 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Flexible Framework for Large Graph Learning
Mar 21, 2020
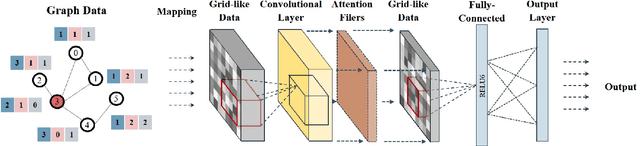

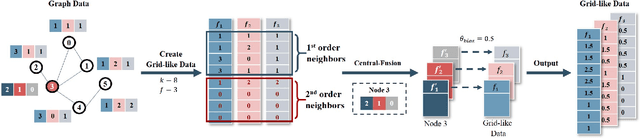
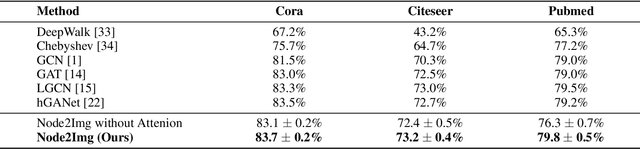
Graph Convolutional Network (GCN) has shown strong effectiveness in graph learning tasks. However, GCN faces challenges in flexibility due to the fact of requiring the full graph Laplacian available in the training phase. Moreover, with the depth of layers increases, the computational and memory cost of GCN grows explosively on account of the recursive neighborhood expansion, which leads to a limitation in processing large graphs. To tackle these issues, we take advantage of image processing in agility and present Node2Img, a flexible architecture for large-scale graph learning. Node2Img maps the nodes to "images" (i.e. grid-like data in Euclidean space) which can be the inputs of Convolutional Neural Network (CNN). Instead of leveraging the fixed whole network as a batch to train the model, Node2Img supports a more efficacious framework in practice, where the batch size can be set elastically and the data in the same batch can be calculated parallelly. Specifically, by ranking each node's influence through degree, Node2Img selects the most influential first-order as well as second-order neighbors with central node fusion information to construct the grid-like data. For further improving the efficiency of downstream tasks, a simple CNN-based neural network is employed to capture the significant information from the Euclidean grids. Additionally, the attention mechanism is implemented, which enables implicitly specifying the different weights for neighboring nodes with different influences. Extensive experiments on real graphs' transductive and inductive learning tasks demonstrate the superiority of the proposed Node2Img model against the state-of-the-art GCN-based approaches.
Deep Amortized Clustering
Sep 30, 2019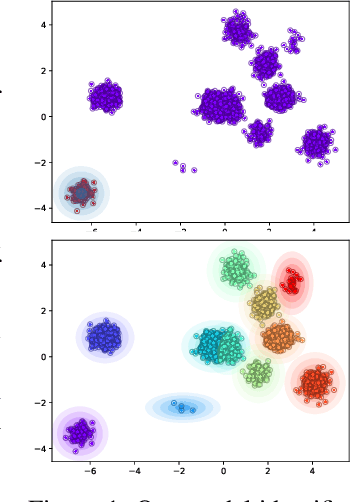
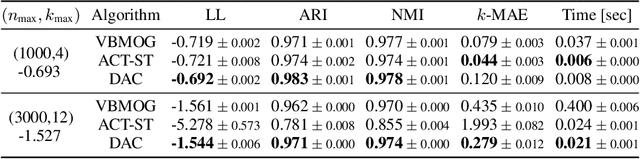
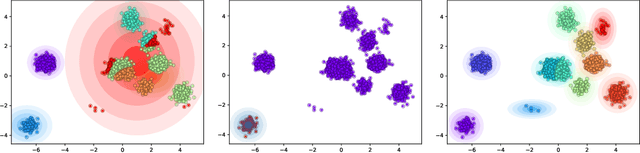
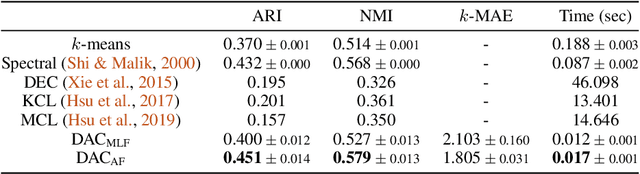
We propose a deep amortized clustering (DAC), a neural architecture which learns to cluster datasets efficiently using a few forward passes. DAC implicitly learns what makes a cluster, how to group data points into clusters, and how to count the number of clusters in datasets. DAC is meta-learned using labelled datasets for training, a process distinct from traditional clustering algorithms which usually require hand-specified prior knowledge about cluster shapes/structures. We empirically show, on both synthetic and image data, that DAC can efficiently and accurately cluster new datasets coming from the same distribution used to generate training datasets.
