 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multiphase Image Segmentation Based on Fuzzy Membership Functions and L1-norm Fidelity
Feb 12, 2016
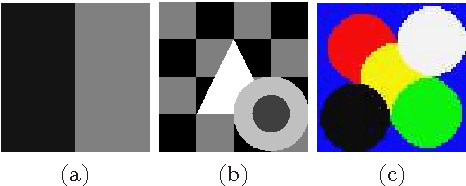
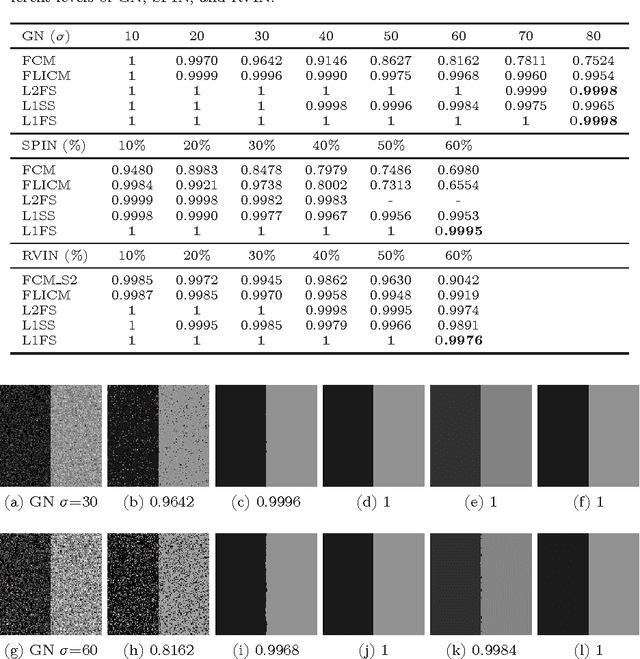
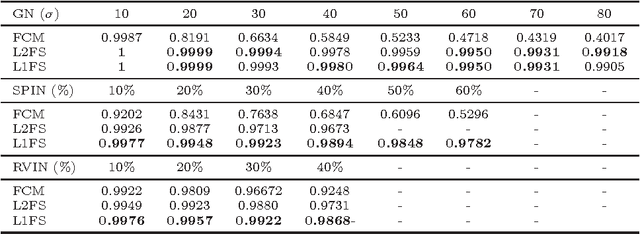
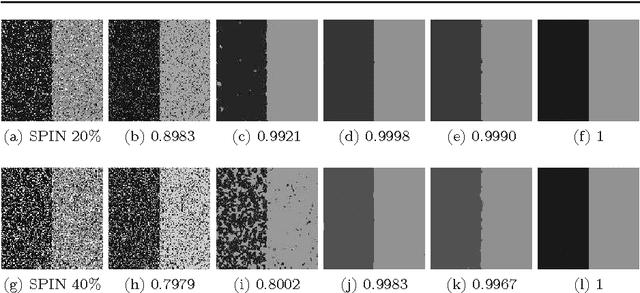
In this paper, we propose a variational multiphase image segmentation model based on fuzzy membership functions and L1-norm fidelity. Then we apply the alternating direction method of multipliers to solve an equivalent problem. All the subproblems can be solved efficiently. Specifically, we propose a fast method to calculate the fuzzy median. Experimental results and comparisons show that the L1-norm based method is more robust to outliers such as impulse noise and keeps better contrast than its L2-norm counterpart. Theoretically, we prove the existence of the minimizer and analyze the convergence of the algorithm.
