 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Sparse Coding for Compressed Sensing CT Reconstruction
Mar 20, 2019
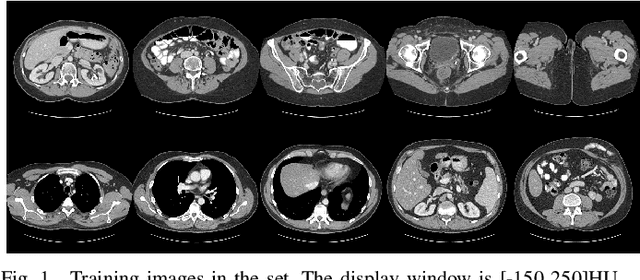
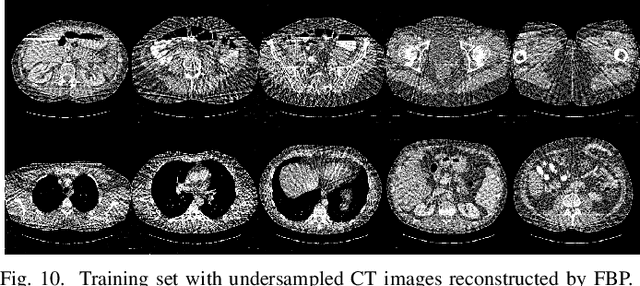


Over the past few years, dictionary learning (DL)-based methods have been successfully used in various image reconstruction problems. However, traditional DL-based computed tomography (CT) reconstruction methods are patch-based and ignore the consistency of pixels in overlapped patches. In addition, the features learned by these methods always contain shifted versions of the same features. In recent years, convolutional sparse coding (CSC) has been developed to address these problems. In this paper, inspired by several successful applications of CSC in the field of signal processing, we explore the potential of CSC in sparse-view CT reconstruction. By directly working on the whole image, without the necessity of dividing the image into overlapped patches in DL-based methods, the proposed methods can maintain more details and avoid artifacts caused by patch aggregation. With predetermined filters, an alternating scheme is developed to optimize the objective function. Extensive experiments with simulated and real CT data were performed to validate the effectiveness of the proposed methods. Qualitative and quantitative results demonstrate that the proposed methods achieve better performance than several existing state-of-the-art methods.
Extra Proximal-Gradient Inspired Non-local Network
Nov 17, 2019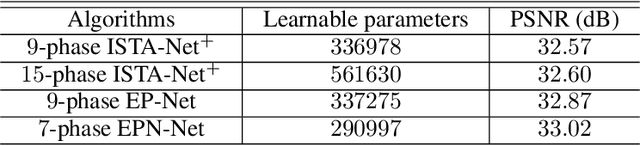

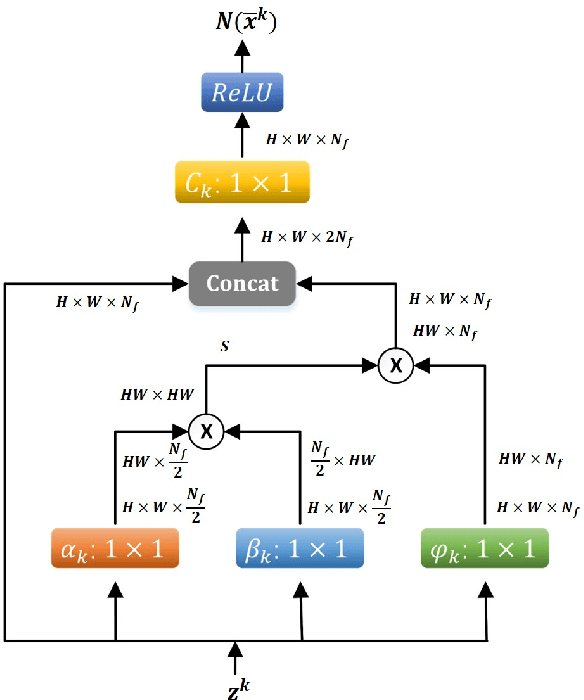
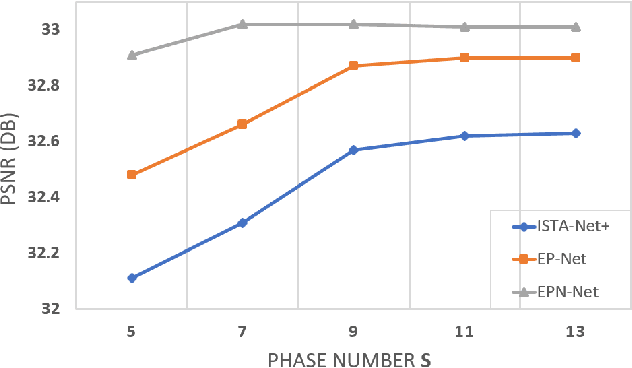
Variational method and deep learning method are two mainstream powerful approaches to solve inverse problems in computer vision. To take advantages of advanced optimization algorithms and powerful representation ability of deep neural networks, we propose a novel deep network for image reconstruction. The architecture of this network is inspired by our proposed accelerated extra proximal gradient algorithm. It is able to incorporate non-local operation to exploit the non-local self-similarity of the images and to learn the nonlinear transform, under which the solution is sparse. All the parameters in our network are learned from minimizing a loss function. Our experimental results show that our network outperforms several state-of-the-art deep networks with almost the same number of learnable parameter.
