 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Classification using Robust Feature Augmentation
May 31, 2019

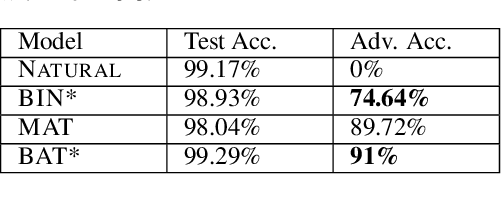
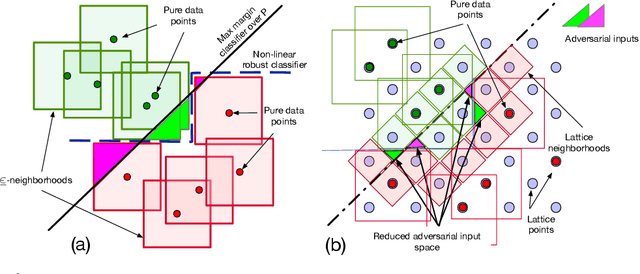

Existing deep neural networks, say for image classification, have been shown to be vulnerable to adversarial images that can cause a DNN misclassification, without any perceptible change to an image. In this work, we propose shock absorbing robust features such as binarization, e.g., rounding, and group extraction, e.g., color or shape, to augment the classification pipeline, resulting in more robust classifiers. Experimentally, we show that augmenting ML models with these techniques leads to improved overall robustness on adversarial inputs as well as significant improvements in training time. On the MNIST dataset, we achieved 14x speedup in training time to obtain 90% adversarial accuracy com-pared to the state-of-the-art adversarial training method of Madry et al., as well as retained higher adversarial accuracy over a broader range of attacks. We also find robustness improvements on traffic sign classification using robust feature augmentation. Finally, we give theoretical insights for why one can expect robust feature augmentation to reduce adversarial input space
Dual Attention Networks for Visual Reference Resolution in Visual Dialog
Feb 25, 2019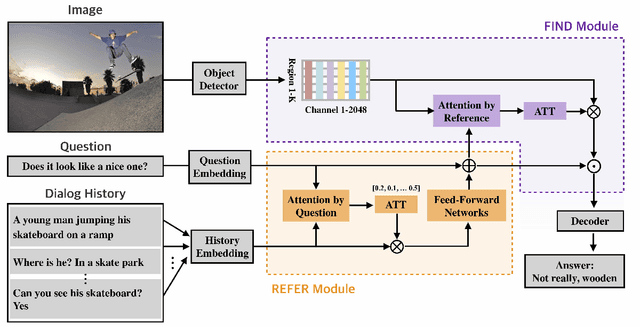
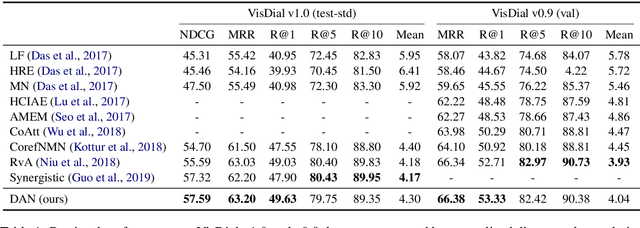
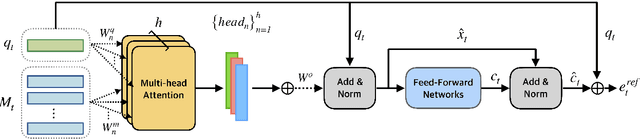
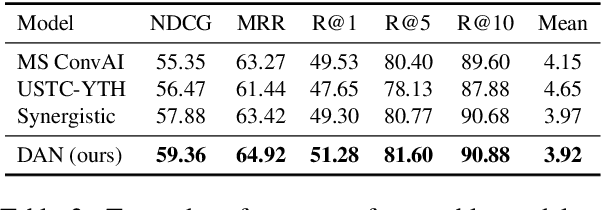
Visual dialog (VisDial) is a task which requires an AI agent to answer a series of questions grounded in an image. Unlike in visual question answering (VQA), the series of questions should be able to capture a temporal context from a dialog history and exploit visually-grounded information. A problem called visual reference resolution involves these challenges, requiring the agent to resolve ambiguous references in a given question and find the references in a given image. In this paper, we propose Dual Attention Networks (DAN) for visual reference resolution. DAN consists of two kinds of attention networks, REFER and FIND. Specifically, REFER module learns latent relationships between a given question and a dialog history by employing a self-attention mechanism. FIND module takes image features and reference-aware representations (i.e., the output of REFER module) as input, and performs visual grounding via bottom-up attention mechanism. We qualitatively and quantitatively evaluate our model on VisDial v1.0 and v0.9 datasets, showing that DAN outperforms the previous state-of-the-art model by a significant margin (2.0% on NDCG).
