 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition
May 23, 2016

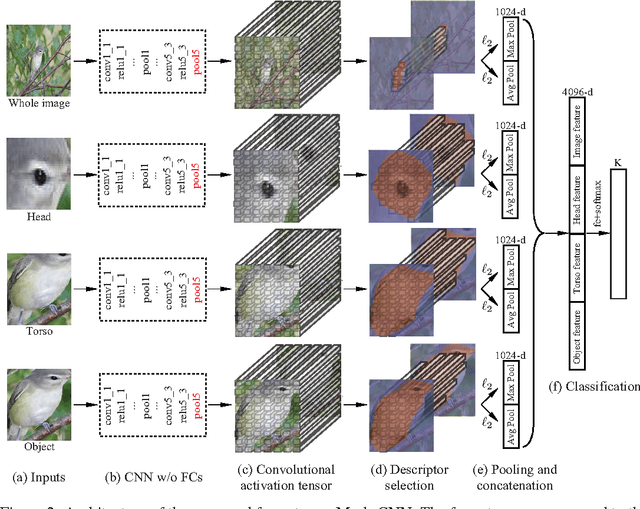
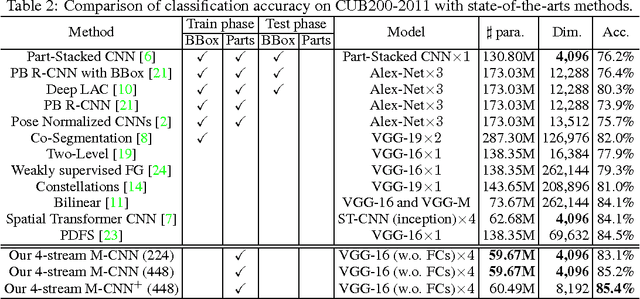
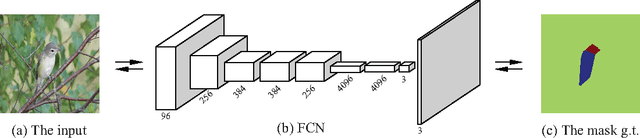
Fine-grained image recognition is a challenging computer vision problem, due to the small inter-class variations caused by highly similar subordinate categories, and the large intra-class variations in poses, scales and rotations. In this paper, we propose a novel end-to-end Mask-CNN model without the fully connected layers for fine-grained recognition. Based on the part annotations of fine-grained images, the proposed model consists of a fully convolutional network to both locate the discriminative parts (e.g., head and torso), and more importantly generate object/part masks for selecting useful and meaningful convolutional descriptors. After that, a four-stream Mask-CNN model is built for aggregating the selected object- and part-level descriptors simultaneously. The proposed Mask-CNN model has the smallest number of parameters, lowest feature dimensionality and highest recognition accuracy when compared with state-of-the-arts fine-grained approaches.
Bayesian Grasp: Robotic visual stable grasp based on prior tactile knowledge
May 30, 2019

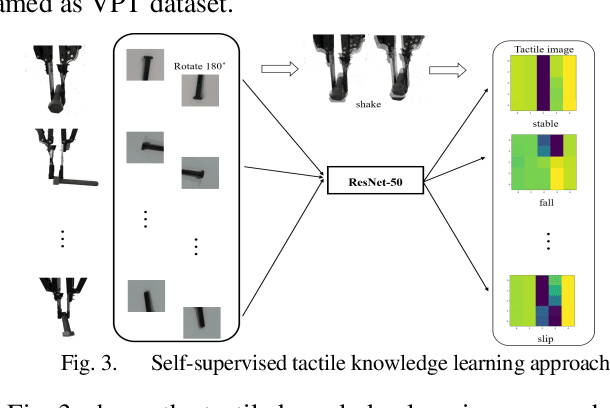
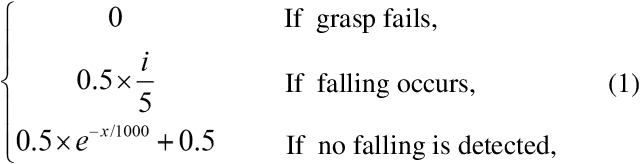
Robotic grasp detection is a fundamental capability for intelligent manipulation in unstructured environments. Previous work mainly employed visual and tactile fusion to achieve stable grasp, while, the whole process depending heavily on regrasping, which wastes much time to regulate and evaluate. We propose a novel way to improve robotic grasping: by using learned tactile knowledge, a robot can achieve a stable grasp from an image. First, we construct a prior tactile knowledge learning framework with novel grasp quality metric which is determined by measuring its resistance to external perturbations. Second, we propose a multi-phases Bayesian Grasp architecture to generate stable grasp configurations through a single RGB image based on prior tactile knowledge. Results show that this framework can classify the outcome of grasps with an average accuracy of 86% on known objects and 79% on novel objects. The prior tactile knowledge improves the successful rate of 55% over traditional vision-based strategies.
