 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Color Edge Detection Algorithm Based on Quaternion Hardy Filter
Jul 17, 2018

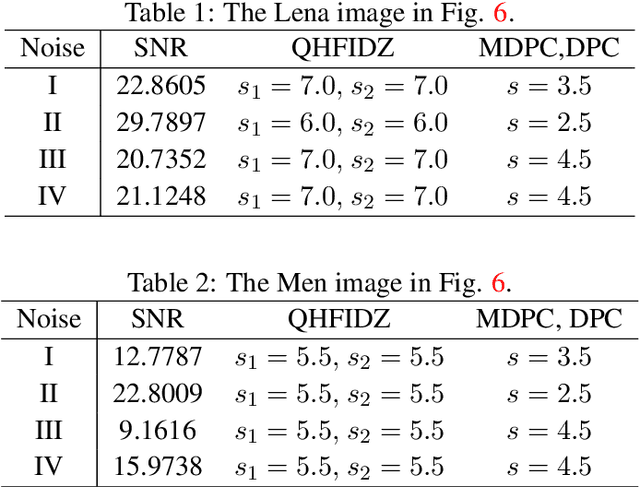
A study on color edge detection using the improved Di Zenzo's gradient operator associated with quaternion Hardy filter is presented. The Di Zenzo gradient operator recently achieved great attentions in edge detection, but it is sensitive to image with additive noise. The quaternion Hardy filter demonstrates its advantage in denoising image. A robust color image edge detection algorithm called Quaternion Hardy filter with the improved Di Zenzo's gradient operator, namely QHFIDZ, is presented in this paper. It preprocesses the color image to quaternion Hardy filter which reduces the noise effect and then apply the improved Di Zenzo's gradient algorithm for edge map. The proposed technique is a robust algorithm for noisy image detection comparison to other image detection techniques.
End-to-End Denoising of Dark Burst Images Using Recurrent Fully Convolutional Networks
Apr 16, 2019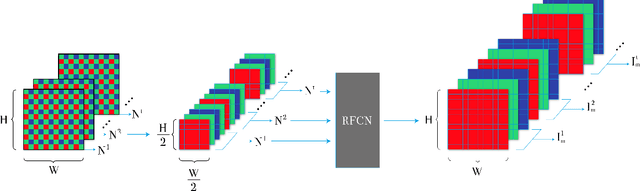
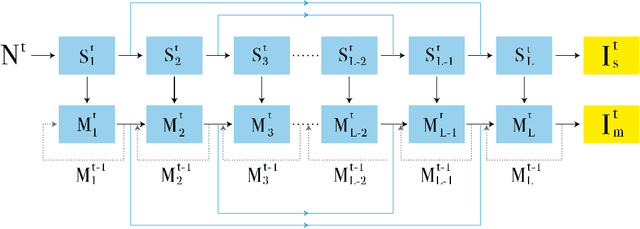


When taking photos in dim-light environments, due to the small amount of light entering, the shot images are usually extremely dark, with a great deal of noise, and the color cannot reflect real-world color. Under this condition, the traditional methods used for single image denoising have always failed to be effective. One common idea is to take multiple frames of the same scene to enhance the signal-to-noise ratio. This paper proposes a recurrent fully convolutional network (RFCN) to process burst photos taken under extremely low-light conditions, and to obtain denoised images with improved brightness. Our model maps raw burst images directly to sRGB outputs, either to produce a best image or to generate a multi-frame denoised image sequence. This process has proven to be capable of accomplishing the low-level task of denoising, as well as the high-level task of color correction and enhancement, all of which is end-to-end processing through our network. Our method has achieved better results than state-of-the-art methods. In addition, we have applied the model trained by one type of camera without fine-tuning on photos captured by different cameras and have obtained similar end-to-end enhancements.
