 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Illusions Also Deceive Convolutional Neural Networks: Analysis and Implications
Dec 03, 2019
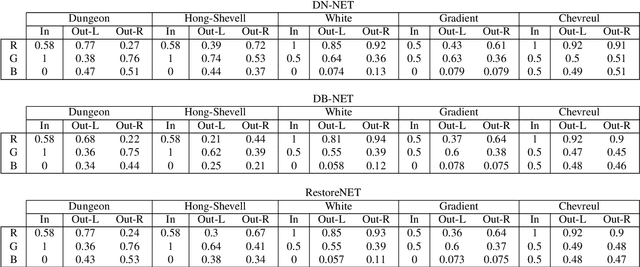
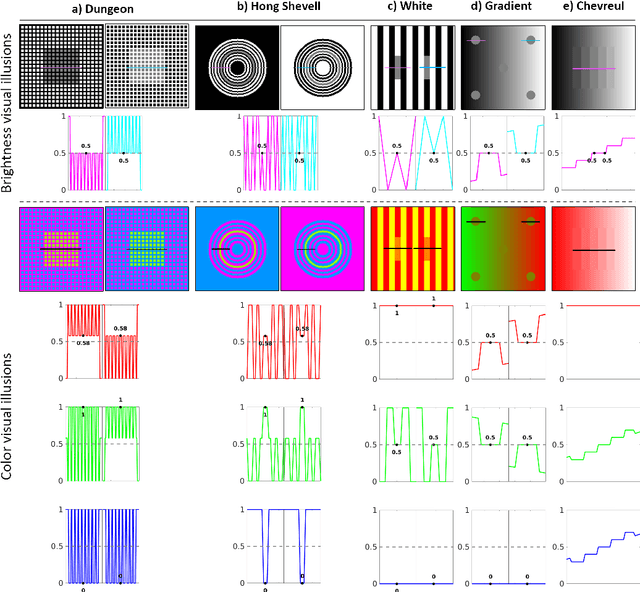
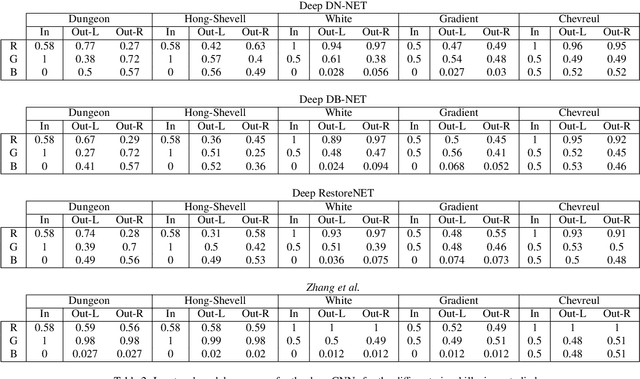
Visual illusions allow researchers to devise and test new models of visual perception. Here we show that artificial neural networks trained for basic visual tasks in natural images are deceived by brightness and color illusions, having a response that is qualitatively very similar to the human achromatic and chromatic contrast sensitivity functions, and consistent with natural image statistics. We also show that, while these artificial networks are deceived by illusions, their response might be significantly different to that of humans. Our results suggest that low-level illusions appear in any system that has to perform basic visual tasks in natural environments, in line with error minimization explanations of visual function, and they also imply a word of caution on using artificial networks to study human vision, as previously suggested in other contexts in the vision science literature.
ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering
Jun 06, 2019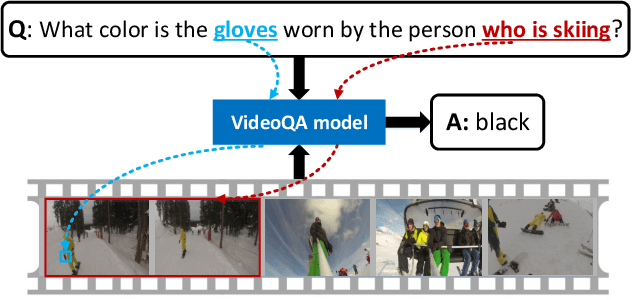

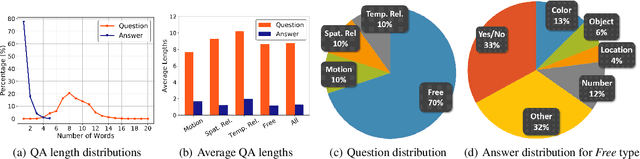
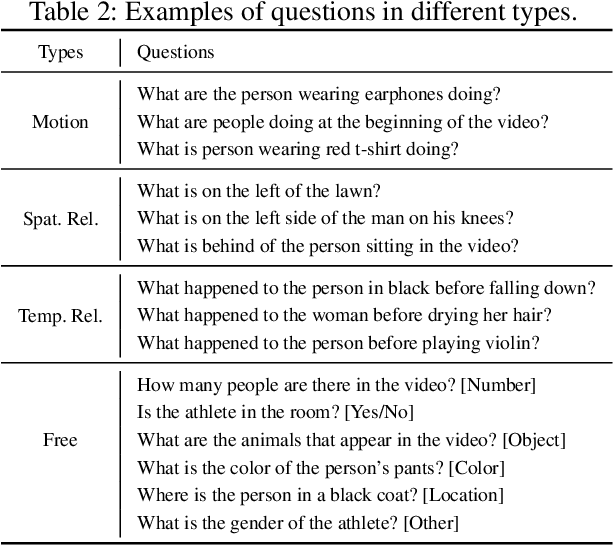
Recent developments in modeling language and vision have been successfully applied to image question answering. It is both crucial and natural to extend this research direction to the video domain for video question answering (VideoQA). Compared to the image domain where large scale and fully annotated benchmark datasets exists, VideoQA datasets are limited to small scale and are automatically generated, etc. These limitations restrict their applicability in practice. Here we introduce ActivityNet-QA, a fully annotated and large scale VideoQA dataset. The dataset consists of 58,000 QA pairs on 5,800 complex web videos derived from the popular ActivityNet dataset. We present a statistical analysis of our ActivityNet-QA dataset and conduct extensive experiments on it by comparing existing VideoQA baselines. Moreover, we explore various video representation strategies to improve VideoQA performance, especially for long videos. The dataset is available at https://github.com/MILVLG/activitynet-qa
Modified Distribution Alignment for Domain Adaptation with Pre-trained Inception ResNet
Apr 18, 2019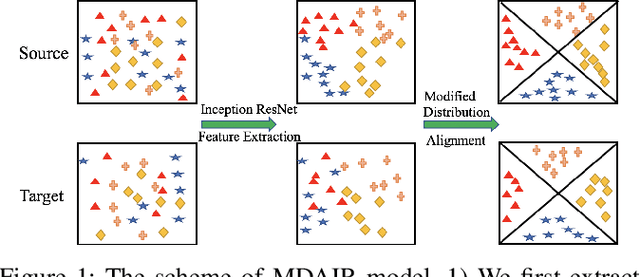
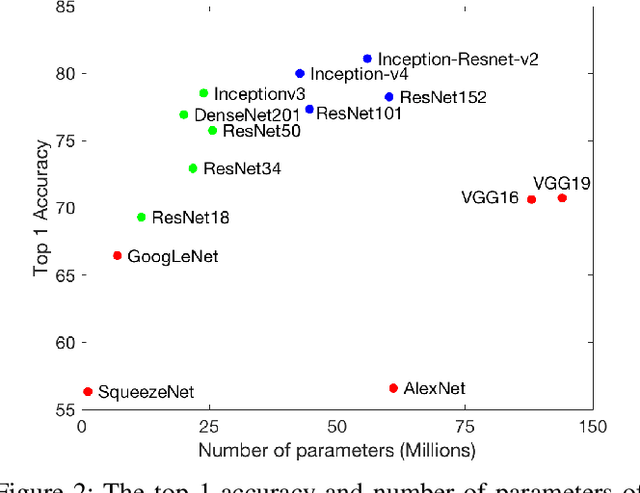

Deep neural networks have been widely used in computer vision. There are several well trained deep neural networks for the ImageNet classification challenge, which has played a significant role in image recognition. However, little work has explored pre-trained neural networks for image recognition in domain adaption. In this paper, we are the first to extract better-represented features from a pre-trained Inception ResNet model for domain adaptation. We then present a modified distribution alignment method for classification using the extracted features. We test our model using three benchmark datasets (Office+Caltech-10, Office-31, and Office-Home). Extensive experiments demonstrate significant improvements (4.8%, 5.5%, and 10%) in classification accuracy over the state-of-the-art.
