 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extracting temporal features into a spatial domain using autoencoders for sperm video analysis
Nov 08, 2019
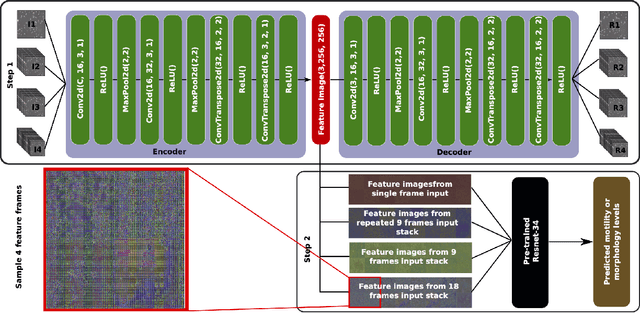
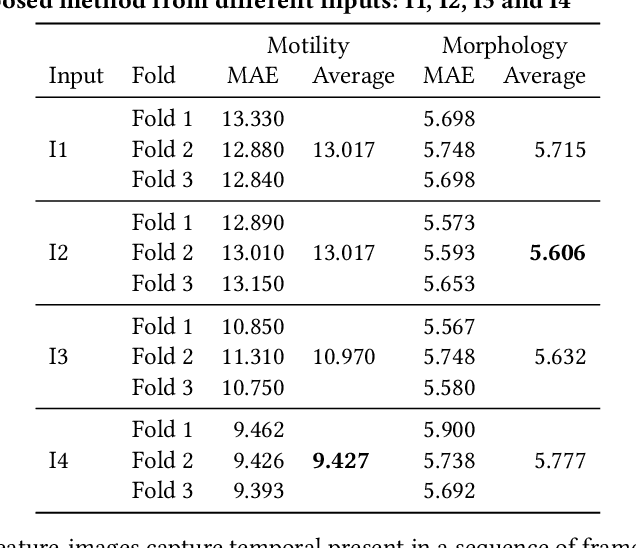
In this paper, we present a two-step deep learning method that is used to predict sperm motility and morphology-based on video recordings of human spermatozoa. First, we use an autoencoder to extract temporal features from a given semen video and plot these into image-space, which we call feature-images. Second, these feature-images are used to perform transfer learning to predict the motility and morphology values of human sperm. The presented method shows it's capability to extract temporal information into spatial domain feature-images which can be used with traditional convolutional neural networks. Furthermore, the accuracy of the predicted motility of a given semen sample shows that a deep learning-based model can capture the temporal information of microscopic recordings of human semen.
Is Texture Predictive for Age and Sex in Brain MRI?
Jul 25, 2019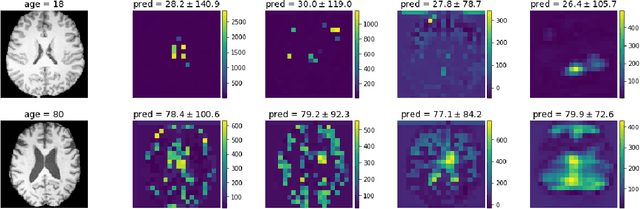
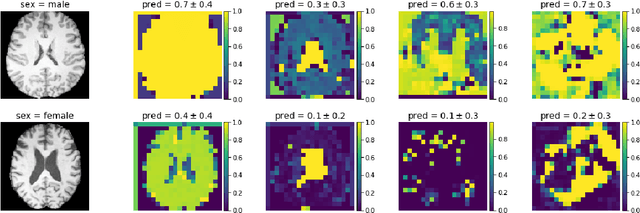
Deep learning builds the foundation for many medical image analysis tasks where neuralnetworks are often designed to have a large receptive field to incorporate long spatialdependencies. Recent work has shown that large receptive fields are not always necessaryfor computer vision tasks on natural images. We explore whether this translates to certainmedical imaging tasks such as age and sex prediction from a T1-weighted brain MRI scans.
