 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PoseGen: Learning to Generate 3D Human Pose Dataset with NeRF
Dec 22, 2023
This paper proposes an end-to-end framework for generating 3D human pose datasets using Neural Radiance Fields (NeRF). Public datasets generally have limited diversity in terms of human poses and camera viewpoints, largely due to the resource-intensive nature of collecting 3D human pose data. As a result, pose estimators trained on public datasets significantly underperform when applied to unseen out-of-distribution samples. Previous works proposed augmenting public datasets by generating 2D-3D pose pairs or rendering a large amount of random data. Such approaches either overlook image rendering or result in suboptimal datasets for pre-trained models. Here we propose PoseGen, which learns to generate a dataset (human 3D poses and images) with a feedback loss from a given pre-trained pose estimator. In contrast to prior art, our generated data is optimized to improve the robustness of the pre-trained model. The objective of PoseGen is to learn a distribution of data that maximizes the prediction error of a given pre-trained model. As the learned data distribution contains OOD samples of the pre-trained model, sampling data from such a distribution for further fine-tuning a pre-trained model improves the generalizability of the model. This is the first work that proposes NeRFs for 3D human data generation. NeRFs are data-driven and do not require 3D scans of humans. Therefore, using NeRF for data generation is a new direction for convenient user-specific data generation. Our extensive experiments show that the proposed PoseGen improves two baseline models (SPIN and HybrIK) on four datasets with an average 6% relative improvement.
Fusion of Deep and Shallow Features for Face Kinship Verification
Dec 16, 2023Kinship verification from face images is a novel and formidable challenge in the realms of pattern recognition and computer vision. This work makes notable contributions by incorporating a preprocessing technique known as Multiscale Retinex (MSR), which enhances image quality. Our approach harnesses the strength of complementary deep (VGG16) and shallow texture descriptors (BSIF) by combining them at the score level using Logistic Regression (LR) technique. We assess the effectiveness of our approach by conducting comprehensive experiments on three challenging kinship datasets: Cornell Kin Face, UB Kin Face and TS Kin Face
Gradient-based Parameter Selection for Efficient Fine-Tuning
Dec 15, 2023With the growing size of pre-trained models, full fine-tuning and storing all the parameters for various downstream tasks is costly and infeasible. In this paper, we propose a new parameter-efficient fine-tuning method, Gradient-based Parameter Selection (GPS), demonstrating that only tuning a few selected parameters from the pre-trained model while keeping the remainder of the model frozen can generate similar or better performance compared with the full model fine-tuning method. Different from the existing popular and state-of-the-art parameter-efficient fine-tuning approaches, our method does not introduce any additional parameters and computational costs during both the training and inference stages. Another advantage is the model-agnostic and non-destructive property, which eliminates the need for any other design specific to a particular model. Compared with the full fine-tuning, GPS achieves 3.33% (91.78% vs. 88.45%, FGVC) and 9.61% (73.1% vs. 65.57%, VTAB) improvement of the accuracy with tuning only 0.36% parameters of the pre-trained model on average over 24 image classification tasks; it also demonstrates a significant improvement of 17% and 16.8% in mDice and mIoU, respectively, on medical image segmentation task. Moreover, GPS achieves state-of-the-art performance compared with existing PEFT methods.
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
Towards the Unification of Generative and Discriminative Visual Foundation Model: A Survey
Dec 15, 2023The advent of foundation models, which are pre-trained on vast datasets, has ushered in a new era of computer vision, characterized by their robustness and remarkable zero-shot generalization capabilities. Mirroring the transformative impact of foundation models like large language models (LLMs) in natural language processing, visual foundation models (VFMs) have become a catalyst for groundbreaking developments in computer vision. This review paper delineates the pivotal trajectories of VFMs, emphasizing their scalability and proficiency in generative tasks such as text-to-image synthesis, as well as their adeptness in discriminative tasks including image segmentation. While generative and discriminative models have historically charted distinct paths, we undertake a comprehensive examination of the recent strides made by VFMs in both domains, elucidating their origins, seminal breakthroughs, and pivotal methodologies. Additionally, we collate and discuss the extensive resources that facilitate the development of VFMs and address the challenges that pave the way for future research endeavors. A crucial direction for forthcoming innovation is the amalgamation of generative and discriminative paradigms. The nascent application of generative models within discriminative contexts signifies the early stages of this confluence. This survey aspires to be a contemporary compendium for scholars and practitioners alike, charting the course of VFMs and illuminating their multifaceted landscape.
