 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel and Efficient Tumor Detection Framework for Pancreatic Cancer via CT Images
Feb 11, 2020
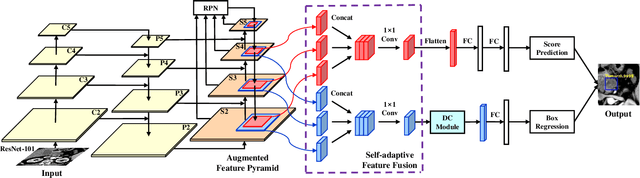
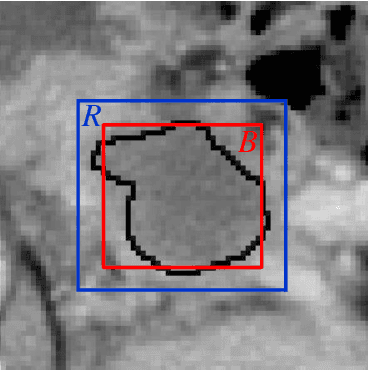
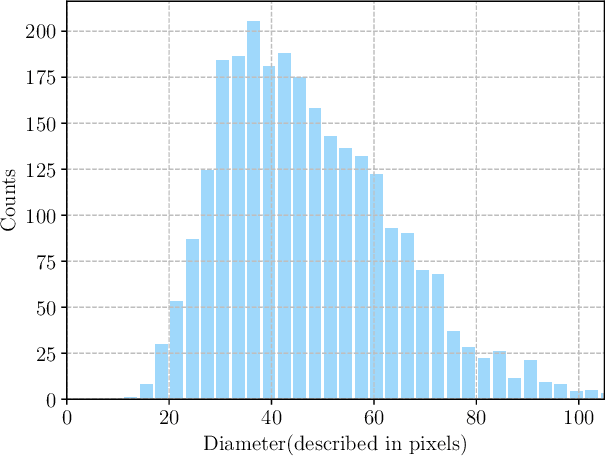
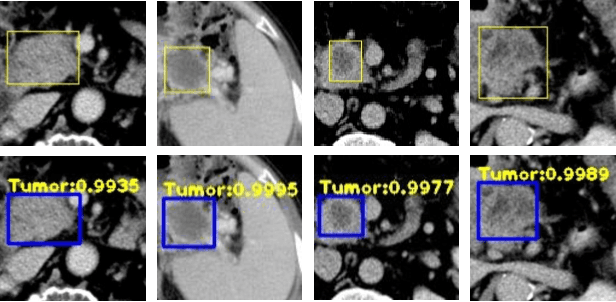
As Deep Convolutional Neural Networks (DCNNs) have shown robust performance and results in medical image analysis, a number of deep-learning-based tumor detection methods were developed in recent years. Nowadays, the automatic detection of pancreatic tumors using contrast-enhanced Computed Tomography (CT) is widely applied for the diagnosis and staging of pancreatic cancer. Traditional hand-crafted methods only extract low-level features. Normal convolutional neural networks, however, fail to make full use of effective context information, which causes inferior detection results. In this paper, a novel and efficient pancreatic tumor detection framework aiming at fully exploiting the context information at multiple scales is designed. More specifically, the contribution of the proposed method mainly consists of three components: Augmented Feature Pyramid networks, Self-adaptive Feature Fusion and a Dependencies Computation (DC) Module. A bottom-up path augmentation to fully extract and propagate low-level accurate localization information is established firstly. Then, the Self-adaptive Feature Fusion can encode much richer context information at multiple scales based on the proposed regions. Finally, the DC Module is specifically designed to capture the interaction information between proposals and surrounding tissues. Experimental results achieve competitive performance in detection with the AUC of 0.9455, which outperforms other state-of-the-art methods to our best of knowledge, demonstrating the proposed framework can detect the tumor of pancreatic cancer efficiently and accurately.