Transferability versus Discriminability: Joint Probability Distribution Adaptation (JPDA)
Dec 01, 2019
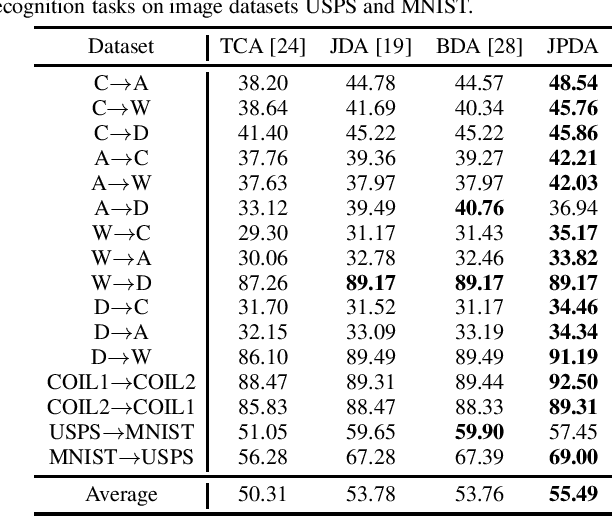
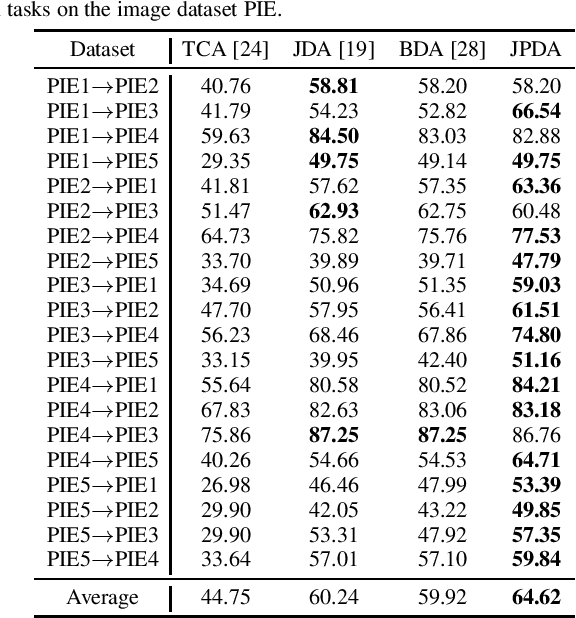
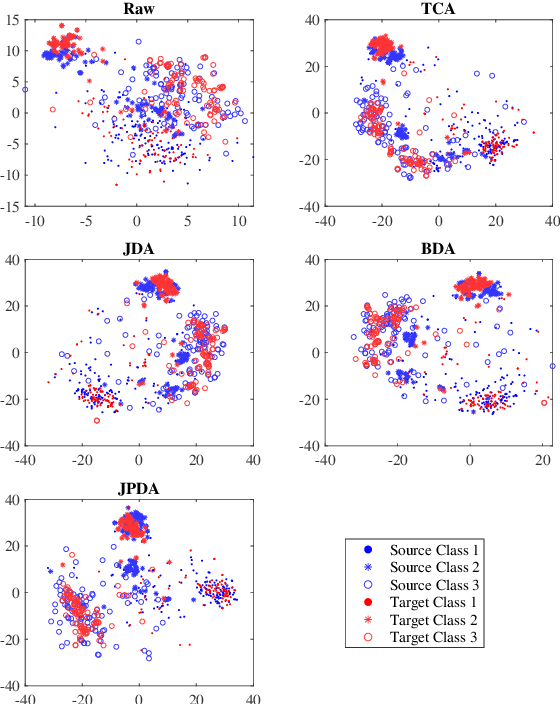
Transfer learning makes use of data or knowledge in one task to help solve a different, yet related, task. Many existing TL approaches are based on a joint probability distribution metric, which is a weighted sum of the marginal distribution and the conditional distribution; however, they optimize the two distributions independently, and ignore their intrinsic dependency. This paper proposes a novel and frustratingly easy Joint Probability Distribution Adaptation (JPDA) approach, to replace the frequently-used joint maximum mean discrepancy metric in transfer learning. During the distribution adaptation, JPDA improves the transferability between the source and the target domains by minimizing the joint probability discrepancy of the corresponding class, and also increases the discriminability between different classes by maximizing their joint probability discrepancy. Experiments on six image classification datasets demonstrated that JPDA outperforms several state-of-the-art metric-based transfer learning approaches.
