 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nested Invariance Pooling and RBM Hashing for Image Instance Retrieval
Apr 14, 2016
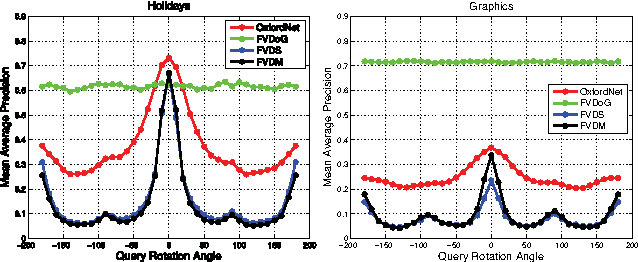
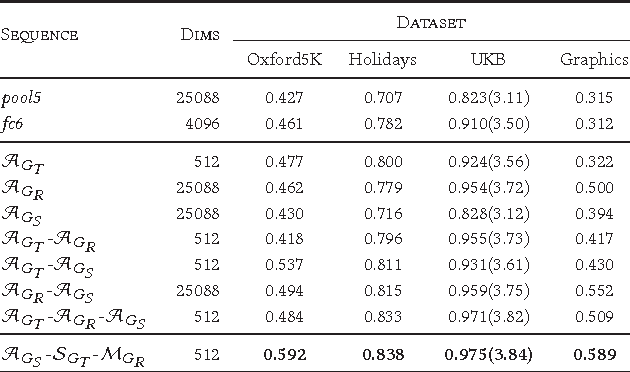
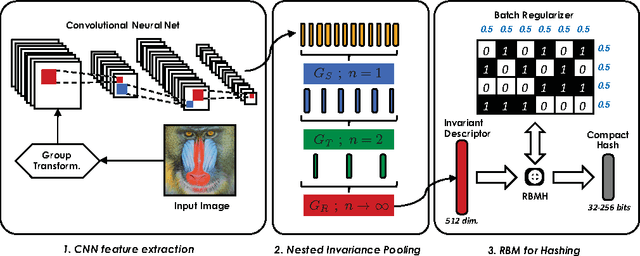

The goal of this work is the computation of very compact binary hashes for image instance retrieval. Our approach has two novel contributions. The first one is Nested Invariance Pooling (NIP), a method inspired from i-theory, a mathematical theory for computing group invariant transformations with feed-forward neural networks. NIP is able to produce compact and well-performing descriptors with visual representations extracted from convolutional neural networks. We specifically incorporate scale, translation and rotation invariances but the scheme can be extended to any arbitrary sets of transformations. We also show that using moments of increasing order throughout nesting is important. The NIP descriptors are then hashed to the target code size (32-256 bits) with a Restricted Boltzmann Machine with a novel batch-level regularization scheme specifically designed for the purpose of hashing (RBMH). A thorough empirical evaluation with state-of-the-art shows that the results obtained both with the NIP descriptors and the NIP+RBMH hashes are consistently outstanding across a wide range of datasets.
Discriminative Joint Probability Maximum Mean Discrepancy (DJP-MMD) for Domain Adaptation
Jan 14, 2020
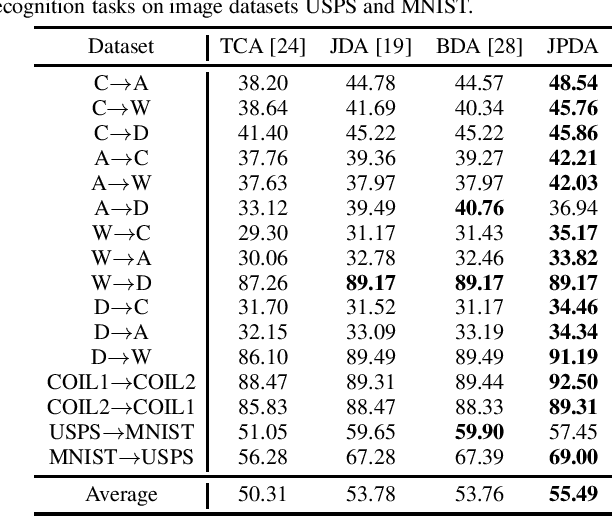
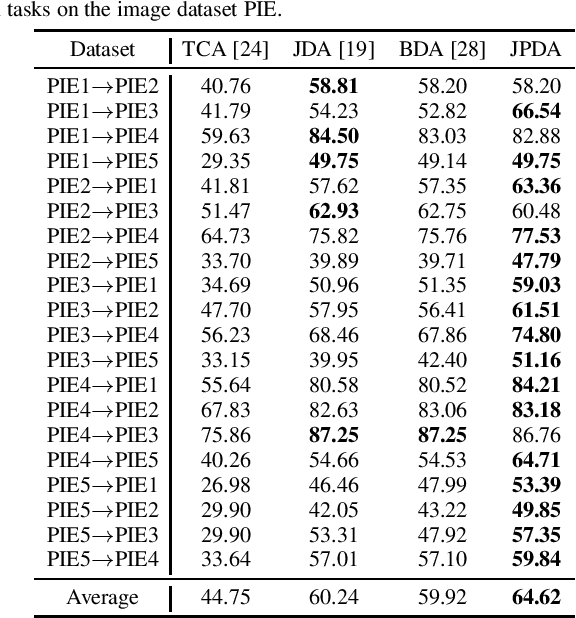
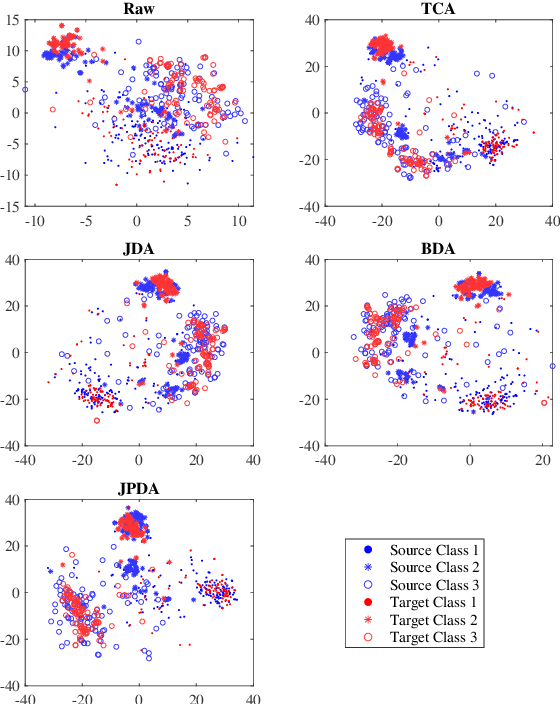
Maximum mean discrepancy (MMD) has been widely adopted in domain adaptation to measure the discrepancy between the source and target domain distributions. Many existing domain adaptation approaches are based on the joint MMD, which is computed as the (weighted) sum of the marginal distribution discrepancy and the conditional distribution discrepancy; however, a more natural metric may be their joint probability distribution discrepancy. Additionally, most metrics only aim to increase the transferability between domains, but