 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transferability versus Discriminability: Joint Probability Distribution Adaptation (JPDA)
Dec 01, 2019

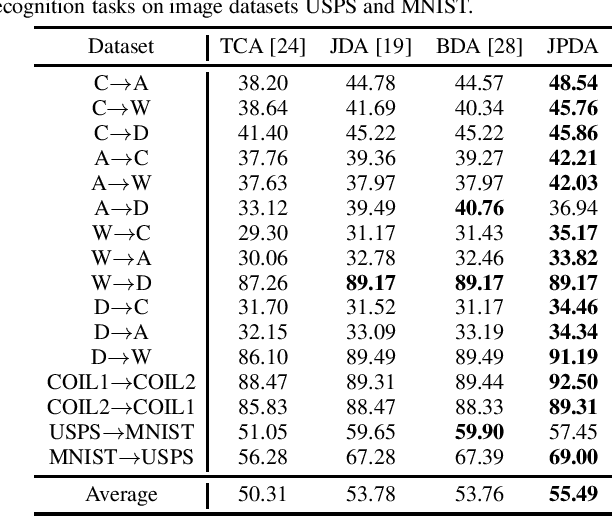
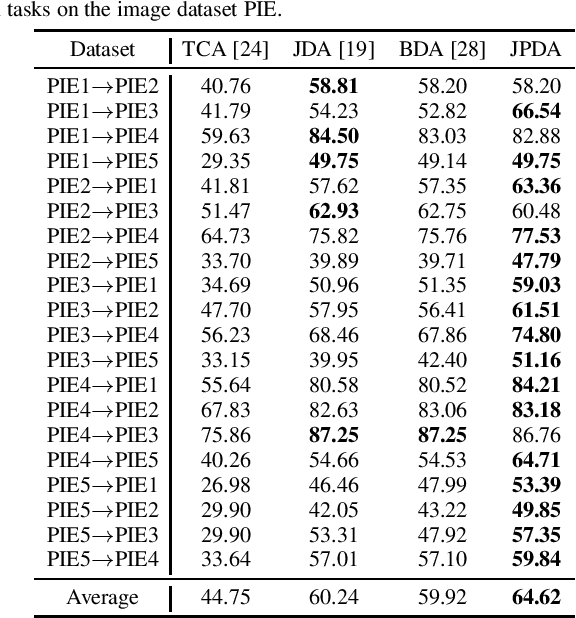
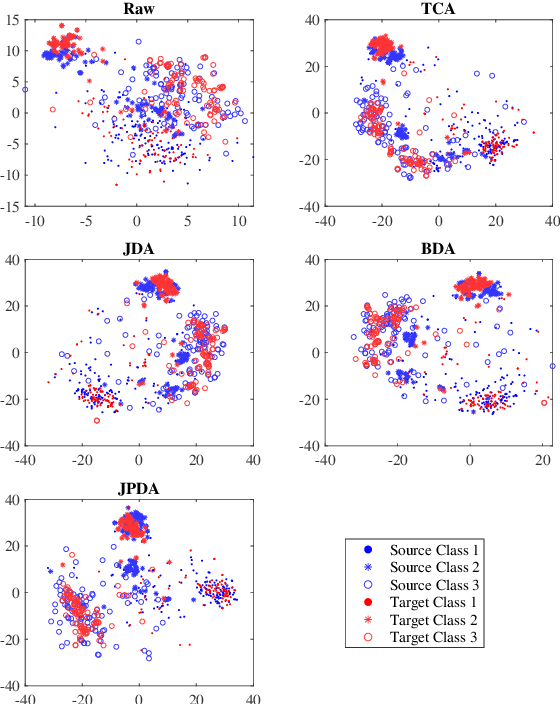
Transfer learning makes use of data or knowledge in one task to help solve a different, yet related, task. Many existing TL approaches are based on a joint probability distribution metric, which is a weighted sum of the marginal distribution and the conditional distribution; however, they optimize the two distributions independently, and ignore their intrinsic dependency. This paper proposes a novel and frustratingly easy Joint Probability Distribution Adaptation (JPDA) approach, to replace the frequently-used joint maximum mean discrepancy metric in transfer learning. During the distribution adaptation, JPDA improves the transferability between the source and the target domains by minimizing the joint probability discrepancy of the corresponding class, and also increases the discriminability between different classes by maximizing their joint probability discrepancy. Experiments on six image classification datasets demonstrated that JPDA outperforms several state-of-the-art metric-based transfer learning approaches.
