 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition
May 23, 2016

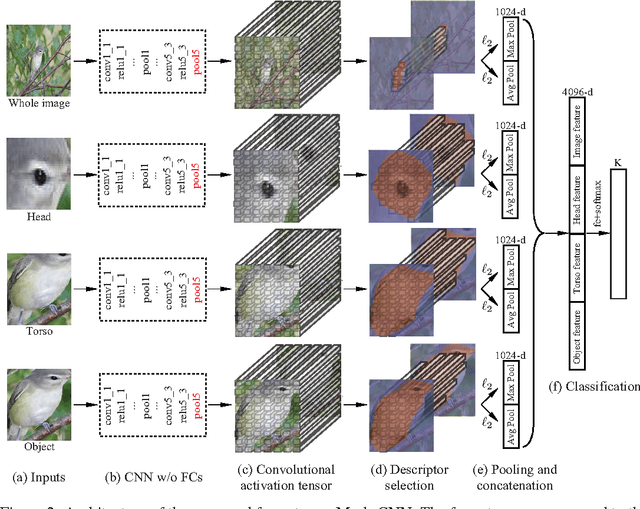
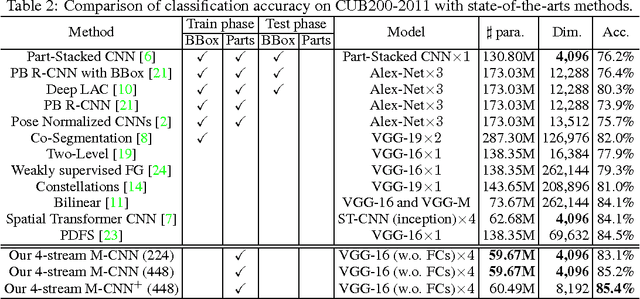
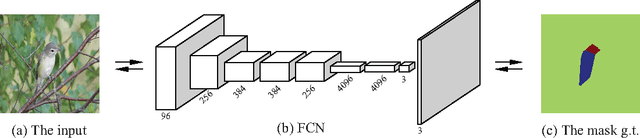
Fine-grained image recognition is a challenging computer vision problem, due to the small inter-class variations caused by highly similar subordinate categories, and the large intra-class variations in poses, scales and rotations. In this paper, we propose a novel end-to-end Mask-CNN model without the fully connected layers for fine-grained recognition. Based on the part annotations of fine-grained images, the proposed model consists of a fully convolutional network to both locate the discriminative parts (e.g., head and torso), and more importantly generate object/part masks for selecting useful and meaningful convolutional descriptors. After that, a four-stream Mask-CNN model is built for aggregating the selected object- and part-level descriptors simultaneously. The proposed Mask-CNN model has the smallest number of parameters, lowest feature dimensionality and highest recognition accuracy when compared with state-of-the-arts fine-grained approaches.
CELNet: Evidence Localization for Pathology Images using Weakly Supervised Learning
Sep 16, 2019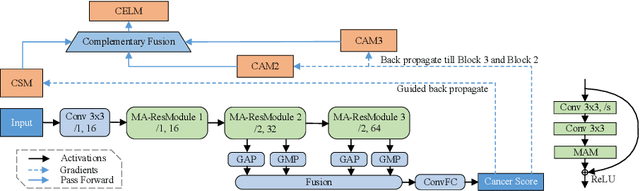
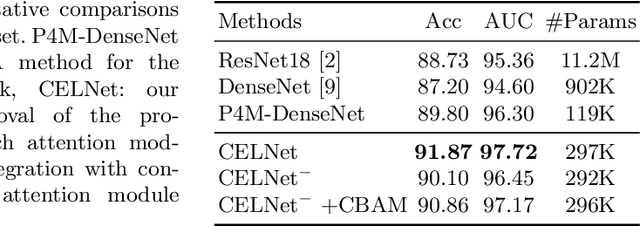

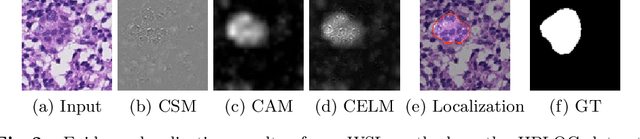
Despite deep convolutional neural networks boost the performance of image classification and segmentation in digital pathology analysis, they are usually weak in interpretability for clinical applications or require heavy annotations to achieve object localization. To overcome this problem, we propose a weakly supervised learning-based approach that can effectively learn to localize the discriminative evidence for a diagnostic label from weakly labeled training data. Experimental results show that our proposed method can reliably pinpoint the location of cancerous evidence supporting the decision of interest, while still achieving a competitive performance on glimpse-level and slide-level histopathologic cancer detection tasks.
