 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High Speed and High Dynamic Range Video with an Event Camera
Jun 15, 2019
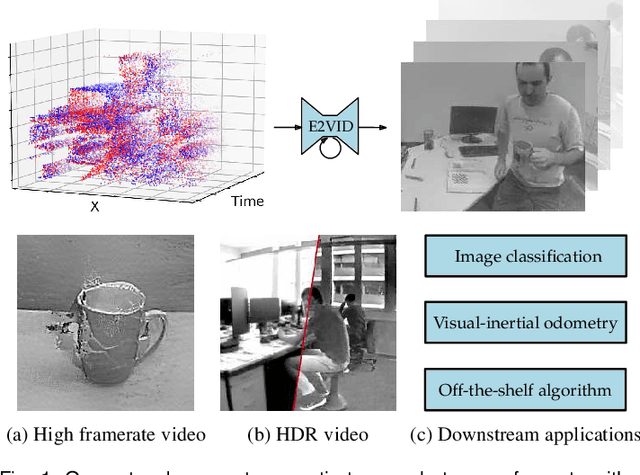
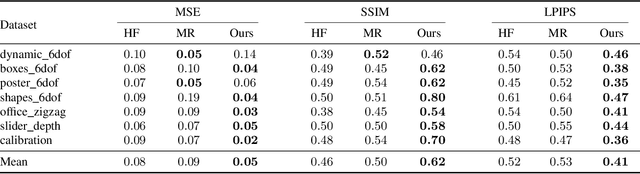
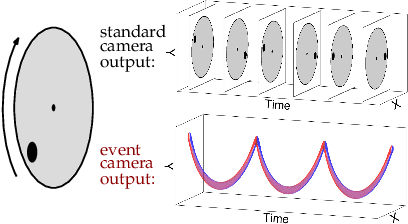
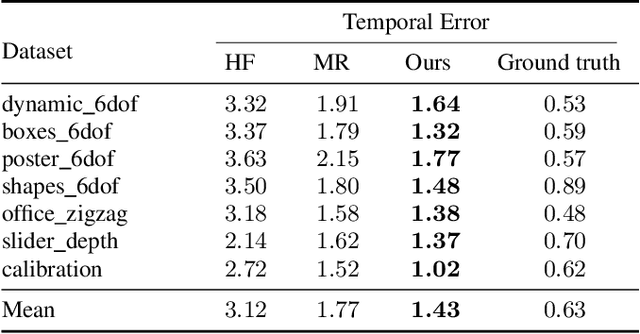
Event cameras are novel sensors that report brightness changes in the form of a stream of asynchronous "events" instead of intensity frames. They offer significant advantages with respect to conventional cameras: high temporal resolution, high dynamic range, and no motion blur. While the stream of events encodes in principle the complete visual signal, the reconstruction of an intensity image from a stream of events is an ill-posed problem in practice. Existing reconstruction approaches are based on hand-crafted priors and strong assumptions about the imaging process as well as the statistics of natural images. In this work we propose to learn to reconstruct intensity images from event streams directly from data instead of relying on any hand-crafted priors. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. During training we propose to use a perceptual loss to encourage reconstructions to follow natural image statistics. We further extend our approach to synthesize color images from color event streams. Our network surpasses state-of-the-art reconstruction methods by a large margin in terms of image quality (> 20%), while comfortably running in real-time. We show that the network is able to synthesize high framerate videos (> 5,000 frames per second) of high-speed phenomena (e.g. a bullet hitting an object) and is able to provide high dynamic range reconstructions in challenging lighting conditions. We also demonstrate the effectiveness of our reconstructions as an intermediate representation for event data. We show that off-the-shelf computer vision algorithms can be applied to our reconstructions for tasks such as object classification and visual-inertial odometry and that this strategy consistently outperforms algorithms that were specifically designed for event data.