A Deep Gradient Boosting Network for Optic Disc and Cup Segmentation
Nov 05, 2019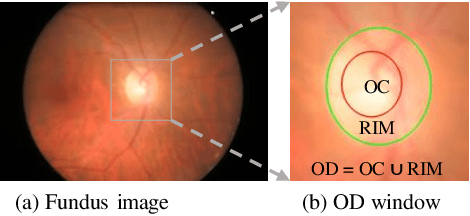
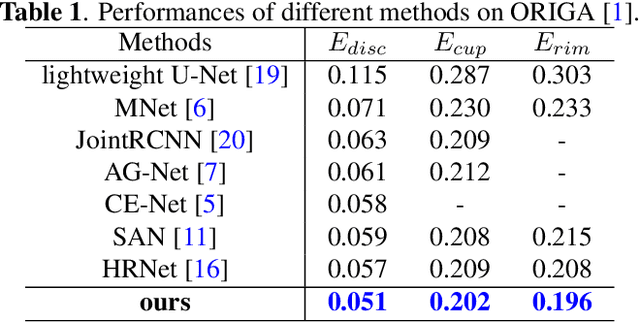
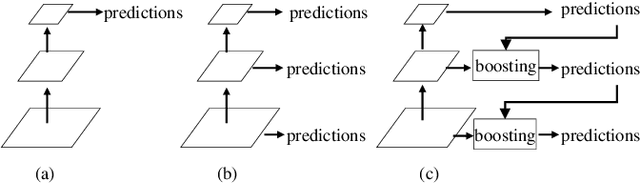
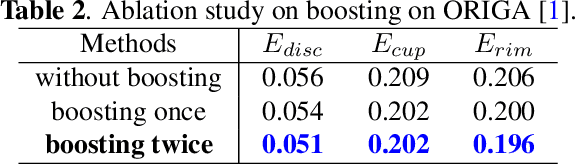
Segmentation of optic disc (OD) and optic cup (OC) is critical in automated fundus image analysis system. Existing state-of-the-arts focus on designing deep neural networks with one or multiple dense prediction branches. Such kind of designs ignore connections among prediction branches and their learning capacity is limited. To build connections among prediction branches, this paper introduces gradient boosting framework to deep classification model and proposes a gradient boosting network called BoostNet. Specifically, deformable side-output unit and aggregation unit with deep supervisions are proposed to learn base functions and expansion coefficients in gradient boosting framework. By stacking aggregation units in a deep-to-shallow manner, models' performances are gradually boosted along deep to shallow stages. BoostNet achieves superior results to existing deep OD and OC segmentation networks on the public dataset ORIGA.
Methods of Weighted Combination for Text Field Recognition in a Video Stream
Nov 27, 2019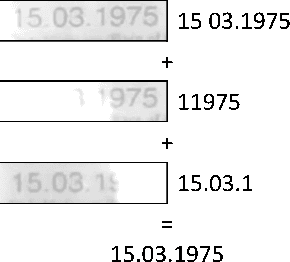
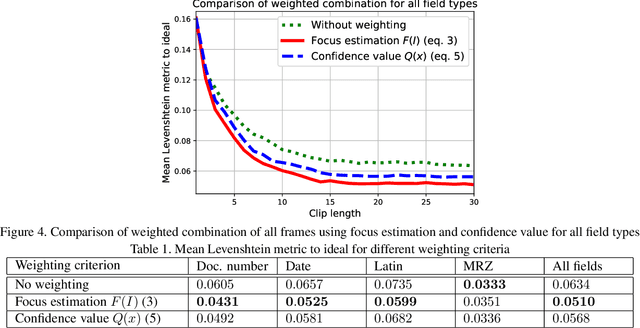
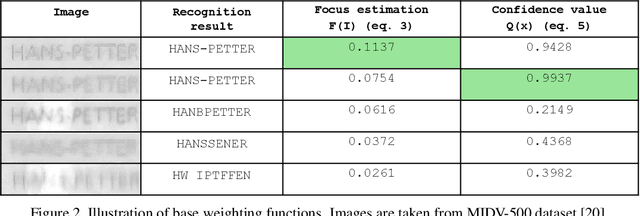
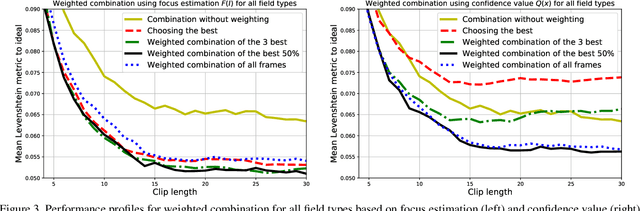
Due to a noticeable expansion of document recognition applicability, there is a high demand for recognition on mobile devices. A mobile camera, unlike a scanner, cannot always ensure the absence of various image distortions, therefore the task of improving the recognition precision is relevant. The advantage of mobile devices over scanners is the ability to use video stream input, which allows to get multiple images of a recognized document. Despite this, not enough attention is currently paid to the issue of combining recognition results obtained from different frames when using video stream input. In this paper we propose a weighted text string recognition results combination method and weighting criteria, and provide experimental data for verifying their validity and effectiveness. Based on the obtained results, it is concluded that the use of such weighted combination is appropriate for improving the quality of the video stream recognition result.
