 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Relationship Detection with Language prior and Softmax
Apr 16, 2019


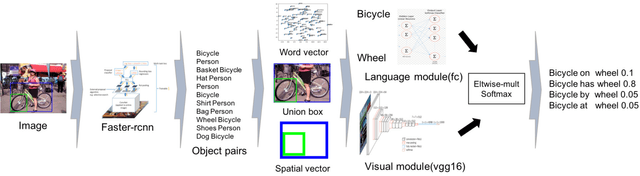
Visual relationship detection is an intermediate image understanding task that detects two objects and classifies a predicate that explains the relationship between two objects in an image. The three components are linguistically and visually correlated (e.g. "wear" is related to "person" and "shirt", while "laptop" is related to "table" and "on") thus, the solution space is huge because there are many possible cases between them. Language and visual modules are exploited and a sophisticated spatial vector is proposed. The models in this work outperformed the state of arts without costly linguistic knowledge distillation from a large text corpus and building complex loss functions. All experiments were only evaluated on Visual Relationship Detection and Visual Genome dataset.
* 6 pages, 4 figures
DeepFont: Identify Your Font from An Image
Jul 12, 2015
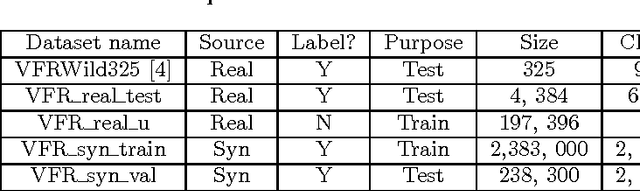


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
A Multimodal Target-Source Classifier with Attention Branches to Understand Ambiguous Instructions for Fetching Daily Objects
Dec 25, 2019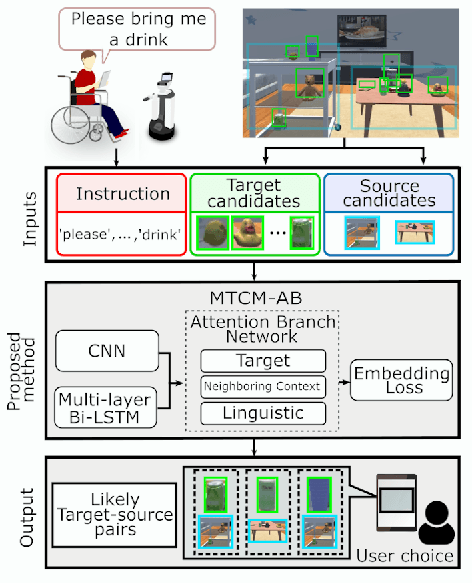
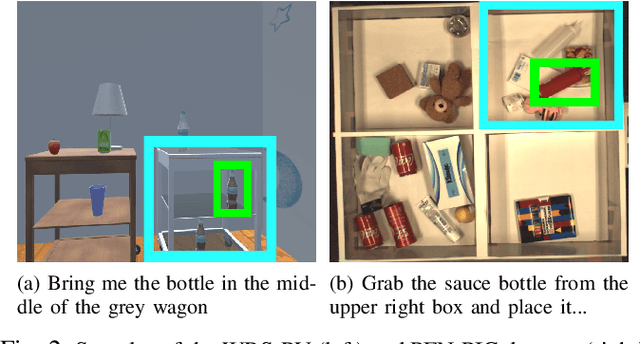
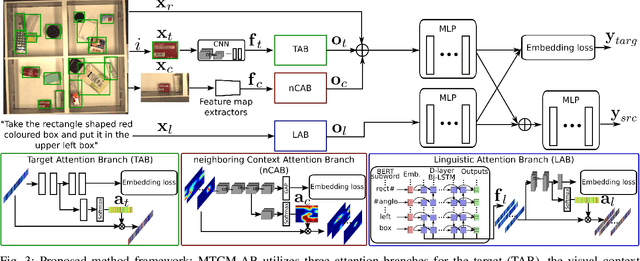

In this study, we focus on multimodal language understanding for fetching instructions in the domestic service robots context. This task consists of predicting a target object, as instructed by the user, given an image and an unstructured sentence, such as "Bring me the yellow box (from the wooden cabinet)." This is challenging because of the ambiguity of natural language, i.e., the relevant information may be missing or there might be several candidates. To solve such a task, we propose the multimodal target-source classifier model with attention branches (MTCM-AB), which is an extension of the MTCM. Our methodology uses the attention branch network (ABN) to develop a multimodal attention mechanism based on linguistic and visual inputs. Experimental validation using a standard dataset showed that the MTCM-AB outperformed both state-of-the-art methods and the MTCM. In particular the MTCM-AB accuracy on average was 90.1% while human performance was 90.3% on the PFN-PIC dataset.