Knowing When to Stop: Evaluation and Verification of Conformity to Output-size Specifications
Apr 26, 2019
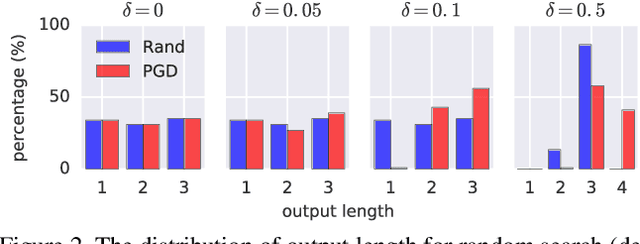
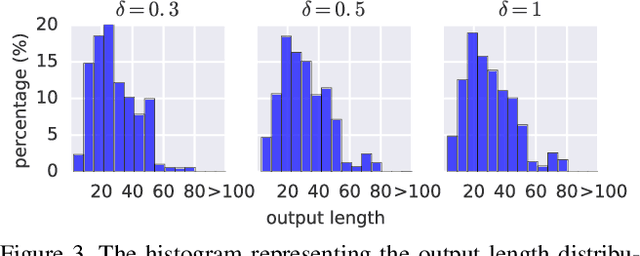
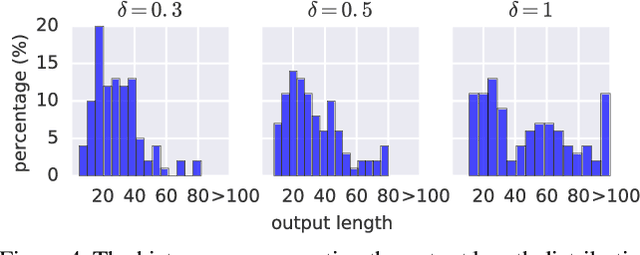
Models such as Sequence-to-Sequence and Image-to-Sequence are widely used in real world applications. While the ability of these neural architectures to produce variable-length outputs makes them extremely effective for problems like Machine Translation and Image Captioning, it also leaves them vulnerable to failures of the form where the model produces outputs of undesirable length. This behavior can have severe consequences such as usage of increased computation and induce faults in downstream modules that expect outputs of a certain length. Motivated by the need to have a better understanding of the failures of these models, this paper proposes and studies the novel output-size modulation problem and makes two key technical contributions. First, to evaluate model robustness, we develop an easy-to-compute differentiable proxy objective that can be used with gradient-based algorithms to find output-lengthening inputs. Second and more importantly, we develop a verification approach that can formally verify whether a network always produces outputs within a certain length. Experimental results on Machine Translation and Image Captioning show that our output-lengthening approach can produce outputs that are 50 times longer than the input, while our verification approach can, given a model and input domain, prove that the output length is below a certain size.