Counterfactual Visual Explanations
Apr 16, 2019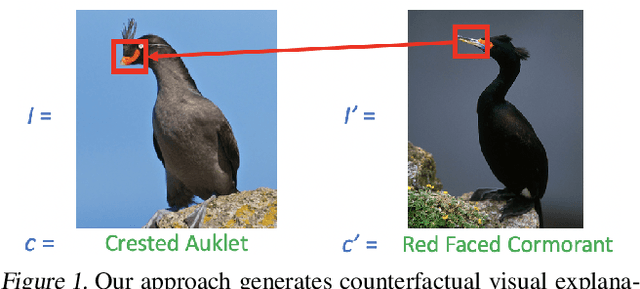
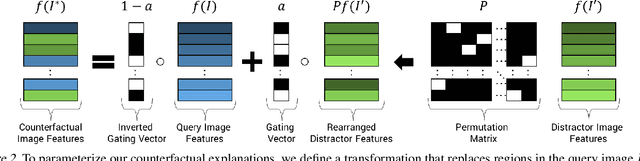
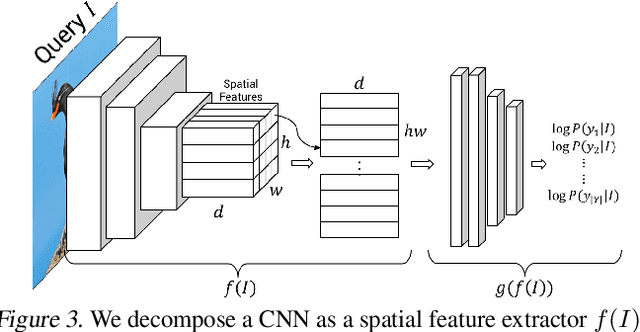
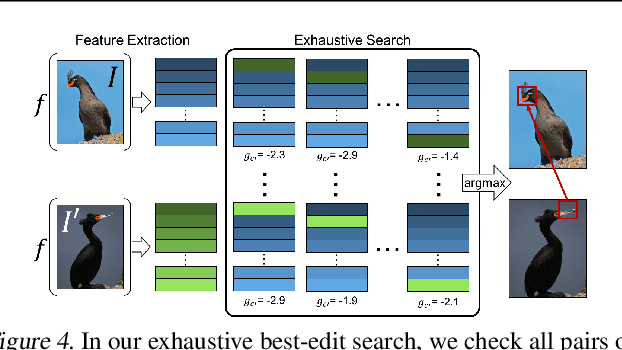
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Wireless Software Synchronization of Multiple Distributed Cameras
Dec 21, 2018


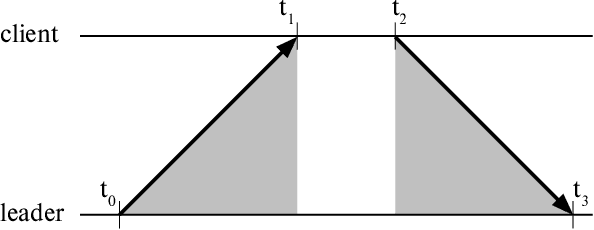
We present a method for precisely time-synchronizing the capture of image sequences from a collection of smartphone cameras connected over WiFi. Our method is entirely software-based, has only modest hardware requirements, and achieves an accuracy of less than 250 microseconds on unmodified commodity hardware. It does not use image content and synchronizes cameras prior to capture. The algorithm operates in two stages. In the first stage, we designate one device as the leader and synchronize each client device's clock to it by estimating network delay. Once clocks are synchronized, the second stage initiates continuous image streaming, estimates the relative phase of image timestamps between each client and the leader, and shifts the streams into alignment. We quantitatively validate our results on a multi-camera rig imaging a high-precision LED array and qualitatively demonstrate significant improvements to multi-view stereo depth estimation and stitching of dynamic scenes. We plan to open-source an Android implementation of our system 'libsoftwaresync', potentially inspiring new types of collective capture applications.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