Learning Shape Priors for Robust Cardiac MR Segmentation from Multi-view Images
Jul 23, 2019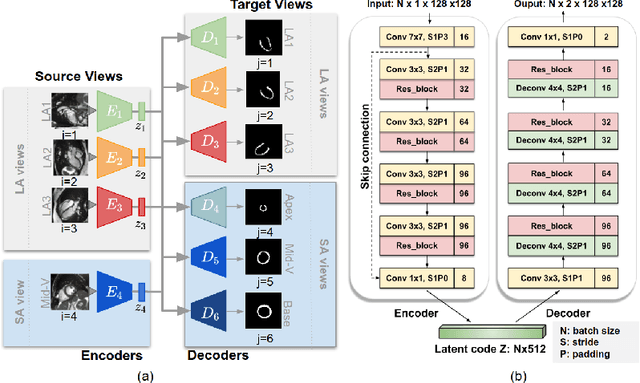
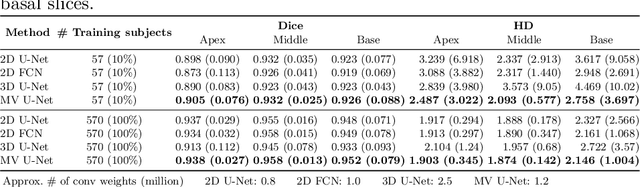
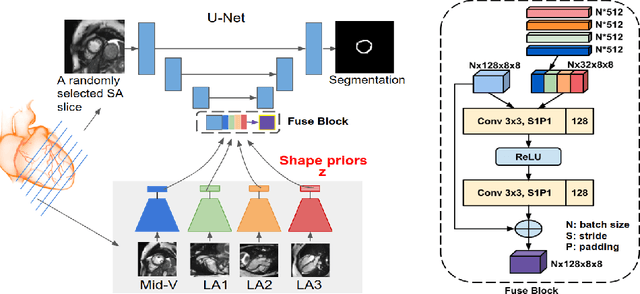
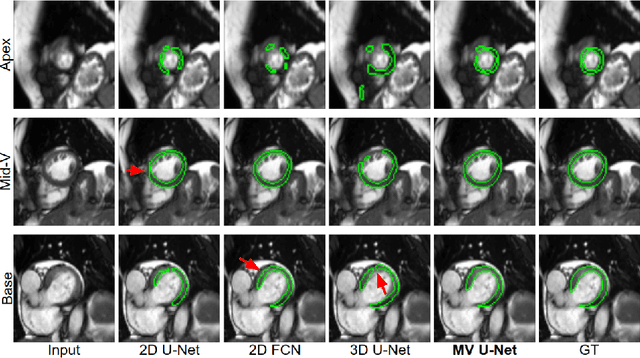
Cardiac MR image segmentation is essential for the morphological and functional analysis of the heart. Inspired by how experienced clinicians assess the cardiac morphology and function across multiple standard views (i.e. long- and short-axis views), we propose a novel approach which learns anatomical shape priors across different 2D standard views and leverages these priors to segment the left ventricular (LV) myocardium from short-axis MR image stacks. The proposed segmentation method has the advantage of being a 2D network but at the same time incorporates spatial context from multiple, complementary views that span a 3D space. Our method achieves accurate and robust segmentation of the myocardium across different short-axis slices (from apex to base), outperforming baseline models (e.g. 2D U-Net, 3D U-Net) while achieving higher data efficiency. Compared to the 2D U-Net, the proposed method reduces the mean Hausdorff distance (mm) from 3.24 to 2.49 on the apical slices, from 2.34 to 2.09 on the middle slices and from 3.62 to 2.76 on the basal slices on the test set, when only 10% of the training data was used.
