 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Network Representation Control: Gaussian Isolation Machines and CVC Regularization
Feb 06, 2020
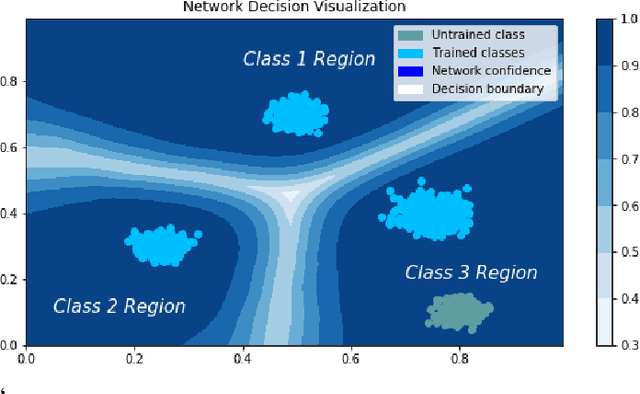

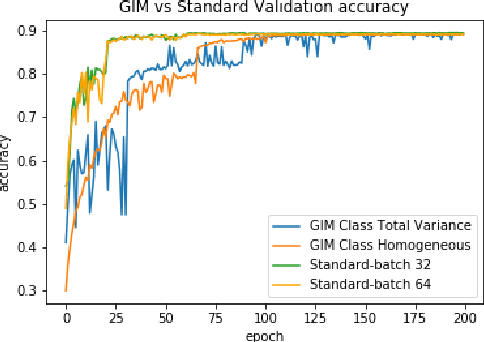
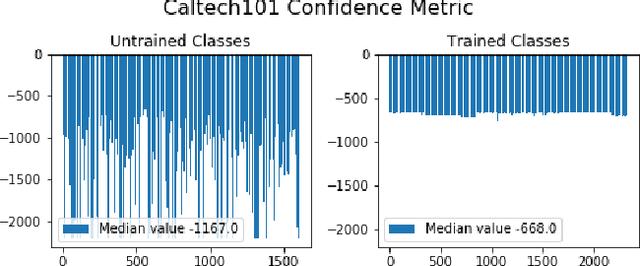
In many cases, neural network classifiers are likely to be exposed to input data that is outside of their training distribution data. Samples from outside the distribution may be classified as an existing class with high probability by softmax-based classifiers; such incorrect classifications affect the performance of the classifiers and the applications/systems that depend on them. Previous research aimed at distinguishing training distribution data from out-of-distribution data (OOD) has proposed detectors that are external to the classification method. We present Gaussian isolation machine (GIM), a novel hybrid (generative-discriminative) classifier aimed at solving the problem arising when OOD data is encountered. The GIM is based on a neural network and utilizes a new loss function that imposes a distribution on each of the trained classes in the neural network's output space, which can be approximated by a Gaussian. The proposed GIM's novelty lies in its discriminative performance and generative capabilities, a combination of characteristics not usually seen in a single classifier. The GIM achieves state-of-the-art classification results on image recognition and sentiment analysis benchmarking datasets and can also deal with OOD inputs. We also demonstrate the benefits of incorporating part of the GIM's loss function into standard neural networks as a regularization method.
