 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Channel Prior Embedded Network for Dynamic Scene Deblurring
Mar 02, 2019


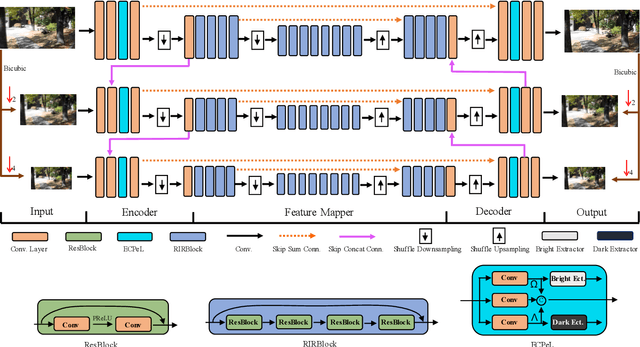
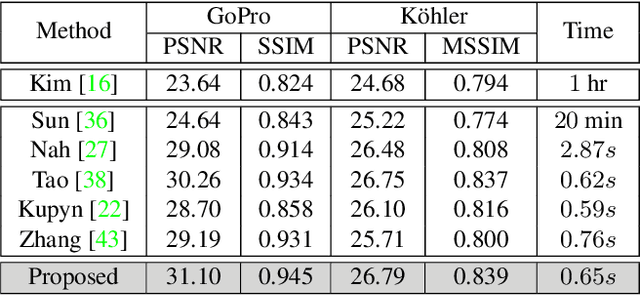
Recent years have witnessed the significant progress on convolutional neural networks (CNNs) in dynamic scene deblurring. While CNN models are generally learned by the reconstruction loss defined on training data, incorporating suitable image priors as well as regularization terms into the network architecture could boost the deblurring performance. In this work, we propose an Extreme Channel Prior embedded Network (ECPeNet) to plug the extreme channel priors (i.e., priors on dark and bright channels) into a network architecture for effective dynamic scene deblurring. A novel trainable extreme channel prior embedded layer (ECPeL) is developed to aggregate both extreme channel and blurry image representations, and sparse regularization is introduced to regularize the ECPeNet model learning. Furthermore, we present an effective multi-scale network architecture that works in both coarse-to-fine and fine-to-coarse manners for better exploiting information flow across scales. Experimental results on GoPro and Kohler datasets show that our proposed ECPeNet performs favorably against state-of-the-art deep image deblurring methods in terms of both quantitative metrics and visual quality.
FUNN: Flexible Unsupervised Neural Network
Nov 05, 2018
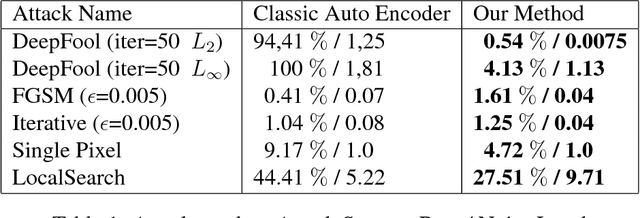

Deep neural networks have demonstrated high accuracy in image classification tasks. However, they were shown to be weak against adversarial examples: a small perturbation in the image which changes the classification output dramatically. In recent years, several defenses have been proposed to solve this issue in supervised classification tasks. We propose a method to obtain robust features in unsupervised learning tasks against adversarial attacks. Our method differs from existing solutions by directly learning the robust features without the need to project the adversarial examples in the original examples distribution space. A first auto-encoder A1 is in charge of perturbing the input image to fool another auto-encoder A2 which is in charge of regenerating the original image. A1 tries to find the less perturbed image under the constraint that the error in the output of A2 should be at least equal to a threshold. Thanks to this training, the encoder of A2 will be robust against adversarial attacks and could be used in different tasks like classification. Using state-of-art network architectures, we demonstrate the robustness of the features obtained thanks to this method in classification tasks.
