 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probabilistic Neural Network with Complex Exponential Activation Functions in Image Recognition using Deep Learning Framework
Aug 09, 2017
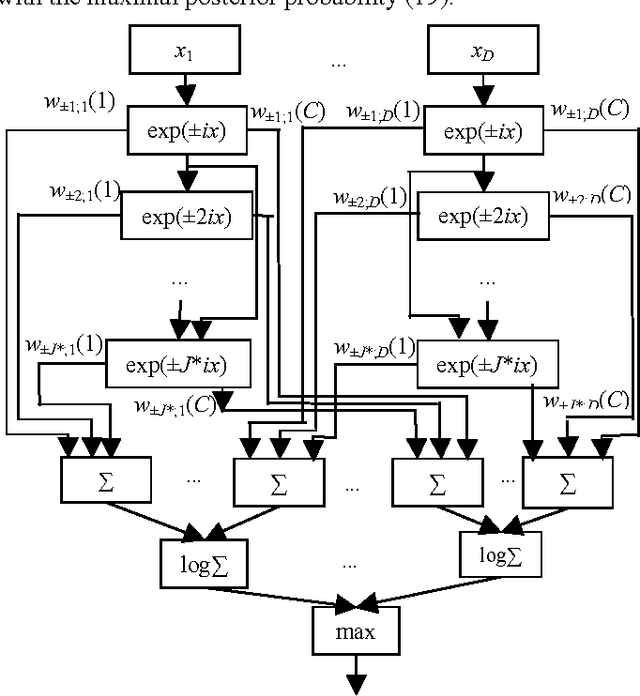
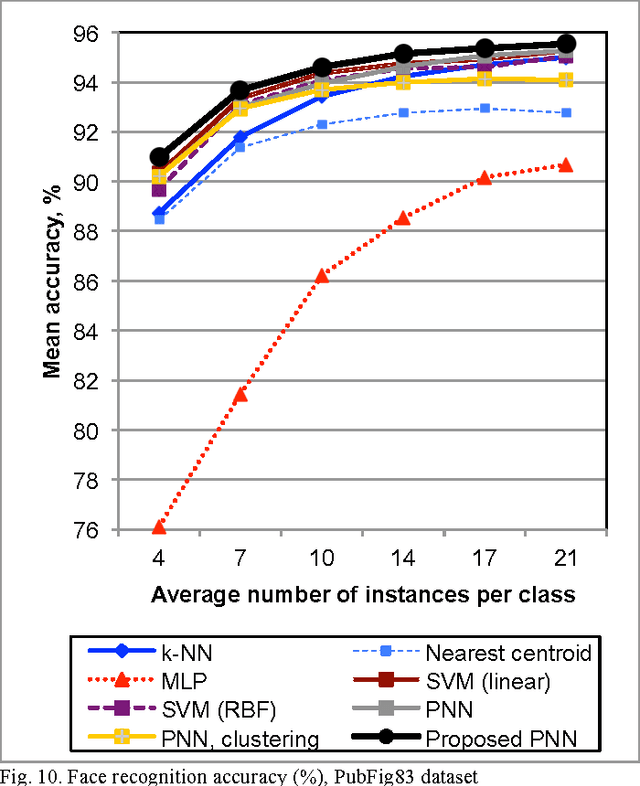
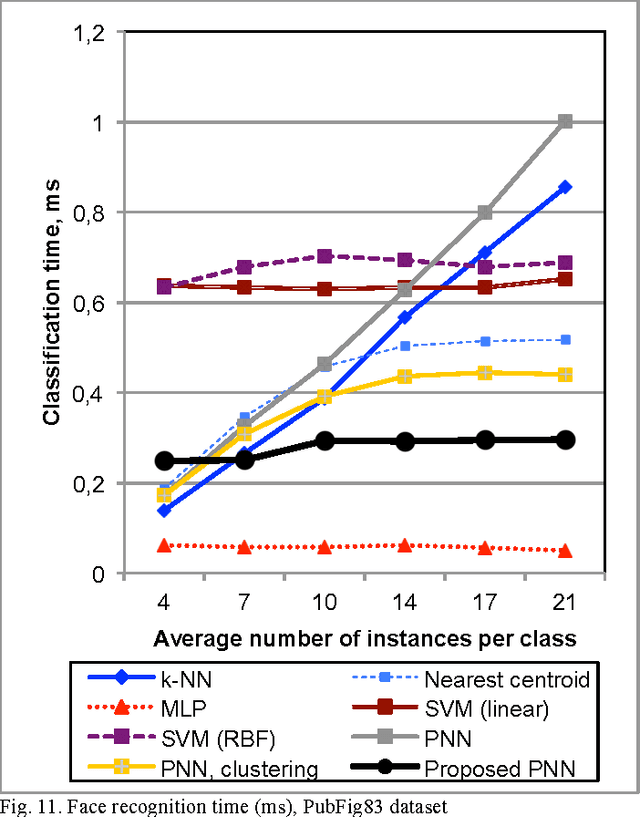
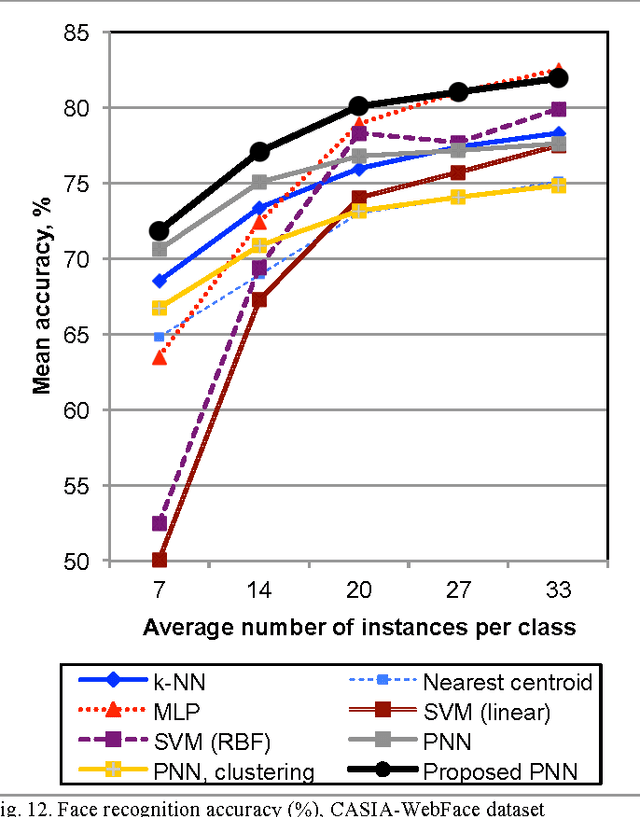
If the training dataset is not very large, image recognition is usually implemented with the transfer learning methods. In these methods the features are extracted using a deep convolutional neural network, which was preliminarily trained with an external very-large dataset. In this paper we consider the nonparametric classification of extracted feature vectors with the probabilistic neural network (PNN). The number of neurons at the pattern layer of the PNN is equal to the database size, which causes the low recognition performance and high memory space complexity of this network. We propose to overcome these drawbacks by replacing the exponential activation function in the Gaussian Parzen kernel to the complex exponential functions in the Fej\'er kernel. We demonstrate that in this case it is possible to implement the network with the number of neurons in the pattern layer proportional to the cubic root of the database size. Thus, the proposed modification of the PNN makes it possible to significantly decrease runtime and memory complexities without loosing its main advantages, namely, extremely fast training procedure and the convergence to the optimal Bayesian decision. An experimental study in visual object