 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On Mixup Training: Improved Calibration and Predictive Uncertainty for Deep Neural Networks
May 27, 2019
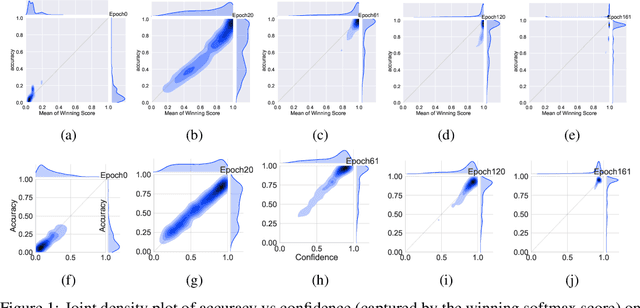
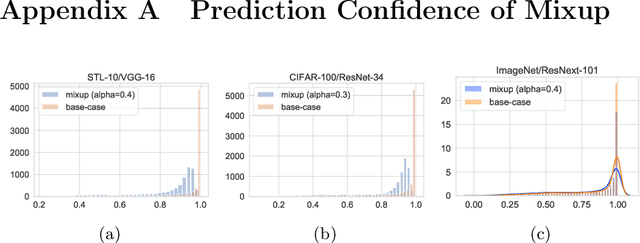
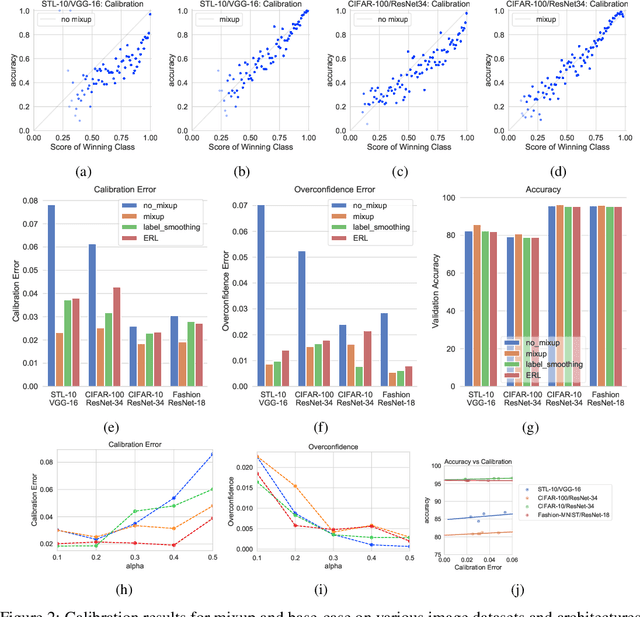
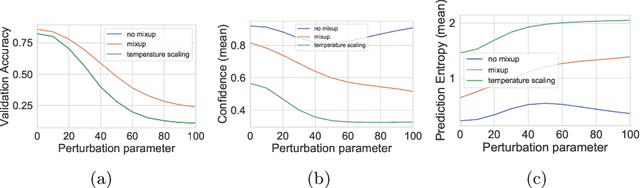
Mixup~\cite{zhang2017mixup} is a recently proposed method for training deep neural networks where additional samples are generated during training by convexly combining random pairs of images and their associated labels. While simple to implement, it has shown to be a surprisingly effective method of data augmentation for image classification; DNNs trained with mixup show noticeable gains in classification performance on a number of image classification benchmarks. In this work, we discuss a hitherto untouched aspect of mixup training -- the calibration and predictive uncertainty of models trained with mixup. We find that DNNs trained with mixup are significantly better calibrated -- i.e., the predicted softmax scores are much better indicators of the actual likelihood of a correct prediction -- than DNNs trained in the regular fashion. We conduct experiments on a number of image classification architectures and datasets -- including large-scale datasets like ImageNet -- and find this to be the case. Additionally, we find that merely mixing features does not result in the same calibration benefit and that the label smoothing in mixup training plays a significant role in improving calibration. Finally, we also observe that mixup-trained DNNs are less prone to over-confident predictions on out-of-distribution and random-noise data. We conclude that the typical overconfidence seen in neural networks, even on in-distribution data is likely a consequence of training with hard labels, suggesting that mixup training be employed for classification tasks where predictive uncertainty is a significant concern.