Flexible, Fast and Accurate Densely-Sampled Light Field Reconstruction Network
Aug 31, 2019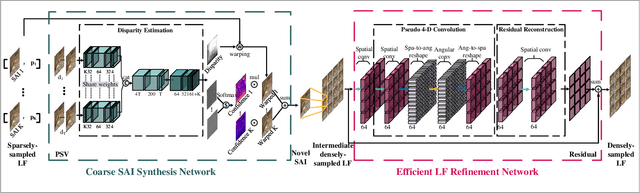
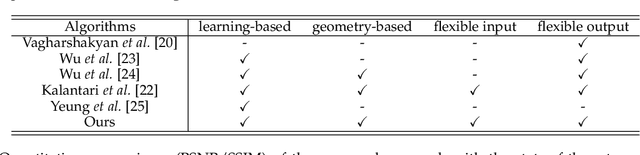
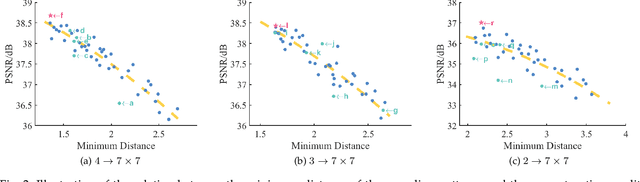

The densely-sampled light field (LF) is highly desirable in various applications, such as 3-D reconstruction, post-capture refocusing and virtual reality. However, it is costly to acquire such data. Although many computational methods have been proposed to reconstruct a densely-sampled LF from a sparsely-sampled one, they still suffer from either low reconstruction quality, low computational efficiency, or the restriction on the regularity of the sampling pattern. To this end, we propose a novel learning-based method, which accepts sparsely-sampled LFs with irregular structures, and produces densely-sampled LFs with arbitrary angular resolution accurately and efficiently. Our proposed method, an end-to-end trainable network, reconstructs a densely-sampled LF in a coarse-to-fine manner. Specifically, the coarse sub-aperture image (SAI) synthesis module first explores the scene geometry from an unstructured sparsely-sampled LF and leverages it to independently synthesize novel SAIs, giving an intermediate densely-sampled LF. Then, the efficient LF refinement module learns the angular relations within the intermediate result to recover the LF parallax structure. Comprehensive experimental evaluations demonstrate the superiority of our method on both real-world and synthetic LF images when compared with state-of-the-art methods. In addition, we illustrate the benefits and advantages of the proposed approach when applied in various LF-based applications, including image-based rendering, depth estimation enhancement, and LF compression.
Recurrent Neural Networks (RNNs): A gentle Introduction and Overview
Nov 23, 2019State-of-the-art solutions in the areas of "Language Modelling & Generating Text", "Speech Recognition", "Generating Image Descriptions" or "Video Tagging" have been using Recurrent Neural Networks as the foundation for their approaches. Understanding the underlying concepts is therefore of tremendous importance if we want to keep up with recent or upcoming publications in those areas. In this work we give a short overview over some of the most important concepts in the realm of Recurrent Neural Networks which enables readers to easily understand the fundamentals such as but not limited to "Backpropagation through Time" or "Long Short-Term Memory Units" as well as some of the more recent advances like the "Attention Mechanism" or "Pointer Networks". We also give recommendations for further reading regarding more complex topics where it is necessary.