Feature-Fused Context-Encoding Network for Neuroanatomy Segmentation
May 07, 2019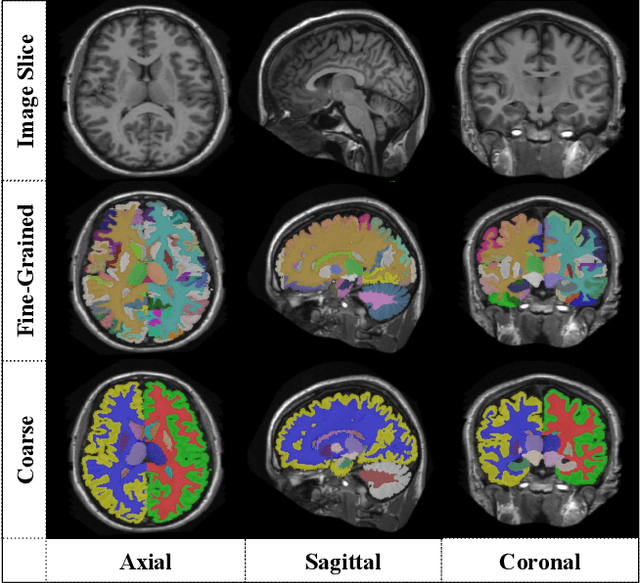
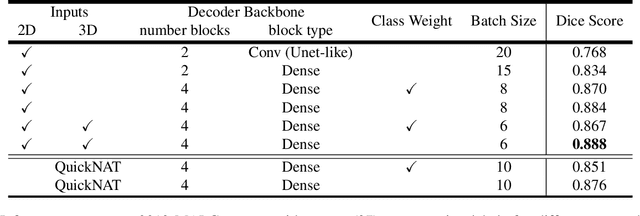
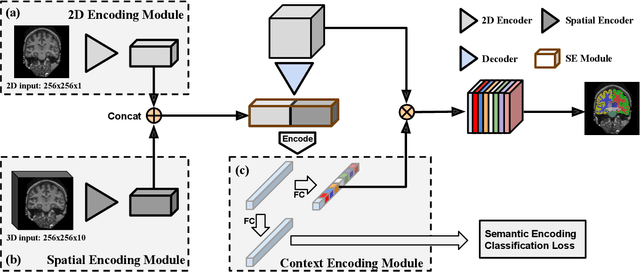
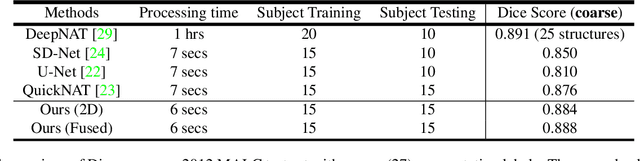
Automatic segmentation of fine-grained brain structures remains a challenging task. Current segmentation methods mainly utilize 2D and 3D deep neural networks. The 2D networks take image slices as input to produce coarse segmentation in less processing time, whereas the 3D networks take the whole image volumes to generated fine-detailed segmentation with more computational burden. In order to obtain accurate fine-grained segmentation efficiently, in this paper, we propose an end-to-end Feature-Fused Context-Encoding Network for brain structure segmentation from MR (magnetic resonance) images. Our model is implemented based on a 2D convolutional backbone, which integrates a 2D encoding module to acquire planar image features and a spatial encoding module to extract spatial context information. A global context encoding module is further introduced to capture global context semantics from the fused 2D encoding and spatial features. The proposed network aims to fully leverage the global anatomical prior knowledge learned from context semantics, which is represented by a structure-aware attention factor to recalibrate the outputs of the network. In this way, the network is guaranteed to be aware of the class-dependent feature maps to facilitate the segmentation. We evaluate our model on 2012 Brain Multi-Atlas Labelling Challenge dataset for 134 fine-grained structure segmentation. Besides, we validate our network on 27 coarse structure segmentation tasks. Experimental results have demonstrated that our model can achieve improved performance compared with the state-of-the-art approaches.
