 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lake Ice Monitoring with Webcams and Crowd-Sourced Images
Feb 18, 2020
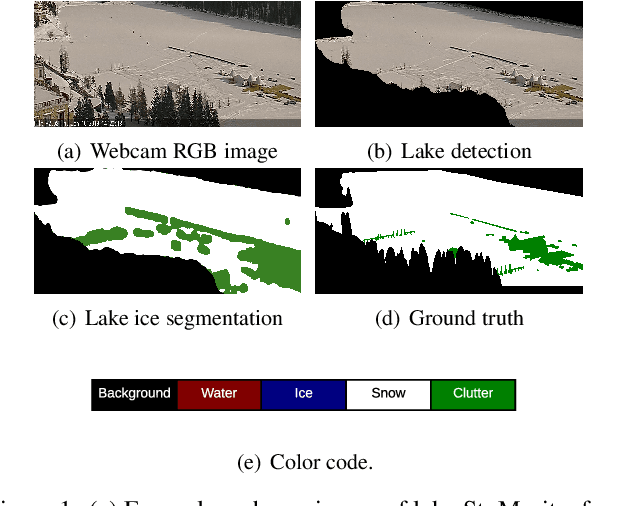
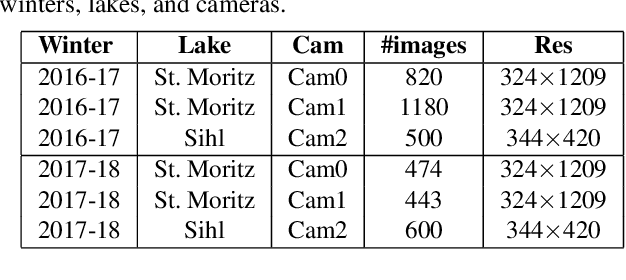

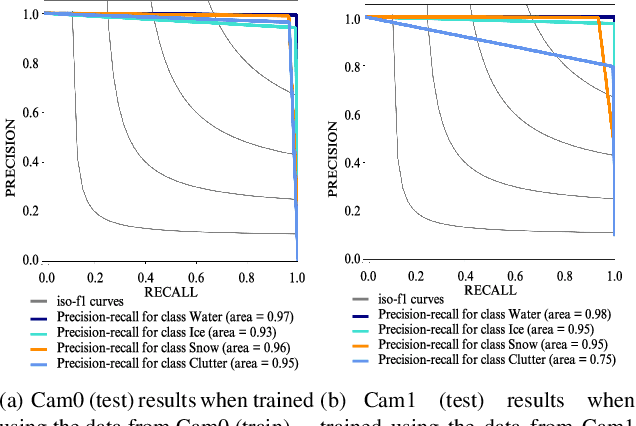
Lake ice is a strong climate indicator and has been recognised as part of the Essential Climate Variables (ECV) by the Global Climate Observing System (GCOS). The dynamics of freezing and thawing, and possible shifts of freezing patterns over time, can help in understanding the local and global climate systems. One way to acquire the spatio-temporal information about lake ice formation, independent of clouds, is to analyse webcam images. This paper intends to move towards a universal model for monitoring lake ice with freely available webcam data. We demonstrate good performance, including the ability to generalise across different winters and different lakes, with a state-of-the-art Convolutional Neural Network (CNN) model for semantic image segmentation, Deeplab v3+. Moreover, we design a variant of that model, termed Deep-U-Lab, which predicts sharper, more correct segmentation boundaries. We have tested the model's ability to generalise with data from multiple camera views and two different winters. On average, it achieves intersection-over-union (IoU) values of ~71% across different cameras and ~69% across different winters, greatly outperforming prior work. Going even further, we show that the model even achieves 60% IoU on arbitrary images scraped from photo-sharing web sites. As part of the work, we introduce a new benchmark dataset of webcam images, Photi-LakeIce, from multiple cameras and two different winters, along with pixel-wise ground truth annotations.
