 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Open-set Recognition and Few-Shot Learning Dataset for Audio Event Classification in Domestic Environments
Mar 14, 2020
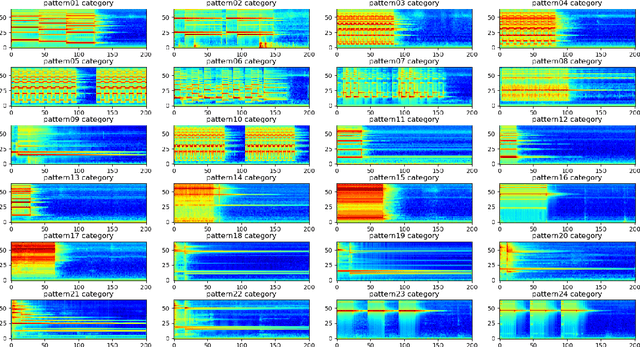
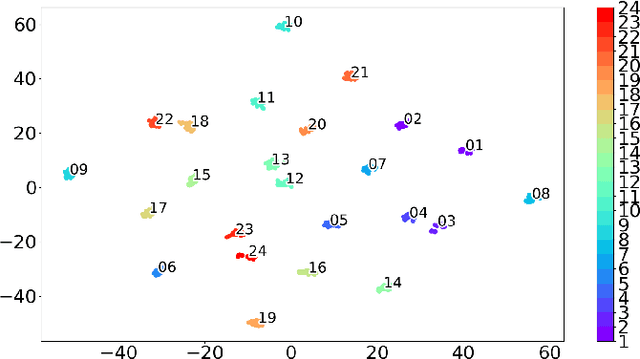

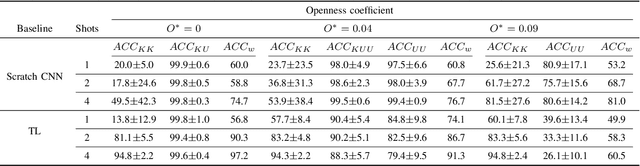
The problem of training a deep neural network with a small set of positive samples is known as few-shot learning (FSL). It is widely known that traditional deep learning (DL) algorithms usually show very good performance when trained with large datasets. However, in many applications, it is not possible to obtain such a high number of samples. In the image domain, typical FSL applications are those related to face recognition. In the audio domain, music fraud or speaker recognition can be clearly benefited from FSL methods. This paper deals with the application of FSL to the detection of specific and intentional acoustic events given by different types of sound alarms, such as door bells or fire alarms, using a limited number of samples. These sounds typically occur in domestic environments where many events corresponding to a wide variety of sound classes take place. Therefore, the detection of such alarms in a practical scenario can be considered an open-set recognition (OSR) problem. To address the lack of a dedicated public dataset for audio FSL, researchers usually make modifications on other available datasets. This paper is aimed at providing the audio recognition community with a carefully annotated dataset for FSL and OSR comprised of 1360 clips from 34 classes divided into pattern sounds and unwanted sounds. To facilitate and promote research in this area, results with two baseline systems (one trained from scratch and another based on transfer learning), are presented.
Data Driven Robust Image Guided Depth Map Restoration
Dec 26, 2015
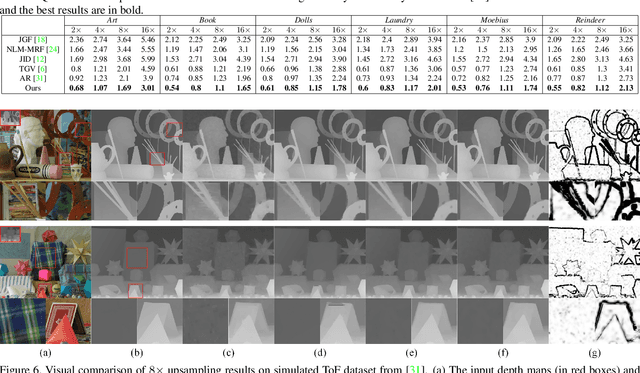
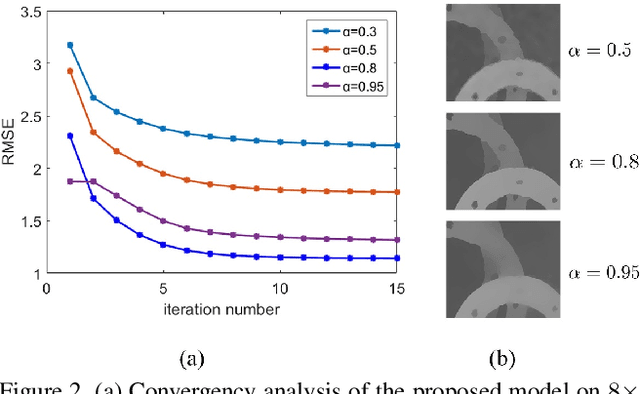
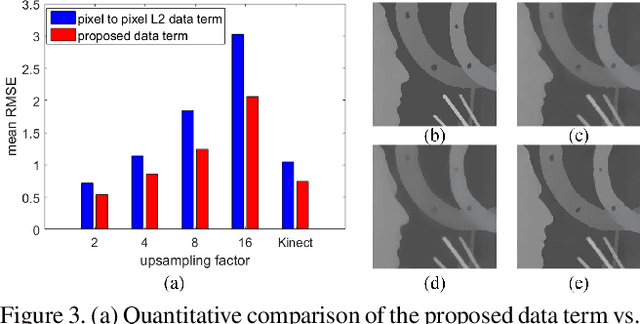