Gray-Level Image Transitions Driven by Tsallis Entropic Index
Feb 19, 2015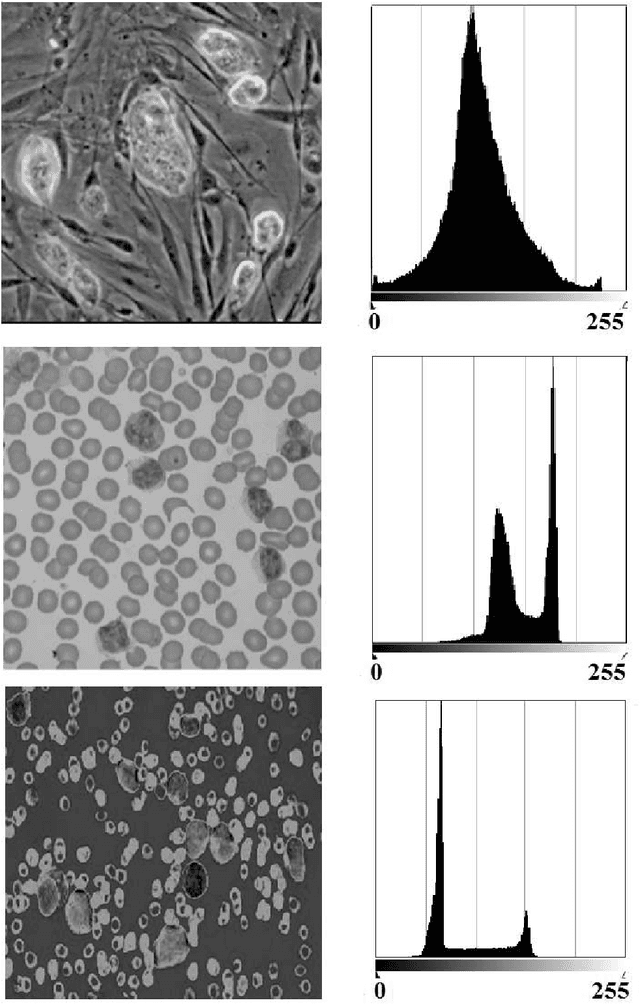
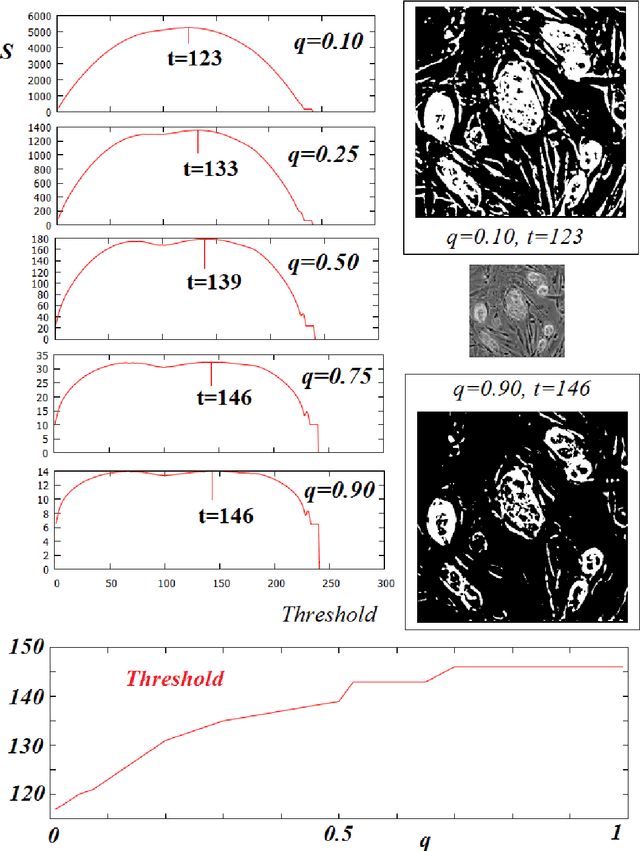
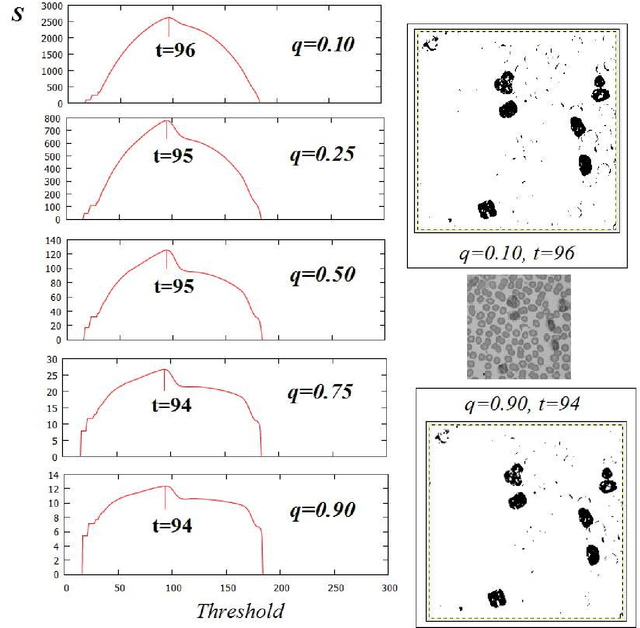
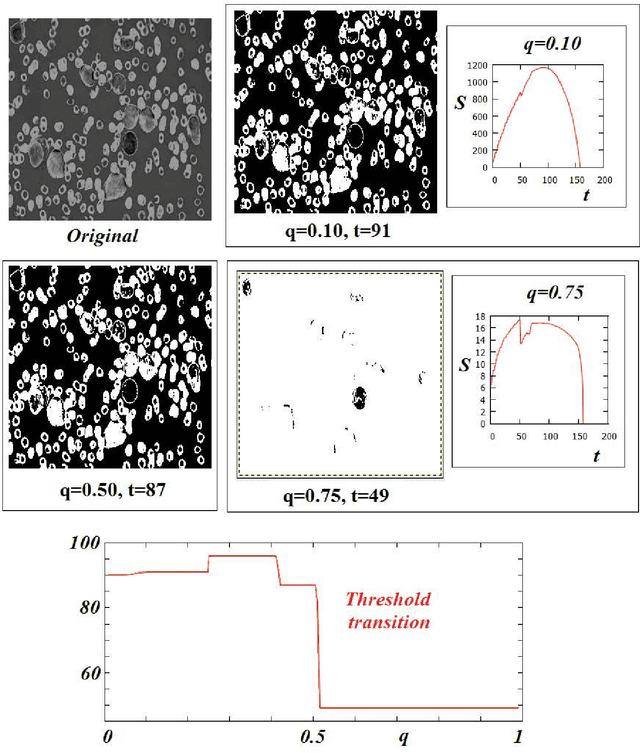
The maximum entropy principle is largely used in thresholding and segmentation of images. Among the several formulations of this principle, the most effectively applied is that based on Tsallis non-extensive entropy. Here, we discuss the role of its entropic index in determining the thresholds. When this index is spanning the interval (0,1), for some images, the values of thresholds can have large leaps. In this manner, we observe abrupt transitions in the appearance of corresponding bi-level or multi-level images. These gray-level image transitions are analogous to order or texture transitions observed in physical systems, transitions which are driven by the temperature or by other physical quantities.
* Tsallis Entropy, Image Processing, Image Segmentation, Image Thresholding, Texture Transitions, Medical Image Processing, Typos emended