On measuring the iconicity of a face
Mar 04, 2019

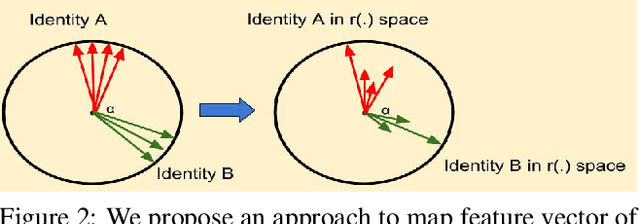
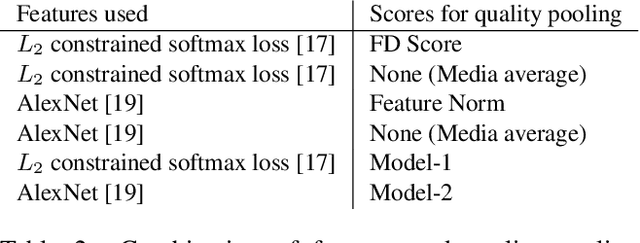
For a given identity in a face dataset, there are certain iconic images which are more representative of the subject than others. In this paper, we explore the problem of computing the iconicity of a face. The premise of the proposed approach is as follows: For an identity containing a mixture of iconic and non iconic images, if a given face cannot be successfully matched with any other face of the same identity, then the iconicity of the face image is low. Using this information, we train a Siamese Multi-Layer Perceptron network, such that each of its twins predict iconicity scores of the image feature pair, fed in as input. We observe the variation of the obtained scores with respect to covariates such as blur, yaw, pitch, roll and occlusion to demonstrate that they effectively predict the quality of the image and compare it with other existing metrics. Furthermore, we use these scores to weight features for template-based face verification and compare it with media averaging of features.
Static and Dynamic Fusion for Multi-modal Cross-ethnicity Face Anti-spoofing
Dec 16, 2019
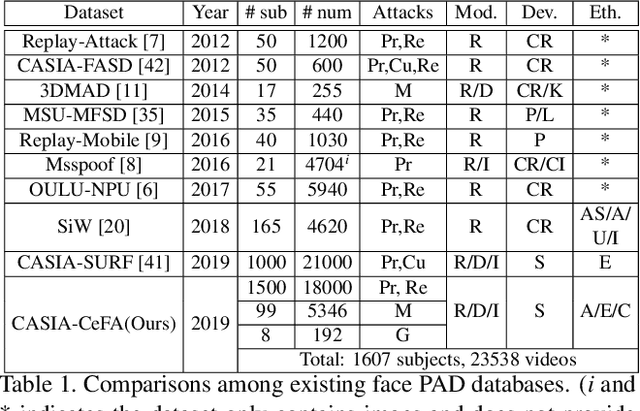
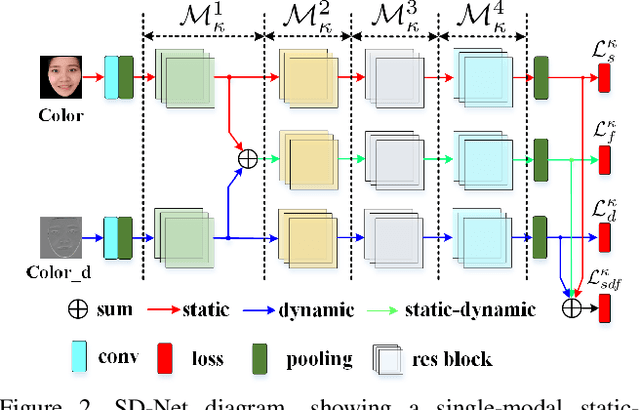
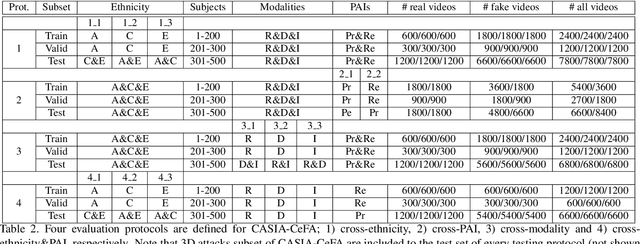
Regardless of the usage of deep learning and handcrafted methods, the dynamic information from videos and the effect of cross-ethnicity are rarely considered in face anti-spoofing. In this work, we propose a static-dynamic fusion mechanism for multi-modal face anti-spoofing. Inspired by motion divergences between real and fake faces, we incorporate the dynamic image calculated by rank pooling with static information into a conventional neural network (CNN) for each modality (i.e., RGB, Depth and infrared (IR)). Then, we develop a partially shared fusion method to learn complementary information from multiple modalities. Furthermore, in order to study the generalization capability of the proposal in terms of cross-ethnicity attacks and unknown spoofs, we introduce the largest public cross-ethnicity Face Anti-spoofing (CASIA-CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types. Experiments demonstrate that the proposed method achieves state-of-the-art results on CASIA-CeFA, CASIA-SURF, OULU-NPU and SiW.
