 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
State of the Art on Neural Rendering
Apr 08, 2020



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Efficient 2D neuron boundary segmentation with local topological constraints
Feb 03, 2020
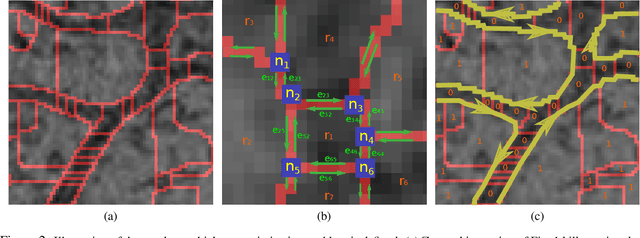
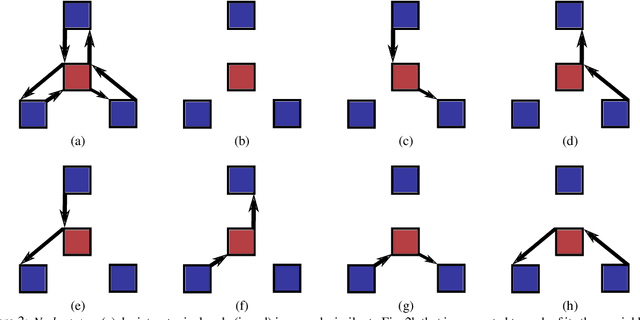

We present a method for segmenting neuron membranes in 2D electron microscopy imagery. This segmentation task has been a bottleneck to reconstruction efforts of the brain's synaptic circuits. One common problem is the misclassification of blurry membrane fragments as cell interior, which leads to merging of two adjacent neuron sections into one via the blurry membrane region. Human annotators can easily avoid such errors by implicitly performing gap completion, taking into account the continuity of membranes. Drawing inspiration from these human strategies, we formulate the segmentation task as an edge labeling problem on a graph with local topological constraints. We derive an integer linear program (ILP) that enforces membrane continuity, i.e. the absence of gaps. The cost function of the ILP is the pixel-wise deviation of the segmentation from a priori membrane probabilities derived from the data. Based on membrane probability maps obtained using random forest classifiers and convolutional neural networks, our method improves the neuron boundary segmentation accuracy compared to a variety of standard segmentation approaches. Our method successfully performs gap completion and leads to fewer topological errors. The method could potentially also be incorporated into other image segmentation pipelines with known topological constraints.
Jacobian Adversarially Regularized Networks for Robustness
Dec 21, 2019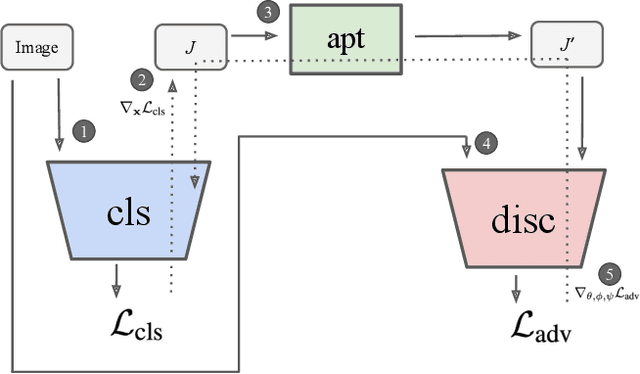
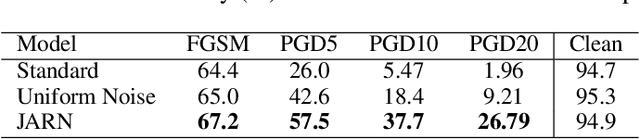
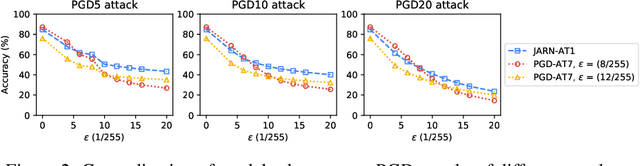
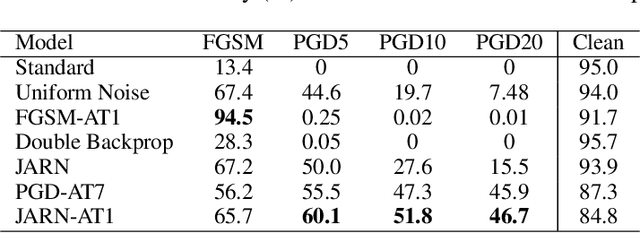