Quality Assessment of DIBR-synthesized views: An Overview
Nov 16, 2019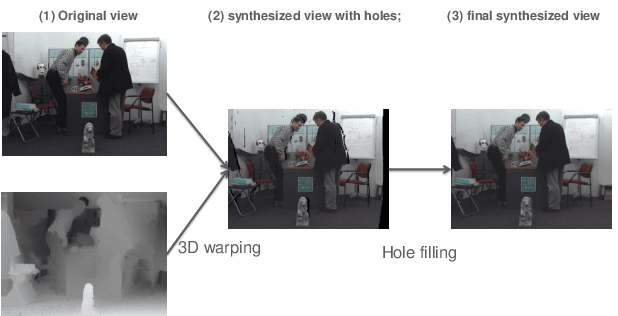
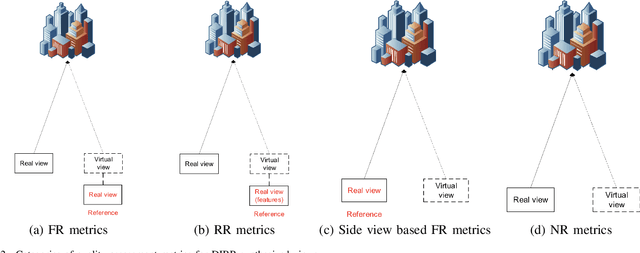
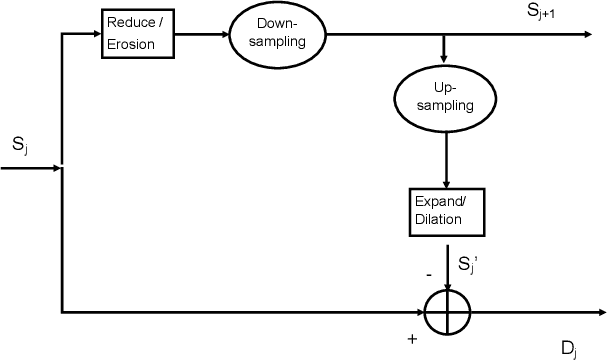
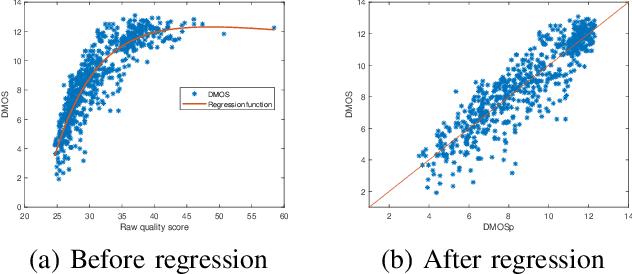
The Depth-Image-Based-Rendering (DIBR) is one of the main fundamental technique to generate new views in 3D video applications, such as Multi-View Videos (MVV), Free-Viewpoint Videos (FVV) and Virtual Reality (VR). However, the quality assessment of DIBR-synthesized views is quite different from the traditional 2D images/videos. In recent years, several efforts have been made towards this topic, but there lacks a detailed survey in literature. In this paper, we provide a comprehensive survey on various current approaches for DIBR-synthesized views. The current accessible datasets of DIBR-synthesized views are firstly reviewed. Followed by a summary and analysis of the representative state-of-the-art objective metrics. Then, the performances of different objective metrics are evaluated and discussed on all available datasets. Finally, we discuss the potential challenges and suggest possible directions for future research.