* 28 pages, 8 figures, 3 tables
Task-Aware Variational Adversarial Active Learning
Feb 11, 2020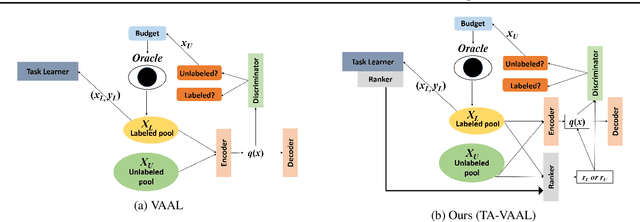
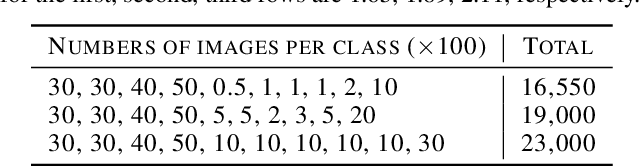
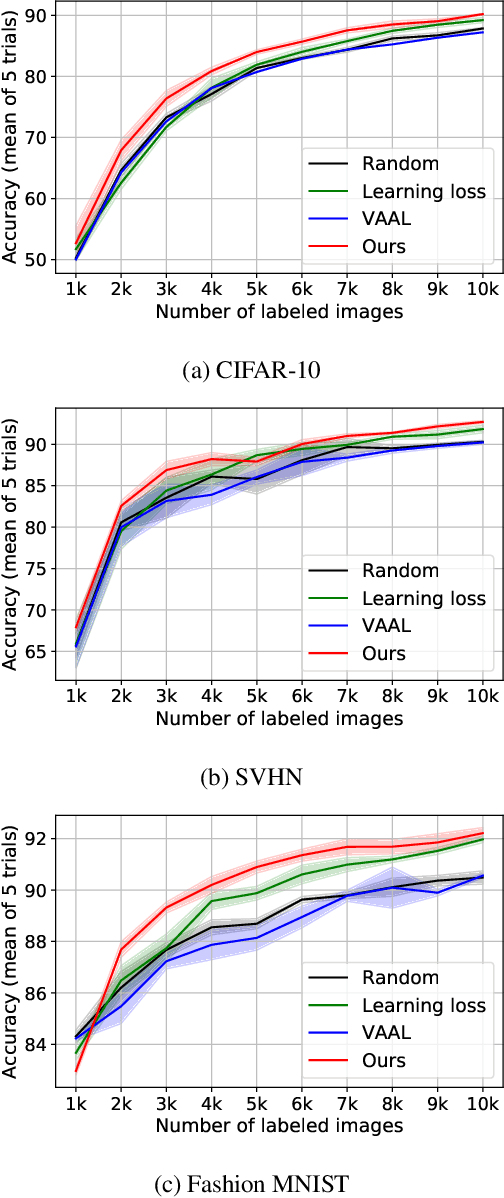
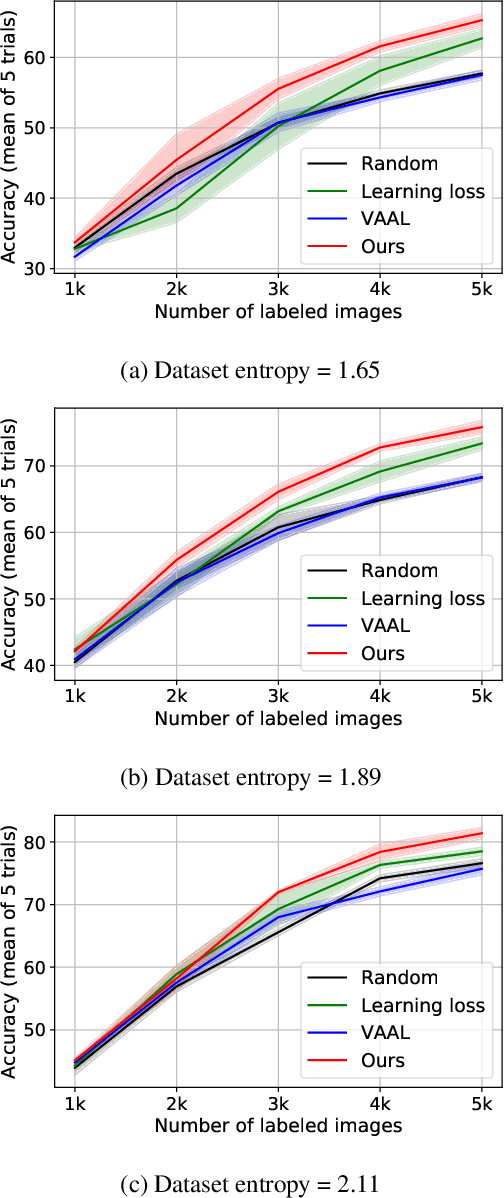
Deep learning has achieved remarkable performance in various tasks thanks to massive labeled datasets. However, there are often cases where labeling large amount of data is challenging or infeasible due to high labeling cost such as labeling by experts or long labeling time per large-scale data sample (e.g., video, very large image). Active learning is one of the ways to query the most informative samples to be annotated among massive unlabeled pool. Two promising directions for active learning that have been recently explored are data distribution-based approach to select data points that are far from current labeled pool and model uncertainty-based approach that relies on the perspective of task model. Unfortunately, the former does not exploit structures from tasks and the latter does not seem to well-utilize overall data distribution. Here, we propose the methods that simultaneously take advantage of both data distribution and model uncertainty approaches. Our proposed methods exploit variational adversarial active learning (VAAL), that considered data distribution of both label and unlabeled pools, by incorporating learning loss prediction module and