Markov-Chain Monte Carlo Approximation of the Ideal Observer using Generative Adversarial Networks
Jan 26, 2020
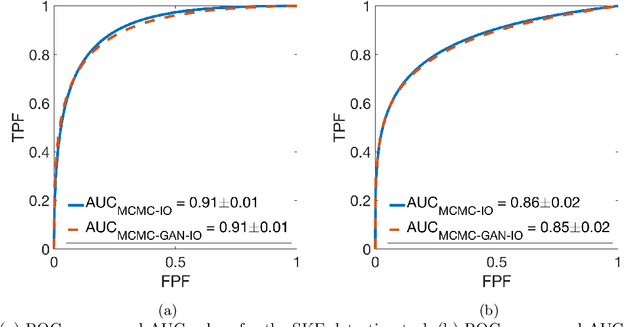
The Ideal Observer (IO) performance has been advocated when optimizing medical imaging systems for signal detection tasks. However, analytical computation of the IO test statistic is generally intractable. To approximate the IO test statistic, sampling-based methods that employ Markov-Chain Monte Carlo (MCMC) techniques have been developed. However, current applications of MCMC techniques have been limited to several object models such as a lumpy object model and a binary texture model, and it remains unclear how MCMC methods can be implemented with other more sophisticated object models. Deep learning methods that employ generative adversarial networks (GANs) hold great promise to learn stochastic object models (SOMs) from image data. In this study, we described a method to approximate the IO by applying MCMC techniques to SOMs learned by use of GANs. The proposed method can be employed with arbitrary object models that can be learned by use of GANs, thereby the domain of applicability of MCMC techniques for approximating the IO performance is extended. In this study, both signal-known-exactly (SKE) and signal-known-statistically (SKS) binary signal detection tasks are considered. The IO performance computed by the proposed method is compared to that computed by the conventional MCMC method. The advantages of the proposed method are discussed.
Beltrami-Net: Domain Independent Deep D-bar Learning for Absolute Imaging with Electrical Impedance Tomography (a-EIT)
Nov 30, 2018

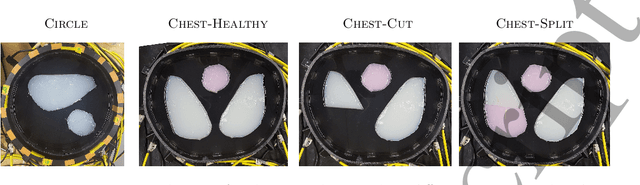
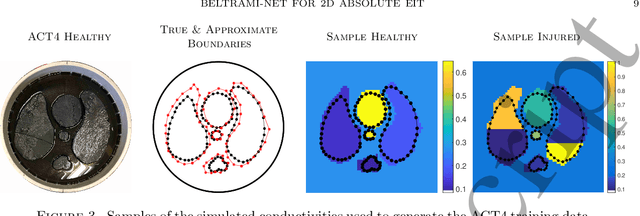
Objective: To develop, and demonstrate the feasibility of, a novel image reconstruction method for absolute Electrical Impedance Tomography (a-EIT) that pairs deep learning techniques with real-time robust D-bar methods. Approach: A D-bar method is paired with a trained Convolutional Neural Network (CNN) as a post-processing step. Training data is simulated for the network using no knowledge of the boundary shape by using an associated nonphysical Beltrami equation rather than simulating the traditional current and voltage data specific to a given domain. This allows the training data to be boundary shape independent. The method is tested on experimental data from two EIT systems (ACT4 and KIT4). Main Results: Post processing the D-bar images with a CNN produces significant improvements in image quality measured by Structural SIMilarity indices (SSIMs) as well as relative $\ell_2$ and $\ell_1$ image errors. Significance: This work demonstrates that more general networks can be trained without being specific about boundary shape, a key challenge in EIT image reconstruction. The work is promising for future studies involving databases of anatomical atlases.