Pseudo-Convolutional Policy Gradient for Sequence-to-Sequence Lip-Reading
Mar 09, 2020
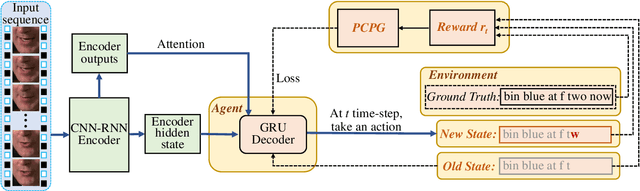
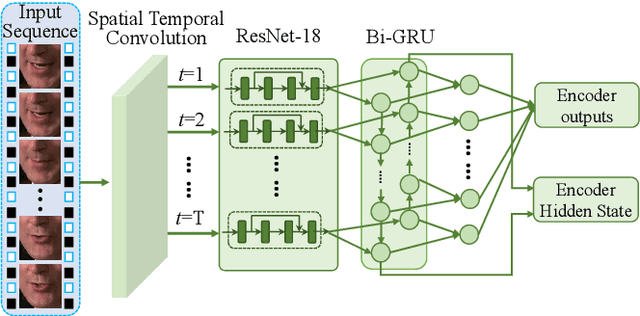
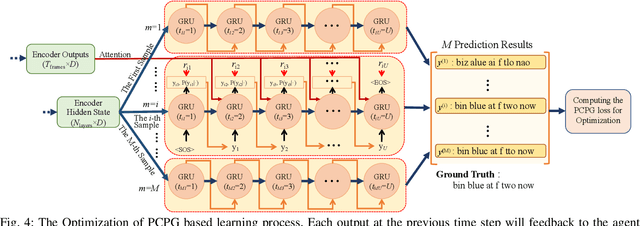
Lip-reading aims to infer the speech content from the lip movement sequence and can be seen as a typical sequence-to-sequence (seq2seq) problem which translates the input image sequence of lip movements to the text sequence of the speech content. However, the traditional learning process of seq2seq models always suffers from two problems: the exposure bias resulted from the strategy of "teacher-forcing", and the inconsistency between the discriminative optimization target (usually the cross-entropy loss) and the final evaluation metric (usually the character/word error rate). In this paper, we propose a novel pseudo-convolutional policy gradient (PCPG) based method to address these two problems. On the one hand, we introduce the evaluation metric (refers to the character error rate in this paper) as a form of reward to optimize the model together with the original discriminative target. On the other hand, inspired by the local perception property of convolutional operation, we perform a pseudo-convolutional operation on the reward and loss dimension, so as to take more context around each time step into account to generate a robust reward and loss for the whole optimization. Finally, we perform a thorough comparison and evaluation on both the word-level and sentence-level benchmarks. The results show a significant improvement over other related methods, and report either a new state-of-the-art performance or a competitive accuracy on all these challenging benchmarks, which clearly proves the advantages of our approach.
Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep Generative Models
Nov 08, 2019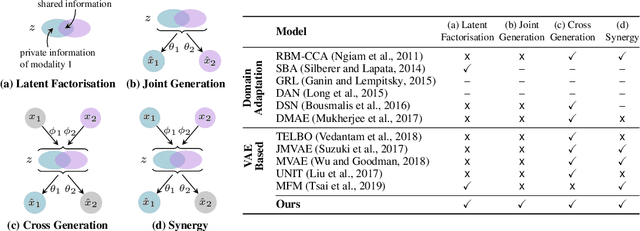


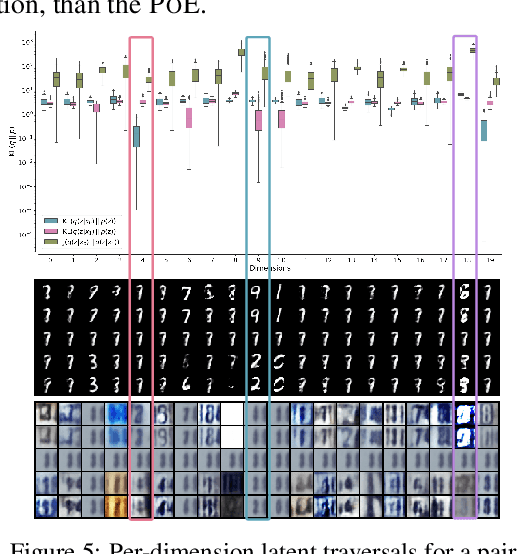
Learning generative models that span multiple data modalities, such as vision and language, is often motivated by the desire to learn more useful, generalisable representations that faithfully capture common underlying factors between the modalities. In this work, we characterise successful learning of such models as the fulfillment of four criteria: i) implicit latent decomposition into shared and private subspaces, ii) coherent joint generation over all modalities, iii) coherent cross-generation across individual modalities, and iv) improved model learning for individual modalities through multi-modal integration. Here, we propose a mixture-of-experts multimodal variational autoencoder (MMVAE) to learn generative models on different sets of modalities, including a challenging image-language dataset, and demonstrate its ability to satisfy all four criteria, both qualitatively and quantitatively.