Hybrid Style Siamese Network: Incorporating style loss in complimentary apparels retrieval
Nov 23, 2019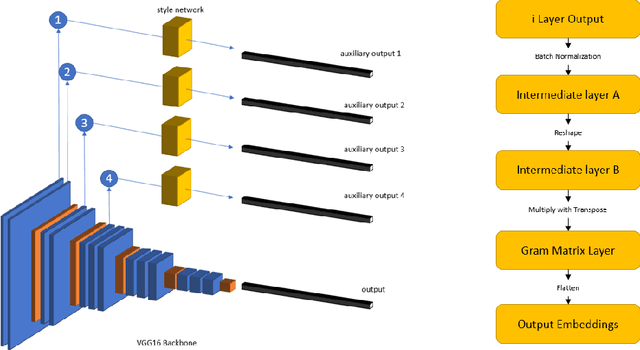
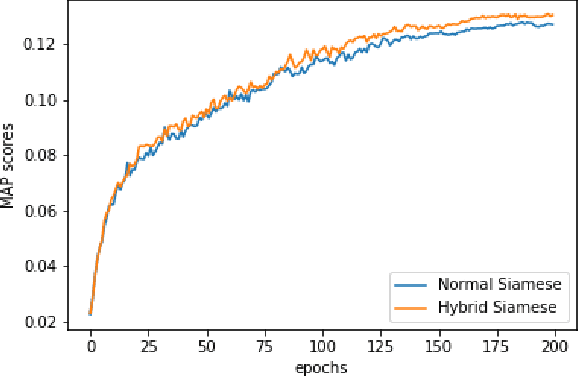
Image Retrieval grows to be an integral part of fashion e-commerce ecosystem as it keeps expanding in multitudes. Other than the retrieval of visually similar items, the retrieval of visually compatible or complimentary items is also an important aspect of it. Normal Siamese Networks tend to work well on complimentary items retrieval. But it fails to identify low level style features which make items compatible in human eyes. These low level style features are captured to a large extent in techniques used in neural style transfer. This paper proposes a mechanism of utilising those methods in this retrieval task and capturing the low level style features through a hybrid siamese network coupled with a hybrid loss. The experimental results indicate that the proposed method outperforms traditional siamese networks in retrieval tasks for complimentary items.
Domain-independent Dominance of Adaptive Methods
Dec 04, 2019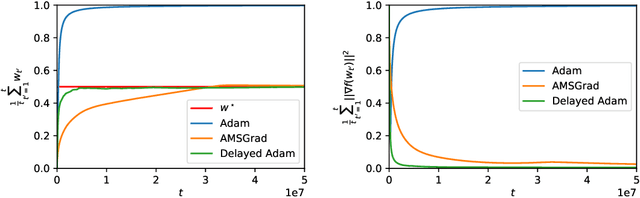
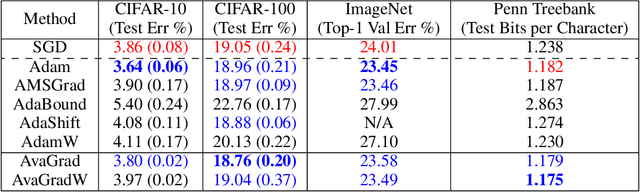
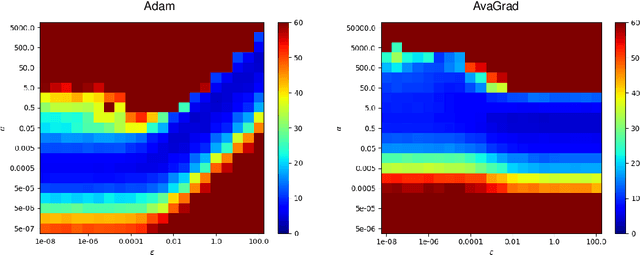
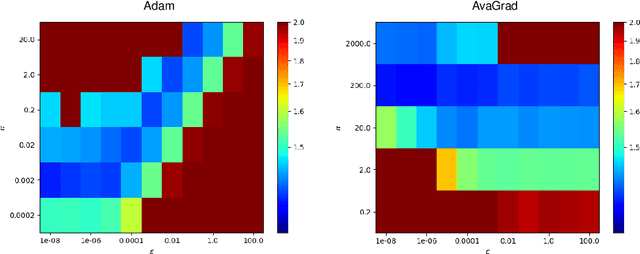
From a simplified analysis of adaptive methods, we derive AvaGrad, a new optimizer which outperforms SGD on vision tasks when its adaptability is properly tuned. We observe that the power of our method is partially explained by a decoupling of learning rate and adaptability, greatly simplifying hyperparameter search. In light of this observation, we demonstrate that, against conventional wisdom, Adam can also outperform SGD on vision tasks, as long as the coupling between its learning rate and adaptability is taken into account. In practice, AvaGrad matches the best results, as measured by generalization accuracy, delivered by any existing optimizer (SGD or adaptive) across image classification (CIFAR, ImageNet) and character-level language modelling (Penn Treebank) tasks. This later observation, alongside of AvaGrad's decoupling of hyperparameters, could make it the preferred optimizer for deep learning, replacing both SGD and Adam.