Image-based Vehicle Classification System
Apr 10, 2012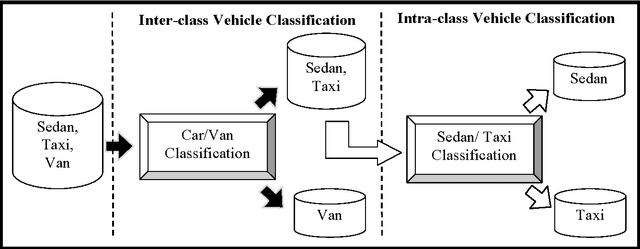
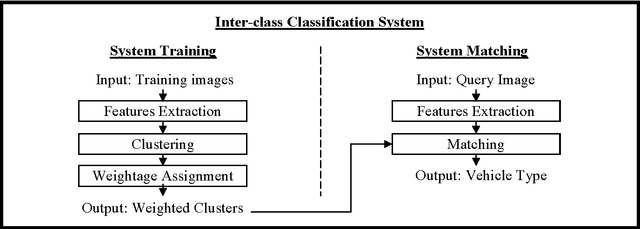
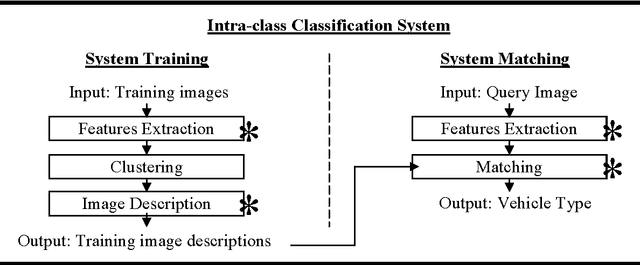
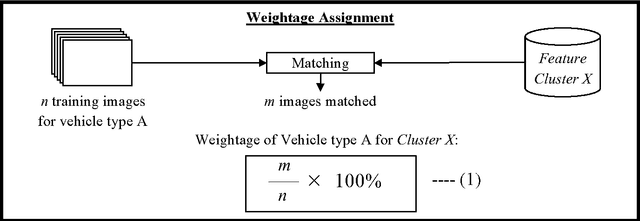
Electronic toll collection (ETC) system has been a common trend used for toll collection on toll road nowadays. The implementation of electronic toll collection allows vehicles to travel at low or full speed during the toll payment, which help to avoid the traffic delay at toll road. One of the major components of an electronic toll collection is the automatic vehicle detection and classification (AVDC) system which is important to classify the vehicle so that the toll is charged according to the vehicle classes. Vision-based vehicle classification system is one type of vehicle classification system which adopt camera as the input sensing device for the system. This type of system has advantage over the rest for it is cost efficient as low cost camera is used. The implementation of vision-based vehicle classification system requires lower initial investment cost and very suitable for the toll collection trend migration in Malaysia from single ETC system to full-scale multi-lane free flow (MLFF). This project includes the development of an image-based vehicle classification system as an effort to seek for a robust vision-based vehicle classification system. The techniques used in the system include scale-invariant feature transform (SIFT) technique, Canny's edge detector, K-means clustering as well as Euclidean distance matching. In this project, a unique way to image description as matching medium is proposed. This distinctiveness of method is analogous to the human DNA concept which is highly unique. The system is evaluated on open datasets and return promising results.
