 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Asymmetric Rejection Loss for Fairer Face Recognition
Feb 09, 2020
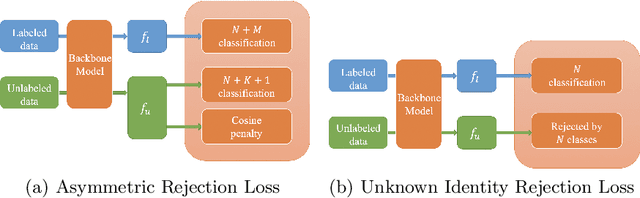
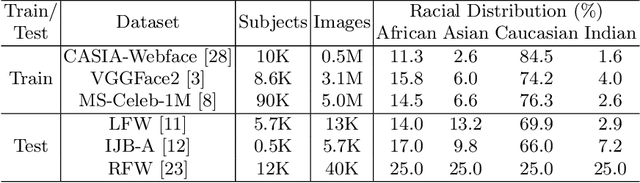
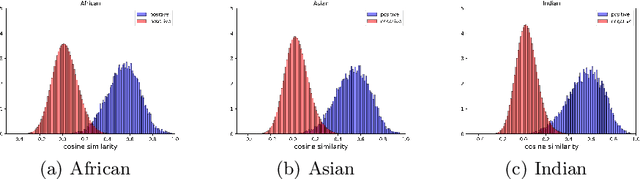
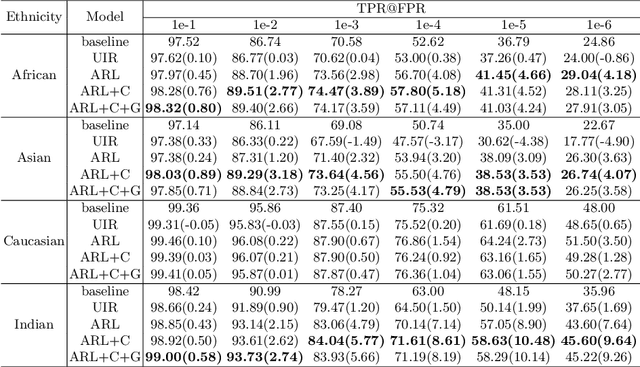
Face recognition performance has seen a tremendous gain in recent years, mostly due to the availability of large-scale face images dataset that can be exploited by deep neural networks to learn powerful face representations. However, recent research has shown differences in face recognition performance across different ethnic groups mostly due to the racial imbalance in the training datasets where Caucasian identities largely dominate other ethnicities. This is actually symptomatic of the under-representation of non-Caucasian ethnic groups in the celebdom from which face datasets are usually gathered, rendering the acquisition of labeled data of the under-represented groups challenging. In this paper, we propose an Asymmetric Rejection Loss, which aims at making full use of unlabeled images of those under-represented groups, to reduce the racial bias of face recognition models. We view each unlabeled image as a unique class, however as we cannot guarantee that two unlabeled samples are from a distinct class we exploit both labeled and unlabeled data in an asymmetric manner in our loss formalism. Extensive experiments show our method's strength in mitigating racial bias, outperforming state-of-the-art semi-supervision methods. Performance on the under-represented ethnicity groups increases while that on the well-represented group is nearly unchanged.