Depth maps captured by modern depth cameras such as Kinect and Time-of-Flight (ToF) are usually contaminated by missing data, noises and suffer from being of low resolution. In this paper, we present a robust method for high-quality restoration of a degraded depth map with the guidance of the corresponding color image. We solve the problem in an energy optimization framework that consists of a novel robust data term and smoothness term. To accommodate not only the noise but also the inconsistency between depth discontinuities and the color edges, we model both the data term and smoothness term with a robust exponential error norm function. We propose to use Iteratively Re-weighted Least Squares (IRLS) methods for efficiently solving the resulting highly non-convex optimization problem. More importantly, we further develop a data-driven adaptive parameter selection scheme to properly determine the parameter in the model. We show that the proposed approach can preserve fine details and sharp depth discontinuities even for a large upsampling factor ($8\times$ for example). Experimental results on both simulated and real datasets demonstrate that the proposed method outperforms recent state-of-the-art methods in coping with the heavy noise, preserving sharp depth discontinuities and suppressing the texture copy artifacts.
Model-based Deep MR Imaging: the roadmap of generalizing compressed sensing model using deep learning
Jun 23, 2019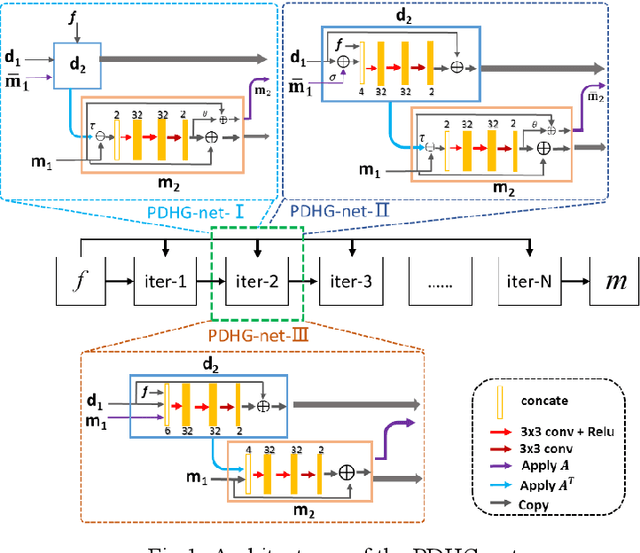
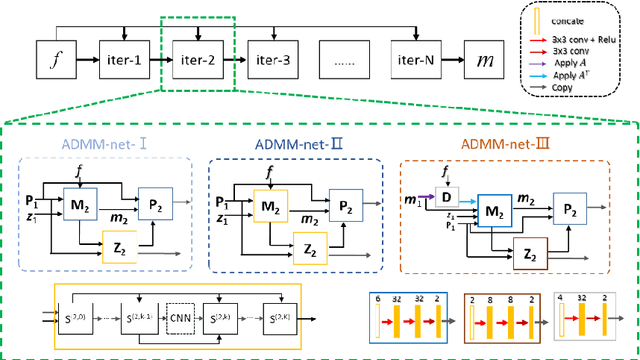
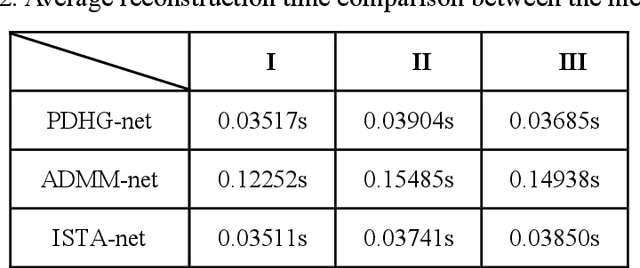
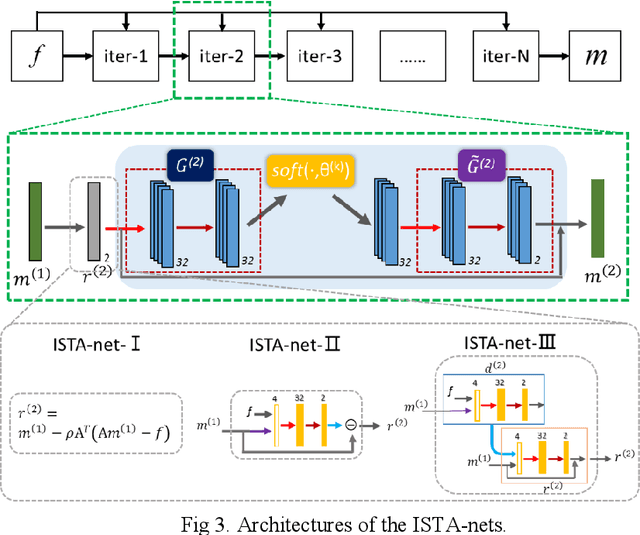
Accelerating magnetic resonance imaging (MRI) has been an ongoing research topic since its invention in the 1970s. Among a variety of acceleration techniques, compressed sensing (CS) has become an important strategy during the past decades. Although CS-based methods can achieve high performance with many theoretical guarantees, it is