category classification and unconstrained face recognition with contemporary deep neural networks have shown, that our approach obtains very efficient and rather accurate decisions for the small training sample in comparison with the well-known classifiers.
Data Consistent Artifact Reduction for Limited Angle Tomography with Deep Learning Prior
Aug 19, 2019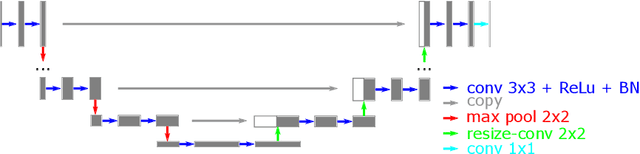
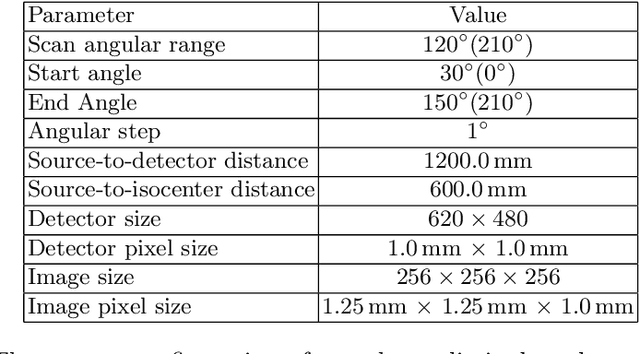
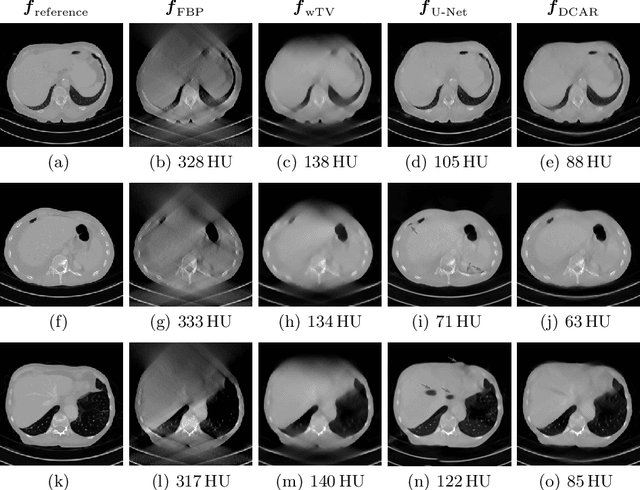
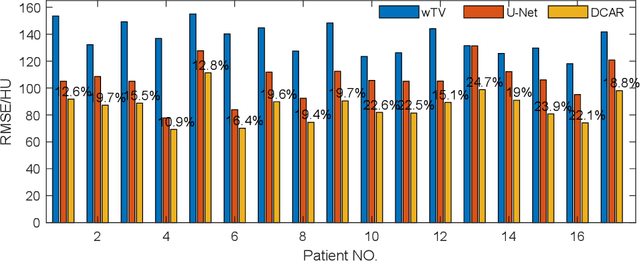
Robustness of deep learning methods for limited angle tomography is challenged by two major factors: a) due to insufficient training data the network may not generalize well to unseen data; b) deep learning methods are sensitive to noise. Thus, generating reconstructed images directly from a neural network appears inadequate. We propose to constrain the reconstructed images to be consistent with the measured projection data, while the unmeasured information is complemented by learning based methods. For this purpose, a data consistent artifact reduction (DCAR) method is introduced: First, a prior image is generated from an initial limited angle reconstruction via deep learning as a substitute for missing information. Afterwards, a conventional iterative reconstruction algorithm is applied, integrating the data consistency in the measured angular range and the prior information in the missing angular range. This ensures data integrity in the measured area, while inaccuracies incorporated by the deep learning prior lie only in areas where no information