 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Evaluation of GPT-4V and Gemini in Online VQA
Dec 17, 2023
A comprehensive evaluation is critical to assess the capabilities of large multimodal models (LMM). In this study, we evaluate the state-of-the-art LMMs, namely GPT-4V and Gemini, utilizing the VQAonline dataset. VQAonline is an end-to-end authentic VQA dataset sourced from a diverse range of everyday users. Compared previous benchmarks, VQAonline well aligns with real-world tasks. It enables us to effectively evaluate the generality of an LMM, and facilitates a direct comparison with human performance. To comprehensively evaluate GPT-4V and Gemini, we generate seven types of metadata for around 2,000 visual questions, such as image type and the required image processing capabilities. Leveraging this array of metadata, we analyze the zero-shot performance of GPT-4V and Gemini, and identify the most challenging questions for both models.
A Survey of Classical And Quantum Sequence Models
Dec 15, 2023Our primary objective is to conduct a brief survey of various classical and quantum neural net sequence models, which includes self-attention and recurrent neural networks, with a focus on recent quantum approaches proposed to work with near-term quantum devices, while exploring some basic enhancements for these quantum models. We re-implement a key representative set of these existing methods, adapting an image classification approach using quantum self-attention to create a quantum hybrid transformer that works for text and image classification, and applying quantum self-attention and quantum recurrent neural networks to natural language processing tasks. We also explore different encoding techniques and introduce positional encoding into quantum self-attention neural networks leading to improved accuracy and faster convergence in text and image classification experiments. This paper also performs a comparative analysis of classical self-attention models and their quantum counterparts, helping shed light on the differences in these models and their performance.
Q-Boost: On Visual Quality Assessment Ability of Low-level Multi-Modality Foundation Models
Dec 23, 2023Recent advancements in Multi-modality Large Language Models (MLLMs) have demonstrated remarkable capabilities in complex high-level vision tasks. However, the exploration of MLLM potential in visual quality assessment, a vital aspect of low-level vision, remains limited. To address this gap, we introduce Q-Boost, a novel strategy designed to enhance low-level MLLMs in image quality assessment (IQA) and video quality assessment (VQA) tasks, which is structured around two pivotal components: 1) Triadic-Tone Integration: Ordinary prompt design simply oscillates between the binary extremes of $positive$ and $negative$. Q-Boost innovates by incorporating a `middle ground' approach through $neutral$ prompts, allowing for a more balanced and detailed assessment. 2) Multi-Prompt Ensemble: Multiple quality-centric prompts are used to mitigate bias and acquire more accurate evaluation. The experimental results show that the low-level MLLMs exhibit outstanding zeros-shot performance on the IQA/VQA tasks equipped with the Q-Boost strategy.
Enhanced Breast Cancer Tumor Classification using MobileNetV2: A Detailed Exploration on Image Intensity, Error Mitigation, and Streamlit-driven Real-time Deployment
Dec 05, 2023This research introduces a sophisticated transfer learning model based on Google's MobileNetV2 for breast cancer tumor classification into normal, benign, and malignant categories, utilizing a dataset of 1576 ultrasound images (265 normal, 891 benign, 420 malignant). The model achieves an accuracy of 0.82, precision of 0.83, recall of 0.81, ROC-AUC of 0.94, PR-AUC of 0.88, and MCC of 0.74. It examines image intensity distributions and misclassification errors, offering improvements for future applications. Addressing dataset imbalances, the study ensures a generalizable model. This work, using a dataset from Baheya Hospital, Cairo, Egypt, compiled by Walid Al-Dhabyani et al., emphasizes MobileNetV2's potential in medical imaging, aiming to improve diagnostic precision in oncology. Additionally, the paper explores Streamlit-based deployment for real-time tumor classification, demonstrating MobileNetV2's applicability in medical imaging and setting a benchmark for future research in oncology diagnostics.
PULASki: Learning inter-rater variability using statistical distances to improve probabilistic segmentation
Dec 25, 2023In the domain of medical imaging, many supervised learning based methods for segmentation face several challenges such as high variability in annotations from multiple experts, paucity of labelled data and class imbalanced datasets. These issues may result in segmentations that lack the requisite precision for clinical analysis and can be misleadingly overconfident without associated uncertainty quantification. We propose the PULASki for biomedical image segmentation that accurately captures variability in expert annotations, even in small datasets. Our approach makes use of an improved loss function based on statistical distances in a conditional variational autoencoder structure (Probabilistic UNet), which improves learning of the conditional decoder compared to the standard cross-entropy particularly in class imbalanced problems. We analyse our method for two structurally different segmentation tasks (intracranial vessel and multiple sclerosis (MS) lesion) and compare our results to four well-established baselines in terms of quantitative metrics and qualitative output. Empirical results demonstrate the PULASKi method outperforms all baselines at the 5\% significance level. The generated segmentations are shown to be much more anatomically plausible than in the 2D case, particularly for the vessel task. Our method can also be applied to a wide range of multi-label segmentation tasks and and is useful for downstream tasks such as hemodynamic modelling (computational fluid dynamics and data assimilation), clinical decision making, and treatment planning.
Generative AI and the History of Architecture
Dec 22, 2023Recent generative AI platforms are able to create texts or impressive images from simple text prompts. This makes them powerful tools for summarizing knowledge about architectural history or deriving new creative work in early design tasks like ideation, sketching and modelling. But, how good is the understanding of the generative AI models of the history of architecture? Has it learned to properly distinguish styles, or is it hallucinating information? In this chapter, we investigate this question for generative AI platforms for text and image generation for different architectural styles, to understand the capabilities and boundaries of knowledge of those tools. We also analyze how they are already being used by analyzing a data set of 101 million Midjourney queries to see if and how practitioners are already querying for specific architectural concepts.
