 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Segmentation in Liquid Argon Time Projection Chamber Detector
Feb 27, 2015

The Liquid Argon Time Projection Chamber (LAr-TPC) detectors provide excellent imaging and particle identification ability for studying neutrinos. An efficient and automatic reconstruction procedures are required to exploit potential of this imaging technology. Herein, a novel method for segmentation of images from LAr-TPC detectors is presented. The proposed approach computes a feature descriptor for each pixel in the image, which characterizes amplitude distribution in pixel and its neighbourhood. The supervised classifier is employed to distinguish between pixels representing particle's track and noise. The classifier is trained and evaluated on the hand-labeled dataset. The proposed approach can be a preprocessing step for reconstructing algorithms working directly on detector images.
Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images
May 15, 2019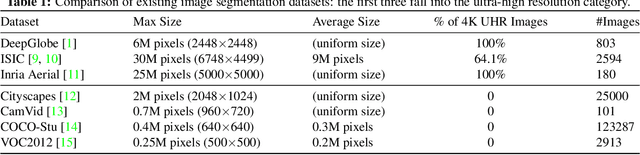
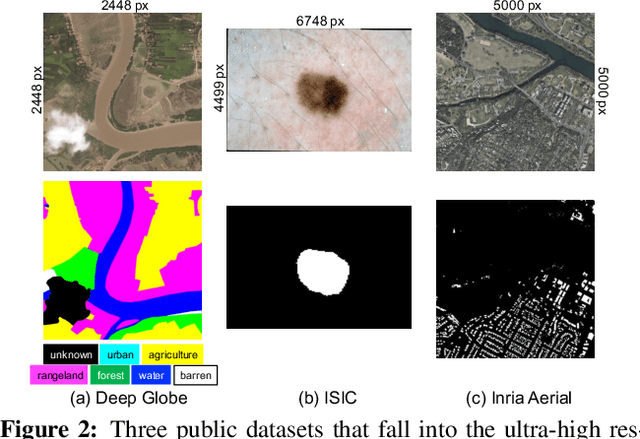
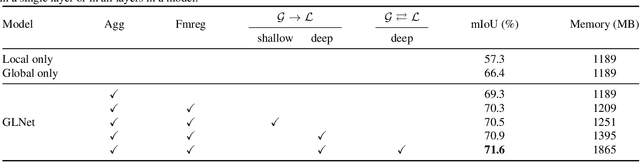
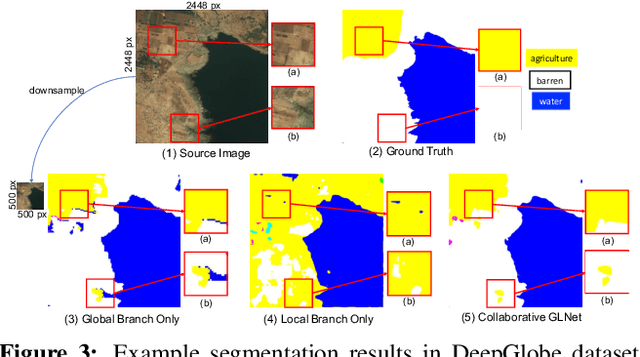
Segmentation of ultra-high resolution images is increasingly demanded, yet poses significant challenges for algorithm efficiency, in particular considering the (GPU) memory limits. Current approaches either downsample an ultra-high resolution image or crop it into small patches for separate processing. In either way, the loss of local fine details or global contextual information results in limited segmentation accuracy. We propose collaborative Global-Local Networks (GLNet) to effectively preserve both global and local information in a highly memory-efficient manner. GLNet is composed of a global branch and a local branch, taking the downsampled entire image and its cropped local patches as respective inputs. For segmentation, GLNet deeply fuses feature maps from two branches, capturing both the high-resolution fine structures from zoomed-in local patches and the contextual dependency from the downsampled input. To further resolve the potential class imbalance problem between background and foreground regions, we present a coarse-to-fine variant of GLNet, also being memory-efficient. Extensive experiments and analyses have been performed on three real-world ultra-high aerial and medical image datasets (resolution up to 30 million pixels). With only one single 1080Ti GPU and less than 2GB memory used, our GLNet yields high-quality segmentation results and achieves much more competitive accuracy-memory usage trade-offs compared to state-of-the-arts.
Non-photorealistic image processing: an Impressionist rendering
Dec 04, 2009The paper describes an image processing for a non-photorealistic rendering. The algorithm is based on a random choice of a set of pixels from those ot the original image and substitution of them with colour spots. An iterative procedure is applied to cover, at a desired level, the canvas. The resulting effect mimics the impressionist painting and Pointillism.