is acquired. The proposed DCAR method achieves significant image quality improvement: for 120-degree cone-beam limited angle tomography more than 10% RMSE reduction in noise-free case and more than 24% RMSE reduction in noisy case compared with a state-of-the-art U-Net based method.
Near-Lossless Post-Training Quantization of Deep Neural Networks via a Piecewise Linear Approximation
Jan 31, 2020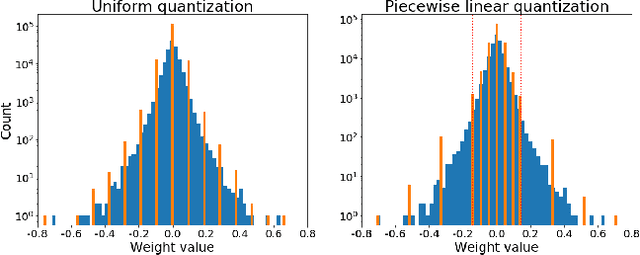
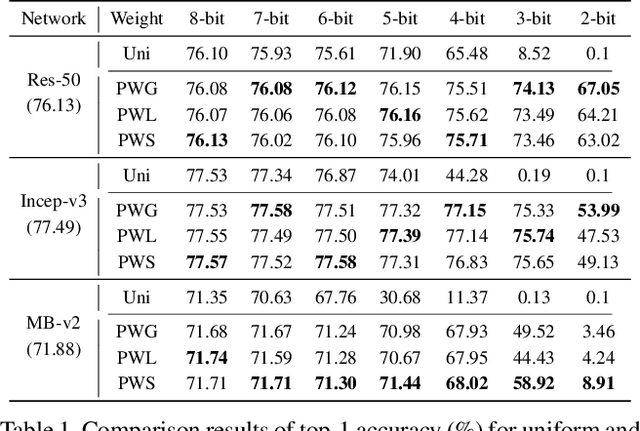
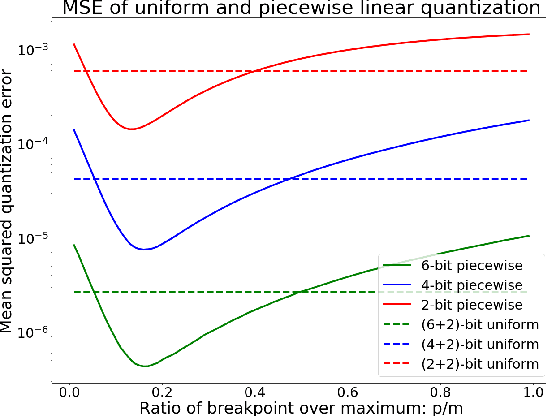
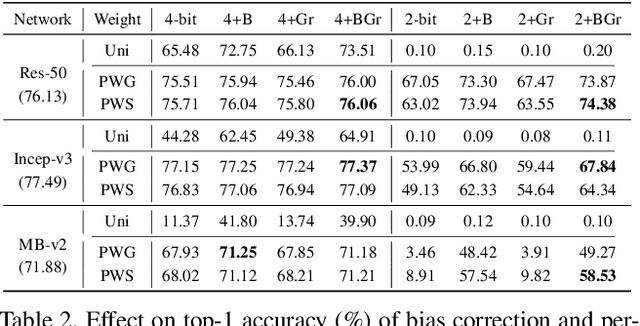
Quantization plays an important role for energy-efficient deployment of deep neural networks (DNNs) on resource-limited devices. Post-training quantization is crucial since it does not require retraining or accessibility to the full training dataset. The conventional post-training uniform quantization scheme achieves satisfactory results by converting DNNs from full-precision to 8-bit integers, however, it suffers from significant performance degradation when quantizing to lower precision such as 4 bits. In this paper, we propose a piecewise linear quantization method to enable accurate post-training quantization. Inspired from the fact that the weight tensors have bell-shaped distributions with long tails, our approach breaks the entire quantization range into two non-overlapping regions for each tensor, with each region being assigned an equal number of quantization levels. The optimal break-point that divides the entire range is found by minimizing the quantization error. Extensive results show that the proposed