 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuous Meta-Learning without Tasks
Dec 18, 2019
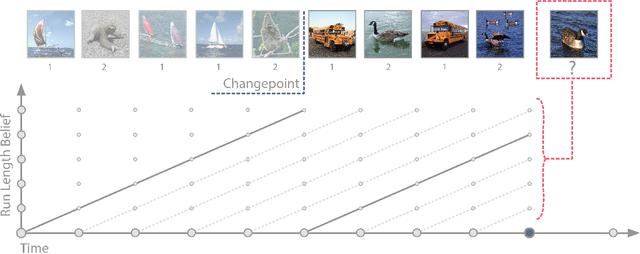
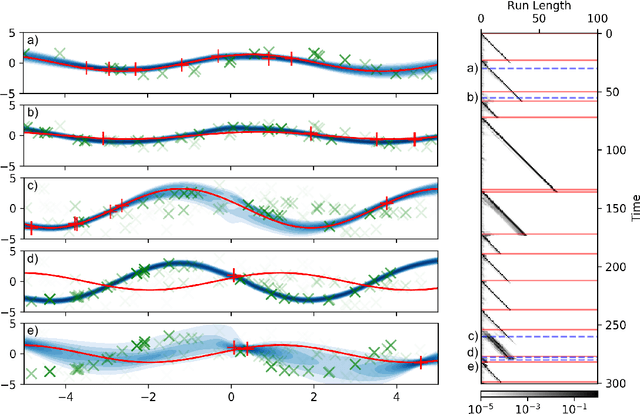

Meta-learning is a promising strategy for learning to efficiently learn within new tasks, using data gathered from a distribution of tasks. However, the meta-learning literature thus far has focused on the task segmented setting, where at train-time, offline data is assumed to be split according to the underlying task, and at test-time, the algorithms are optimized to learn in a single task. In this work, we enable the application of generic meta-learning algorithms to settings where this task segmentation is unavailable, such as continual online learning with a time-varying task. We present meta-learning via online changepoint analysis (MOCA), an approach which augments a meta-learning algorithm with a differentiable Bayesian changepoint detection scheme. The framework allows both training and testing directly on time series data without segmenting it into discrete tasks. We demonstrate the utility of this approach on a nonlinear meta-regression benchmark as well as two meta-image-classification benchmarks.
Graph4Code: A Machine Interpretable Knowledge Graph for Code
Feb 21, 2020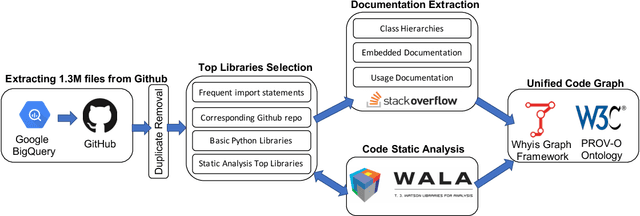
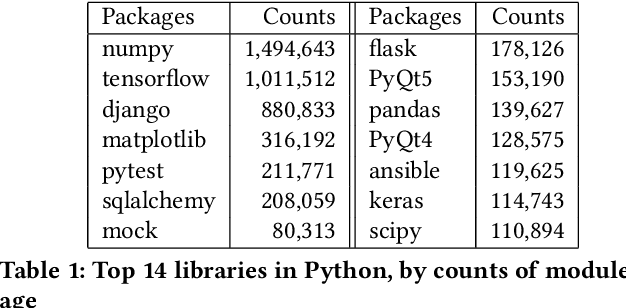
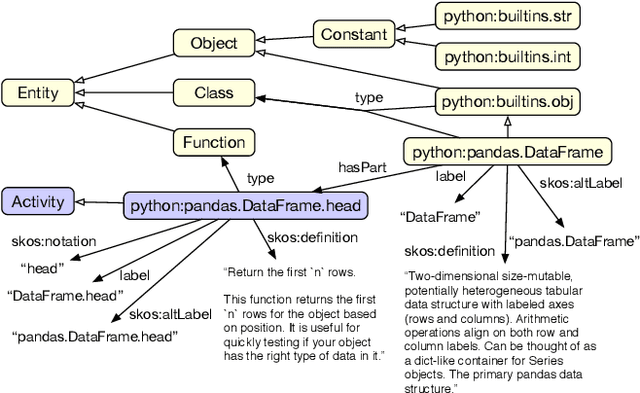

Knowledge graphs have proven to be extremely useful in powering diverse applications in semantic search, natural language understanding, and even image classification. Graph4Code attempts to build well structured knowledge graphs about program code to similarly revolutionize diverse applications such as code search, code understanding, refactoring, bug detection, and code automation. We build such a graph by applying a set of generic code analysis techniques to Python code on the web. Since use of popular Python modules is ubiquitous in code, calls to functions in Python modules serve as key nodes of the knowledge graph. The edges in the graph are based on 1) function usage in the wild (e.g., which other function tends to call this one, or which function tends to precede this one, as gleaned from program analysis), 2) documentation about the function (e.g., code documentation, usage documentation, or forum discussions such as StackOverflow), and 3) program specific features such as class hierarchies. We use the Whyis knowledge graph management framework to make the graph easily extensible. We apply these techniques to 1.3M Python files drawn from GitHub, and associated documentation on the web for over 400 popular libraries, as well as StackOverflow posts about the same set of libraries. This knowledge graph will be made available soon to the larger community for use.
