 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimal Mini-Batch Size Selection for Fast Gradient Descent
Nov 15, 2019
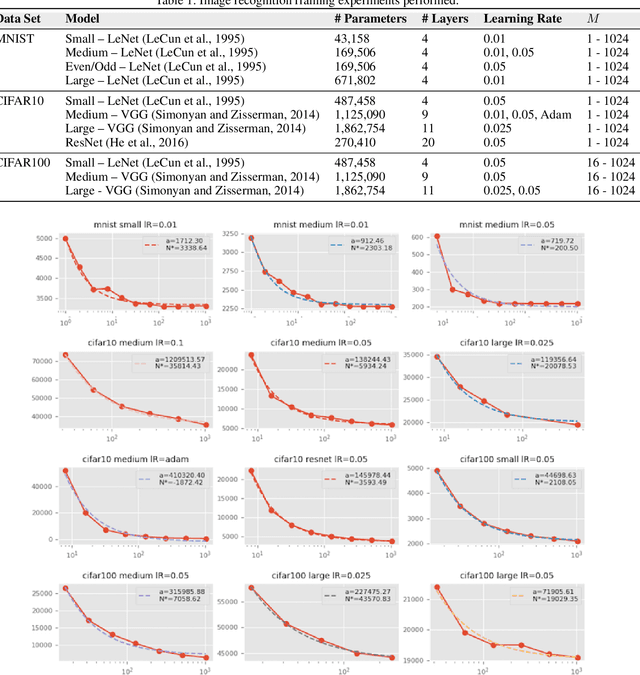
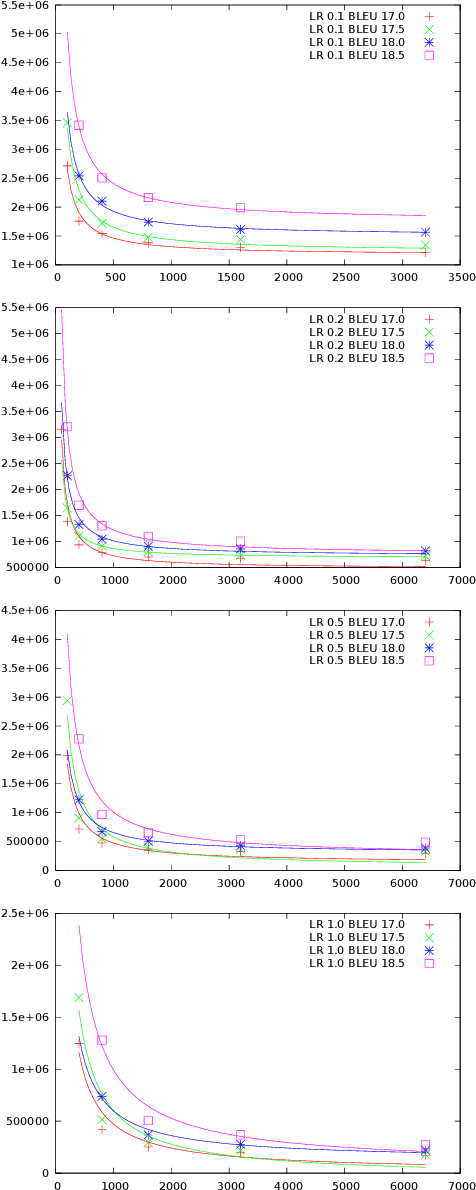
This paper presents a methodology for selecting the mini-batch size that minimizes Stochastic Gradient Descent (SGD) learning time for single and multiple learner problems. By decoupling algorithmic analysis issues from hardware and software implementation details, we reveal a robust empirical inverse law between mini-batch size and the average number of SGD updates required to converge to a specified error threshold. Combining this empirical inverse law with measured system performance, we create an accurate, closed-form model of average training time and show how this model can be used to identify quantifiable implications for both algorithmic and hardware aspects of machine learning. We demonstrate the inverse law empirically, on both image recognition (MNIST, CIFAR10 and CIFAR100) and machine translation (Europarl) tasks, and provide a theoretic justification via proving a novel bound on mini-batch SGD training.