method achieves state-of-the-art performance on image classification, semantic segmentation and object detection. It is possible to quantize weights to 4 bits without retraining while nearly maintaining the performance of the original full-precision model.
Translating multispectral imagery to nighttime imagery via conditional generative adversarial networks
Dec 28, 2019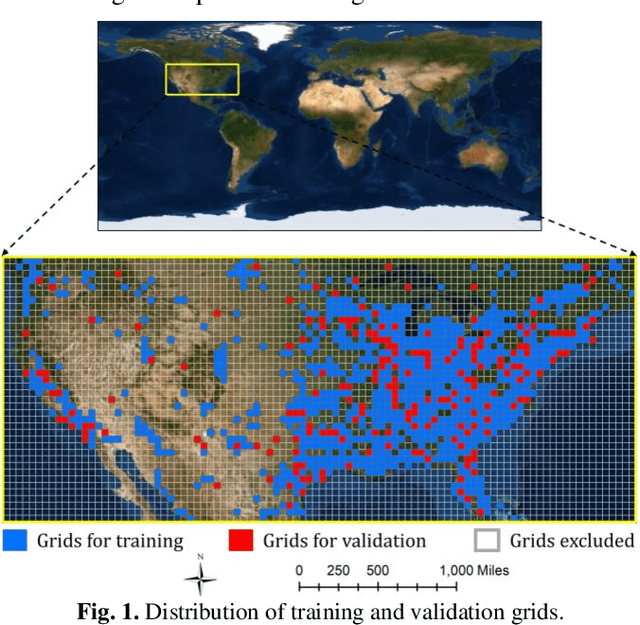
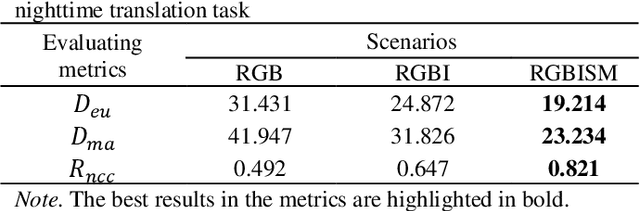
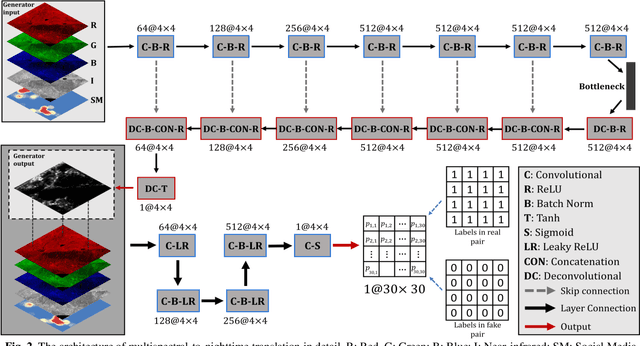

Nighttime satellite imagery has been applied in a wide range of fields. However, our limited understanding of how observed light intensity is formed and whether it can be simulated greatly hinders its further application. This study explores the potential of conditional Generative Adversarial Networks (cGAN) in translating multispectral imagery to nighttime imagery. A popular cGAN framework, pix2pix, was adopted and modified to facilitate this translation using gridded training image pairs derived from Landsat 8 and Visible Infrared Imaging Radiometer Suite (VIIRS). The results of this study prove the possibility of multispectral-to-nighttime translation and further indicate that, with the additional social media data, the generated nighttime imagery can be very similar to the ground-truth imagery. This study fills the gap in understanding the composition of satellite observed nighttime light and provides new paradigms to solve the emerging problems in nighttime remote sensing fields, including nighttime series construction, light desaturation, and multi-sensor calibration.