Adversarial examples are crafted with imperceptible perturbations with the intent to fool neural networks. Against such attacks, adversarial training and its variants stand as the strongest defense to date. Previous studies have pointed out that robust models that have undergone adversarial training tend to produce more salient and interpretable Jacobian matrices than their non-robust counterparts. A natural question is whether a model trained with an objective to produce salient Jacobian can result in better robustness. This paper answers this question with affirmative empirical results. We propose Jacobian Adversarially Regularized Networks (JARN) as a method to optimize the saliency of a classifier's Jacobian by adversarially regularizing the model's Jacobian to resemble natural training images. Image classifiers trained with JARN show improved robust accuracy compared to standard models on the MNIST, SVHN and CIFAR-10 datasets, uncovering a new angle to boost robustness without using adversarial training.
Adversarial Incremental Learning
Feb 03, 2020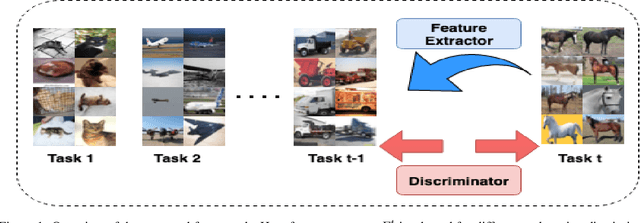
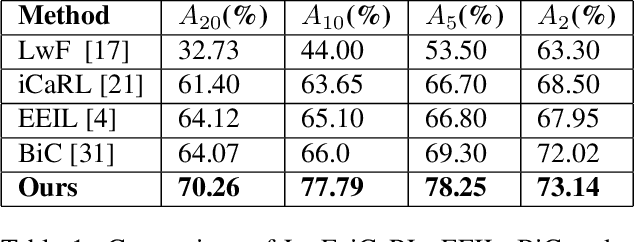
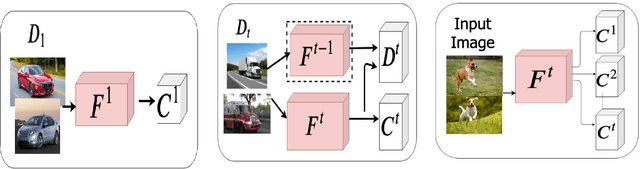
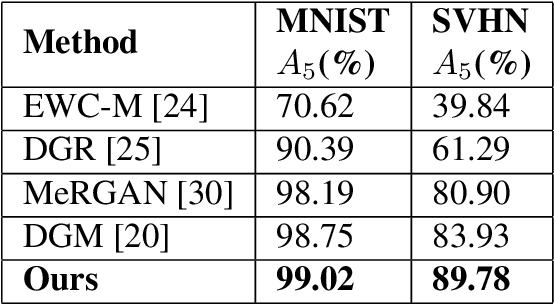
Although deep learning performs really well in a wide variety of tasks, it still suffers from catastrophic forgetting -- the tendency of neural networks to forget previously learned information upon learning new tasks where previous data is not available. Earlier methods of incremental learning tackle this problem by either using a part of the old dataset, by generating exemplars or by using memory networks. Although, these methods have shown good results but using exemplars or generating them, increases memory and computation requirements. To solve these problems we propose an adversarial discriminator based method that does not make use of old data at all while training on new tasks. We particularly tackle the class incremental learning problem in image classification, where data is provided in a class-based sequential manner. For this problem, the network is trained using an adversarial loss along with the traditional cross-entropy loss. The cross-entropy loss helps the network progressively learn new classes while the adversarial loss helps in preserving information about the existing classes. Using this approach, we are able to outperform other state-of-the-art methods on CIFAR-100, SVHN, and MNIST datasets.