Bottleneck detection by slope difference distribution: a robust approach for separating overlapped cells
Dec 11, 2019
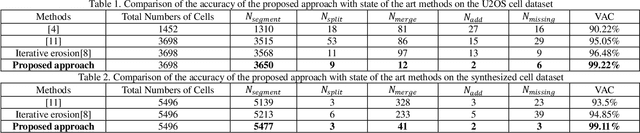

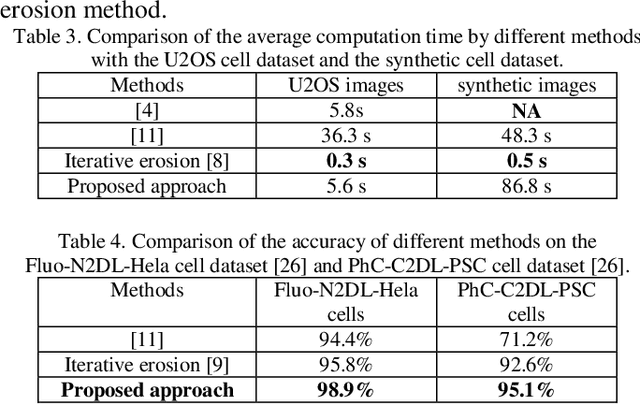
To separate the overlapped cells, a bottleneck detection approach is proposed in this paper. The cell image is segmented by slope difference distribution (SDD) threshold selection. For each segmented binary clump, its one-dimensional boundary is computed as the distance distribution between its centroid and each point on the two-dimensional boundary. The bottleneck points of the one-dimensional boundary is detected by SDD and then transformed back into two-dimensional bottleneck points. Two largest concave parts of the binary clump are used to select the valid bottleneck points. Two bottleneck points from different concave parts with the minimum Euclidean distance is connected to separate the binary clump with minimum-cut. The binary clumps are separated iteratively until the number of computed concave parts is smaller than two. We use four types of open-accessible cell datasets to verify the effectiveness of the proposed approach and experimental results showed that the proposed approach is significantly more robust than state of the art methods.
SG-One: Similarity Guidance Network for One-Shot Semantic Segmentation
Oct 26, 2018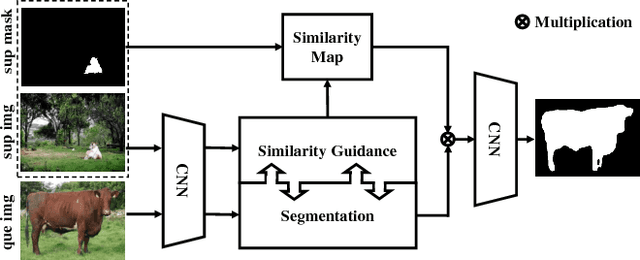

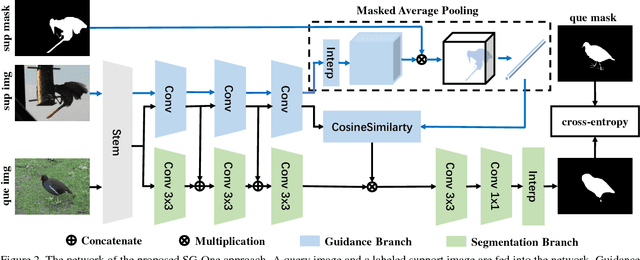
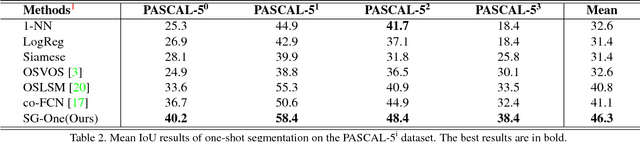
One-shot semantic segmentation poses a challenging task of recognizing the object regions from unseen categories with only one annotated example as supervision. In this paper, we propose a simple yet effective Similarity Guidance network to tackle the One-shot (SG-One) segmentation problem. We aim at predicting the segmentation mask of a query image with the reference to one densely labeled support image. To obtain the robust representative feature of the support image, we firstly propose a masked average pooling strategy for producing the guidance features using only the pixels belonging to the support image. We then leverage the cosine similarity to build the relationship between the guidance features and features of pixels from the query image. In this way, the possibilities embedded in the produced similarity maps can be adopted to guide the process of segmenting objects. Furthermore, our SG-One is a unified framework which can efficiently process both support and query images within one network and be learned in an end-to-end manner. We conduct extensive experiments on Pascal VOC 2012. In particular, our SG-One achieves the mIoU score of 46.3%, which outperforms the state-of-the-art.