lambda-Connectedness Determination for Image Segmentation
Mar 16, 2008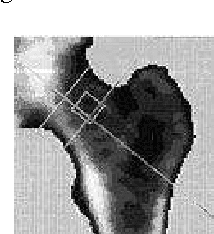
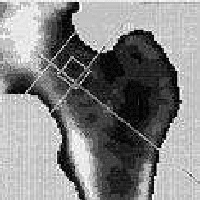

Image segmentation is to separate an image into distinct homogeneous regions belonging to different objects. It is an essential step in image analysis and computer vision. This paper compares some segmentation technologies and attempts to find an automated way to better determine the parameters for image segmentation, especially the connectivity value of $\lambda$ in $\lambda$-connected segmentation. Based on the theories on the maximum entropy method and Otsu's minimum variance method, we propose:(1)maximum entropy connectedness determination: a method that uses maximum entropy to determine the best $\lambda$ value in $\lambda$-connected segmentation, and (2) minimum variance connectedness determination: a method that uses the principle of minimum variance to determine $\lambda$ value. Applying these optimization techniques in real images, the experimental results have shown great promise in the development of the new methods. In the end, we extend the above method to more general case in order to compare it with the famous Mumford-Shah method that uses variational principle and geometric measure.
Learning Mid-Level Features and Modeling Neuron Selectivity for Image Classification
Jan 23, 2014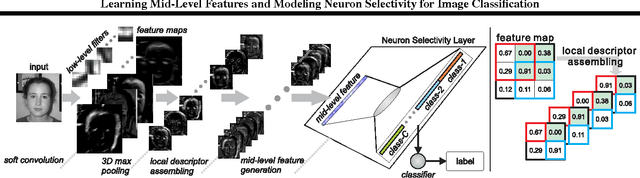
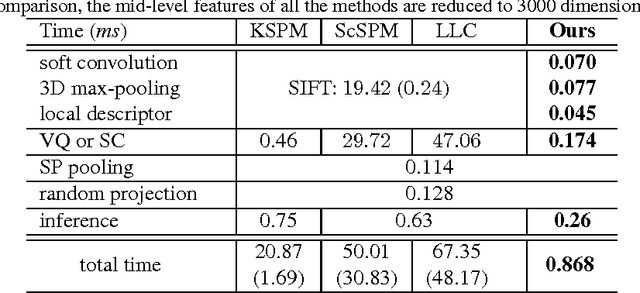
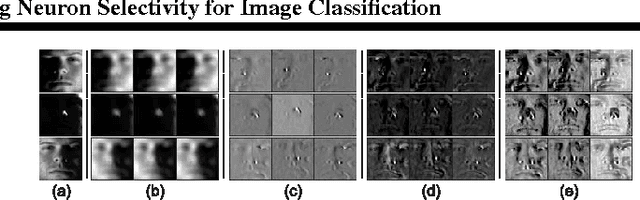
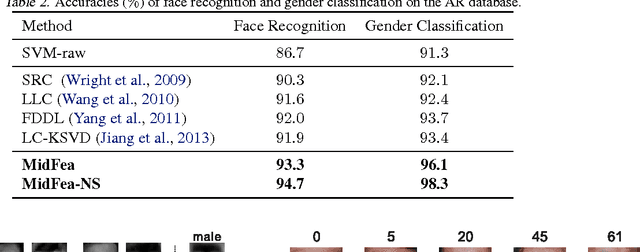
We now know that mid-level features can greatly enhance the performance of image learning, but how to automatically learn the image features efficiently and in an unsupervised manner is still an open question. In this paper, we present a very efficient mid-level feature learning approach (MidFea), which only involves simple operations such as $k$-means clustering, convolution, pooling, vector quantization and random projection. We explain why this simple method generates the desired features, and argue that there is no need to spend much time in learning low-level feature extractors. Furthermore, to boost the performance, we propose to model the neuron selectivity (NS) principle by building an additional layer over the mid-level features before feeding the features into the classifier. We show that the NS-layer learns category-specific neurons with both bottom-up inference and top-down analysis, and thus supports fast inference for a query image. We run extensive experiments on several public databases to demonstrate that our approach can achieve state-of-the-art performances for face recognition, gender classification, age estimation and object categorization. In particular, we demonstrate that our approach is more than an order of magnitude faster than some recently proposed sparse coding based methods.
