 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Hate Speech Detection in Multimodal Publications
Oct 09, 2019

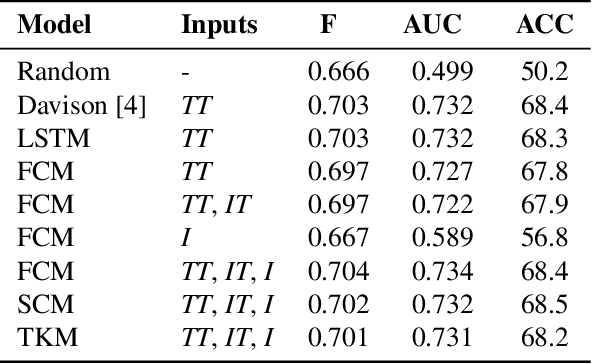
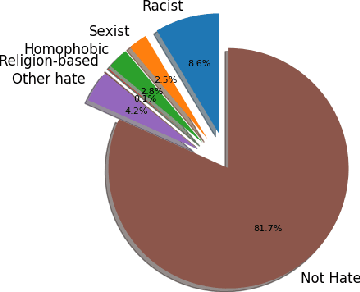
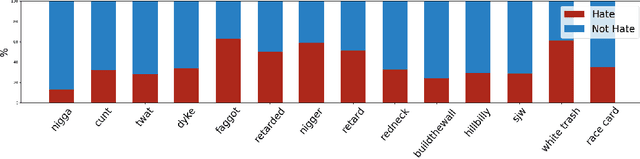
In this work we target the problem of hate speech detection in multimodal publications formed by a text and an image. We gather and annotate a large scale dataset from Twitter, MMHS150K, and propose different models that jointly analyze textual and visual information for hate speech detection, comparing them with unimodal detection. We provide quantitative and qualitative results and analyze the challenges of the proposed task. We find that, even though images are useful for the hate speech detection task, current multimodal models cannot outperform models analyzing only text. We discuss why and open the field and the dataset for further research.
Domain-independent Dominance of Adaptive Methods
Dec 10, 2019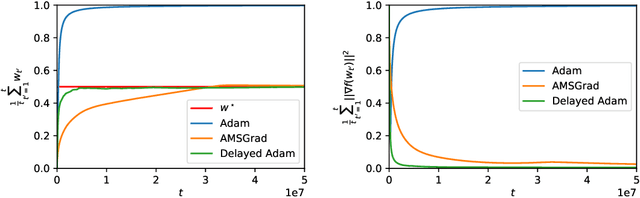
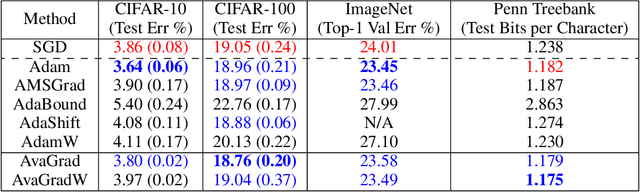
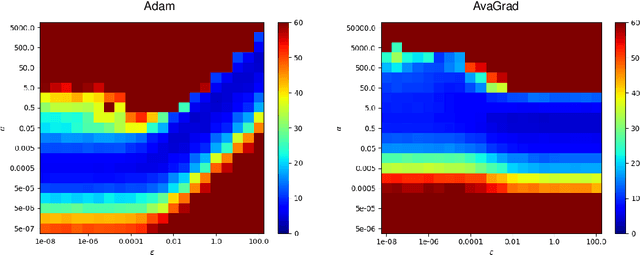
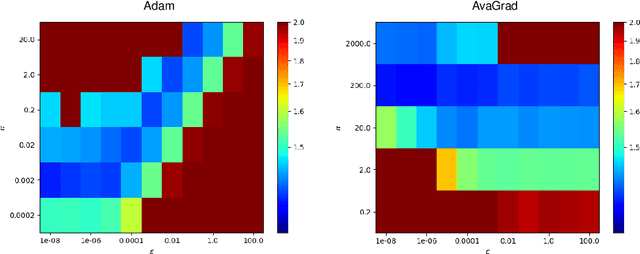
From a simplified analysis of adaptive methods, we derive AvaGrad, a new optimizer which outperforms SGD on vision tasks when its adaptability is properly tuned. We observe that the power of our method is partially explained by a decoupling of learning rate and adaptability, greatly simplifying hyperparameter search. In light of this observation, we demonstrate that, against conventional wisdom, Adam can also outperform SGD on vision tasks, as long as the coupling between its learning rate and adaptability is taken into account. In practice, AvaGrad matches the best results, as measured by generalization accuracy, delivered by any existing optimizer (SGD or adaptive) across image classification (CIFAR, ImageNet) and character-level language modelling (Penn Treebank) tasks. This later observation, alongside of AvaGrad's decoupling of hyperparameters, could make it the preferred optimizer for deep learning, replacing both SGD and Adam.
