 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Driven Robust Image Guided Depth Map Restoration
Dec 26, 2015

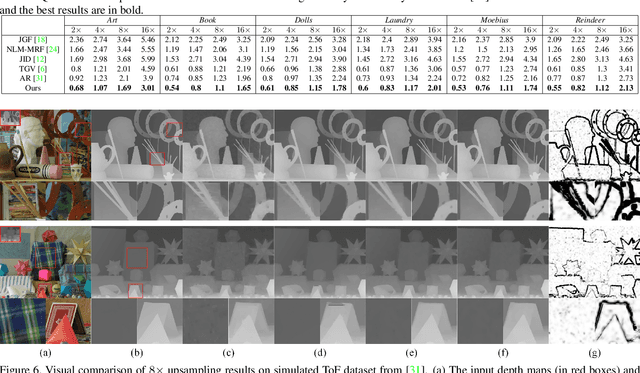
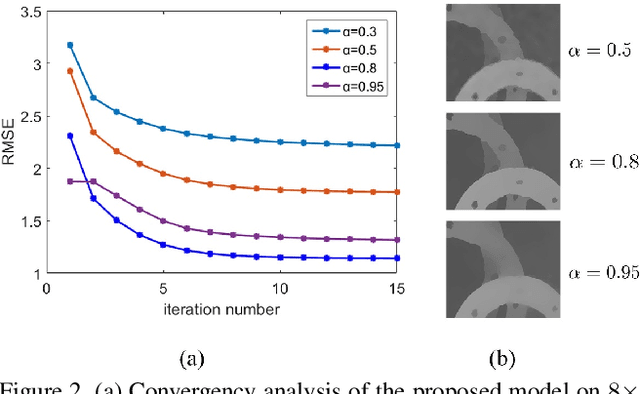
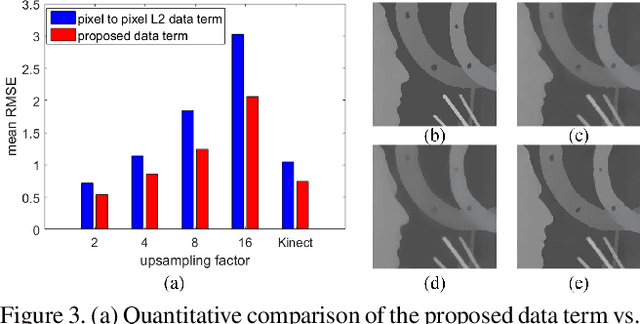
Depth maps captured by modern depth cameras such as Kinect and Time-of-Flight (ToF) are usually contaminated by missing data, noises and suffer from being of low resolution. In this paper, we present a robust method for high-quality restoration of a degraded depth map with the guidance of the corresponding color image. We solve the problem in an energy optimization framework that consists of a novel robust data term and smoothness term. To accommodate not only the noise but also the inconsistency between depth discontinuities and the color edges, we model both the data term and smoothness term with a robust exponential error norm function. We propose to use Iteratively Re-weighted Least Squares (IRLS) methods for efficiently solving the resulting highly non-convex optimization problem. More importantly, we further develop a data-driven adaptive parameter selection scheme to properly determine the parameter in the model. We show that the proposed approach can preserve fine details and sharp depth discontinuities even for a large upsampling factor ($8\times$ for example). Experimental results on both simulated and real datasets demonstrate that the proposed method outperforms recent state-of-the-art methods in coping with the heavy noise, preserving sharp depth discontinuities and suppressing the texture copy artifacts.