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Dec 14, 2023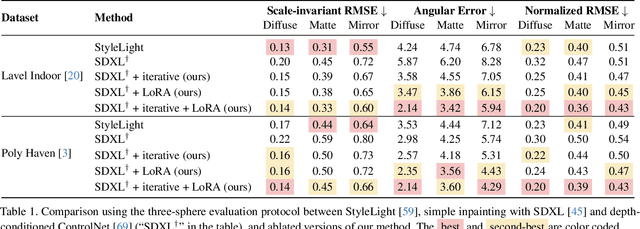


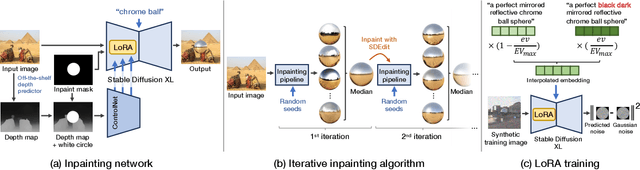
We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.
Tokenize Anything via Prompting
Dec 14, 2023We present a unified, promptable model capable of simultaneously segmenting, recognizing, and captioning anything. Unlike SAM, we aim to build a versatile region representation in the wild via visual prompting. To achieve this, we train a generalizable model with massive segmentation masks, e.g., SA-1B masks, and semantic priors from a pre-trained CLIP model with 5 billion parameters. Specifically, we construct a promptable image decoder by adding a semantic token to each mask token. The semantic token is responsible for learning the semantic priors in a predefined concept space. Through joint optimization of segmentation on mask tokens and concept prediction on semantic tokens, our model exhibits strong regional recognition and localization capabilities. For example, an additional 38M-parameter causal text decoder trained from scratch sets a new record with a CIDEr score of 150.7 on the Visual Genome region captioning task. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of perception tasks. Code and models are available at https://github.com/baaivision/tokenize-anything.
SimAC: A Simple Anti-Customization Method against Text-to-Image Synthesis of Diffusion Models
Dec 13, 2023Despite the success of diffusion-based customization methods on visual content creation, increasing concerns have been raised about such techniques from both privacy and political perspectives. To tackle this issue, several anti-customization methods have been proposed in very recent months, predominantly grounded in adversarial attacks. Unfortunately, most of these methods adopt straightforward designs, such as end-to-end optimization with a focus on adversarially maximizing the original training loss, thereby neglecting nuanced internal properties intrinsic to the diffusion model, and even leading to ineffective optimization in some diffusion time steps. In this paper, we strive to bridge this gap by undertaking a comprehensive exploration of these inherent properties, to boost the performance of current anti-customization approaches. Two aspects of properties are investigated: 1) We examine the relationship between time step selection and the model's perception in the frequency domain of images and find that lower time steps can give much more contributions to adversarial noises. This inspires us to propose an adaptive greedy search for optimal time steps that seamlessly integrates with existing anti-customization methods. 2) We scrutinize the roles of features at different layers during denoising and devise a sophisticated feature-based optimization framework for anti-customization. Experiments on facial benchmarks demonstrate that our approach significantly increases identity disruption, thereby enhancing user privacy and security.
Language-Guided Transformer for Federated Multi-Label Classification
Dec 12, 2023Federated Learning (FL) is an emerging paradigm that enables multiple users to collaboratively train a robust model in a privacy-preserving manner without sharing their private data. Most existing approaches of FL only consider traditional single-label image classification, ignoring the impact when transferring the task to multi-label image classification. Nevertheless, it is still challenging for FL to deal with user heterogeneity in their local data distribution in the real-world FL scenario, and this issue becomes even more severe in multi-label image classification. Inspired by the recent success of Transformers in centralized settings, we propose a novel FL framework for multi-label classification. Since partial label correlation may be observed by local clients during training, direct aggregation of locally updated models would not produce satisfactory performances. Thus, we propose a novel FL framework of Language-Guided Transformer (FedLGT) to tackle this challenging task, which aims to exploit and transfer knowledge across different clients for learning a robust global model. Through extensive experiments on various multi-label datasets (e.g., FLAIR, MS-COCO, etc.), we show that our FedLGT is able to achieve satisfactory performance and outperforms standard FL techniques under multi-label FL scenarios. Code is available at https://github.com/Jack24658735/FedLGT.
Delving Deeper Into Astromorphic Transformers
Dec 18, 2023Preliminary attempts at incorporating the critical role of astrocytes - cells that constitute more than 50% of human brain cells - in brain-inspired neuromorphic computing remain in infancy. This paper seeks to delve deeper into various key aspects of neuron-synapse-astrocyte interactions to mimic self-attention mechanisms in Transformers. The cross-layer perspective explored in this work involves bio-plausible modeling of Hebbian and pre-synaptic plasticities in neuron-astrocyte networks, incorporating effects of non-linearities and feedback along with algorithmic formulations to map the neuron-astrocyte computations to self-attention mechanism and evaluating the impact of incorporating bio-realistic effects from the machine learning application side. Our analysis on sentiment and image classification tasks on the IMDB and CIFAR10 datasets underscores the importance of constructing Astromorphic Transformers from both accuracy and learning speed improvement perspectives.