Constrained Nonnegative Matrix Factorization for Blind Hyperspectral Unmixing incorporating Endmember Independence
Mar 16, 2020
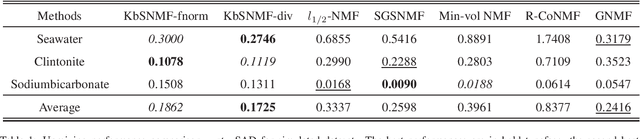
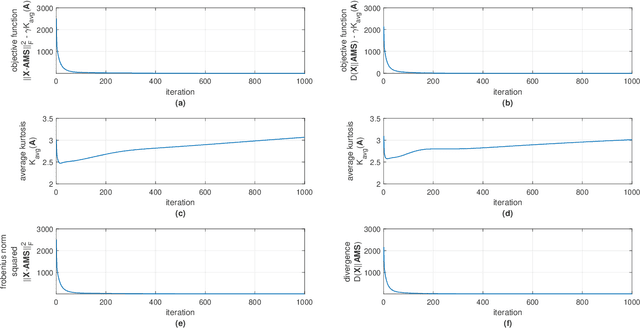
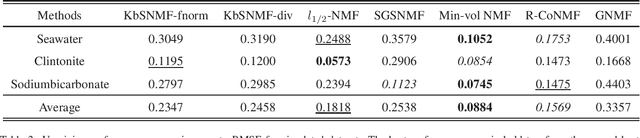
Hyperspectral image (HSI) analysis has become a key area in the field of remote sensing as a result of its ability to exploit richer information in the form of multiple spectral bands. The study of hyperspectral unmixing (HU) is important in HSI analysis due to the insufficient spatial resolution of customary imaging spectrometers. The endmembers of an HSI are more likely to be generated by independent sources and be mixed in a macroscopic degree before arriving at the sensor element of the imaging spectrometer as mixed spectra. Over the past few decades, many attempts have focused on imposing auxiliary constraints on the conventional nonnegative matrix factorization (NMF) framework in order to effectively unmix these mixed spectra. Signifying a step forward toward finding an optimum constraint to extract endmembers, this paper presents a novel blind HU algorithm, referred to as Kurtosis-based Smooth Nonnegative Matrix Factorization (KbSNMF) which incorporates a novel constraint based on the statistical independence of the probability density functions of endmember spectra. Imposing this constraint on the conventional NMF framework promotes the extraction of independent endmembers while further enhancing the parts-based representation of data. The proposed algorithm manages to outperform several state of the art NMF-based algorithms in terms of extracting endmember spectra from hyperspectral remote sensing data; therefore, it could uplift the performance of recent deep learning HU methods which utilizes the endmember spectra as supervisory input data for abundance extraction. We release all code utilized to implement KbSNMF.