Measuring the Utilization of Public Open Spaces by Deep Learning: a Benchmark Study at the Detroit Riverfront
Feb 04, 2020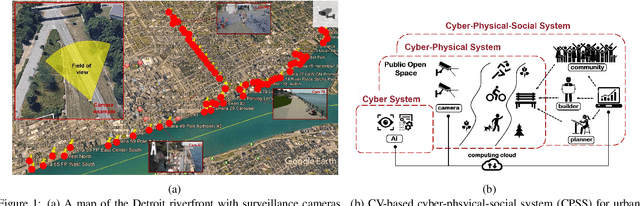
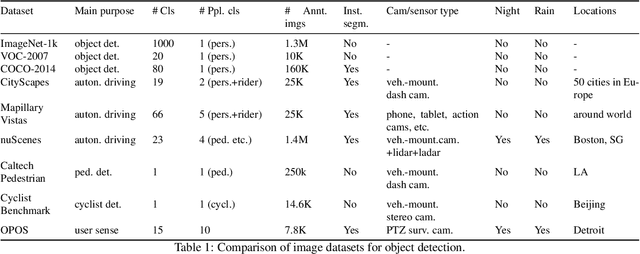

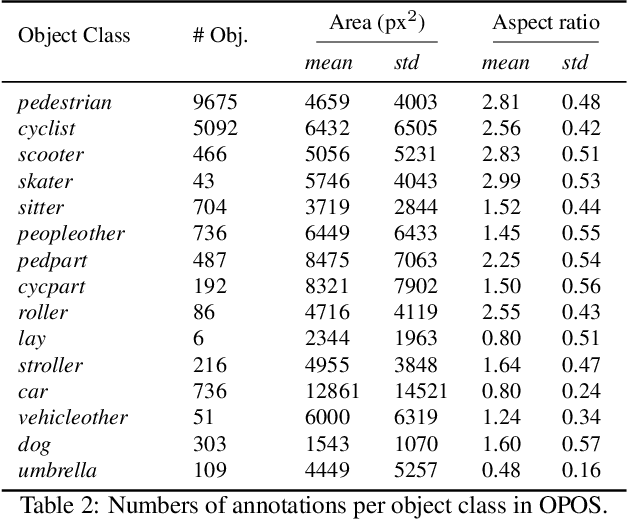
Physical activities and social interactions are essential activities that ensure a healthy lifestyle. Public open spaces (POS), such as parks, plazas and greenways, are key environments that encourage those activities. To evaluate a POS, there is a need to study how humans use the facilities within it. However, traditional approaches to studying use of POS are manual and therefore time and labor intensive. They also may only provide qualitative insights. It is appealing to make use of surveillance cameras and to extract user-related information through computer vision. This paper proposes a proof-of-concept deep learning computer vision framework for measuring human activities quantitatively in POS and demonstrates a case study of the proposed framework using the Detroit Riverfront Conservancy (DRFC) surveillance camera network. A custom image dataset is presented to train the framework; the dataset includes 7826 fully annotated images collected from 18 cameras across the DRFC park space under various illumination conditions. Dataset analysis is also provided as well as a baseline model for one-step user localization and activity recognition. The mAP results are 77.5\% for {\it pedestrian} detection and 81.6\% for {\it cyclist} detection. Behavioral maps are autonomously generated by the framework to locate different POS users and the average error for behavioral localization is within 10 cm.