Stories for Images-in-Sequence by using Visual and Narrative Components
Sep 22, 2018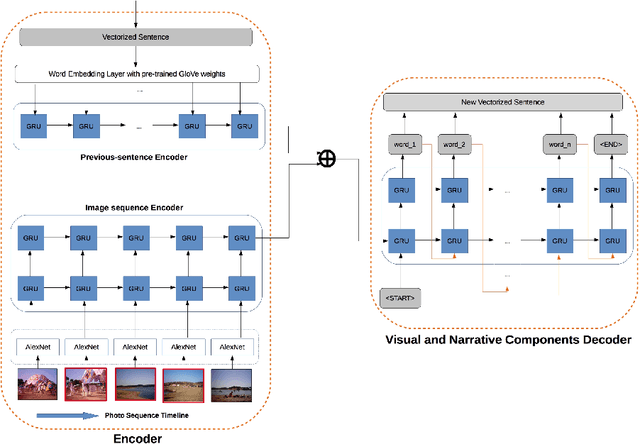
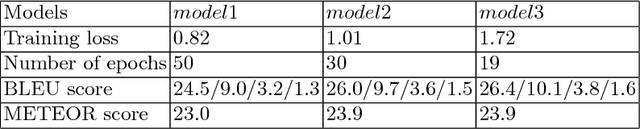
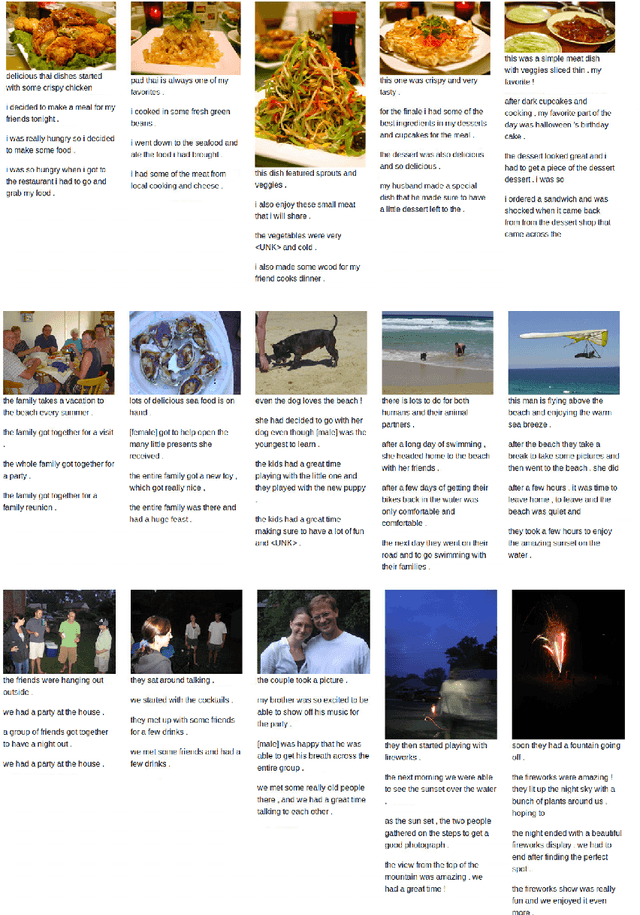
Recent research in AI is focusing towards generating narrative stories about visual scenes. It has the potential to achieve more human-like understanding than just basic description generation of images- in-sequence. In this work, we propose a solution for generating stories for images-in-sequence that is based on the Sequence to Sequence model. As a novelty, our encoder model is composed of two separate encoders, one that models the behaviour of the image sequence and other that models the sentence-story generated for the previous image in the sequence of images. By using the image sequence encoder we capture the temporal dependencies between the image sequence and the sentence-story and by using the previous sentence-story encoder we achieve a better story flow. Our solution generates long human-like stories that not only describe the visual context of the image sequence but also contains narrative and evaluative language. The obtained results were confirmed by manual human evaluation.