Complete CVDL Methodology for Investigating Hydrodynamic Instabilities
Apr 03, 2020
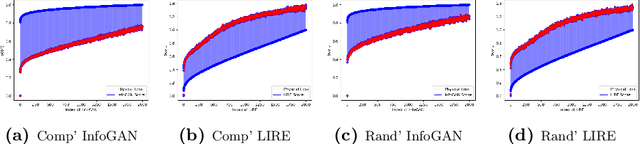

In fluid dynamics, one of the most important research fields is hydrodynamic instabilities and their evolution in different flow regimes. The investigation of said instabilities is concerned with the highly non-linear dynamics. Currently, three main methods are used for understanding of such phenomenon - namely analytical models, experiments and simulations - and all of them are primarily investigated and correlated using human expertise. In this work we claim and demonstrate that a major portion of this research effort could and should be analysed using recent breakthrough advancements in the field of Computer Vision with Deep Learning (CVDL, or Deep Computer-Vision). Specifically, we target and evaluate specific state-of-the-art techniques - such as Image Retrieval, Template Matching, Parameters Regression and Spatiotemporal Prediction - for the quantitative and qualitative benefits they provide. In order to do so we focus in this research on one of the most representative instabilities, the Rayleigh-Taylor one, simulate its behaviour and create an open-sourced state-of-the-art annotated database (RayleAI). Finally, we use adjusted experimental results and novel physical loss methodologies to validate the correspondence of the predicted results to actual physical reality to prove the models efficiency. The techniques which were developed and proved in this work can be served as essential tools for physicists in the field of hydrodynamics for investigating a variety of physical systems, and also could be used via Transfer Learning to other instabilities research. A part of the techniques can be easily applied on already exist simulation results. All models as well as the data-set that was created for this work, are publicly available at: https://github.com/scientific-computing-nrcn/SimulAI.
Towards calibrated and scalable uncertainty representations for neural networks
Dec 04, 2019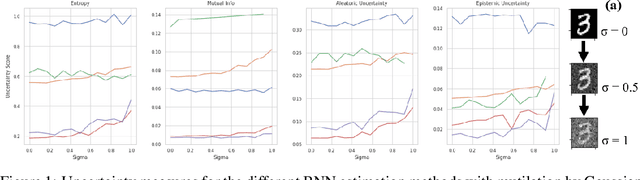
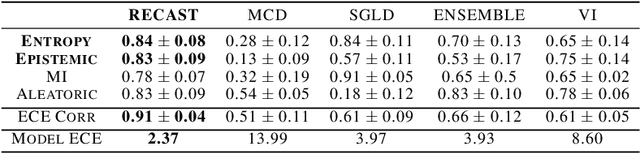
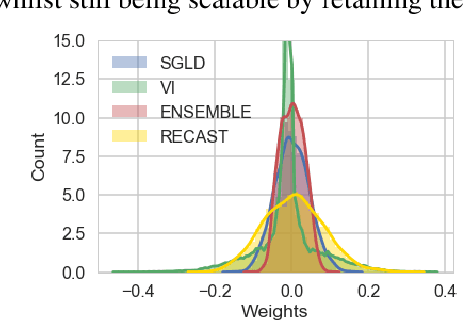
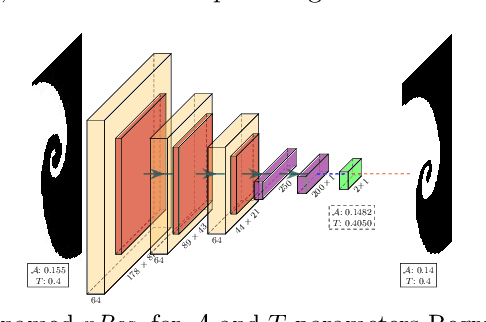
For many applications it is critical to know the uncertainty of a neural network's predictions. While a variety of neural network parameter estimation methods have been proposed for uncertainty estimation, they have not been rigorously compared across uncertainty measures. We assess four of these parameter estimation methods to calibrate uncertainty estimation using four different uncertainty measures: entropy, mutual information, aleatoric uncertainty and epistemic uncertainty. We evaluate the calibration of these parameter estimation methods using expected calibration error. Additionally, we propose a novel method of neural network parameter estimation called RECAST, which combines cosine annealing with warm restarts with Stochastic Gradient Langevin Dynamics, capturing more diverse parameter distributions. When benchmarked against mutilated image data, we show that RECAST is well-calibrated and when combined with predictive entropy and epistemic uncertainty it offers the best calibrated measure of uncertainty when compared to recent methods.
