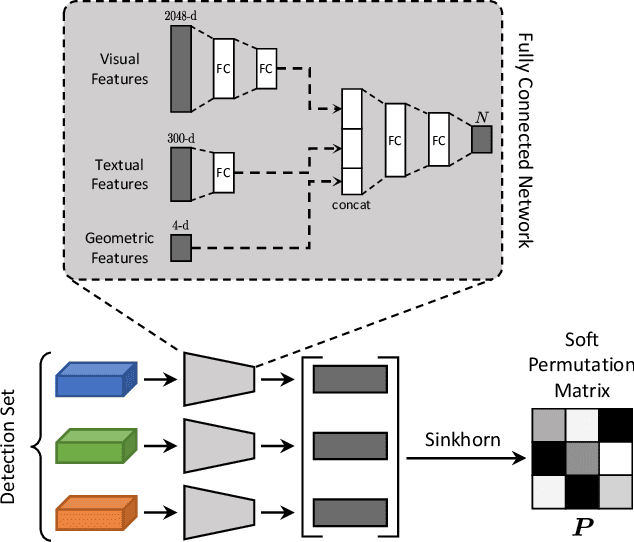
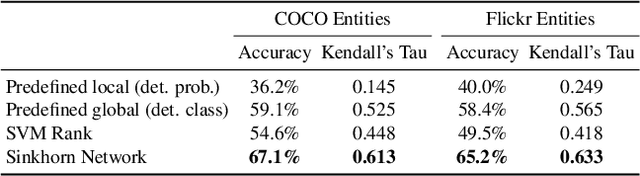
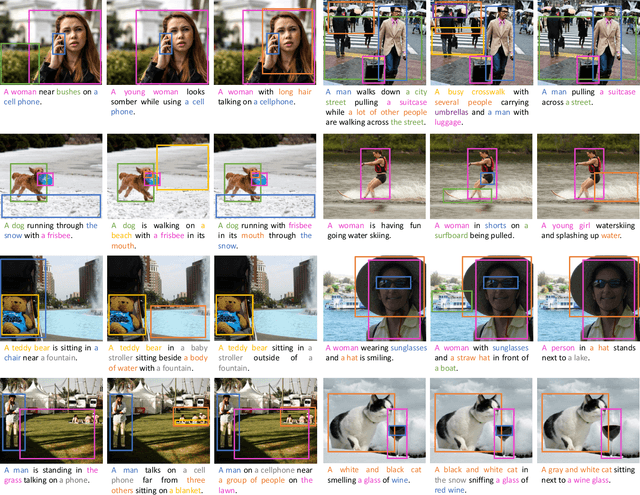
Current captioning approaches can describe images using black-box architectures whose behavior is hardly controllable and explainable from the exterior. As an image can be described in infinite ways depending on the goal and the context at hand, a higher degree of controllability is needed to apply captioning algorithms in complex scenarios. In this paper, we introduce a novel framework for image captioning which can generate diverse descriptions by allowing both grounding and controllability. Given a control signal in the form of a sequence or set of image regions, we generate the corresponding caption through a recurrent architecture which predicts textual chunks explicitly grounded on regions, following the constraints of the given control. Experiments are conducted on Flickr30k Entities and on COCO Entities, an extended version of COCO in which we add grounding annotations collected in a semi-automatic manner. Results demonstrate that our method achieves state of the art performances on controllable image captioning, in terms of caption quality and diversity. Code will be made publicly available.
Shape Detection of Liver From 2D Ultrasound Images
Nov 23, 2019Applications of ultrasound images have expanded from fetal imaging to abdominal and cardiac diagnosis. Liver-being the largest gland in the body and responsible for metabolic activities requires to be to be diagnosed and therefore subject to utmost injury. Although, ultrasound imaging has developed into three and four dimensions providing higher amount of information; it requires highly trained medical staff due to the image complexity and dimensions it contain. Since 2D ultrasound images are still considered to be the basis of clinical treatments,computer aided automated liver diagnosis is very essential. Due to the limitations of ultrasound images, such as loss of resolution leading to speckle noise, it is difficult to detect shape of organs.In this project, we propose a shape detection method for liver in 2D Ultrasound images. Then we compare the accuracies of the method for both noise and after noise removal.