Extract an essential skeleton of a character as a graph from a character image
Jun 13, 2015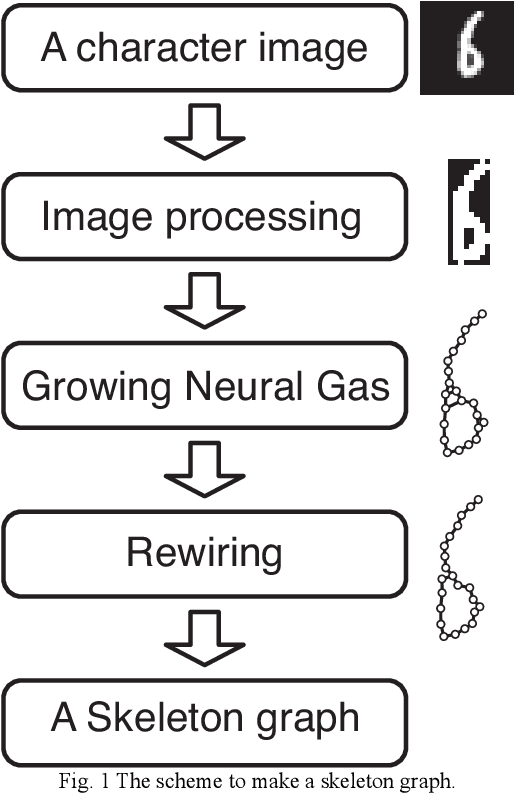
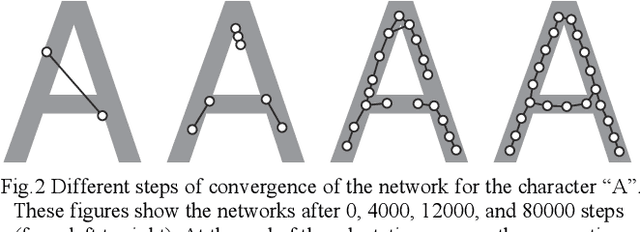
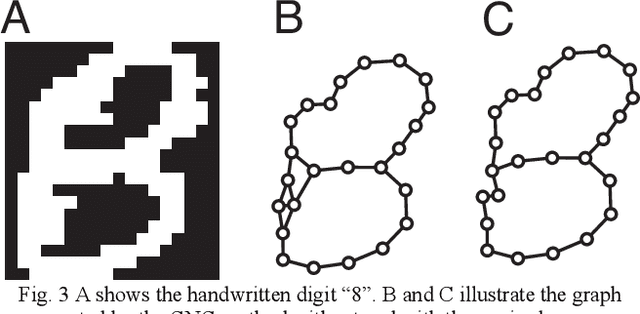

This paper aims to make a graph representing an essential skeleton of a character from an image that includes a machine printed or a handwritten character using the growing neural gas (GNG) method and the relative neighborhood graph (RNG) algorithm. The visual system in our brain can recognize printed characters and handwritten characters easily, robustly, and precisely. How can our brains robustly recognize characters? In the visual processing in our brain, essential features of an object will be used for recognition. The essential features are crosses, corners, junctions and so on. These features may be useful for character recognition by a computer. However, extraction of the features is difficult. If the skeleton of a character is represented as a graph, the features can be more easily extracted. To extract the skeleton of a character as a graph from a character image, we used the GNG method and the RNG algorithm. We achieved to extract skeleton graphs from images including distorted, noisy, and handwritten characters.