Incremental Learning In Online Scenario
Mar 30, 2020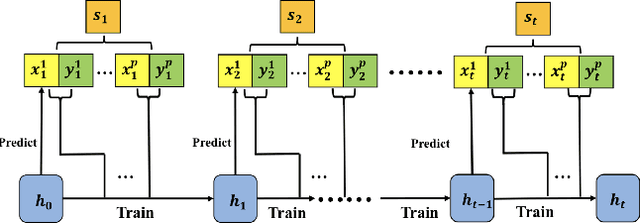

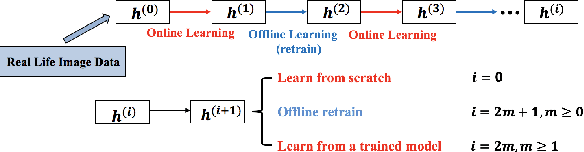

Modern deep learning approaches have achieved great success in many vision applications by training a model using all available task-specific data. However, there are two major obstacles making it challenging to implement for real life applications: (1) Learning new classes makes the trained model quickly forget old classes knowledge, which is referred to as catastrophic forgetting. (2) As new observations of old classes come sequentially over time, the distribution may change in unforeseen way, making the performance degrade dramatically on future data, which is referred to as concept drift. Current state-of-the-art incremental learning methods require a long time to train the model whenever new classes are added and none of them takes into consideration the new observations of old classes. In this paper, we propose an incremental learning framework that can work in the challenging online learning scenario and handle both new classes data and new observations of old classes. We address problem (1) in online mode by introducing a modified cross-distillation loss together with a two-step learning technique. Our method outperforms the results obtained from current state-of-the-art offline incremental learning methods on the CIFAR-100 and ImageNet-1000 (ILSVRC 2012) datasets under the same experiment protocol but in online scenario. We also provide a simple yet effective method to mitigate problem (2) by updating exemplar set using the feature of each new observation of old classes and demonstrate a real life application of online food image classification based on our complete framework using the Food-101 dataset.
Aligning where to see and what to tell: image caption with region-based attention and scene factorization
Jun 20, 2015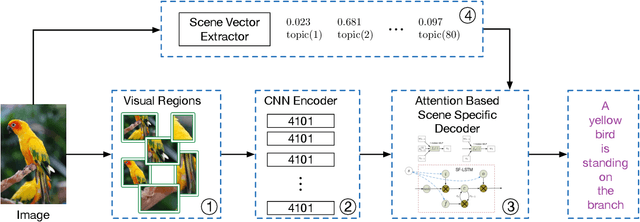
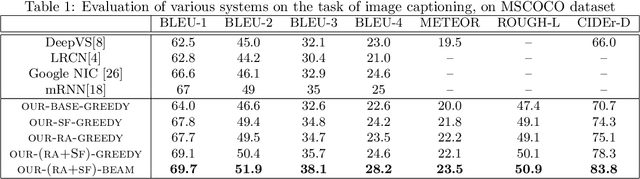
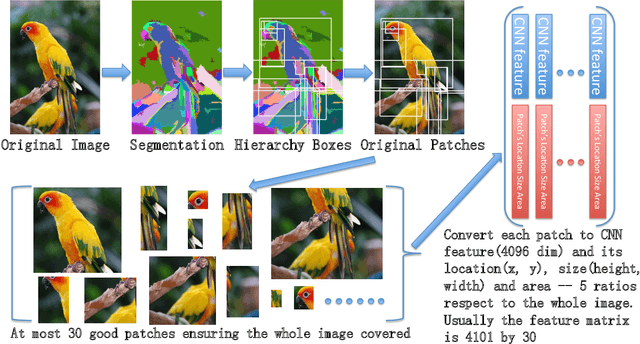
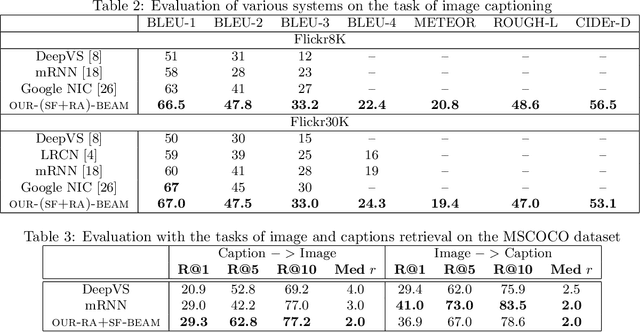
Recent progress on automatic generation of image captions has shown that it is possible to describe the most salient information conveyed by images with accurate and meaningful sentences. In this paper, we propose an image caption system that exploits the parallel structures between images and sentences. In our model, the process of generating the next word, given the previously generated ones, is aligned with the visual perception experience where the attention shifting among the visual regions imposes a thread of visual ordering. This alignment characterizes the flow of "abstract meaning", encoding what is semantically shared by both the visual scene and the text description. Our system also makes another novel modeling contribution by introducing scene-specific contexts that capture higher-level semantic information encoded in an image. The contexts adapt language models for word generation to specific scene types. We benchmark our system and contrast to published results on several popular datasets. We show that using either region-based attention or scene-specific contexts improves systems without those components. Furthermore, combining these two modeling ingredients attains the state-of-the-art performance.