Car Pose in Context: Accurate Pose Estimation with Ground Plane Constraints
Dec 09, 2019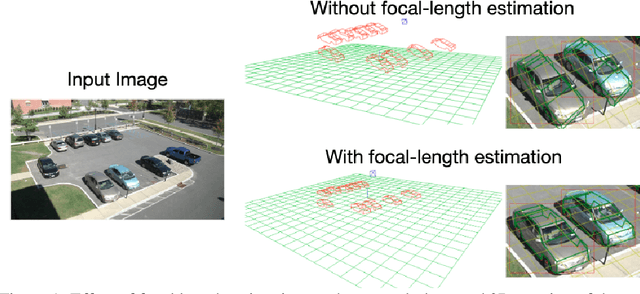
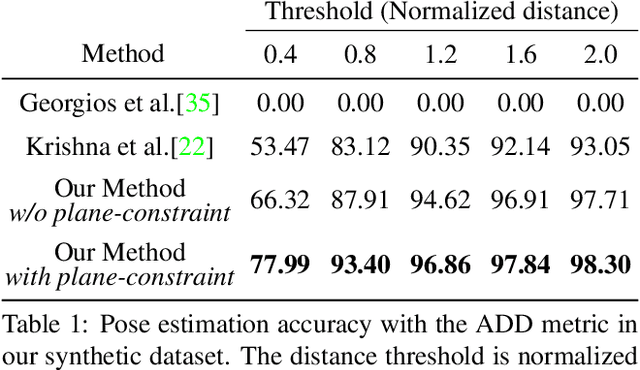
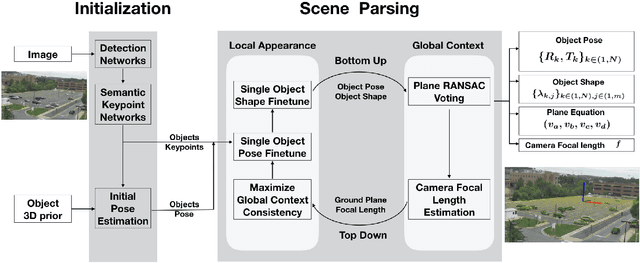
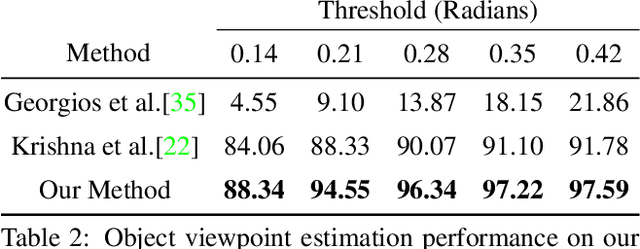
Scene context is a powerful constraint on the geometry of objects within the scene in cases, such as surveillance, where the camera geometry is unknown and image quality may be poor. In this paper, we describe a method for estimating the pose of cars in a scene jointly with the ground plane that supports them. We formulate this as a joint optimization that accounts for varying car shape using a statistical atlas, and which simultaneously computes geometry and internal camera parameters. We demonstrate that this method produces significant improvements for car pose estimation, and we show that the resulting 3D geometry, when computed over a video sequence, makes it possible to improve on state of the art classification of car behavior. We also show that introducing the planar constraint allows us to estimate camera focal length in a reliable manner.