Vectorizing World Buildings: Planar Graph Reconstruction by Primitive Detection and Relationship Classification
Dec 12, 2019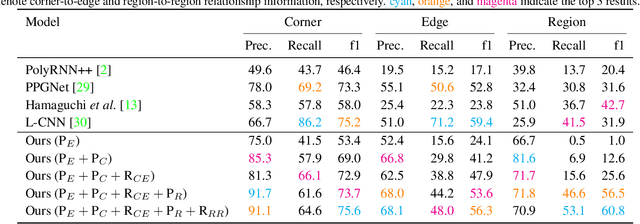


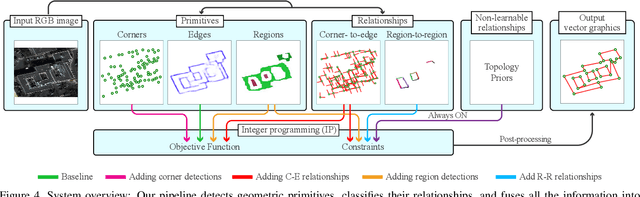
This paper tackles a 2D architecture vectorization problem, whose task is to infer an outdoor building architecture as a 2D planar graph from a single RGB image. We provide a new benchmark with ground-truth annotations for 2,001 complex buildings across the cities of Atlanta, Paris, and Las Vegas. We also propose a novel algorithm utilizing 1) convolutional neural networks (CNNs) that detects geometric primitives and classifies their relationships and 2) an integer programming (IP) that assembles the information into a 2D planar graph. While being a trivial task for human vision, the inference of a graph structure with an arbitrary topology is still an open problem for computer vision. Qualitative and quantitative evaluations demonstrate that our algorithm makes significant improvements over the current state-of-the-art, towards an intelligent system at the level of human perception. We will share code and data to promote further research.
End-to-End Denoising of Dark Burst Images Using Recurrent Fully Convolutional Networks
Apr 16, 2019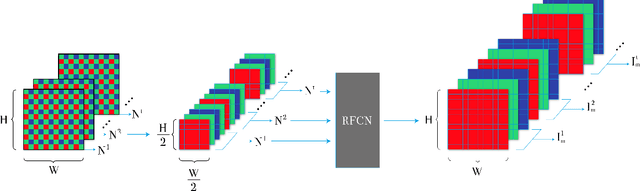
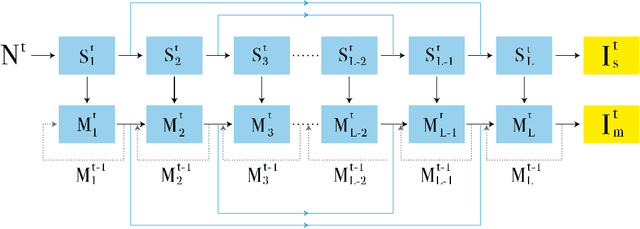


When taking photos in dim-light environments, due to the small amount of light entering, the shot images are usually extremely dark, with a great deal of noise, and the color cannot reflect real-world color. Under this condition, the traditional methods used for single image denoising have always failed to be effective. One common idea is to take multiple frames of the same scene to enhance the signal-to-noise ratio. This paper proposes a recurrent fully convolutional network (RFCN) to process burst photos taken under extremely low-light conditions, and to obtain denoised images with improved brightness. Our model maps raw burst images directly to sRGB outputs, either to produce a best image or to generate a multi-frame denoised image sequence. This process has proven to be capable of accomplishing the low-level task of denoising, as well as the high-level task of color correction and enhancement, all of which is end-to-end processing through our network. Our method has achieved better results than state-of-the-art methods. In addition, we have applied the model trained by one type of camera without fine-tuning on photos captured by different cameras and have obtained similar end-to-end enhancements.