Expert Sample Consensus Applied to Camera Re-Localization
Aug 07, 2019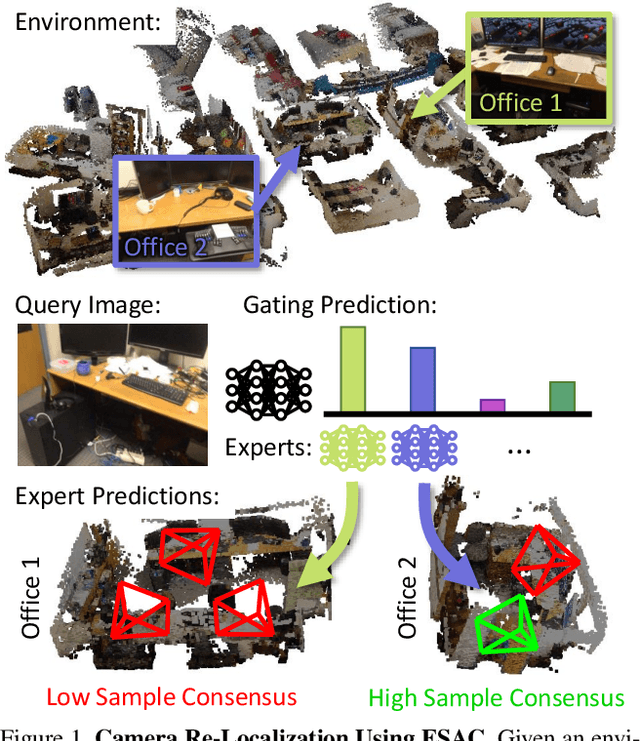
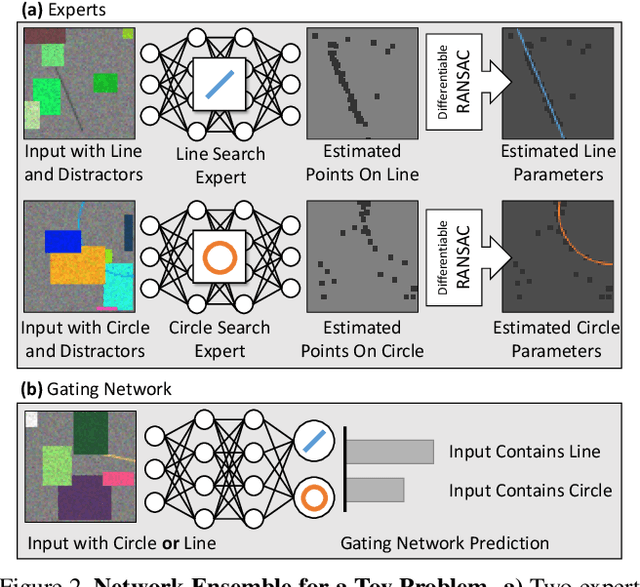
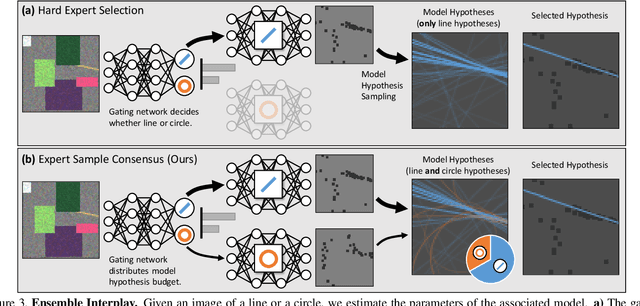
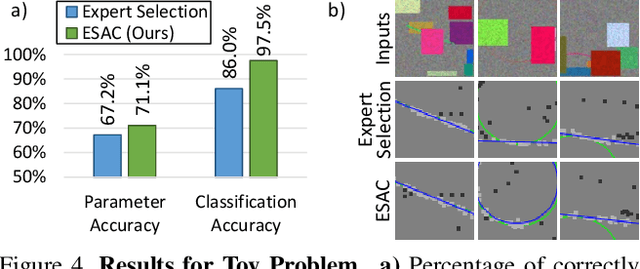
Fitting model parameters to a set of noisy data points is a common problem in computer vision. In this work, we fit the 6D camera pose to a set of noisy correspondences between the 2D input image and a known 3D environment. We estimate these correspondences from the image using a neural network. Since the correspondences often contain outliers, we utilize a robust estimator such as Random Sample Consensus (RANSAC) or Differentiable RANSAC (DSAC) to fit the pose parameters. When the problem domain, e.g. the space of all 2D-3D correspondences, is large or ambiguous, a single network does not cover the domain well. Mixture of Experts (MoE) is a popular strategy to divide a problem domain among an ensemble of specialized networks, so called experts, where a gating network decides which expert is responsible for a given input. In this work, we introduce Expert Sample Consensus (ESAC), which integrates DSAC in a MoE. Our main technical contribution is an efficient method to train ESAC jointly and end-to-end. We demonstrate experimentally that ESAC handles two real-world problems better than competing methods, i.e. scalability and ambiguity. We apply ESAC to fitting simple geometric models to synthetic images, and to camera re-localization for difficult, real datasets.
