 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards automated mobile-phone-based plant pathology management
Dec 19, 2019
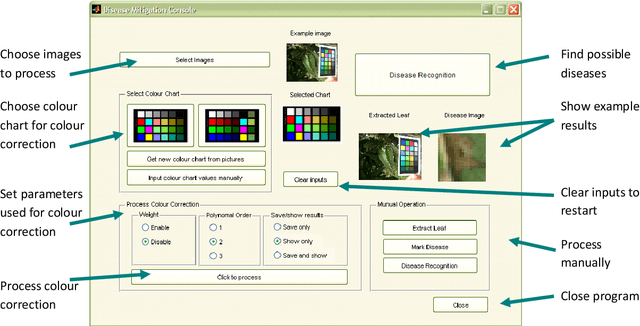


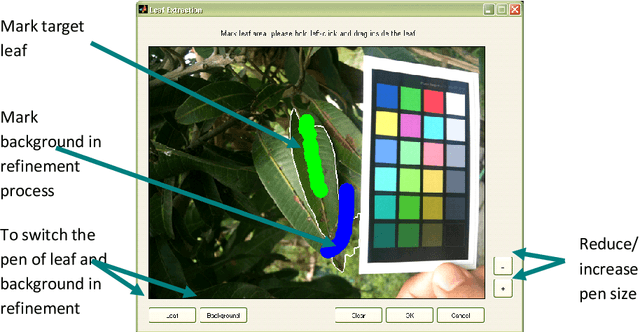
This paper presents a framework which uses computer vision algorithms to standardise images and analyse them for identifying crop diseases automatically. The tools are created to bridge the information gap between farmers, advisory call centres and agricultural experts using the images of diseased/infected crop captured by mobile-phones. These images are generally sensitive to a number of factors including camera type and lighting. We therefore propose a technique for standardising the colour of plant images within the context of the advisory system. Subsequently, to aid the advisory process, the disease recognition process is automated using image processing in conjunction with machine learning techniques. We describe our proposed leaf extraction, affected area segmentation and disease classification techniques. The proposed disease recognition system is tested using six mango diseases and the results show over 80% accuracy. The final output of our system is a list of possible diseases with relevant management advice.
Learning a Layout Transfer Network for Context Aware Object Detection
Dec 09, 2019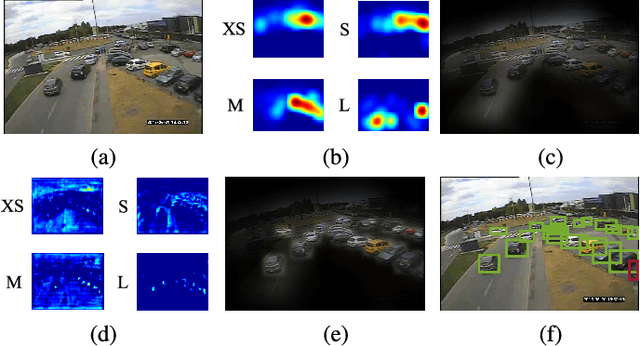

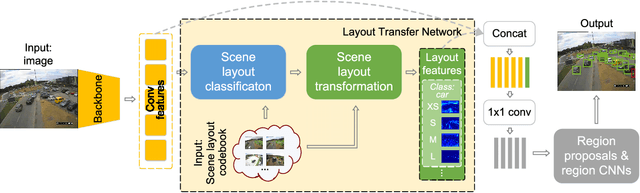

We present a context aware object detection method based on a retrieve-and-transform scene layout model. Given an input image, our approach first retrieves a coarse scene layout from a codebook of typical layout templates. In order to handle large layout variations, we use a variant of the spatial transformer network to transform and refine the retrieved layout, resulting in a set of interpretable and semantically meaningful feature maps of object locations and scales. The above steps are implemented as a Layout Transfer Network which we integrate into Faster RCNN to allow for joint reasoning of object detection and scene layout estimation. Extensive experiments on three public datasets verified that our approach provides consistent performance improvements to the state-of-the-art object detection baselines on a variety of challenging tasks in the traffic surveillance and the autonomous driving domains.