SGAS: Sequential Greedy Architecture Search
Nov 30, 2019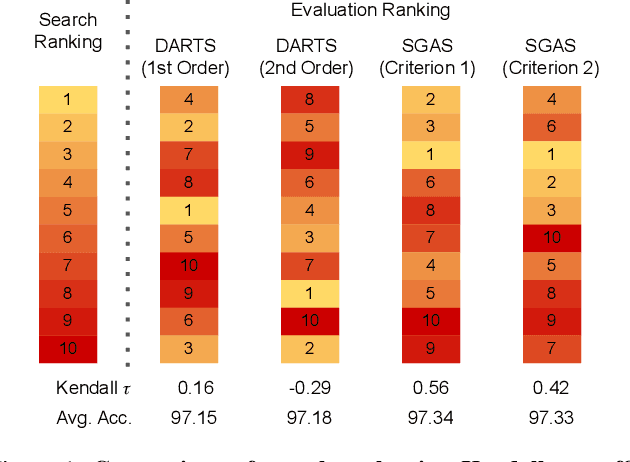
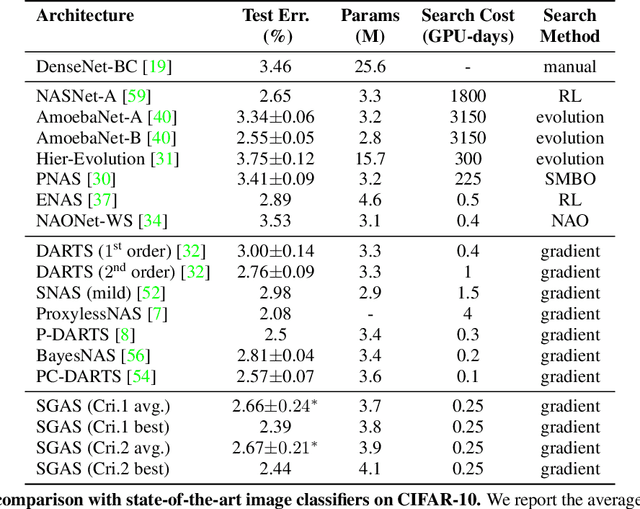
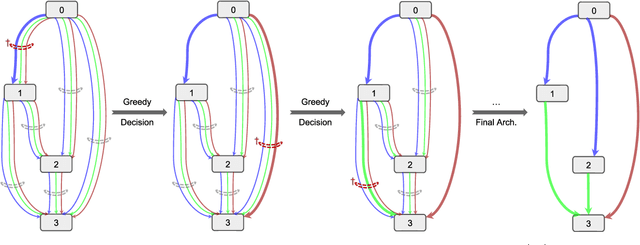
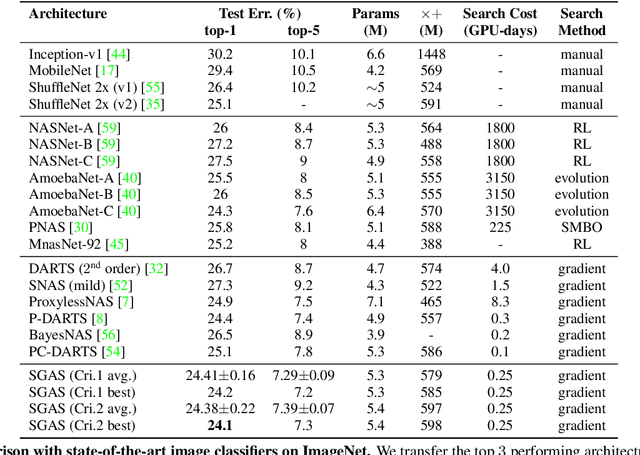
Architecture design has become a crucial component of successful deep learning. Recent progress in automatic neural architecture search (NAS) shows a lot of promise. However, discovered architectures often fail to generalize in the final evaluation. Architectures with a higher validation accuracy during the search phase may perform worse in the evaluation. Aiming to alleviate this common issue, we introduce sequential greedy architecture search (SGAS), an efficient method for neural architecture search. By dividing the search procedure into sub-problems, SGAS chooses and prunes candidate operations in a greedy fashion. We apply SGAS to search architectures for Convolutional Neural Networks (CNN) and Graph Convolutional Networks (GCN). Extensive experiments show that SGAS is able to find state-of-the-art architectures for tasks such as image classification, point cloud classification and node classification in protein-protein interaction graphs with minimal computational cost. Please visit https://sites.google.com/kaust.edu.sa/sgas for more information about SGAS.