OmniTact: A Multi-Directional High Resolution Touch Sensor
Mar 16, 2020



Incorporating touch as a sensing modality for robots can enable finer and more robust manipulation skills. Existing tactile sensors are either flat, have small sensitive fields or only provide low-resolution signals. In this paper, we introduce OmniTact, a multi-directional high-resolution tactile sensor. OmniTact is designed to be used as a fingertip for robotic manipulation with robotic hands, and uses multiple micro-cameras to detect multi-directional deformations of a gel-based skin. This provides a rich signal from which a variety of different contact state variables can be inferred using modern image processing and computer vision methods. We evaluate the capabilities of OmniTact on a challenging robotic control task that requires inserting an electrical connector into an outlet, as well as a state estimation problem that is representative of those typically encountered in dexterous robotic manipulation, where the goal is to infer the angle of contact of a curved finger pressing against an object. Both tasks are performed using only touch sensing and deep convolutional neural networks to process images from the sensor's cameras. We compare with a state-of-the-art tactile sensor that is only sensitive on one side, as well as a state-of-the-art multi-directional tactile sensor, and find that OmniTact's combination of high-resolution and multi-directional sensing is crucial for reliably inserting the electrical connector and allows for higher accuracy in the state estimation task. Videos and supplementary material can be found at https://sites.google.com/berkeley.edu/omnitact
Eye Semantic Segmentation with a Lightweight Model
Nov 04, 2019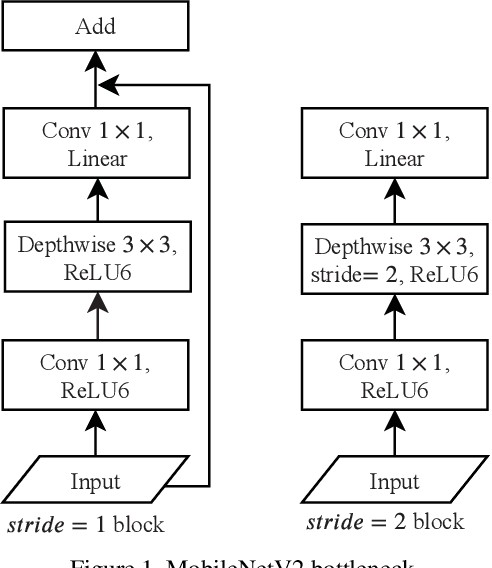
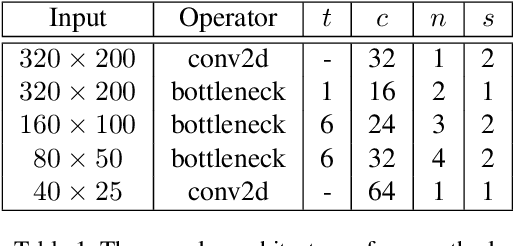
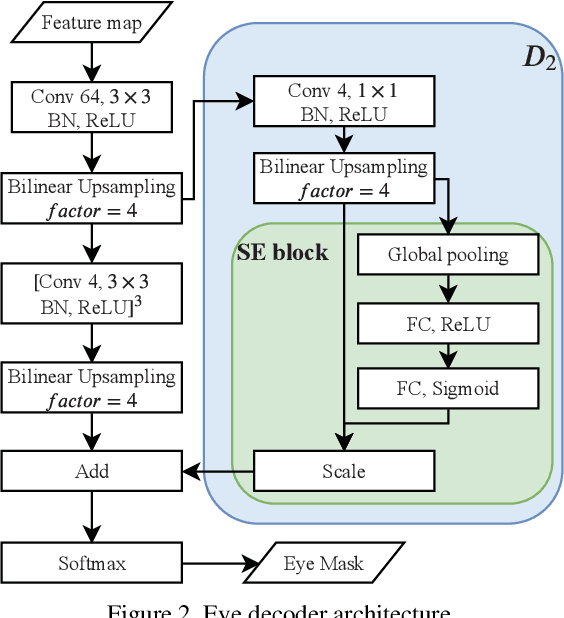
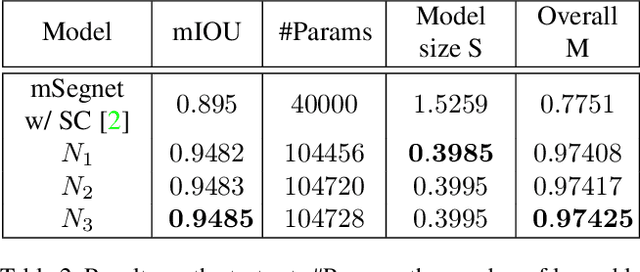