SCRAM: Spatially Coherent Randomized Attention Maps
May 24, 2019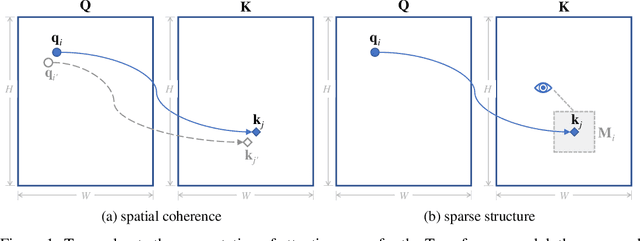
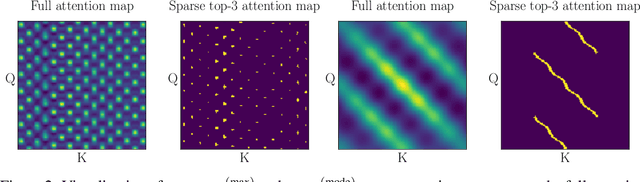
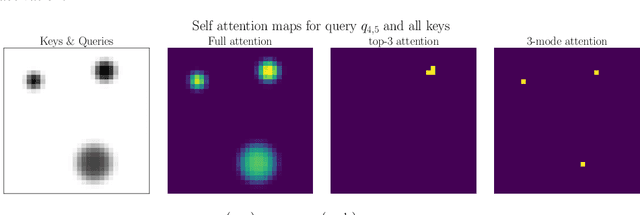
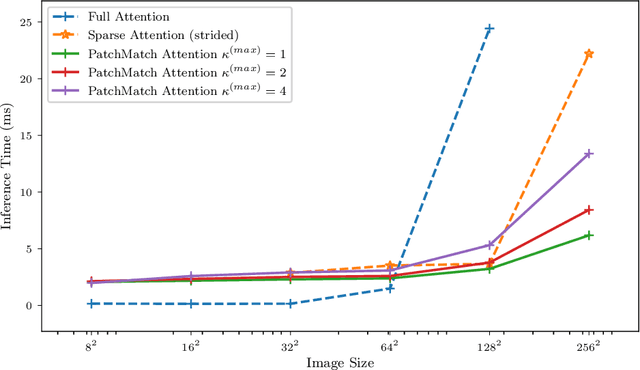
Attention mechanisms and non-local mean operations in general are key ingredients in many state-of-the-art deep learning techniques. In particular, the Transformer model based on multi-head self-attention has recently achieved great success in natural language processing and computer vision. However, the vanilla algorithm computing the Transformer of an image with n pixels has O(n^2) complexity, which is often painfully slow and sometimes prohibitively expensive for large-scale image data. In this paper, we propose a fast randomized algorithm --- SCRAM --- that only requires O(n log(n)) time to produce an image attention map. Such a dramatic acceleration is attributed to our insight that attention maps on real-world images usually exhibit (1) spatial coherence and (2) sparse structure. The central idea of SCRAM is to employ PatchMatch, a randomized correspondence algorithm, to quickly pinpoint the most compatible key (argmax) for each query first, and then exploit that knowledge to design a sparse approximation to non-local mean operations. Using the argmax (mode) to dynamically construct the sparse approximation distinguishes our algorithm from all of the existing sparse approximate methods and makes it very efficient. Moreover, SCRAM is a broadly applicable approximation to any non-local mean layer in contrast to some other sparse approximations that can only approximate self-attention. Our preliminary experimental results suggest that SCRAM is indeed promising for speeding up or scaling up the computation of attention maps in the Transformer.