DHOG: Deep Hierarchical Object Grouping
Mar 13, 2020Recently, a number of competitive methods have tackled unsupervised representation learning by maximising the mutual information between the representations produced from augmentations. The resulting representations are then invariant to stochastic augmentation strategies, and can be used for downstream tasks such as clustering or classification. Yet data augmentations preserve many properties of an image and so there is potential for a suboptimal choice of representation that relies on matching easy-to-find features in the data. We demonstrate that greedy or local methods of maximising mutual information (such as stochastic gradient optimisation) discover local optima of the mutual information criterion; the resulting representations are also less-ideally suited to complex downstream tasks. Earlier work has not specifically identified or addressed this issue. We introduce deep hierarchical object grouping (DHOG) that computes a number of distinct discrete representations of images in a hierarchical order, eventually generating representations that better optimise the mutual information objective. We also find that these representations align better with the downstream task of grouping into underlying object classes. We tested DHOG on unsupervised clustering, which is a natural downstream test as the target representation is a discrete labelling of the data. We achieved new state-of-the-art results on the three main benchmarks without any prefiltering or Sobel-edge detection that proved necessary for many previous methods to work. We obtain accuracy improvements of: 4.3% on CIFAR-10, 1.5% on CIFAR-100-20, and 7.2% on SVHN.
Learning Deep Analysis Dictionaries -- Part I: Unstructured Dictionaries
Jan 31, 2020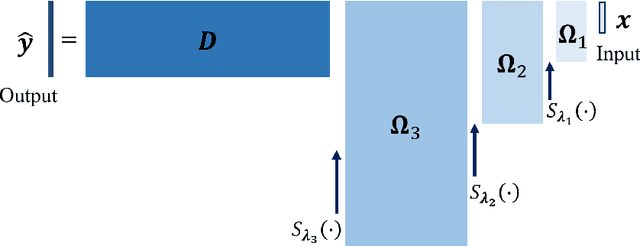
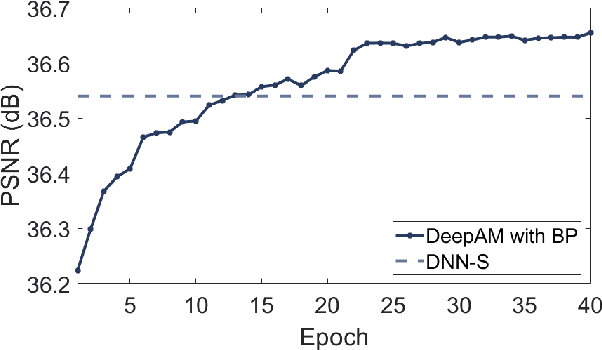

Inspired by the recent success of Deep Neural Networks and the recent efforts to develop multi-layer dictionary models, we propose a Deep Analysis dictionary Model (DeepAM) which is optimized to address a specific regression task known as single image super-resolution. Contrary to other multi-layer dictionary models, our architecture contains L layers of analysis dictionary and soft-thresholding operators to gradually extract high-level features and a layer of synthesis dictionary which is designed to optimize the regression task at hand. In our approach, each analysis dictionary is partitioned into two sub-dictionaries: an Information Preserving Analysis Dictionary (IPAD) and a Clustering Analysis Dictionary (CAD). The IPAD together with the corresponding soft-thresholds is designed to pass the key information from the previous layer to the next layer, while the CAD together with the corresponding soft-thresholding operator is designed to produce a sparse feature representation of its input data that facilitates discrimination of key features. Simulation results show that the proposed deep analysis dictionary model achieves comparable performance with a Deep Neural Network which has the same structure and is optimized using back-propagation.