In this paper, we present a multi-class eye segmentation method that can run the hardware limitations for real-time inference. Our approach includes three major stages: get a grayscale image from the input, segment three distinct eye region with a deep network, and remove incorrect areas with heuristic filters. Our model based on the encoder decoder structure with the key is the depthwise convolution operation to reduce the computation cost. We experiment on OpenEDS, a large scale dataset of eye images captured by a head-mounted display with two synchronized eye facing cameras. We achieved the mean intersection over union (mIoU) of 94.85% with a model of size 0.4 megabytes. The source code are available https://github.com/th2l/Eye_VR_Segmentation
Image segmentation by adaptive distance based on EM algorithm
Apr 07, 2012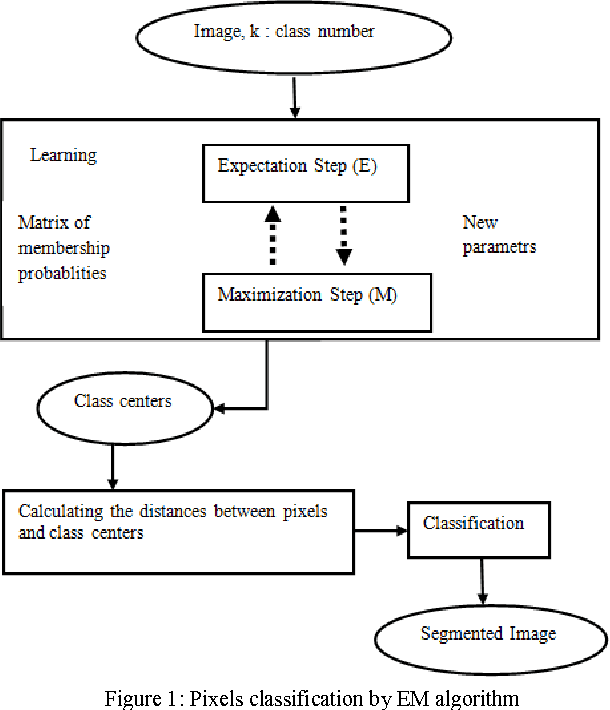
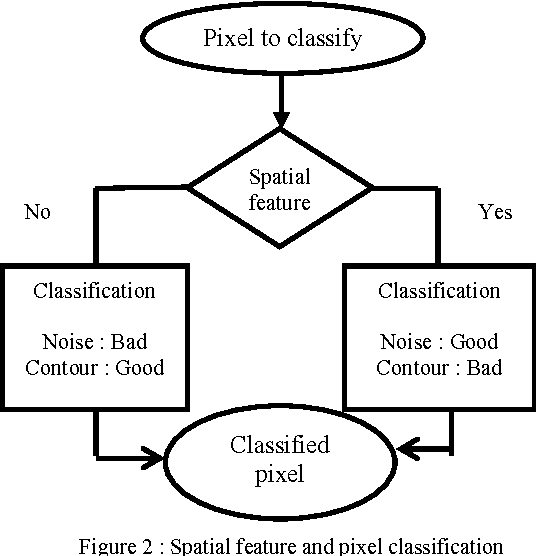
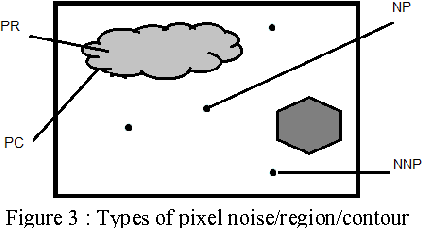
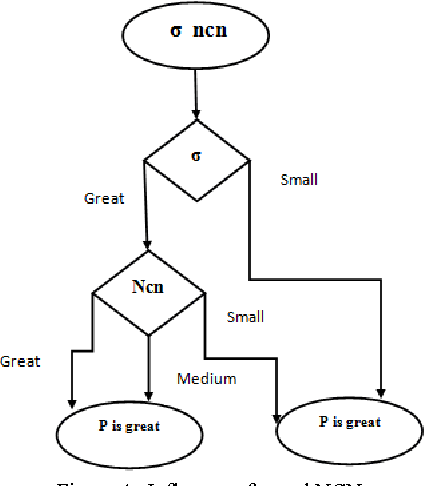
This paper introduces a Bayesian image segmentation algorithm based on finite mixtures. An EM algorithm is developed to estimate parameters of the Gaussian mixtures. The finite mixture is a flexible and powerful probabilistic modeling tool. It can be used to provide a model-based clustering in the field of pattern recognition. However, the application of finite mixtures to image segmentation presents some difficulties; especially it's sensible to noise. In this paper we propose a variant of this method which aims to resolve this problem. Our approach proceeds by the characterization of pixels by two features: the first one describes the intrinsic properties of the pixel and the second characterizes the neighborhood of pixel. Then the classification is made on the base on adaptive distance which privileges the one or the other features according to the spatial position of the pixel in the image. The obtained results have shown a significant improvement of our approach compared to the standard version of EM algorithm.