ignores the discriminability between different classes, which may result in insufficient classification performance. To address these issues, discriminative joint probability MMD (DJP-MMD) is proposed in this paper to replace the frequently-used joint MMD in domain adaptation. It has two desirable properties: 1) it provides a new theoretical basis for computing the distribution discrepancy, which is simpler and more accurate; 2) it increases the transferability and discriminability simultaneously. We validate its performance by embedding it into a joint probability domain adaptation framework. Experiments on six image classification datasets demonstrated that the proposed DJP-MMD can outperform traditional MMDs.
Bayes Merging of Multiple Vocabularies for Scalable Image Retrieval
Apr 13, 2014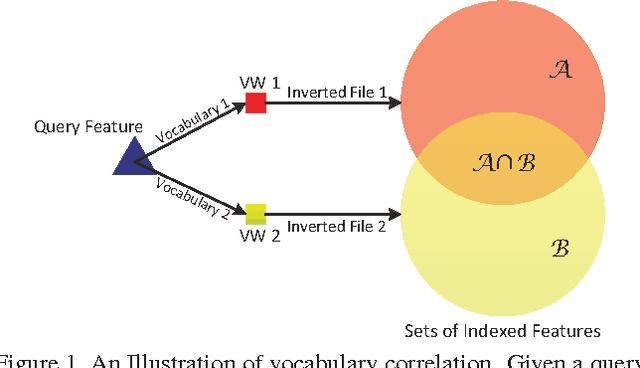
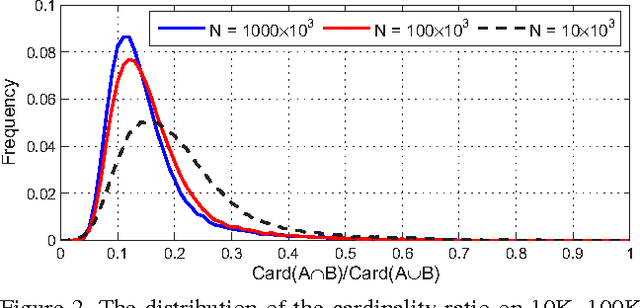

The Bag-of-Words (BoW) representation is well applied to recent state-of-the-art image retrieval works. Typically, multiple vocabularies are generated to correct quantization artifacts and improve recall. However, this routine is corrupted by vocabulary correlation, i.e., overlapping among different vocabularies. Vocabulary correlation leads to an over-counting of the indexed features in the overlapped area, or the intersection set, thus compromising the retrieval accuracy. In order to address the correlation problem while preserve the benefit of high recall, this paper proposes a Bayes merging approach to down-weight the indexed features in the intersection set. Through explicitly modeling the correlation problem in a probabilistic view, a joint similarity on both image- and feature-level is estimated for the indexed features in the intersection set. We evaluate our method through extensive experiments on three benchmark datasets. Albeit simple, Bayes merging can be well applied in various merging tasks, and consistently improves the baselines on multi-vocabulary merging. Moreover, Bayes merging is efficient in terms of both time and memory cost, and yields competitive performance compared with the state-of-the-art methods.