The Rate-Distortion-Perception-Classification Tradeoff: Joint Source Coding and Modulation via Inverse-Domain GANs
Dec 22, 2023The joint source coding and modulation (JSCM) framework was enabled by recent developments in deep learning, which allows to automatically learn from data, and in an end-to-end fashion, the best compression codes and modulation schemes. In this paper, we show the existence of a strict tradeoff between channel rate, distortion, perception, and classification accuracy in a JSCM scenario. We then propose two image compression methods to navigate that tradeoff: an inverse-domain generative adversarial network (ID-GAN), which achieves extreme compression, and a simpler, heuristic method that reveals insights about the performance of ID-GAN. Experiment results not only corroborate the theoretical findings, but also demonstrate that the proposed ID-GAN algorithm significantly improves system performance compared to traditional separation-based methods and recent deep JSCM architectures.
Quality and Quantity: Unveiling a Million High-Quality Images for Text-to-Image Synthesis in Fashion Design
Nov 29, 2023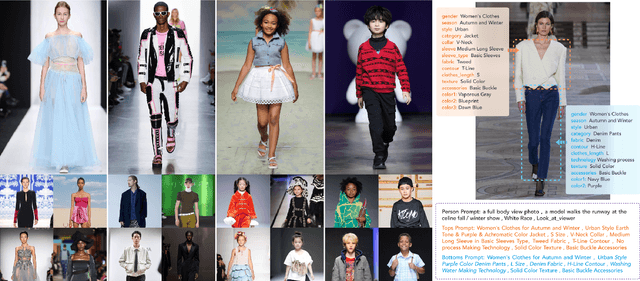
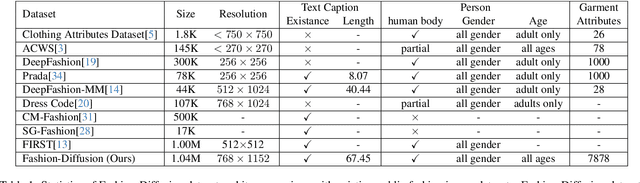
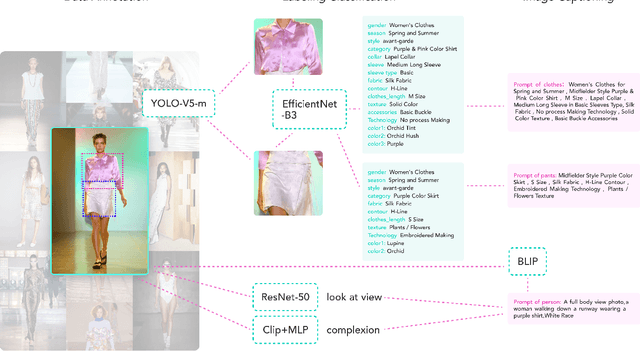
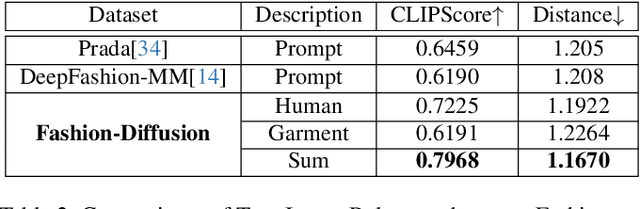
The fusion of AI and fashion design has emerged as a promising research area. However, the lack of extensive, interrelated data on clothing and try-on stages has hindered the full potential of AI in this domain. Addressing this, we present the Fashion-Diffusion dataset, a product of multiple years' rigorous effort. This dataset, the first of its kind, comprises over a million high-quality fashion images, paired with detailed text descriptions. Sourced from a diverse range of geographical locations and cultural backgrounds, the dataset encapsulates global fashion trends. The images have been meticulously annotated with fine-grained attributes related to clothing and humans, simplifying the fashion design process into a Text-to-Image (T2I) task. The Fashion-Diffusion dataset not only provides high-quality text-image pairs and diverse human-garment pairs but also serves as a large-scale resource about humans, thereby facilitating research in T2I generation. Moreover, to foster standardization in the T2I-based fashion design field, we propose a new benchmark comprising multiple datasets for evaluating the performance of fashion design models. This work represents a significant leap forward in the realm of AI-driven fashion design, setting a new standard for future research in this field.
Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Nov 30, 2023Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $\Theta_{imi}$, inter-class matrix consistency as $\Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $\Theta_{imi}$ and $\Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.
Testing the Segment Anything Model on radiology data
Dec 20, 2023Deep learning models trained with large amounts of data have become a recent and effective approach to predictive problem solving -- these have become known as "foundation models" as they can be used as fundamental tools for other applications. While the paramount examples of image classification (earlier) and large language models (more recently) led the way, the Segment Anything Model (SAM) was recently proposed and stands as the first foundation model for image segmentation, trained on over 10 million images and with recourse to over 1 billion masks. However, the question remains -- what are the limits of this foundation? Given that magnetic resonance imaging (MRI) stands as an important method of diagnosis, we sought to understand whether SAM could be used for a few tasks of zero-shot segmentation using MRI data. Particularly, we wanted to know if selecting masks from the pool of SAM predictions could lead to good segmentations. Here, we provide a critical assessment of the performance of SAM on magnetic resonance imaging data. We show that, while acceptable in a very limited set of cases, the overall trend implies that these models are insufficient for MRI segmentation across the whole volume, but can provide good segmentations in a few, specific slices. More importantly, we note that while foundation models trained on natural images are set to become key aspects of predictive modelling, they may prove ineffective when used on other imaging modalities.