* 6 pages
Compressed MRI Reconstruction Exploiting a Rotation-Invariant Total Variation Discretization
Nov 26, 2019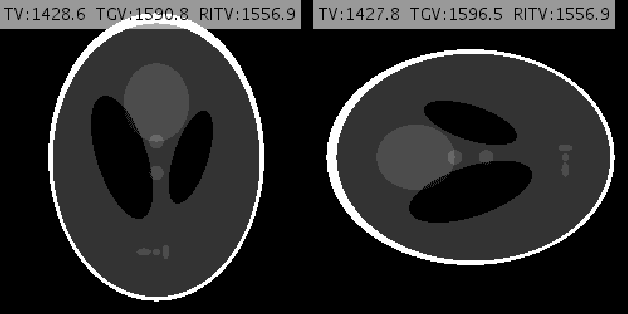
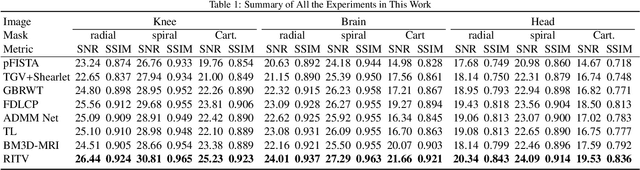
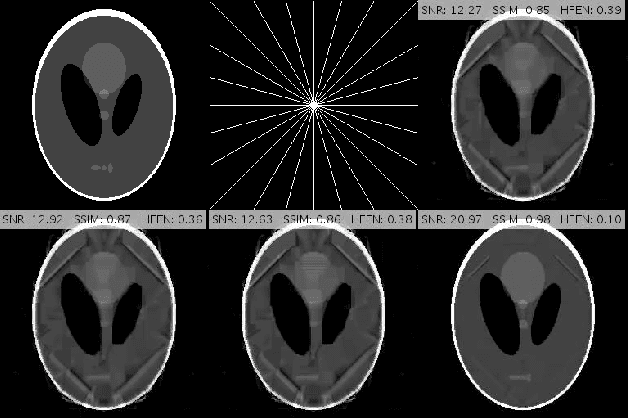
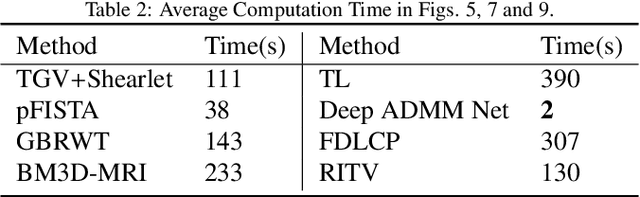
Inspired by the first-order method of Malitsky and Pock, we propose a novel variational framework for compressed MR image reconstruction which introduces the application of a rotation-invariant discretization of total variation functional into MR imaging while exploiting BM3D frame as a sparsifying transform. The proposed model is presented as a constrained optimization problem, however, we do not use conventional ADMM-type algorithms designed for constrained problems to obtain a solution, but rather we tailor the linesearch-equipped method of Malitsky and Pock to our model, which was originally proposed for unconstrained problems. As attested by numerical experiments, this framework significantly outperforms various state-of-the-art algorithms from variational methods to adaptive and learning approaches and in particular, it eliminates the stagnating behavior of a previous work on BM3D-MRI which compromised the solution beyond a certain iteration.