Explicit Facial Expression Transfer via Fine-Grained Semantic Representations
Sep 06, 2019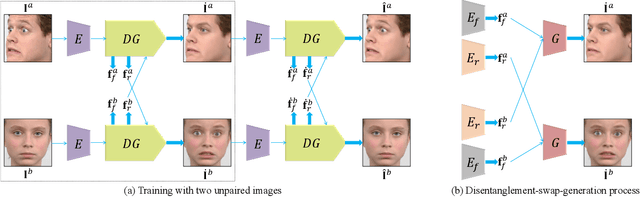

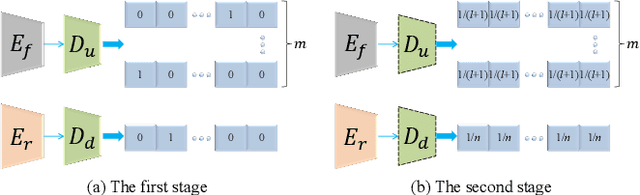
Facial expression transfer between two unpaired images is a challenging problem, as fine-grained expressions are typically tangled with other facial attributes such as identity and pose. Most existing methods treat expression transfer as an application of expression manipulation, and use predicted facial expressions, landmarks or action units (AUs) of a source image to guide the expression edit of a target image. However, the prediction of expressions, landmarks and especially AUs may be inaccurate, which limits the accuracy of transferring fine-grained expressions. Instead of using an intermediate estimated guidance, we propose to explicitly transfer expressions by directly mapping two unpaired images to two synthesized images with swapped expressions. Since each AU semantically describes local expression details, we can synthesize new images with preserved identities and swapped expressions by combining AU-free features with swapped AU-related features. To disentangle the images into AU-related features and AU-free features, we propose a novel adversarial training method which can solve the adversarial learning of multi-class classification problems. Moreover, to obtain reliable expression transfer results of the unpaired input, we introduce a swap consistency loss to make the synthesized images and self-reconstructed images indistinguishable. Extensive experiments on RaFD, MMI and CFD datasets show that our approach can generate photo-realistic expression transfer results between unpaired images with different expression appearances including genders, ages, races and poses.
Improving Dataset Distillation
Oct 06, 2019

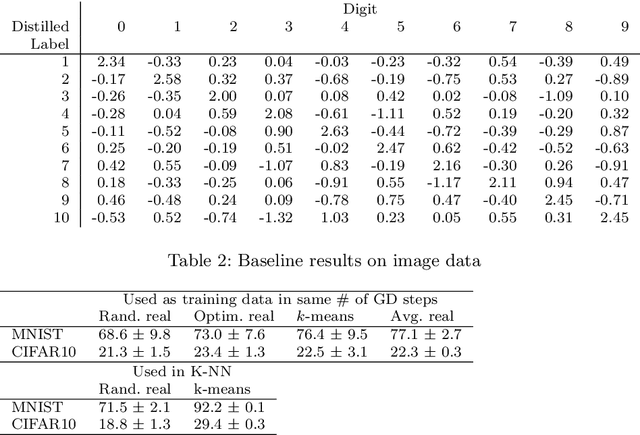
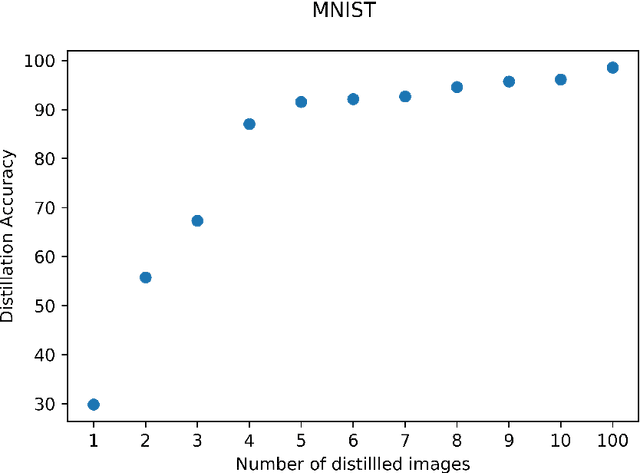
Dataset distillation is a method for reducing dataset sizes: the goal is to learn a small number of synthetic samples containing all the information of a large dataset. This has several benefits: speeding up model training in deep learning, reducing energy consumption, and reducing required storage space. Currently, each synthetic sample is assigned a single `hard' label, which limits the accuracies that models trained on distilled datasets can achieve. Also, currently dataset distillation can only be used with image data. We propose to simultaneously distill both images and their labels, and thus to assign each synthetic sample a `soft' label (a distribution of labels) rather than a single `hard' label. Our improved algorithm increases accuracy by 2-4% over the original dataset distillation algorithm for several image classification tasks. For example, training a LeNet model with just 10 distilled images (one per class) results in over 96% accuracy on the MNIST data. Using `soft' labels also enables distilled datasets to consist of fewer samples than there are classes as each sample can encode information for more than one class. For example, we show that LeNet achieves almost 92% accuracy on MNIST after being trained on just 5 distilled images. We also propose an extension of the dataset distillation algorithm that allows it to distill sequential datasets including texts. We demonstrate that text distillation outperforms other methods across multiple datasets. For example, we are able to train models to almost their original accuracy on the IMDB sentiment analysis task using just 20 distilled sentences.