Cell R-CNN V3: A Novel Panoptic Paradigm for Instance Segmentation in Biomedical Images
Feb 15, 2020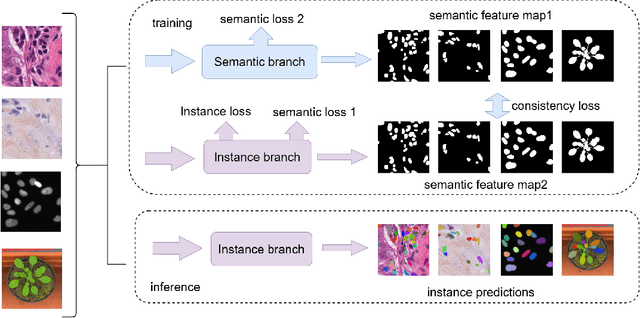
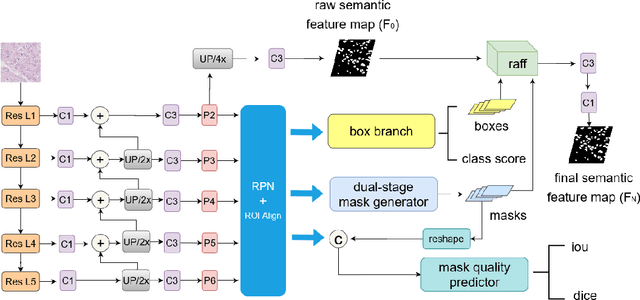
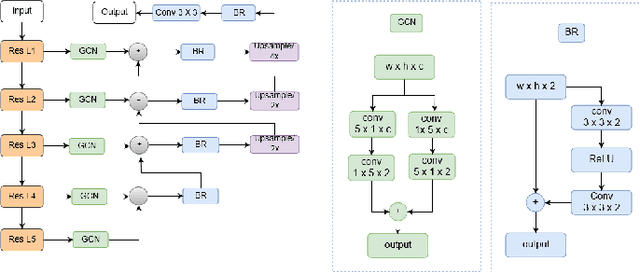
Instance segmentation is an important task for biomedical image analysis. Due to the complicated background components, the high variability of object appearances, numerous overlapping objects, and ambiguous object boundaries, this task still remains challenging. Recently, deep learning based methods have been widely employed to solve these problems and can be categorized into proposal-free and proposal-based methods. However, both proposal-free and proposal-based methods suffer from information loss, as they focus on either global-level semantic or local-level instance features. To tackle this issue, we present a panoptic architecture that unifies the semantic and instance features in this work. Specifically, our proposed method contains a residual attention feature fusion mechanism to incorporate the instance prediction with the semantic features, in order to facilitate the semantic contextual information learning in the instance branch. Then, a mask quality branch is designed to align the confidence score of each object with the quality of the mask prediction. Furthermore, a consistency regularization mechanism is designed between the semantic segmentation tasks in the semantic and instance branches, for the robust learning of both tasks. Extensive experiments demonstrate the effectiveness of our proposed method, which outperforms several state-of-the-art methods on various biomedical datasets.