Don't Forget The Past: Recurrent Depth Estimation from Monocular Video
Jan 08, 2020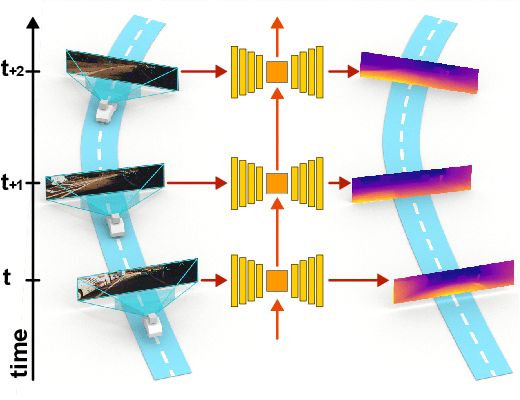
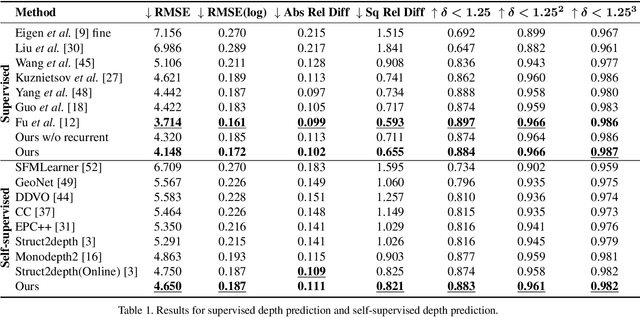
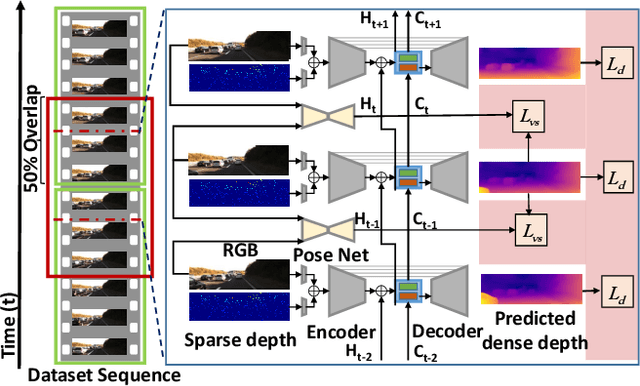
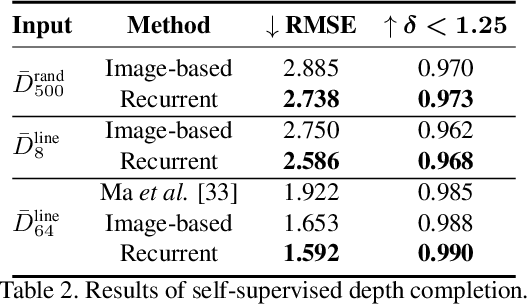
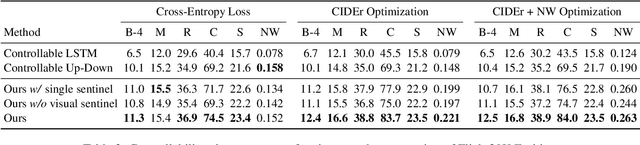
Autonomous cars need continuously updated depth information. Thus far, the depth is mostly estimated independently for a single frame at a time, even if the method starts from video input. Our method produces a time series of depth maps, which makes it an ideal candidate for online learning approaches. In particular, we put three different types of depth estimation (supervised depth prediction, self-supervised depth prediction, and self-supervised depth completion) into a common framework. We integrate the corresponding networks with a convolutional LSTM such that the spatiotemporal structures of depth across frames can be exploited to yield a more accurate depth estimation. Our method is flexible. It can be applied to monocular videos only or be combined with different types of sparse depth patterns. We carefully study the architecture of the recurrent network and its training strategy. We are first to successfully exploit recurrent networks for real-time self-supervised monocular depth estimation and completion. Extensive experiments show that our recurrent method outperforms its image-based counterpart consistently and significantly in both self-supervised scenarios. It also outperforms previous depth estimation methods of the three popular groups.