Semantic Redundancies in Image-Classification Datasets: The 10% You Don't Need
Jan 29, 2019
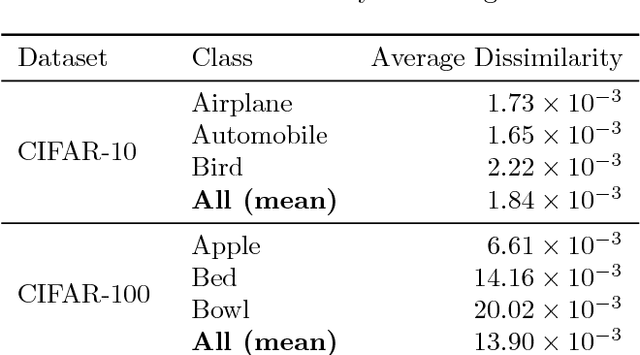
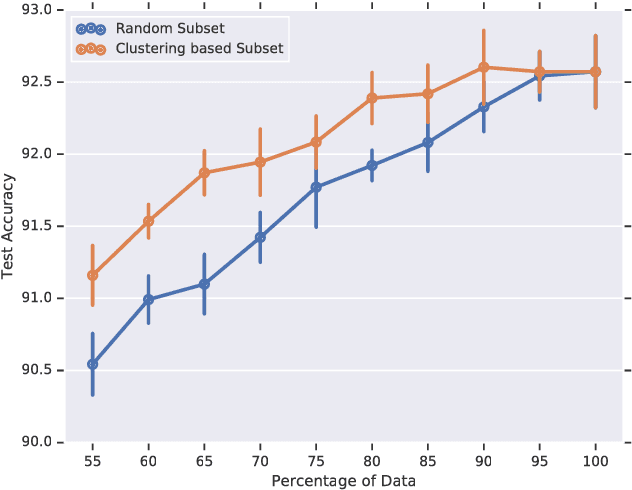

Large datasets have been crucial to the success of deep learning models in the recent years, which keep performing better as they are trained with more labelled data. While there have been sustained efforts to make these models more data-efficient, the potential benefit of understanding the data itself, is largely untapped. Specifically, focusing on object recognition tasks, we wonder if for common benchmark datasets we can do better than random subsets of the data and find a subset that can generalize on par with the full dataset when trained on. To our knowledge, this is the first result that can find notable redundancies in CIFAR-10 and ImageNet datasets (at least 10%). Interestingly, we observe semantic correlations between required and redundant images. We hope that our findings can motivate further research into identifying additional redundancies and exploiting them for more efficient training or data-collection.
Deep Learning and Control Algorithms of Direct Perception for Autonomous Driving
Nov 12, 2019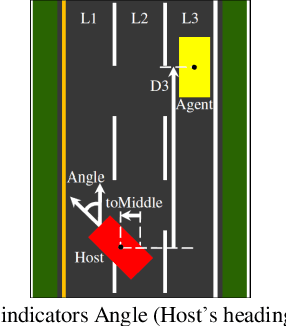
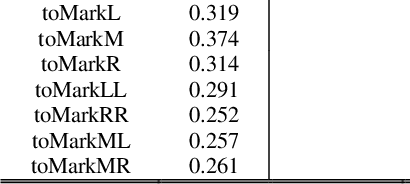
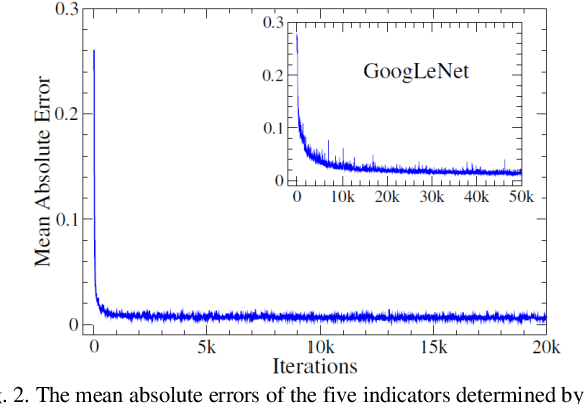

Based on the direct perception paradigm of autonomous driving, we investigate and modify the CNNs (convolutional neural networks) AlexNet and GoogLeNet that map an input image to few perception indicators (heading angle, distances to preceding cars, and distance to road centerline) for estimating driving affordances in highway traffic. We also design a controller with these indicators and the short-range sensor information of TORCS (the open racing car simulator) for driving simulated cars to avoid collisions. We collect a set of images from a TORCS camera in various driving scenarios, train these CNNs using the dataset, test them in unseen traffics, and find that they perform better than earlier algorithms and controllers in terms of training efficiency and driving stability. Source code and data are available on our website.