challenging to determine the numerical uncertainties in the reconstruction model such as the optimal sparse transformations, sparse regularizer in the transform do-main, regularization parameters and the parameters of the optimization algorithm. Recently, deep learning has been introduced in MR reconstruction to address these issues and shown potential to significantly improve image quality. In this paper, we propose a general framework combining the CS-MR model with deep learning to maximize the potential of deep learning and model-based reconstruction for fast MR imaging and attempt to provide a guideline on how to improve the image quality with deep learning based on the traditional reconstruction algorithms.
GLA in MediaEval 2018 Emotional Impact of Movies Task
Nov 27, 2019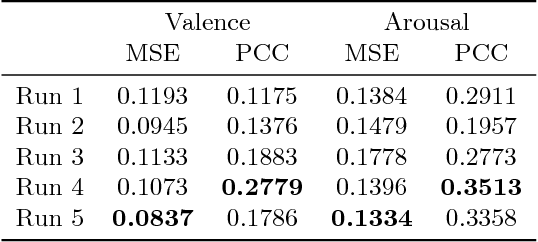
The visual and audio information from movies can evoke a variety of emotions in viewers. Towards a better understanding of viewer impact, we present our methods for the MediaEval 2018 Emotional Impact of Movies Task to predict the expected valence and arousal continuously in movies. This task, using the LIRIS-ACCEDE dataset, enables researchers to compare different approaches for predicting viewer impact from movies. Our approach leverages image, audio, and face based features computed using pre-trained neural networks. These features were computed over time and modeled using a gated recurrent unit (GRU) based network followed by a mixture of experts model to compute multiclass predictions. We smoothed these predictions using a Butterworth filter for our final result. Our method enabled us to achieve top performance in three evaluation metrics in the MediaEval 2018 task.
Metric Pose Estimation for Human-Machine Interaction Using Monocular Vision
Oct 08, 2019
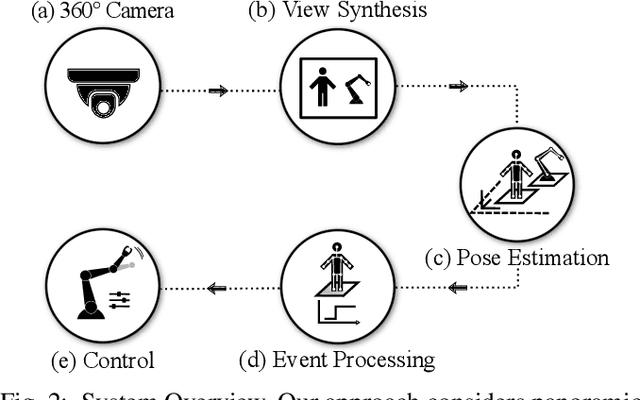
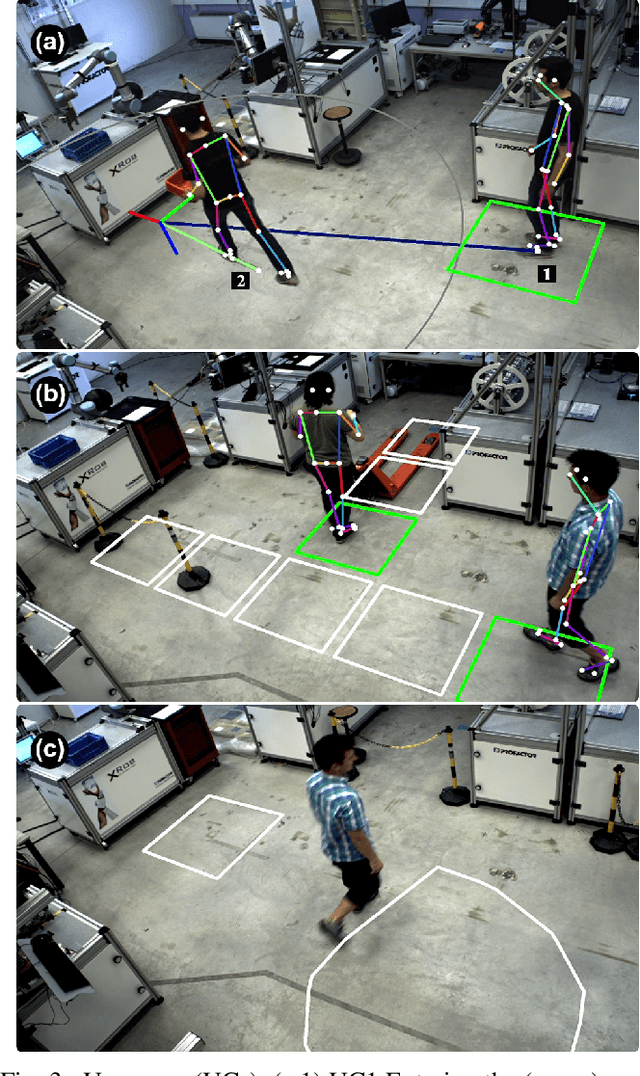