Adversarial Transformations for Semi-Supervised Learning
Nov 13, 2019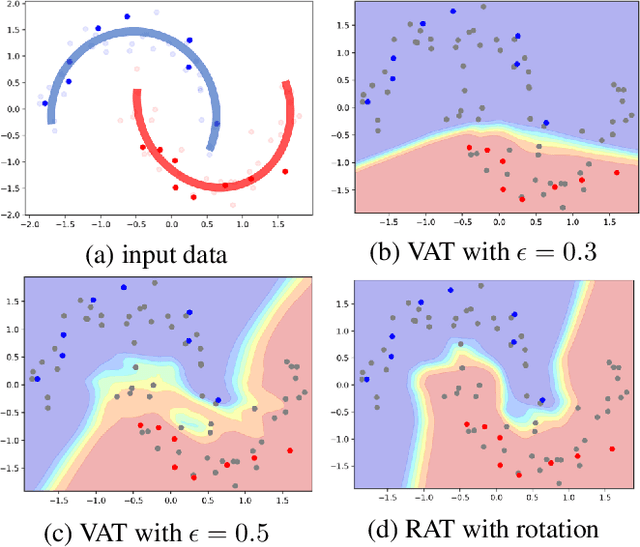


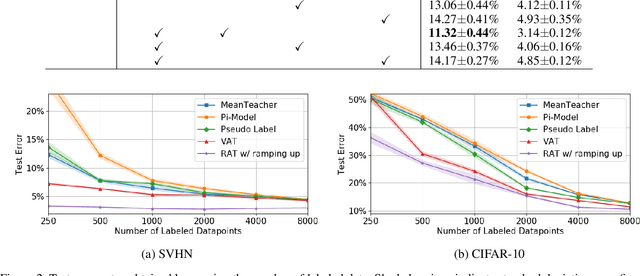
We propose a Regularization framework based on Adversarial Transformations (RAT) for semi-supervised learning. RAT is designed to enhance robustness of the output distribution of class prediction for a given data against input perturbation. RAT is an extension of Virtual Adversarial Training (VAT) in such a way that RAT adversarialy transforms data along the underlying data distribution by a rich set of data transformation functions that leave class label invariant, whereas VAT simply produces adversarial additive noises. In addition, we verified that a technique of gradually increasing of perturbation region further improve the robustness. In experiments, we show that RAT significantly improves classification performance on CIFAR-10 and SVHN compared to existing regularization methods under standard semi-supervised image classification settings.
Reducing audio membership inference attack accuracy to chance: 4 defenses
Oct 31, 2019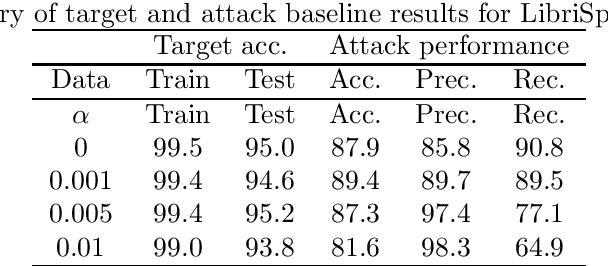
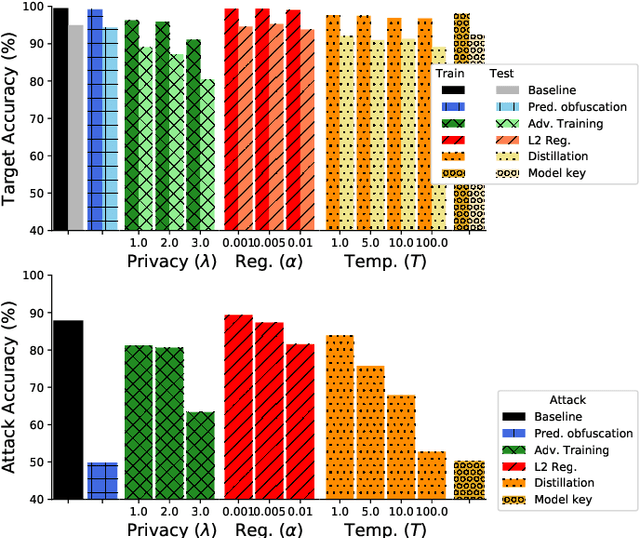
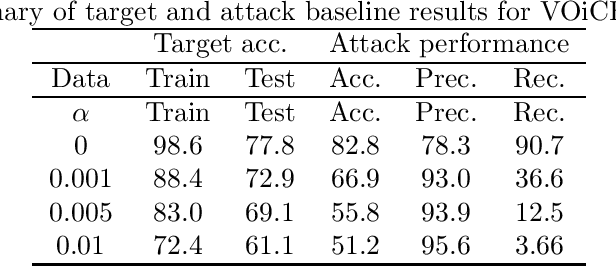
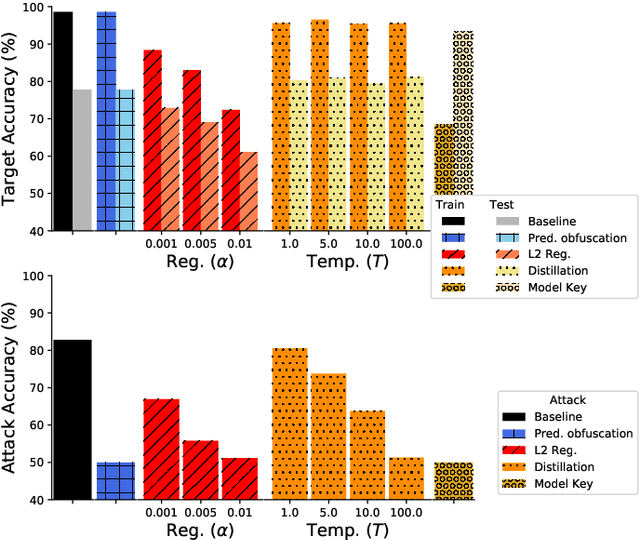
It is critical to understand the privacy and robustness vulnerabilities of machine learning models, as their implementation expands in scope. In membership inference attacks, adversaries can determine whether a particular set of data was used in training, putting the privacy of the data at risk. Existing work has mostly focused on image related tasks; we generalize this type of attack to speaker identification on audio