Improving Dataset Distillation
Oct 06, 2019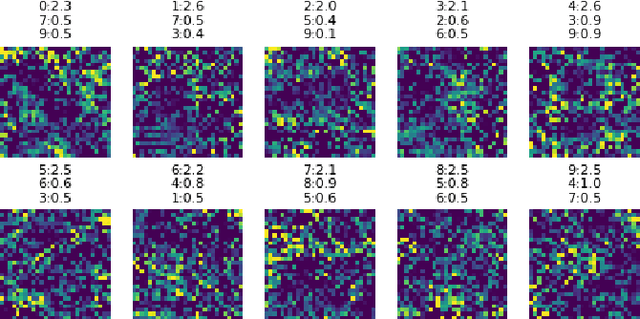

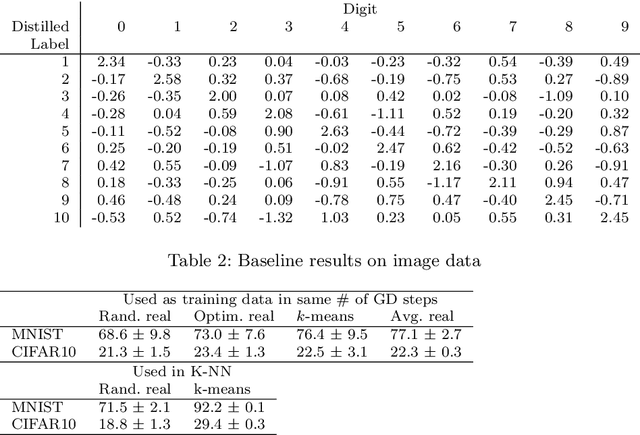
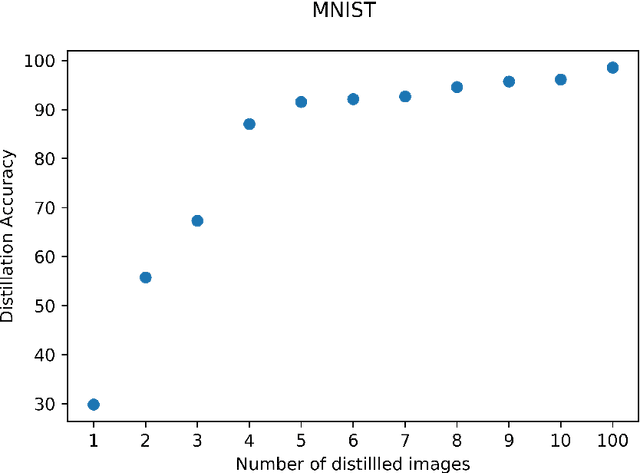
Dataset distillation is a method for reducing dataset sizes: the goal is to learn a small number of synthetic samples containing all the information of a large dataset. This has several benefits: speeding up model training in deep learning, reducing energy consumption, and reducing required storage space. Currently, each synthetic sample is assigned a single `hard' label, which limits the accuracies that models trained on distilled datasets can achieve. Also, currently dataset distillation can only be used with image data. We propose to simultaneously distill both images and their labels, and thus to assign each synthetic sample a `soft' label (a distribution of labels) rather than a single `hard' label. Our improved algorithm increases accuracy by 2-4% over the original dataset distillation algorithm for several image classification tasks. For example, training a LeNet model with just 10 distilled images (one per class) results in over 96% accuracy on the MNIST data. Using `soft' labels also enables distilled datasets to consist of fewer samples than there are classes as each sample can encode information for more than one class. For example, we show that LeNet achieves almost 92% accuracy on MNIST after being trained on just 5 distilled images. We also propose an extension of the dataset distillation algorithm that allows it to distill sequential