Spectral Metric for Dataset Complexity Assessment
May 17, 2019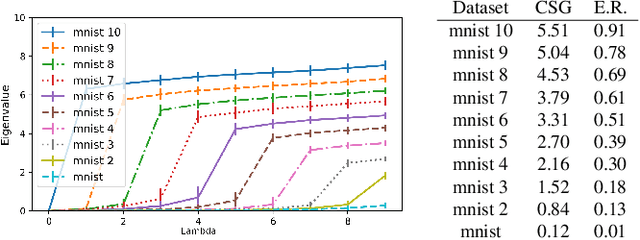
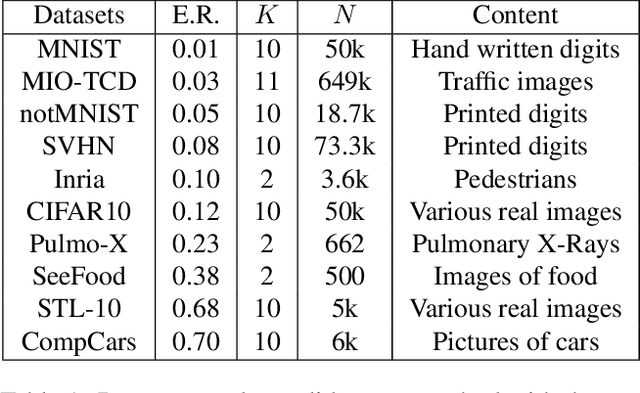
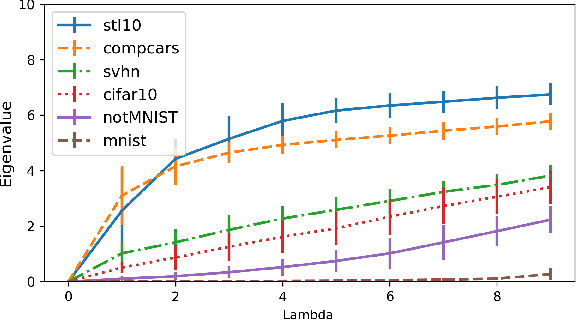
In this paper, we propose a new measure to gauge the complexity of image classification problems. Given an annotated image dataset, our method computes a complexity measure called the cumulative spectral gradient (CSG) which strongly correlates with the test accuracy of convolutional neural networks (CNN). The CSG measure is derived from the probabilistic divergence between classes in a spectral clustering framework. We show that this metric correlates with the overall separability of the dataset and thus its inherent complexity. As will be shown, our metric can be used for dataset reduction, to assess which classes are more difficult to disentangle, and approximate the accuracy one could expect to get with a CNN. Results obtained on 11 datasets and three CNN models reveal that our method is more accurate and faster than previous complexity measures.
When Unseen Domain Generalization is Unnecessary? Rethinking Data Augmentation
Jun 12, 2019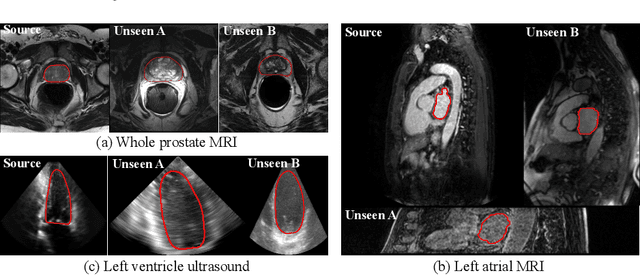

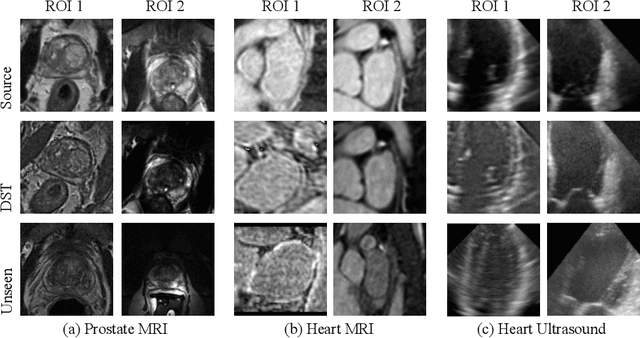
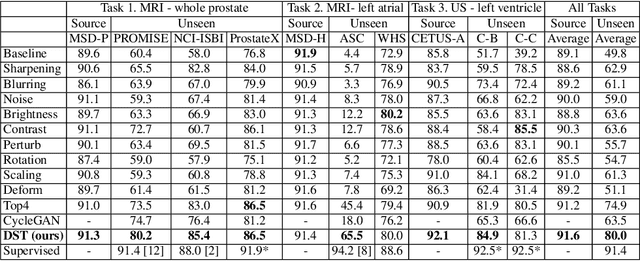
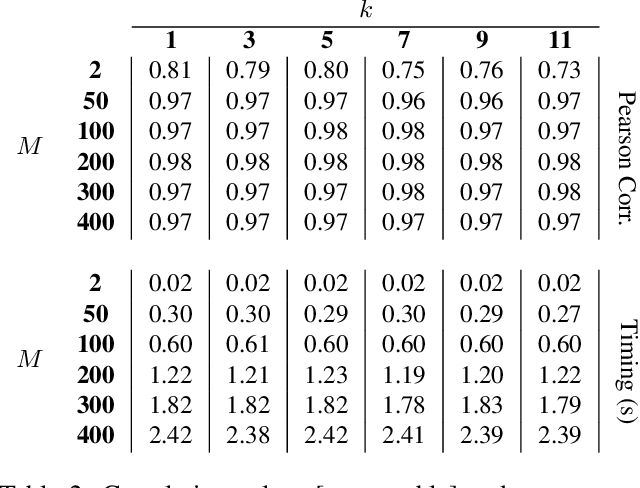
Recent advances in deep learning for medical image segmentation demonstrate expert-level accuracy. However, in clinically realistic environments, such methods have marginal performance due to differences in image domains, including different imaging protocols, device vendors and patient populations. Here we consider the problem of domain generalization, when a model is trained once, and