Efficient 2D neuron boundary segmentation with local topological constraints
Feb 03, 2020
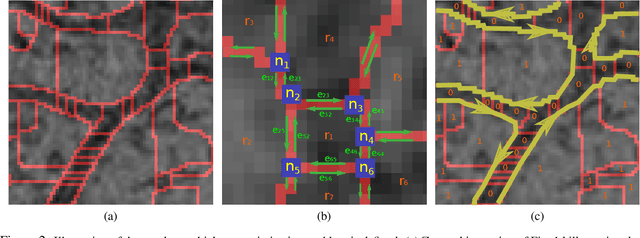

We present a method for segmenting neuron membranes in 2D electron microscopy imagery. This segmentation task has been a bottleneck to reconstruction efforts of the brain's synaptic circuits. One common problem is the misclassification of blurry membrane fragments as cell interior, which leads to merging of two adjacent neuron sections into one via the blurry membrane region. Human annotators can easily avoid such errors by implicitly performing gap completion, taking into account the continuity of membranes. Drawing inspiration from these human strategies, we formulate the segmentation task as an edge labeling problem on a graph with local topological constraints. We derive an integer linear program (ILP) that enforces membrane continuity, i.e. the absence of gaps. The cost function of the ILP is the pixel-wise deviation of the segmentation from a priori membrane probabilities derived from the data. Based on membrane probability maps obtained using random forest classifiers and convolutional neural networks, our method improves the neuron boundary segmentation accuracy compared to a variety of standard segmentation approaches. Our method successfully performs gap completion and leads to fewer topological errors. The method could potentially also be incorporated into other image segmentation pipelines with known topological constraints.
Explicit Facial Expression Transfer via Fine-Grained Semantic Representations
Sep 06, 2019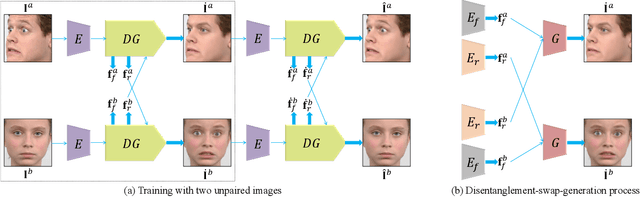

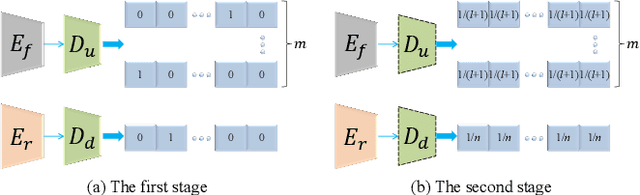
Facial expression transfer between two unpaired images is a challenging problem, as fine-grained expressions are typically tangled with other facial attributes such as identity and pose. Most existing methods treat expression transfer as an application of expression manipulation, and use predicted facial expressions, landmarks or action units (AUs) of a source image to guide the expression edit of a target image. However, the prediction of expressions, landmarks and especially AUs may be inaccurate, which limits the accuracy of transferring fine-grained expressions. Instead of using an intermediate estimated guidance, we propose to explicitly transfer expressions by directly mapping two unpaired images to two synthesized images with swapped expressions. Since each AU semantically describes local expression details, we can synthesize new images with preserved identities and swapped expressions by combining AU-free features with swapped AU-related features. To disentangle the images into AU-related features and AU-free features, we propose a novel adversarial training method which can solve the adversarial learning of multi-class classification problems. Moreover, to obtain reliable expression transfer results of the unpaired input, we introduce a swap consistency loss to make the synthesized images and self-reconstructed images indistinguishable. Extensive experiments on RaFD, MMI and CFD datasets show that our approach can generate photo-realistic expression transfer results between unpaired images with different expression appearances including genders, ages, races and poses.
