 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating Adversarial Perturbation with Root Mean Square Gradient
Jan 26, 2019

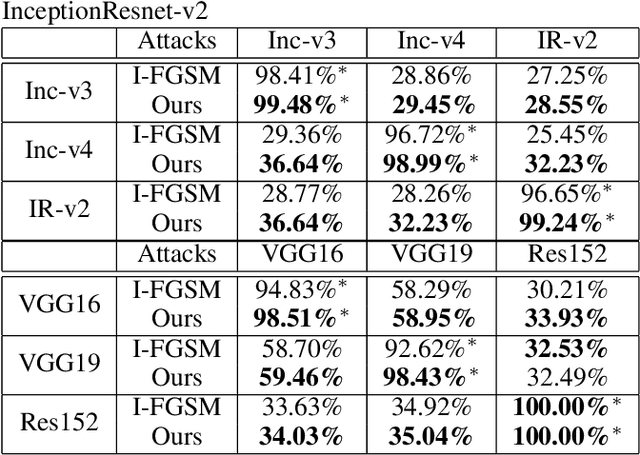
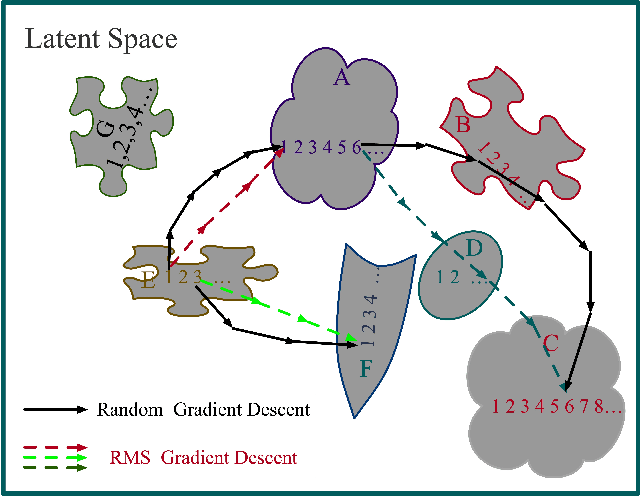
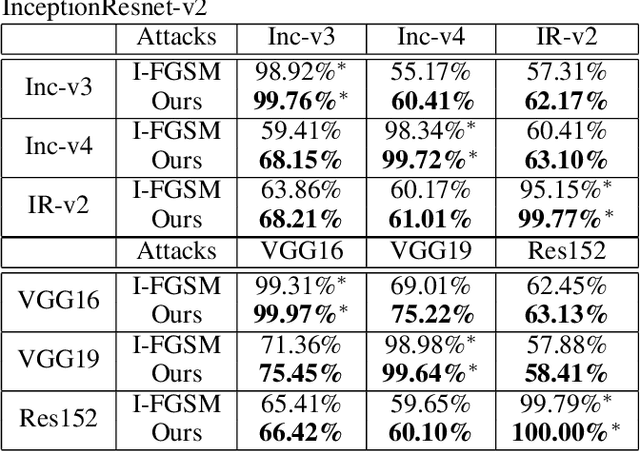
Deep Neural Models are vulnerable to adversarial perturbations in classification. Many attack methods generate adversarial examples with large pixel modification and low cosine similarity with original images. In this paper, we propose an adversarial method generating perturbations based on root mean square gradient which formulates adversarial perturbation size in root mean square level and update gradient in direction, due to updating gradients with adaptive and root mean square stride, our method map origin, and corresponding adversarial image directly which shows good transferability in adversarial examples generation. We evaluate several traditional perturbations creating ways in image classification with our methods. Experimental results show that our approach works well and outperform recent techniques in the change of misclassifying image classification with slight pixel modification, and excellent efficiency in fooling deep network models.