Merlin: Enabling Machine Learning-Ready HPC Ensembles
Dec 05, 2019
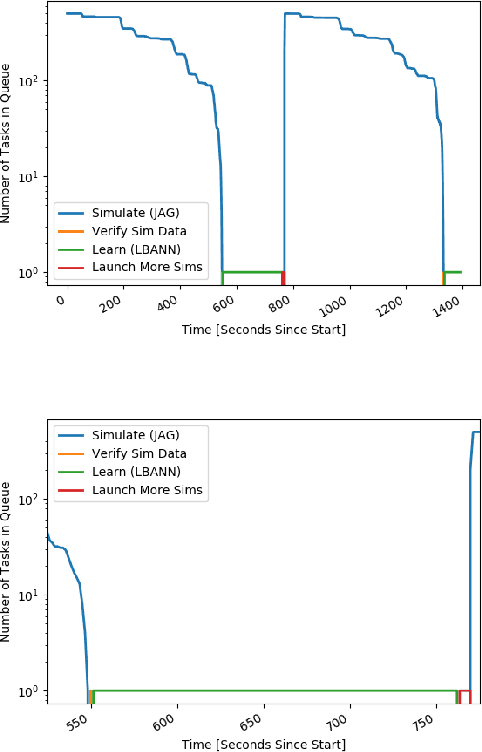
With the growing complexity of computational and experimental facilities, many scientific researchers are turning to machine learning (ML) techniques to analyze large scale ensemble data. With complexities such as multi-component workflows, heterogeneous machine architectures, parallel file systems, and batch scheduling, care must be taken to facilitate this analysis in a high performance computing (HPC) environment. In this paper, we present Merlin, a workflow framework to enable large ML-friendly ensembles of scientific HPC simulations. By augmenting traditional HPC with distributed compute technologies, Merlin aims to lower the barrier for scientific subject matter experts to incorporate ML into their analysis. In addition to its design and some examples, we describe how Merlin was deployed on the Sierra Supercomputer at Lawrence Livermore National Laboratory to create an unprecedented benchmark inertial confinement fusion dataset of approximately 100 million individual simulations and over 24 terabytes of multi-modal physics-based scalar, vector and hyperspectral image data.
In Defense of Grid Features for Visual Question Answering
Jan 10, 2020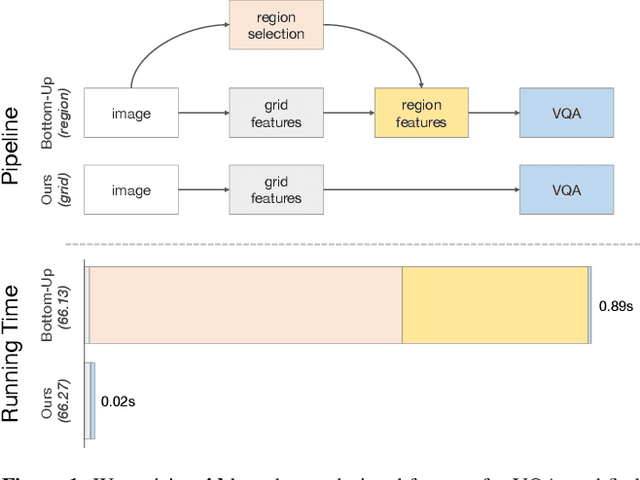
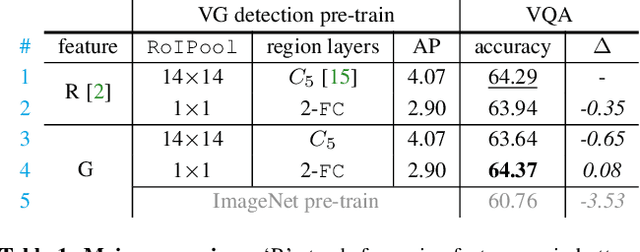
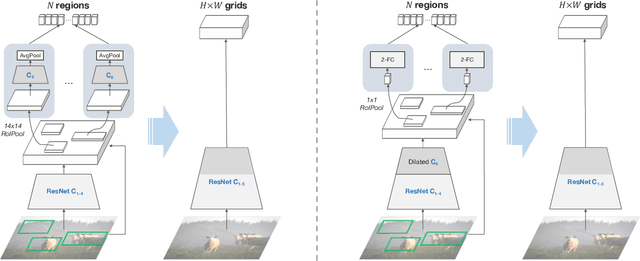
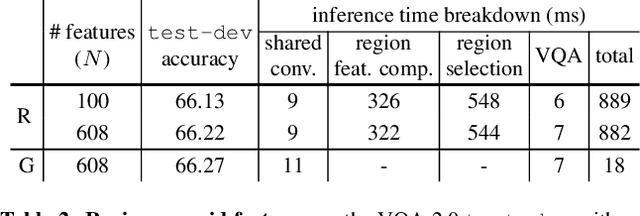
Popularized as 'bottom-up' attention, bounding box (or region) based visual features have recently surpassed vanilla grid-based convolutional features as the de facto standard for vision and language tasks like visual question answering (VQA). However, it is not clear whether the advantages of regions (e.g. better localization) are the key reasons for the success of bottom-up attention. In this paper, we revisit grid features for VQA and find they can work surprisingly well-running more than an order of magnitude faster with the same accuracy. Through extensive experiments, we verify that this observation holds true across different VQA models, datasets, and generalizes well to other tasks like image captioning. As grid features make the model design and training process much simpler, this enables us to train them end-to-end and also use a more flexible network design. We learn VQA models end-to-end, from pixels directly to answers, and show that strong performance is achievable without using any region annotations in pre-training. We hope our findings help further improve the scientific understanding and the practical application of VQA. Code and features will be made available.