The rapid growth of collaborative robotics in production requires new automation technologies that take human and machine equally into account. In this work, we describe a monocular camera based system to detect human-machine interactions from a bird's-eye perspective. Our system predicts poses of humans and robots from a single wide-angle color image. Even though our approach works on 2D color input, we lift the majority of detections to a metric 3D space. Our system merges pose information with predefined virtual sensors to coordinate human-machine interactions. We demonstrate the advantages of our system in three use cases.
Synergetic Reconstruction from 2D Pose and 3D Motion for Wide-Space Multi-Person Video Motion Capture in the Wild
Jan 16, 2020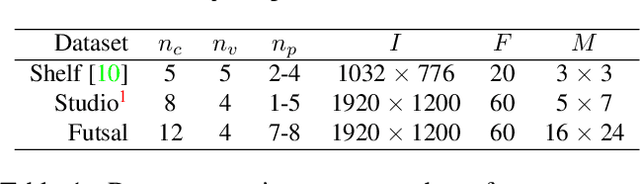
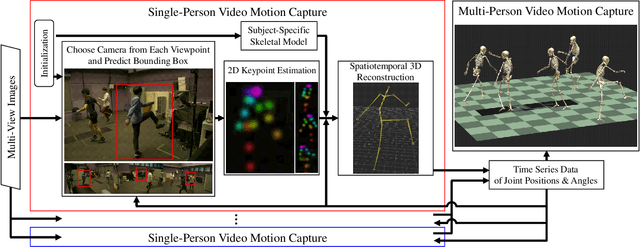
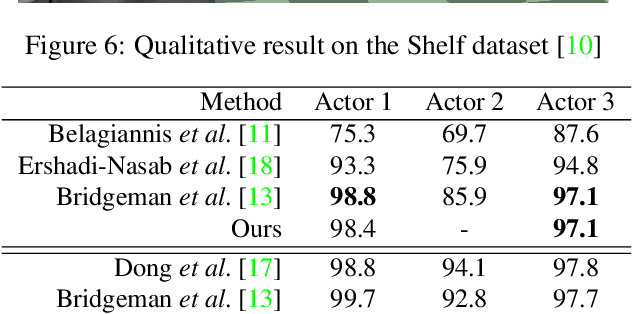
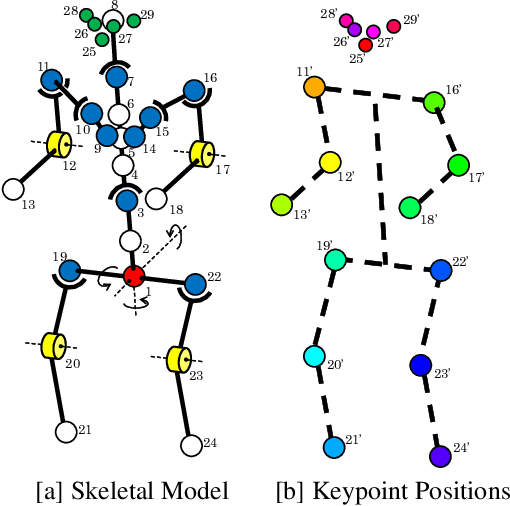
Although many studies have been made on markerless motion capture, it has not been applied to real sports or concerts. In this paper, we propose a markerless motion capture method with spatiotemporal accuracy and smoothness from multiple cameras, even in wide and multi-person environments. The key idea is predicting each person's 3D pose and determining the bounding box of multi-camera images small enough. This prediction and spatiotemporal filtering based on human skeletal structure eases 3D reconstruction of the person and yields accuracy. The accurate 3D reconstruction is then used to predict the bounding box of each camera image in the next frame. This is a feedback from 3D motion to 2D pose, and provides a synergetic effect to the total performance of video motion capture. We demonstrate the method using various datasets and a real sports field. The experimental results show the mean per joint position error was 31.6mm and the percentage of correct parts was 99.3% under five people moving dynamically, with satisfying the range of motion. Video demonstration, datasets, and additional materials are posted on our project page.