Counterfactual Visual Explanations
Apr 16, 2019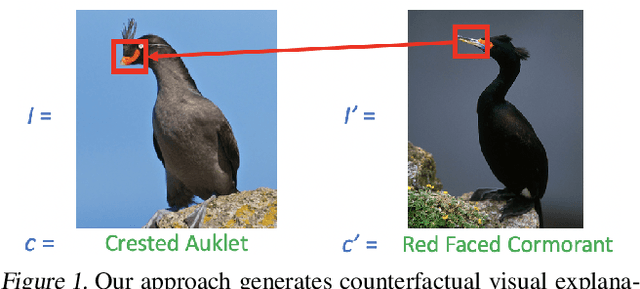
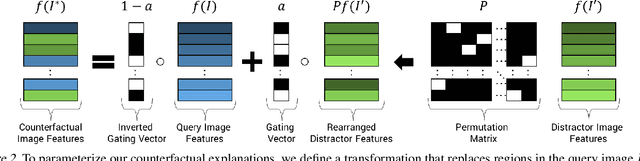
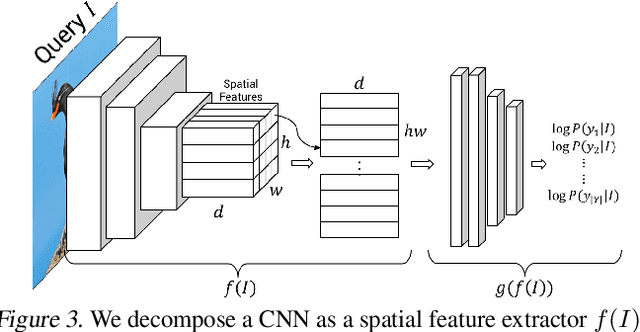
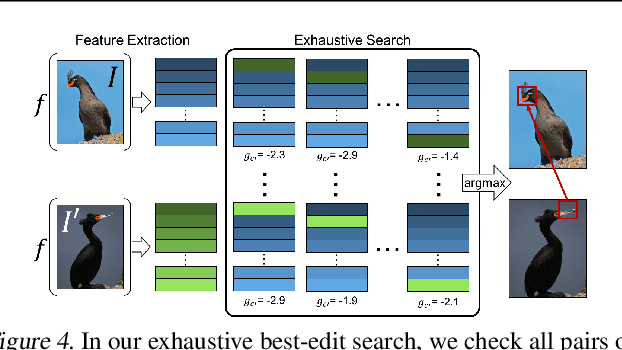
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Deep Learning for Estimating Synaptic Health of Primary Neuronal Cell Culture
Aug 29, 2019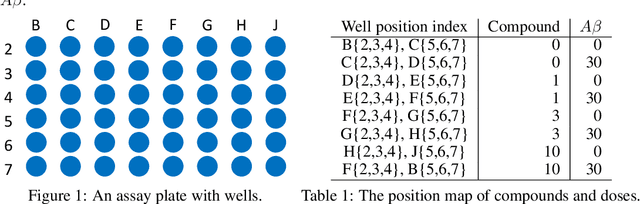

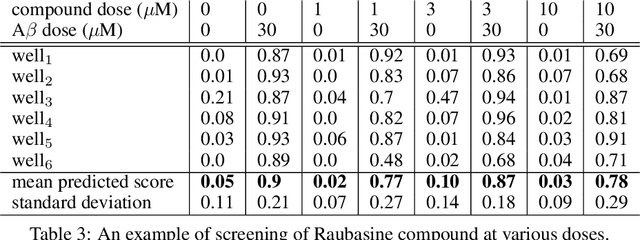

Understanding the morphological changes of primary neuronal cells induced by chemical compounds is essential for drug discovery. Using the data from a single high-throughput imaging assay, a classification model for predicting the biological activity of candidate compounds was introduced. The image recognition model which is based on deep convolutional neural network (CNN) architecture with residual connections achieved accuracy of 99.6$\%$ on a binary classification task of distinguishing untreated and treated rodent primary neuronal cells with Amyloid-$\beta_{(25-35)}$.