Constrained Nonnegative Matrix Factorization for Blind Hyperspectral Unmixing incorporating Endmember Independence
Mar 02, 2020
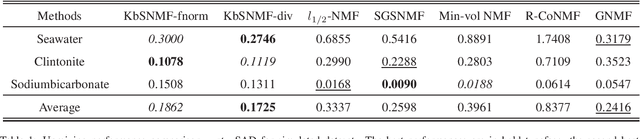
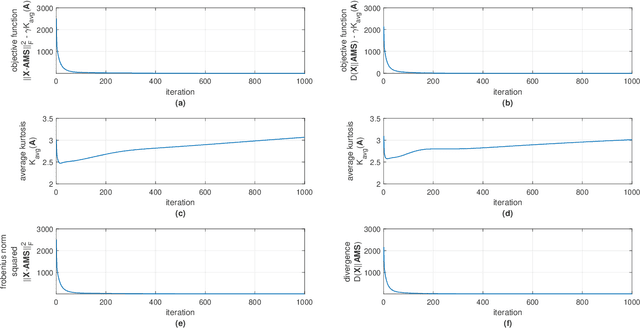
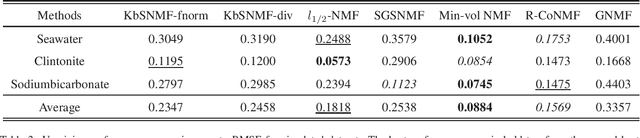
Hyperspectral image (HSI) analysis has become a key area in the field of remote sensing as a result of its ability to exploit richer information in the form of multiple spectral bands. The study of hyperspectral unmixing (HU) is important in HSI analysis due to the insufficient spatial resolution of customary imaging spectrometers. The endmembers of an HSI are more likely to be generated by independent sources and be mixed in a macroscopic degree before arriving at the sensor element of the imaging spectrometer as mixed spectra. Over the past few decades, many attempts have focused on imposing auxiliary constraints on the conventional nonnegative matrix factorization (NMF) framework in order to effectively unmix these mixed spectra. Signifying a step forward toward finding an optimum constraint to extract endmembers, this paper presents a novel blind HU algorithm, referred to as Kurtosis-based Smooth Nonnegative Matrix Factorization (KbSNMF) which incorporates a novel constraint-based on the statistical independence of the probability density functions of endmembers. Imposing this constraint on the conventional NMF framework promotes the extraction of independent endmembers while further enhancing the parts-based representation of data. The proposed algorithm manages to outperform several state of the art NMF-based algorithms in terms of extracting endmembers from hyperspectral remote sensing data, hence could uplift the performance of recent deep learning HU methods which utilizes the endmembers as supervisory data for abundance extraction. Keywords: Hyperspectral unmixing (HU), blind source separation, kurtosis, constrained, Gaussianity, endmember independence, nonnegative matrix factorization (NMF).
The effect of scene context on weakly supervised semantic segmentation
Feb 12, 2019
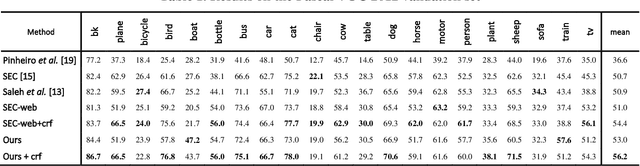
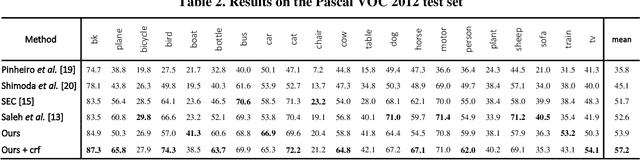

Image semantic segmentation is parsing image into several partitions in such a way that each region of which involves a semantic concept. In a weakly supervised manner, since only image-level labels are available, discriminating objects from the background is challenging, and in some cases, much more difficult. More specifically, some objects which are commonly seen in one specific scene (e.g. 'train' typically is seen on 'railroad track') are much more likely to be confused. In this paper, we propose a method to add the target-specific scenes in order to overcome the aforementioned problem. Actually, we propose a scene recommender which suggests to add some specific scene contexts to the target dataset in order to train the model more accurately. It is notable that this idea could be a complementary part of the baselines of many other methods. The experiments validate the effectiveness of the proposed method for the objects for which the scene context is added.