Deep Direct Visual Odometry
Dec 11, 2019
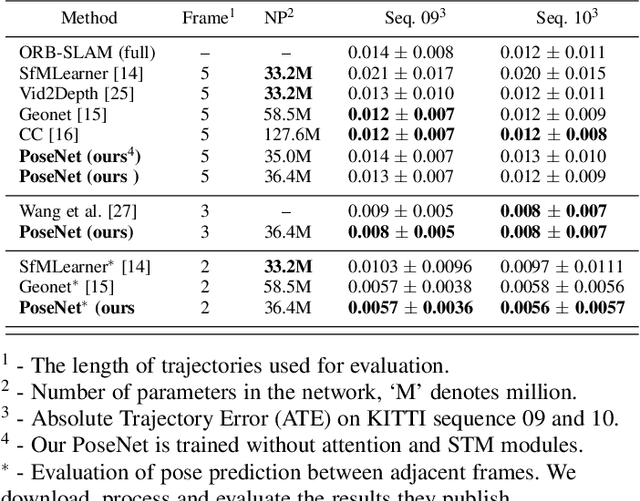
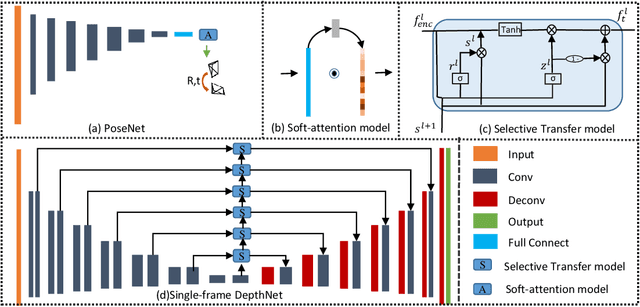
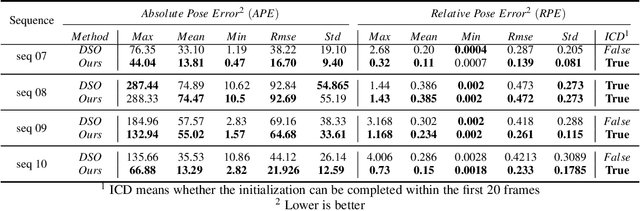
Monocular direct visual odometry (DVO) relies heavily on high-quality images and good initial pose estimation for accuracy tracking process, which means that DVO may fail if the image quality is poor or the initial value is incorrect. In this study, we present a new architecture to overcome the above limitations by embedding deep learning into DVO. A novel self-supervised network architecture for effectively predicting 6-DOF pose is proposed in this paper, and we incorporate the pose prediction into Direct Sparse Odometry (DSO) for robust initialization and tracking process. Furthermore, the attention mechanism is included to select useful features for accurate pose regression. The experiments on the KITTI dataset show that the proposed network achieves an outstanding performance compared with previous self-supervised methods, and the integration with pose network makes the initialization and tracking of DSO more robust and accurate.
Dermoscopic Image Analysis for ISIC Challenge 2018
Jul 24, 2018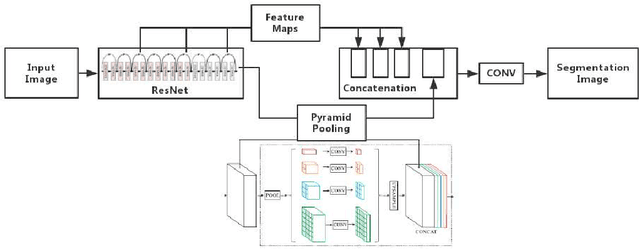
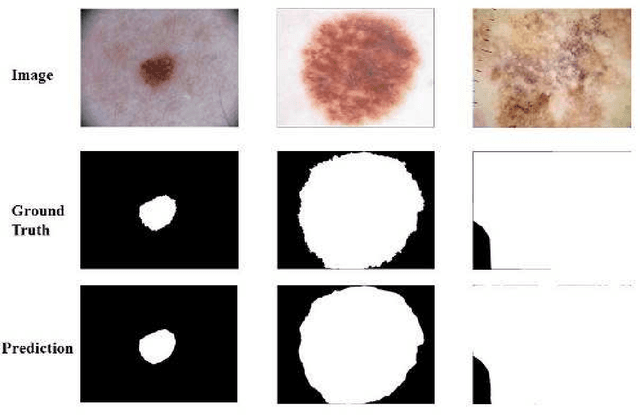
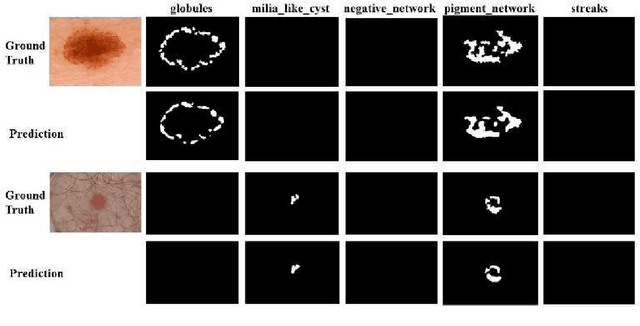
This short paper reports the algorithms we used and the evaluation performances for ISIC Challenge 2018. Our team participates in all the tasks in this challenge. In lesion segmentation task, the pyramid scene parsing network (PSPNet) is modified to segment the lesions. In lesion attribute detection task, the modified PSPNet is also adopted in a multi-label way. In disease classification task, the DenseNet-169 is adopted for multi-class classification.