Extract an essential skeleton of a character as a graph from a character image
Jun 13, 2015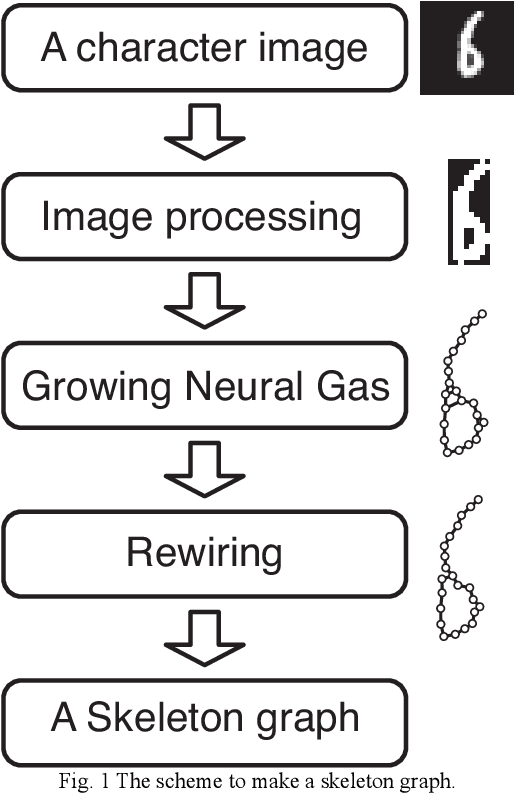
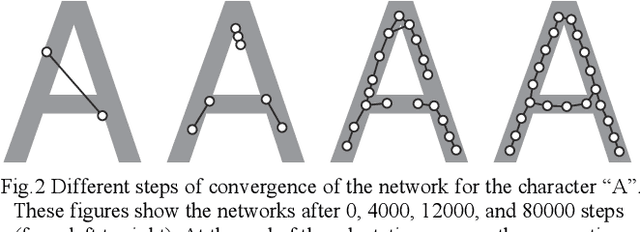
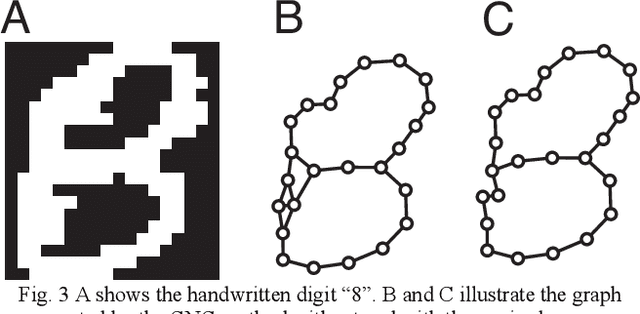

This paper aims to make a graph representing an essential skeleton of a character from an image that includes a machine printed or a handwritten character using the growing neural gas (GNG) method and the relative neighborhood graph (RNG) algorithm. The visual system in our brain can recognize printed characters and handwritten characters easily, robustly, and precisely. How can our brains robustly recognize characters? In the visual processing in our brain, essential features of an object will be used for recognition. The essential features are crosses, corners, junctions and so on. These features may be useful for character recognition by a computer. However, extraction of the features is difficult. If the skeleton of a character is represented as a graph, the features can be more easily extracted. To extract the skeleton of a character as a graph from a character image, we used the GNG method and the RNG algorithm. We achieved to extract skeleton graphs from images including distorted, noisy, and handwritten characters.