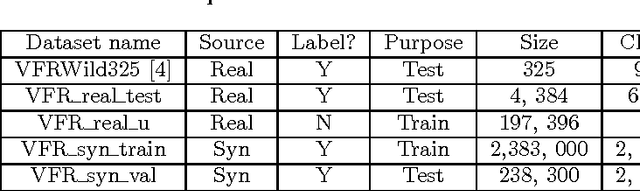


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
deepCR: Cosmic Ray Rejection with Deep Learning
Jul 22, 2019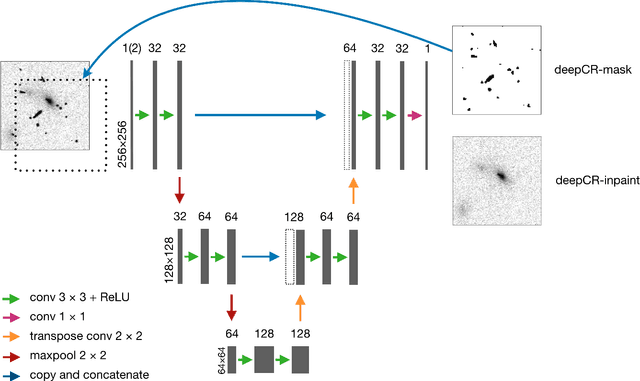
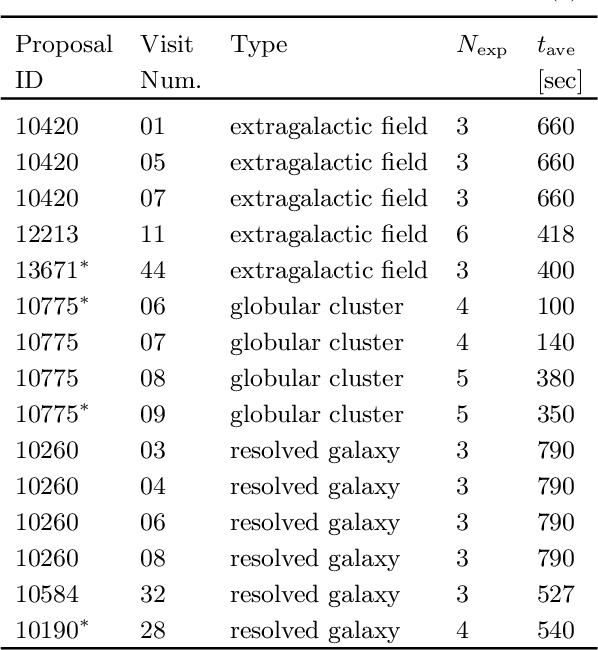

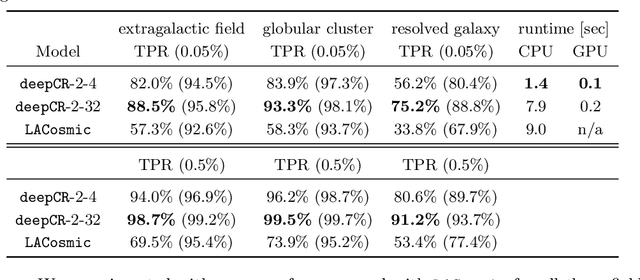
Cosmic ray (CR) identification and removal are critical components of imaging and spectroscopic reduction pipelines involving solid-state detectors. We present deepCR, a deep learning based framework for cosmic ray (CR) identification and subsequent image inpainting based on the predicted CR mask. To demonstrate the effectiveness of our framework, we have trained and evaluated models on Hubble Space Telescope ACS/WFC images of sparse extragalactic fields, globular clusters, and resolved galaxies. We demonstrate that at a reasonable false positive rate of 0.5%, deepCR achieves close to 100% detection rates in both extragalactic and globular cluster fields, and 91% in resolved galaxy fields, which is a significant improvement over current state-of-the-art method, LACosmic. Compared to a well-threaded CPU implementation of LACosmic, deepCR mask predictions runs up to 6.5 times faster on CPU and 90 times faster on GPU. For image inpainting, mean squared error of deepDR predictions are 20 times lower in globular cluster fields, 5 times lower in resolved galaxy fields, and 2.5 times lower in extragalactic fields, compared to the best performing non-neural technique. We present our framework and trained models as an open-source Python project, with a simple-to-use API.