A deep-learning based Bayesian approach to seismic imaging and uncertainty quantification
Jan 15, 2020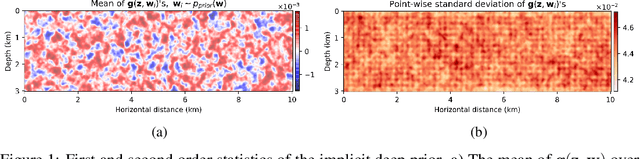
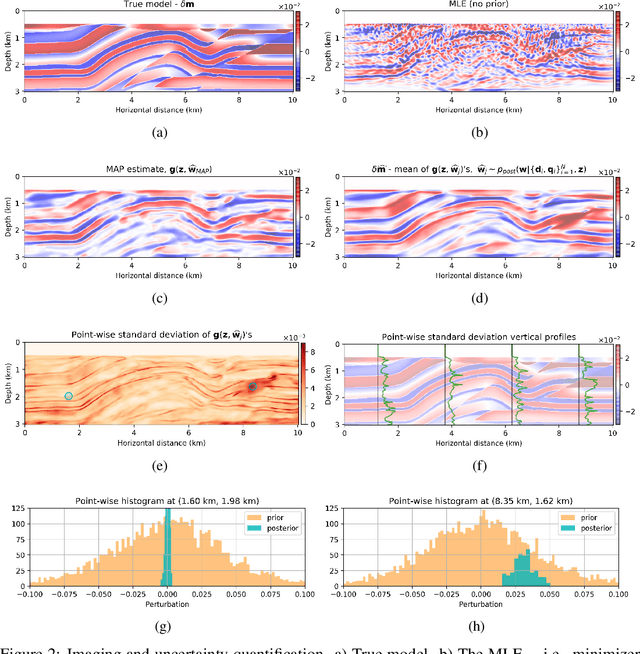
Uncertainty quantification is essential when dealing with ill-conditioned inverse problems due to the inherent nonuniqueness of the solution. Bayesian approaches allow us to determine how likely an estimation of the unknown parameters is via formulating the posterior distribution. Unfortunately, it is often not possible to formulate a prior distribution that precisely encodes our prior knowledge about the unknown. Furthermore, adherence to handcrafted priors may greatly bias the outcome of the Bayesian analysis. To address this issue, we propose to use the functional form of a randomly initialized convolutional neural network as an implicit structured prior, which is shown to promote natural images and excludes images with unnatural noise. In order to incorporate the model uncertainty into the final estimate, we sample the posterior distribution using stochastic gradient Langevin dynamics and perform Bayesian model averaging on the obtained samples. Our synthetic numerical experiment verifies that deep priors combined with Bayesian model averaging are able to partially circumvent imaging artifacts and reduce the risk of overfitting in the presence of extreme noise. Finally, we present pointwise variance of the estimates as a measure of uncertainty, which coincides with regions that are more difficult to image.