Monocular 3D Object Detection via Geometric Reasoning on Keypoints
May 14, 2019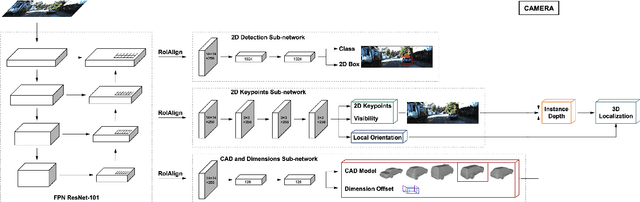
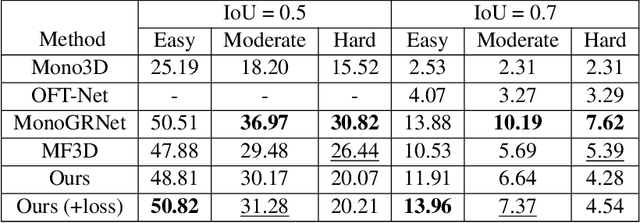

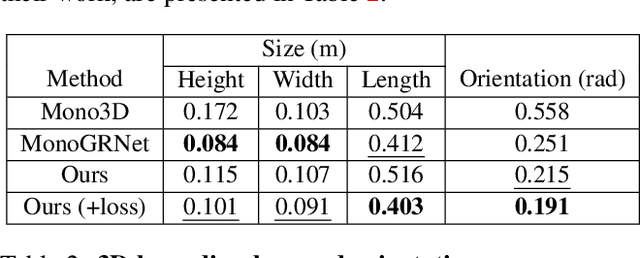
Monocular 3D object detection is well-known to be a challenging vision task due to the loss of depth information; attempts to recover depth using separate image-only approaches lead to unstable and noisy depth estimates, harming 3D detections. In this paper, we propose a novel keypoint-based approach for 3D object detection and localization from a single RGB image. We build our multi-branch model around 2D keypoint detection in images and complement it with a conceptually simple geometric reasoning method. Our network performs in an end-to-end manner, simultaneously and interdependently estimating 2D characteristics, such as 2D bounding boxes, keypoints, and orientation, along with full 3D pose in the scene. We fuse the outputs of distinct branches, applying a reprojection consistency loss during training. The experimental evaluation on the challenging KITTI dataset benchmark demonstrates that our network achieves state-of-the-art results among other monocular 3D detectors.
Beltrami-Net: Domain Independent Deep D-bar Learning for Absolute Imaging with Electrical Impedance Tomography (a-EIT)
Nov 30, 2018

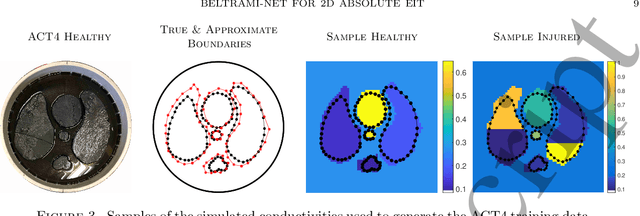
Objective: To develop, and demonstrate the feasibility of, a novel image reconstruction method for absolute Electrical Impedance Tomography (a-EIT) that pairs deep learning techniques with real-time robust D-bar methods. Approach: A D-bar method is paired with a trained Convolutional Neural Network (CNN) as a post-processing step. Training data is simulated for the network using no knowledge of the boundary shape by using an associated nonphysical Beltrami equation rather than simulating the traditional current and voltage data specific to a given domain. This allows the training data to be boundary shape independent. The method is tested on experimental data from two EIT systems (ACT4 and KIT4). Main Results: Post processing the D-bar images with a CNN produces significant improvements in image quality measured by Structural SIMilarity indices (SSIMs) as well as relative $\ell_2$ and $\ell_1$ image errors. Significance: This work demonstrates that more general networks can be trained without being specific about boundary shape, a key challenge in EIT image reconstruction. The work is promising for future studies involving databases of anatomical atlases.