Learning in Confusion: Batch Active Learning with Noisy Oracle
Sep 27, 2019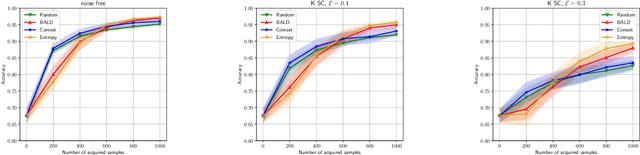
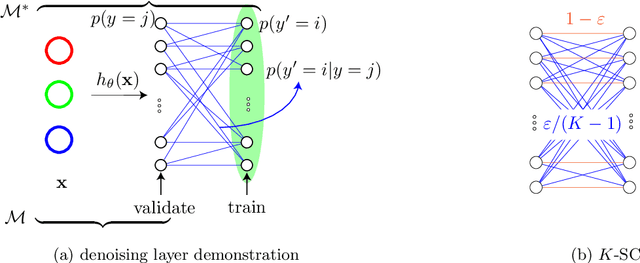
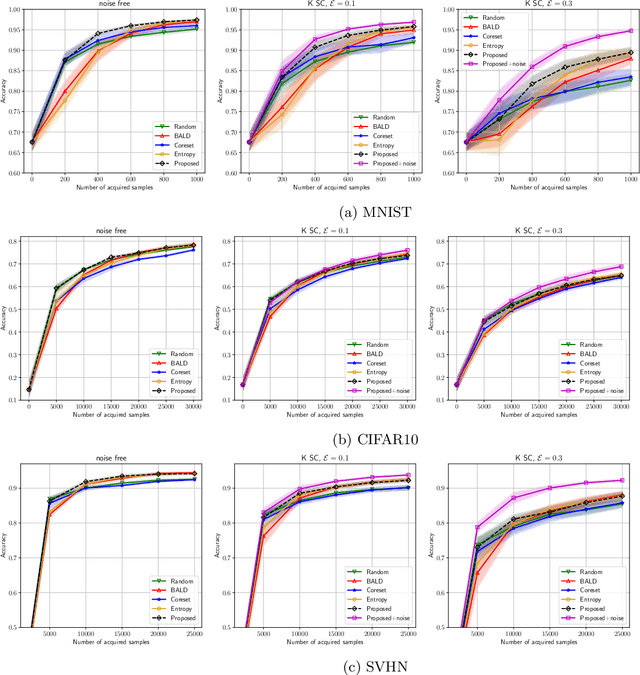
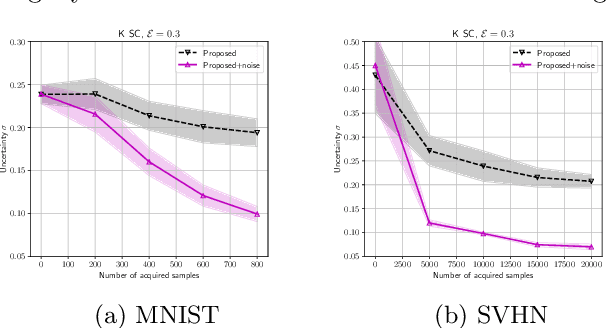
We study the problem of training machine learning models incrementally using active learning with access to imperfect or noisy oracles. We specifically consider the setting of batch active learning, in which multiple samples are selected as opposed to a single sample as in classical settings so as to reduce the training overhead. Our approach bridges between uniform randomness and score based importance sampling of clusters when selecting a batch of new samples. Experiments on benchmark image classification datasets (MNIST, SVHN, and CIFAR10) shows improvement over existing active learning strategies. We introduce an extra denoising layer to deep networks to make active learning robust to label noises and show significant improvements.
No Peeking through My Windows: Conserving Privacy in Personal Drones
Aug 26, 2019



The drone technology has been increasingly used by many tech-savvy consumers, a number of defense companies, hobbyists and enthusiasts during the last ten years. Drones often come in various sizes and are designed for a multitude of purposes. Nowadays many people have small-sized personal drones for entertainment, filming, or transporting items from one place to another. However, personal drones lack a privacy-preserving mechanism. While in mission, drones often trespass into the personal territories of other people and capture photos or videos through windows without their knowledge and consent. They may also capture video or pictures of people walking, sitting, or doing private things within the drones' reach in clear form without their go permission. This could potentially invade people's personal privacy. This paper, therefore, proposes a lightweight privacy-preserving-by-design method that prevents drones from peeking through windows of houses and capturing people