Focus Quality Assessment of High-Throughput Whole Slide Imaging in Digital Pathology
Nov 14, 2018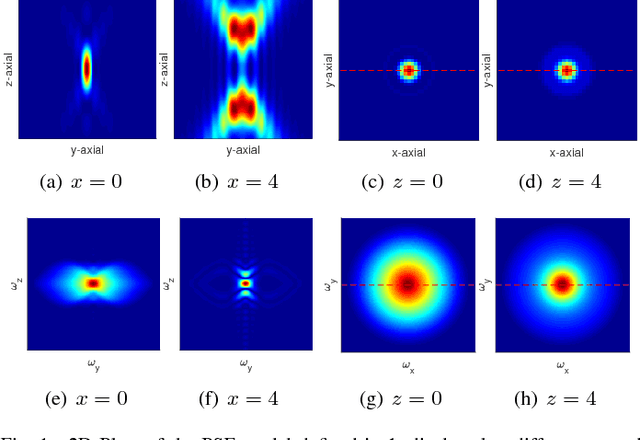
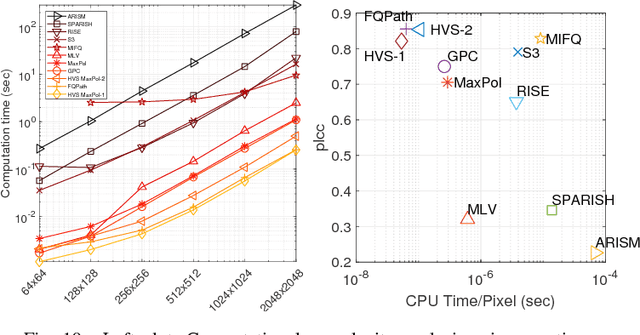
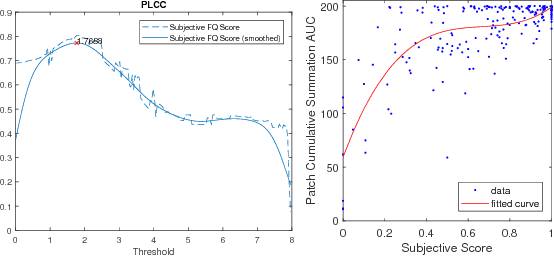
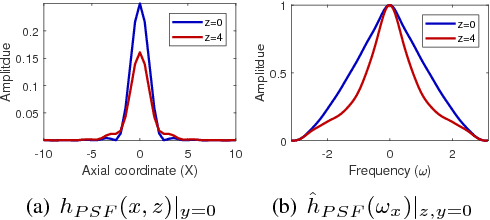
One of the challenges facing the adoption of digital pathology workflows for clinical use is the need for automated quality control. As the scanners sometimes determine focus inaccurately, the resultant image blur deteriorates the scanned slide to the point of being unusable. Also, the scanned slide images tend to be extremely large when scanned at greater or equal 20X image resolution. Hence, for digital pathology to be clinically useful, it is necessary to use computational tools to quickly and accurately quantify the image focus quality and determine whether an image needs to be re-scanned. We propose a no-reference focus quality assessment metric specifically for digital pathology images, that operates by using a sum of even-derivative filter bases to synthesize a human visual system-like kernel, which is modeled as the inverse of the lens' point spread function. This kernel is then applied to a digital pathology image to modify high-frequency image information deteriorated by the scanner's optics and quantify the focus quality at the patch level. We show in several experiments that our method correlates better with ground-truth $z$-level data than other methods, and is more computationally efficient. We also extend our method to generate a local slide-level focus quality heatmap, which can be used for automated slide quality control, and demonstrate the utility of our method for clinical scan quality control by comparison with subjective slide quality scores.