Reduced Dilation-Erosion Perceptron for Binary Classification
Mar 04, 2020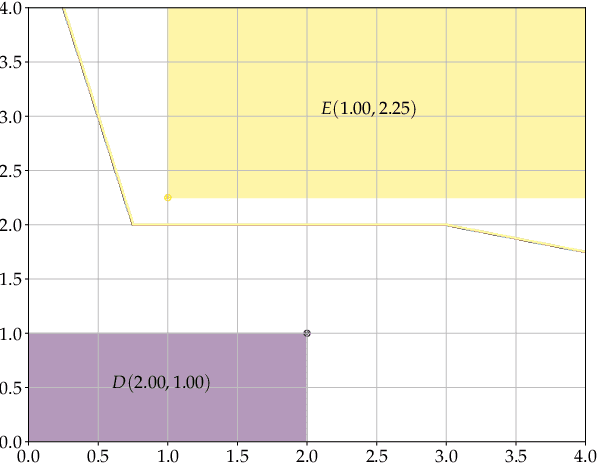
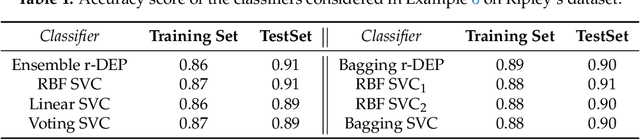

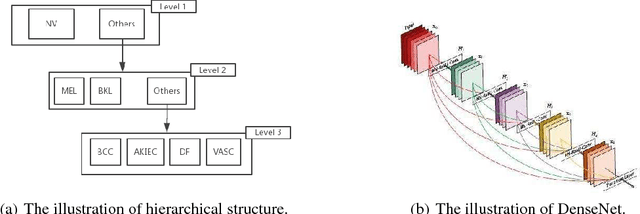
Dilation and erosion are two elementary operations from mathematical morphology, a non-linear lattice computing methodology widely used for image processing and analysis. The dilation-erosion perceptron (DEP) is a morphological neural network obtained by a convex combination of a dilation and an erosion followed by the application of a hard-limiter function for binary classification tasks. A DEP classifier can be trained using a convex-concave procedure along with the minimization of the hinge loss function. As a lattice computing model, the DEP classifier assumes the feature and class spaces are partially ordered sets. In many practical situations, however, there is no natural ordering for the feature patterns. Using concepts from multi-valued mathematical morphology, this paper introduces the reduced dilation-erosion (r-DEP) classifier. An r-DEP classifier is obtained by endowing the feature space with an appropriate reduced ordering. Such reduced ordering can be determined using two approaches: One based on an ensemble of support vector classifiers (SVCs) with different kernels and the other based on a bagging of similar SVCs trained using different samples of the training set. Using several binary classification datasets from the OpenML repository, the ensemble and bagging r-DEP classifiers yielded in mean higher balanced accuracy scores than the linear, polynomial, and radial basis function (RBF) SVCs as well as their ensemble and a bagging of RBF SVCs.