RankCGAN concept into VAAL by modeling loss prediction as a ranker. We demonstrate that our proposed methods outperform recent state-of-the-art active learning methods on various balanced and imbalanced benchmark datasets.
Learning to Generate Dense Point Clouds with Textures on Multiple Categories
Dec 22, 2019
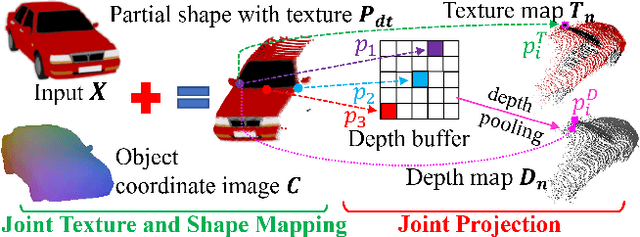

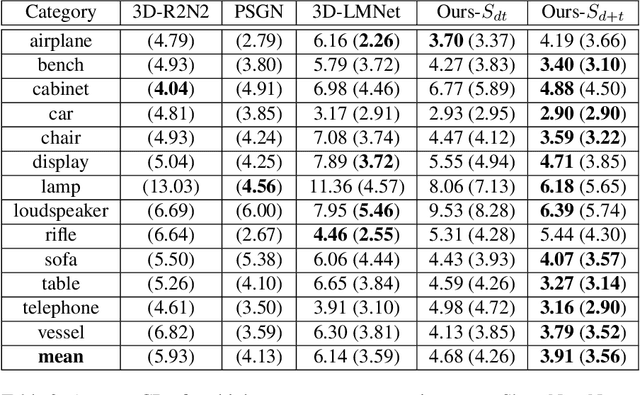
3D reconstruction from images is a core problem in computer vision. With recent advances in deep learning, it has become possible to recover plausible 3D shapes even from single RGB images for the first time. However, obtaining detailed geometry and texture for objects with arbitrary topology remains challenging. In this paper, we propose a novel approach for reconstructing point clouds from RGB images. Unlike other methods, we can recover dense point clouds with hundreds of thousands of points, and we also include RGB textures. In addition, we train our model on multiple categories which leads to superior generalization to unseen categories compared to previous techniques. We achieve this using a two-stage approach, where we first infer an object coordinate map from the input RGB image, and then obtain the final point cloud using a reprojection and completion step. We show results on standard benchmarks that demonstrate the advantages of our technique. Code is available at https://github.com/TaoHuUMD/3D-Reconstruction.