Age Progression and Regression with Spatial Attention Modules
Mar 06, 2019
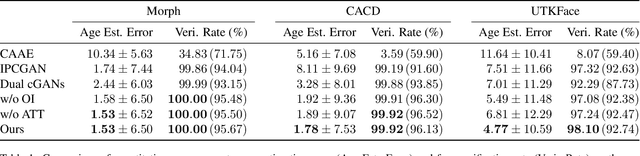
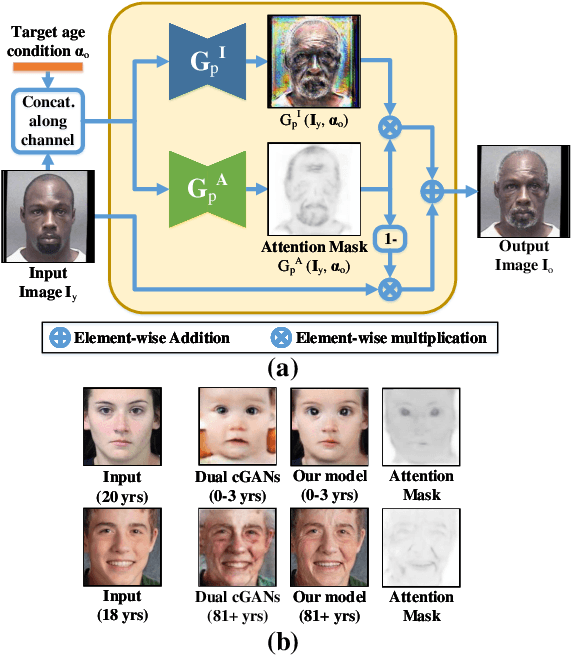
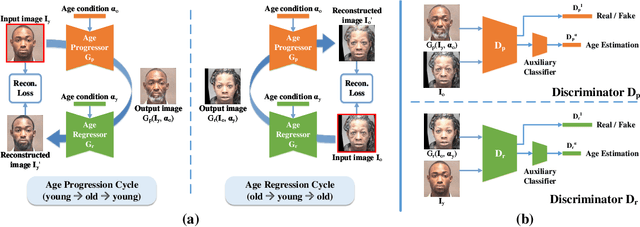
Age progression and regression refers to aesthetically rendering a given face image to present effects of face aging and rejuvenation, respectively. Although numerous studies have been conducted in this topic, there are still two major problems: 1) multiple models are usually trained to simulate different age mappings, and 2) the photo-realism of generated face images is heavily influenced by the variation of training images in terms of pose, illumination, and background. To address these issues, in this paper, we propose a framework based on conditional Generative Adversarial Networks (cGANs) to achieve age progression and regression simultaneously. Particularly, since face aging and rejuvenation are largely different in terms of image translation patterns, we model these two processes using two separate generators, each dedicated to one age changing process. In addition, we exploit the spatial attention mechanism to limit image modifications to regions closely related to age changes, so that images with high visual fidelity could be synthesized for in-the-wild cases. Experiments on multiple datasets demonstrate the ability of our model in synthesizing lifelike face images at desired ages with personalized features well preserved.
Attention Tree: Learning Hierarchies of Visual Features for Large-Scale Image Recognition
Aug 01, 2016
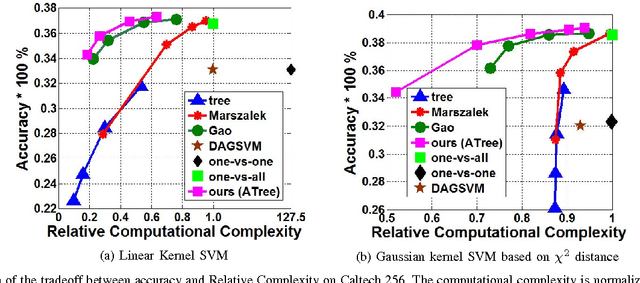
One of the key challenges in machine learning is to design a computationally efficient multi-class classifier while maintaining the output accuracy and performance. In this paper, we present a tree-based classifier: Attention Tree (ATree) for large-scale image classification that uses recursive Adaboost training to construct a visual attention hierarchy. The proposed attention model is inspired from the biological 'selective tuning mechanism for cortical visual processing'. We exploit the inherent feature similarity across images in datasets to identify the input variability and use recursive optimization procedure, to determine data partitioning at each node, thereby, learning the attention hierarchy. A set of binary classifiers is organized on top of the learnt hierarchy to minimize the overall test-time complexity. The attention model maximizes the margins for the binary classifiers for optimal decision boundary modelling, leading to better performance at minimal complexity. The proposed framework has been evaluated on both Caltech-256 and SUN datasets and achieves accuracy improvement over state-of-the-art tree-based methods at significantly lower computational cost.