Dermoscopic Image Analysis for ISIC Challenge 2018
Jul 24, 2018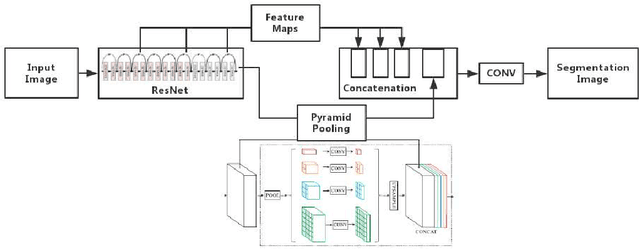
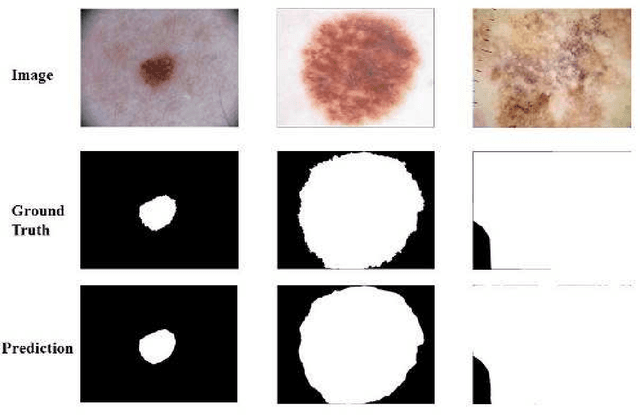
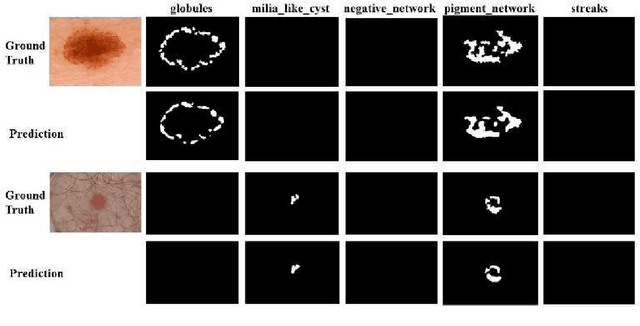
This short paper reports the algorithms we used and the evaluation performances for ISIC Challenge 2018. Our team participates in all the tasks in this challenge. In lesion segmentation task, the pyramid scene parsing network (PSPNet) is modified to segment the lesions. In lesion attribute detection task, the modified PSPNet is also adopted in a multi-label way. In disease classification task, the DenseNet-169 is adopted for multi-class classification.
Adversarial Transformations for Semi-Supervised Learning
Nov 18, 2019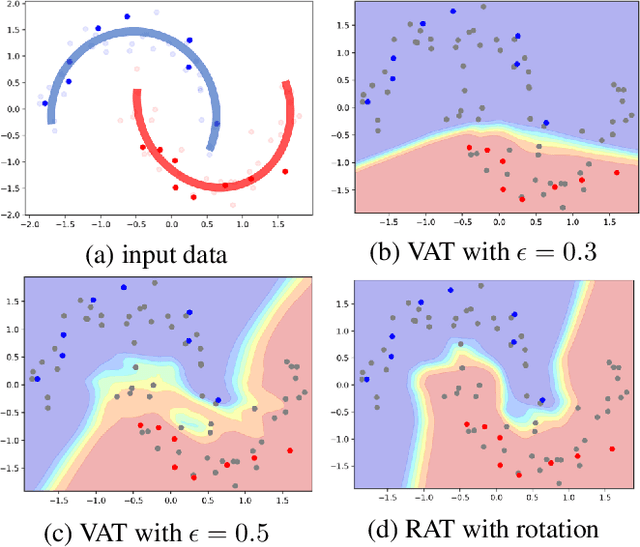


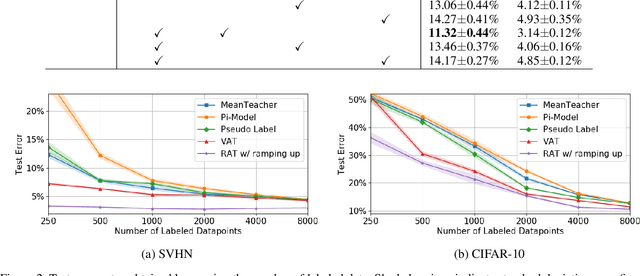
We propose a Regularization framework based on Adversarial Transformations (RAT) for semi-supervised learning. RAT is designed to enhance robustness of the output distribution of class prediction for a given data against input perturbation. RAT is an extension of Virtual Adversarial Training (VAT) in such a way that RAT adversarialy transforms data along the underlying data distribution by a rich set of data transformation functions that leave class label invariant, whereas VAT simply produces adversarial additive noises. In addition, we verified that a technique of gradually increasing of perturbation region further improve the robustness. In experiments, we show that RAT significantly improves classification performance on CIFAR-10 and SVHN compared to existing regularization methods under standard semi-supervised image classification settings.