Identification of Orchid Species Using Content-Based Flower Image Retrieval
Jun 10, 2014
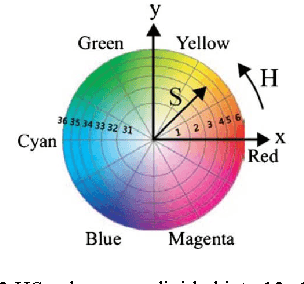
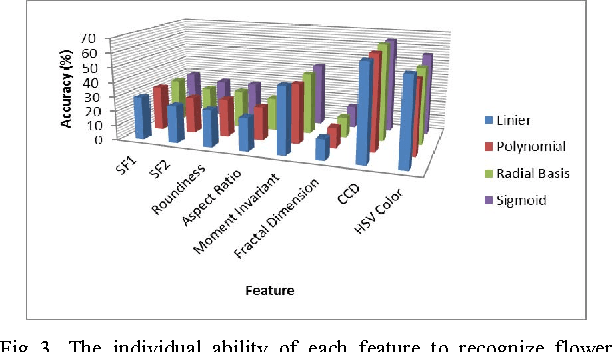
In this paper, we developed the system for recognizing the orchid species by using the images of flower. We used MSRM (Maximal Similarity based on Region Merging) method for segmenting the flower object from the background and extracting the shape feature such as the distance from the edge to the centroid point of the flower, aspect ratio, roundness, moment invariant, fractal dimension and also extract color feature. We used HSV color feature with ignoring the V value. To retrieve the image, we used Support Vector Machine (SVM) method. Orchid is a unique flower. It has a part of flower called lip (labellum) that distinguishes it from other flowers even from other types of orchids. Thus, in this paper, we proposed to do feature extraction not only on flower region but also on lip (labellum) region. The result shows that our proposed method can increase the accuracy value of content based flower image retrieval for orchid species up to $\pm$ 14%. The most dominant feature is Centroid Contour Distance, Moment Invariant and HSV Color. The system accuracy is 85,33% in validation phase and 79,33% in testing phase.
Fast Glioblastoma Detection in Fluid-attenuated inversion recovery (FLAIR) images by Topological Explainable Automatic Machine Learning
Jan 10, 2020

Glioblastoma multiforme (GBM) is a fast-growing and highly invasive brain tumor, it tends to occur in adults between the ages of 45 and 70 and it accounts for 52 percent of all primary brain tumors. Usually, GBMs are detected by magnetic resonance images (MRI). Among MRI images, Fluid-attenuated inversion recovery (FLAIR) sequence produces high quality digital tumor representation. This sequence is very sensitive to pathology and makes the differentiation between cerebrospinal fluid (CSF) and an abnormality much easier. Fast detection and segmentation techniques are needed for overcoming subjective medical doctors (MDs) judgment. In this work, a new methodology for fast detection and segmentation of GBM on FLAIR images is presented. The methodology leverages topological data analysis, textural features and interpretable machine learning algorithm, it was evaluated on a public available dataset. The machine learning classifier uses only eight input numerical features and it reaches up to the 97% of accuracy on the detection task and up to 95% of accuracy on the segmentation task. Tools from information theory were used for interpreting, in a human readable format, what are the main numerical characteristics of an image to be classified ill or healthy.