Dressing for Diverse Body Shapes
Dec 13, 2019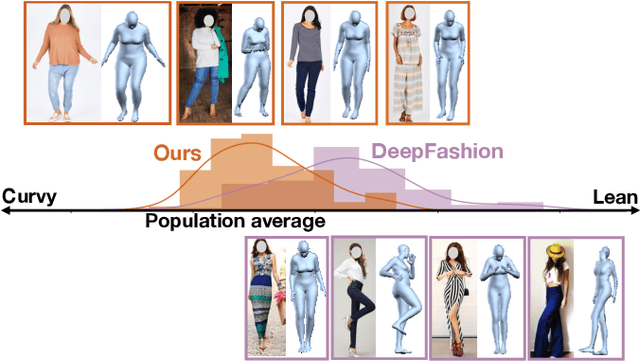
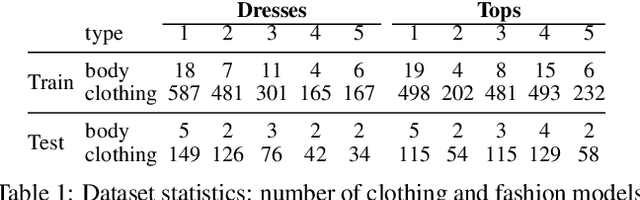

Body shape plays an important role in determining what garments will best suit a given person, yet today's clothing recommendation methods take a "one shape fits all" approach. These body-agnostic vision methods and datasets are a barrier to inclusion, ill-equipped to provide good suggestions for diverse body shapes. We introduce ViBE, a VIsual Body-aware Embedding that captures clothing's affinity with different body shapes. Given an image of a person, the proposed multi-view embedding identifies garments that will flatter her specific body shape. We show how to learn the embedding from an online catalog displaying fashion models of various shapes and sizes wearing the products, and we devise a method to explain the algorithm's suggestions for well-fitting garments. We apply our approach to a dataset of diverse subjects, and demonstrate its strong advantages over the status quo body-agnostic recommendation, both according to automated metrics and human opinion.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020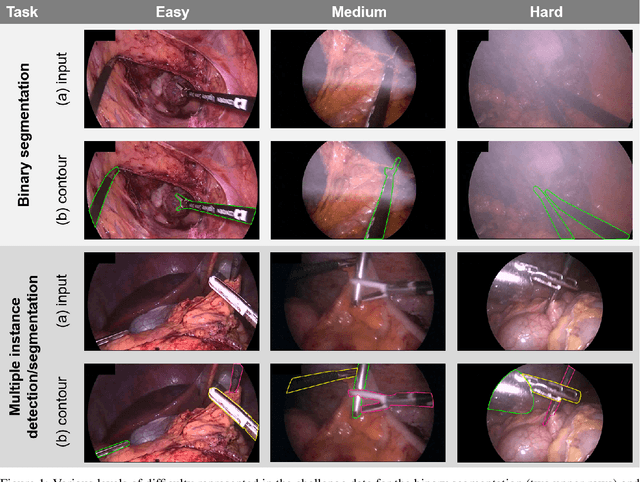
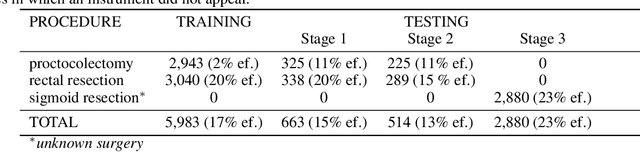
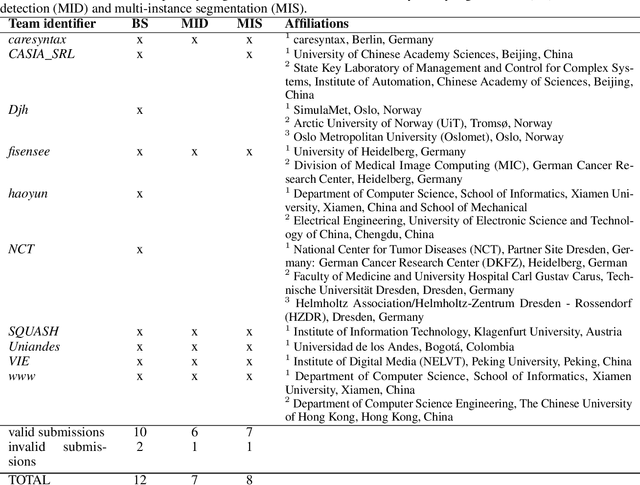
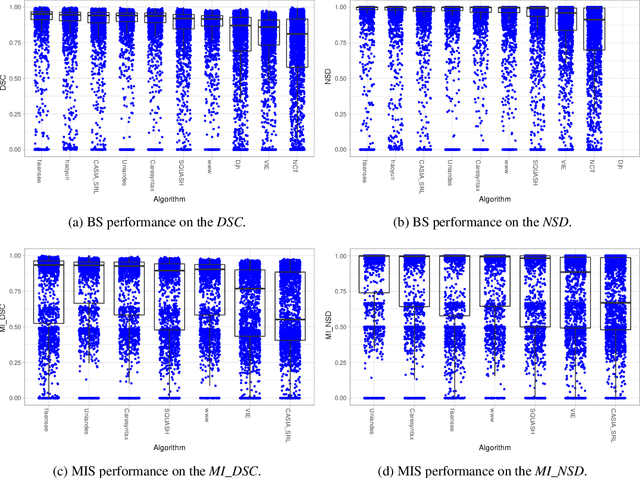
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Are Perceptually-Aligned Gradients a General Property of Robust Classifiers?
Oct 18, 2019



For a standard convolutional neural network, optimizing over the input pixels to maximize the score of some target class will generally produce a grainy-looking version of the original image. However, researchers have demonstrated that for adversarially-trained neural networks, this optimization produces images that uncannily resemble the target class. In this paper, we show that these "perceptually-aligned gradients" also occur under randomized smoothing, an alternative means of constructing adversarially-robust classifiers. Our finding suggests that perceptually-aligned gradients may be a general property of robust classifiers, rather than a specific property of adversarially-trained neural networks. We hope that our results will inspire research aimed at explaining this link between perceptually-aligned gradients and adversarial robustness.
Texture Based Image Segmentation of Chili Pepper X-Ray Images Using Gabor Filter