Image segmentation by adaptive distance based on EM algorithm
Apr 07, 2012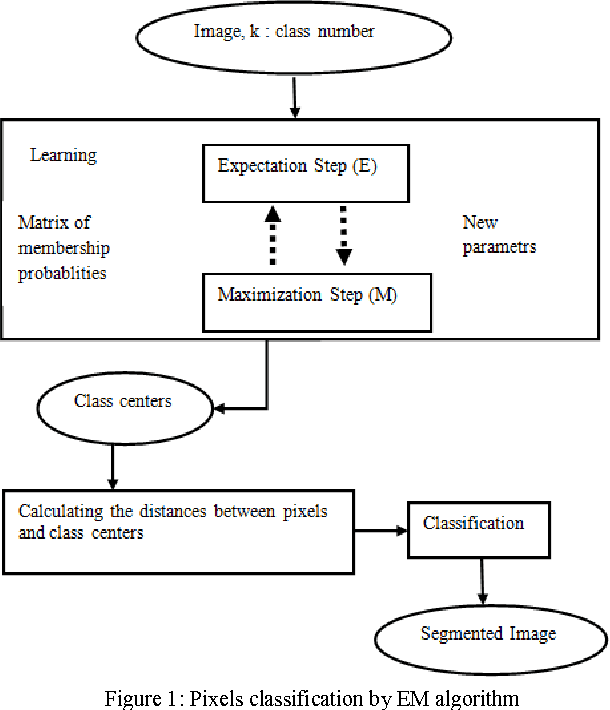
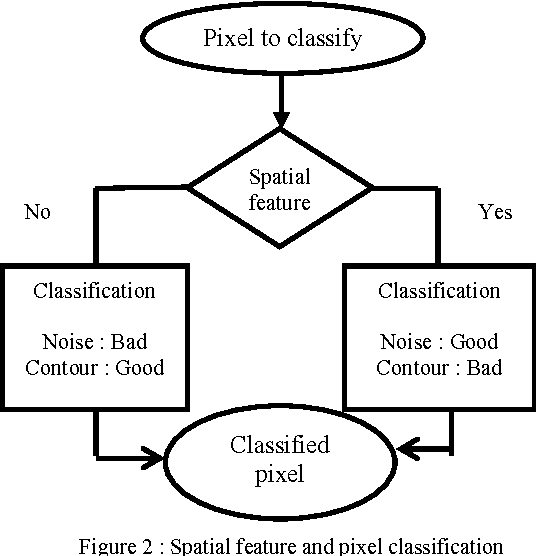
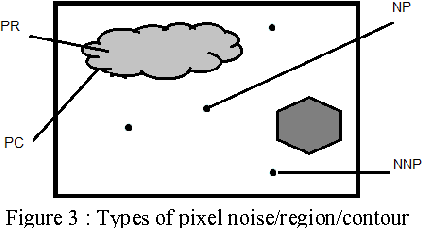
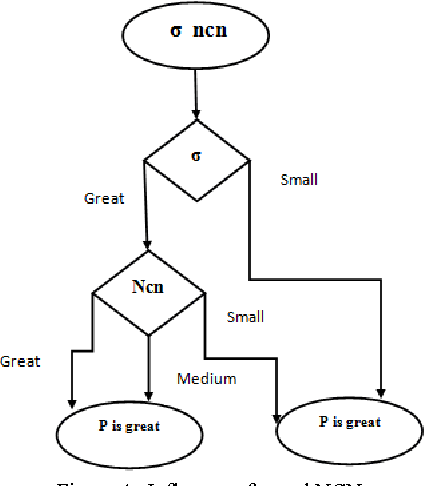
This paper introduces a Bayesian image segmentation algorithm based on finite mixtures. An EM algorithm is developed to estimate parameters of the Gaussian mixtures. The finite mixture is a flexible and powerful probabilistic modeling tool. It can be used to provide a model-based clustering in the field of pattern recognition. However, the application of finite mixtures to image segmentation presents some difficulties; especially it's sensible to noise. In this paper we propose a variant of this method which aims to resolve this problem. Our approach proceeds by the characterization of pixels by two features: the first one describes the intrinsic properties of the pixel and the second characterizes the neighborhood of pixel. Then the classification is made on the base on adaptive distance which privileges the one or the other features according to the spatial position of the pixel in the image. The obtained results have shown a significant improvement of our approach compared to the standard version of EM algorithm.