DASNet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images
Mar 07, 2020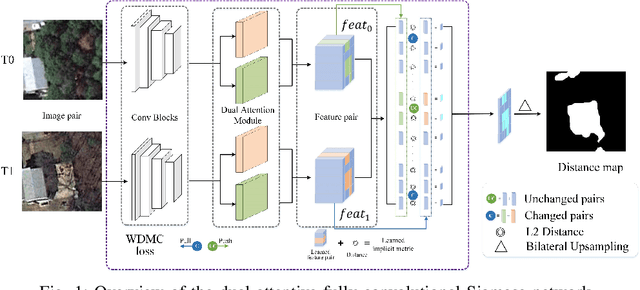
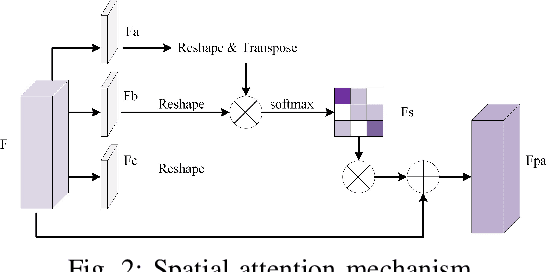
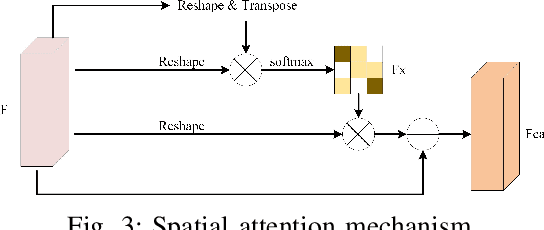

Change detection is a basic task of remote sensing image processing. The research objective is to identity the change information of interest and filter out the irrelevant change information as interference factors. Recently, the rise of deep learning has provided new tools for change detection, which have yielded impressive results. However, the available methods focus mainly on the difference information between multitemporal remote sensing images and lack robustness to pseudo-change information. To overcome the lack of resistance of current methods to pseudo-changes, in this paper, we propose a new method, namely, dual attentive fully convolutional Siamese networks (DASNet) for change detection in high-resolution images. Through the dual-attention mechanism, long-range dependencies are captured to obtain more discriminant feature representations to enhance the recognition performance of the model. Moreover, the imbalanced sample is a serious problem in change detection, i.e. unchanged samples are much more than changed samples, which is one of the main reasons resulting in pseudo-changes. We put forward the weighted double margin contrastive loss to address this problem by punishing the attention to unchanged feature pairs and increase attention to changed feature pairs. The experimental results of our method on the change detection dataset (CDD) and the building change detection dataset (BCDD) demonstrate that compared with other baseline methods, the proposed method realizes maximum improvements of 2.1\% and 3.6\%, respectively, in the F1 score. Our Pytorch implementation is available at https://github.com/lehaifeng/DASNet.