Multi-Cue Vehicle Detection for Semantic Video Compression In Georegistered Aerial Videos
Jul 02, 2019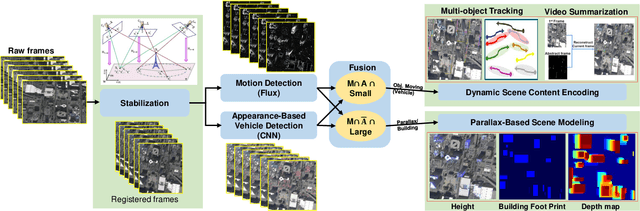
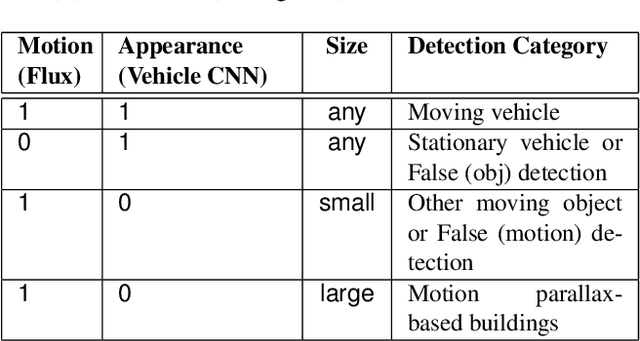
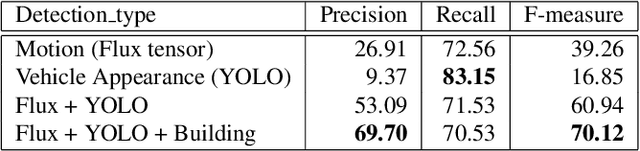
Detection of moving objects such as vehicles in videos acquired from an airborne camera is very useful for video analytics applications. Using fast low power algorithms for onboard moving object detection would also provide region of interest-based semantic information for scene content aware image compression. This would enable more efficient and flexible communication link utilization in lowbandwidth airborne cloud computing networks. Despite recent advances in both UAV or drone platforms and imaging sensor technologies, vehicle detection from aerial video remains challenging due to small object sizes, platform motion and camera jitter, obscurations, scene complexity and degraded imaging conditions. This paper proposes an efficient moving vehicle detection pipeline which synergistically fuses both appearance and motion-based detections in a complementary manner using deep learning combined with flux tensor spatio-temporal filtering. Our proposed multi-cue pipeline is able to detect moving vehicles with high precision and recall, while filtering out false positives such as parked vehicles, through intelligent fusion. Experimental results show that incorporating contextual information of moving vehicles enables high semantic compression ratios of over 100:1 with high image fidelity, for better utilization of limited bandwidth air-to-ground network links.