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Dec 10, 2019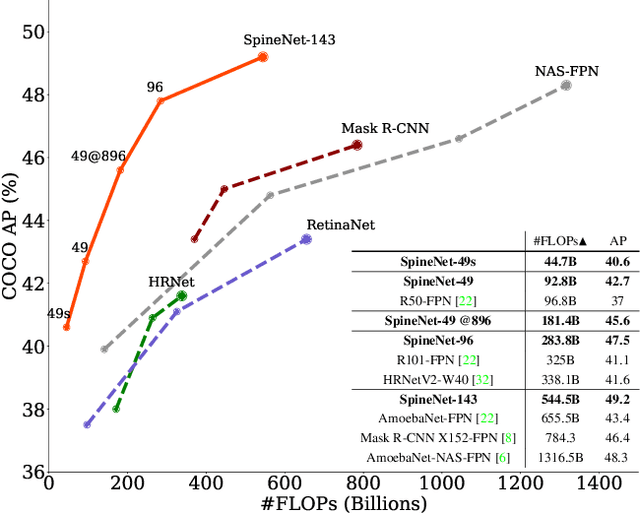
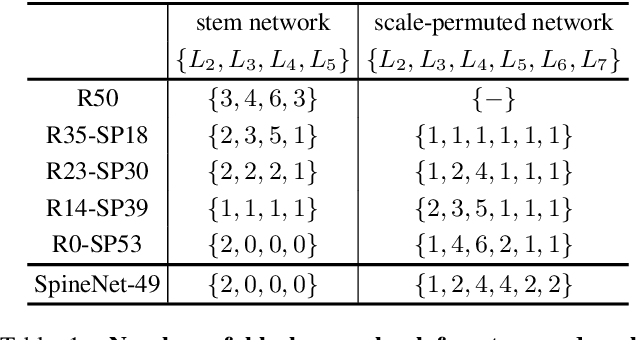
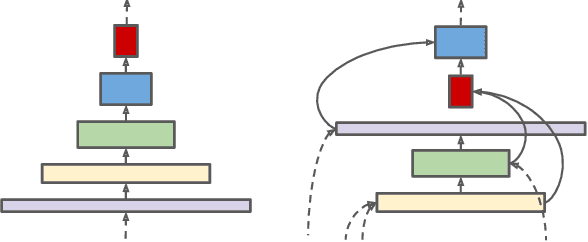
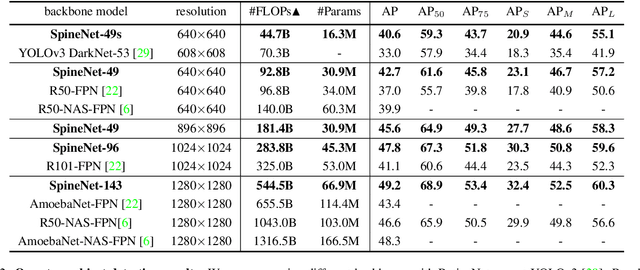
Convolutional neural networks typically encode an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that is learned on an object detection task by Neural Architecture Search. SpineNet achieves state-of-the-art performance of one-stage object detector on COCO with 60% less computation, and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
Automatic lung segmentation in routine imaging is a data diversity problem, not a methodology problem
Jan 31, 2020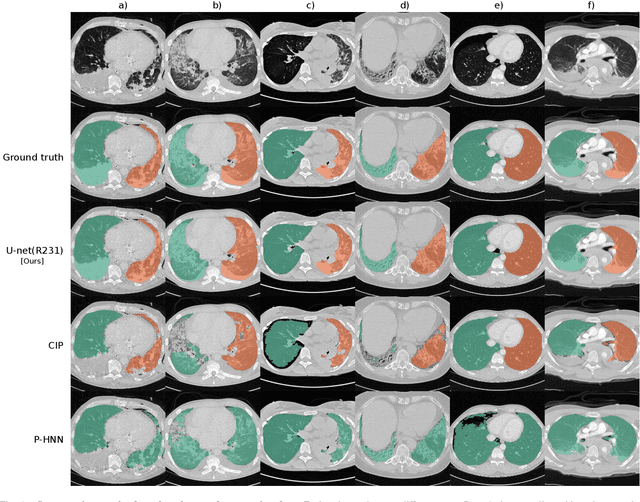
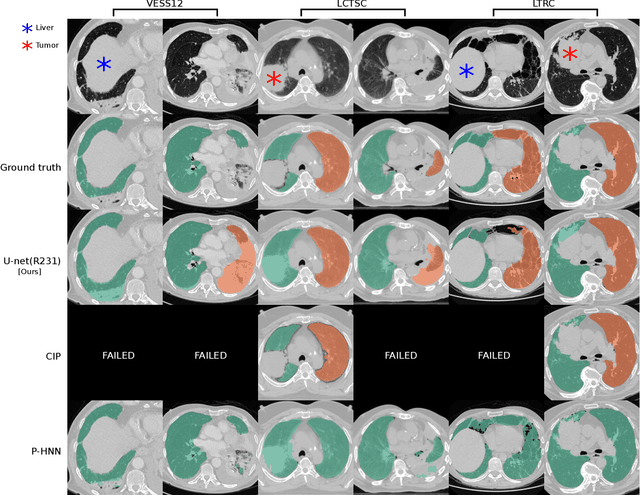
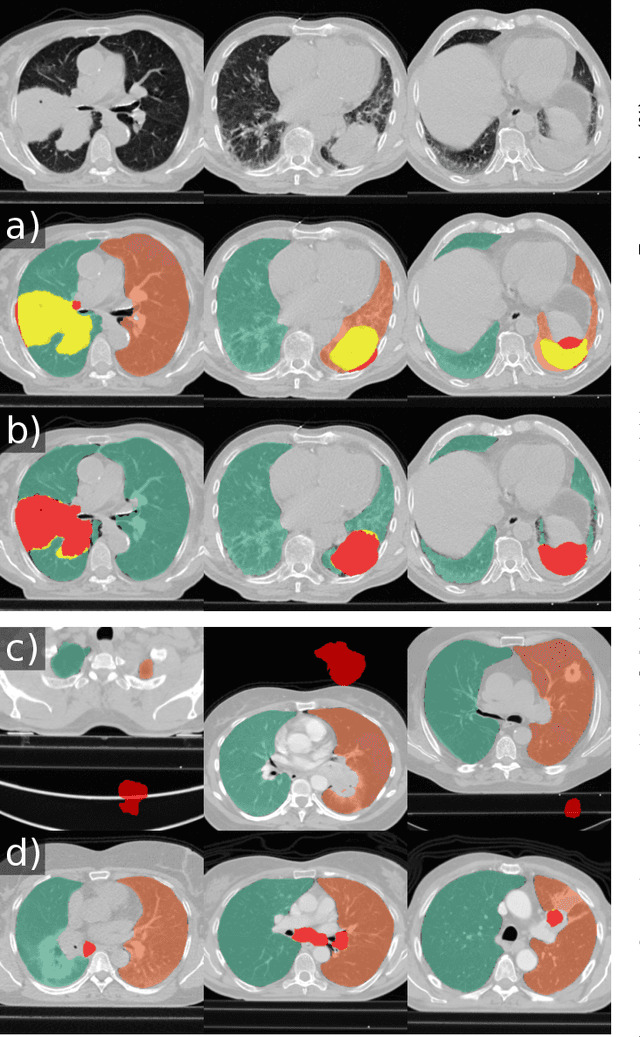
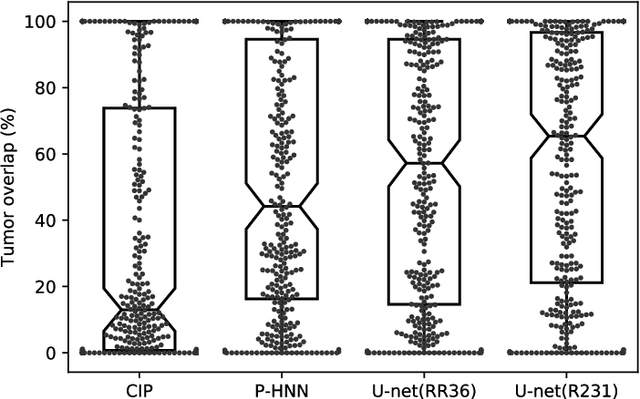
Automated segmentation of anatomical structures is a crucial step in many medical image analysis tasks. For lung segmentation, a variety of approaches exist, involving sophisticated pipelines trained and validated on a range of different data sets. However, during translation to clinical routine