* 12 pages, 4 figures, ICT Innovations 2018
Harvesting Visual Objects from Internet Images via Deep Learning Based Objectness Assessment
Apr 01, 2019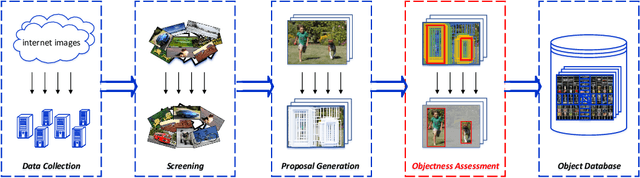
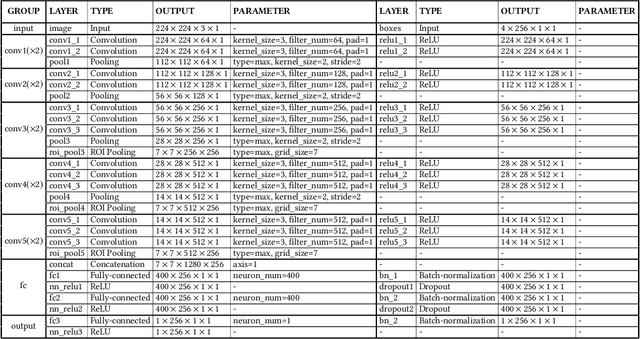
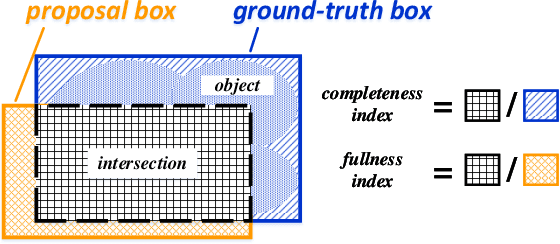
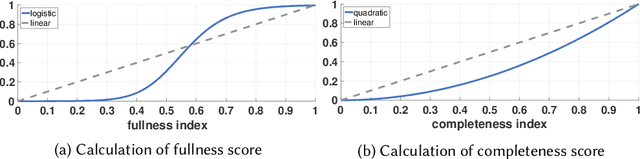
The collection of internet images has been growing in an astonishing speed. It is undoubted that these images contain rich visual information that can be useful in many applications, such as visual media creation and data-driven image synthesis. In this paper, we focus on the methodologies for building a visual object database from a collection of internet images. Such database is built to contain a large number of high-quality visual objects that can help with various data-driven image applications. Our method is based on dense proposal generation and objectness-based re-ranking. A novel deep convolutional neural network is designed for the inference of proposal objectness, the probability of a proposal containing optimally-located foreground object. In our work, the objectness is quantitatively measured in regard of completeness and fullness, reflecting two complementary features of an optimal proposal: a complete foreground and relatively small background. Our experiments indicate that object proposals re-ranked according to the output of our network generally achieve higher performance than those produced by other state-of-the-art methods. As a concrete example, a database of over 1.2 million visual objects has been built using the proposed method, and has been successfully used in various data-driven image applications.