its performance generalizes to unseen domains. Intuitively, within a specific medical imaging modality the domain differences are smaller relative to natural images domain variability. We rethink data augmentation for medical 3D images and propose a deep stacked transformations (DST) approach for domain generalization. Specifically, a series of n stacked transformations are applied to each image in each mini-batch during network training to account for the contribution of domain-specific shifts in medical images. We comprehensively evaluate our method on three tasks: segmentation of whole prostate from 3D MRI, left atrial from 3D MRI, and left ventricle from 3D ultrasound. We demonstrate that when trained on a small source dataset, (i) on average, DST models on unseen datasets degrade only by 11% (Dice score change), compared to the conventional augmentation (degrading 39%) and CycleGAN-based domain adaptation method (degrading 25%); (ii) when evaluation on the same domain, DST is also better albeit only marginally. (iii) When training on large-sized data, DST on unseen domains reaches performance of state-of-the-art fully supervised models. These findings establish a strong benchmark for the study of domain generalization in medical imaging, and can be generalized to the design of robust deep segmentation models for clinical deployment.
New approach using Bayesian Network to improve content based image classification systems
Apr 07, 2012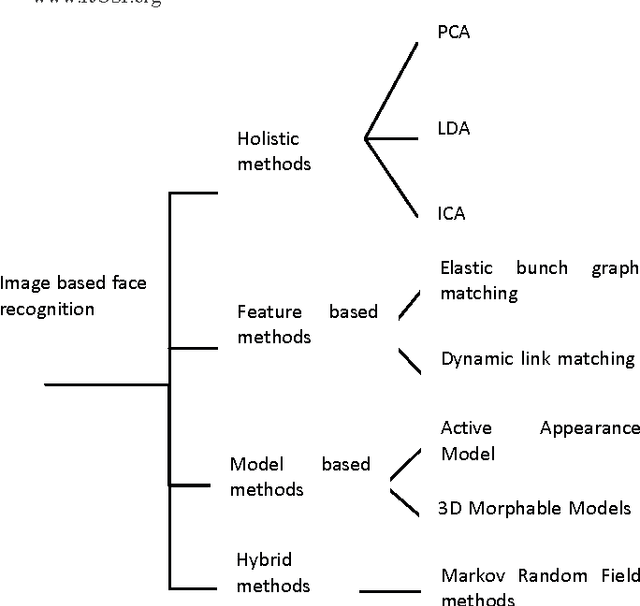
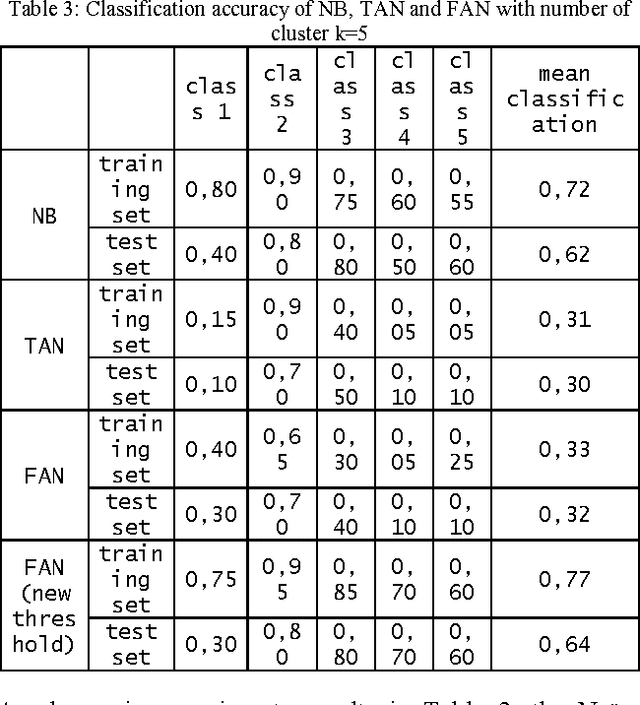
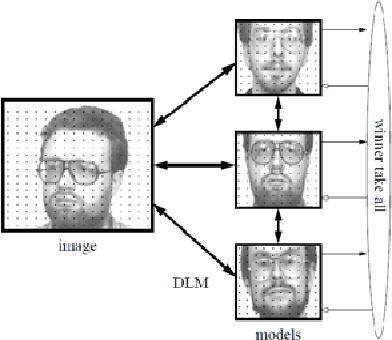
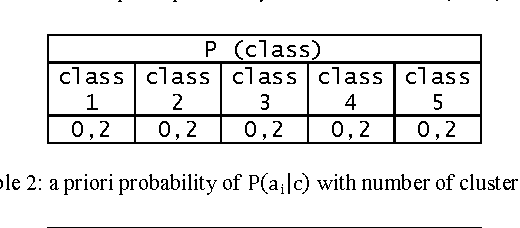