Towards Photo-Realistic Visible Watermark Removal with Conditional Generative Adversarial Networks
May 31, 2019
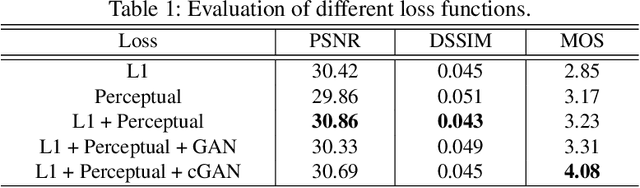
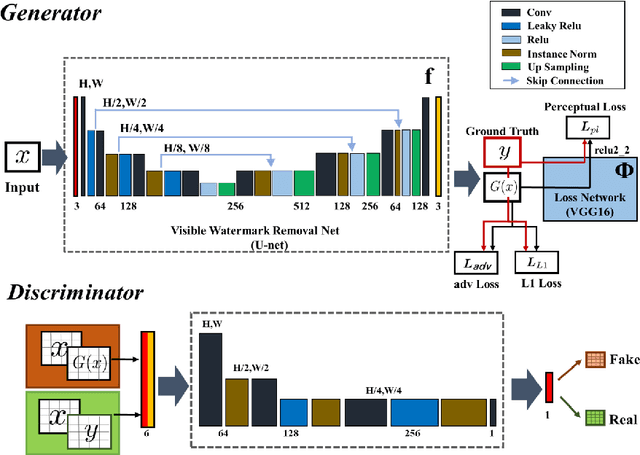
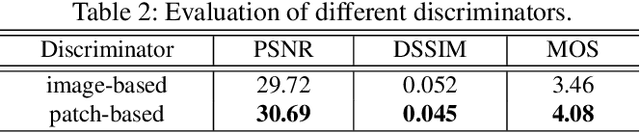
Visible watermark plays an important role in image copyright protection and the robustness of a visible watermark to an attack is shown to be essential. To evaluate and improve the effectiveness of watermark, watermark removal attracts increasing attention and becomes a hot research top. Current methods cast the watermark removal as an image-to-image translation problem where the encode-decode architectures with pixel-wise loss are adopted to transfer the transparent watermarked pixels into unmarked pixels. However, when a number of realistic images are presented, the watermarks are more likely to be unknown and diverse (i.e., the watermarks might be opaque or semi-transparent; the category and pattern of watermarks are unknown). When applying existing methods to the real-world scenarios, they mostly can not satisfactorily reconstruct the hidden information obscured under the complex and various watermarks (i.e., the residual watermark traces remain and the reconstructed images lack reality). To address this difficulty, in this paper, we present a new watermark processing framework using the conditional generative adversarial networks (cGANs) for visible watermark removal in the real-world application. The proposed method enables the watermark removal solution to be more closed to the photo-realistic reconstruction using a patch-based discriminator conditioned on the watermarked images, which is adversarially trained to differentiate the difference between the recovered images and original watermark-free images. Extensive experimental results on a large-scale visible watermark dataset demonstrate the effectiveness of the proposed method and clearly indicate that our proposed approach can produce more photo-realistic and convincing results compared with the state-of-the-art methods.