samples. We demonstrate attack precision of 85.9\% and recall of 90.8\% for LibriSpeech, and 78.3\% precision and 90.7\% recall for VOiCES (Voices Obscured in Complex Environmental Settings). We find that implementing defenses such as prediction obfuscation, defensive distillation or adversarial training, can reduce attack accuracy to chance.
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
Jan 18, 2019
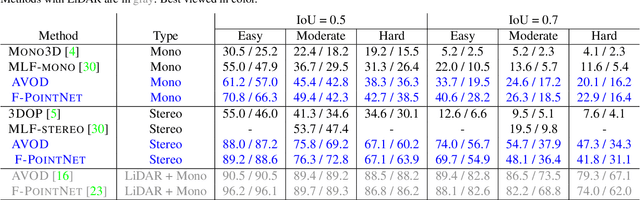


3D object detection is an essential task in autonomous driving. Recent techniques excel with highly accurate detection rates, provided the 3D input data is obtained from precise but expensive LiDAR technology. Approaches based on cheaper monocular or stereo imagery data have, until now, resulted in drastically lower accuracies --- a gap that is commonly attributed to poor image-based depth estimation. However, in this paper we argue that data representation (rather than its quality) accounts for the majority of the difference. Taking the inner workings of convolutional neural networks into consideration, we propose to convert image-based depth maps to pseudo-LiDAR representations --- essentially mimicking LiDAR signal. With this representation we can apply different existing LiDAR-based detection algorithms. On the popular KITTI benchmark, our approach achieves impressive improvements over the existing state-of-the-art in image-based performance --- raising the detection accuracy of objects within 30m range from the previous state-of-the-art of 22% to an unprecedented 74%. At the time of submission our algorithm holds the highest entry on the KITTI 3D object detection leaderboard for stereo image based approaches.