This paper proposes a new approach based on augmented naive Bayes for image classification. Initially, each image is cutting in a whole of blocks. For each block, we compute a vector of descriptors. Then, we propose to carry out a classification of the vectors of descriptors to build a vector of labels for each image. Finally, we propose three variants of Bayesian Networks such as Naive Bayesian Network (NB), Tree Augmented Naive Bayes (TAN) and Forest Augmented Naive Bayes (FAN) to classify the image using the vector of labels. The results showed a marked improvement over the FAN, NB and TAN.
Generating Adversarial Perturbation with Root Mean Square Gradient
Jan 26, 2019
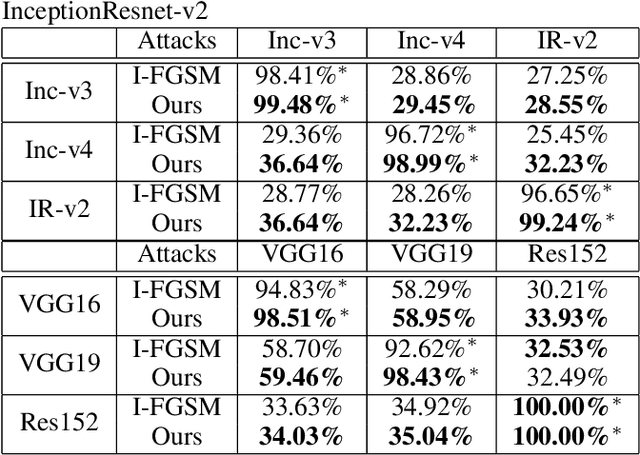
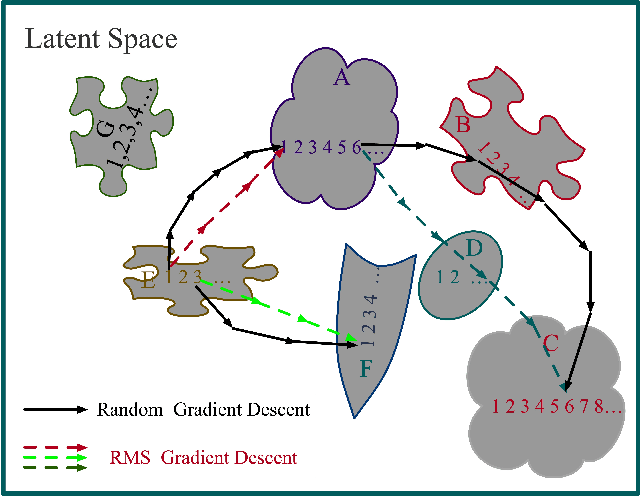
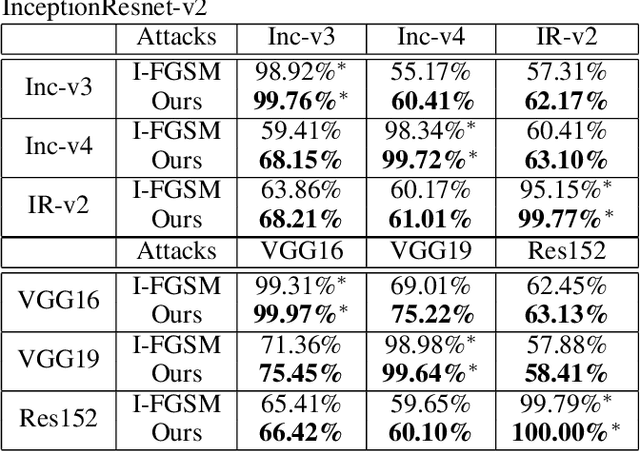
Deep Neural Models are vulnerable to adversarial perturbations in classification. Many attack methods generate adversarial examples with large pixel modification and low cosine similarity with original images. In this paper, we propose an adversarial method generating perturbations based on root mean square gradient which formulates adversarial perturbation size in root mean square level and update gradient in direction, due to updating gradients with adaptive and root mean square stride, our method map origin, and corresponding adversarial image directly which shows good transferability in adversarial examples generation. We evaluate several traditional perturbations creating ways in image classification with our methods. Experimental results show that our approach works well and outperform recent techniques in the change of misclassifying image classification with slight pixel modification, and excellent efficiency in fooling deep network models.