Towards automated mobile-phone-based plant pathology management
Dec 20, 2019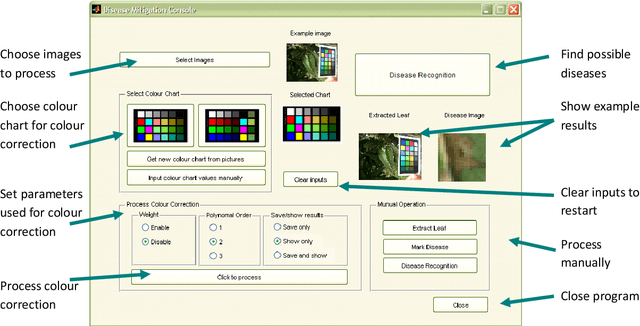


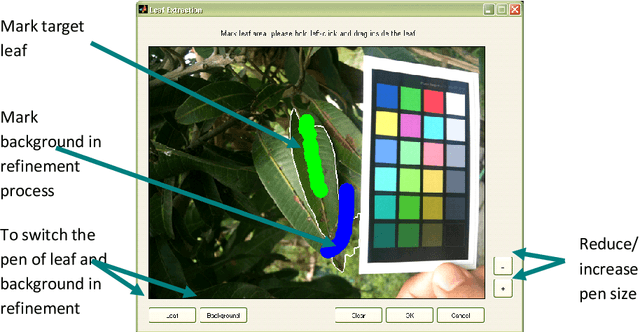
This paper presents a framework which uses computer vision algorithms to standardise images and analyse them for identifying crop diseases automatically. The tools are created to bridge the information gap between farmers, advisory call centres and agricultural experts using the images of diseased/infected crop captured by mobile-phones. These images are generally sensitive to a number of factors including camera type and lighting. We therefore propose a technique for standardising the colour of plant images within the context of the advisory system. Subsequently, to aid the advisory process, the disease recognition process is automated using image processing in conjunction with machine learning techniques. We describe our proposed leaf extraction, affected area segmentation and disease classification techniques. The proposed disease recognition system is tested using six mango diseases and the results show over 80% accuracy. The final output of our system is a list of possible diseases with relevant management advice.
Constrained Nonnegative Matrix Factorization for Blind Hyperspectral Unmixing incorporating Endmember Independence
Mar 16, 2020
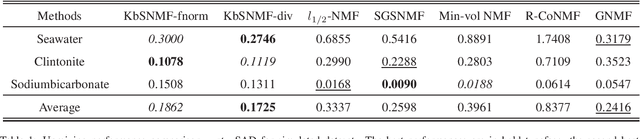
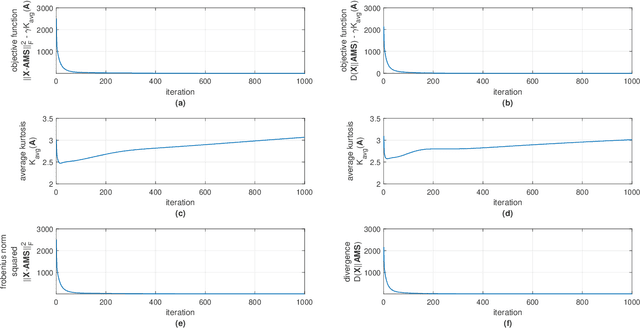
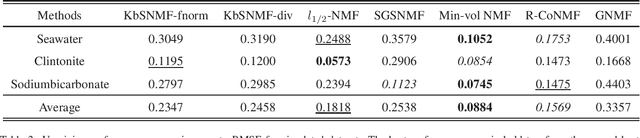
Hyperspectral image (HSI) analysis has become a key area in the field of remote sensing as a result of its ability to exploit richer information in the form of multiple spectral bands. The study of hyperspectral unmixing (HU) is important in HSI analysis due to the insufficient spatial resolution of customary imaging spectrometers. The endmembers of an HSI are more likely to be generated by independent sources and be mixed in a macroscopic degree before arriving at the sensor element of the imaging spectrometer as mixed spectra. Over the past few decades, many attempts have focused on imposing auxiliary constraints on the conventional nonnegative matrix factorization (NMF) framework in order to effectively unmix these mixed spectra. Signifying a step forward toward finding an optimum constraint to extract endmembers, this paper presents a novel blind HU algorithm, referred to as Kurtosis-based Smooth Nonnegative Matrix Factorization (KbSNMF) which incorporates a novel constraint based on the statistical independence of the probability density functions of endmember spectra. Imposing this constraint on the conventional NMF framework promotes the extraction of independent endmembers while further enhancing the parts-based representation of data. The proposed algorithm manages to outperform several state of the art NMF-based algorithms in terms of extracting endmember spectra from hyperspectral remote sensing data; therefore, it could uplift the performance of recent deep learning HU methods which utilizes the endmember spectra as supervisory input data for abundance extraction. We release all code utilized to implement KbSNMF.