Bayesian Tensor Network and Optimization Algorithm for Probabilistic Machine Learning
Dec 30, 2019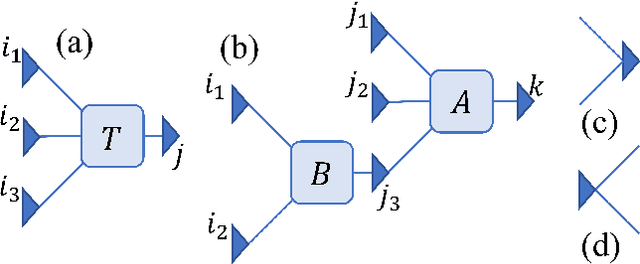
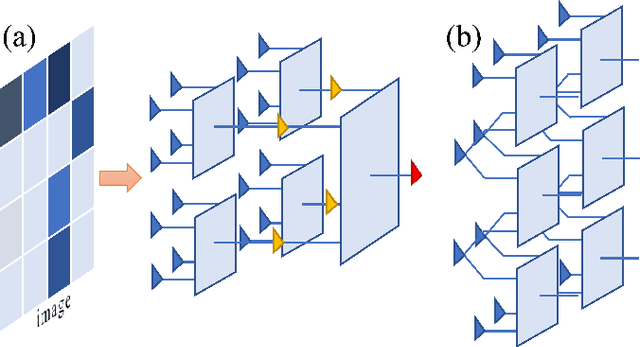
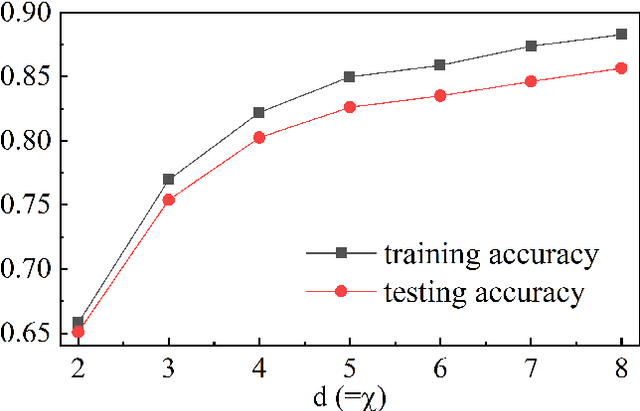
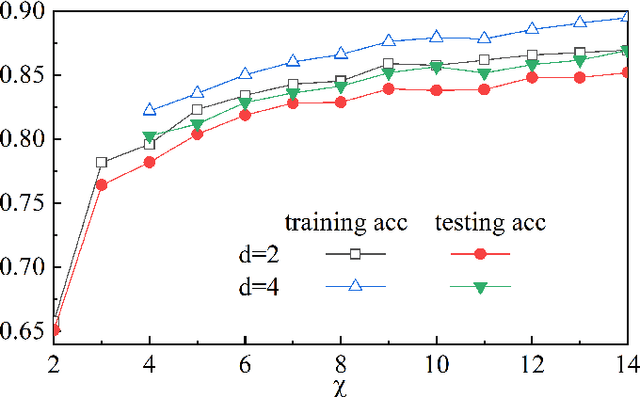
Describing or calculating the conditional probabilities of multiple events is exponentially expensive. In this work, a natural generalization of Bayesian belief network is proposed by incorporating with tensor network, which is dubbed as Bayesian tensor network (BTN), to efficiently describe the conditional probabilities among multiple sets of events. The complexity of BTN that gives the conditional probabilities of $M$ sets of events scales only polynomially with $M$. To testify its validity, BTN is implemented to capture the conditional probabilities between images and their classifications, where each feature is mapped to a probability distribution of a set of mutually exclusive events. A rotation optimization method is suggested to update BTN, which avoids gradient vanishing problem and exhibits high efficiency. With a simple tree network structures, BTN exhibits competitive performances on fashion-MNIST dataset. Analogous to the tensor network simulations of quantum systems, the validity of BTN implies an "area law" of fluctuations in image recognition problems.