Semi-supervised learning method based on predefined evenly-distributed class centroids
Jan 13, 2020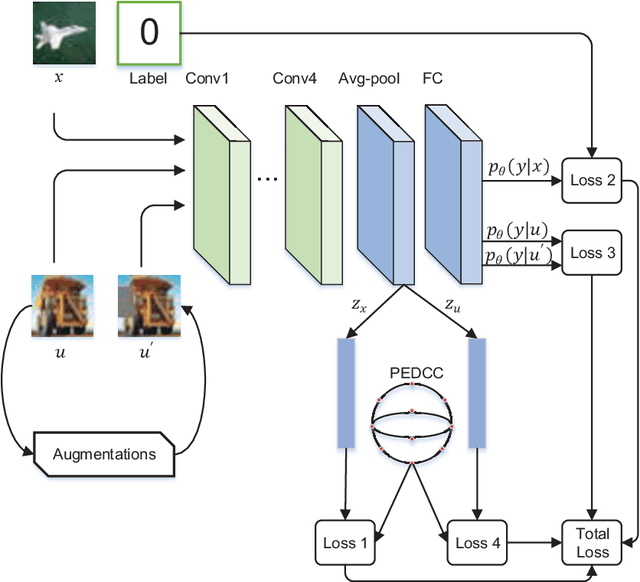
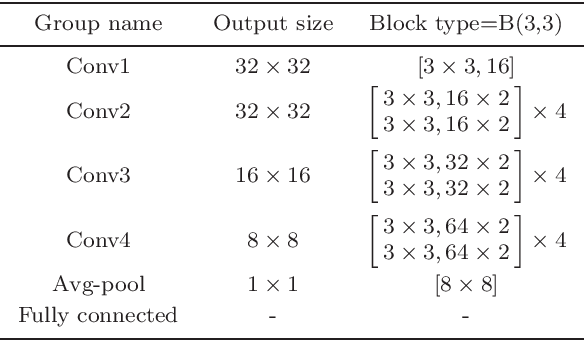
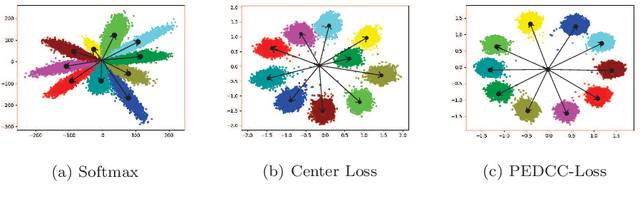

Compared to supervised learning, semi-supervised learning reduces the dependence of deep learning on a large number of labeled samples. In this work, we use a small number of labeled samples and perform data augmentation on unlabeled samples to achieve image classification. Our method constrains all samples to the predefined evenly-distributed class centroids (PEDCC) by the corresponding loss function. Specifically, the PEDCC-Loss for labeled samples, and the maximum mean discrepancy loss for unlabeled samples are used to make the feature distribution closer to the distribution of PEDCC. Our method ensures that the inter-class distance is large and the intra-class distance is small enough to make the classification boundaries between different classes clearer. Meanwhile, for unlabeled samples, we also use KL divergence to constrain the consistency of the network predictions between unlabeled and augmented samples. Our semi-supervised learning method achieves the state-of-the-art results, with 4000 labeled samples on CIFAR10 and 1000 labeled samples on SVHN, and the accuracy is 95.10% and 97.58% respectively.