Video Summarization using Keyframe Extraction and Video Skimming
Oct 10, 2019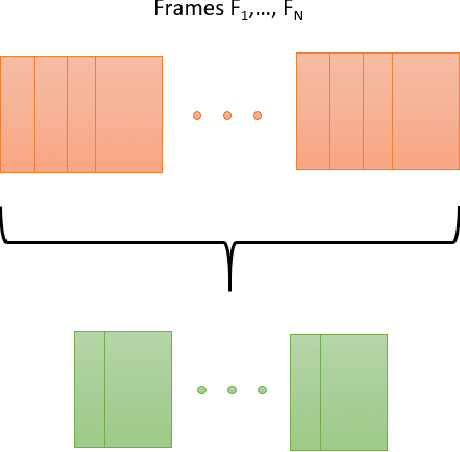
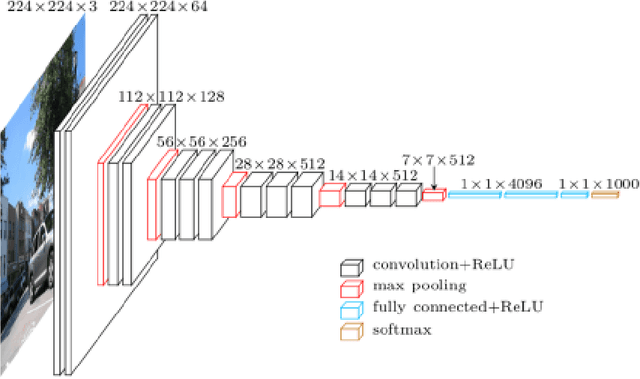

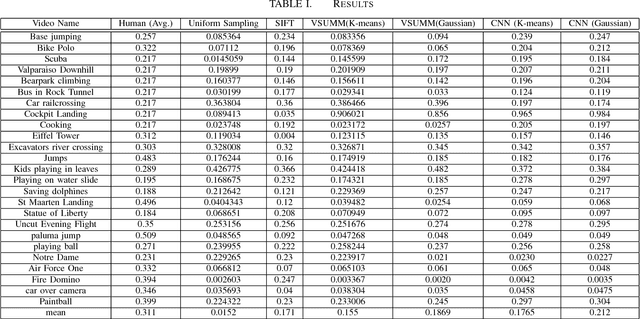
Video is one of the robust sources of information and the consumption of online and offline videos has reached an unprecedented level in the last few years. A fundamental challenge of extracting information from videos is a viewer has to go through the complete video to understand the context, as opposed to an image where the viewer can extract information from a single frame. In this work, we attempt to employ different Algorithmic methodologies including local features and deep neural networks along with multiple clustering methods to find an effective way of summarizing a video by interesting keyframe extraction.