Coupled Learning for Facial Deblur
Apr 18, 2019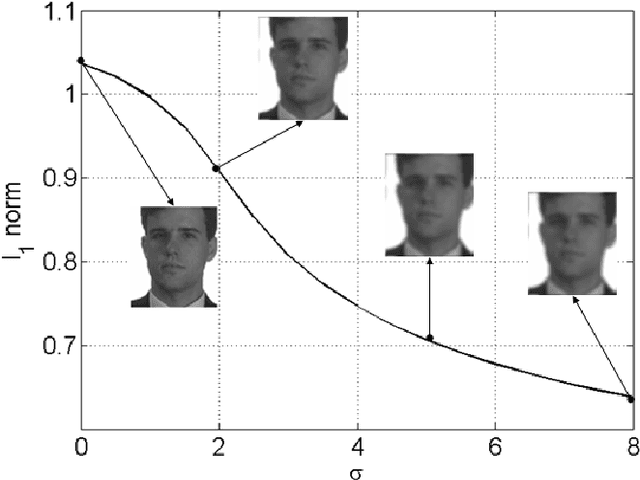


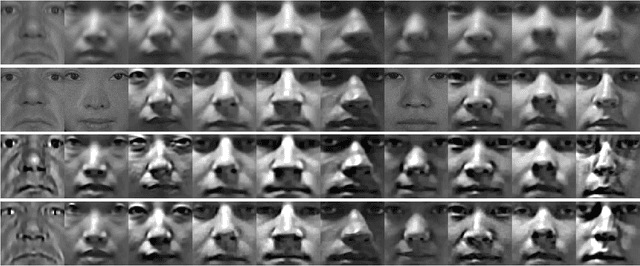
Blur in facial images significantly impedes the efficiency of recognition approaches. However, most existing blind deconvolution methods cannot generate satisfactory results due to their dependence on strong edges, which are sufficient in natural images but not in facial images. In this paper, we represent point spread functions (PSFs) by the linear combination of a set of pre-defined orthogonal PSFs, and similarly, an estimated intrinsic (EI) sharp face image is represented by the linear combination of a set of pre-defined orthogonal face images. In doing so, PSF and EI estimation is simplified to discovering two sets of linear combination coefficients, which are simultaneously found by our proposed coupled learning algorithm. To make our method robust to different types of blurry face images, we generate several candidate PSFs and EIs for a test image, and then, a non-blind deconvolution method is adopted to generate more EIs by those candidate PSFs. Finally, we deploy a blind image quality assessment metric to automatically select the optimal EI. Thorough experiments on the facial recognition technology database, extended Yale face database B, CMU pose, illumination, and expression (PIE) database, and face recognition grand challenge database version 2.0 demonstrate that the proposed approach effectively restores intrinsic sharp face images and, consequently, improves the performance of face recognition.
Deep Amortized Clustering
Sep 30, 2019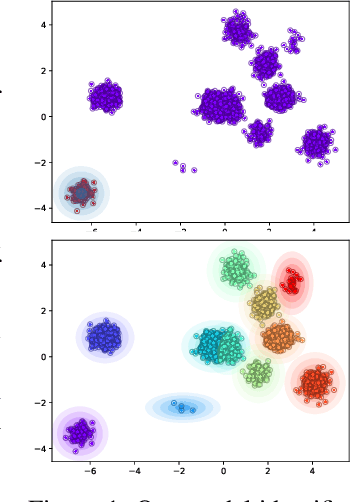
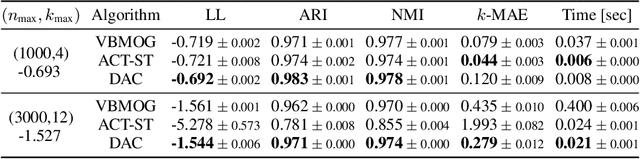
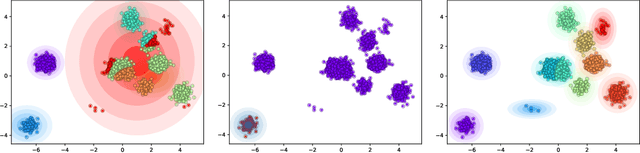
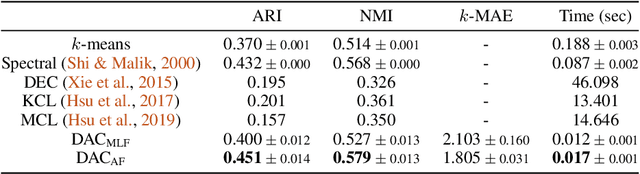
We propose a deep amortized clustering (DAC), a neural architecture which learns to cluster datasets efficiently using a few forward passes. DAC implicitly learns what makes a cluster, how to group data points into clusters, and how to count the number of clusters in datasets. DAC is meta-learned using labelled datasets for training, a process distinct from traditional clustering algorithms which usually require hand-specified prior knowledge about cluster shapes/structures. We empirically show, on both synthetic and image data, that DAC can efficiently and accurately cluster new datasets coming from the same distribution used to generate training datasets.