Collaborative Global-Local Networks for Memory-Efficient Segmentation of Ultra-High Resolution Images
May 15, 2019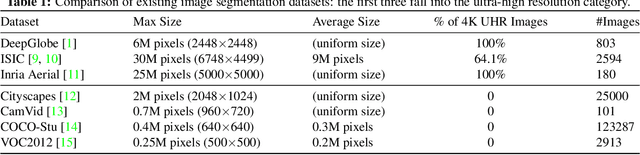
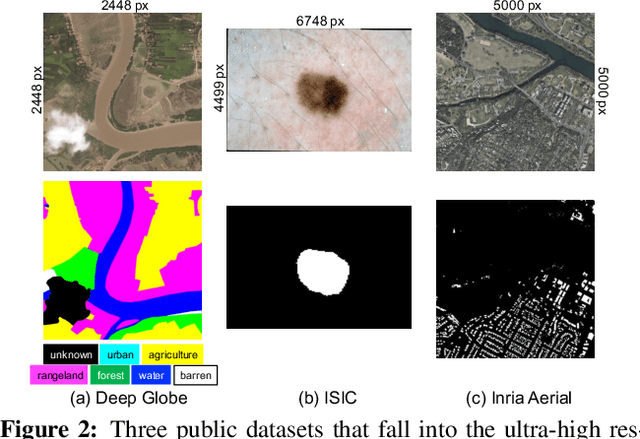
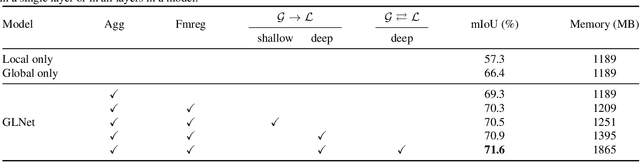
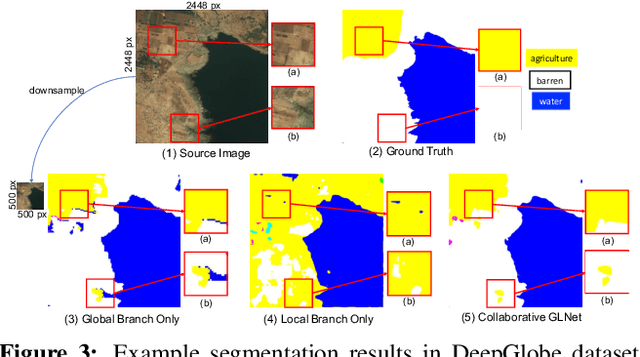
Segmentation of ultra-high resolution images is increasingly demanded, yet poses significant challenges for algorithm efficiency, in particular considering the (GPU) memory limits. Current approaches either downsample an ultra-high resolution image or crop it into small patches for separate processing. In either way, the loss of local fine details or global contextual information results in limited segmentation accuracy. We propose collaborative Global-Local Networks (GLNet) to effectively preserve both global and local information in a highly memory-efficient manner. GLNet is composed of a global branch and a local branch, taking the downsampled entire image and its cropped local patches as respective inputs. For segmentation, GLNet deeply fuses feature maps from two branches, capturing both the high-resolution fine structures from zoomed-in local patches and the contextual dependency from the downsampled input. To further resolve the potential class imbalance problem between background and foreground regions, we present a coarse-to-fine variant of GLNet, also being memory-efficient. Extensive experiments and analyses have been performed on three real-world ultra-high aerial and medical image datasets (resolution up to 30 million pixels). With only one single 1080Ti GPU and less than 2GB memory used, our GLNet yields high-quality segmentation results and achieves much more competitive accuracy-memory usage trade-offs compared to state-of-the-arts.