SuperGlue: Learning Feature Matching with Graph Neural Networks
Nov 26, 2019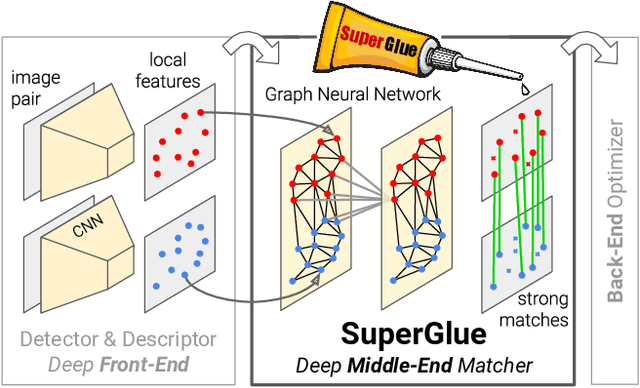
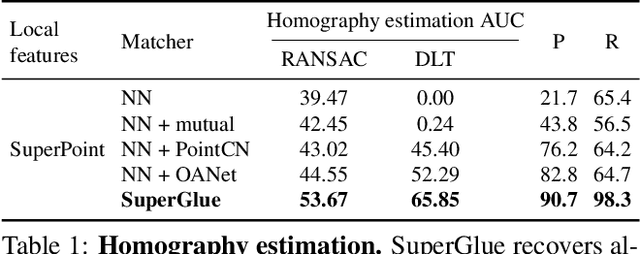

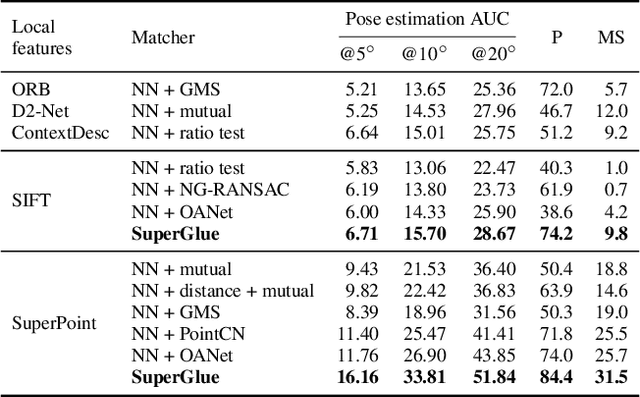
This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems.
Anatomy-Aware Self-supervised Fetal MRI Synthesis from Unpaired Ultrasound Images
Sep 08, 2019

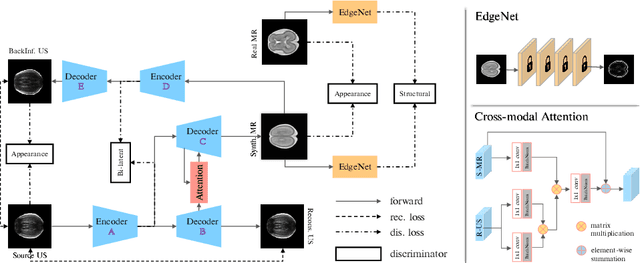
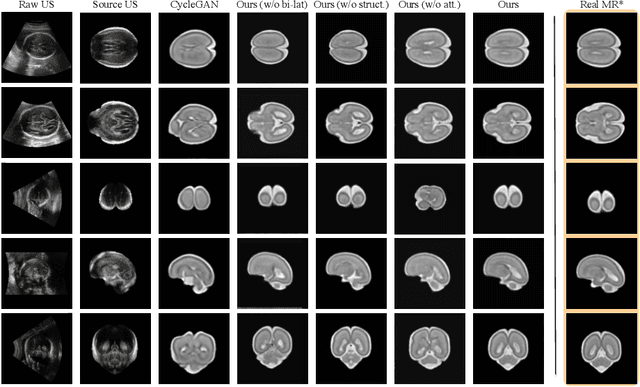
Fetal brain magnetic resonance imaging (MRI) offers exquisite images of the developing brain but is not suitable for anomaly screening. For this ultrasound (US) is employed. While expert sonographers are adept at reading US images, MR images are much easier for non-experts to interpret. Hence in this paper we seek to produce images with MRI-like appearance directly from clinical US images. Our own clinical motivation is to seek a way to communicate US findings to patients or clinical professionals unfamiliar with US, but in medical image analysis such a capability is potentially useful, for instance, for US-MRI registration or fusion. Our model is self-supervised and end-to-end trainable. Specifically, based on an assumption that the US and MRI data share a similar anatomical latent space, we first utilise an extractor to determine shared latent features, which are then used for data synthesis. Since paired data was unavailable for our study (and rare in practice), we propose to enforce the distributions to be similar instead of employing pixel-wise constraints, by adversarial learning in both the image domain and latent space. Furthermore, we propose an adversarial structural constraint to regularise the anatomical structures between the two modalities during the synthesis. A cross-modal attention scheme is proposed to leverage non-local spatial correlations. The feasibility of the approach to produce realistic looking MR images is demonstrated quantitatively and with a qualitative evaluation compared to real fetal MR images.