Probabilistic Neural Network with Complex Exponential Activation Functions in Image Recognition using Deep Learning Framework
Aug 09, 2017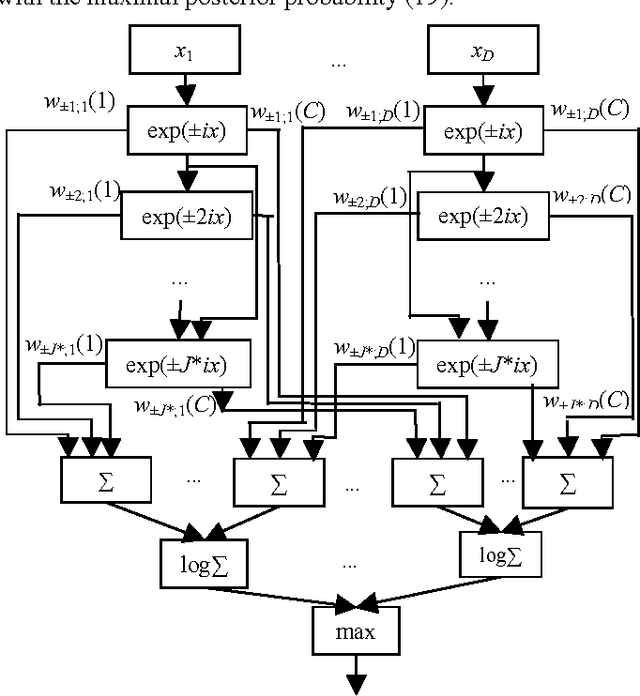
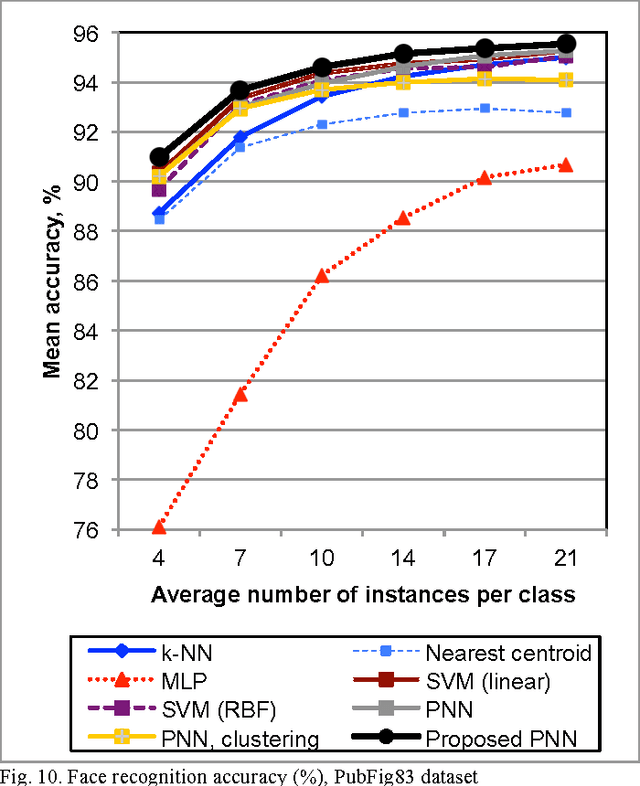
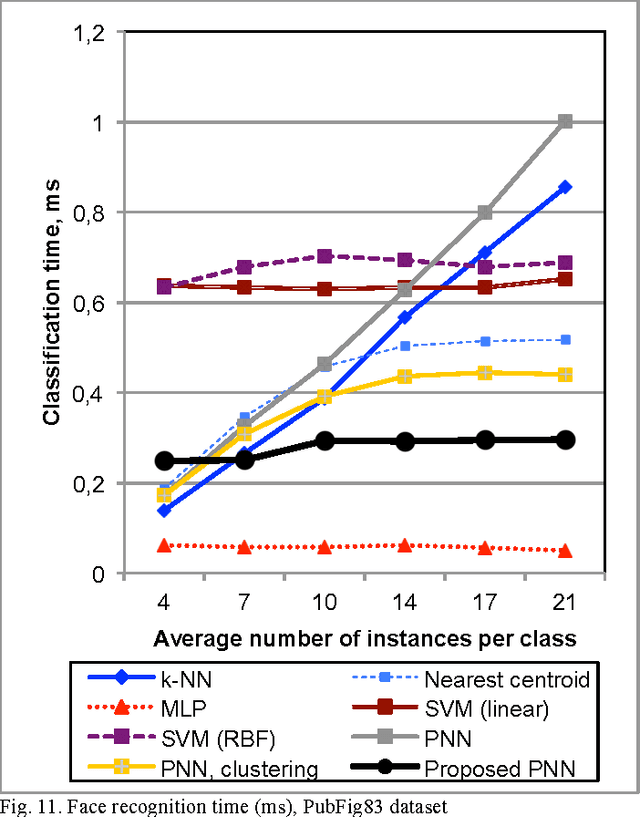
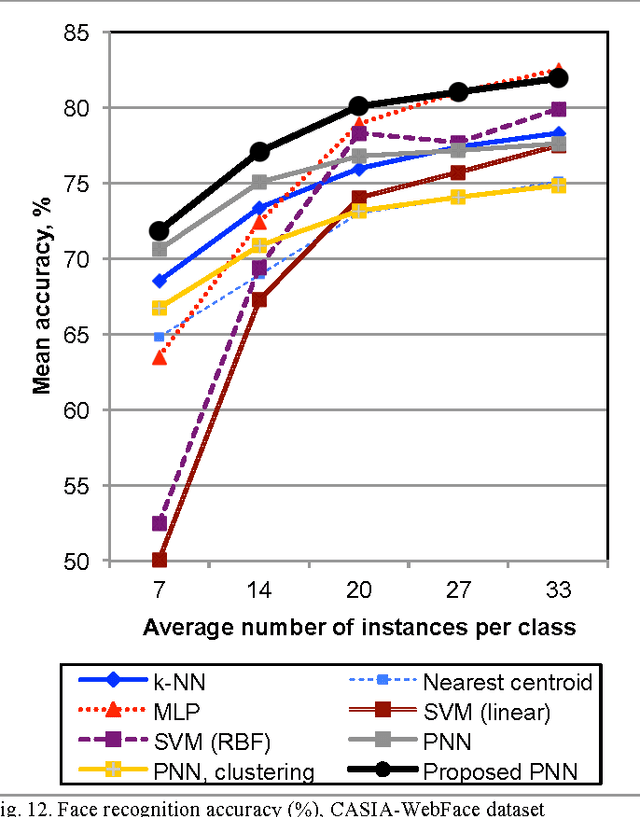
If the training dataset is not very large, image recognition is usually implemented with the transfer learning methods. In these methods the features are extracted using a deep convolutional neural network, which was preliminarily trained with an external very-large dataset. In this paper we consider the nonparametric classification of extracted feature vectors with the probabilistic neural network (PNN). The number of neurons at the pattern layer of the PNN is equal to the database size, which causes the low recognition performance and high memory space complexity of this network. We propose to overcome these drawbacks by replacing the exponential activation function in the Gaussian Parzen kernel to the complex exponential functions in the Fej\'er kernel. We demonstrate that in this case it is possible to implement the network with the number of neurons in the pattern layer proportional to the cubic root of the database size. Thus, the proposed modification of the PNN makes it possible to significantly decrease runtime and memory complexities without loosing its main advantages, namely, extremely fast training procedure and the convergence to the optimal Bayesian decision. An experimental study in visual object category classification and unconstrained face recognition with contemporary deep neural networks have shown, that our approach obtains very efficient and rather accurate decisions for the small training sample in comparison with the well-known classifiers.