datasets including texts. We demonstrate that text distillation outperforms other methods across multiple datasets. For example, we are able to train models to almost their original accuracy on the IMDB sentiment analysis task using just 20 distilled sentences.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Mar 16, 2020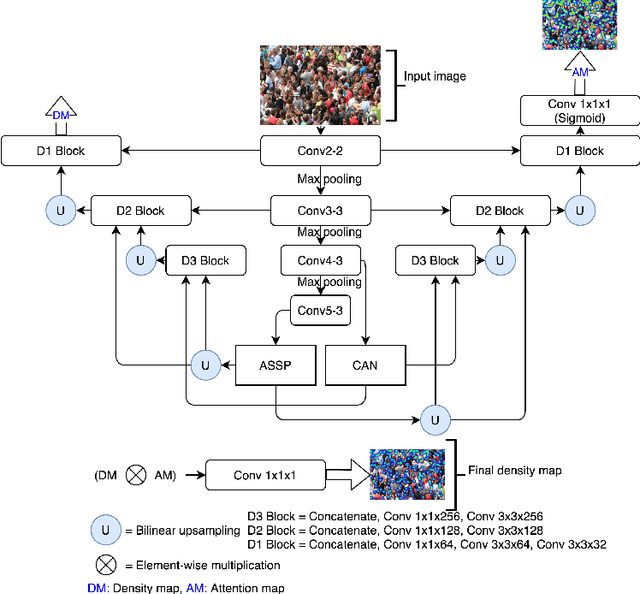
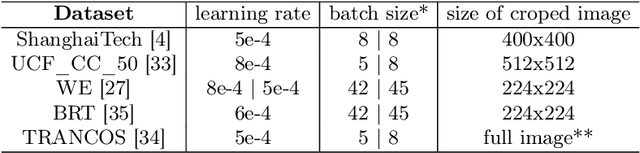
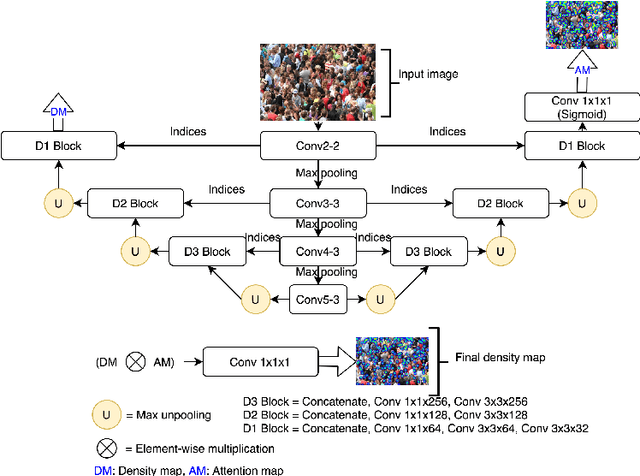
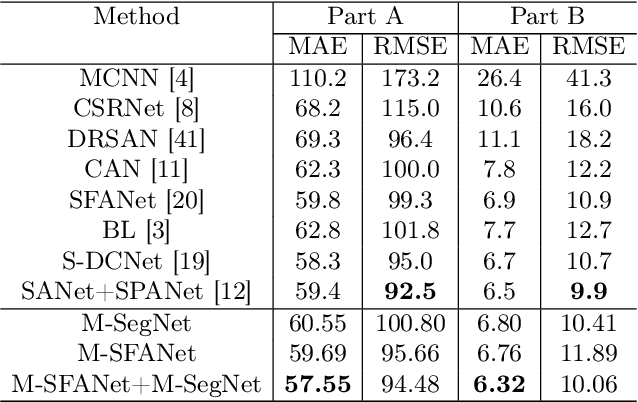
In this paper, we proposed two modified neural network architectures based on SFANet and SegNet respectively for accurate and efficient crowd counting. Inspired by SFANet, the first model is attached with two novel multi-scale-aware modules, called ASSP and CAN. This model is called M-SFANet. The encoder of M-SFANet is enhanced with ASSP containing parallel atrous convolution with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage contextual module called CAN which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet's decoder structure, M-SFANet's decoder has dual paths, for density map generation and attention map generation. The second model is called M-SegNet. For M-SegNet, we simply change bilinear upsampling used in SFANet to max unpooling originally from SegNet and propose the faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and end-to-end trainable. We also conduct extensive experiments on four crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could outperform some state-of-the-art crowd counting methods.