Bioresorbable Scaffold Visualization in IVOCT Images Using CNNs and Weakly Supervised Localization
Oct 22, 2018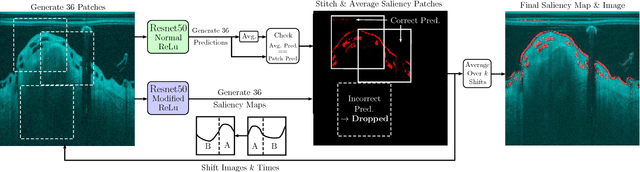

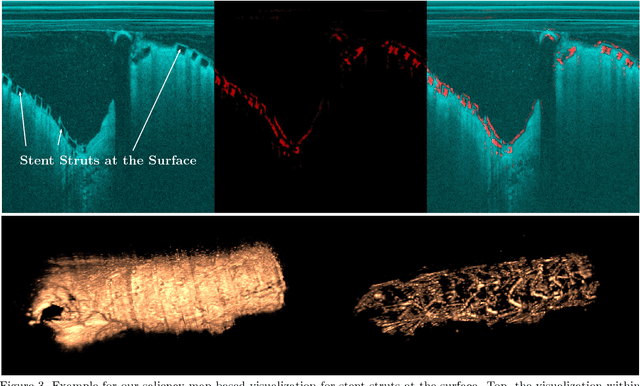
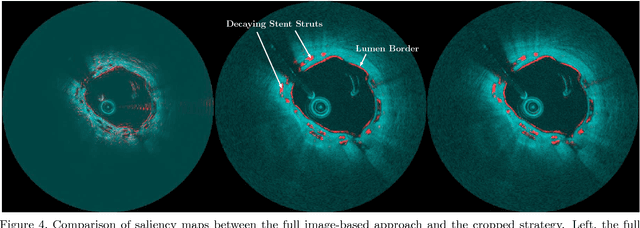
Bioresorbable scaffolds have become a popular choice for treatment of coronary heart disease, replacing traditional metal stents. Often, intravascular optical coherence tomography is used to assess potential malapposition after implantation and for follow-up examinations later on. Typically, the scaffold is manually reviewed by an expert, analyzing each of the hundreds of image slices. As this is time consuming, automatic stent detection and visualization approaches have been proposed, mostly for metal stent detection based on classic image processing. As bioresorbable scaffolds are harder to detect, recent approaches have used feature extraction and machine learning methods for automatic detection. However, these methods require detailed, pixel-level labels in each image slice and extensive feature engineering for the particular stent type which might limit the approaches' generalization capabilities. Therefore, we propose a deep learning-based method for bioresorbable scaffold visualization using only image-level labels. A convolutional neural network is trained to predict whether an image slice contains a metal stent, a bioresorbable scaffold, or no device. Then, we derive local stent strut information by employing weakly supervised localization using saliency maps with guided backpropagation. As saliency maps are generally diffuse and noisy, we propose a novel patch-based method with image shifting which allows for high resolution stent visualization. Our convolutional neural network model achieves a classification accuracy of 99.0 % for image-level stent classification which can be used for both high quality in-slice stent visualization and 3D rendering of the stent structure.
Learning-based real-time method to looking through scattering medium beyond the memory effect
Nov 04, 2019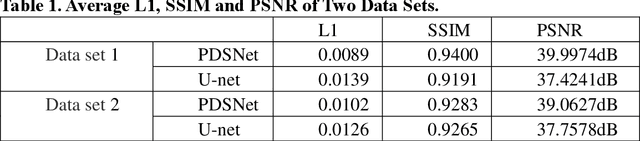


Strong scattering medium brings great difficulties to optical imaging, which is also a problem in medical imaging and many other fields. Optical memory effect makes it possible to image through strong random scattering medium. However, this method also has the limitation of limited angle field-of-view (FOV), which prevents it from being applied in practice. In this paper, a kind of practical convolutional neural network called PDSNet is proposed, which effectively breaks through the limitation of optical memory effect on FOV. Experiments is conducted to prove that the scattered pattern can be reconstructed accurately in real-time by PDSNet, and it is widely applicable to retrieve complex objects of random scales and different scattering media.