Apr 15, 2014

Texture segmentation is the process of partitioning an image into regions with different textures containing a similar group of pixels. Detecting the discontinuity of the filter's output and their statistical properties help in segmenting and classifying a given image with different texture regions. In this proposed paper, chili x-ray image texture segmentation is performed by using Gabor filter. The texture segmented result obtained from Gabor filter fed into three texture filters, namely Entropy, Standard Deviation and Range filter. After performing texture analysis, features can be extracted by using Statistical methods. In this paper Gray Level Co-occurrence Matrices and First order statistics are used as feature extraction methods. Features extracted from statistical methods are given to Support Vector Machine (SVM) classifier. Using this methodology, it is found that texture segmentation is followed by the Gray Level Co-occurrence Matrix feature extraction method gives a higher accuracy rate of 84% when compared with First order feature extraction method. Key Words: Texture segmentation, Texture filter, Gabor filter, Feature extraction methods, SVM classifier.
* 7 pages, 2 figures, 8 tables
Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
Jun 04, 2019
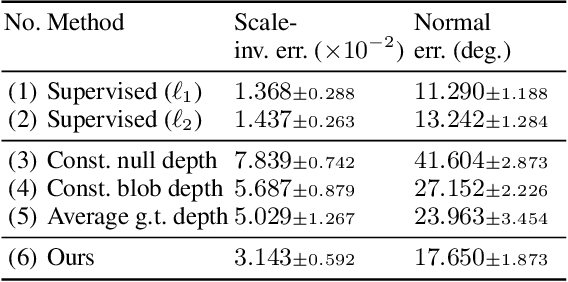
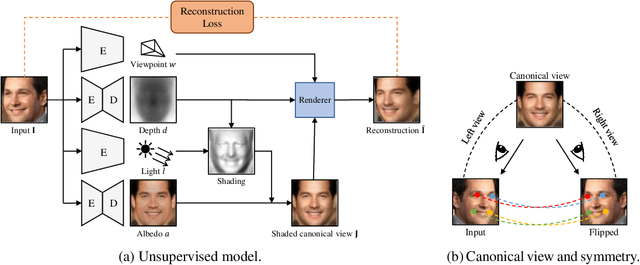

We show that generative models can be used to capture visual geometry constraints statistically. We use this fact to infer the 3D shape of object categories from raw single-view images. Differently from prior work, we use no external supervision, nor do we use multiple views or videos of the objects. We achieve this by a simple reconstruction task, exploiting the symmetry of the objects' shape and albedo. Specifically, given a single image of the object seen from an arbitrary viewpoint, our model predicts a symmetric canonical view, the corresponding 3D shape and a viewpoint transformation, and trains with the goal of reconstructing the input view, resembling an auto-encoder. Our experiments show that this method can recover the 3D shape of human faces, cat faces, and cars from single view images, without supervision. On benchmarks, we demonstrate superior accuracy compared to other methods that use supervision at the level of 2D image correspondences.