Parting with Illusions about Deep Active Learning
Dec 11, 2019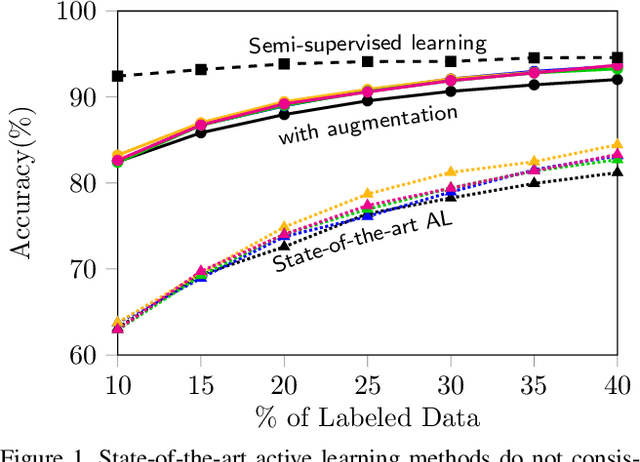
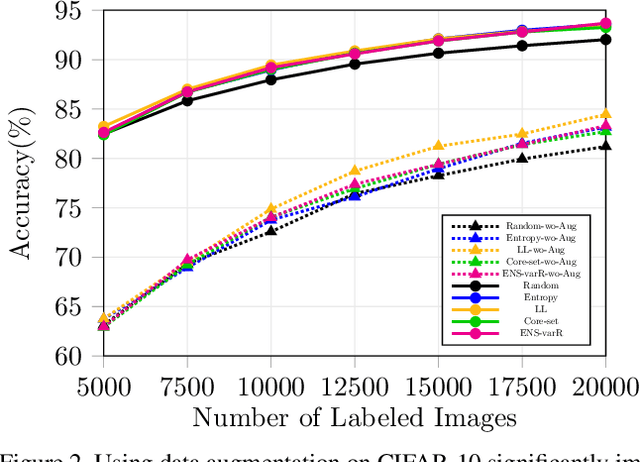
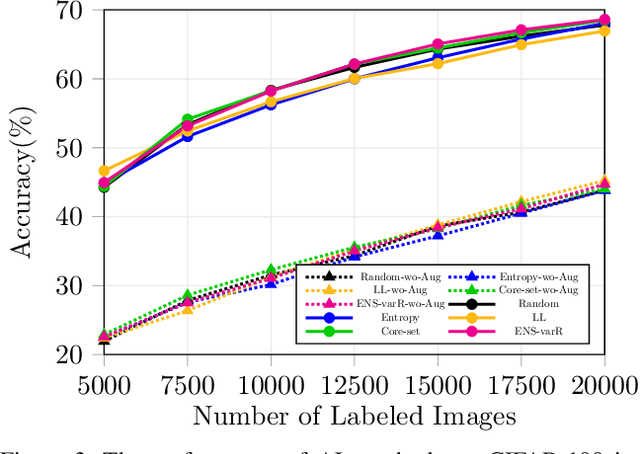
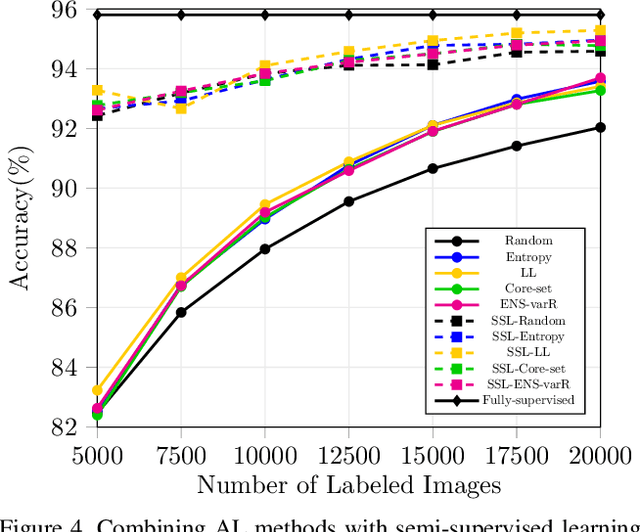
Active learning aims to reduce the high labeling cost involved in training machine learning models on large datasets by efficiently labeling only the most informative samples. Recently, deep active learning has shown success on various tasks. However, the conventional evaluation scheme used for deep active learning is below par. Current methods disregard some apparent parallel work in the closely related fields. Active learning methods are quite sensitive w.r.t. changes in the training procedure like data augmentation. They improve by a large-margin when integrated with semi-supervised learning, but barely perform better than the random baseline. We re-implement various latest active learning approaches for image classification and evaluate them under more realistic settings. We further validate our findings for semantic segmentation. Based on our observations, we realistically assess the current state of the field and propose a more suitable evaluation protocol.