Scalable NAS with Factorizable Architectural Parameters
Dec 31, 2019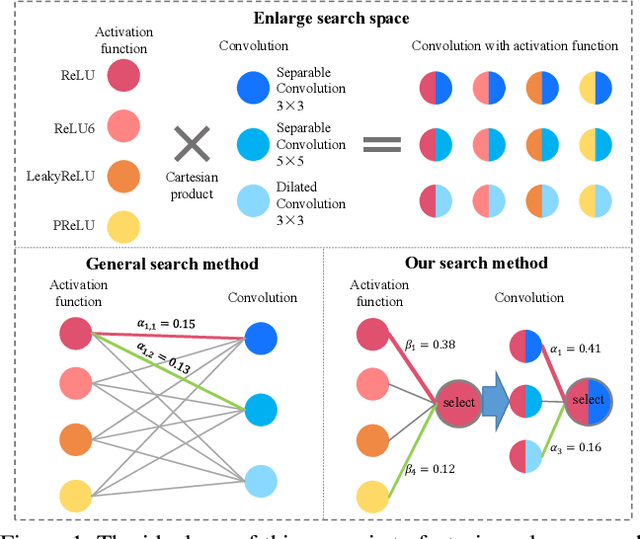
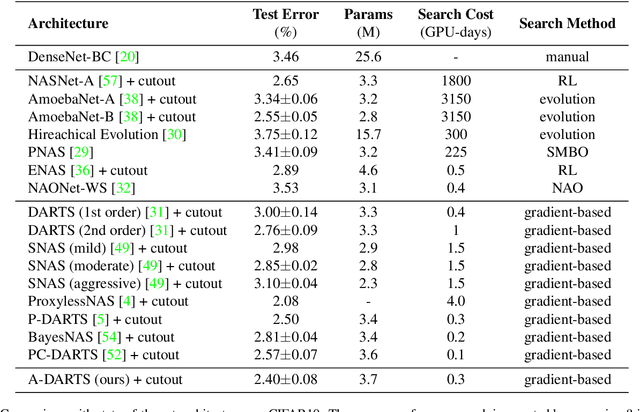
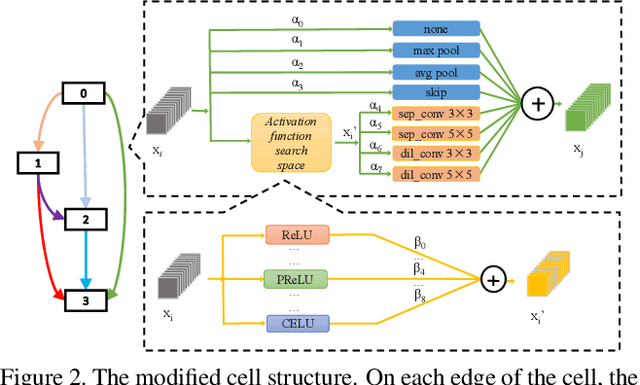
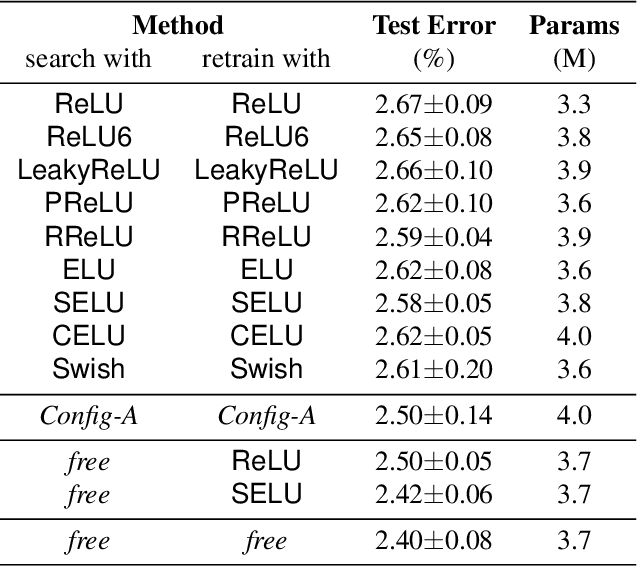
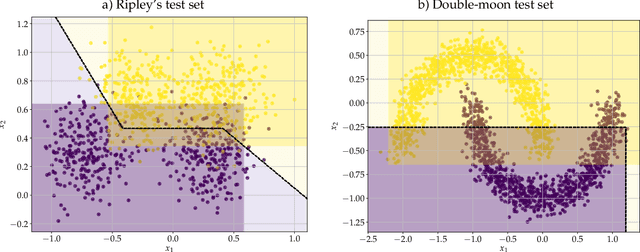
Neural architecture search (NAS) is an emerging topic in machine learning and computer vision. The fundamental ideology of NAS is using an automatic mechanism to replace manual designs for exploring powerful network architectures. One of the key factors of NAS is to scale-up the search space, e.g., increasing the number of operators, so that more possibilities are covered, but existing search algorithms often get lost in a large number of operators. This paper presents a scalable NAS algorithm by designing a factorizable set of architectural parameters, so that the size of the search space goes up quadratically while the burden of optimization increases linearly. As a practical example, we add a set of activation functions to the original set containing convolution, pooling and skip-connect, etc. With a marginal increase in search costs and no extra costs in retraining, we can find interesting architectures that were not explored before and achieve state-of-the-art performance in CIFAR10 and ImageNet, two standard image classification benchmarks.