Transformed Subspace Clustering
Dec 10, 2019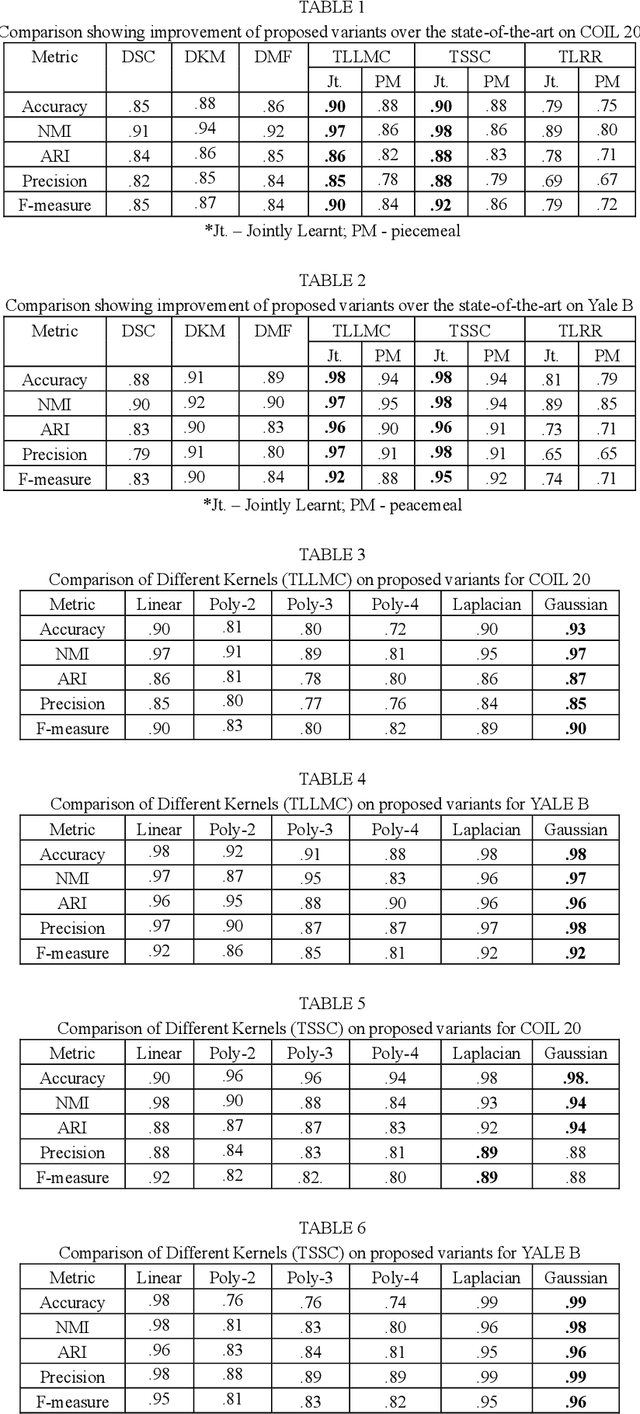
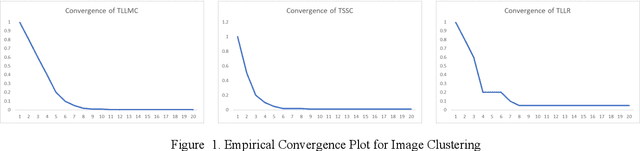
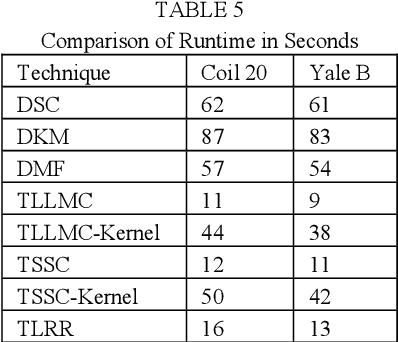
Subspace clustering assumes that the data is sepa-rable into separate subspaces. Such a simple as-sumption, does not always hold. We assume that, even if the raw data is not separable into subspac-es, one can learn a representation (transform coef-ficients) such that the learnt representation is sep-arable into subspaces. To achieve the intended goal, we embed subspace clustering techniques (locally linear manifold clustering, sparse sub-space clustering and low rank representation) into transform learning. The entire formulation is jointly learnt; giving rise to a new class of meth-ods called transformed subspace clustering (TSC). In order to account for non-linearity, ker-nelized extensions of TSC are also proposed. To test the performance of the proposed techniques, benchmarking is performed on image clustering and document clustering datasets. Comparison with state-of-the-art clustering techniques shows that our formulation improves upon them.