Potential Flow Generator with $L_2$ Optimal Transport Regularity for Generative Models
Aug 29, 2019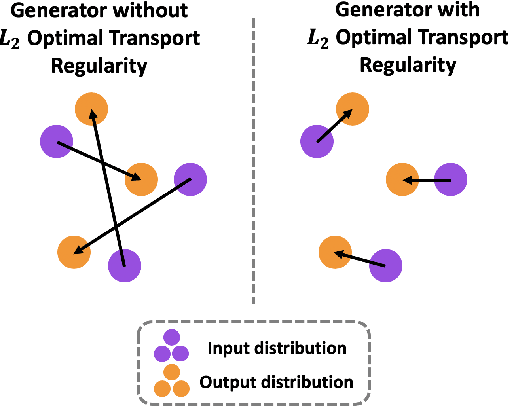
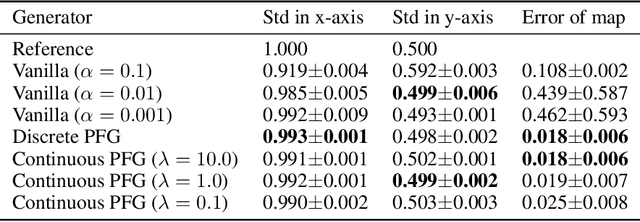
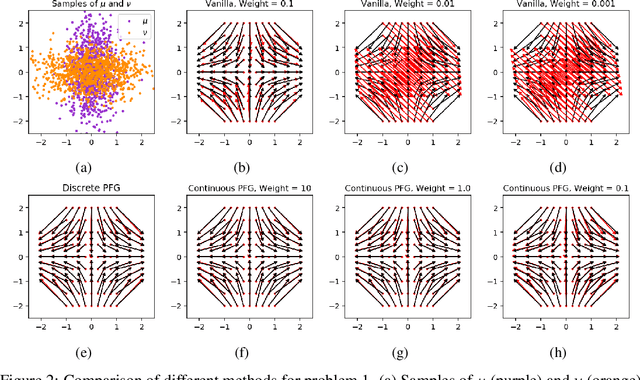
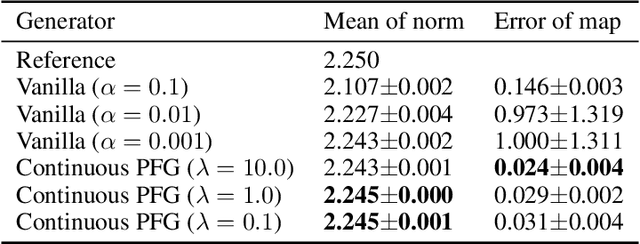
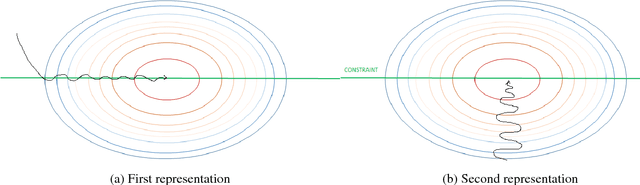
We propose a potential flow generator with $L_2$ optimal transport regularity, which can be easily integrated into a wide range of generative models including different versions of GANs and flow-based models. We show the correctness and robustness of the potential flow generator in several 2D problems, and illustrate the concept of "proximity" due to the $L_2$ optimal transport regularity. Subsequently, we demonstrate the effectiveness of the potential flow generator in image translation tasks with unpaired training data from the MNIST dataset and the CelebA dataset.