Extract an essential skeleton of a character as a graph from a character image
Jun 13, 2015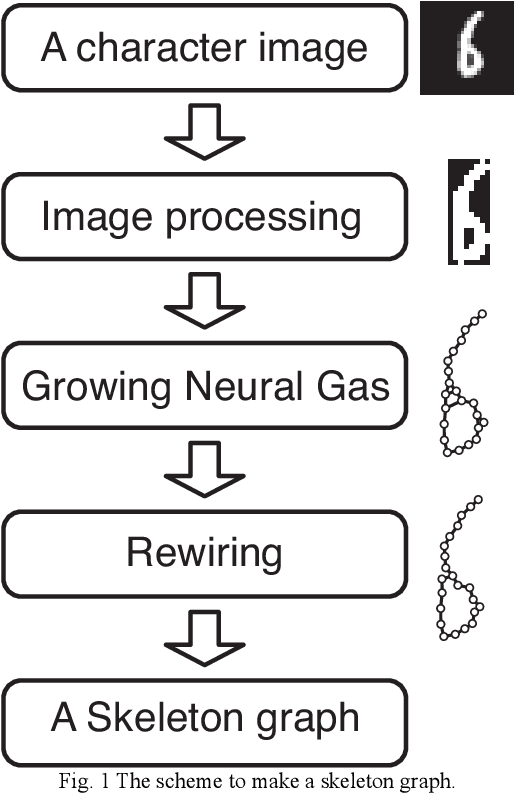
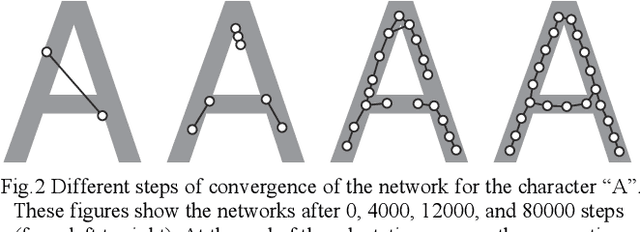
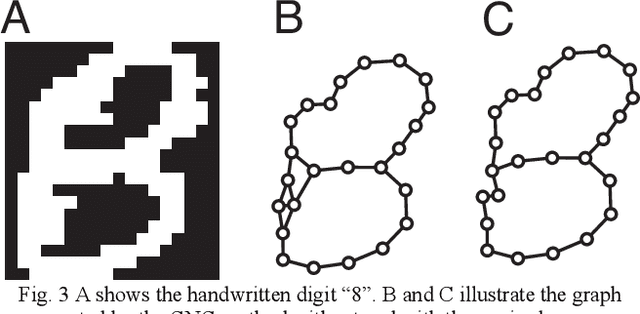

This paper aims to make a graph representing an essential skeleton of a character from an image that includes a machine printed or a handwritten character using the growing neural gas (GNG) method and the relative neighborhood graph (RNG) algorithm. The visual system in our brain can recognize printed characters and handwritten characters easily, robustly, and precisely. How can our brains robustly recognize characters? In the visual processing in our brain, essential features of an object will be used for recognition. The essential features are crosses, corners, junctions and so on. These features may be useful for character recognition by a computer. However, extraction of the features is difficult. If the skeleton of a character is represented as a graph, the features can be more easily extracted. To extract the skeleton of a character as a graph from a character image, we used the GNG method and the RNG algorithm. We achieved to extract skeleton graphs from images including distorted, noisy, and handwritten characters.