Language Features Matter: Effective Language Representations for Vision-Language Tasks
Aug 17, 2019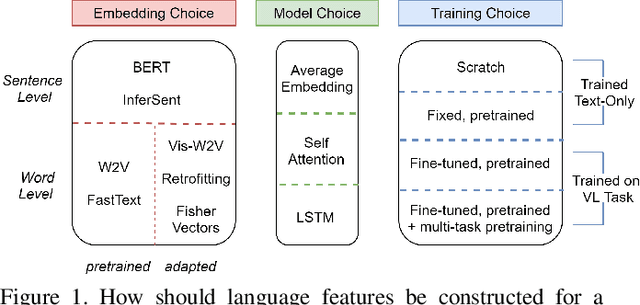
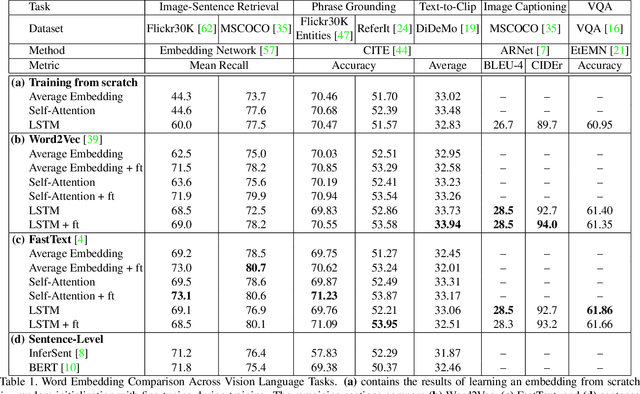
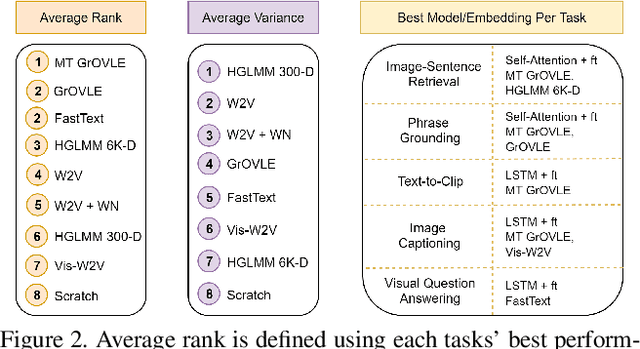
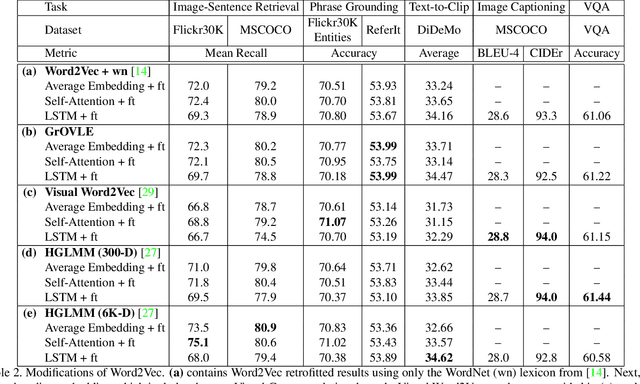
Shouldn't language and vision features be treated equally in vision-language (VL) tasks? Many VL approaches treat the language component as an afterthought, using simple language models that are either built upon fixed word embeddings trained on text-only data or are learned from scratch. We believe that language features deserve more attention, and conduct experiments which compare different word embeddings, language models, and embedding augmentation steps on five common VL tasks: image-sentence retrieval, image captioning, visual question answering, phrase grounding, and text-to-clip retrieval. Our experiments provide some striking results; an average embedding language model outperforms an LSTM on retrieval-style tasks; state-of-the-art representations such as BERT perform relatively poorly on vision-language tasks. From this comprehensive set of experiments we propose a set of best practices for incorporating the language component of VL tasks. To further elevate language features, we also show that knowledge in vision-language problems can be transferred across tasks to gain performance with multi-task training. This multi-task training is applied to a new Graph Oriented Vision-Language Embedding (GrOVLE), which we adapt from Word2Vec using WordNet and an original visual-language graph built from Visual Genome, providing a ready-to-use vision-language embedding: http://ai.bu.edu/grovle.