SESS: Self-Ensembling Semi-Supervised 3D Object Detection
Dec 26, 2019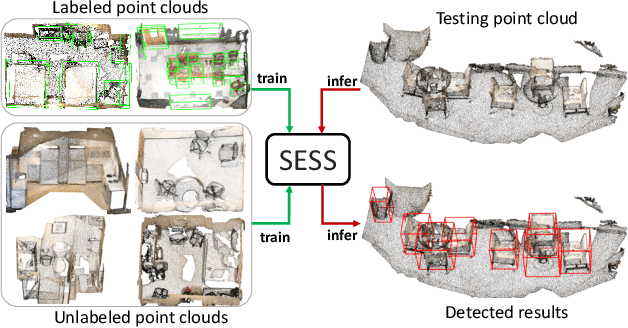
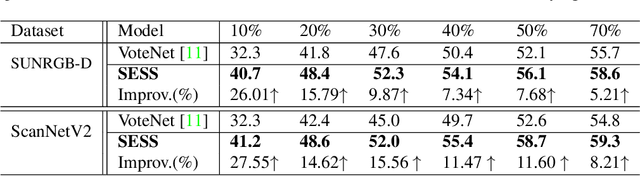
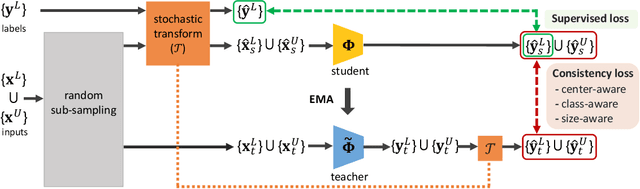

The performance of existing point cloud-based 3D object detection methods heavily relies on large-scale high-quality 3D annotations. However, such annotations are often tedious and expensive to collect. Semi-supervised learning is a good alternative to mitigate the data annotation issue, but has remained largely unexplored in 3D object detection. Inspired by the recent success of self-ensembling technique in semi-supervised image classification task, we propose SESS, a self-ensembling semi-supervised 3D object detection framework. Specifically, we design a thorough perturbation scheme to enhance generalization of the network on unlabeled and new unseen data. Furthermore, we propose three consistency losses to enforce the consistency between two sets of predicted 3D object proposals, to facilitate the learning of structure and semantic invariances of objects. Extensive experiments conducted on SUN RGB-D and ScanNet datasets demonstrate the effectiveness of SESS in both inductive and transductive semi-supervised 3D object detection. Our SESS achieves competitive performance compared to the state-of-the-art fully-supervised method by using only 50% labeled data.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018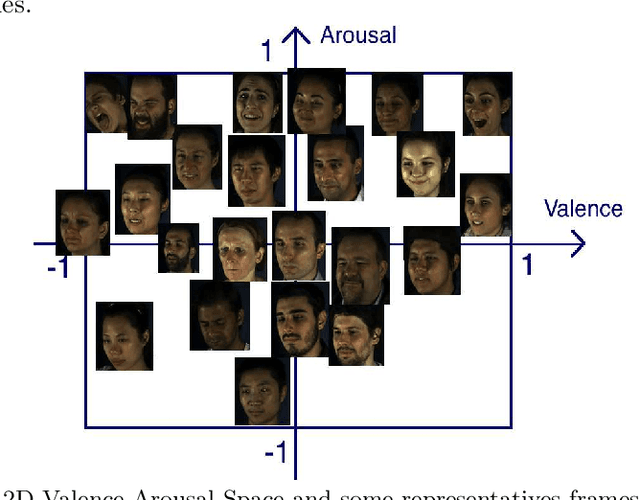