RED-NET: A Recursive Encoder-Decoder Network for Edge Detection
Dec 05, 2019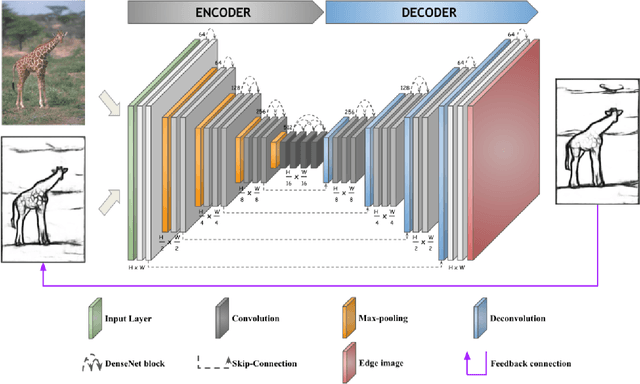

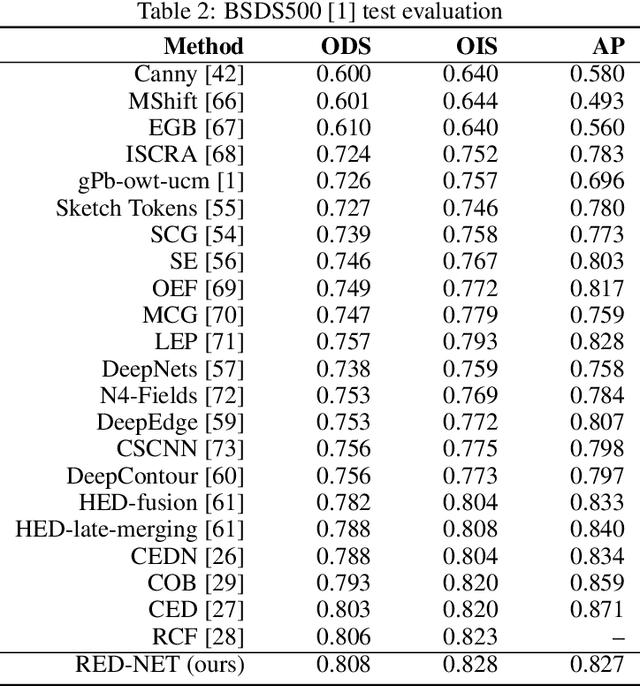
In this paper, we introduce RED-NET: A Recursive Encoder-Decoder Network with Skip-Connections for edge detection in natural images. The proposed network is a novel integration of a Recursive Neural Network with an Encoder-Decoder architecture. The recursive network enables us to increase the network depth without increasing the number of parameters. Adding skip-connections between encoder and decoder helps the gradients reach all the layers of a network more easily and allows information related to finer details in the early stage of the encoder to be fully utilized in the decoder. Based on our extensive experiments on popular boundary detection datasets including BSDS500 \cite{Arbelaez2011}, NYUD \cite{Silberman2012} and Pascal Context \cite{Mottaghi2014}, RED-NET significantly advances the state-of-the-art on edge detection regarding standard evaluation metrics such as Optimal Dataset Scale (ODS) F-measure, Optimal Image Scale (OIS) F-measure, and Average Precision (AP).