A Differential Approach for Gaze Estimation
Apr 24, 2019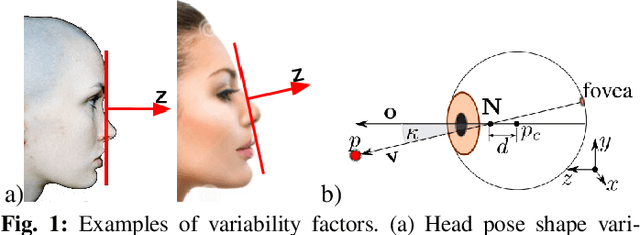
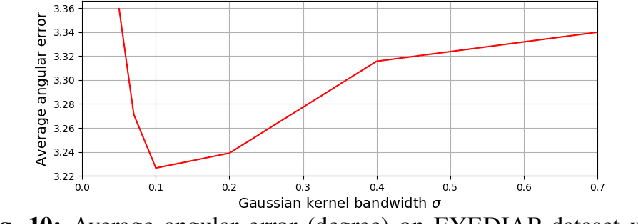

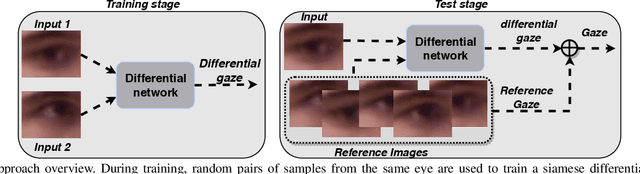
Non-invasive gaze estimation methods usually regress gaze directions directly from a single face or eye image. However, due to important variabilities in eye shapes and inner eye structures amongst individuals, universal models obtain limited accuracies and their output usually exhibit high variance as well as biases which are subject dependent. Therefore, increasing accuracy is usually done through calibration, allowing gaze predictions for a subject to be mapped to his/her actual gaze. In this paper, we introduce a novel image differential method for gaze estimation. We propose to directly train a differential convolutional neural network to predict the gaze differences between two eye input images of the same subject. Then, given a set of subject specific calibration images, we can use the inferred differences to predict the gaze direction of a novel eye sample. The assumption is that by allowing the comparison between two eye images, annoyance factors (alignment, eyelid closing, illumination perturbations) which usually plague single image prediction methods can be much reduced, allowing better prediction altogether. Experiments on 3 public datasets validate our approach which constantly outperforms state-of-the-art methods even when using only one calibration sample or when the latter methods are followed by subject specific gaze adaptation.
Non-photorealistic image processing: an Impressionist rendering
Dec 04, 2009The paper describes an image processing for a non-photorealistic rendering. The algorithm is based on a random choice of a set of pixels from those ot the original image and substitution of them with colour spots. An iterative procedure is applied to cover, at a desired level, the canvas. The resulting effect mimics the impressionist painting and Pointillism.
Complete CVDL Methodology for Investigating Hydrodynamic Instabilities
Apr 03, 2020
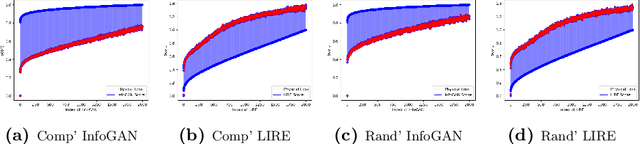

In fluid dynamics, one of the most important research fields is hydrodynamic instabilities and their evolution in different flow regimes. The investigation of said instabilities is concerned with the highly non-linear dynamics. Currently, three main methods are used for understanding of such phenomenon - namely analytical models, experiments and simulations - and all of them are primarily investigated and correlated using human expertise. In this work we claim and demonstrate that a major portion of this research effort could and should be analysed using recent breakthrough advancements in the field of Computer Vision with Deep Learning (CVDL, or Deep Computer-Vision). Specifically, we target and evaluate specific state-of-the-art techniques - such as Image Retrieval, Template Matching, Parameters Regression and Spatiotemporal Prediction - for the quantitative and qualitative benefits they provide. In order to do so we focus in this research on one of the most representative instabilities, the Rayleigh-Taylor one, simulate its behaviour and create an open-sourced state-of-the-art annotated database (RayleAI). Finally, we use adjusted experimental results and novel physical loss methodologies to validate the correspondence of the predicted results to actual physical reality to prove the models efficiency. The techniques which were developed and proved in this work can be served as essential tools for physicists in the field of hydrodynamics for investigating a variety of physical systems, and also could be used via Transfer Learning to other instabilities research. A part of the techniques can be easily applied on already exist simulation results. All models as well as the data-set that was created for this work, are publicly available at: https://github.com/scientific-computing-nrcn/SimulAI.