Extracting temporal features into a spatial domain using autoencoders for sperm video analysis
Nov 08, 2019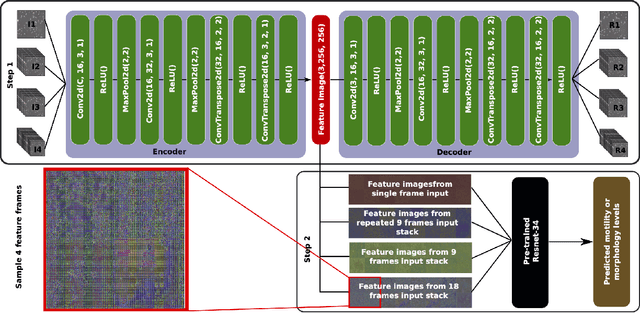
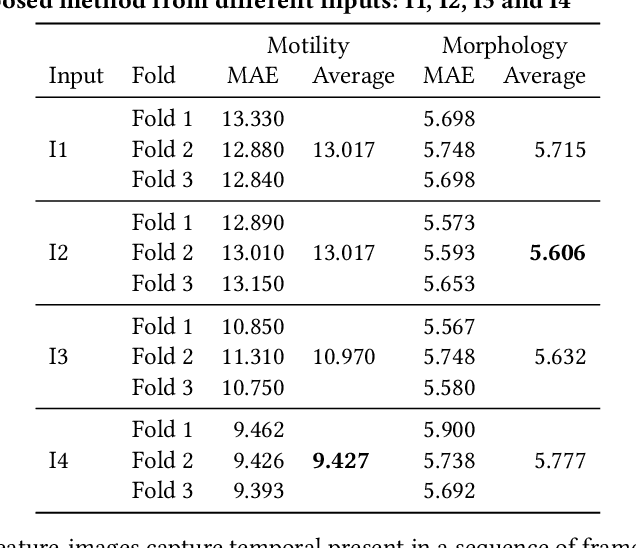
In this paper, we present a two-step deep learning method that is used to predict sperm motility and morphology-based on video recordings of human spermatozoa. First, we use an autoencoder to extract temporal features from a given semen video and plot these into image-space, which we call feature-images. Second, these feature-images are used to perform transfer learning to predict the motility and morphology values of human sperm. The presented method shows it's capability to extract temporal information into spatial domain feature-images which can be used with traditional convolutional neural networks. Furthermore, the accuracy of the predicted motility of a given semen sample shows that a deep learning-based model can capture the temporal information of microscopic recordings of human semen.
Decoupled Attention Network for Text Recognition