* 6 pages
Attend To Count: Crowd Counting with Adaptive Capacity Multi-scale CNNs
Aug 07, 2019
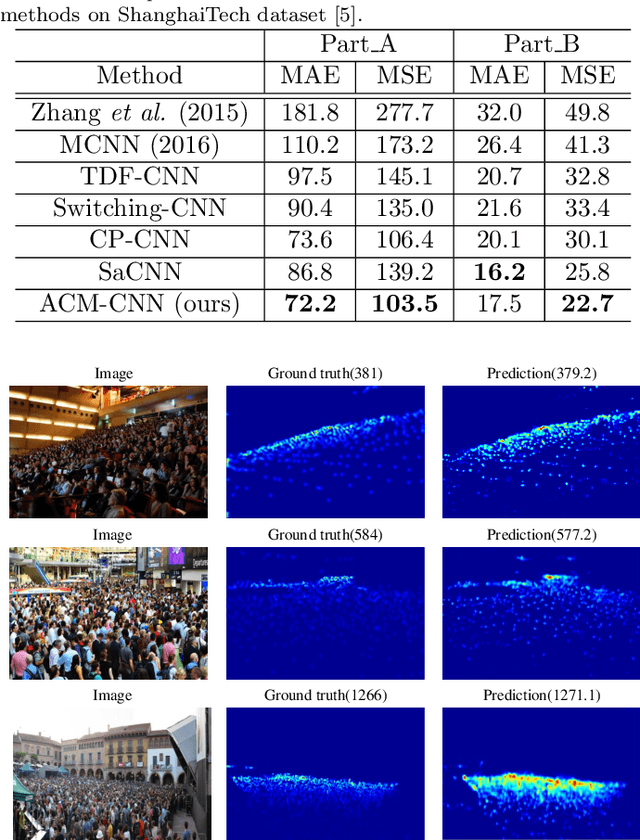
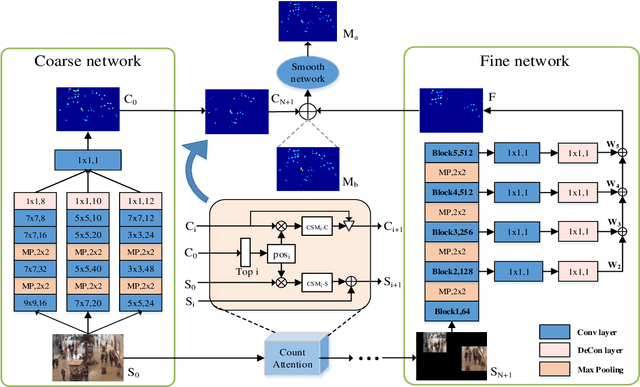
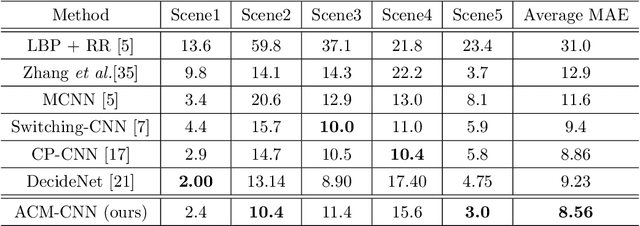
Crowd counting is a challenging task due to the large variations in crowd distributions. Previous methods tend to tackle the whole image with a single fixed structure, which is unable to handle diverse complicated scenes with different crowd densities. Hence, we propose the Adaptive Capacity Multi-scale convolutional neural networks (ACM-CNN), a novel crowd counting approach which can assign different capacities to different portions of the input. The intuition is that the model should focus on important regions of the input image and optimize its capacity allocation conditioning on the crowd intensive degree. ACM-CNN consists of three types of modules: a coarse network, a fine network, and a smooth network. The coarse network is used to explore the areas that need to be focused via count attention mechanism, and generate a rough feature map. Then the fine network processes the areas of interest into a fine feature map. To alleviate the sense of division caused by fusion, the smooth network is designed to combine two feature maps organically to produce high-quality density maps. Extensive experiments are conducted on five mainstream datasets. The results demonstrate the effectiveness of the proposed model for both density estimation and crowd counting tasks.