On the Benefits of Attributional Robustness
Dec 10, 2019
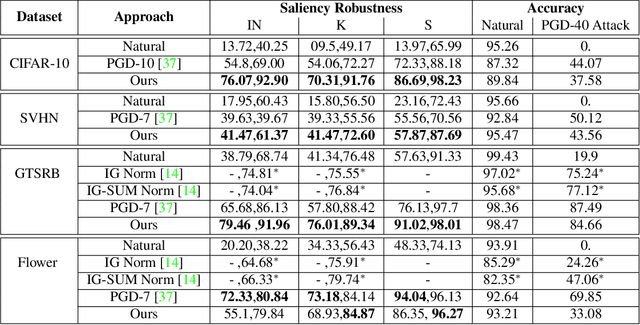
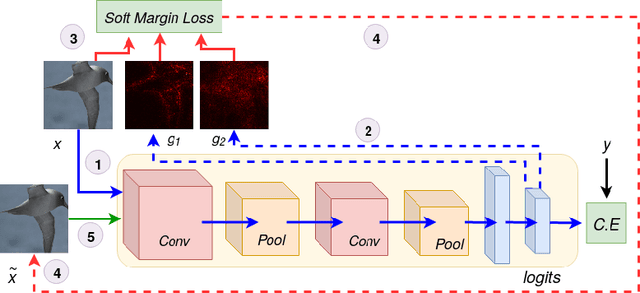
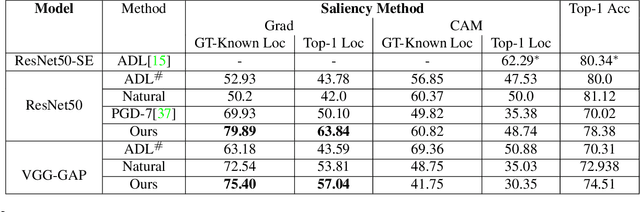
Interpretability is an emerging area of research in trustworthy machine learning. Safe deployment of machine learning system mandates that the prediction and its explanation be reliable and robust. Recently, it was shown that one could craft perturbations that produce perceptually indistinguishable inputs having the same prediction, yet very different interpretations. We tackle the problem of attributional robustness (i.e. models having robust explanations) by maximizing the alignment between the input image and its saliency map using soft-margin triplet loss. We propose a robust attribution training methodology that beats the state-of-the-art attributional robustness measure by a margin of approximately 6-18% on several standard datasets, ie. SVHN, CIFAR-10 and GTSRB. We further show the utility of the proposed robust model in the domain of weakly supervised object localization and segmentation. Our proposed robust model also achieves a new state-of-the-art object localization accuracy on the CUB-200 dataset.
Appending Adversarial Frames for Universal Video Attack
Dec 10, 2019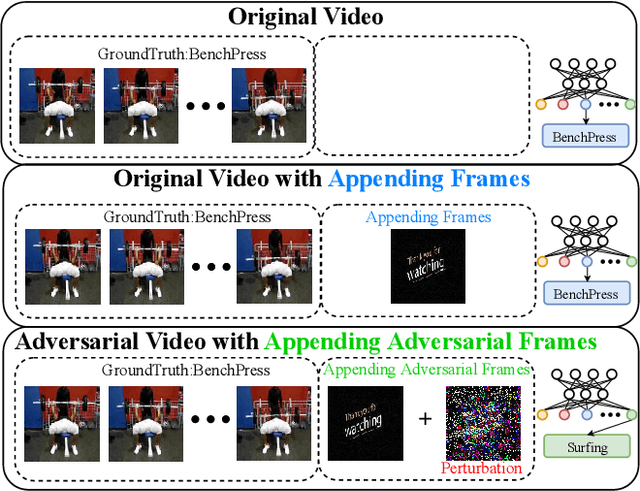
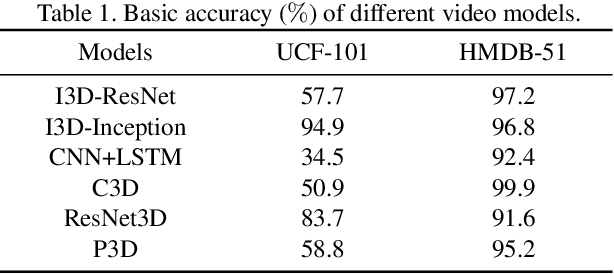
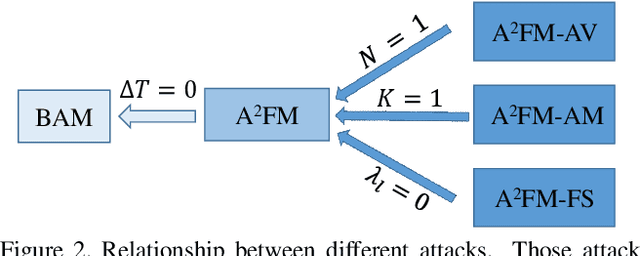
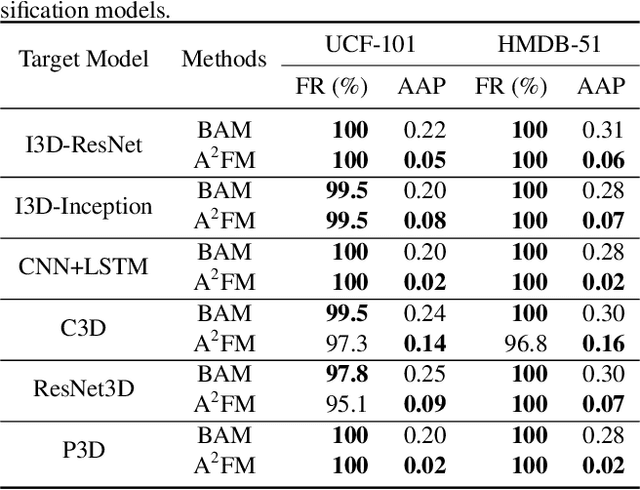
There have been many efforts in attacking image classification models with adversarial perturbations, but the same topic on video classification has not yet been thoroughly studied. This paper presents a novel idea of video-based attack, which appends a few dummy frames (e.g., containing the texts of `thanks for watching') to a video clip and then adds adversarial perturbations only on these new frames. Our approach enjoys three major benefits, namely, a high success