Dec 21, 2019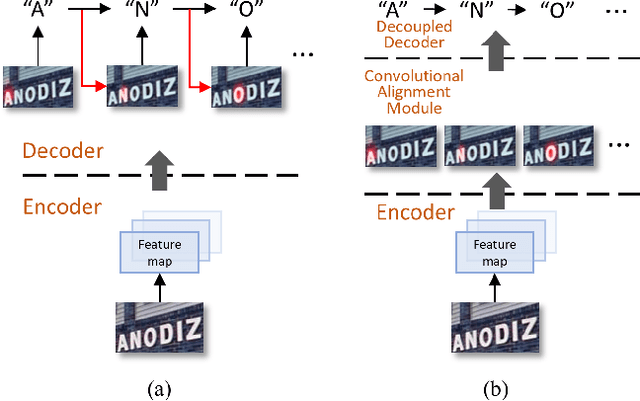
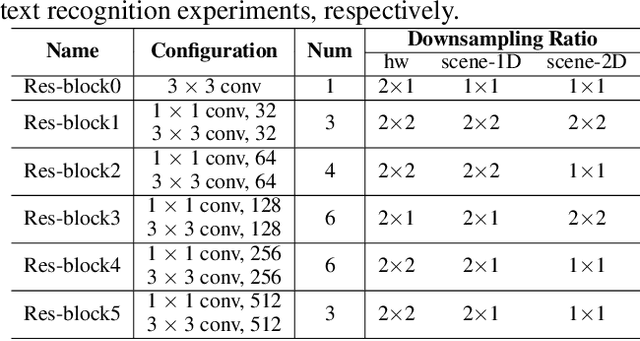
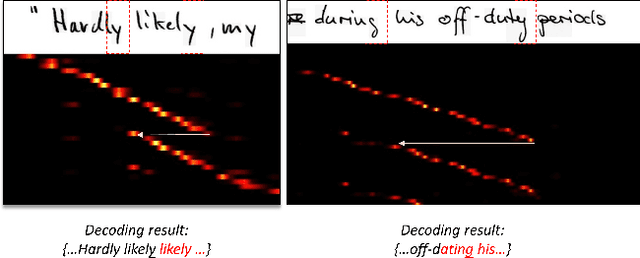
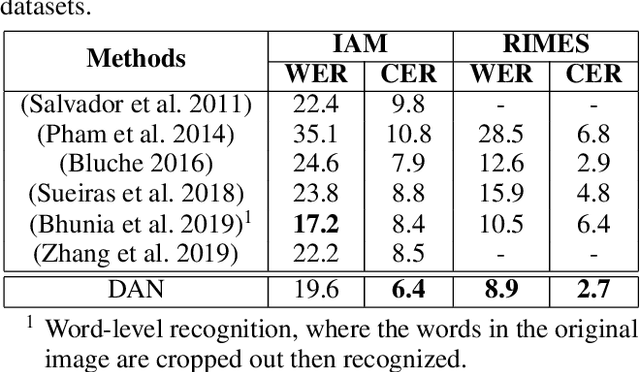
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
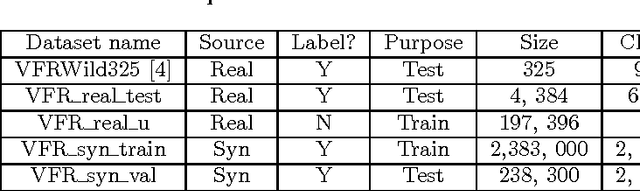


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
FocusNet: An attention-based Fully Convolutional Network for Medical Image Segmentation
Feb 08, 2019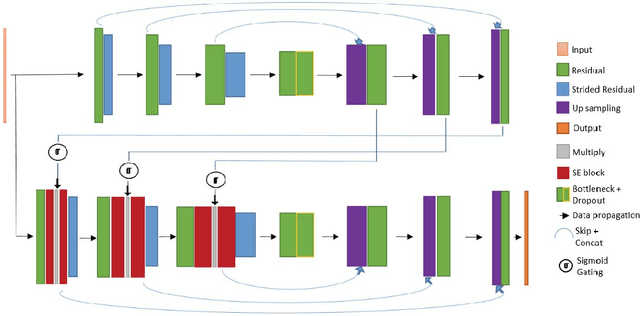
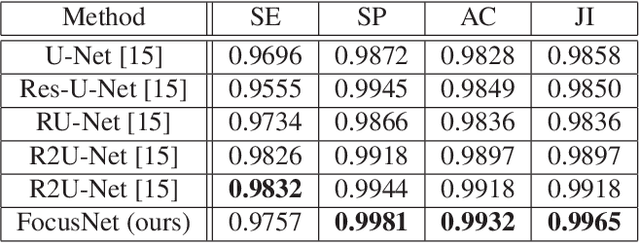
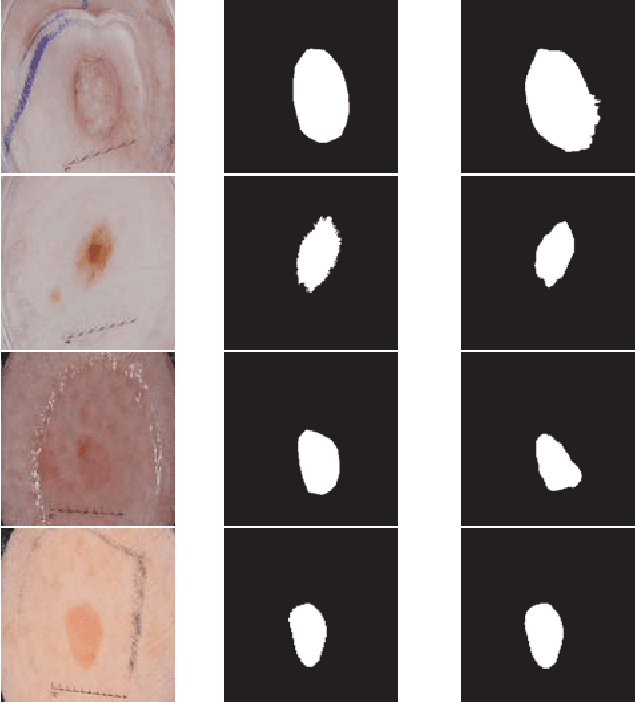
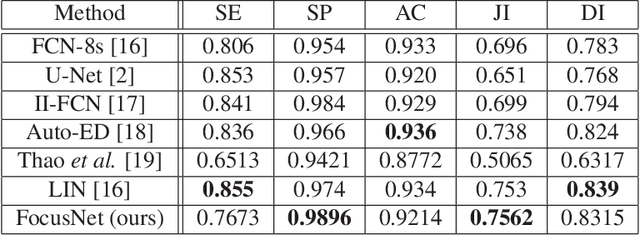
We propose a novel technique to incorporate attention within convolutional neural networks using feature maps generated by a separate convolutional autoencoder. Our attention architecture is well suited for incorporation with deep convolutional networks. We evaluate our model on benchmark segmentation datasets in skin cancer segmentation and lung lesion segmentation. Results show highly competitive performance when compared with U-Net and it's residual variant.