HRank: Filter Pruning using High-Rank Feature Map
Mar 16, 2020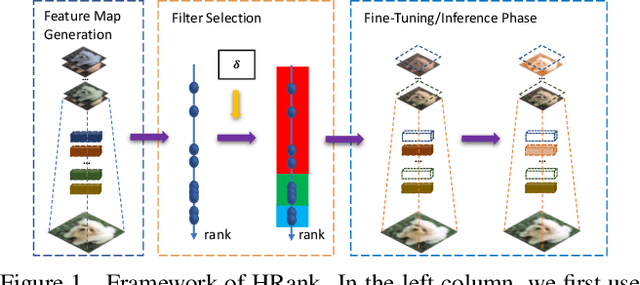
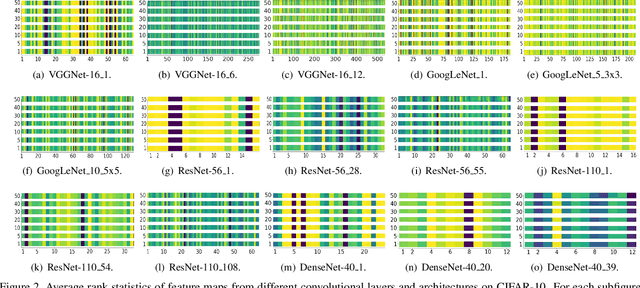
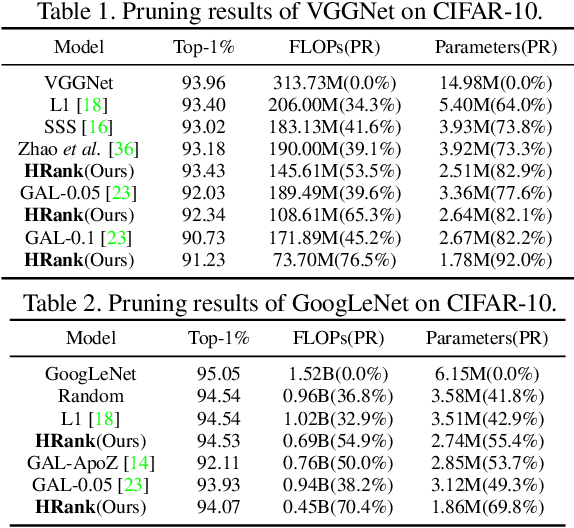
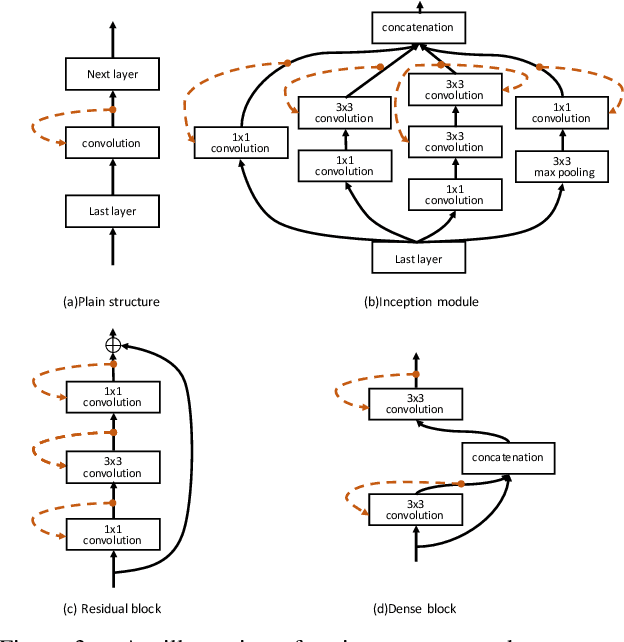
Neural network pruning offers a promising prospect to facilitate deploying deep neural networks on resource-limited devices. However, existing methods are still challenged by the training inefficiency and labor cost in pruning designs, due to missing theoretical guidance of non-salient network components. In this paper, we propose a novel filter pruning method by exploring the High Rank of feature maps (HRank). Our HRank is inspired by the discovery that the average rank of multiple feature maps generated by a single filter is always the same, regardless of the number of image batches CNNs receive. Based on HRank, we develop a method that is mathematically formulated to prune filters with low-rank feature maps. The principle behind our pruning is that low-rank feature maps contain less information, and thus pruned results can be easily reproduced. Besides, we experimentally show that weights with high-rank feature maps contain more important information, such that even when a portion is not updated, very little damage would be done to the model performance. Without introducing any additional constraints, HRank leads to significant improvements over the state-of-the-arts in terms of FLOPs and parameters reduction, with similar accuracies. For example, with ResNet-110, we achieve a 58.2%-FLOPs reduction by removing 59.2% of the parameters, with only a small loss of 0.14% in top-1 accuracy on CIFAR-10. With Res-50, we achieve a 43.8%-FLOPs reduction by removing 36.7% of the parameters, with only a loss of 1.17% in the top-1 accuracy on ImageNet. The codes can be available at https://github.com/lmbxmu/HRank.