Structured Domain Adaptation for Unsupervised Person Re-identification
Mar 14, 2020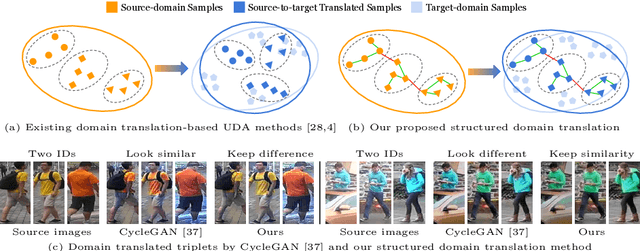
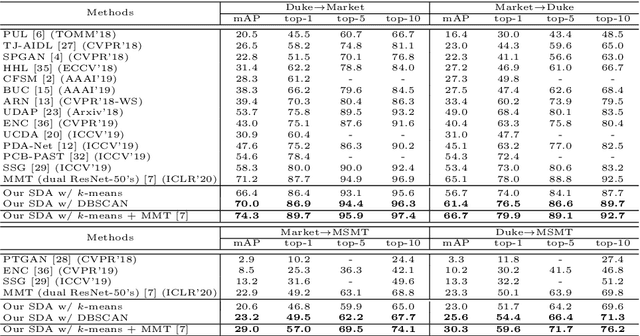
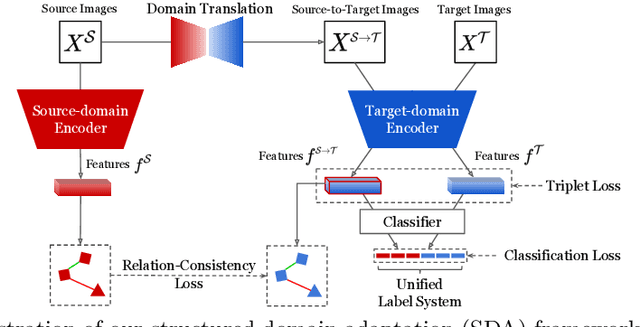
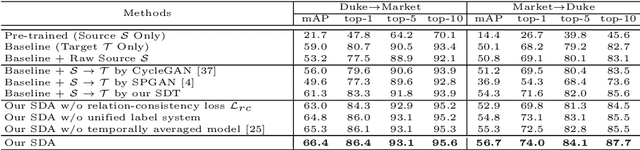
Unsupervised domain adaptation (UDA) aims at adapting the model trained on a labeled source-domain dataset to another target-domain dataset without any annotation. The task of UDA for the open-set person re-identification (re-ID) is even more challenging as the identities (classes) have no overlap between the two domains. Existing UDA methods for person re-ID have the following limitations. 1) Pseudo-label-based methods achieve state-of-the-art performances but ignore the complex relations between two domains' images, along with the valuable source-domain annotations. 2) Domain translation-based methods cannot achieve competitive performances as the domain translation is not properly regularized to generate informative enough training samples that well maintain inter-sample relations. To tackle the above challenges, we propose an end-to-end structured domain adaptation framework that consists of a novel structured domain-translation network and two domain-specific person image encoders. The structured domain-translation network can effectively transform the source-domain images into the target domain while well preserving the original intra- and inter-identity relations. The target-domain encoder could then be trained using both source-to-target translated images with valuable ground-truth labels and target-domain images with pseudo labels. Importantly, the domain-translation network and target-domain encoder are jointly optimized, improving each other towards the overall objective, i.e. to achieve optimal re-ID performances on the target domain. Our proposed framework outperforms state-of-the-art methods on multiple UDA tasks of person re-ID.
Estimating People Flows to Better Count them in Crowded Scenes
Nov 25, 2019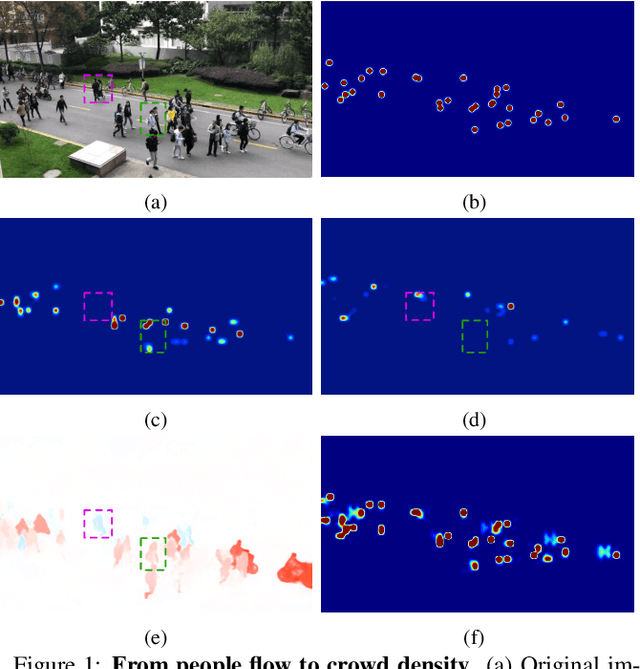
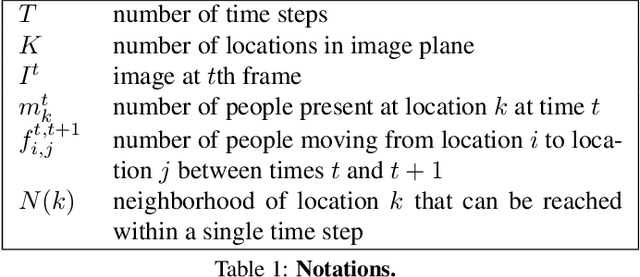
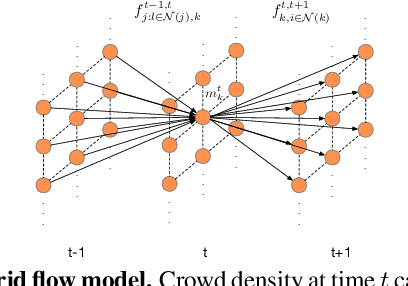
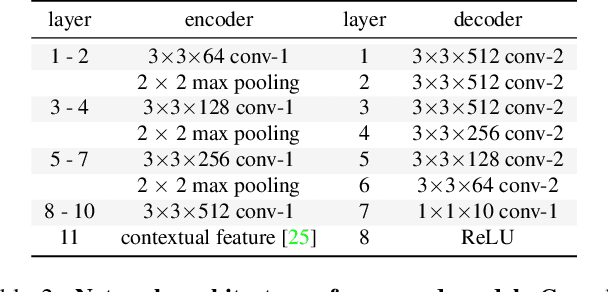