rate, a low perceptibility, and a strong ability in transferring across different networks. These benefits mostly come from the common dummy frame which pushes all samples towards the boundary of classification. On the other hand, such attacks are easily to be concealed since most people would not notice the abnormality behind the perturbed video clips. We perform experiments on two popular datasets with six state-of-the-art video classification models, and demonstrate the effectiveness of our approach in the scenario of universal video attacks.
Evolution Attack On Neural Networks
Jun 21, 2019
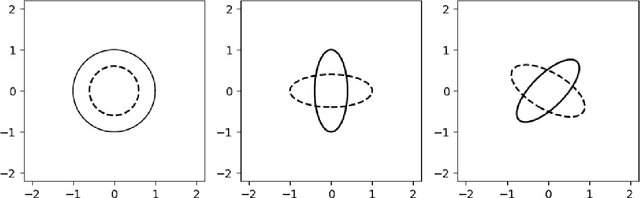
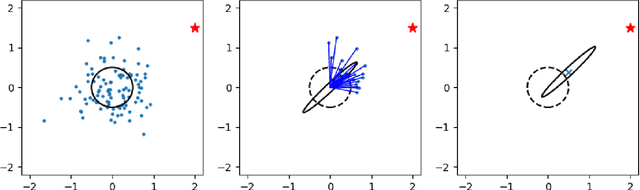
Many studies have been done to prove the vulnerability of neural networks to adversarial example. A trained and well-behaved model can be fooled by a visually imperceptible perturbation, i.e., an originally correctly classified image could be misclassified after a slight perturbation. In this paper, we propose a black-box strategy to attack such networks using an evolution algorithm. First, we formalize the generation of an adversarial example into the optimization problem of perturbations that represent the noise added to an original image at each pixel. To solve this optimization problem in a black-box way, we find that an evolution algorithm perfectly meets our requirement since it can work without any gradient information. Therefore, we test various evolution algorithms, including a simple genetic algorithm, a parameter-exploring policy gradient, an OpenAI evolution strategy, and a covariance matrix adaptive evolution strategy. Experimental results show that a covariance matrix adaptive evolution Strategy performs best in this optimization problem. Additionally, we also perform several experiments to explore the effect of different regularizations on improving the quality of an adversarial example.
Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
Apr 03, 2019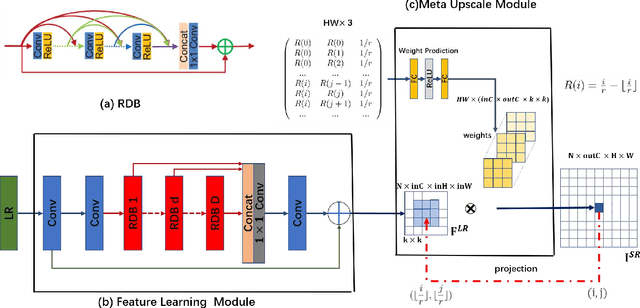
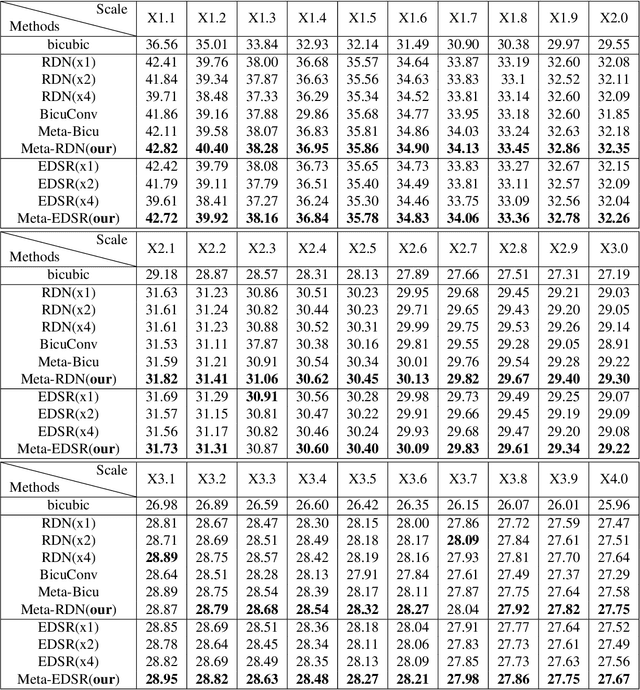
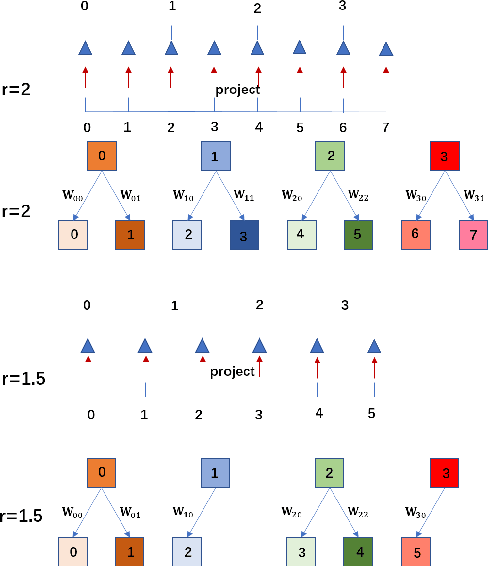
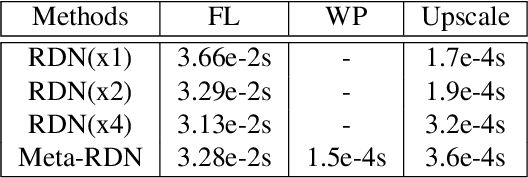
Recent research on super-resolution has achieved great success due to the development of deep convolutional neural networks (DCNNs). However, super-resolution of arbitrary scale factor has been ignored for a long time. Most previous researchers regard super-resolution of different scale factors as independent tasks. They train a specific model for each scale factor which is inefficient in computing, and prior work only take the super-resolution of several integer scale factors into consideration. In this work, we propose a novel method called Meta-SR to firstly solve super-resolution of arbitrary scale factor (including non-integer scale factors) with a single model. In our Meta-SR, the Meta-Upscale Module is proposed to replace the traditional upscale module. For arbitrary scale factor, the Meta-Upscale Module dynamically predicts the weights of the upscale filters by taking the scale factor as input and use these weights to generate the HR image of arbitrary size. For any low-resolution image, our Meta-SR can continuously zoom in it with arbitrary scale factor by only using a single model. We evaluated the proposed method through extensive experiments on widely used benchmark datasets on single image super-resolution. The experimental results show the superiority of our Meta-Upscale.