Localizing Discriminative Visual Landmarks for Place Recognition
Apr 14, 2019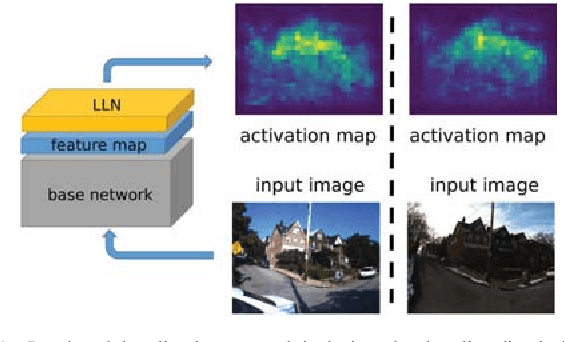
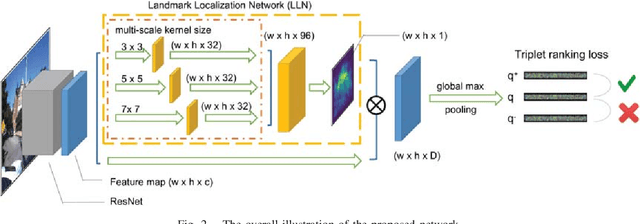
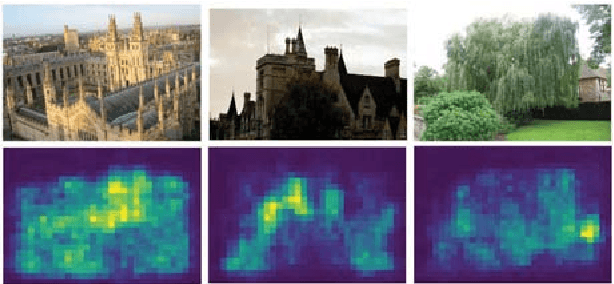
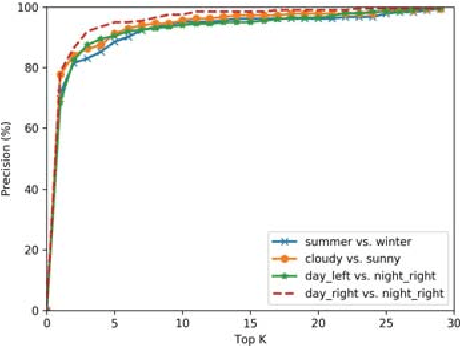
We address the problem of visual place recognition with perceptual changes. The fundamental problem of visual place recognition is generating robust image representations which are not only insensitive to environmental changes but also distinguishable to different places. Taking advantage of the feature extraction ability of Convolutional Neural Networks (CNNs), we further investigate how to localize discriminative visual landmarks that positively contribute to the similarity measurement, such as buildings and vegetations. In particular, a Landmark Localization Network (LLN) is designed to indicate which regions of an image are used for discrimination. Detailed experiments are conducted on open source datasets with varied appearance and viewpoint changes. The proposed approach achieves superior performance against state-of-the-art methods.
Analysis of Video Feature Learning in Two-Stream CNNs on the Example of Zebrafish Swim Bout Classification
Dec 20, 2019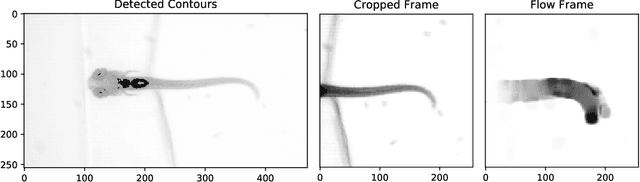

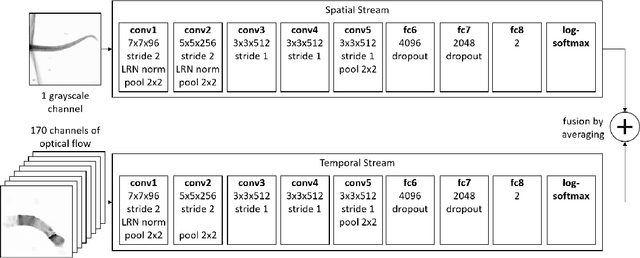
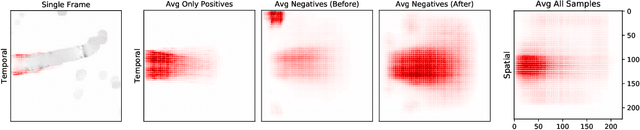
Semmelhack et al. (2014) have achieved high classification accuracy in distinguishing swim bouts of zebrafish using a Support Vector Machine (SVM). Convolutional Neural Networks (CNNs) have reached superior performance in various image recognition tasks over SVMs, but these powerful networks remain a black box. Reaching better transparency helps to build trust in their classifications and makes learned features interpretable to experts. Using a recently developed technique called Deep Taylor Decomposition, we generated heatmaps to highlight input regions of high relevance for predictions. We find that our CNN makes predictions by analyzing the steadiness of the tail's trunk, which markedly differs from the manually extracted features used by Semmelhack et al. (2014). We further uncovered that the network paid attention to experimental artifacts. Removing these artifacts ensured the validity of predictions. After correction, our best CNN beats the SVM by 6.12%, achieving a classification accuracy of 96.32%. Our work thus demonstrates the utility of AI explainability for CNNs.