KISS: Keeping It Simple for Scene Text Recognition
Nov 19, 2019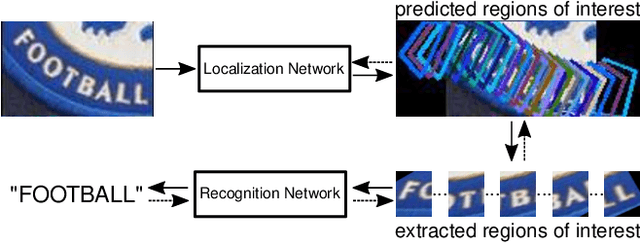
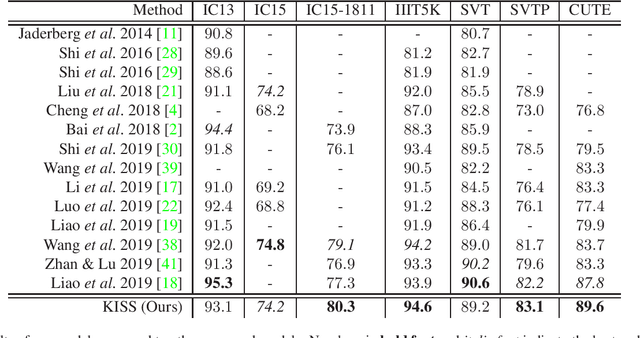
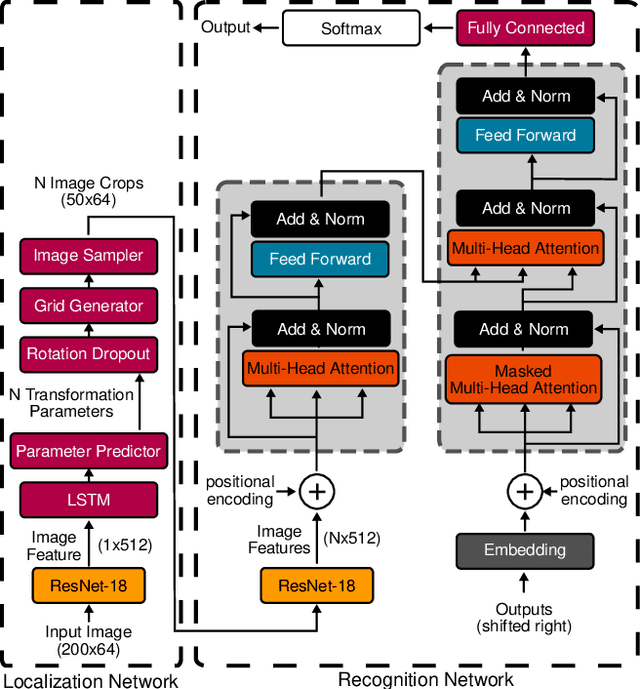
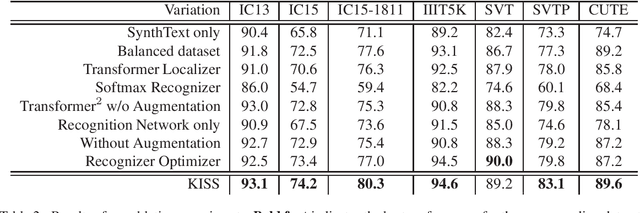
Over the past few years, several new methods for scene text recognition have been proposed. Most of these methods propose novel building blocks for neural networks. These novel building blocks are specially tailored for the task of scene text recognition and can thus hardly be used in any other tasks. In this paper, we introduce a new model for scene text recognition that only consists of off-the-shelf building blocks for neural networks. Our model (KISS) consists of two ResNet based feature extractors, a spatial transformer, and a transformer. We train our model only on publicly available, synthetic training data and evaluate it on a range of scene text recognition benchmarks, where we reach state-of-the-art or competitive performance, although our model does not use methods like 2D-attention, or image rectification.
deepCR: Cosmic Ray Rejection with Deep Learning
Jul 22, 2019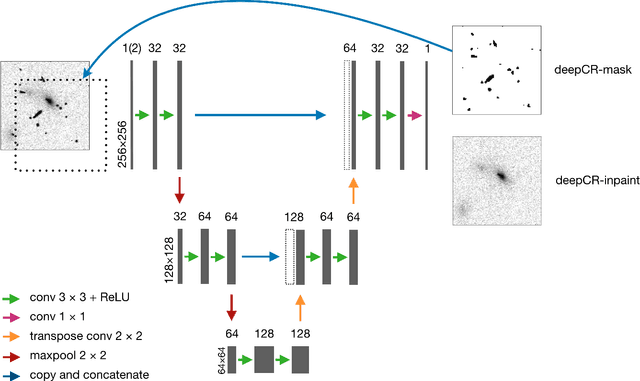
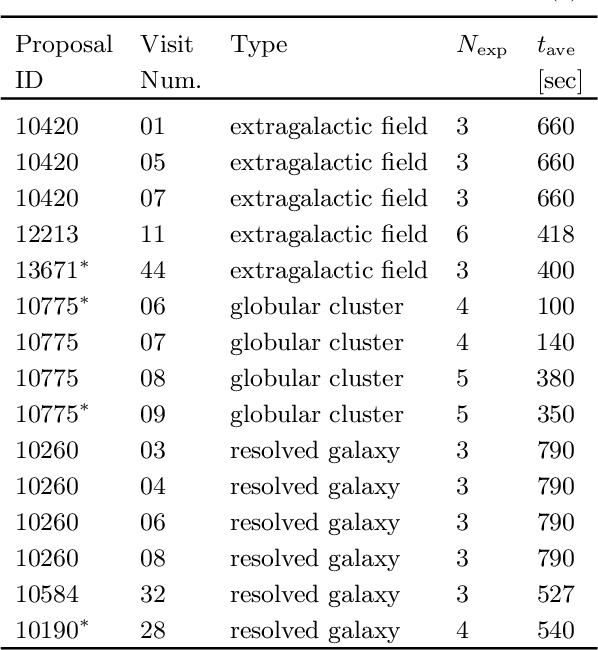

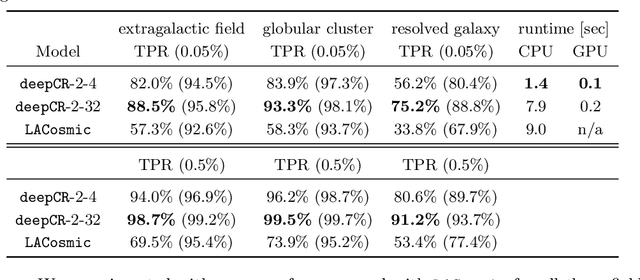
Cosmic ray (CR) identification and removal are critical components of imaging and spectroscopic reduction pipelines involving solid-state detectors. We present deepCR, a deep learning based framework for cosmic ray (CR) identification and subsequent image inpainting based on the predicted CR mask. To demonstrate the effectiveness of our framework, we