Improving land cover segmentation across satellites using domain adaptation
Nov 25, 2019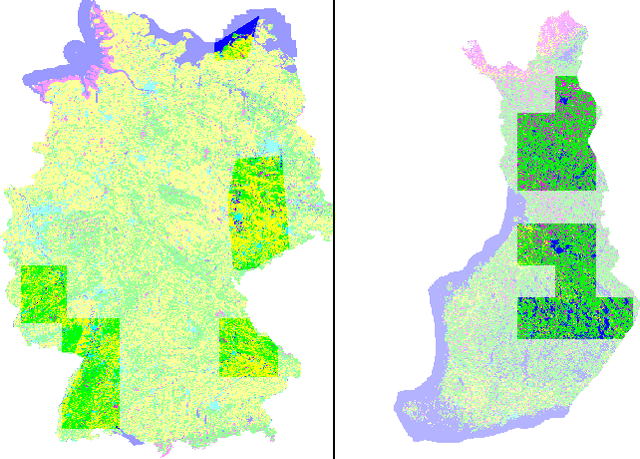

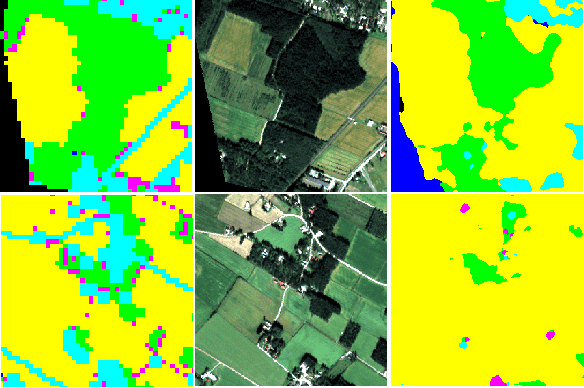
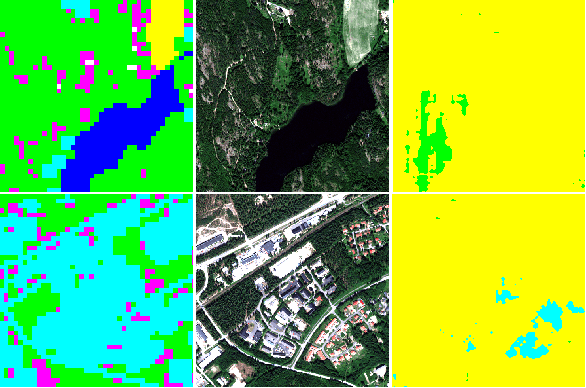
Image segmentation for Land Use and Land Cover (LULC) mapping is a valuable asset that saves a lot of time and effort as opposed to manual annotation. However the lack of datasets to train a model good enough to cover a variety of locations on the planet does not exist. Domain adaptation which proved to be quite useful in segmenting street view images can be used to solve the problem of scarcely labeled land cover datasets. In this paper we build a few labeled datasets based on multispectral imagery from Sentinel-2, Worldview-2 and Pleiades-1 satellites and test domain adaptation between those datasets. Experiments show that domain adaptation manages to make it possible to semantically segment images from different areas on the planet with a limited amount of labeled data.