the applicability of these approaches across diseases remains limited. Here, we show that the accuracy and reliability of lung segmentation algorithms on demanding cases primarily does not depend on methodology, but on the diversity of training data. We compare 4 generic deep learning approaches and 2 published lung segmentation algorithms on routine imaging data with more than 6 different disease patterns and 3 published data sets. We show that a basic approach - U-net - performs either better, or competitively with other approaches on both routine data and published data sets, and outperforms published approaches once trained on a diverse data set covering multiple diseases. Training data composition consistently has a bigger impact than algorithm choice on accuracy across test data sets. We carefully analyse the impact of data diversity, and the specifications of annotations on both training and validation sets to provide a reference for algorithms, training data, and annotation. Results on a seemingly well understood task of lung segmentation suggest the critical importance of training data diversity compared to model choice.
Representing Images in 200 Bytes: Compression via Triangulation
Sep 20, 2018

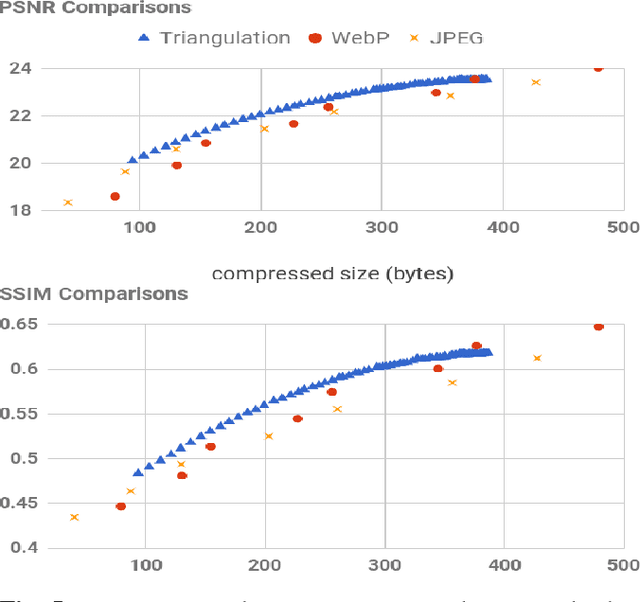
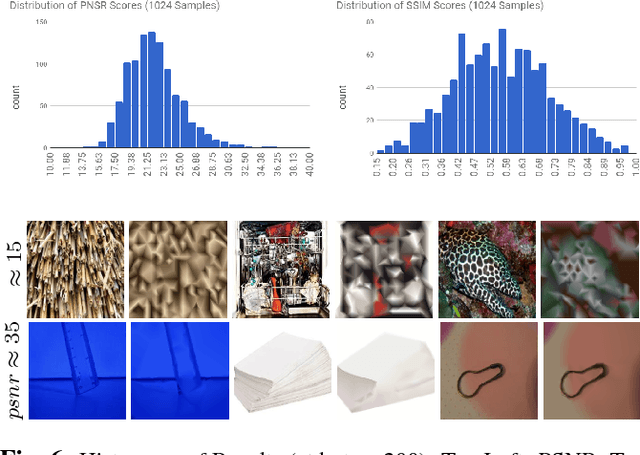
A rapidly increasing portion of internet traffic is dominated by requests from mobile devices with limited and metered bandwidth constraints. To satisfy these requests, it has become standard practice for websites to transmit small and extremely compressed image previews as part of the initial page load process to improve responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore an active research direction. In this work, we concentrate on extreme compression rates, where the size of the image is typically 200 bytes or less. First, we propose a novel approach for image compression that, unlike commonly used methods, does not rely on block-based statistics. We use an approach based on an adaptive triangulation of the target image, devoting more triangles to high entropy regions of the image. Second, we present a novel algorithm for encoding the triangles. The results show favorable statistics, in terms of PSNR and SSIM, over both the JPEG and the WebP standards.