Focus Quality Assessment of High-Throughput Whole Slide Imaging in Digital Pathology
Nov 14, 2018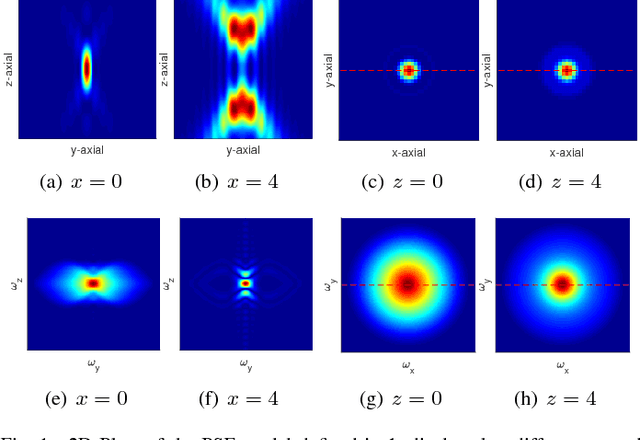
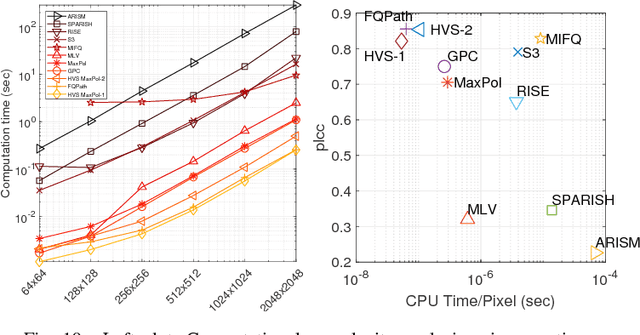
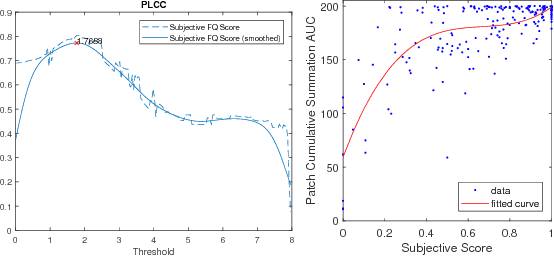
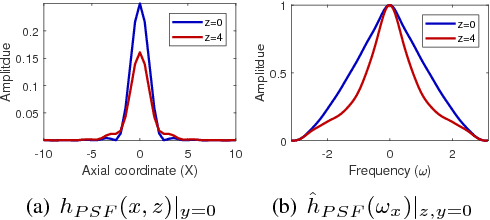
One of the challenges facing the adoption of digital pathology workflows for clinical use is the need for automated quality control. As the scanners sometimes determine focus inaccurately, the resultant image blur deteriorates the scanned slide to the point of being unusable. Also, the scanned slide images tend to be extremely large when scanned at greater or equal 20X image resolution. Hence, for digital pathology to be clinically useful, it is necessary to use computational tools to quickly and accurately quantify the image focus quality and determine whether an image needs to be re-scanned. We propose a no-reference focus quality assessment metric specifically for digital pathology images, that operates by using a sum of even-derivative filter bases to synthesize a human visual system-like kernel, which is modeled as the inverse of the lens' point spread function. This kernel is then applied to a digital pathology image to modify high-frequency image information deteriorated by the scanner's optics and quantify the focus quality at the patch level. We show in several experiments that our method correlates better with ground-truth $z$-level data than other methods, and is more computationally efficient. We also extend our method to generate a local slide-level focus quality heatmap, which can be used for automated slide quality control, and demonstrate the utility of our method for clinical scan quality control by comparison with subjective slide quality scores.