An Open-set Recognition and Few-Shot Learning Dataset for Audio Event Classification in Domestic Environments
Mar 14, 2020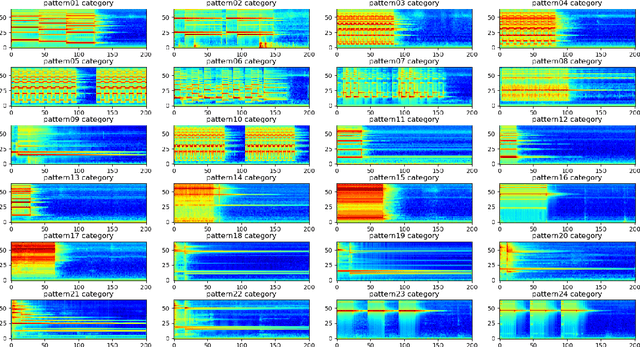
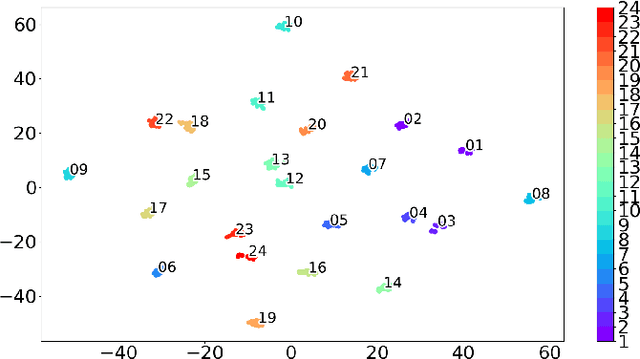

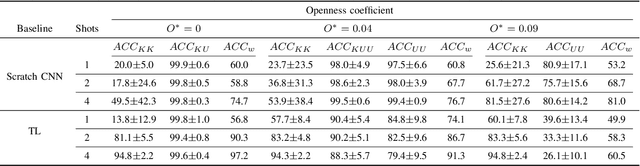
The problem of training a deep neural network with a small set of positive samples is known as few-shot learning (FSL). It is widely known that traditional deep learning (DL) algorithms usually show very good performance when trained with large datasets. However, in many applications, it is not possible to obtain such a high number of samples. In the image domain, typical FSL applications are those related to face recognition. In the audio domain, music fraud or speaker recognition can be clearly benefited from FSL methods. This paper deals with the application of FSL to the detection of specific and intentional acoustic events given by different types of sound alarms, such as door bells or fire alarms, using a limited number of samples. These sounds typically occur in domestic environments where many events corresponding to a wide variety of sound classes take place. Therefore, the detection of such alarms in a practical scenario can be considered an open-set recognition (OSR) problem. To address the lack of a dedicated public dataset for audio FSL, researchers usually make modifications on other available datasets. This paper is aimed at providing the audio recognition community with a carefully annotated dataset for FSL and OSR comprised of 1360 clips from 34 classes divided into pattern sounds and unwanted sounds. To facilitate and promote research in this area, results with two baseline systems (one trained from scratch and another based on transfer learning), are presented.
Post-mortem Iris Recognition with Deep-Learning-based Image Segmentation
Jan 07, 2019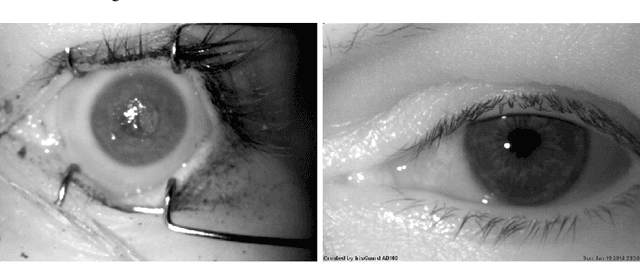
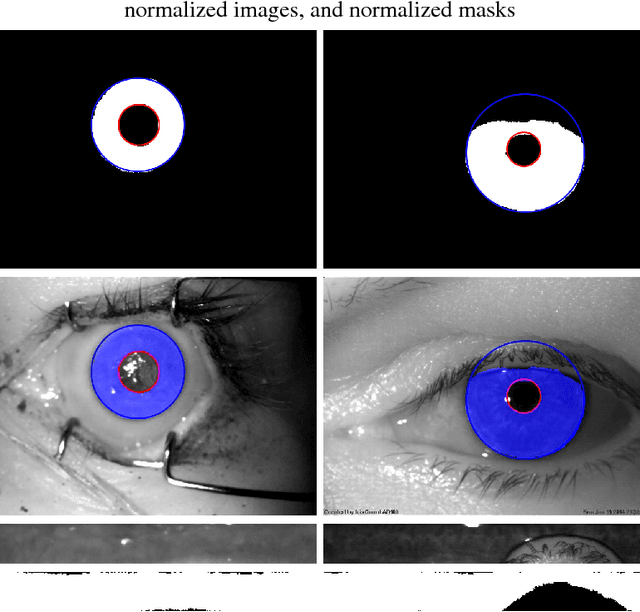
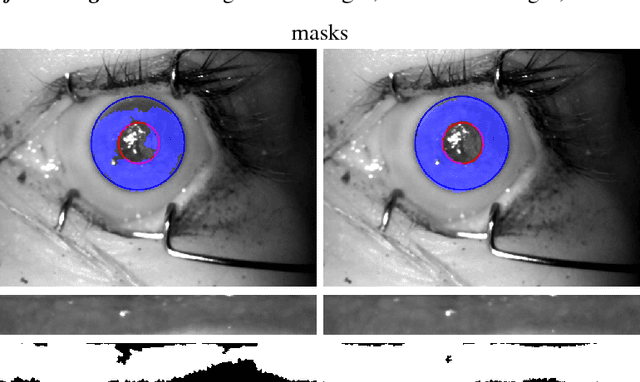
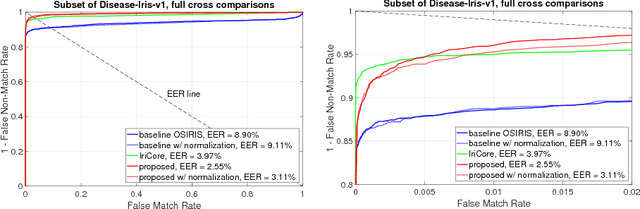