Weakly-Supervised Salient Object Detection via Scribble Annotations
Mar 17, 2020
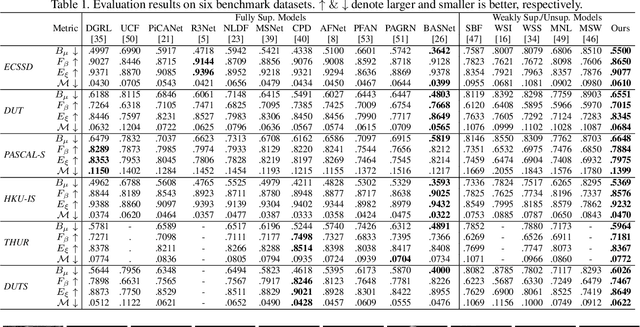
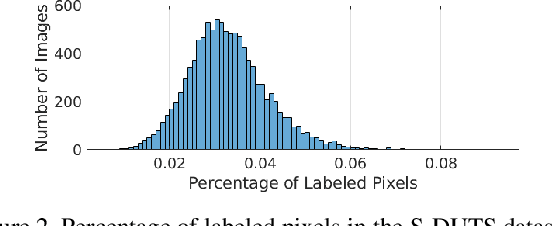
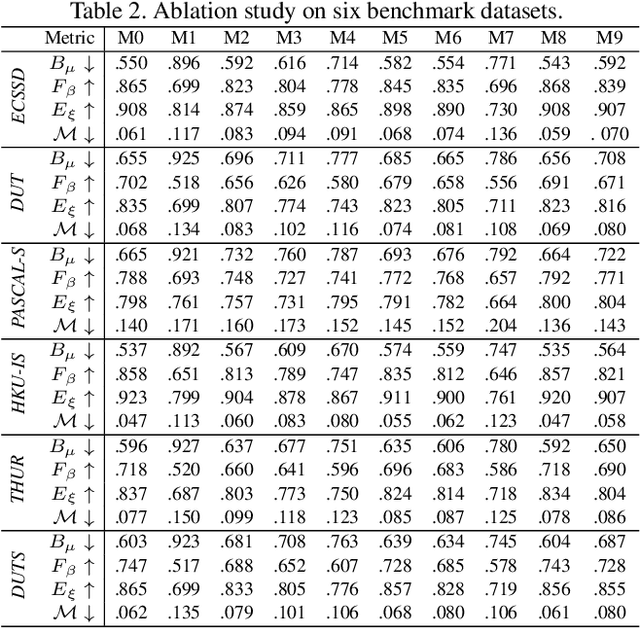
Compared with laborious pixel-wise dense labeling, it is much easier to label data by scribbles, which only costs 1$\sim$2 seconds to label one image. However, using scribble labels to learn salient object detection has not been explored. In this paper, we propose a weakly-supervised salient object detection model to learn saliency from such annotations. In doing so, we first relabel an existing large-scale salient object detection dataset with scribbles, namely S-DUTS dataset. Since object structure and detail information is not identified by scribbles, directly training with scribble labels will lead to saliency maps of poor boundary localization. To mitigate this problem, we propose an auxiliary edge detection task to localize object edges explicitly, and a gated structure-aware loss to place constraints on the scope of structure to be recovered. Moreover, we design a scribble boosting scheme to iteratively consolidate our scribble annotations, which are then employed as supervision to learn high-quality saliency maps. As existing saliency evaluation metrics neglect to measure structure alignment of the predictions, the saliency map ranking metric may not comply with human perception. We present a new metric, termed saliency structure measure, to measure the structure alignment of the predicted saliency maps, which is more consistent with human perception. Extensive experiments on six benchmark datasets demonstrate that our method not only outperforms existing weakly-supervised/unsupervised methods, but also is on par with several fully-supervised state-of-the-art models. Our code and data is publicly available at https://github.com/JingZhang617/Scribble_Saliency.