have trained and evaluated models on Hubble Space Telescope ACS/WFC images of sparse extragalactic fields, globular clusters, and resolved galaxies. We demonstrate that at a reasonable false positive rate of 0.5%, deepCR achieves close to 100% detection rates in both extragalactic and globular cluster fields, and 91% in resolved galaxy fields, which is a significant improvement over current state-of-the-art method, LACosmic. Compared to a well-threaded CPU implementation of LACosmic, deepCR mask predictions runs up to 6.5 times faster on CPU and 90 times faster on GPU. For image inpainting, mean squared error of deepDR predictions are 20 times lower in globular cluster fields, 5 times lower in resolved galaxy fields, and 2.5 times lower in extragalactic fields, compared to the best performing non-neural technique. We present our framework and trained models as an open-source Python project, with a simple-to-use API.
Image Dynamic Range Enhancement in the Context of Logarithmic Models
Dec 18, 2014
Images of a scene observed under a variable illumination or with a variable optical aperture are not identical. Does a privileged representant exist? In which mathematical context? How to obtain it? The authors answer to such questions in the context of logarithmic models for images. After a short presentation of the model, the paper presents two image transforms: one performs an optimal enhancement of the dynamic range, and the other does the same for the mean dynamic range. Experimental results are shown.
Improving STDP-based Visual Feature Learning with Whitening
Feb 24, 2020