Flexible, Fast and Accurate Densely-Sampled Light Field Reconstruction Network
Aug 31, 2019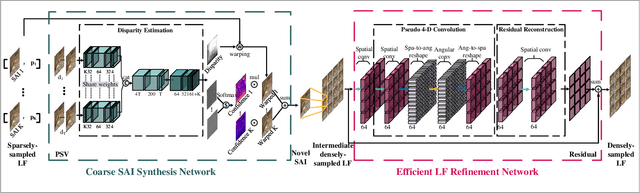

The densely-sampled light field (LF) is highly desirable in various applications, such as 3-D reconstruction, post-capture refocusing and virtual reality. However, it is costly to acquire such data. Although many computational methods have been proposed to reconstruct a densely-sampled LF from a sparsely-sampled one, they still suffer from either low reconstruction quality, low computational efficiency, or the restriction on the regularity of the sampling pattern. To this end, we propose a novel learning-based method, which accepts sparsely-sampled LFs with irregular structures, and produces densely-sampled LFs with arbitrary angular resolution accurately and efficiently. Our proposed method, an end-to-end trainable network, reconstructs a densely-sampled LF in a coarse-to-fine manner. Specifically, the coarse sub-aperture image (SAI) synthesis module first explores the scene geometry from an unstructured sparsely-sampled LF and leverages it to independently synthesize novel SAIs, giving an intermediate densely-sampled LF. Then, the efficient LF refinement module learns the angular relations within the intermediate result to recover the LF parallax structure. Comprehensive experimental evaluations demonstrate the superiority of our method on both real-world and synthetic LF images when compared with state-of-the-art methods. In addition, we illustrate the benefits and advantages of the proposed approach when applied in various LF-based applications, including image-based rendering, depth estimation enhancement, and LF compression.
Interpreting Adversarial Examples by Activation Promotion and Suppression
Apr 03, 2019
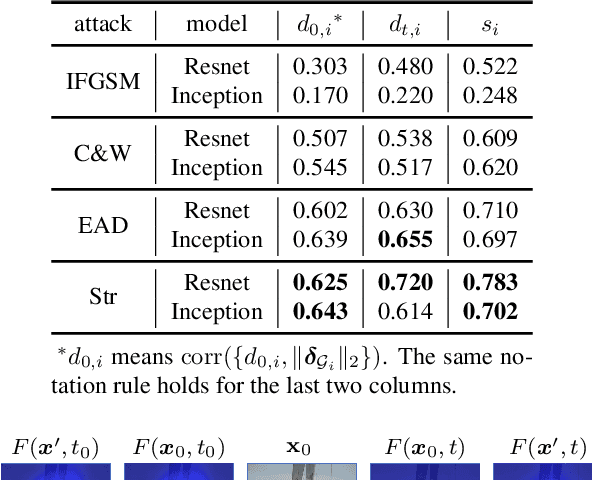
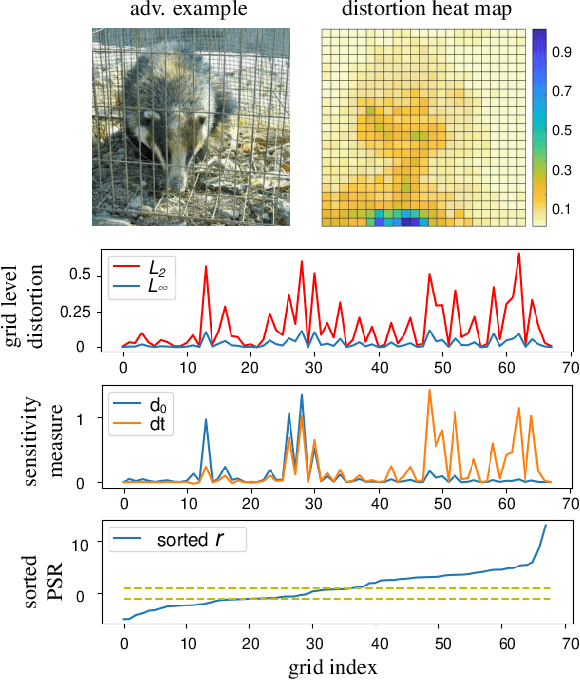

It is widely known that convolutional neural networks (CNNs) are vulnerable to adversarial examples: crafted images with imperceptible perturbations. However, interpretability of these perturbations is less explored in the literature. This work aims to better understand the roles of adversarial perturbations and provide visual explanations from pixel, image and network perspectives. We show that adversaries make a promotion and suppression effect (PSE) on neurons' activation and can be primarily categorized into three types: 1)suppression-dominated perturbations that mainly reduce the classification score of the true label, 2)promotion-dominated perturbations that focus on boosting the confidence of the target label, and 3)balanced perturbations that play a dual role on suppression and promotion. Further, we provide the image-level interpretability of adversarial examples, which links PSE of pixel-level perturbations to class-specific discriminative image regions localized by class activation mapping. Lastly, we analyze the effect of adversarial examples through network dissection, which offers concept-level interpretability of hidden units. We show that there exists a tight connection between the sensitivity (against attacks) of internal response of units with their interpretability on semantic concepts.