KISS: Keeping It Simple for Scene Text Recognition
Nov 19, 2019
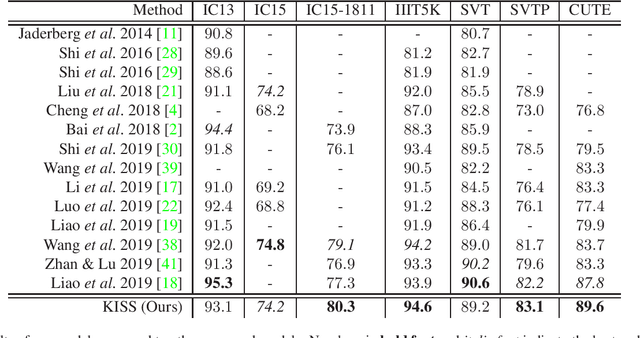
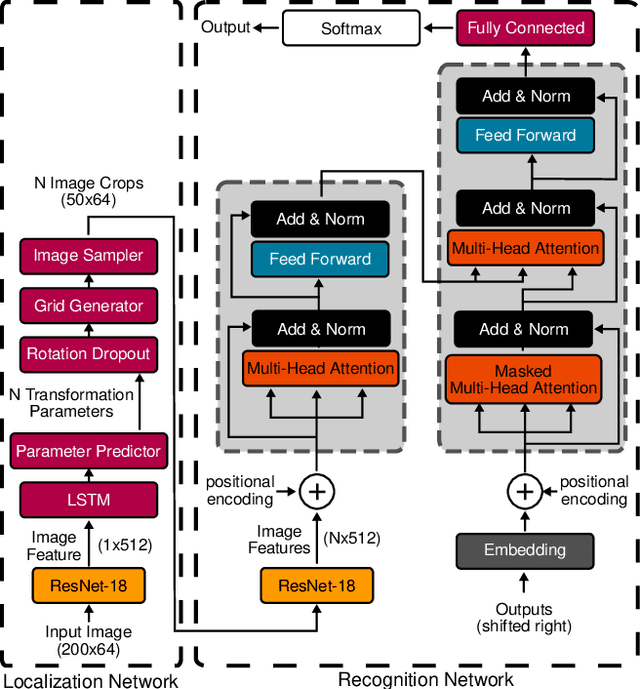
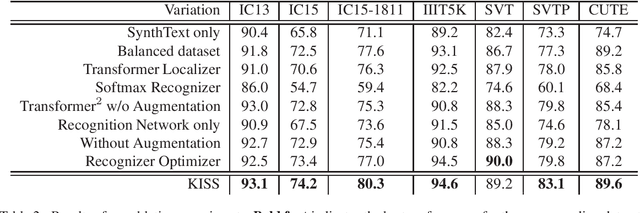
Over the past few years, several new methods for scene text recognition have been proposed. Most of these methods propose novel building blocks for neural networks. These novel building blocks are specially tailored for the task of scene text recognition and can thus hardly be used in any other tasks. In this paper, we introduce a new model for scene text recognition that only consists of off-the-shelf building blocks for neural networks. Our model (KISS) consists of two ResNet based feature extractors, a spatial transformer, and a transformer. We train our model only on publicly available, synthetic training data and evaluate it on a range of scene text recognition benchmarks, where we reach state-of-the-art or competitive performance, although our model does not use methods like 2D-attention, or image rectification.