Abnormal Client Behavior Detection in Federated Learning
Oct 22, 2019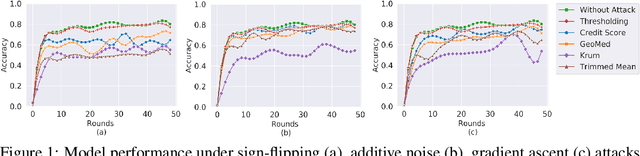
In federated learning systems, clients are autonomous in that their behaviors are not fully governed by the server. Consequently, a client may intentionally or unintentionally deviate from the prescribed course of federated model training, resulting in abnormal behaviors, such as turning into a malicious attacker or a malfunctioning client. Timely detecting those anomalous clients is therefore critical to minimize their adverse impacts. In this work, we propose to detect anomalous clients at the server side. In particular, we generate low-dimensional surrogates of model weight vectors and use them to perform anomaly detection. We evaluate our solution through experiments on image classification model training over the FEMNIST dataset. Experimental results show that the proposed detection-based approach significantly outperforms the conventional defense-based methods.
Efficient Neural Network Approaches for Leather Defect Classification
Jun 15, 2019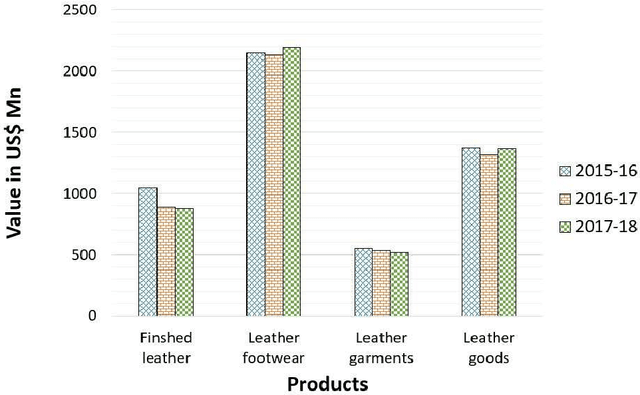
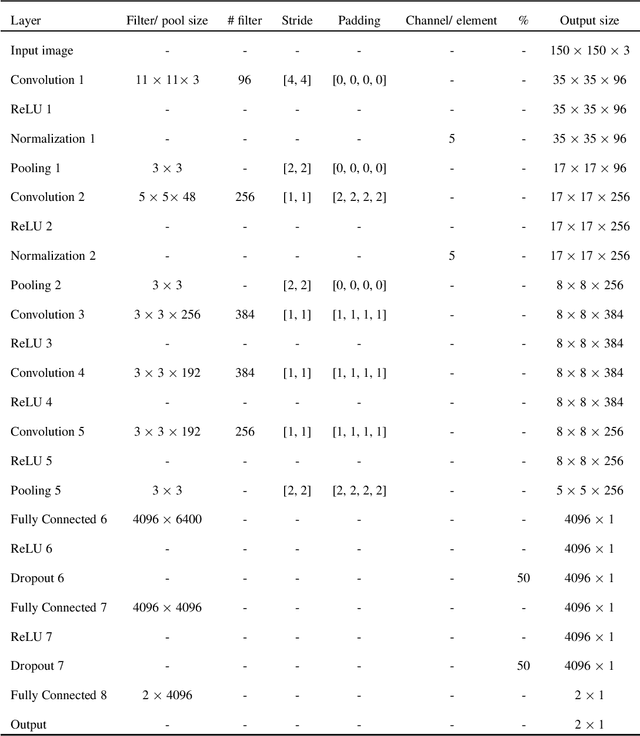

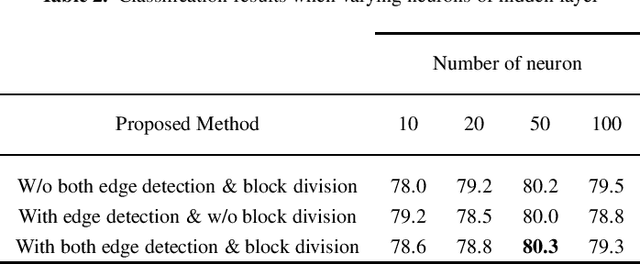
Genuine leather, such as the hides of cows, crocodiles, lizards and goats usually contain natural and artificial defects, like holes, fly bites, tick marks, veining, cuts, wrinkles and others. A traditional solution to identify the defects is by manual defect inspection, which involves skilled experts. It is time consuming and may incur a high error rate and results in low productivity. This paper presents a series of automatic image processing processes to perform the classification of leather defects by adopting deep learning approaches. Particularly, the leather images are first partitioned into small patches,then it undergoes a pre-processing technique, namely the Canny edge detection to enhance defect visualization. Next, artificial neural network (ANN) and convolutional neural network (CNN) are employed to extract the rich image features. The best classification result achieved is 80.3 %, evaluated on a data set that consists of 2000 samples. In addition, the performance metrics such as confusion matrix and Receiver Operating Characteristic (ROC) are reported to demonstrate the efficiency of the method proposed.