SAR Image Segmentation using Vector Quantization Technique on Entropy Images
Apr 11, 2010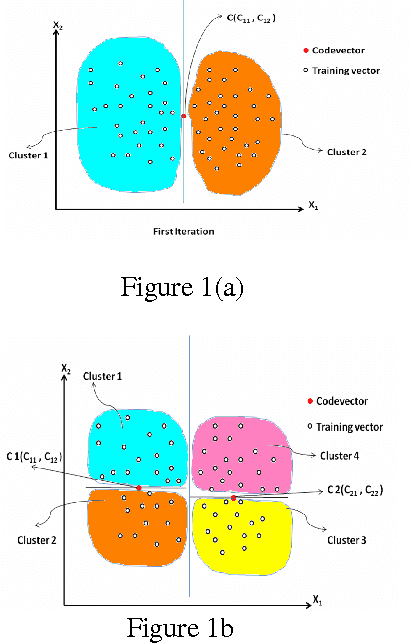


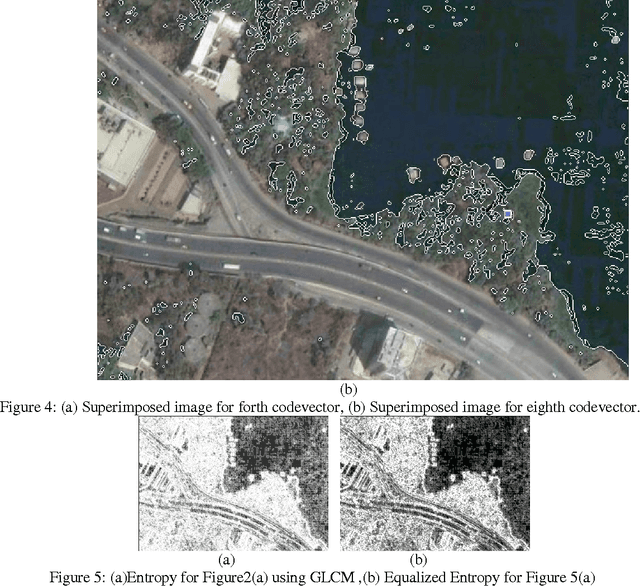
The development and application of various remote sensing platforms result in the production of huge amounts of satellite image data. Therefore, there is an increasing need for effective querying and browsing in these image databases. In order to take advantage and make good use of satellite images data, we must be able to extract meaningful information from the imagery. Hence we proposed a new algorithm for SAR image segmentation. In this paper we propose segmentation using vector quantization technique on entropy image. Initially, we obtain entropy image and in second step we use Kekre's Fast Codebook Generation (KFCG) algorithm for segmentation of the entropy image. Thereafter, a codebook of size 128 was generated for the Entropy image. These code vectors were further clustered in 8 clusters using same KFCG algorithm and converted into 8 images. These 8 images were displayed as a result. This approach does not lead to over segmentation or under segmentation. We compared these results with well known Gray Level Co-occurrence Matrix. The proposed algorithm gives better segmentation with less complexity.
Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels
Mar 29, 2019
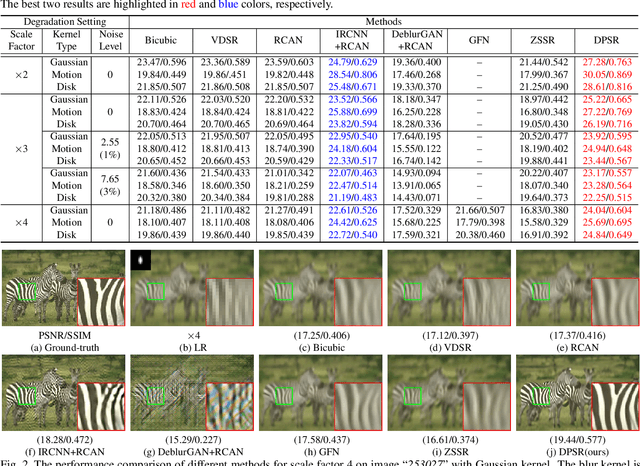


While deep neural networks (DNN) based single image super-resolution (SISR) methods are rapidly gaining popularity, they are mainly designed for the widely-used bicubic degradation, and there still remains the fundamental challenge for them to super-resolve low-resolution (LR) image with arbitrary blur kernels. In the meanwhile, plug-and-play image restoration has been recognized with high flexibility due to its modular structure for easy plug-in of denoiser priors. In this paper, we propose a principled formulation and framework by extending bicubic degradation based deep SISR with the help of plug-and-play framework to handle LR images with arbitrary blur kernels. Specifically, we design a new SISR degradation model so as to take advantage of existing blind deblurring methods for blur kernel estimation. To optimize the new degradation induced energy function, we then derive a plug-and-play algorithm via variable splitting technique, which allows us to plug any super-resolver prior rather than the denoiser prior as a modular part. Quantitative and qualitative evaluations on synthetic and real LR images demonstrate that the proposed deep plug-and-play super-resolution framework is flexible and effective to deal with blurry LR images.
Adversarial Defense Through Network Profiling Based Path Extraction
May 09, 2019



Recently, researchers have started decomposing deep neural network models according to their semantics or functions. Recent work has shown the effectiveness of decomposed functional blocks for defending adversarial attacks, which add small input perturbation to the input image to fool the DNN models. This work proposes a profiling-based method to decompose the DNN models to different functional blocks, which lead to the effective path as a new approach to exploring DNNs' internal organization. Specifically, the per-image effective path can be aggregated to the class-level effective path, through which we observe that adversarial images activate effective path different from normal images. We propose an effective path similarity-based method to detect adversarial images with an interpretable model, which achieve better accuracy and broader applicability than the state-of-the-art technique.
Training Object Detectors on Synthetic Images Containing Reflecting Materials
Mar 29, 2019
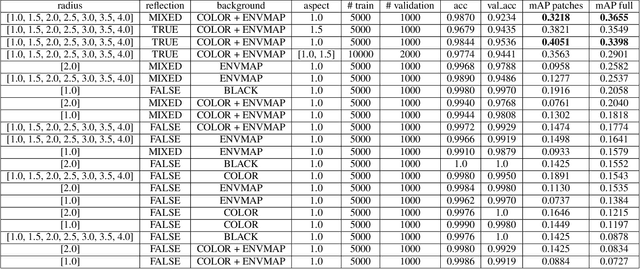
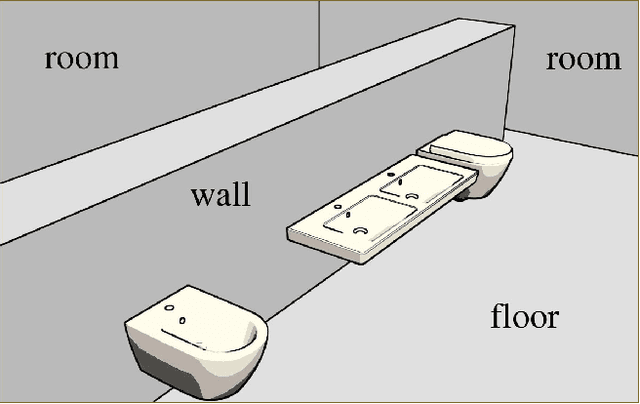
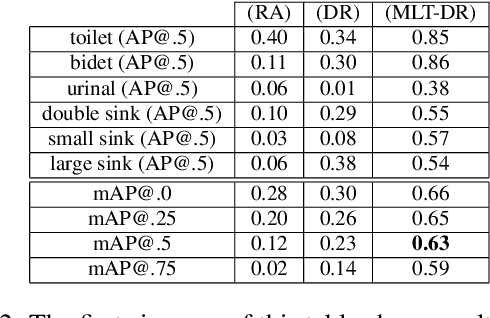
One of the grand challenges of deep learning is the requirement to obtain large labeled training data sets. While synthesized data sets can be used to overcome this challenge, it is important that these data sets close the reality gap, i.e., a model trained on synthetic image data is able to generalize to real images. Whereas, the reality gap can be considered bridged in several application scenarios, training on synthesized images containing reflecting materials requires further research. Since the appearance of objects with reflecting materials is dominated by the surrounding environment, this interaction needs to be considered during training data generation. Therefore, within this paper we examine the effect of reflecting materials in the context of synthetic image generation for training object detectors. We investigate the influence of rendering approach used for image synthesis, the effect of domain randomization, as well as the amount of used training data. To be able to compare our results to the state-of-the-art, we focus on indoor scenes as they have been investigated extensively. Within this scenario, bathroom furniture is a natural choice for objects with reflecting materials, for which we report our findings on real and synthetic testing data.