Metric Pose Estimation for Human-Machine Interaction Using Monocular Vision
Oct 08, 2019
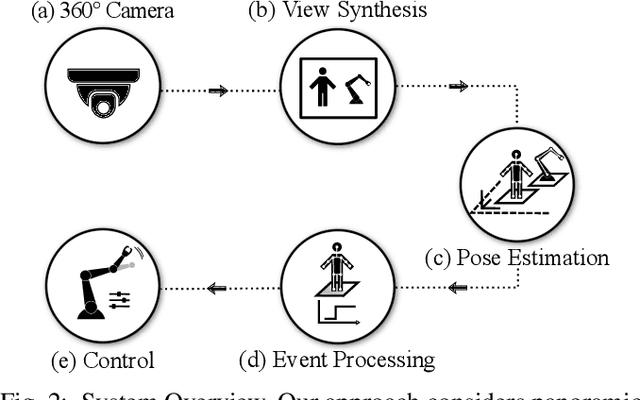
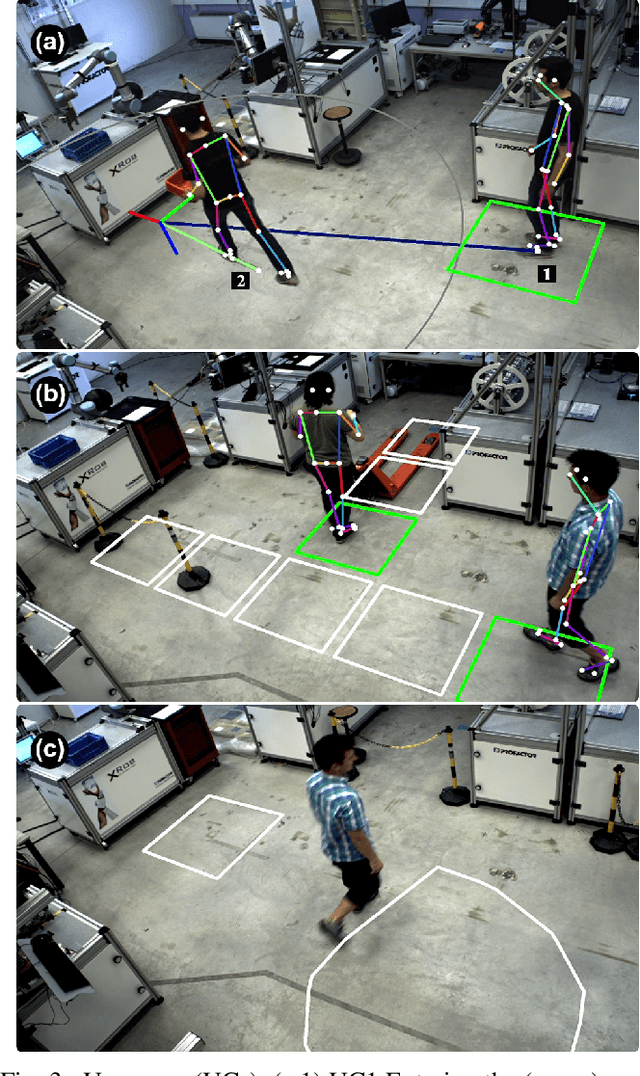
The rapid growth of collaborative robotics in production requires new automation technologies that take human and machine equally into account. In this work, we describe a monocular camera based system to detect human-machine interactions from a bird's-eye perspective. Our system predicts poses of humans and robots from a single wide-angle color image. Even though our approach works on 2D color input, we lift the majority of detections to a metric 3D space. Our system merges pose information with predefined virtual sensors to coordinate human-machine interactions. We demonstrate the advantages of our system in three use cases.