This paper proposes the first known to us iris recognition methodology designed specifically for post-mortem samples. We propose to use deep learning-based iris segmentation models to extract highly irregular iris texture areas in post-mortem iris images. We show how to use segmentation masks predicted by neural networks in conventional, Gabor-based iris recognition method, which employs circular approximations of the pupillary and limbic iris boundaries. As a whole, this method allows for a significant improvement in post-mortem iris recognition accuracy over the methods designed only for ante-mortem irises, including the academic OSIRIS and commercial IriCore implementations. The proposed method reaches the EER less than 1% for samples collected up to 10 hours after death, when compared to 16.89% and 5.37% of EER observed for OSIRIS and IriCore, respectively. For samples collected up to 369 hours post-mortem, the proposed method achieves the EER 21.45%, while 33.59% and 25.38% are observed for OSIRIS and IriCore, respectively. Additionally, the method is tested on a database of iris images collected from ophthalmology clinic patients, for which it also offers an advantage over the two remaining methods. This work is the first step towards post-mortem-specific iris recognition, which increases the chances of identification of deceased subjects in forensic investigations. The new database of post-mortem iris images acquired from 42 subjects, as well as the deep learning-based segmentation models are made available along with the paper, to ensure all the results presented in this manuscript are reproducible.
GLA in MediaEval 2018 Emotional Impact of Movies Task
Nov 27, 2019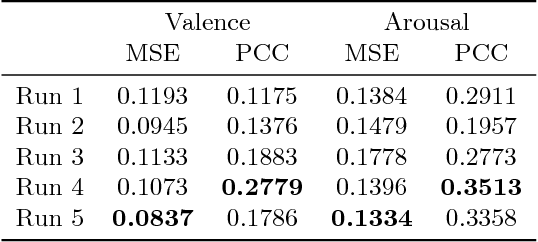
The visual and audio information from movies can evoke a variety of emotions in viewers. Towards a better understanding of viewer impact, we present our methods for the MediaEval 2018 Emotional Impact of Movies Task to predict the expected valence and arousal continuously in movies. This task, using the LIRIS-ACCEDE dataset, enables researchers to compare different approaches for predicting viewer impact from movies. Our approach leverages image, audio, and face based features computed using pre-trained neural networks. These features were computed over time and modeled using a gated recurrent unit (GRU) based network followed by a mixture of experts model to compute multiclass predictions. We smoothed these predictions using a Butterworth filter for our final result. Our method enabled us to achieve top performance in three evaluation metrics in the MediaEval 2018 task.