Unsupervised Domain-Specific Deblurring via Disentangled Representations
Mar 05, 2019
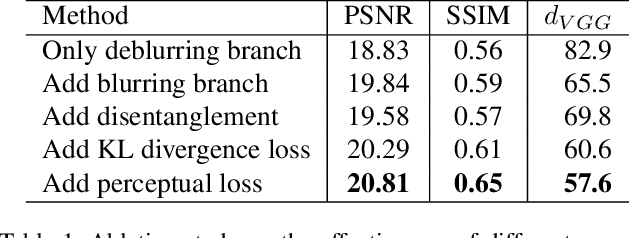
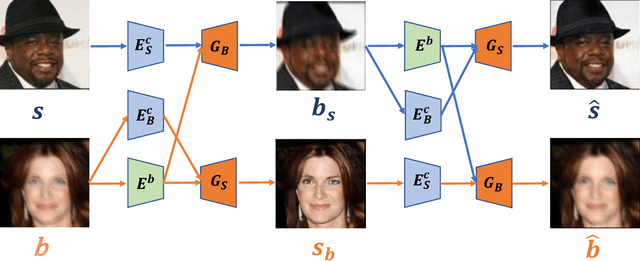
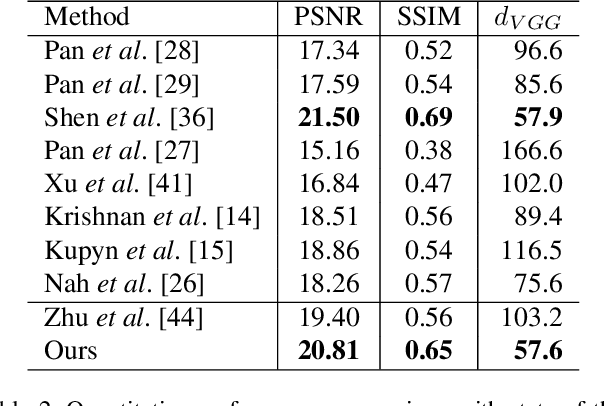
Image deblurring aims to restore the latent sharp images from the corresponding blurred ones. In this paper, we present an unsupervised method for domain-specific single-image deblurring based on disentangled representations. The disentanglement is achieved by splitting the content and blur features in a blurred image using content encoders and blur encoders. We enforce a KL divergence loss to regularize the distribution range of extracted blur attributes such that little content information is contained. Meanwhile, to handle the unpaired training data, a blurring branch and the cycle-consistency loss are added to guarantee that the content structures of the deblurred results match the original images. We also add an adversarial loss on deblurred results to generate visually realistic images and a perceptual loss to further mitigate the artifacts. We perform extensive experiments on the tasks of face and text deblurring using both synthetic datasets and real images, and achieve improved results compared to recent state-of-the-art deblurring methods.