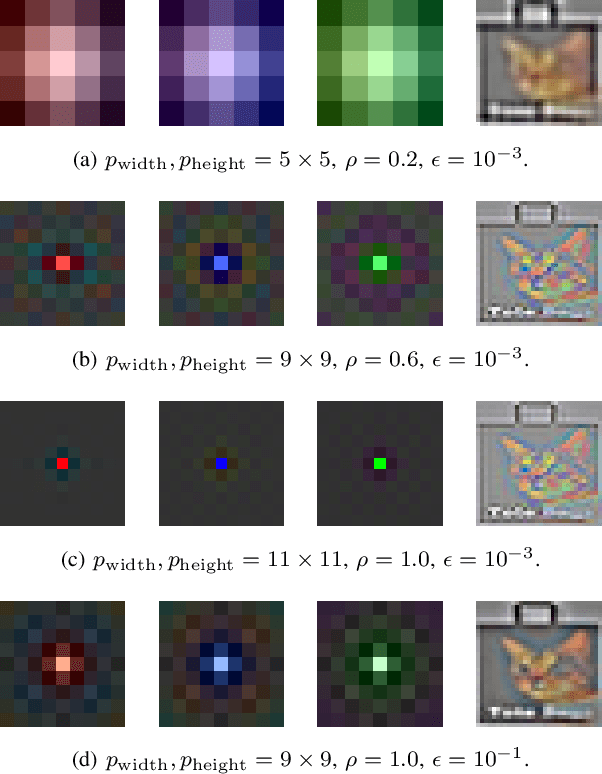
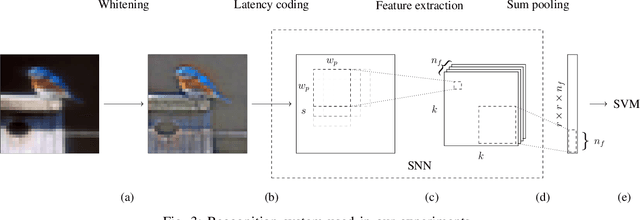
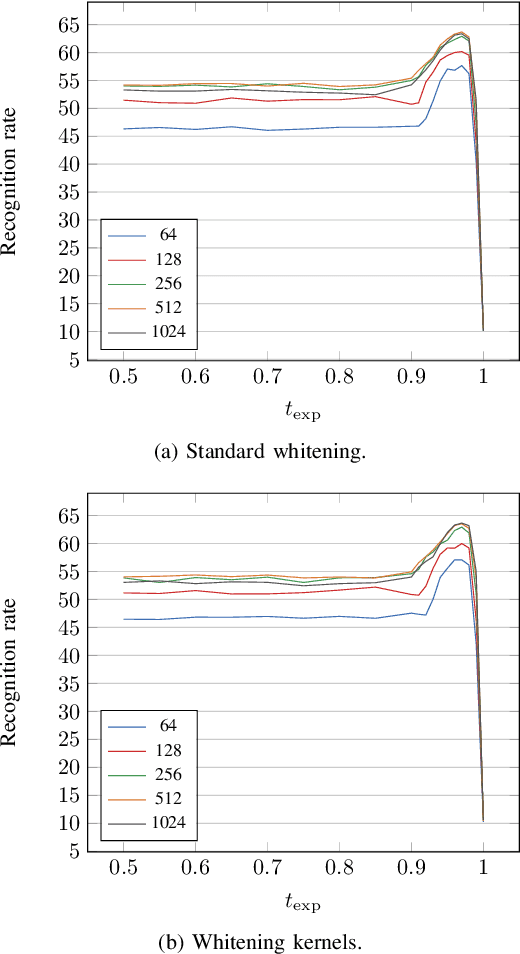
In recent years, spiking neural networks (SNNs) emerge as an alternative to deep neural networks (DNNs). SNNs present a higher computational efficiency using low-power neuromorphic hardware and require less labeled data for training using local and unsupervised learning rules such as spike timing-dependent plasticity (STDP). SNN have proven their effectiveness in image classification on simple datasets such as MNIST. However, to process natural images, a pre-processing step is required. Difference-of-Gaussians (DoG) filtering is typically used together with on-center/off-center coding, but it results in a loss of information that is detrimental to the classification performance. In this paper, we propose to use whitening as a pre-processing step before learning features with STDP. Experiments on CIFAR-10 show that whitening allows STDP to learn visual features that are closer to the ones learned with standard neural networks, with a significantly increased classification performance as compared to DoG filtering. We also propose an approximation of whitening as convolution kernels that is computationally cheaper to learn and more suited to be implemented on neuromorphic hardware. Experiments on CIFAR-10 show that it performs similarly to regular whitening. Cross-dataset experiments on CIFAR-10 and STL-10 also show that it is fairly stable across datasets, making it possible to learn a single whitening transformation to process different datasets.