M3D-RPN: Monocular 3D Region Proposal Network for Object Detection
Jul 13, 2019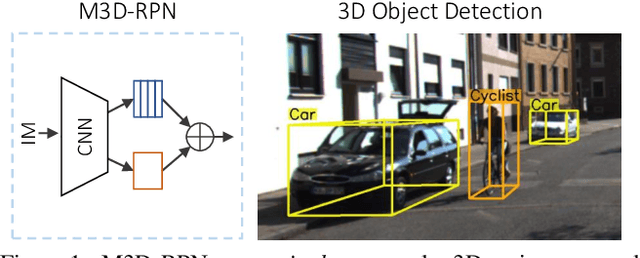

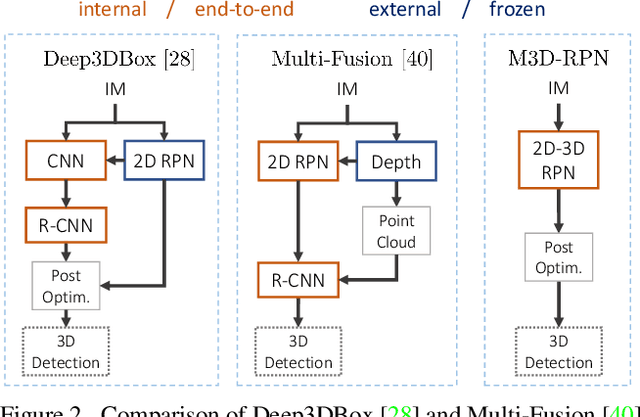

Understanding the world in 3D is a critical component of urban autonomous driving. Generally, the combination of expensive LiDAR sensors and stereo RGB imaging has been paramount for successful 3D object detection algorithms, whereas monocular image-only methods experience drastically reduced performance. We propose to reduce the gap by reformulating the monocular 3D detection problem as a standalone 3D region proposal network. We leverage the geometric relationship of 2D and 3D perspectives, allowing 3D boxes to utilize well-known and powerful convolutional features generated in the image-space. To help address the strenuous 3D parameter estimations, we further design depth-aware convolutional layers which enable location specific feature development and in consequence improved 3D scene understanding. Compared to prior work in monocular 3D detection, our method consists of only the proposed 3D region proposal network rather than relying on external networks, data, or multiple stages. M3D-RPN is able to significantly improve the performance of both monocular 3D Object Detection and Bird's Eye View tasks within the KITTI urban autonomous driving dataset, while efficiently using a shared multi-class model.
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
Mar 28, 2020
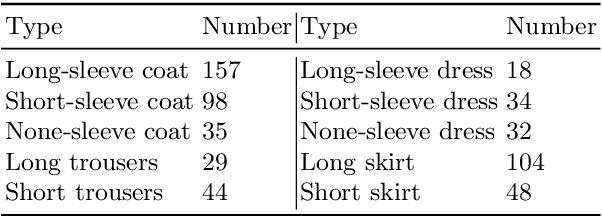

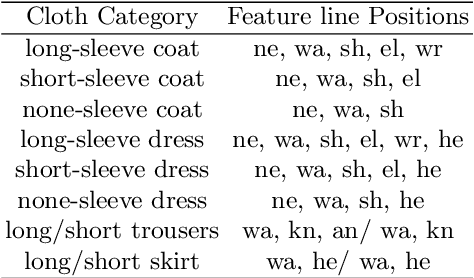
High-fidelity clothing reconstruction is the key to achieving photorealism in a wide range of applications including human digitization, virtual try-on, etc. Recent advances in learning-based approaches have accomplished unprecedented accuracy in recovering unclothed human shape and pose from single images, thanks to the availability of powerful statistical models, e.g. SMPL, learned from a large number of body scans. In contrast, modeling and recovering clothed human and 3D garments remains notoriously difficult, mostly due to the lack of large-scale clothing models available for the research community. We propose to fill this gap by introducing Deep Fashion3D, the largest collection to date of 3D garment models, with the goal of establishing a novel benchmark and dataset for the evaluation of image-based garment reconstruction systems. Deep Fashion3D contains 2078 models reconstructed from real garments, which covers 10 different categories and 563 garment instances. It provides rich annotations including 3D feature lines, 3D body pose and the corresponded multi-view real images. In addition, each garment is randomly posed to enhance the variety of real clothing deformations. To demonstrate the advantage of Deep Fashion3D, we propose a novel baseline approach for single-view garment reconstruction, which leverages the merits of both mesh and implicit representations. A novel adaptable template is proposed to enable the learning of all types of clothing in a single network. Extensive experiments have been conducted on the proposed dataset to verify its significance and usefulness. We will make Deep Fashion3D publicly available upon publication.