Deep Sequential Mosaicking of Fetoscopic Videos
Jul 15, 2019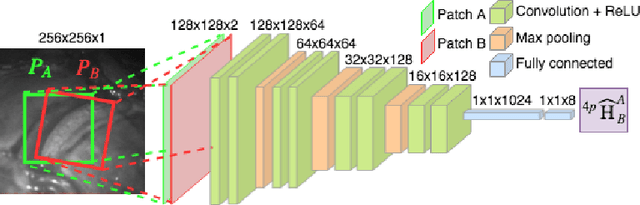
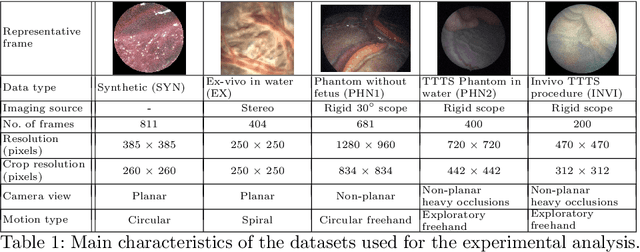
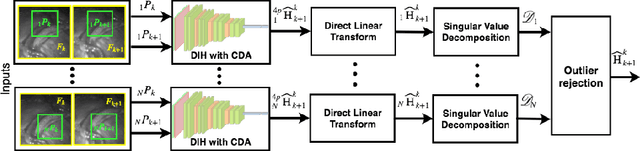

Twin-to-twin transfusion syndrome treatment requires fetoscopic laser photocoagulation of placental vascular anastomoses to regulate blood flow to both fetuses. Limited field-of-view (FoV) and low visual quality during fetoscopy make it challenging to identify all vascular connections. Mosaicking can align multiple overlapping images to generate an image with increased FoV, however, existing techniques apply poorly to fetoscopy due to the low visual quality, texture paucity, and hence fail in longer sequences due to the drift accumulated over time. Deep learning techniques can facilitate in overcoming these challenges. Therefore, we present a new generalized Deep Sequential Mosaicking (DSM) framework for fetoscopic videos captured from different settings such as simulation, phantom, and real environments. DSM extends an existing deep image-based homography model to sequential data by proposing controlled data augmentation and outlier rejection methods. Unlike existing methods, DSM can handle visual variations due to specular highlights and reflection across adjacent frames, hence reducing the accumulated drift. We perform experimental validation and comparison using 5 diverse fetoscopic videos to demonstrate the robustness of our framework.
3D Human Pose Estimation from a Single Image via Distance Matrix Regression
Nov 28, 2016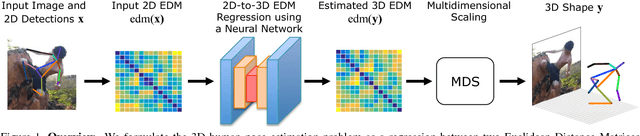
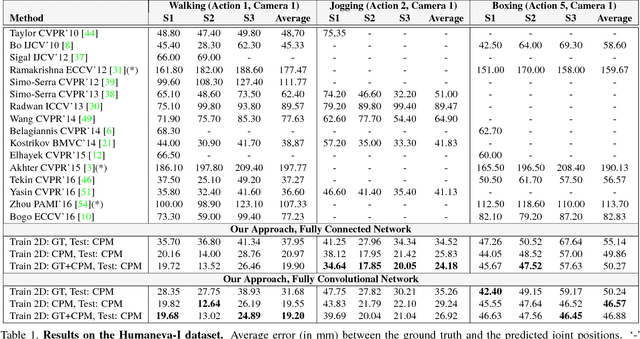
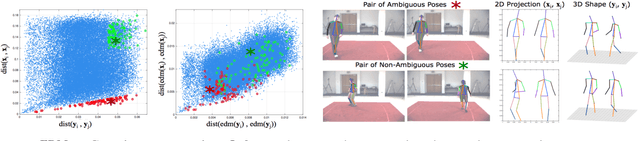
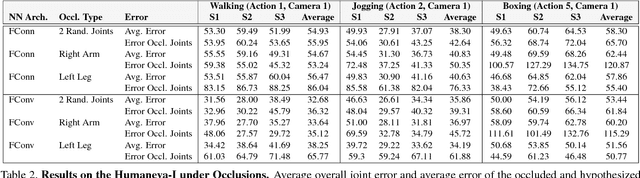
This paper addresses the problem of 3D human pose estimation from a single image. We follow a standard two-step pipeline by first detecting the 2D position of the $N$ body joints, and then using these observations to infer 3D pose. For the first step, we use a recent CNN-based detector. For the second step, most existing approaches perform 2$N$-to-3$N$ regression of the Cartesian joint coordinates. We show that more precise pose estimates can be obtained by representing both the 2D and 3D human poses using $N\times N$ distance matrices, and formulating the problem as a 2D-to-3D distance matrix regression. For learning such a regressor we leverage on simple