Large-scale Tag-based Font Retrieval with Generative Feature Learning
Sep 04, 2019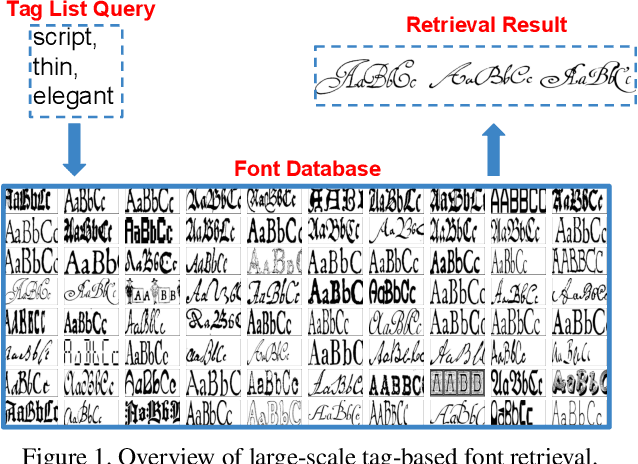
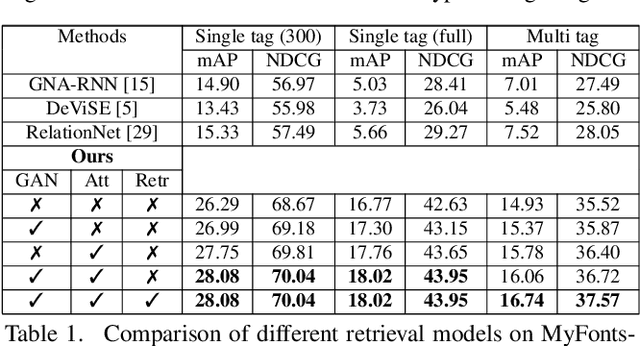
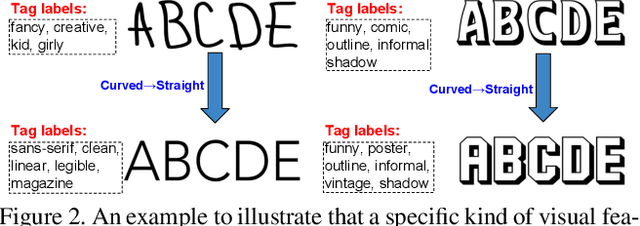

Font selection is one of the most important steps in a design workflow. Traditional methods rely on ordered lists which require significant domain knowledge and are often difficult to use even for trained professionals. In this paper, we address the problem of large-scale tag-based font retrieval which aims to bring semantics to the font selection process and enable people without expert knowledge to use fonts effectively. We collect a large-scale font tagging dataset of high-quality professional fonts. The dataset contains nearly 20,000 fonts, 2,000 tags, and hundreds of thousands of font-tag relations. We propose a novel generative feature learning algorithm that leverages the unique characteristics of fonts. The key idea is that font images are synthetic and can therefore be controlled by the learning algorithm. We design an integrated rendering and learning process so that the visual feature from one image can be used to reconstruct another image with different text. The resulting feature captures important font design details while is robust to nuisance factors such as text. We propose a novel attention mechanism to re-weight the visual feature for joint visual-text modeling. We combine the feature and the attention mechanism in a novel recognition-retrieval model. Experimental results show that our method significantly outperforms the state-of-the-art for the important problem of large-scale tag-based font retrieval.
HumanMeshNet: Polygonal Mesh Recovery of Humans
Aug 19, 2019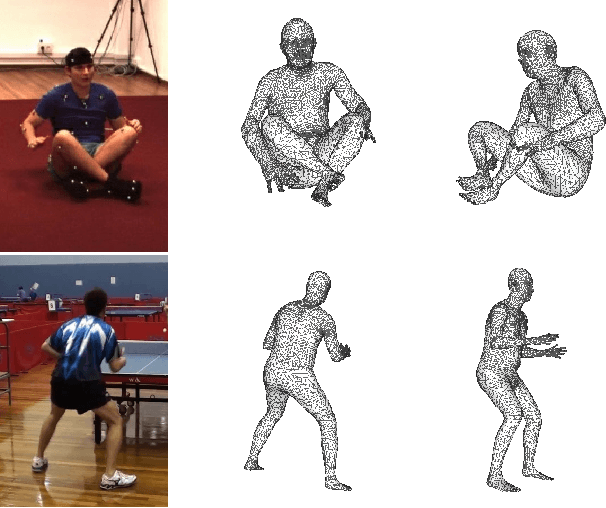
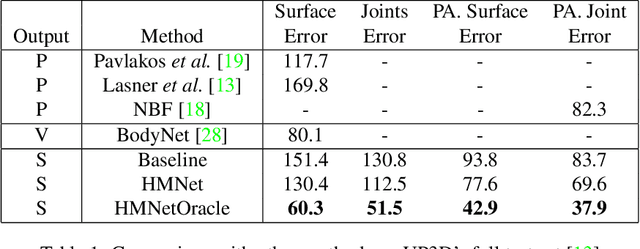
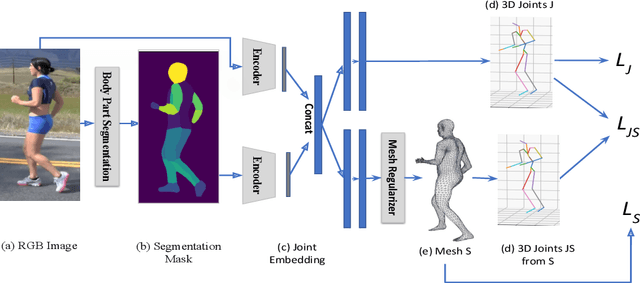
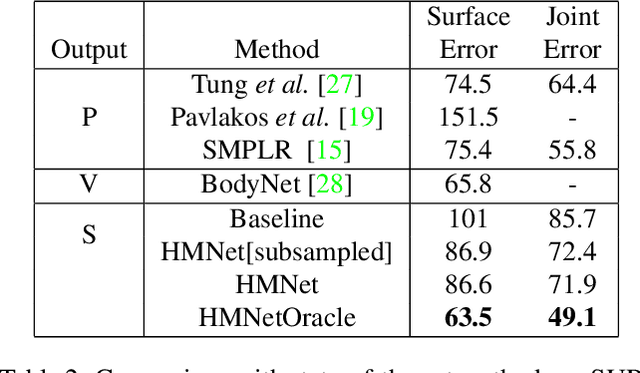