What Do Single-view 3D Reconstruction Networks Learn?
May 09, 2019
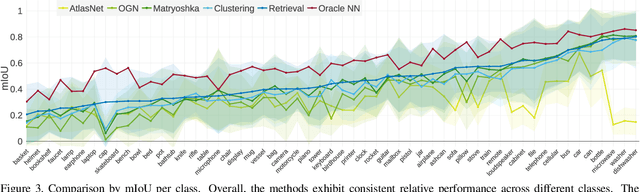
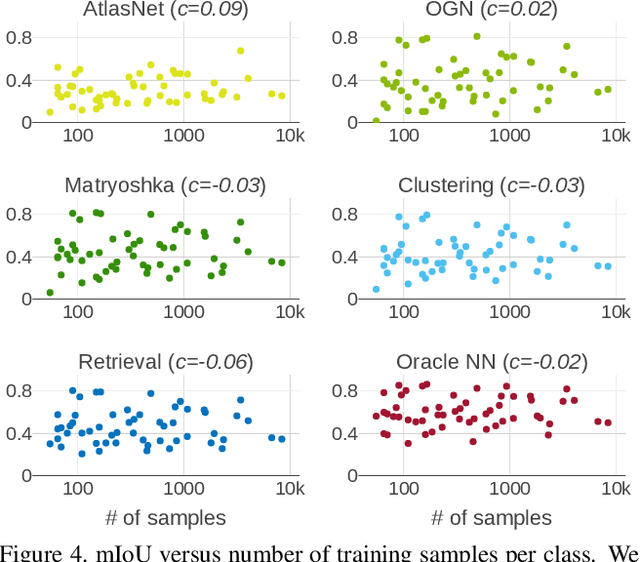

Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
Transfer Learning with Edge Attention for Prostate MRI Segmentation
Dec 20, 2019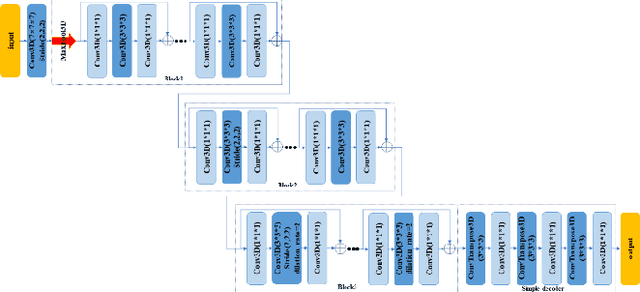
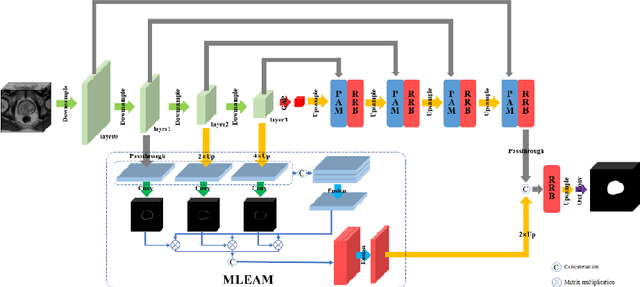
Prostate cancer is one of the common diseases in men, and it is the most common malignant tumor in developed countries. Studies have shown that the male prostate incidence rate is as high as 2.5% to 16%, Currently, the inci-dence of prostate cancer in Asia is lower than that in the West, but it is increas-ing rapidly. If prostate cancer can be found as early as possible and treated in time, it will have a high survival rate. Therefore, it is of great significance for the diagnosis and treatment of prostate cancer. In this paper, we propose a trans-fer learning method based on deep neural network for prostate MRI segmenta-tion. In addition, we design a multi-level edge attention module using wavelet decomposition to overcome the difficulty of ambiguous boundary in prostate MRI segmentation tasks. The prostate images were provided by MICCAI Grand Challenge-Prostate MR Image Segmentation 2012 (PROMISE 12) challenge dataset.