Are Self-Driving Cars Secure? Evasion Attacks against Deep Neural Networks for Steering Angle Prediction
Apr 15, 2019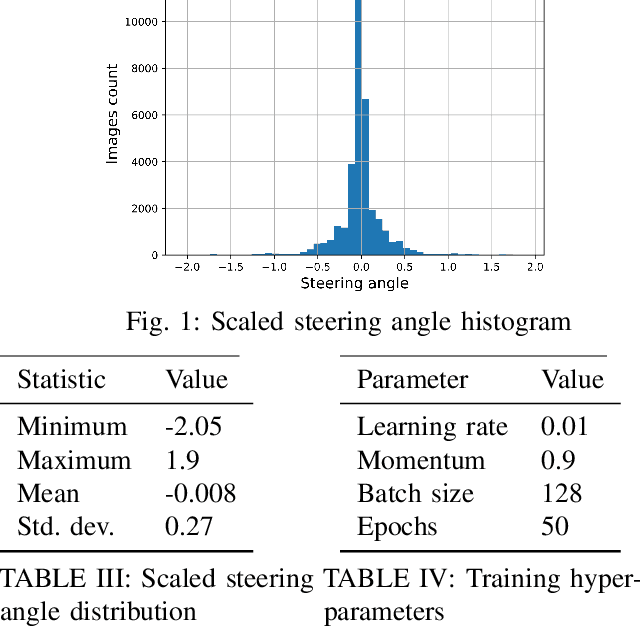
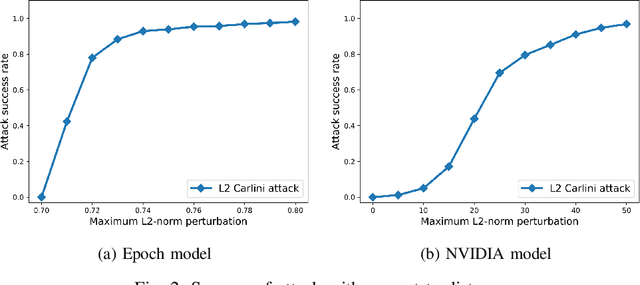
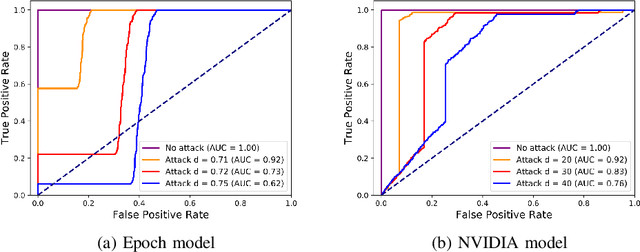

Deep Neural Networks (DNNs) have tremendous potential in advancing the vision for self-driving cars. However, the security of DNN models in this context leads to major safety implications and needs to be better understood. We consider the case study of steering angle prediction from camera images, using the dataset from the 2014 Udacity challenge. We demonstrate for the first time adversarial testing-time attacks for this application for both classification and regression settings. We show that minor modifications to the camera image (an L2 distance of 0.82 for one of the considered models) result in mis-classification of an image to any class of attacker's choice. Furthermore, our regression attack results in a significant increase in Mean Square Error (MSE) by a factor of 69 in the worst case.
AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers
Sep 23, 2019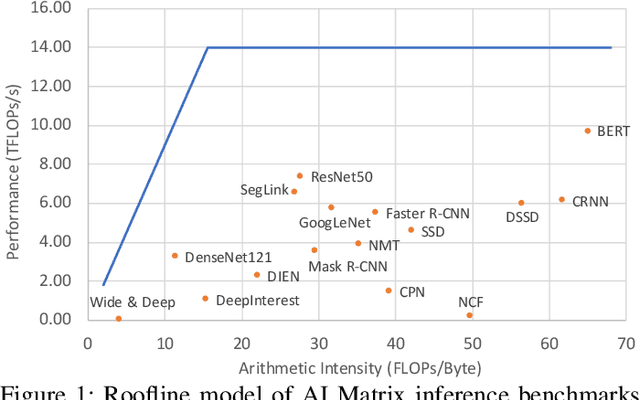
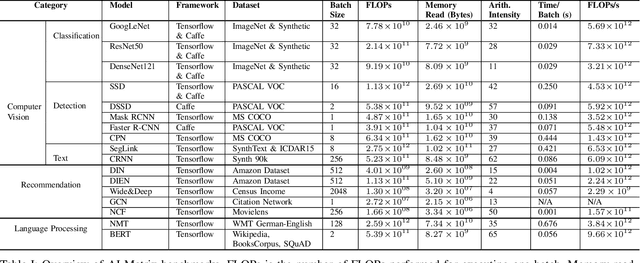
Alibaba has China's largest e-commerce platform. To support its diverse businesses, Alibaba has its own large-scale data centers providing the computing foundation for a wide variety of software applications. Among these applications, deep learning (DL) has been playing an important role in delivering services like image recognition, objection detection, text recognition, recommendation, and language processing. To build more efficient data centers that deliver higher performance for these DL applications, it is important to understand their computational needs and use that information to guide the design of future computing infrastructure. An effective way to achieve this is through benchmarks that can fully represent Alibaba's DL applications.