Learning Shape Priors for Robust Cardiac MR Segmentation from Multi-view Images
Jul 23, 2019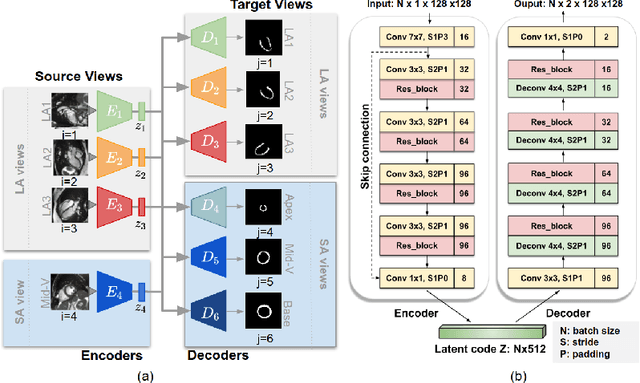
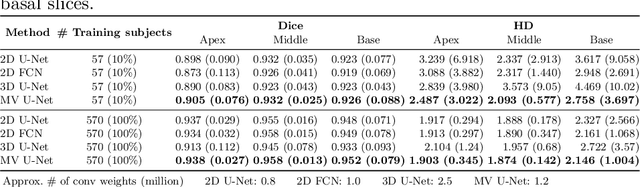
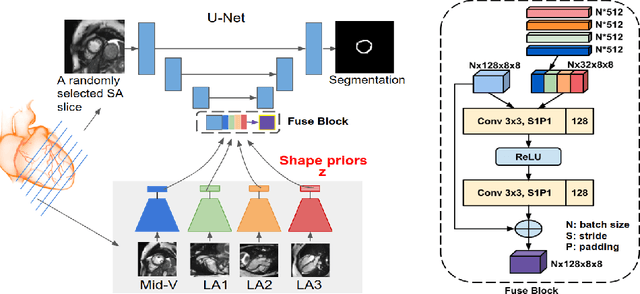
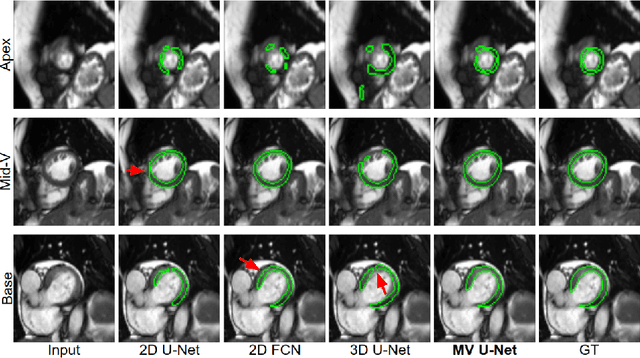
Cardiac MR image segmentation is essential for the morphological and functional analysis of the heart. Inspired by how experienced clinicians assess the cardiac morphology and function across multiple standard views (i.e. long- and short-axis views), we propose a novel approach which learns anatomical shape priors across different 2D standard views and leverages these priors to segment the left ventricular (LV) myocardium from short-axis MR image stacks. The proposed segmentation method has the advantage of being a 2D network but at the same time incorporates spatial context from multiple, complementary views that span a 3D space. Our method achieves accurate and robust segmentation of the myocardium across different short-axis slices (from apex to base), outperforming baseline models (e.g. 2D U-Net, 3D U-Net) while achieving higher data efficiency. Compared to the 2D U-Net, the proposed method reduces the mean Hausdorff distance (mm) from 3.24 to 2.49 on the apical slices, from 2.34 to 2.09 on the middle slices and from 3.62 to 2.76 on the basal slices on the test set, when only 10% of the training data was used.