A Flexible Framework for Large Graph Learning
Mar 21, 2020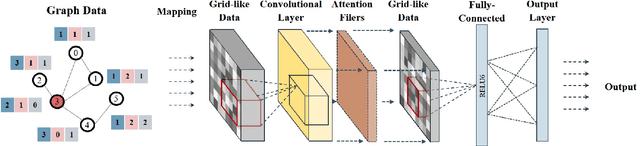

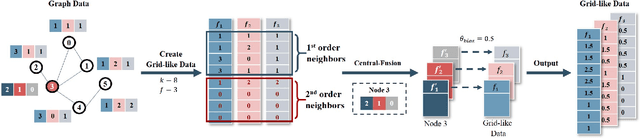
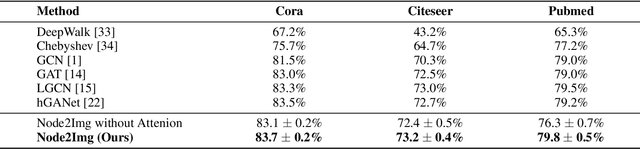
Graph Convolutional Network (GCN) has shown strong effectiveness in graph learning tasks. However, GCN faces challenges in flexibility due to the fact of requiring the full graph Laplacian available in the training phase. Moreover, with the depth of layers increases, the computational and memory cost of GCN grows explosively on account of the recursive neighborhood expansion, which leads to a limitation in processing large graphs. To tackle these issues, we take advantage of image processing in agility and present Node2Img, a flexible architecture for large-scale graph learning. Node2Img maps the nodes to "images" (i.e. grid-like data in Euclidean space) which can be the inputs of Convolutional Neural Network (CNN). Instead of leveraging the fixed whole network as a batch to train the model, Node2Img supports a more efficacious framework in practice, where the batch size can be set elastically and the data in the same batch can be calculated parallelly. Specifically, by ranking each node's influence through degree, Node2Img selects the most influential first-order as well as second-order neighbors with central node fusion information to construct the grid-like data. For further improving the efficiency of downstream tasks, a simple CNN-based neural network is employed to capture the significant information from the Euclidean grids. Additionally, the attention mechanism is implemented, which enables implicitly specifying the different weights for neighboring nodes with different influences. Extensive experiments on real graphs' transductive and inductive learning tasks demonstrate the superiority of the proposed Node2Img model against the state-of-the-art GCN-based approaches.