Neural Network architectures, which by construction, enforce positivity and symmetry of the predicted matrices. The approach has also the advantage to naturally handle missing observations and allowing to hypothesize the position of non-observed joints. Quantitative results on Humaneva and Human3.6M datasets demonstrate consistent performance gains over state-of-the-art. Qualitative evaluation on the images in-the-wild of the LSP dataset, using the regressor learned on Human3.6M, reveals very promising generalization results.
Blind Denoising Autoencoder
Dec 11, 2019
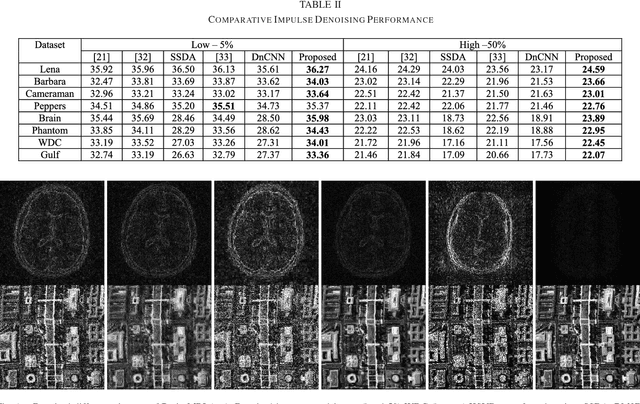
The term blind denoising refers to the fact that the basis used for denoising is learnt from the noisy sample itself during denoising. Dictionary learning and transform learning based formulations for blind denoising are well known. But there has been no autoencoder based solution for the said blind denoising approach. So far autoencoder based denoising formulations have learnt the model on a separate training data and have used the learnt model to denoise test samples. Such a methodology fails when the test image (to denoise) is not of the same kind as the models learnt with. This will be first work, where we learn the autoencoder from the noisy sample while denoising. Experimental results show that our proposed method performs better than dictionary learning (KSVD), transform learning, sparse stacked denoising autoencoder and the gold standard BM3D algorithm.
Optimization with soft Dice can lead to a volumetric bias
Nov 06, 2019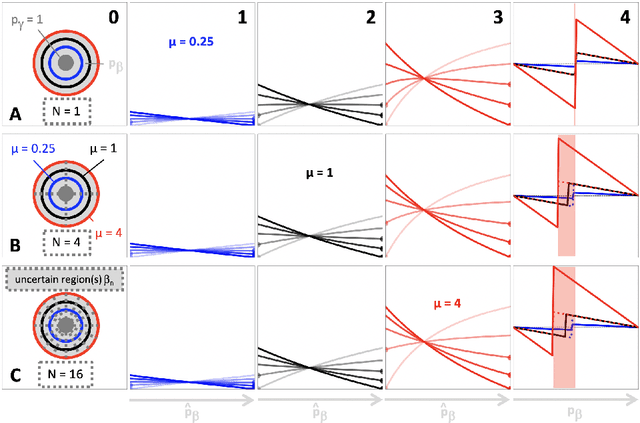

Segmentation is a fundamental task in medical image analysis. The clinical interest is often to measure the volume of a structure. To evaluate and compare segmentation methods, the similarity between a segmentation and a predefined ground truth is measured using metrics such as the Dice score. Recent segmentation methods based on convolutional neural networks use a differentiable surrogate of the Dice score, such as soft Dice, explicitly as the loss function during the learning phase. Even though this approach leads to improved Dice scores, we find that, both theoretically and empirically on four medical tasks, it can introduce a volumetric bias for tasks with high inherent uncertainty. As such, this may limit the method's clinical applicability.