Performance of a Deep Neural Network at Detecting North Atlantic Right Whale Upcalls
Jan 24, 2020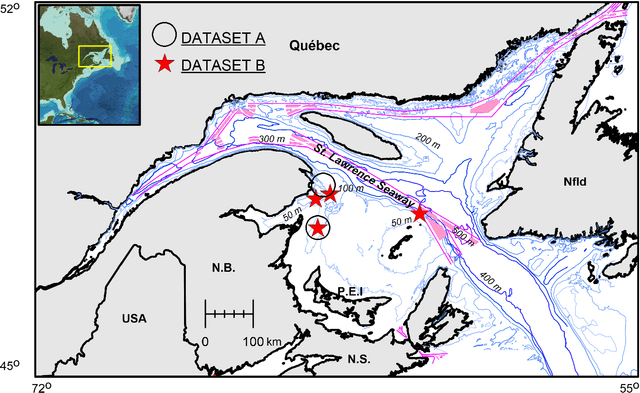
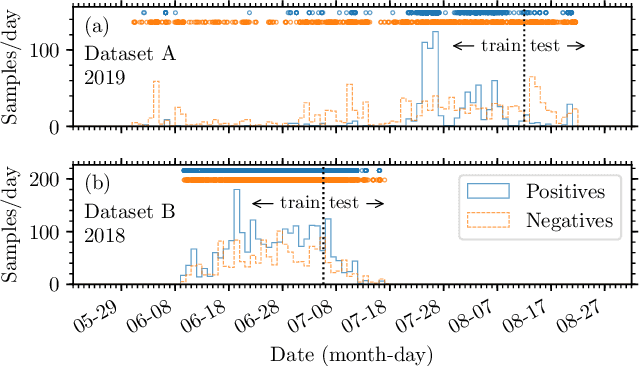
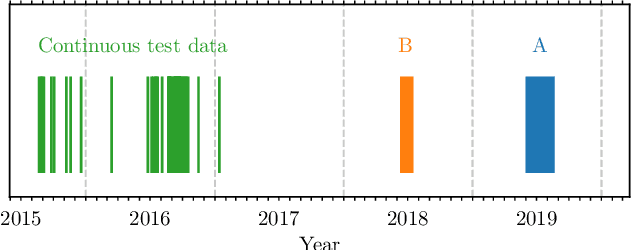
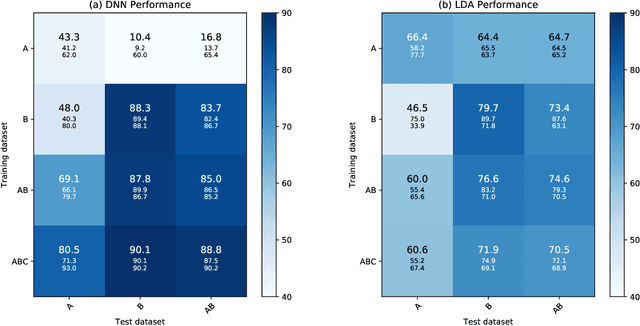
Passive acoustics provides a powerful tool for monitoring the endangered North Atlantic right whale (NARW), but improved detection algorithms are needed to handle diverse and variable acoustic conditions and differences in recording techniques and equipment. Here, we investigate the potential of Deep Neural Networks for addressing this need. ResNet, an architecture commonly used for image recognition, is trained to recognize the time-frequency representation of the characteristic NARW upcall. The network is trained on several thousand examples recorded at various locations in the Gulf of St. Lawrence in 2018 and 2019, using different equipment and deployment techniques. Used as a detection algorithm on fifty 30-minute recordings from the years 2015-2017 containing over one thousand upcalls, the network achieves recalls up to 80%, while maintaining a precision of 90%. Importantly, the performance of the network improves as more variance is introduced into the training dataset, whereas the opposite trend is observed using a conventional linear discriminant analysis approach. Our work demonstrates that Deep Neural Networks can be trained to identify NARW upcalls under diverse and variable conditions with a performance that compares favorably to that of existing algorithms.