Integrated unpaired appearance-preserving shape translation across domains
Dec 05, 2018
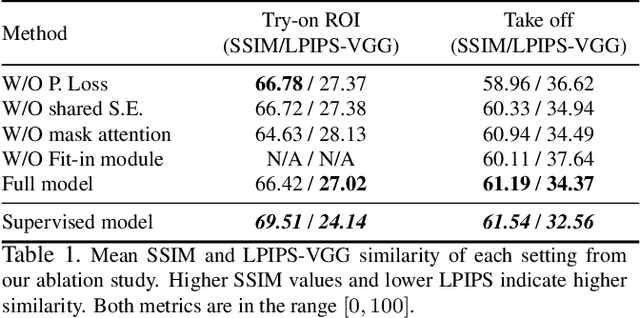
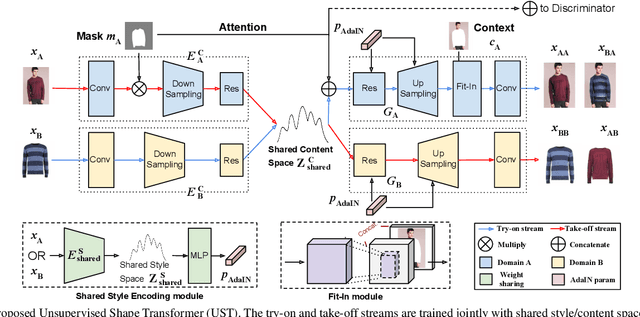
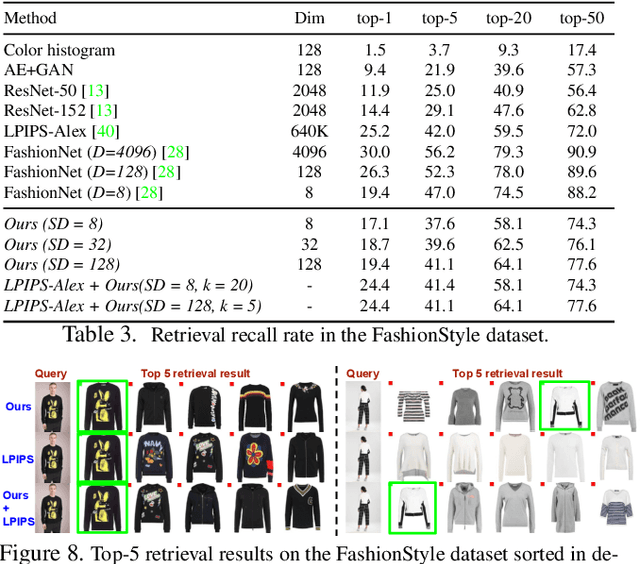
We address the problem of un-supervised geometric image-to-image translation. Rather than transferring the style of an image as a whole, our goal is to translate the geometry of an object as depicted in different domains while preserving its appearance. Towards this goal, we propose a fully un-paired model that performs shape translation within a single model and without the need of additional post-processing stages. Extensive experiments on the VITON, CMU-Multi-PIE and our own FashionStyle datasets show the effectiveness of the proposed method at achieving the task at hand. In addition, we show that despite their low-dimensionality, the features learned by our model have potential for the item retrieval task
SGAS: Sequential Greedy Architecture Search
Nov 30, 2019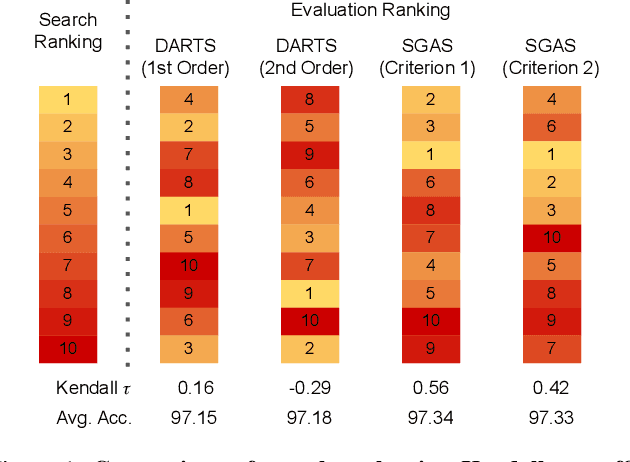
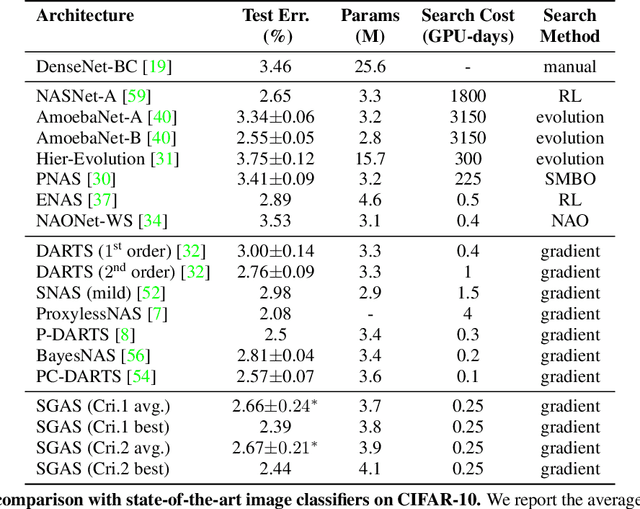
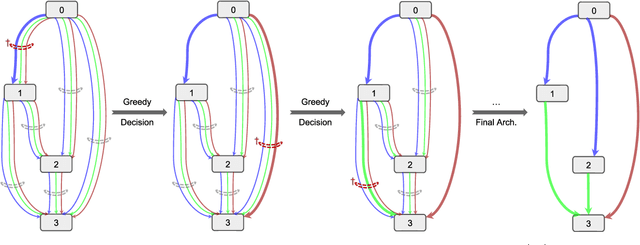