Bidirectional Scene Text Recognition with a Single Decoder
Dec 08, 2019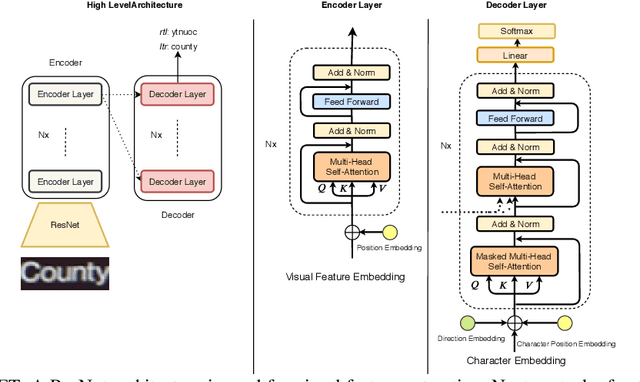
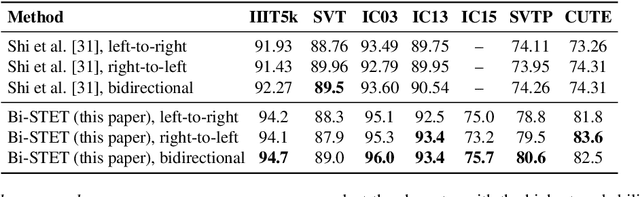
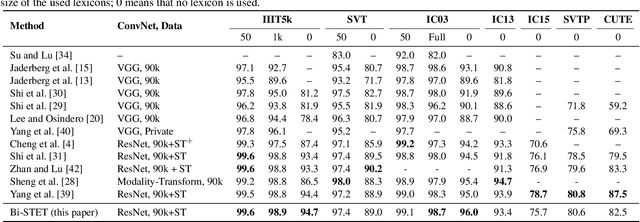

Scene Text Recognition (STR) is the problem of recognizing the correct word or character sequence in a cropped word image. To obtain more robust output sequences, the notion of bidirectional STR has been introduced. So far, bidirectional STRs have been implemented by using two separate decoders; one for left-to-right decoding and one for right-to-left. Having two separate decoders for almost the same task with the same output space is undesirable from a computational and optimization point of view. We introduce the bidirectional Scene Text Transformer (Bi-STET), a novel bidirectional STR method with a single decoder for bidirectional text decoding. With its single decoder, Bi-STET outperforms methods that apply bidirectional decoding by using two separate decoders while also being more efficient than those methods, Furthermore, we achieve or beat state-of-the-art (SOTA) methods on all STR benchmarks with Bi-STET. Finally, we provide analyses and insights into the performance of Bi-STET.
A Generalization Theory based on Independent and Task-Identically Distributed Assumption
Nov 28, 2019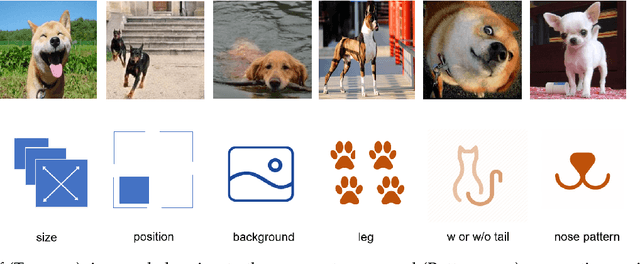
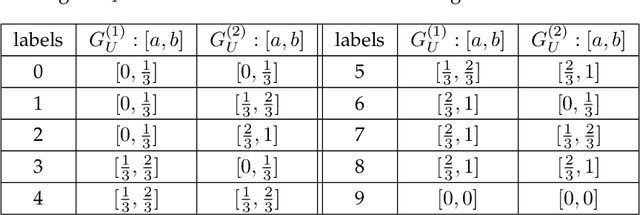
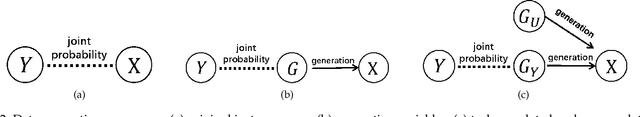
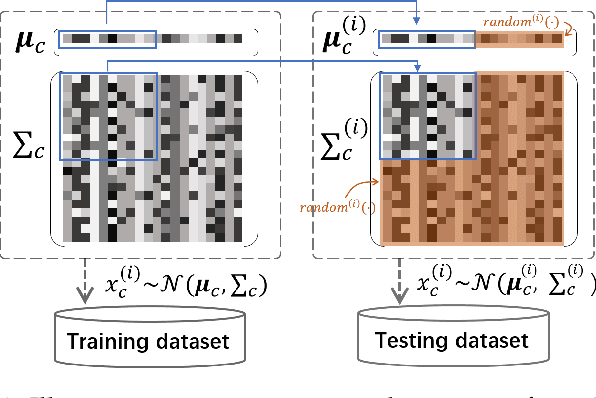
Existing generalization theories analyze the generalization performance mainly based on the model complexity and training process. The ignorance of the task properties, which results from the widely used IID assumption, makes these theories fail to interpret many generalization phenomena or guide practical learning tasks. In this paper, we propose a new Independent and Task-Identically Distributed (ITID) assumption, to consider the task properties into the data generating process. The derived generalization bound based on the ITID assumption identifies the significance of hypothesis invariance in guaranteeing generalization performance. Based on the new bound, we introduce a practical invariance enhancement algorithm from the perspective of modifying data distributions. Finally, we verify the algorithm and theorems in the context of image classification task on both toy and real-world datasets. The experimental results demonstrate the reasonableness of the ITID assumption and the effectiveness of new generalization theory in improving practical generalization performance.