Task-Aware Variational Adversarial Active Learning
Feb 11, 2020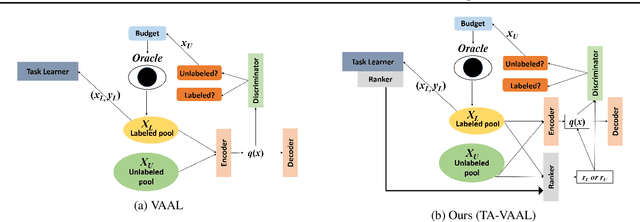
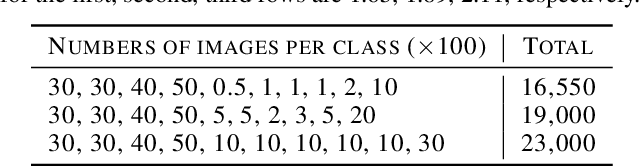
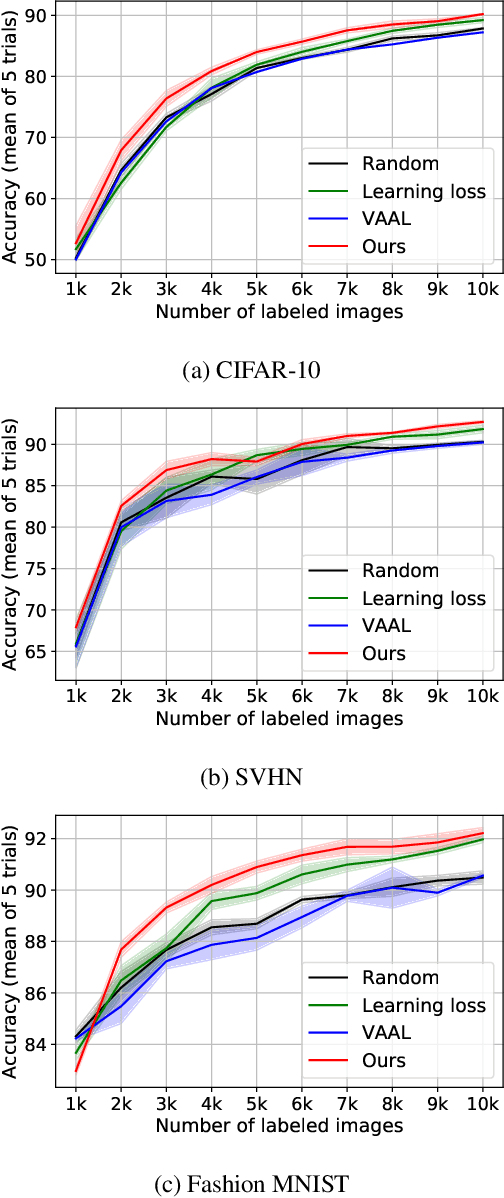
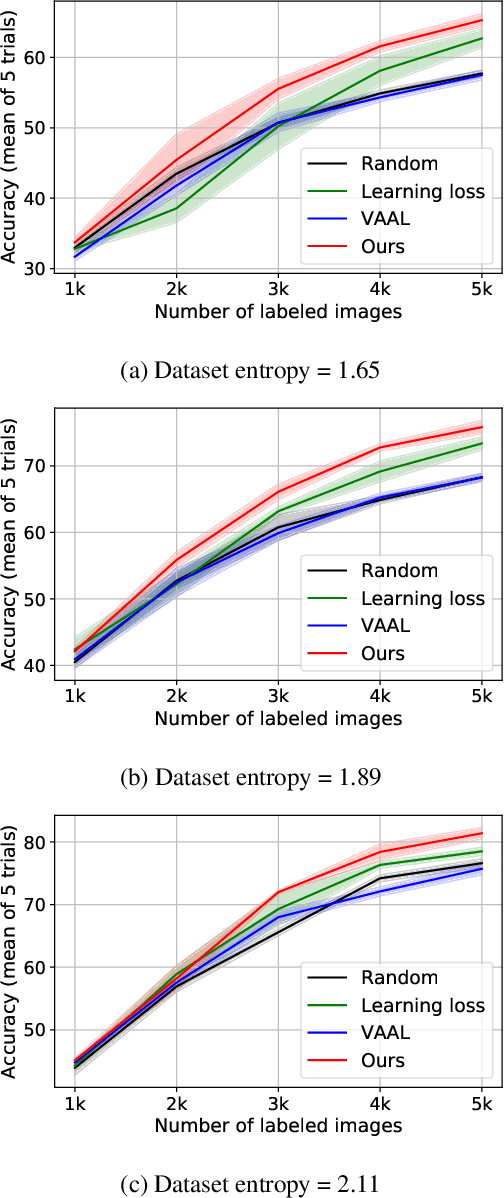
Deep learning has achieved remarkable performance in various tasks thanks to massive labeled datasets. However, there are often cases where labeling large amount of data is challenging or infeasible due to high labeling cost such as labeling by experts or long labeling time per large-scale data sample (e.g., video, very large image). Active learning is one of the ways to query the most informative samples to be annotated among massive unlabeled pool. Two promising directions for active learning that have been recently explored are data distribution-based approach to select data points that are far from current labeled pool and model uncertainty-based approach that relies on the perspective of task model. Unfortunately, the former does not exploit structures from tasks and the latter does not seem to well-utilize overall data distribution. Here, we propose the methods that simultaneously take advantage of both data distribution and model uncertainty approaches. Our proposed methods exploit variational adversarial active learning (VAAL), that considered data distribution of both label and unlabeled pools, by incorporating learning loss prediction module and RankCGAN concept into VAAL by modeling loss prediction as a ranker. We demonstrate that our proposed methods outperform recent state-of-the-art active learning methods on various balanced and imbalanced benchmark datasets.