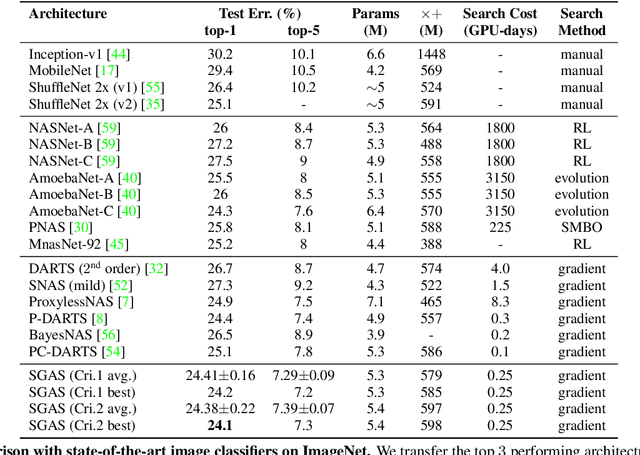
Architecture design has become a crucial component of successful deep learning. Recent progress in automatic neural architecture search (NAS) shows a lot of promise. However, discovered architectures often fail to generalize in the final evaluation. Architectures with a higher validation accuracy during the search phase may perform worse in the evaluation. Aiming to alleviate this common issue, we introduce sequential greedy architecture search (SGAS), an efficient method for neural architecture search. By dividing the search procedure into sub-problems, SGAS chooses and prunes candidate operations in a greedy fashion. We apply SGAS to search architectures for Convolutional Neural Networks (CNN) and Graph Convolutional Networks (GCN). Extensive experiments show that SGAS is able to find state-of-the-art architectures for tasks such as image classification, point cloud classification and node classification in protein-protein interaction graphs with minimal computational cost. Please visit https://sites.google.com/kaust.edu.sa/sgas for more information about SGAS.