Adversarial Learning of Disentangled and Generalizable Representations for Visual Attributes
Apr 18, 2019
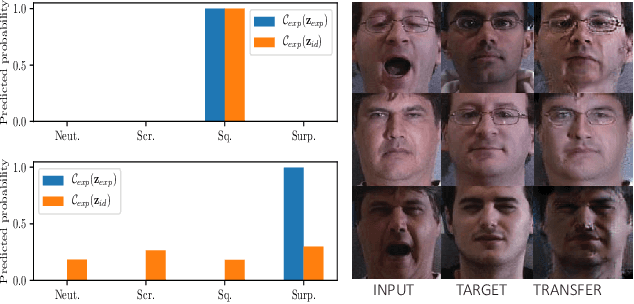
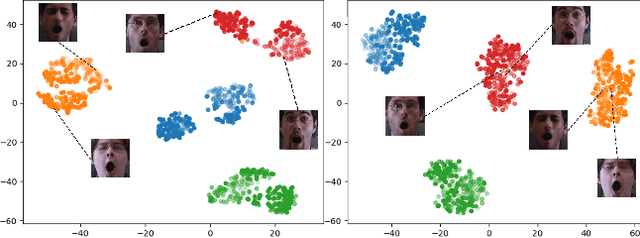
Recently, a multitude of methods for image-to-image translation has demonstrated impressive results on problems such as multi-domain or multi-attribute transfer. The vast majority of such works leverages the strengths of adversarial learning in tandem with deep convolutional autoencoders to achieve realistic results by well-capturing the target data distribution. Nevertheless, the most prominent representatives of this class of methods do not facilitate semantic structure in the latent space, and usually rely on domain labels for test-time transfer. This leads to rigid models that are unable to capture the variance of each domain label. In this light, we propose a novel adversarial learning method that (i) facilitates latent structure by disentangling sources of variation based on a novel cost function and (ii) encourages learning generalizable, continuous and transferable latent codes that can be utilized for tasks such as unpaired multi-domain image transfer and synthesis, without requiring labelled test data. The resulting representations can be combined in arbitrary ways to generate novel hybrid imagery, as for example generating mixtures of identities. We demonstrate the merits of the proposed method by a set of qualitative and quantitative experiments on popular databases, where our method clearly outperforms other, state-of-the-art methods. Code for reproducing our results can be found at: https://github.com/james-oldfield/adv-attribute-disentanglement
Predictive modeling of brain tumor: A Deep learning approach
Nov 06, 2019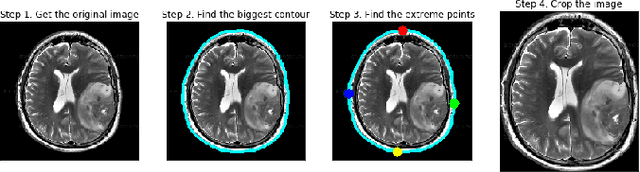

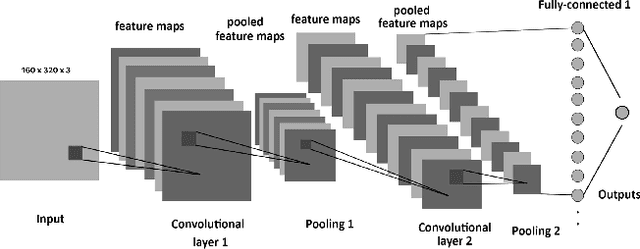
Image processing concepts can visualize the different anatomy structure of the human body. Recent advancements in the field of deep learning have made it possible to detect the growth of cancerous tissue just by a patient's brain Magnetic Resonance Imaging (MRI) scans. These methods require very high accuracy and meager false negative rates to be of any practical use. This paper presents a Convolutional Neural Network (CNN) based transfer learning approach to classify the brain MRI scans into two classes using three pre-trained models. The performances of these models are compared with each other. Experimental results show that the Resnet-50 model achieves the highest accuracy and least false negative rates as 95% and zero respectively. It is followed by VGG-16 and Inception-V3 model with an accuracy of 90% and 55% respectively.