DeepSUM: Deep neural network for Super-resolution of Unregistered Multitemporal images
Jul 15, 2019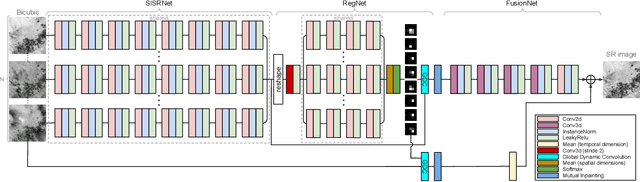

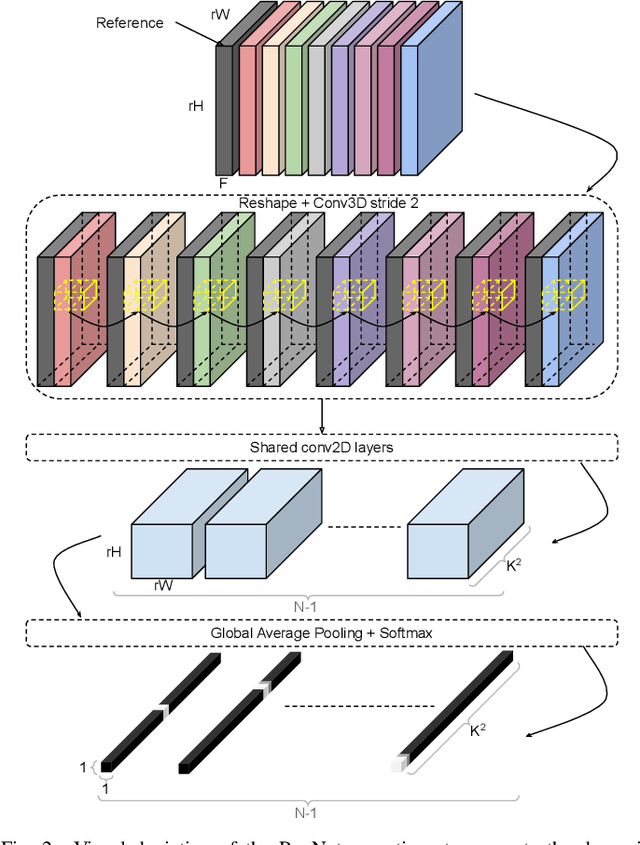
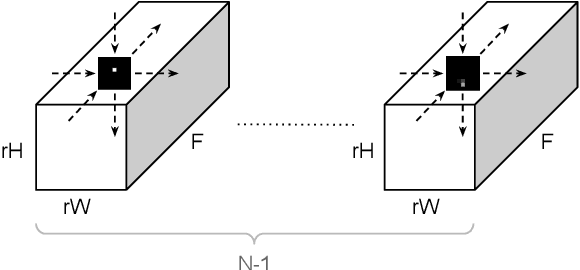
Recently, convolutional neural networks (CNN) have been successfully applied to many remote sensing problems. However, deep learning techniques for multi-image super-resolution from multitemporal unregistered imagery have received little attention so far. This work proposes a novel CNN-based technique that exploits both spatial and temporal correlations to combine multiple images. This novel framework integrates the spatial registration task directly inside the CNN, and allows to exploit the representation learning capabilities of the network to enhance registration accuracy. The entire super-resolution process relies on a single CNN with three main stages: shared 2D convolutions to extract high-dimensional features from the input images; a subnetwork proposing registration filters derived from the high-dimensional feature representations; 3D convolutions for slow fusion of the features from multiple images. The whole network can be trained end-to-end to recover a single high resolution image from multiple unregistered low resolution images. The method presented in this paper is the winner of the PROBA-V super-resolution challenge issued by the European Space Agency.