doing private things at home. It is a fast window object detection and scrambling technology built based on image-enhancing, morphological transformation, segmentation and contouring processes (MASP). Besides, a chaotic scrambling technique is incorporated into it for privacy purpose. Hence, this mechanism detects window objects in every image or frame of a real-time video and masks them chaotically to protect the privacy of people. The experimental results validated that the proposed MASP method is lightweight and suitable to be employed in drones, considered as edge devices.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018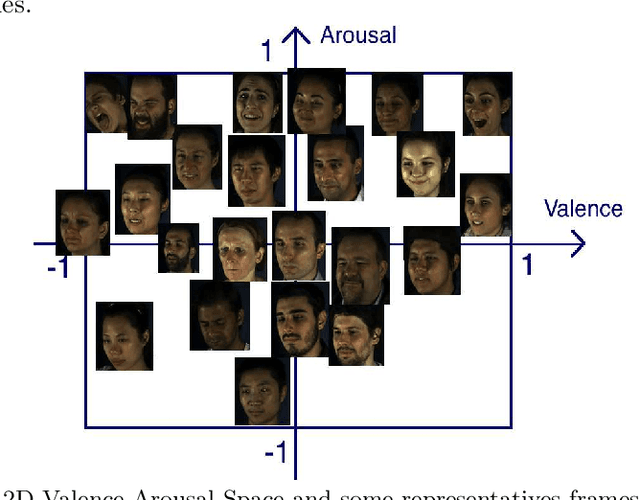
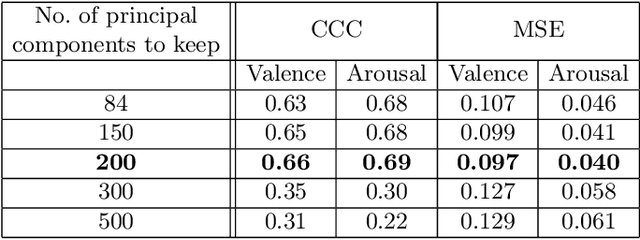
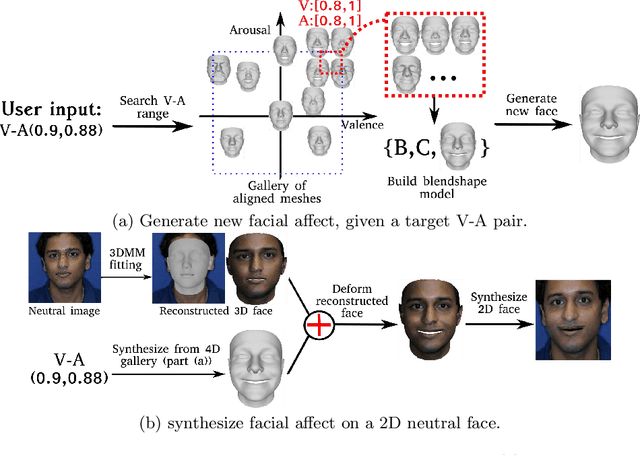

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
Learning Direct Optimization for Scene Understanding
Dec 18, 2018
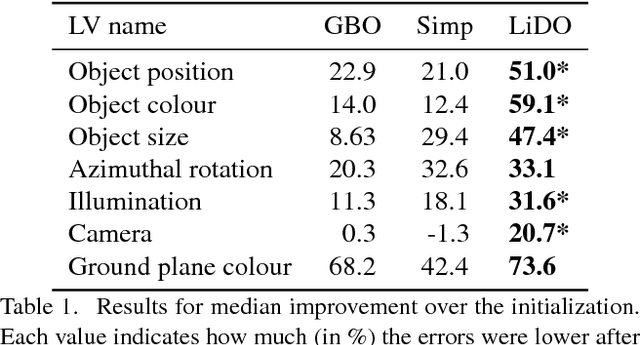
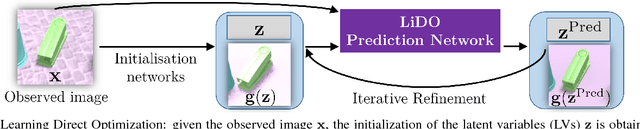
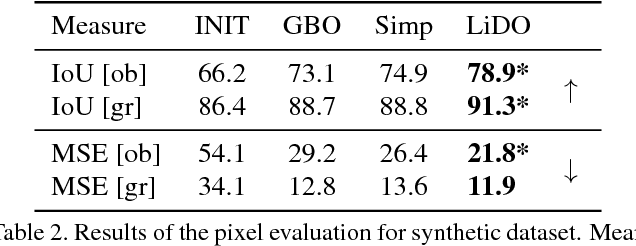
We introduce a Learning Direct Optimization method for the refinement of a latent variable model that describes input image x. Our goal is to explain a single image x with a 3D computer graphics model having scene graph latent variables z (such as object appearance, camera position). Given a current estimate of z we can render a prediction of the image g(z), which can be compared to the image x. The standard way to proceed is then to measure the error E(x, g(z)) between the two, and use an optimizer to minimize the error. Our novel Learning Direct Optimization (LiDO) approach trains a Prediction Network to predict an update directly to correct z, rather than minimizing the error with respect to z. Experiments show that our LiDO method converges rapidly as it does not need to perform a search on the error landscape, produces better solutions, and is able to handle the mismatch between the data and the fitted scene model. We apply the LiDO to a realistic synthetic dataset, and show that the method transfers to work well with real images.