Background Hardly Matters: Understanding Personality Attribution in Deep Residual Networks
Dec 20, 2019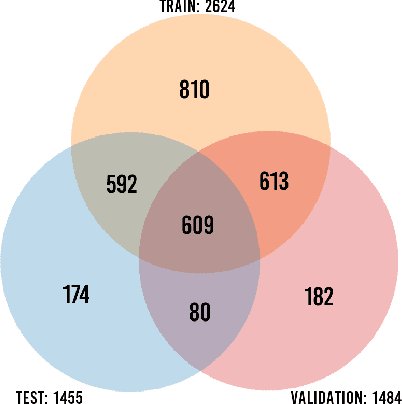
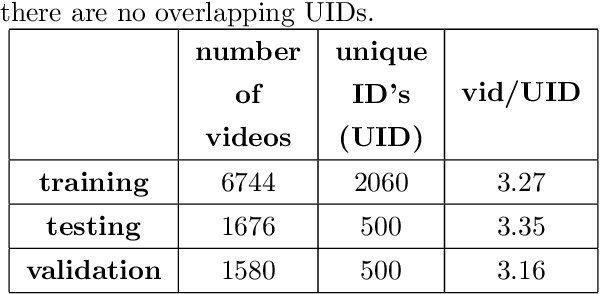

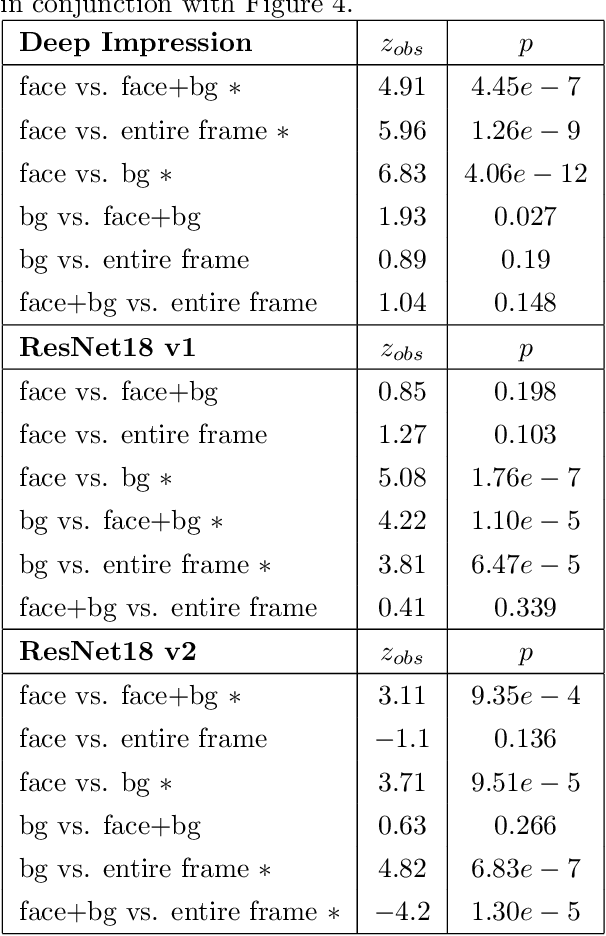
Perceived personality traits attributed to an individual do not have to correspond to their actual personality traits and may be determined in part by the context in which one encounters a person. These apparent traits determine, to a large extent, how other people will behave towards them. Deep neural networks are increasingly being used to perform automated personality attribution (e.g., job interviews). It is important that we understand the driving factors behind the predictions, in humans and in deep neural networks. This paper explicitly studies the effect of the image background on apparent personality prediction while addressing two important confounds present in existing literature; overlapping data splits and including facial information in the background. Surprisingly, we found no evidence that background information improves model predictions for apparent personality traits. In fact, when background is explicitly added to the input, a decrease in performance was measured across all models.