Perception and Decision-Making of Autonomous Systems in the Era of Learning: An Overview
Jan 08, 2020The ability of inferring its own ego-motion, autonomous understanding the surroundings and planning trajectory are the features of autonomous robot systems. Therefore, in order to improve the perception and decision-making ability of autonomous robot systems, Simultaneous localization and mapping (SLAM) and autonomous trajectory planning are widely researched, especially combining learning-based algorithms. In this paper, we mainly focus on the application of learning-based approaches to perception and decision-making, and survey the current state-of-the-art SLAM and trajectory planning algorithms. Firstly, we delineate the existing classical SLAM solutions and review deep learning-based methods of environment perception and understanding, including deep learning-based monocular depth estimation, ego-motion prediction, image enhancement, object detection, semantic segmentation and their combinations with previous SLAM frameworks. Secondly, we summarize the existing path planning and trajectory planning methods and survey the navigation methods based on reinforcement learning. Finally, several challenges and promising directions are concluded to related researchers for future work in both autonomous perception and decision-making.
Deep Learning for Estimating Synaptic Health of Primary Neuronal Cell Culture
Aug 29, 2019

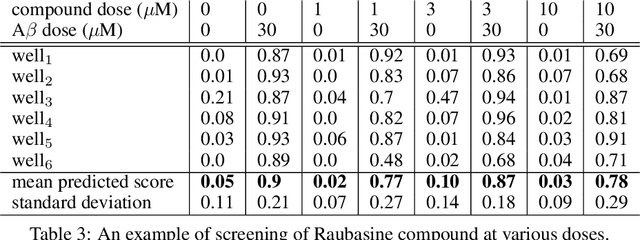

Understanding the morphological changes of primary neuronal cells induced by chemical compounds is essential for drug discovery. Using the data from a single high-throughput imaging assay, a classification model for predicting the biological activity of candidate compounds was introduced. The image recognition model which is based on deep convolutional neural network (CNN) architecture with residual connections achieved accuracy of 99.6$\%$ on a binary classification task of distinguishing untreated and treated rodent primary neuronal cells with Amyloid-$\beta_{(25-35)}$.