End-to-end Training of CNN-CRF via Differentiable Dual-Decomposition
Dec 06, 2019
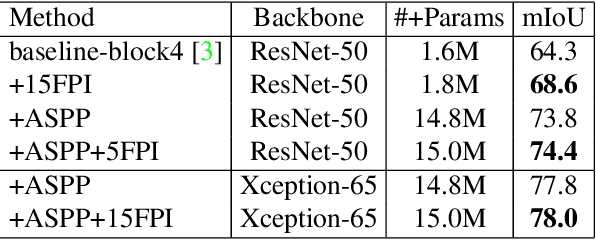

Modern computer vision (CV) is often based on convolutional neural networks (CNNs) that excel at hierarchical feature extraction. The previous generation of CV approaches was often based on conditional random fields (CRFs) that excel at modeling flexible higher order interactions. As their benefits are complementary they are often combined. However, these approaches generally use mean-field approximations and thus, arguably, did not directly optimize the real problem. Here we revisit dual-decomposition-based approaches to CRF optimization, an alternative to the mean-field approximation. These algorithms can efficiently and exactly solve sub-problems and directly optimize a convex upper bound of the real problem, providing optimality certificates on the way. Our approach uses a novel fixed-point iteration algorithm which enjoys dual-monotonicity, dual-differentiability and high parallelism. The whole system, CRF and CNN can thus be efficiently trained using back-propagation. We demonstrate the effectiveness of our system on semantic image segmentation, showing consistent improvement over baseline models.
Understanding Graph Isomorphism Network for Brain MR Functional Connectivity Analysis
Jan 10, 2020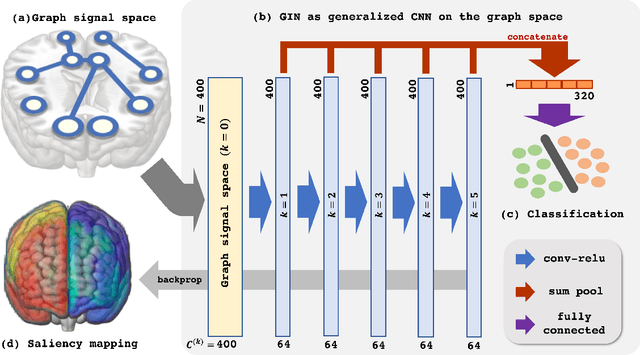
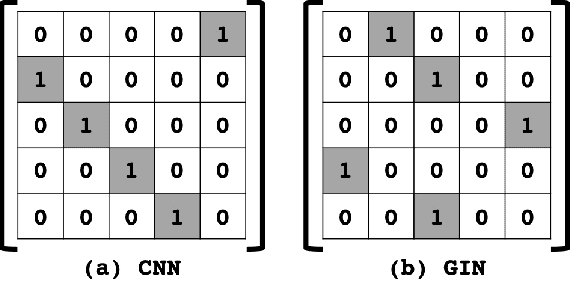
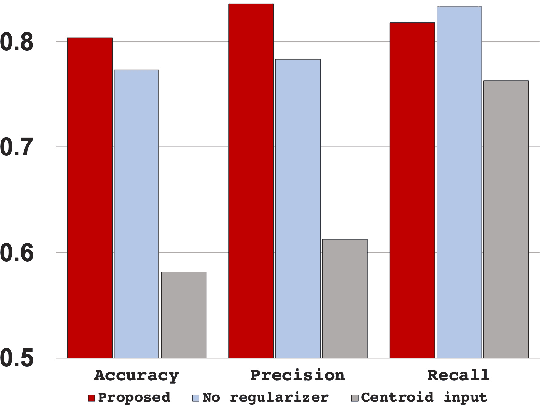

Graph neural networks (GNN) rely on graph operations that include neural network training for various graph related tasks. Recently, several attempts have been made to apply the GNNs to functional magnetic resonance image (fMRI) data. Despite the recent progress, a common limitation is its difficulty to explain the classification results in a neuroscientifically explainable way. Here, we develop a framework for analyzing the fMRI data using the Graph Isomorphism Network (GIN), which was recently proposed as a state-of-the-art GNN for graph classification. One important observation in this paper is that the GIN is a realization of convolutional neural network (CNN) with two-tab filters in the graph space where the shift operation is realized using the adjacent matrix. Based on this observation, we visualize the important regions of the brain by a saliency mapping method of the trained GIN. We validate our proposed framework using large-scale resting-state fMRI data for classifying the sex of the subject based on the graph structure of the brain. The experiment was consistent with our expectation such that the obtained saliency map show high correspondence with previous neuroimaging evidences related to sex differences.