HR-CAM: Precise Localization of Pathology Using Multi-level Learning in CNNs
Sep 23, 2019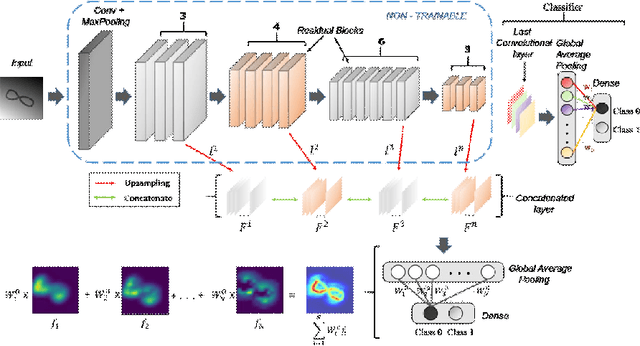
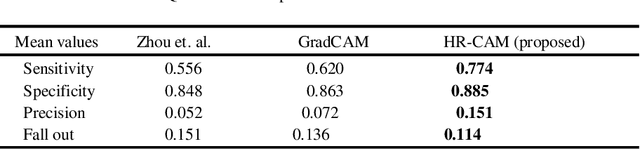
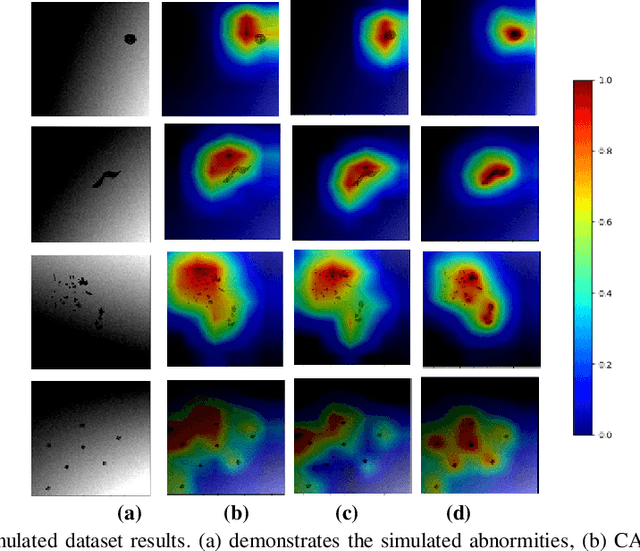
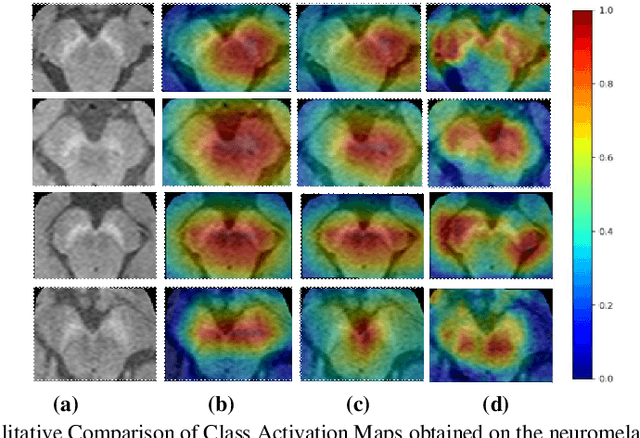
We propose a CNN based technique that aggregates feature maps from its multiple layers that can localize abnormalities with greater details as well as predict pathology under consideration. Existing class activation mapping (CAM) techniques extract feature maps from either the final layer or a single intermediate layer to create the discriminative maps and then interpolate to upsample to the original image resolution. In this case, the subject specific localization is coarse and is unable to capture subtle abnormalities. To mitigate this, our method builds a novel CNN based discriminative localization model that we call high resolution CAM (HR-CAM), which accounts for layers from each resolution, therefore facilitating a comprehensive map that can delineate the pathology for each subject by combining low-level, intermediate as well as high-level features from the CNN. Moreover, our model directly provides the discriminative map in the resolution of the original image facilitating finer delineation of abnormalities. We demonstrate the working of our model on a simulated abnormalities data where we illustrate how the model captures finer details in the final discriminative maps as compared to current techniques. We then apply this technique: (1) to classify ependymomas from grade IV glioblastoma on T1-weighted contrast enhanced (T1-CE) MRI and (2) to predict Parkinson's disease from neuromelanin sensitive MRI. In all these cases we demonstrate that our model not only predicts pathologies with high accuracies, but also creates clinically interpretable subject specific high resolution discriminative localizations. Overall, the technique can be generalized to any CNN and carries high relevance in a clinical setting.