Analysis of Video Feature Learning in Two-Stream CNNs on the Example of Zebrafish Swim Bout Classification
Dec 20, 2019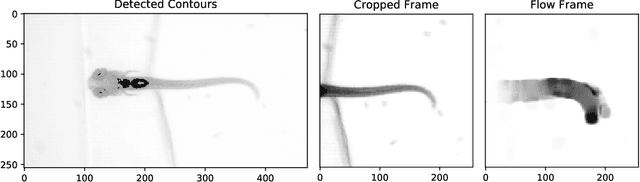

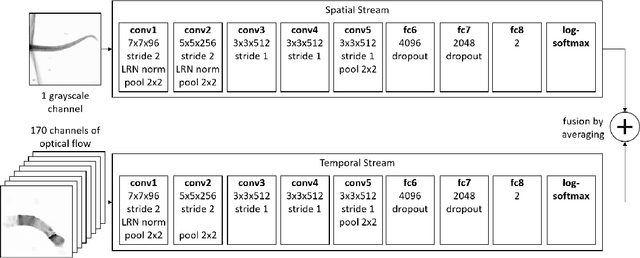
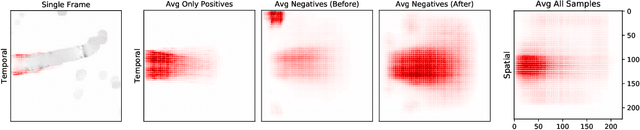
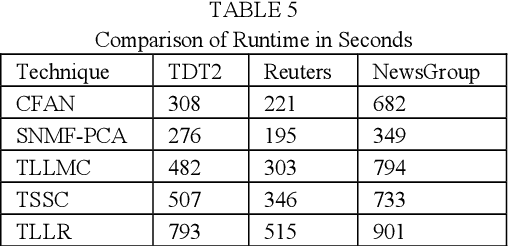
Semmelhack et al. (2014) have achieved high classification accuracy in distinguishing swim bouts of zebrafish using a Support Vector Machine (SVM). Convolutional Neural Networks (CNNs) have reached superior performance in various image recognition tasks over SVMs, but these powerful networks remain a black box. Reaching better transparency helps to build trust in their classifications and makes learned features interpretable to experts. Using a recently developed technique called Deep Taylor Decomposition, we generated heatmaps to highlight input regions of high relevance for predictions. We find that our CNN makes predictions by analyzing the steadiness of the tail's trunk, which markedly differs from the manually extracted features used by Semmelhack et al. (2014). We further uncovered that the network paid attention to experimental artifacts. Removing these artifacts ensured the validity of predictions. After correction, our best CNN beats the SVM by 6.12%, achieving a classification accuracy of 96.32%. Our work thus demonstrates the utility of AI explainability for CNNs.