Using Deep Learning for Image-Based Plant Disease Detection
Apr 15, 2016

Crop diseases are a major threat to food security, but their rapid identification remains difficult in many parts of the world due to the lack of the necessary infrastructure. The combination of increasing global smartphone penetration and recent advances in computer vision made possible by deep learning has paved the way for smartphone-assisted disease diagnosis. Using a public dataset of 54,306 images of diseased and healthy plant leaves collected under controlled conditions, we train a deep convolutional neural network to identify 14 crop species and 26 diseases (or absence thereof). The trained model achieves an accuracy of 99.35% on a held-out test set, demonstrating the feasibility of this approach. When testing the model on a set of images collected from trusted online sources - i.e. taken under conditions different from the images used for training - the model still achieves an accuracy of 31.4%. While this accuracy is much higher than the one based on random selection (2.6%), a more diverse set of training data is needed to improve the general accuracy. Overall, the approach of training deep learning models on increasingly large and publicly available image datasets presents a clear path towards smartphone-assisted crop disease diagnosis on a massive global scale.
Adversarial Incremental Learning
Feb 03, 2020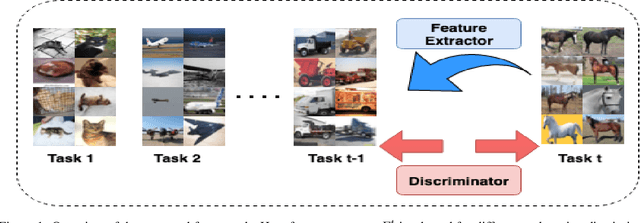
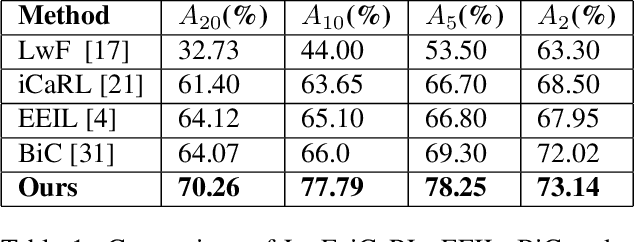
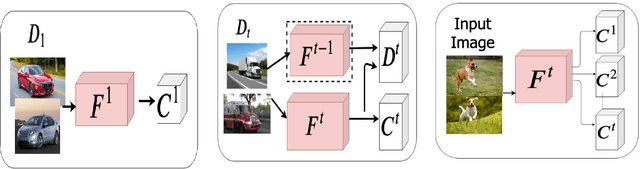
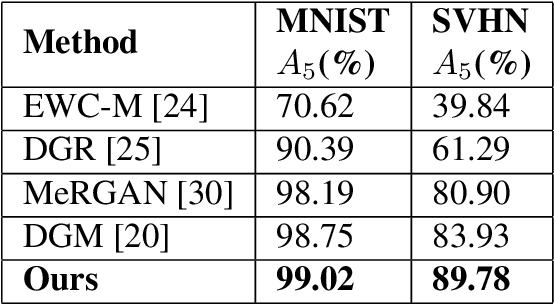
Although deep learning performs really well in a wide variety of tasks, it still suffers from catastrophic forgetting -- the tendency of neural networks to forget previously learned information upon learning new tasks where previous data is not available. Earlier methods of incremental learning tackle this problem by either using a part of the old dataset, by generating exemplars or by using memory networks. Although, these methods have shown good results but using exemplars or generating them, increases memory and computation requirements. To solve these problems we propose an adversarial discriminator based method that does not make use of old data at all while training on new tasks. We particularly tackle the class incremental learning problem in image classification, where data is provided in a class-based sequential manner. For this problem, the network is trained using an adversarial loss along with the traditional cross-entropy loss. The cross-entropy loss helps the network progressively learn new classes while the adversarial loss helps in preserving information about the existing classes. Using this approach, we are able to outperform other state-of-the-art methods on CIFAR-100, SVHN, and MNIST datasets.