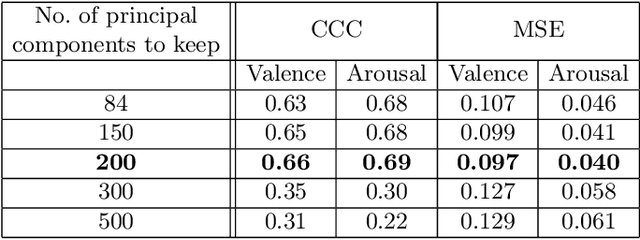
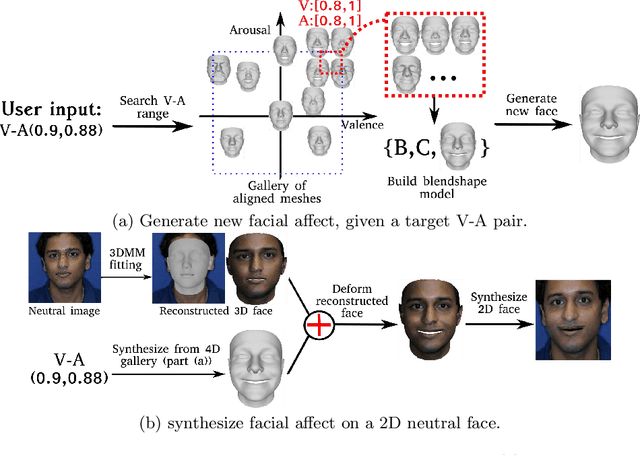

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
Superposition as Data Augmentation using LSTM and HMM in Small Training Sets
Oct 24, 2019
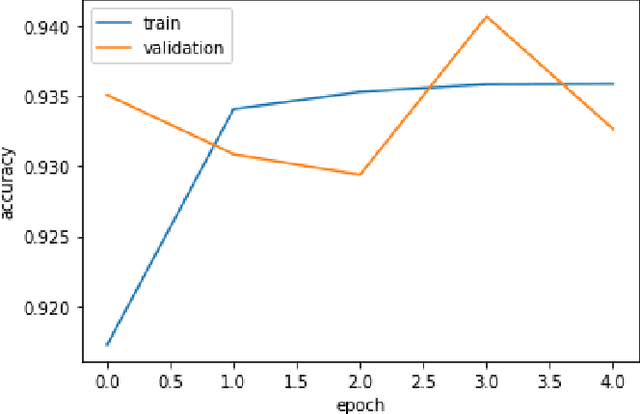
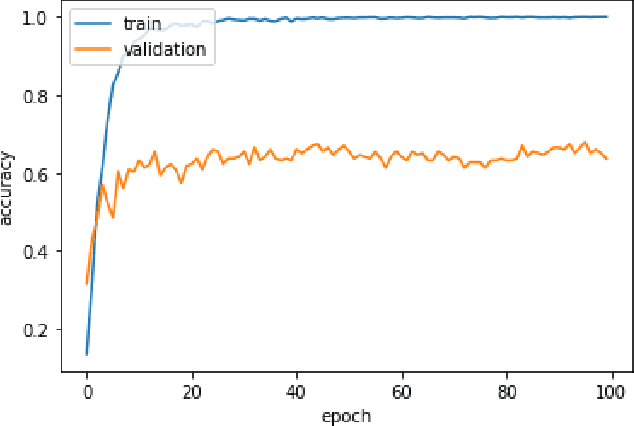
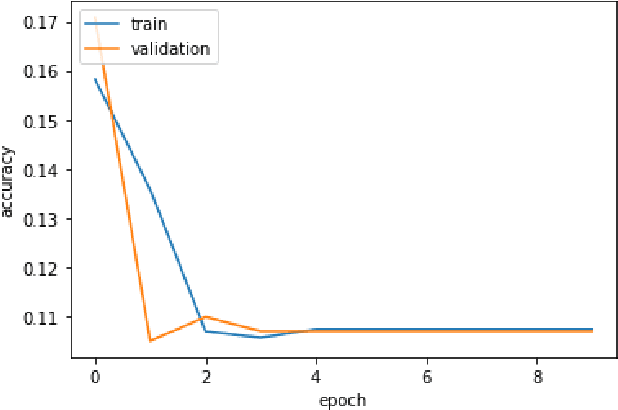
Considering audio and image data as having quantum nature (data are represented by density matrices), we achieved better results on training architectures such as 3-layer stacked LSTM and HMM by mixing training samples using superposition augmentation and compared with plain default training and mix-up augmentation. This augmentation technique originates from the mix-up approach but provides more solid theoretical reasoning based on quantum properties. We achieved 3% improvement (from 68% to 71%) by using 38% lesser number of training samples in Russian audio-digits recognition task and 7,16% better accuracy than mix-up augmentation by training only 500 samples using HMM on the same task. Also, we achieved 1.1% better accuracy than mix-up on first 900 samples in MNIST using 3-layer stacked LSTM.