Bayesian Tensor Network and Optimization Algorithm for Probabilistic Machine Learning
Dec 30, 2019
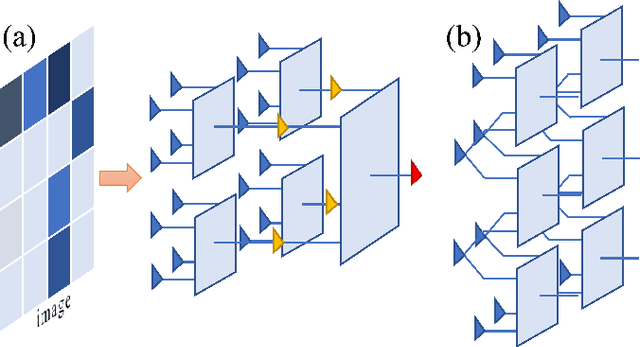
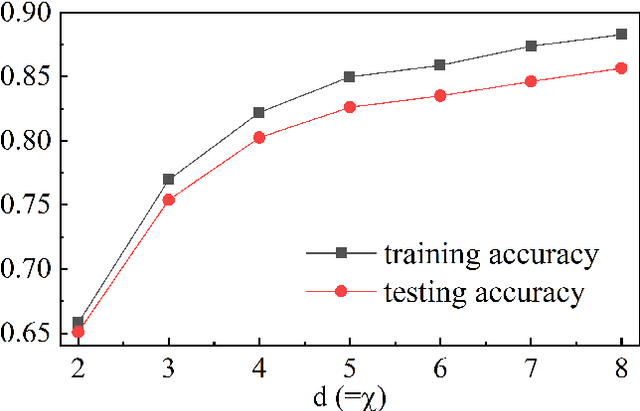
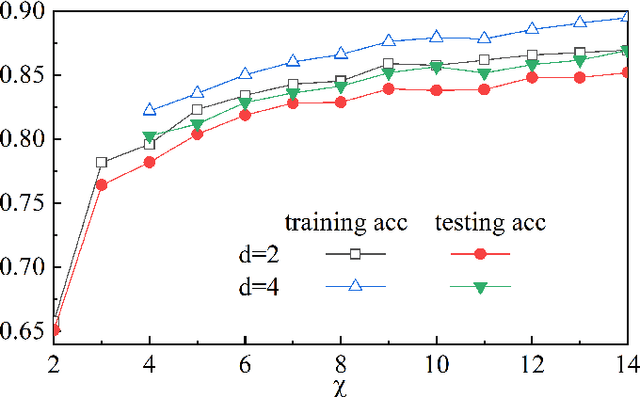
Describing or calculating the conditional probabilities of multiple events is exponentially expensive. In this work, a natural generalization of Bayesian belief network is proposed by incorporating with tensor network, which is dubbed as Bayesian tensor network (BTN), to efficiently describe the conditional probabilities among multiple sets of events. The complexity of BTN that gives the conditional probabilities of $M$ sets of events scales only polynomially with $M$. To testify its validity, BTN is implemented to capture the conditional probabilities between images and their classifications, where each feature is mapped to a probability distribution of a set of mutually exclusive events. A rotation optimization method is suggested to update BTN, which avoids gradient vanishing problem and exhibits high efficiency. With a simple tree network structures, BTN exhibits competitive performances on fashion-MNIST dataset. Analogous to the tensor network simulations of quantum systems, the validity of BTN implies an "area law" of fluctuations in image recognition problems.