A Novel and Efficient Tumor Detection Framework for Pancreatic Cancer via CT Images
Feb 11, 2020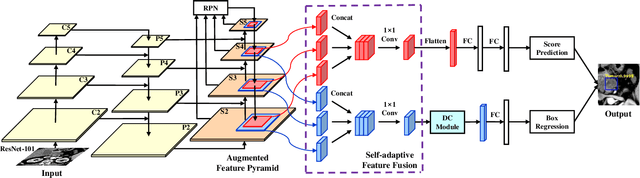
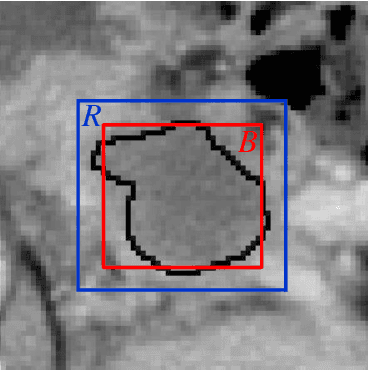
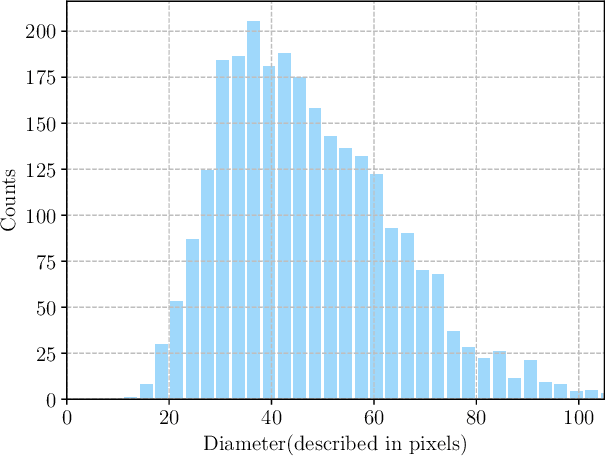
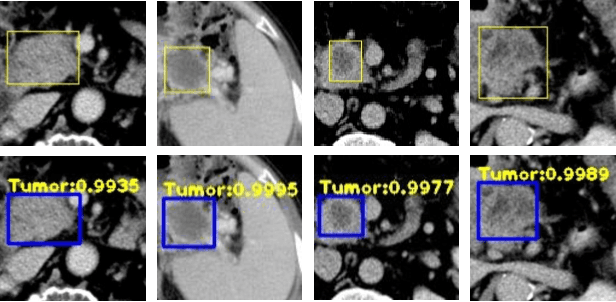
As Deep Convolutional Neural Networks (DCNNs) have shown robust performance and results in medical image analysis, a number of deep-learning-based tumor detection methods were developed in recent years. Nowadays, the automatic detection of pancreatic tumors using contrast-enhanced Computed Tomography (CT) is widely applied for the diagnosis and staging of pancreatic cancer. Traditional hand-crafted methods only extract low-level features. Normal convolutional neural networks, however, fail to make full use of effective context information, which causes inferior detection results. In this paper, a novel and efficient pancreatic tumor detection framework aiming at fully exploiting the context information at multiple scales is designed. More specifically, the contribution of the proposed method mainly consists of three components: Augmented Feature Pyramid networks, Self-adaptive Feature Fusion and a Dependencies Computation (DC) Module. A bottom-up path augmentation to fully extract and propagate low-level accurate localization information is established firstly. Then, the Self-adaptive Feature Fusion can encode much richer context information at multiple scales based on the proposed regions. Finally, the DC Module is specifically designed to capture the interaction information between proposals and surrounding tissues. Experimental results achieve competitive performance in detection with the AUC of 0.9455, which outperforms other state-of-the-art methods to our best of knowledge, demonstrating the proposed framework can detect the tumor of pancreatic cancer efficiently and accurately.