A Machine-Synesthetic Approach To DDoS Network Attack Detection
Jan 13, 2019
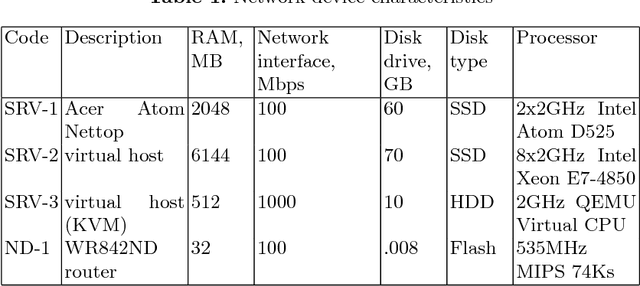

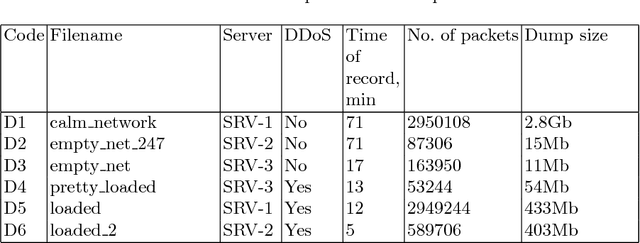
In the authors' opinion, anomaly detection systems, or ADS, seem to be the most perspective direction in the subject of attack detection, because these systems can detect, among others, the unknown (zero-day) attacks. To detect anomalies, the authors propose to use machine synesthesia. In this case, machine synesthesia is understood as an interface that allows using image classification algorithms in the problem of detecting network anomalies, making it possible to use non-specialized image detection methods that have recently been widely and actively developed. The proposed approach is that the network traffic data is "projected" into the image. It can be seen from the experimental results that the proposed method for detecting anomalies shows high results in the detection of attacks. On a large sample, the value of the complex efficiency indicator reaches 97%.
Decoupled Attention Network for Text Recognition
Dec 21, 2019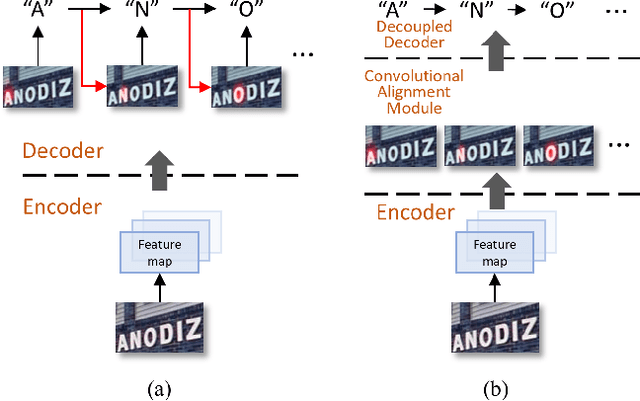
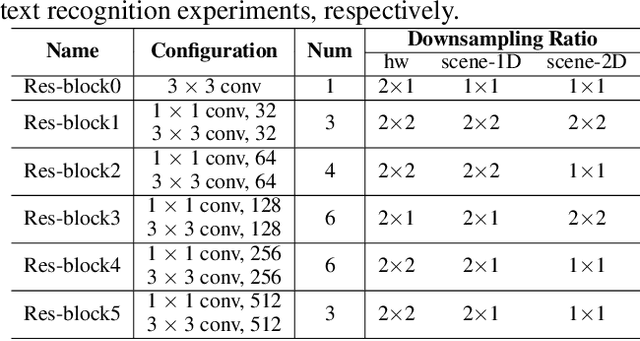
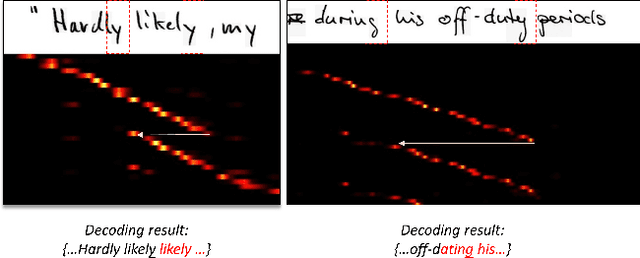
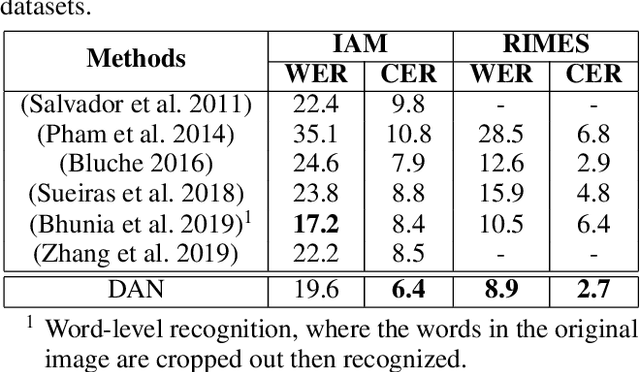
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.