State of the Art on Neural Rendering
Apr 08, 2020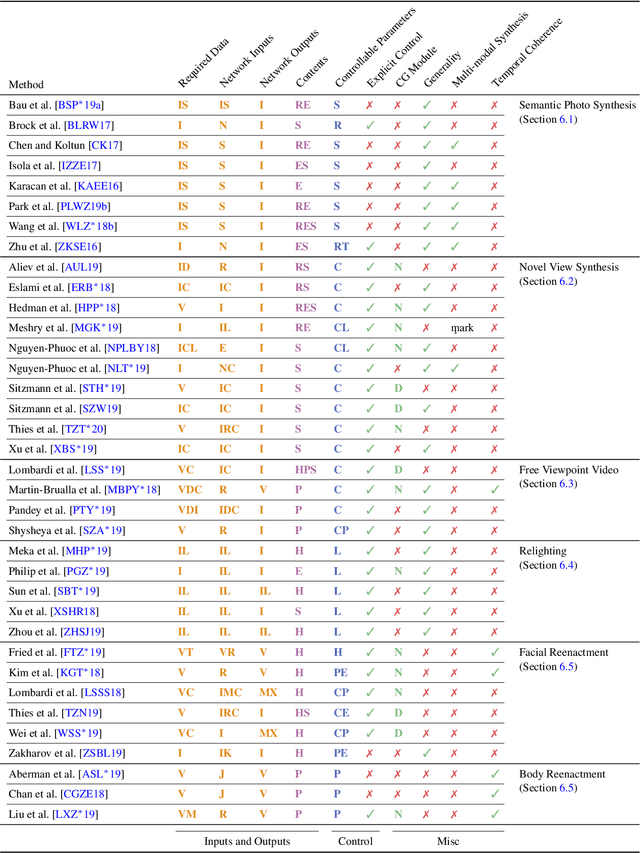



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Learning-based real-time method to looking through scattering medium beyond the memory effect
Nov 04, 2019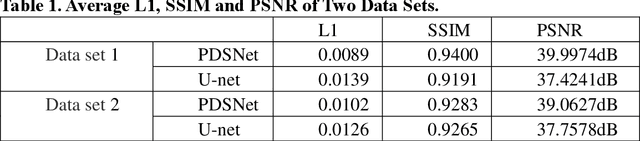


Strong scattering medium brings great difficulties to optical imaging, which is also a problem in medical imaging and many other fields. Optical memory effect makes it possible to image through strong random scattering medium. However, this method also has the limitation of limited angle field-of-view (FOV), which prevents it from being applied in practice. In this paper, a kind of practical convolutional neural network called PDSNet is proposed, which effectively breaks through the limitation of optical memory effect on FOV. Experiments is conducted to prove that the scattered pattern can be reconstructed accurately in real-time by PDSNet, and it is widely applicable to retrieve complex objects of random scales and different scattering media.
Deep multi-class learning from label proportions
May 30, 2019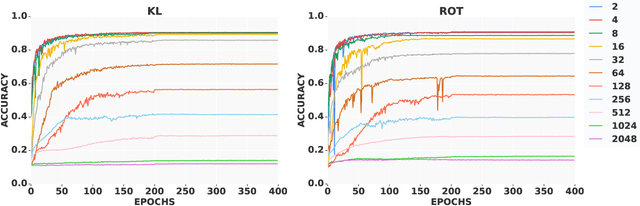
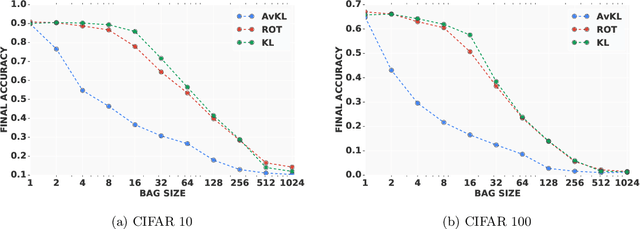
We propose a learning algorithm capable of learning from label proportions instead of direct data labels. In this scenario, our data are arranged into various bags of a certain size, and only the proportions of each label within a given bag are known. This is a common situation in cases where per-data labeling is lengthy, but a more general label is easily accessible. Several approaches have been proposed to learn in this setting with linear models in the multiclass setting, or with nonlinear models in the binary classification setting. Here we investigate the more general nonlinear multiclass setting, and compare two differentiable loss functions to train end-to-end deep neural networks from bags with label proportions. We illustrate the relevance of our methods on an image classification benchmark, and demonstrate the possibility to learn accurate image classifiers from bags of images.