Optimal Mini-Batch Size Selection for Fast Gradient Descent
Nov 15, 2019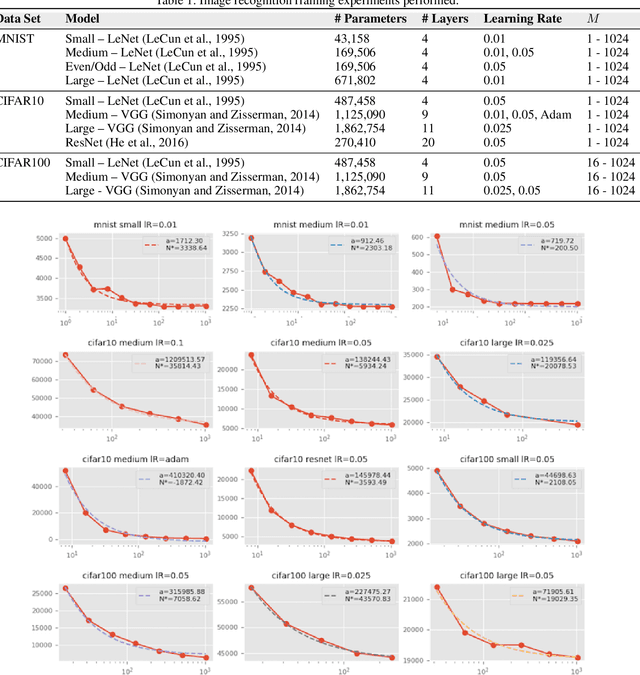
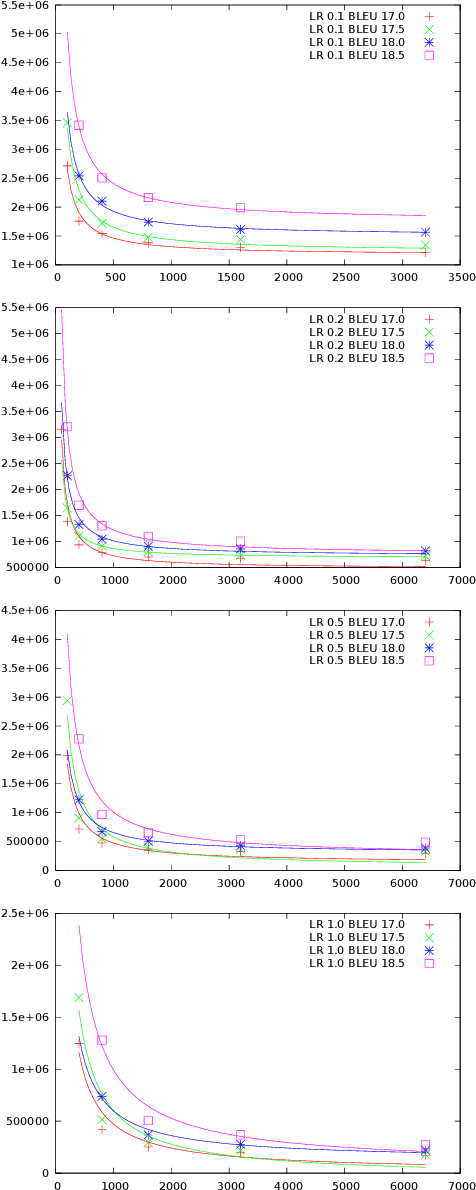
This paper presents a methodology for selecting the mini-batch size that minimizes Stochastic Gradient Descent (SGD) learning time for single and multiple learner problems. By decoupling algorithmic analysis issues from hardware and software implementation details, we reveal a robust empirical inverse law between mini-batch size and the average number of SGD updates required to converge to a specified error threshold. Combining this empirical inverse law with measured system performance, we create an accurate, closed-form model of average training time and show how this model can be used to identify quantifiable implications for both algorithmic and hardware aspects of machine learning. We demonstrate the inverse law empirically, on both image recognition (MNIST, CIFAR10 and CIFAR100) and machine translation (Europarl) tasks, and provide a theoretic justification via proving a novel bound on mini-batch SGD training.