Wireless Software Synchronization of Multiple Distributed Cameras
Dec 21, 2018


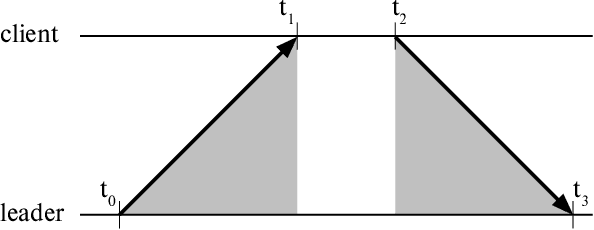
We present a method for precisely time-synchronizing the capture of image sequences from a collection of smartphone cameras connected over WiFi. Our method is entirely software-based, has only modest hardware requirements, and achieves an accuracy of less than 250 microseconds on unmodified commodity hardware. It does not use image content and synchronizes cameras prior to capture. The algorithm operates in two stages. In the first stage, we designate one device as the leader and synchronize each client device's clock to it by estimating network delay. Once clocks are synchronized, the second stage initiates continuous image streaming, estimates the relative phase of image timestamps between each client and the leader, and shifts the streams into alignment. We quantitatively validate our results on a multi-camera rig imaging a high-precision LED array and qualitatively demonstrate significant improvements to multi-view stereo depth estimation and stitching of dynamic scenes. We plan to open-source an Android implementation of our system 'libsoftwaresync', potentially inspiring new types of collective capture applications.
Diagnosing Colorectal Polyps in the Wild with Capsule Networks
Jan 10, 2020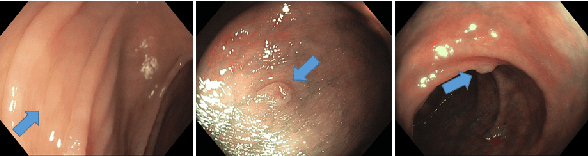
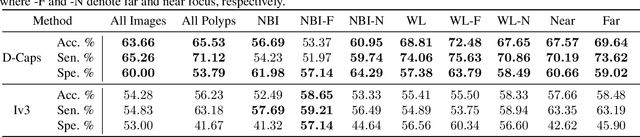
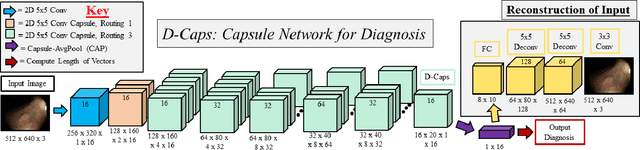
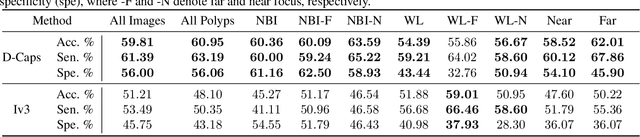
Colorectal cancer, largely arising from precursor lesions called polyps, remains one of the leading causes of cancer-related death worldwide. Current clinical standards require the resection and histopathological analysis of polyps due to test accuracy and sensitivity of optical biopsy methods falling substantially below recommended levels. In this study, we design a novel capsule network architecture (D-Caps) to improve the viability of optical biopsy of colorectal polyps. Our proposed method introduces several technical novelties including a novel capsule architecture with a capsule-average pooling (CAP) method to improve efficiency in large-scale image classification. We demonstrate improved results over the previous state-of-the-art convolutional neural network (CNN) approach by as much as 43%. This work provides an important benchmark on the new Mayo Polyp dataset, a significantly more challenging and larger dataset than previous polyp studies, with results stratified across all available categories, imaging devices and modalities, and focus modes to promote future direction into AI-driven colorectal cancer screening systems. Code is publicly available at https://github.com/lalonderodney/D-Caps .