ComplexFace: a Multi-Representation Approach for Image Classification with Small Dataset
Feb 21, 2019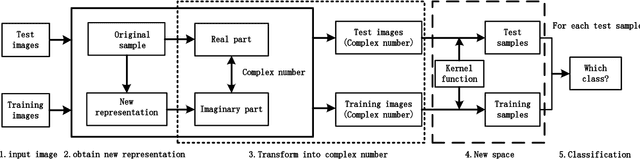



State-of-the-art face recognition algorithms are able to achieve good performance when sufficient training images are provided. Unfortunately, the number of facial images is limited in some real face recognition applications. In this paper, we propose ComplexFace, a novel and effective algorithm for face recognition with limited samples using complex number based data augmentation. The algorithm first generates new representations from original samples and then fuse both into complex numbers, which avoids the difficulty of weight setting in other fusion approaches. A test sample can then be expressed by the linear combination of all the training samples, which mapped the sample to the new representation space for classification by the kernel function. The collaborative representation based classifier is then built to make predictions. Extensive experiments on the Georgia Tech (GT) face database and the ORL face database show that our algorithm significantly outperforms existing methods: the average errors of previous approaches ranging from 31.66% to 41.75% are reduced to 14.54% over the GT database; the average errors of previous approaches ranging from 5.21% to 10.99% are reduced to 1.67% over the ORL database. In other words, our algorithm has decreased the average errors by up to 84.80% on the ORL database.
Extra Proximal-Gradient Inspired Non-local Network
Nov 17, 2019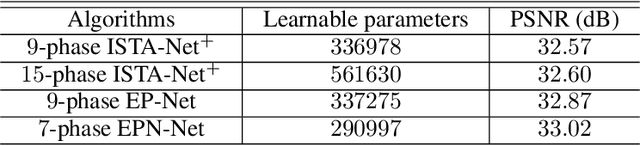

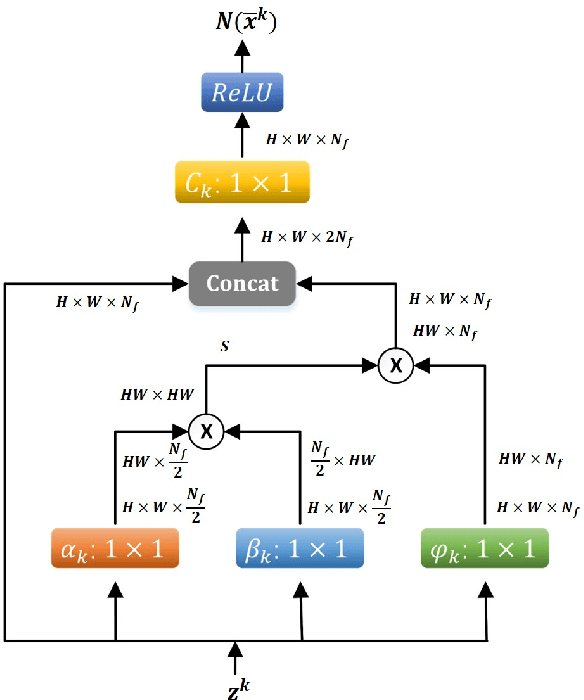
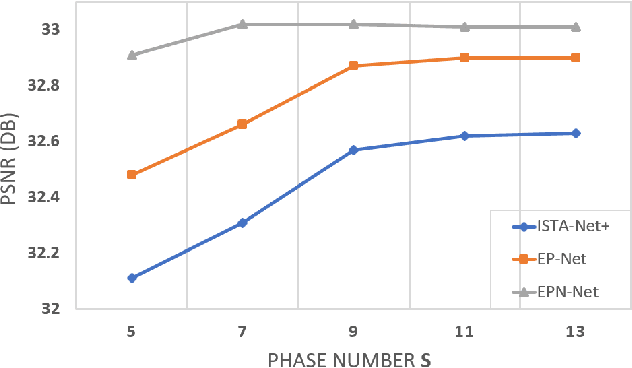
Variational method and deep learning method are two mainstream powerful approaches to solve inverse problems in computer vision. To take advantages of advanced optimization algorithms and powerful representation ability of deep neural networks, we propose a novel deep network for image reconstruction. The architecture of this network is inspired by our proposed accelerated extra proximal gradient algorithm. It is able to incorporate non-local operation to exploit the non-local self-similarity of the images and to learn the nonlinear transform, under which the solution is sparse. All the parameters in our network are learned from minimizing a loss function. Our experimental results show that our network outperforms several state-of-the-art deep networks with almost the same number of learnable parameter.