COVID-19 identification in chest X-ray images on flat and hierarchical classification scenarios
Apr 15, 2020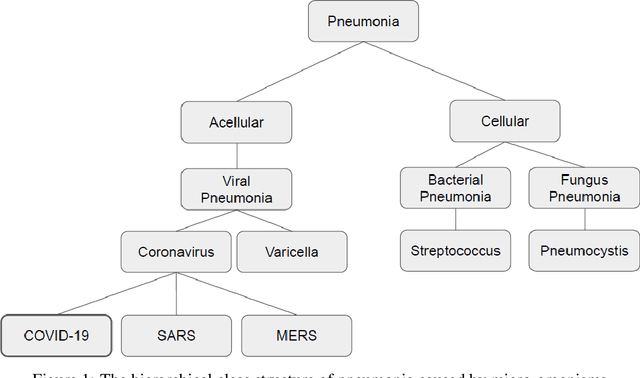

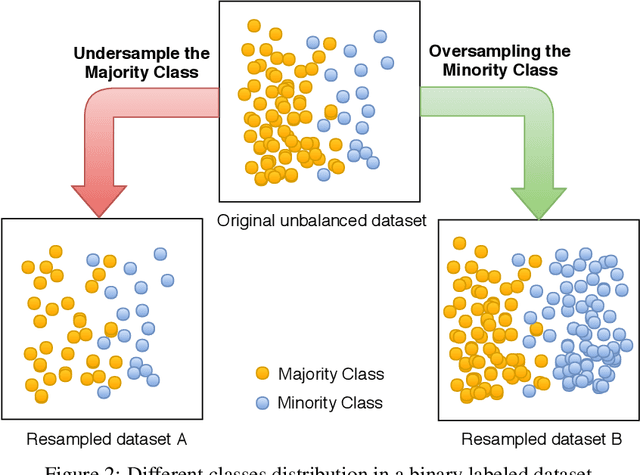
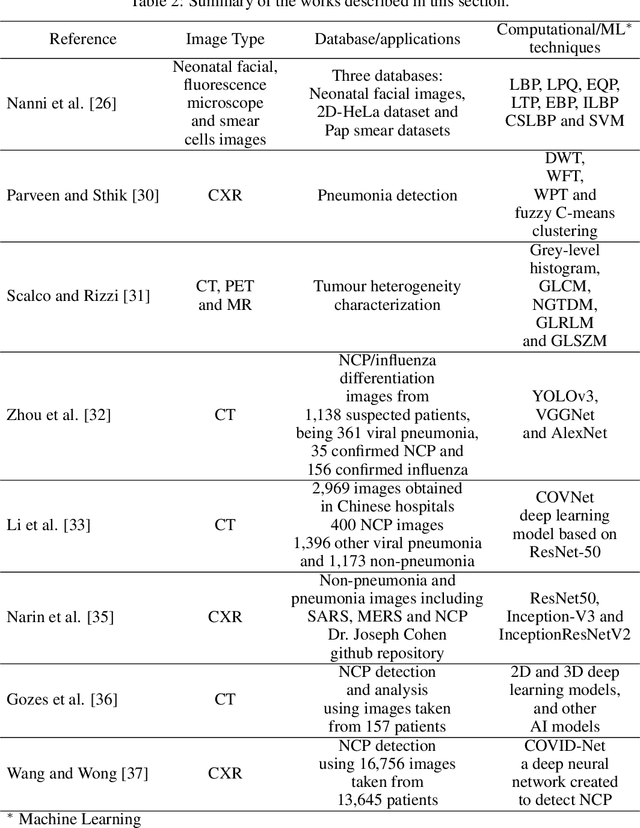
The COVID-19 can cause severe pneumonia and is estimated to have a high impact on the healthcare system. The standard image diagnosis tests for pneumonia are chest X-ray (CXR) and computed tomography (CT) scan. CXR are useful in because it is cheaper, faster and more widespread than CT. This study aims to identify pneumonia caused by COVID-19 from other types and also healthy lungs using only CXR images. In order to achieve the objectives, we have proposed a classification schema considering the multi-class and hierarchical perspectives, since pneumonia can be structured as a hierarchy. Given the natural data imbalance in this domain, we also proposed the use of resampling algorithms in order to re-balance the classes distribution. Our classification schema extract features using some well-known texture descriptors and also using a pre-trained CNN model. We also explored early and late fusion techniques in order to leverage the strength of multiple texture descriptors and base classifiers at once. To evaluate the approach, we composed a database, named RYDLS-20, containing CXR images of pneumonia caused by different pathogens as well as CXR images of healthy lungs. The classes distribution follows a real-world scenario in which some pathogens are more common than others. The proposed approach achieved a macro-avg F1-Score of 0.65 using a multi-class approach and a F1-Score of 0.89 for the COVID-19 identification in the hierarchical classification scenario. As far as we know, we achieve best nominal rate obtained for COVID-19 identification in an unbalanced environment with more than three classes. We must also highlight the novel proposed hierarchical classification approach for this task, which considers the types of pneumonia caused by the different pathogens and lead us to the best COVID-19 recognition rate obtained here.