SLOAM: Semantic Lidar Odometry and Mapping for Forest Inventory
Dec 29, 2019

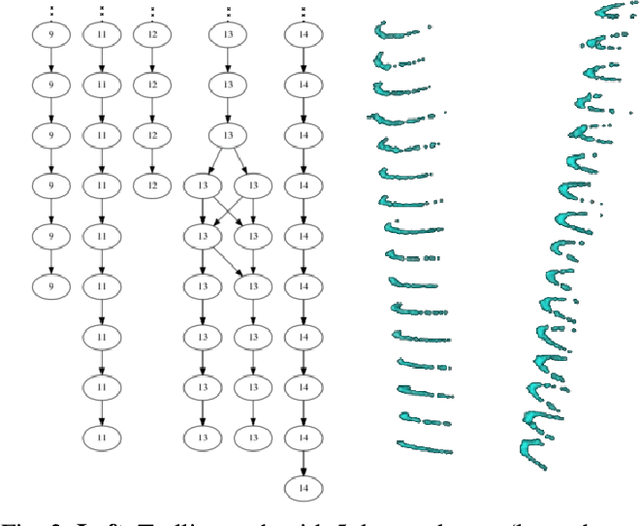
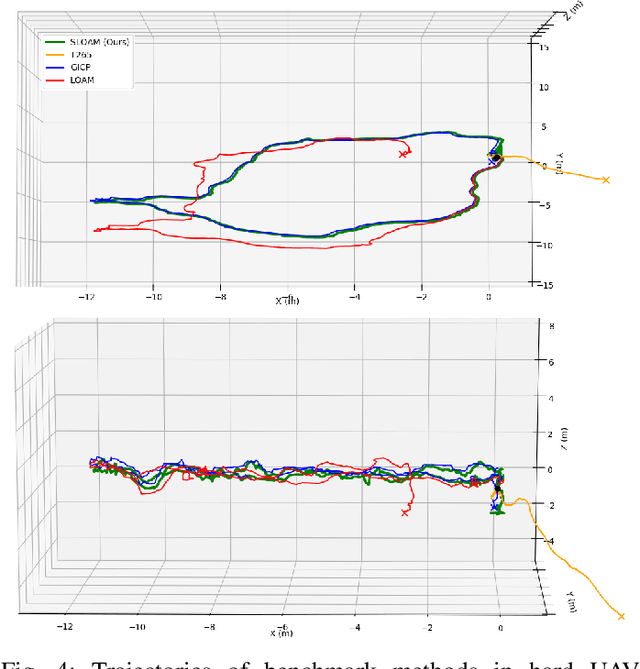
This paper describes an end-to-end pipeline for tree diameter estimation based on semantic segmentation and lidar odometry and mapping. Accurate mapping of this type of environment is challenging since the ground and the trees are surrounded by leaves, thorns and vines, and the sensor typically experiences extreme motion. We propose a semantic feature based pose optimization that simultaneously refines the tree models while estimating the robot pose. The pipeline utilizes a custom virtual reality tool for labeling 3D scans that is used to train a semantic segmentation network. The masked point cloud is used to compute a trellis graph that identifies individual instances and extracts relevant features that are used by the SLAM module. We show that traditional lidar and image based methods fail in the forest environment on both Unmanned Aerial Vehicle (UAV) and hand-carry systems, while our method is more robust, scalable, and automatically generates tree diameter estimations.