High-throughput, high-resolution registration-free generated adversarial network microscopy
Oct 03, 2018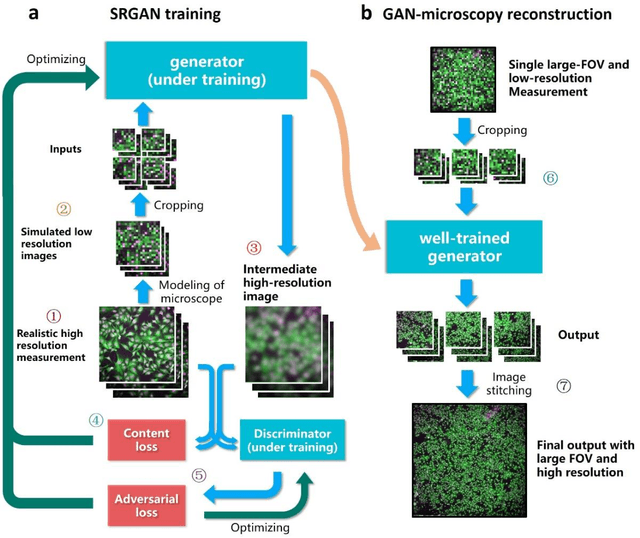

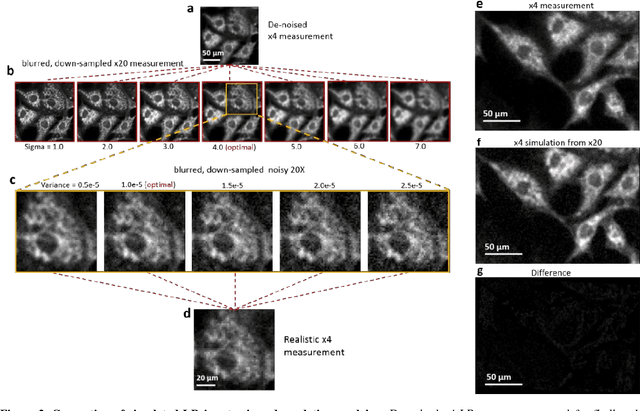
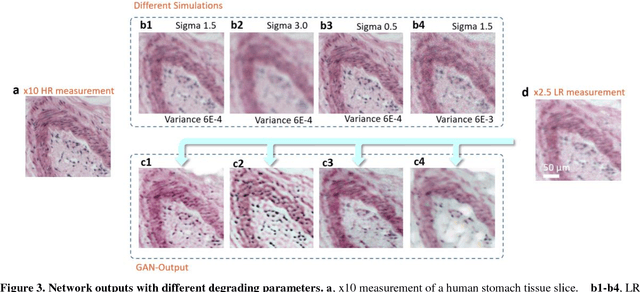
We combine generative adversarial network (GAN) with light microscopy to achieve deep learning super-resolution under a large field of view (FOV). By appropriately adopting prior microscopy data in an adversarial training, the neural network can recover a high-resolution, accurate image of new specimen from its single low-resolution measurement. Its capacity has been broadly demonstrated via imaging various types of samples, such as USAF resolution target, human pathological slides, fluorescence-labelled fibroblast cells, and deep tissues in transgenic mouse brain, by both wide-field and light-sheet microscopes. The gigapixel, multi-color reconstruction of these samples verifies a successful GAN-based single image super-resolution procedure. We also propose an image degrading model to generate low resolution images for training, making our approach free from the complex image registration during training dataset preparation. After a welltrained network being created, this deep learning-based imaging approach is capable of recovering a large FOV (~95 mm2), high-resolution (~1.7 {\mu}m) image at high speed (within 1 second), while not necessarily introducing any changes to the setup of existing microscopes.