Deep Convolutional Ranking for Multilabel Image Annotation
Apr 14, 2014


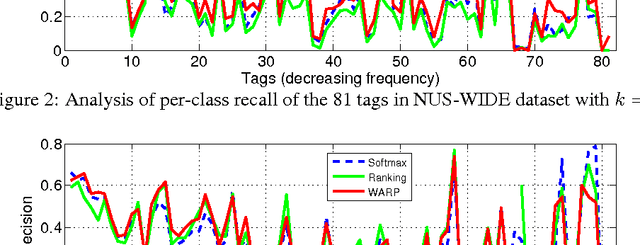
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.
CNN-based Density Estimation and Crowd Counting: A Survey
Mar 28, 2020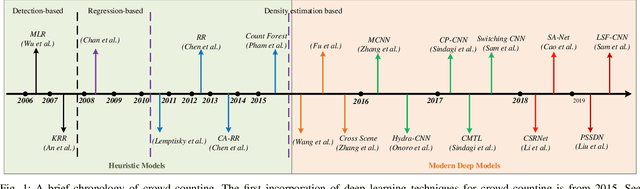
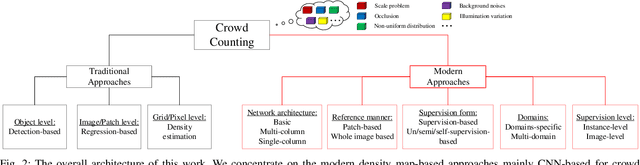
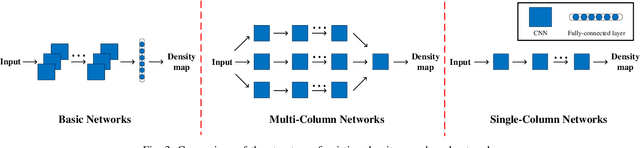

Accurately estimating the number of objects in a single image is a challenging yet meaningful task and has been applied in many applications such as urban planning and public safety. In the various object counting tasks, crowd counting is particularly prominent due to its specific significance to social security and development. Fortunately, the development of the techniques for crowd counting can be generalized to other related fields such as vehicle counting and environment survey, if without taking their characteristics into account. Therefore, many researchers are devoting to crowd counting, and many excellent works of literature and works have spurted out. In these works, they are must be helpful for the development of crowd counting. However, the question we should consider is why they are effective for this task. Limited by the cost of time and energy, we cannot analyze all the algorithms. In this paper, we have surveyed over 220 works to comprehensively and systematically study the crowd counting models, mainly CNN-based density map estimation methods. Finally, according to the evaluation metrics, we select the top three performers on their crowd counting datasets and analyze their merits and drawbacks. Through our analysis, we expect to make reasonable inference and prediction for the future development of crowd counting, and meanwhile, it can also provide feasible solutions for the problem of object counting in other fields. We provide the density maps and prediction results of some mainstream algorithm in the validation set of NWPU dataset for comparison and testing. Meanwhile, density map generation and evaluation tools are also provided. All the codes and evaluation results are made publicly available at https://github.com/gaoguangshuai/survey-for-crowd-counting.
Are Perceptually-Aligned Gradients a General Property of Robust Classifiers?
Oct 23, 2019



For a standard convolutional neural network, optimizing over the input pixels to maximize the score of some target class will generally produce a grainy-looking version of the original image. However, Santurkar et al. (2019) demonstrated that for adversarially-trained neural networks, this optimization produces images that uncannily resemble the target class. In this paper, we show that these "perceptually-aligned gradients" also occur under randomized smoothing, an alternative means of constructing adversarially-robust classifiers. Our finding supports the hypothesis that perceptually-aligned gradients may be a general property of robust classifiers. We hope that our results will inspire research aimed at explaining this link between perceptually-aligned gradients and adversarial robustness.