Towards High Performance Human Keypoint Detection
Feb 03, 2020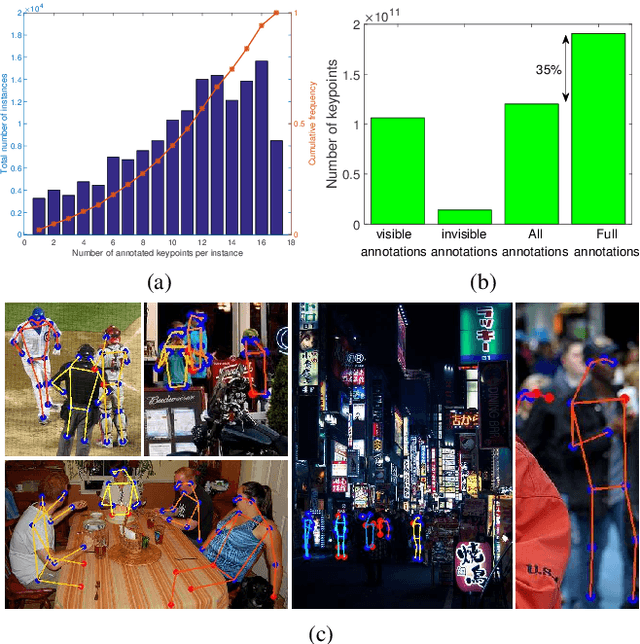
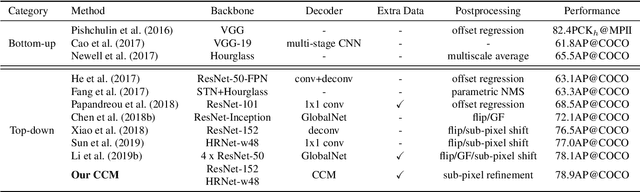

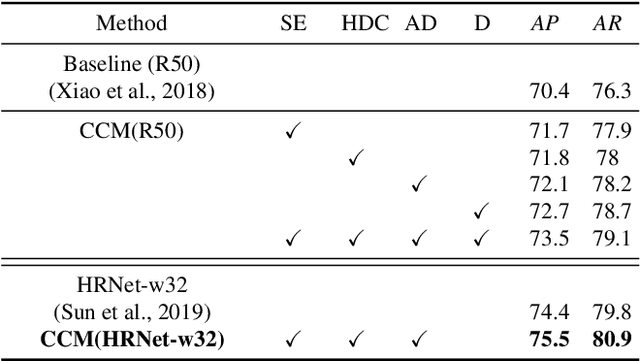
Human keypoint detection from a single image is very challenging due to occlusion, blur, illumination and scale variance. In this paper, we address this problem from three aspects by devising an efficient network structure, proposing three effective training strategies, and exploiting four useful postprocessing techniques. First, we find that context information plays an important role in reasoning human body configuration and invisible keypoints. Inspired by this, we propose a cascaded context mixer (CCM), which efficiently integrates spatial and channel context information and progressively refines them. Then, to maximize CCM's representation capability, we develop a hard-negative person detection mining strategy and a joint-training strategy by exploiting abundant unlabeled data. It enables CCM to learn discriminative features from massive diverse poses. Third, we present several sub-pixel refinement techniques for postprocessing keypoint predictions to improve detection accuracy. Extensive experiments on the MS COCO keypoint detection benchmark demonstrate the superiority of the proposed method over representative state-of-the-art (SOTA) methods. Our single model achieves comparable performance with the winner of the 2018 COCO Keypoint Detection Challenge. The final ensemble model sets a new SOTA on this benchmark.
A Trainable Multiplication Layer for Auto-correlation and Co-occurrence Extraction
May 30, 2019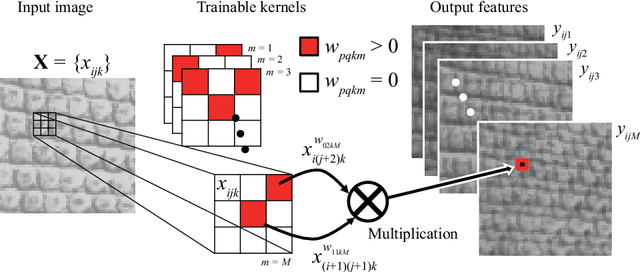

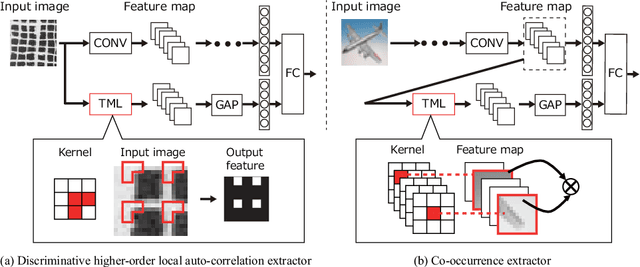

In this paper, we propose a trainable multiplication layer (TML) for a neural network that can be used to calculate the multiplication between the input features. Taking an image as an input, the TML raises each pixel value to the power of a weight and then multiplies them, thereby extracting the higher-order local auto-correlation from the input image. The TML can also be used to extract co-occurrence from the feature map of a convolutional network. The training of the TML is formulated based on backpropagation with constraints to the weights, enabling us to learn discriminative multiplication patterns in an end-to-end manner. In the experiments, the characteristics of the TML are investigated by visualizing learned kernels and the corresponding output features. The applicability of the TML for classification and neural network interpretation is also evaluated using public datasets.