Unsupervised Speech Domain Adaptation Based on Disentangled Representation Learning for Robust Speech Recognition
Apr 12, 2019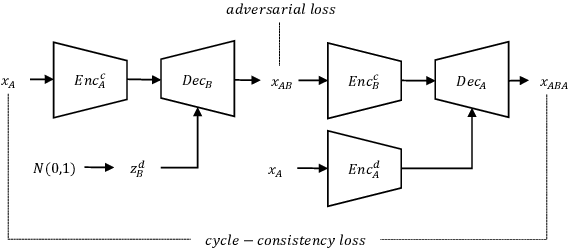
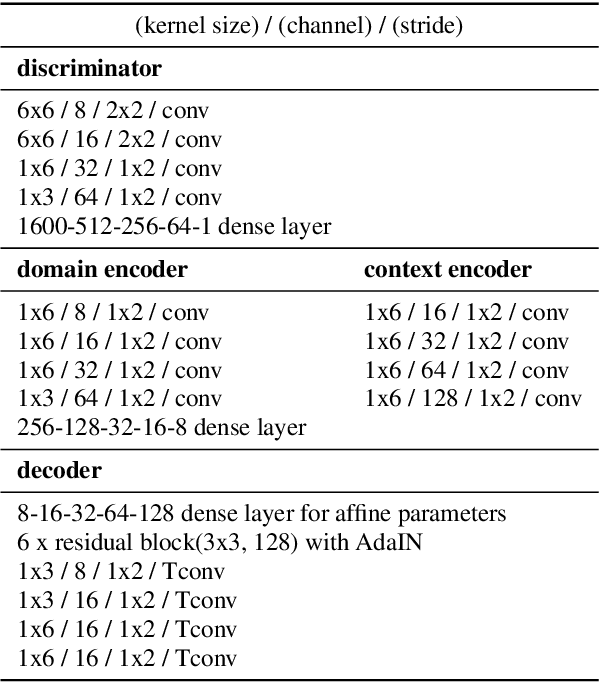
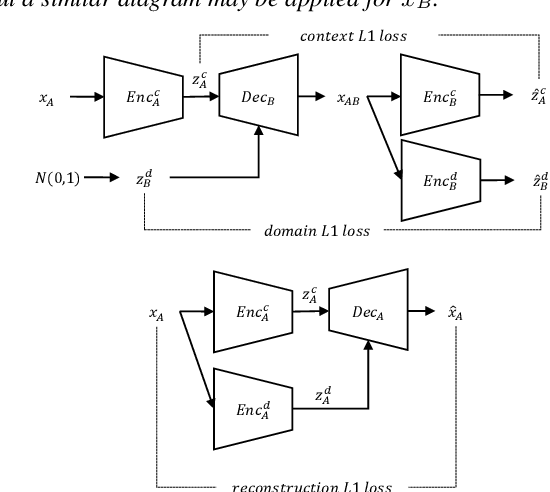
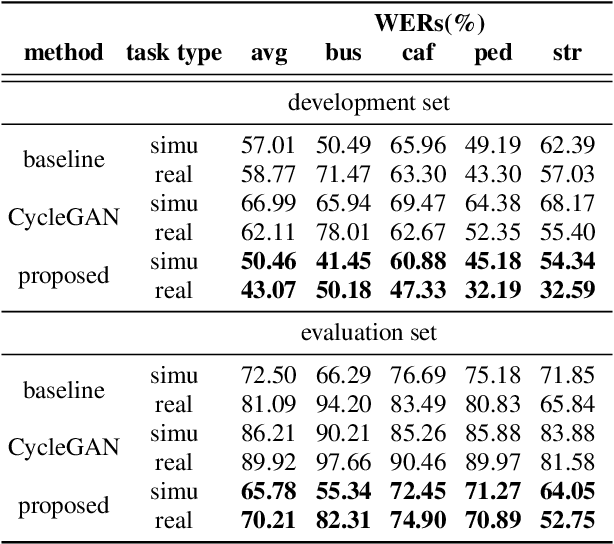
In general, the performance of automatic speech recognition (ASR) systems is significantly degraded due to the mismatch between training and test environments. Recently, a deep-learning-based image-to-image translation technique to translate an image from a source domain to a desired domain was presented, and cycle-consistent adversarial network (CycleGAN) was applied to learn a mapping for speech-to-speech conversion from a speaker to a target speaker. However, this method might not be adequate to remove corrupting noise components for robust ASR because it was designed to convert speech itself. In this paper, we propose a domain adaptation method based on generative adversarial nets (GANs) with disentangled representation learning to achieve robustness in ASR systems. In particular, two separated encoders, context and domain encoders, are introduced to learn distinct latent variables. The latent variables allow us to convert the domain of speech according to its context and domain representation. We improved word accuracies by 6.55~15.70\% for the CHiME4 challenge corpus by applying a noisy-to-clean environment adaptation for robust ASR. In addition, similar to the method based on the CycleGAN, this method can be used for gender adaptation in gender-mismatched recognition.