Variational Integrator Networks for Physically Meaningful Embeddings
Oct 21, 2019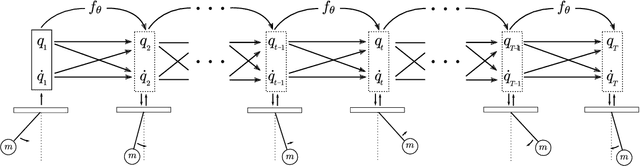
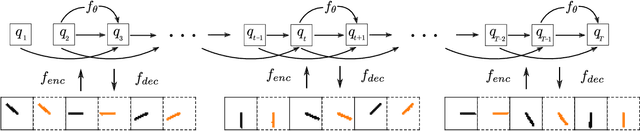
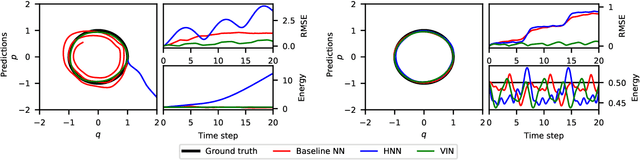
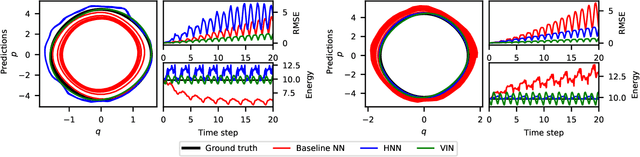
Learning workable representations of dynamical systems is becoming an increasingly important problem in a number of application areas. By leveraging recent work connecting deep neural networks to systems of differential equations, we propose variational integrator networks, a class of neural network architectures designed to ensure faithful representations of the dynamics under study. This class of network architectures facilitates accurate long-term prediction, interpretability, and data-efficient learning, while still remaining highly flexible and capable of modeling complex behavior. We demonstrate that they can accurately learn dynamical systems from both noisy observations in phase space and from image pixels within which the unknown dynamics are embedded.
M3D-RPN: Monocular 3D Region Proposal Network for Object Detection
Jul 13, 2019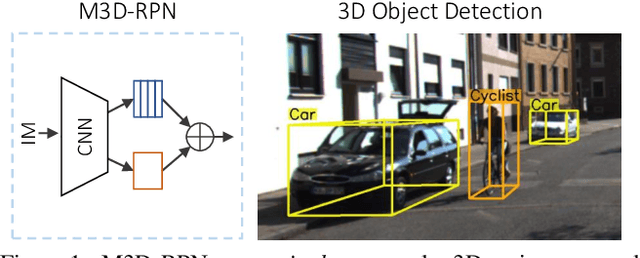

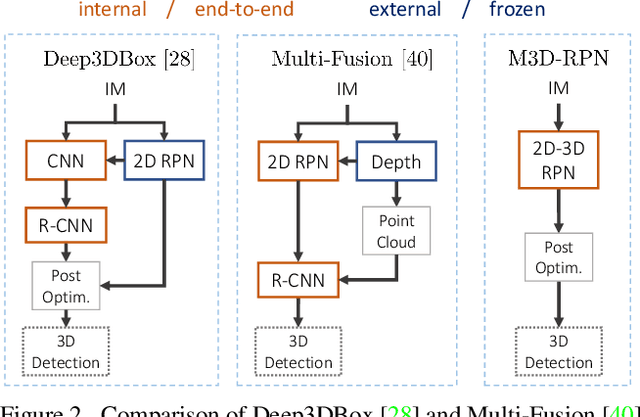

Understanding the world in 3D is a critical component of urban autonomous driving. Generally, the combination of expensive LiDAR sensors and stereo RGB imaging has been paramount for successful 3D object detection algorithms, whereas monocular image-only methods experience drastically reduced performance. We propose to reduce the gap by reformulating the monocular 3D detection problem as a standalone 3D region proposal network. We leverage the geometric relationship of 2D and 3D perspectives, allowing 3D boxes to utilize well-known and powerful convolutional features generated in the image-space. To help address the strenuous 3D parameter estimations, we further design depth-aware convolutional layers which enable location specific feature development and in consequence improved 3D scene understanding. Compared to prior work in monocular 3D detection, our method consists of only the proposed 3D region proposal network rather than relying on external networks, data, or multiple stages. M3D-RPN is able to significantly improve the performance of both monocular 3D Object Detection and Bird's Eye View tasks within the KITTI urban autonomous driving dataset, while efficiently using a shared multi-class model.