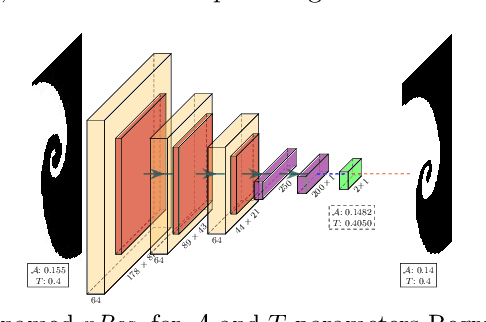
Revealing Scenes by Inverting Structure from Motion Reconstructions
Apr 05, 2019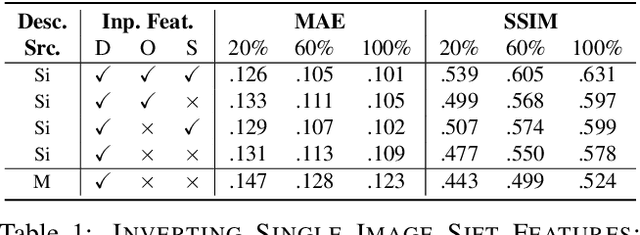
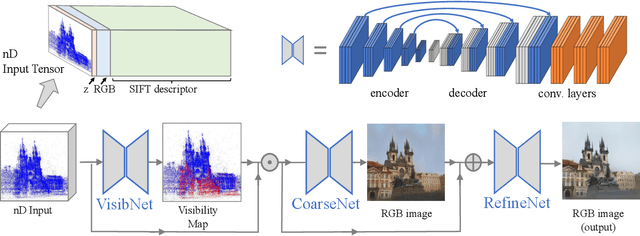
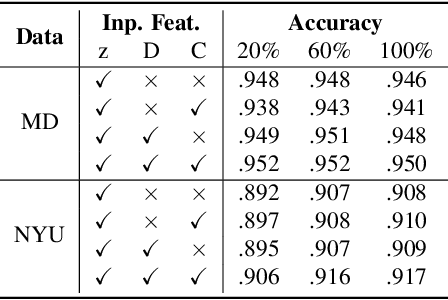

Many 3D vision systems localize cameras within a scene using 3D point clouds. Such point clouds are often obtained using structure from motion (SfM), after which the images are discarded to preserve privacy. In this paper, we show, for the first time, that such point clouds retain enough information to reveal scene appearance and compromise privacy. We present a privacy attack that reconstructs color images of the scene from the point cloud. Our method is based on a cascaded U-Net that takes as input, a 2D multichannel image of the points rendered from a specific viewpoint containing point depth and optionally color and SIFT descriptors and outputs a color image of the scene from that viewpoint. Unlike previous feature inversion methods, we deal with highly sparse and irregular 2D point distributions and inputs where many point attributes are missing, namely keypoint orientation and scale, the descriptor image source and the 3D point visibility. We evaluate our attack algorithm on public datasets and analyze the significance of the point cloud attributes. Finally, we show that novel views can also be generated thereby enabling compelling virtual tours of the underlying scene.
Color Constancy based on Image Similarity via Bilayer Sparse Coding
Nov 08, 2012Computational color constancy is a very important topic in computer vision and has attracted many researchers' attention. Recently, lots of research has shown the effects of high level visual content information for illumination estimation. However, all of these existing methods are essentially combinational strategies in which image's content analysis is only used to guide the combination or selection from a variety of individual illumination estimation methods. In this paper, we propose a novel bilayer sparse coding model for illumination estimation that considers image similarity in terms of both low level color distribution and high level image scene content simultaneously. For the purpose, the image's scene content information is integrated with its color distribution to obtain optimal illumination estimation model. The experimental results on two real-world image sets show that our algorithm is superior to other prevailing illumination estimation methods, even better than combinational methods.