PUGeo-Net: A Geometry-centric Network for 3D Point Cloud Upsampling
Mar 07, 2020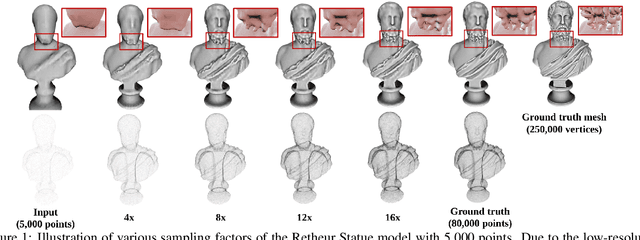
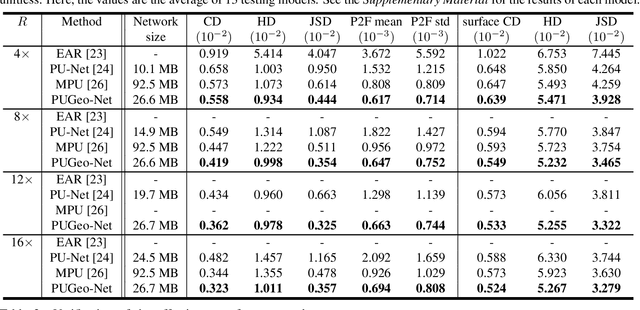
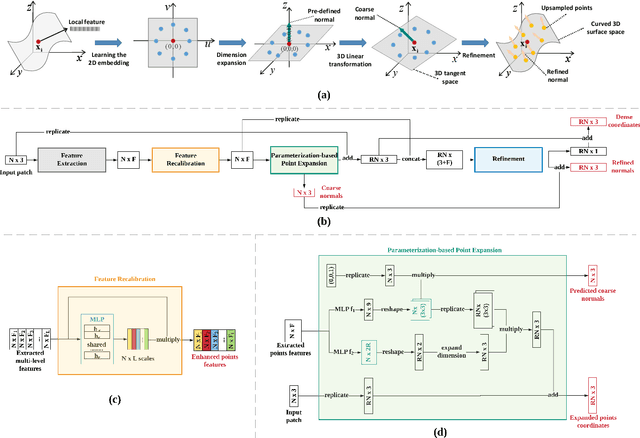
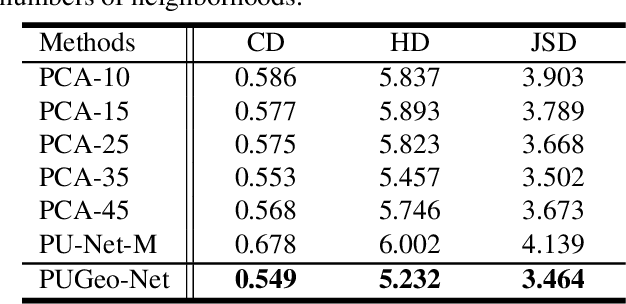
This paper addresses the problem of generating uniform dense point clouds to describe the underlying geometric structures from given sparse point clouds. Due to the irregular and unordered nature, point cloud densification as a generative task is challenging. To tackle the challenge, we propose a novel deep neural network based method, called PUGeo-Net, that learns a $3\times 3$ linear transformation matrix $\bf T$ for each input point. Matrix $\mathbf T$ approximates the augmented Jacobian matrix of a local parameterization and builds a one-to-one correspondence between the 2D parametric domain and the 3D tangent plane so that we can lift the adaptively distributed 2D samples (which are also learned from data) to 3D space. After that, we project the samples to the curved surface by computing a displacement along the normal of the tangent plane. PUGeo-Net is fundamentally different from the existing deep learning methods that are largely motivated by the image super-resolution techniques and generate new points in the abstract feature space. Thanks to its geometry-centric nature, PUGeo-Net works well for both CAD models with sharp features and scanned models with rich geometric details. Moreover, PUGeo-Net can compute the normal for the original and generated points, which is highly desired by the surface reconstruction algorithms. Computational results show that PUGeo-Net, the first neural network that can jointly generate vertex coordinates and normals, consistently outperforms the state-of-the-art in terms of accuracy and efficiency for upsampling factor $4\sim 16$.