Circle Loss: A Unified Perspective of Pair Similarity Optimization
Feb 25, 2020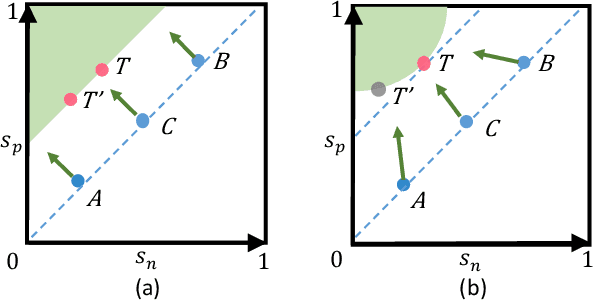
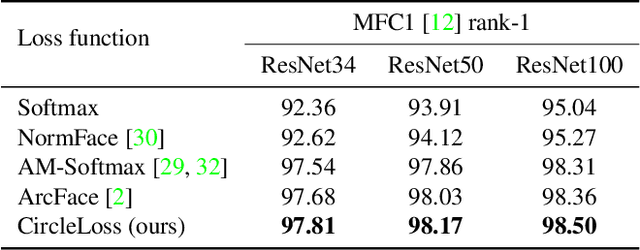
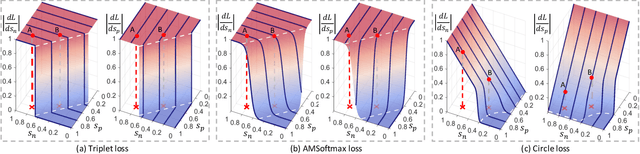
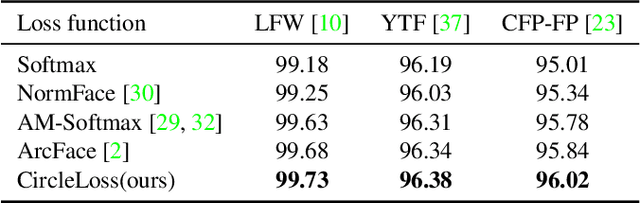
This paper provides a pair similarity optimization viewpoint on deep feature learning, aiming to maximize the within-class similarity $s_p$ and minimize the between-class similarity $s_n$. We find a majority of loss functions, including the triplet loss and the softmax plus cross-entropy loss, embed $s_n$ and $s_p$ into similarity pairs and seek to reduce $(s_n-s_p)$. Such an optimization manner is inflexible, because the penalty strength on every single similarity score is restricted to be equal. Our intuition is that if a similarity score deviates far from the optimum, it should be emphasized. To this end, we simply re-weight each similarity to highlight the less-optimized similarity scores. It results in a Circle loss, which is named due to its circular decision boundary. The Circle loss has a unified formula for two elemental deep feature learning approaches, i.e. learning with class-level labels and pair-wise labels. Analytically, we show that the Circle loss offers a more flexible optimization approach towards a more definite convergence target, compared with the loss functions optimizing $(s_n-s_p)$. Experimentally, we demonstrate the superiority of the Circle loss on a variety of deep feature learning tasks. On face recognition, person re-identification, as well as several fine-grained image retrieval datasets, the achieved performance is on par with the state of the art.