Dense Dilated Convolutions Merging Network for Land Cover Classification
Mar 09, 2020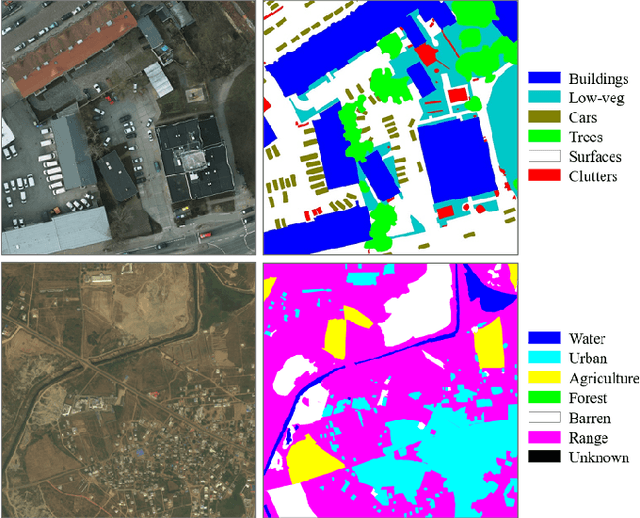
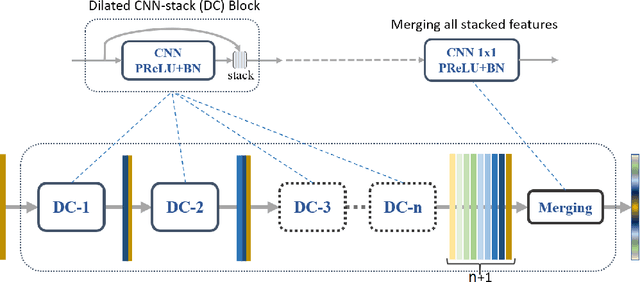
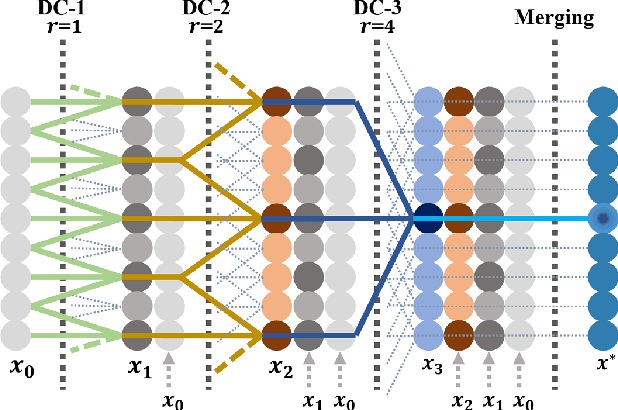
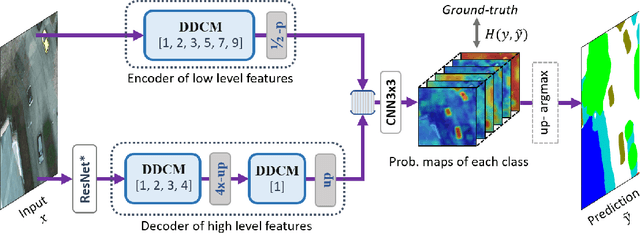
Land cover classification of remote sensing images is a challenging task due to limited amounts of annotated data, highly imbalanced classes, frequent incorrect pixel-level annotations, and an inherent complexity in the semantic segmentation task. In this article, we propose a novel architecture called the dense dilated convolutions' merging network (DDCM-Net) to address this task. The proposed DDCM-Net consists of dense dilated image convolutions merged with varying dilation rates. This effectively utilizes rich combinations of dilated convolutions that enlarge the network's receptive fields with fewer parameters and features compared with the state-of-the-art approaches in the remote sensing domain. Importantly, DDCM-Net obtains fused local- and global-context information, in effect incorporating surrounding discriminative capability for multiscale and complex-shaped objects with similar color and textures in very high-resolution aerial imagery. We demonstrate the effectiveness, robustness, and flexibility of the proposed DDCM-Net on the publicly available ISPRS Potsdam and Vaihingen data sets, as well as the DeepGlobe land cover data set. Our single model, trained on three-band Potsdam and Vaihingen data sets, achieves better accuracy in terms of both mean intersection over union (mIoU) and F1-score compared with other published models trained with more than three-band data. We further validate our model on the DeepGlobe data set, achieving state-of-the-art result 56.2% mIoU with much fewer parameters and at a lower computational cost compared with related recent work. Code available at https://github.com/samleoqh/DDCM-Semantic-Segmentation-PyTorch