3D Human Body Reconstruction from a monocular image is an important problem in computer vision with applications in virtual and augmented reality platforms, animation industry, en-commerce domain, etc. While several of the existing works formulate it as a volumetric or parametric learning with complex and indirect reliance on re-projections of the mesh, we would like to focus on implicitly learning the mesh representation. To that end, we propose a novel model, HumanMeshNet, that regresses a template mesh's vertices, as well as receives a regularization by the 3D skeletal locations in a multi-branch, multi-task setup. The image to mesh vertex regression is further regularized by the neighborhood constraint imposed by mesh topology ensuring smooth surface reconstruction. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations and can therefore learn high-resolution meshes going ahead. We show comparable performance with SoA (in terms of surface and joint error) with far lesser computational complexity, modeling cost and therefore real-time reconstructions on three publicly available datasets. We also show the generalizability of the proposed paradigm for a similar task of predicting hand mesh models. Given these initial results, we would like to exploit the mesh topology in an explicit manner going ahead.
Degraded Historical Documents Images Binarization Using a Combination of Enhanced Techniques
Jan 27, 2019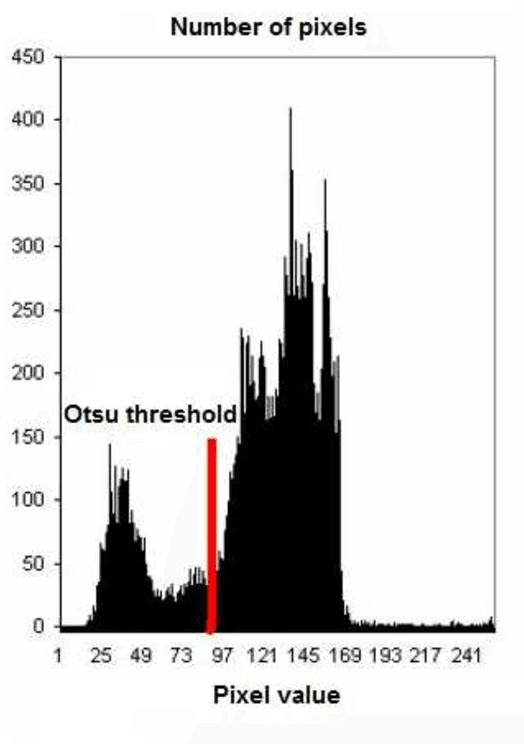
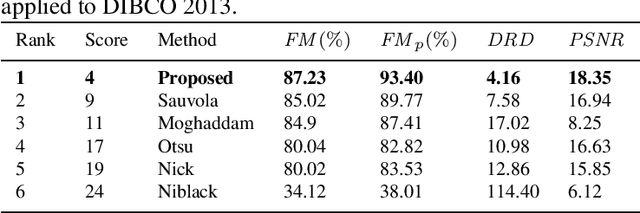
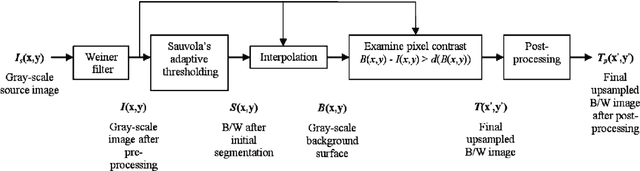
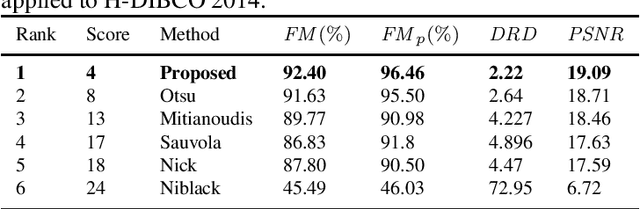
Document image binarization is the initial step and a crucial in many document analysis and recognition scheme. In fact, it is still a relevant research subject and a fundamental challenge due to its importance and influence. This paper provides an original multi-phases system that hybridizes various efficient image thresholding methods in order to get the best binarization output. First, to improve contrast in particularly defective images, the application of CLAHE algorithm is suggested and justified. We then use a cooperative technique to segment image into two separated classes. At the end, a special transformation is applied for the purpose of removing scattered noise and of correcting characters forms. Experimentations demonstrate the precision and the robustness of our framework applied on historical degraded documents images within three benchmarks compared to other noted methods.