Transfer Learning with Edge Attention for Prostate MRI Segmentation
Dec 20, 2019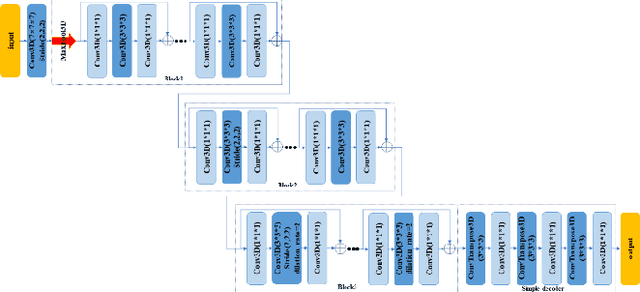
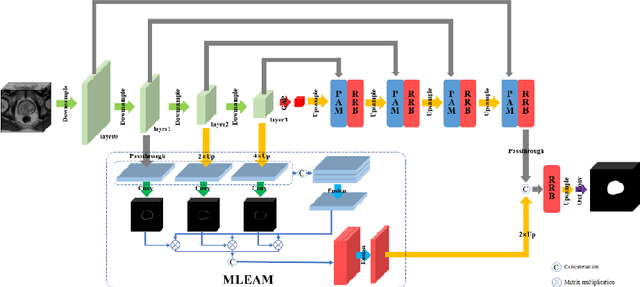
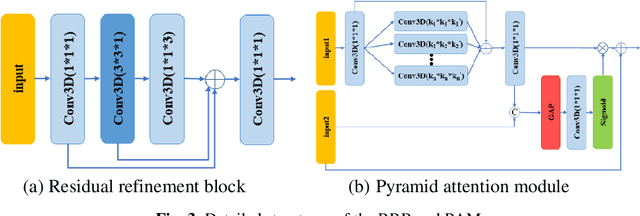
Prostate cancer is one of the common diseases in men, and it is the most common malignant tumor in developed countries. Studies have shown that the male prostate incidence rate is as high as 2.5% to 16%, Currently, the inci-dence of prostate cancer in Asia is lower than that in the West, but it is increas-ing rapidly. If prostate cancer can be found as early as possible and treated in time, it will have a high survival rate. Therefore, it is of great significance for the diagnosis and treatment of prostate cancer. In this paper, we propose a trans-fer learning method based on deep neural network for prostate MRI segmenta-tion. In addition, we design a multi-level edge attention module using wavelet decomposition to overcome the difficulty of ambiguous boundary in prostate MRI segmentation tasks. The prostate images were provided by MICCAI Grand Challenge-Prostate MR Image Segmentation 2012 (PROMISE 12) challenge dataset.
WITCHcraft: Efficient PGD attacks with random step size
Nov 18, 2019
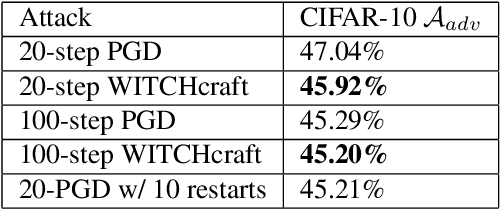
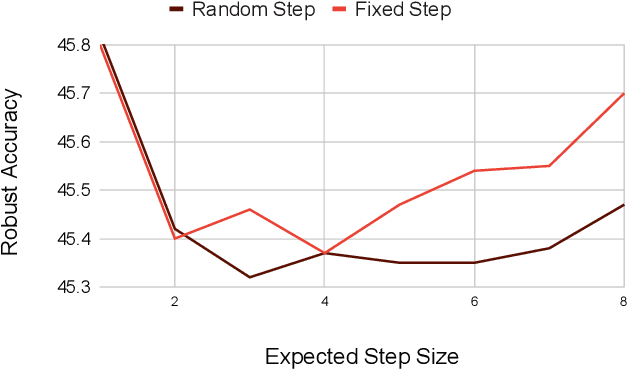
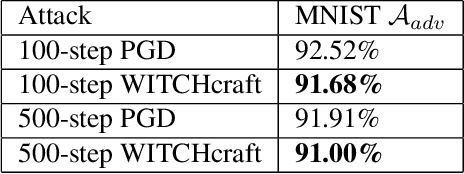
State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.