UMONS Submission for WMT18 Multimodal Translation Task
Oct 15, 2018This paper describes the UMONS solution for the Multimodal Machine Translation Task presented at the third conference on machine translation (WMT18). We explore a novel architecture, called deepGRU, based on recent findings in the related task of Neural Image Captioning (NIC). The models presented in the following sections lead to the best METEOR translation score for both constrained (English, image) -> German and (English, image) -> French sub-tasks.
Adversarial Transformations for Semi-Supervised Learning
Nov 18, 2019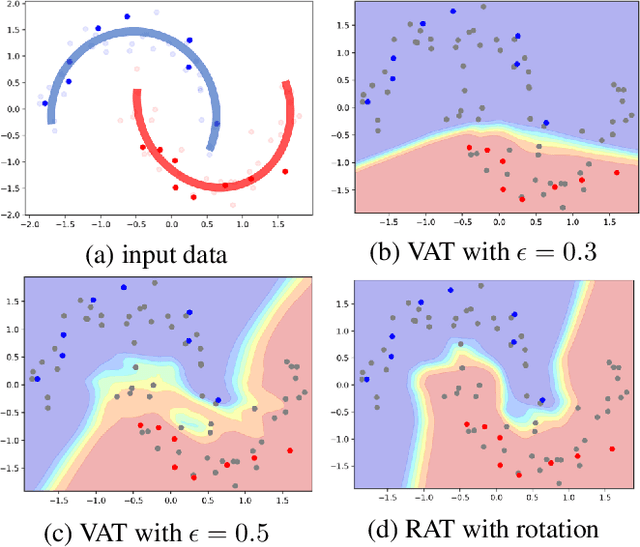


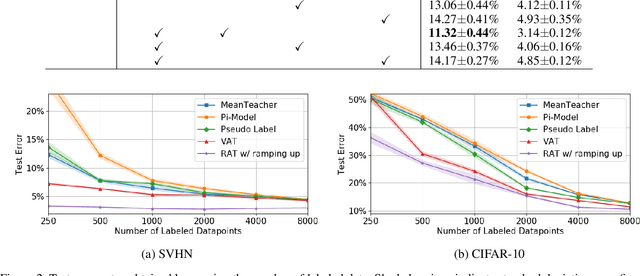
We propose a Regularization framework based on Adversarial Transformations (RAT) for semi-supervised learning. RAT is designed to enhance robustness of the output distribution of class prediction for a given data against input perturbation. RAT is an extension of Virtual Adversarial Training (VAT) in such a way that RAT adversarialy transforms data along the underlying data distribution by a rich set of data transformation functions that leave class label invariant, whereas VAT simply produces adversarial additive noises. In addition, we verified that a technique of gradually increasing of perturbation region further improve the robustness. In experiments, we show that RAT significantly improves classification performance on CIFAR-10 and SVHN compared to existing regularization methods under standard semi-supervised image classification settings.
Removing input features via a generative model to explain their attributions to classifier's decisions
Oct 09, 2019
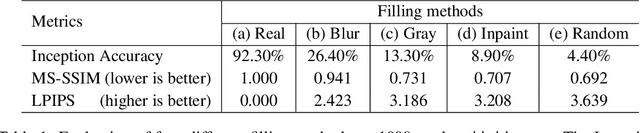


Interpretability methods often measure the contribution of an input feature to an image classifier's decisions by heuristically removing it via e.g. blurring, adding noise, or graying out, which often produce unrealistic, out-of-samples. Instead, we propose to integrate a generative inpainter into three representative attribution methods to remove an input feature. Compared to the original counterparts, our methods (1) generate more plausible counterfactual samples under the true data generating process; (2) are more robust to hyperparameter settings; and (3) localize objects more accurately. Our findings were consistent across both ImageNet and Places365 datasets and two different pairs of classifiers and inpainters.