Transformed Subspace Clustering
Dec 10, 2019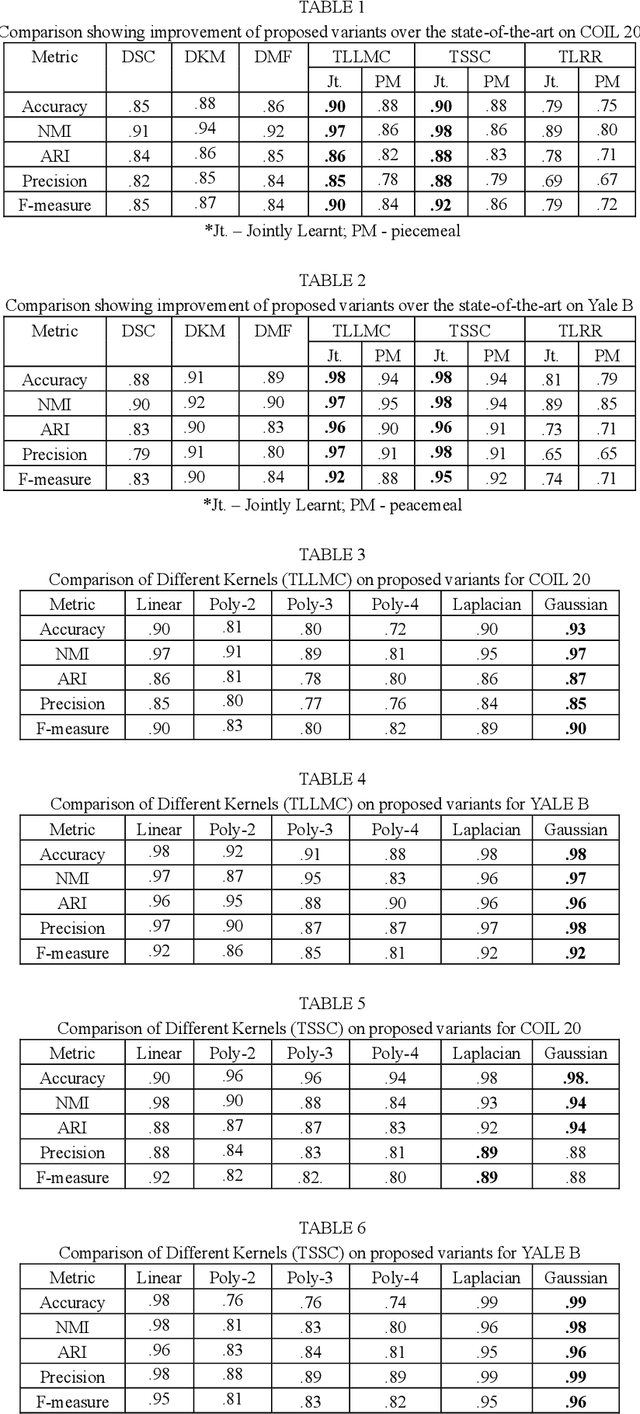
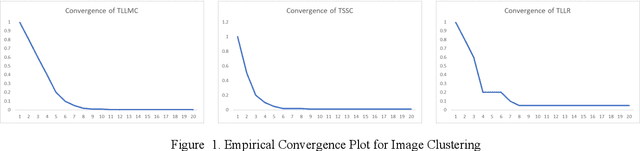
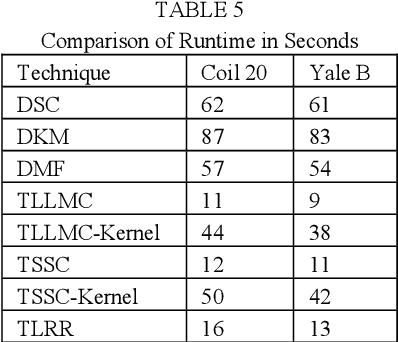
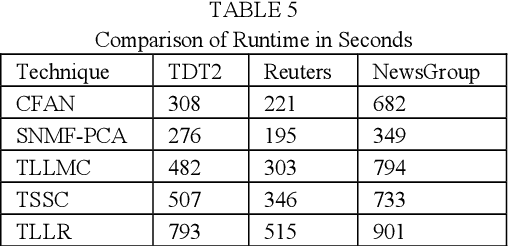
Subspace clustering assumes that the data is sepa-rable into separate subspaces. Such a simple as-sumption, does not always hold. We assume that, even if the raw data is not separable into subspac-es, one can learn a representation (transform coef-ficients) such that the learnt representation is sep-arable into subspaces. To achieve the intended goal, we embed subspace clustering techniques (locally linear manifold clustering, sparse sub-space clustering and low rank representation) into transform learning. The entire formulation is jointly learnt; giving rise to a new class of meth-ods called transformed subspace clustering (TSC). In order to account for non-linearity, ker-nelized extensions of TSC are also proposed. To test the performance of the proposed techniques, benchmarking is performed on image clustering and document clustering datasets. Comparison with state-of-the-art clustering techniques shows that our formulation improves upon them.