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate people densities in individual images. As such, only very few take advantage of temporal consistency in video sequences, and those that do only impose weak smoothness constraints across consecutive frames. In this paper, we show that estimating people flows across image locations between consecutive images and inferring the people densities from these flows instead of directly regressing them makes it possible to impose much stronger constraints encoding the conservation of the number of people, which significantly boost performance without requiring a more complex architecture. Furthermore, it also enables us to exploit the correlation between people flow and optical flow to further improve the results. We will demonstrate that we consistently outperform state-of-the-art methods on five benchmark datasets.
Cross-Resolution Person Re-identification with Deep Antithetical Learning
Oct 24, 2018
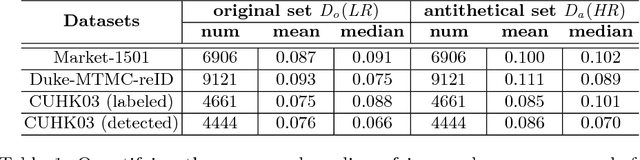
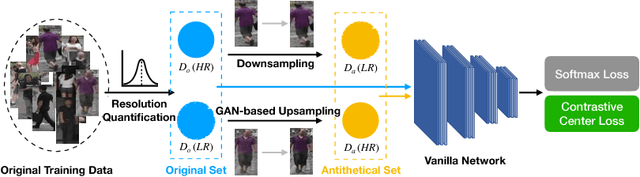
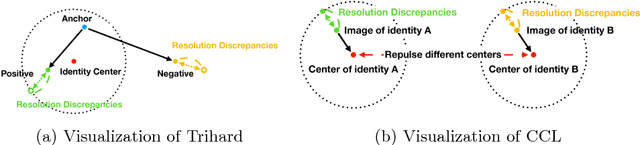
Images with different resolutions are ubiquitous in public person re-identification (ReID) datasets and real-world scenes, it is thus crucial for a person ReID model to handle the image resolution variations for improving its generalization ability. However, most existing person ReID methods pay little attention to this resolution discrepancy problem. One paradigm to deal with this problem is to use some complicated methods for mapping all images into an artificial image space, which however will disrupt the natural image distribution and requires heavy image preprocessing. In this paper, we analyze the deficiencies of several widely-used objective functions handling image resolution discrepancies and propose a new framework called deep antithetical learning that directly learns from the natural image space rather than creating an arbitrary one. We first quantify and categorize original training images according to their resolutions. Then we create an antithetical training set and make sure that original training images have counterparts with antithetical resolutions in this new set. At last, a novel Contrastive Center Loss(CCL) is proposed to learn from images with different resolutions without being interfered by their resolution discrepancies. Extensive experimental analyses and evaluations indicate that the proposed framework, even using a vanilla deep ReID network, exhibits remarkable performance improvements. Without bells and whistles, our approach outperforms previous state-of-the-art methods by a large margin.