SpatialSense: An Adversarially Crowdsourced Benchmark for Spatial Relation Recognition
Aug 07, 2019
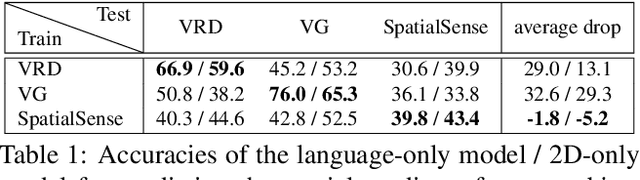
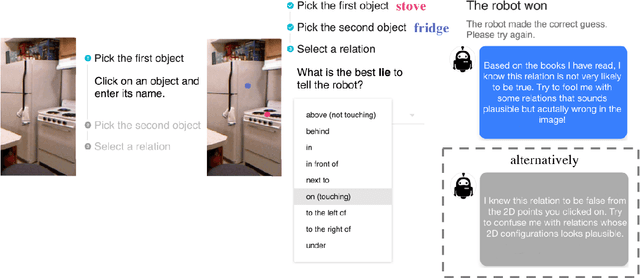
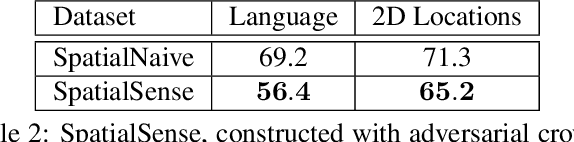
Understanding the spatial relations between objects in images is a surprisingly challenging task. A chair may be "behind" a person even if it appears to the left of the person in the image (depending on which way the person is facing). Two students that appear close to each other in the image may not in fact be "next to" each other if there is a third student between them. We introduce SpatialSense, a dataset specializing in spatial relation recognition which captures a broad spectrum of such challenges, allowing for proper benchmarking of computer vision techniques. SpatialSense is constructed through adversarial crowdsourcing, in which human annotators are tasked with finding spatial relations that are difficult to predict using simple cues such as 2D spatial configuration or language priors. Adversarial crowdsourcing significantly reduces dataset bias and samples more interesting relations in the long tail compared to existing datasets. On SpatialSense, state-of-the-art recognition models perform comparably to simple baselines, suggesting that they rely on straightforward cues instead of fully reasoning about this complex task. The SpatialSense benchmark provides a path forward to advancing the spatial reasoning capabilities of computer vision systems. The dataset and code are available at https://github.com/princeton-vl/SpatialSense.
Synthetic dataset generation for object-to-model deep learning in industrial applications
Sep 24, 2019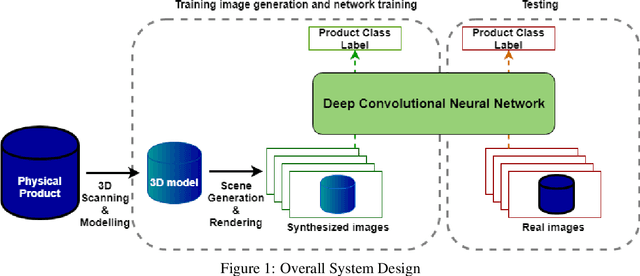
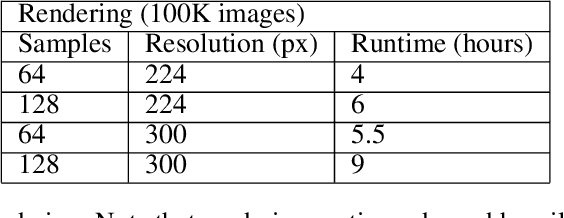
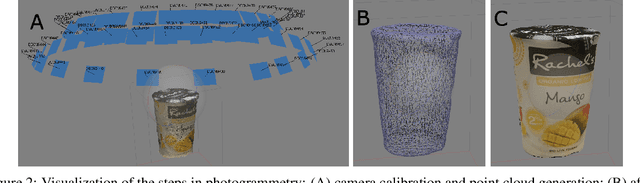

The availability of large image data sets has been a crucial factor in the success of deep learning-based classification and detection methods. While data sets for everyday objects are widely available, data for specific industrial use-cases (e.g. identifying packaged products in a warehouse) remains scarce. In such cases, the data sets have to be created from scratch, placing a crucial bottleneck on the deployment of deep learning techniques in industrial applications. We present work carried out in collaboration with a leading UK online supermarket, with the aim of creating a computer vision system capable of detecting and identifying unique supermarket products in a warehouse setting. To this end, we demonstrate a framework for using synthetic data to create an end-to-end deep learning pipeline, beginning with real-world objects and culminating in a trained model. Our method is based on the generation of a synthetic dataset from 3D models obtained by applying photogrammetry techniques to real-world objects. Using 100k synthetic images generated from 60 real images per class, an InceptionV3 convolutional neural network (CNN) was trained, which achieved classification accuracy of 95.8% on a separately acquired test set of real supermarket product images. The image generation process supports automatic pixel annotation. This eliminates the prohibitively expensive manual annotation typically required for detection tasks. Based on this readily available data, a one-stage RetinaNet detector was trained on the synthetic, annotated images to produce a detector that can accurately localize and classify the specimen products in real-time.