Compressed MRI Reconstruction Exploiting a Rotation-Invariant Total Variation Discretization
Dec 07, 2019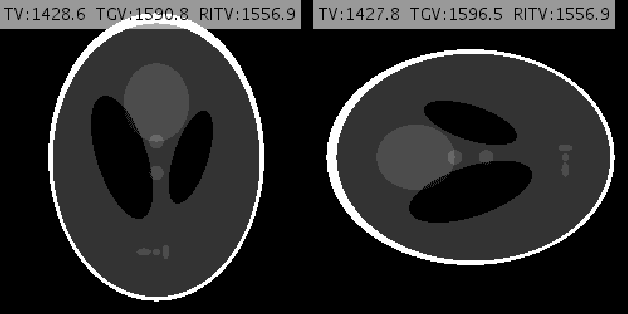
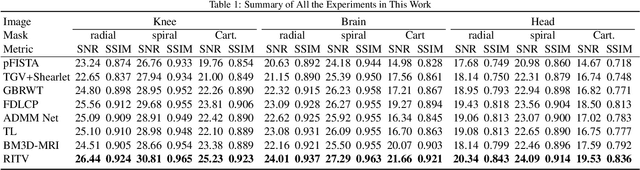
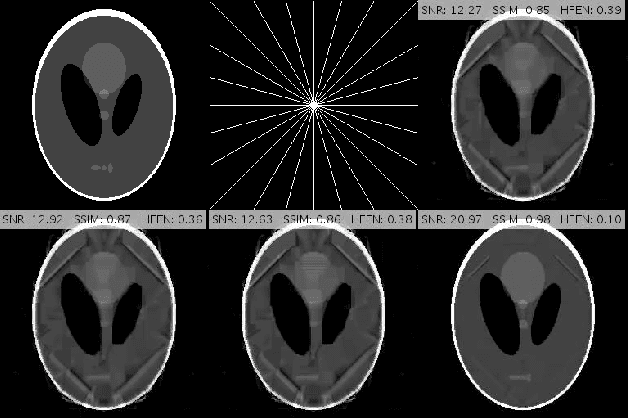
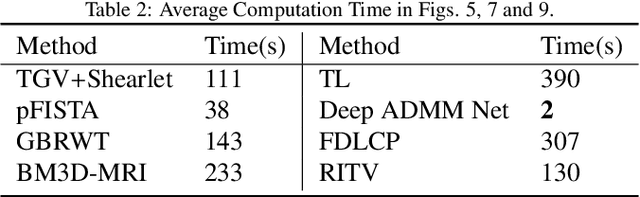
Inspired by the first-order method of Malitsky and Pock, we propose a novel variational framework for compressed MR image reconstruction which introduces the application of a rotation-invariant discretization of total variation functional into MR imaging while exploiting BM3D frame as a sparsifying transform. The proposed model is presented as a constrained optimization problem, however, we do not use conventional ADMM-type algorithms designed for constrained problems to obtain a solution, but rather we tailor the linesearch-equipped method of Malitsky and Pock to our model, which was originally proposed for unconstrained problems. As attested by numerical experiments, this framework significantly outperforms various state-of-the-art algorithms from variational methods to adaptive and learning approaches and in particular, it eliminates the stagnating behavior of a previous work on BM3D-MRI which compromised the solution beyond a certain iteration.