Spinal Metastases Segmentation in MR Imaging using Deep Convolutional Neural Networks
Jan 28, 2020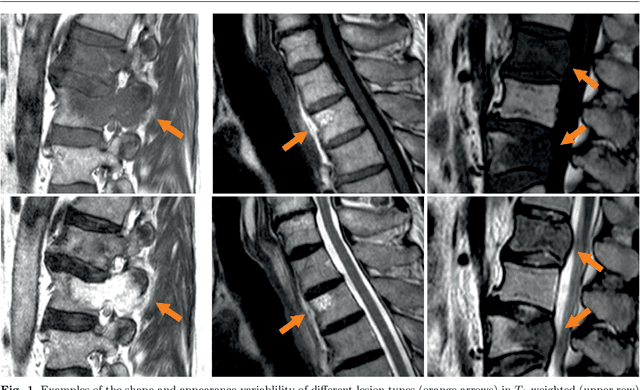
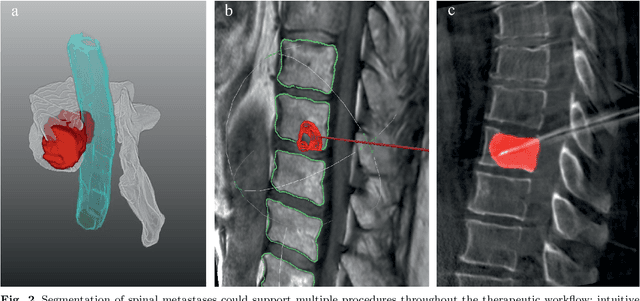
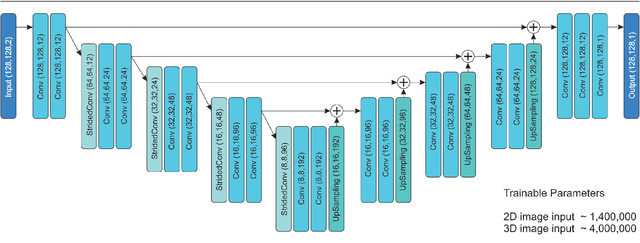

This study's objective was to segment spinal metastases in diagnostic MR images using a deep learning-based approach. Segmentation of such lesions can present a pivotal step towards enhanced therapy planning and validation, as well as intervention support during minimally invasive and image-guided surgeries like radiofrequency ablations. For this purpose, we used a U-Net like architecture trained with 40 clinical cases including both, lytic and sclerotic lesion types and various MR sequences. Our proposed method was evaluated with regards to various factors influencing the segmentation quality, e.g. the used MR sequences and the input dimension. We quantitatively assessed our experiments using Dice coefficients, sensitivity and specificity rates. Compared to expertly annotated lesion segmentations, the experiments yielded promising results with average Dice scores up to 77.6% and mean sensitivity rates up to 78.9%. To our best knowledge, our proposed study is one of the first to tackle this particular issue, which limits direct comparability with related works. In respect to similar deep learning-based lesion segmentations, e.g. in liver MR images or spinal CT images, our experiments showed similar or in some respects superior segmentation quality. Overall, our automatic approach can provide almost expert-like segmentation accuracy in this challenging and ambitious task.