An Optical Flow-Based Approach for Minimally-Divergent Velocimetry Data Interpolation
Dec 20, 2018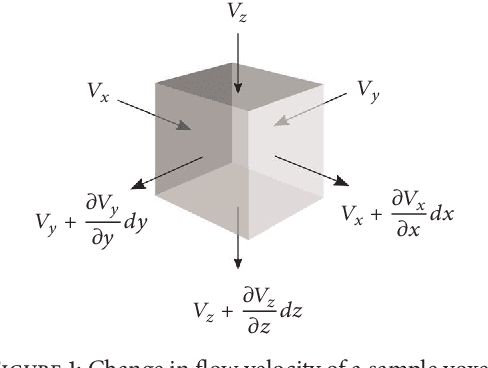
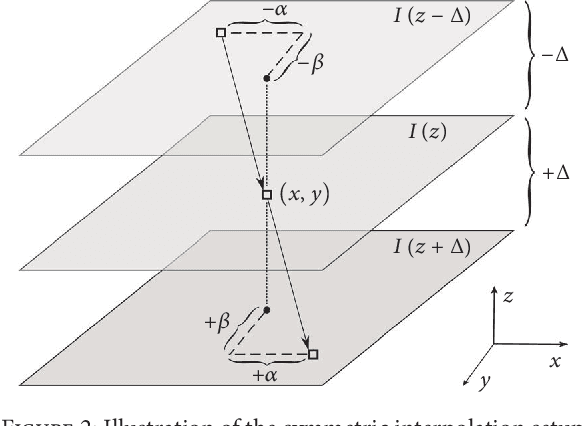
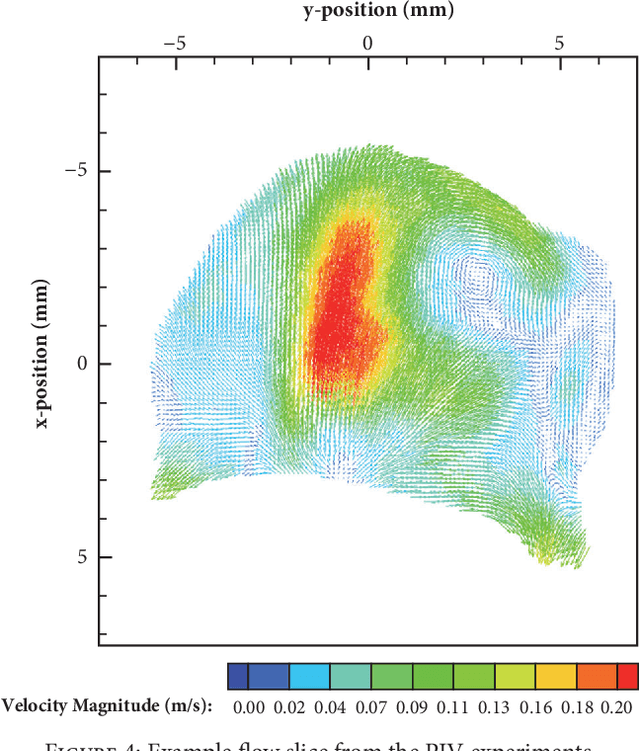
Three-dimensional (3D) biomedical image sets are often acquired with in-plane pixel spacings that are far less than the out-of-plane spacings between images. The resultant anisotropy, which can be detrimental in many applications, can be decreased using image interpolation. Optical flow and/or other registration-based interpolators have proven useful in such interpolation roles in the past. When acquired images are comprised of signals that describe the flow velocity of fluids, additional information is available to guide the interpolation process. In this paper, we present an optical-flow based framework for image interpolation that also minimizes resultant divergence in the interpolated data.