 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Neural Network Decoupling
Jun 04, 2019
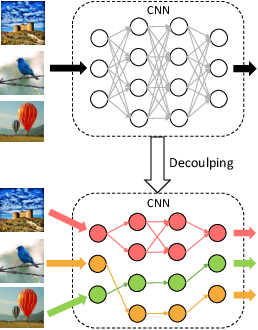
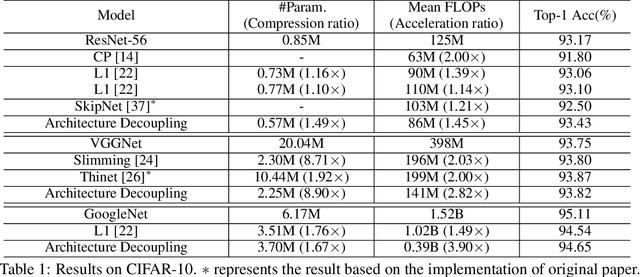
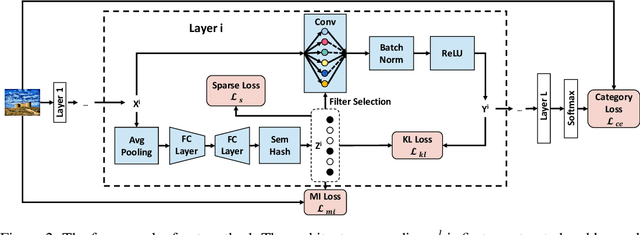
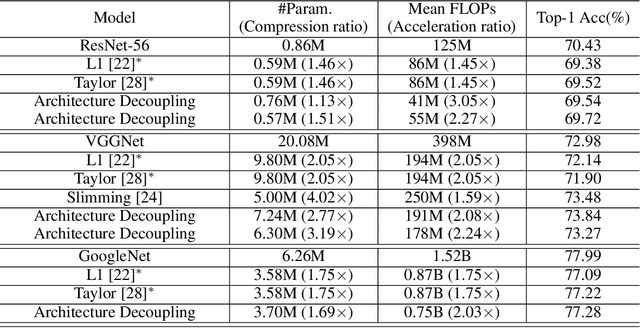
Convolutional neural networks (CNNs) have achieved a superior performance by taking advantages of the complex network architectures and huge numbers of parameters, which however become uninterpretable and challenge their full potential to practical applications. Towards better understand the rationale behind the network decisions, we propose a novel architecture decoupling method, which dynamically discovers the hierarchical path consisting of activated filters for each input image. In particular, architecture controlling module is introduced in each layer to encode the network architecture and identify the activated filters corresponding to the specific input. Then, mutual information between architecture encoding and the attribute of input image is maximized to decouple the network architecture, and subsequently disentangles the filters by limiting the outputs of filter during training. Extensive experiments show that several merits have been achieved based on the proposed architecture decoupling, i.e., interpretation, acceleration and adversarial attacking.
TopoTag: A Robust and Scalable Topological Fiducial Marker System
Aug 05, 2019
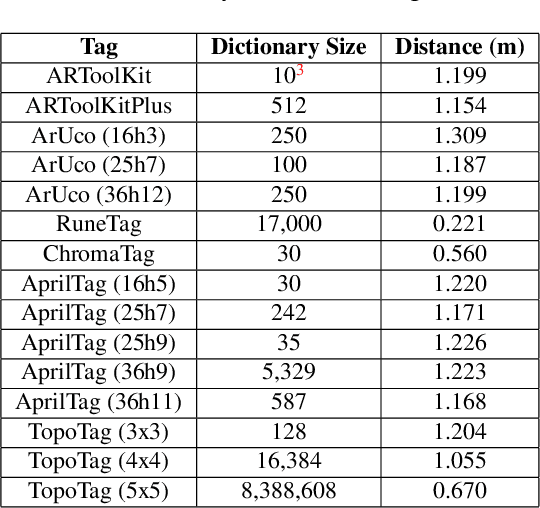

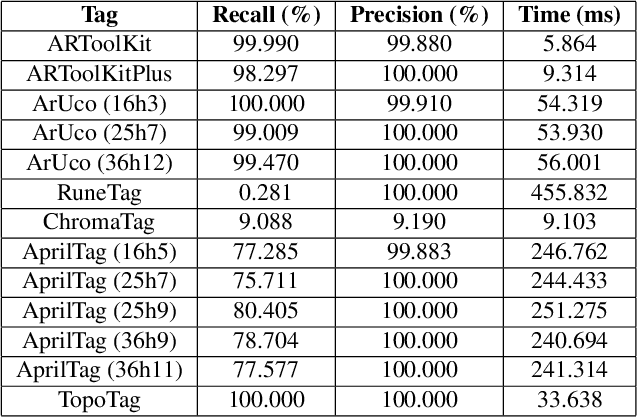
Fiducial markers have been playing an important role in augmented reality (AR), robot navigation, and general applications where the relative pose between a camera and an object is required. We introduce TopoTag, a robust and scalable topological fiducial marker system, which supports reliable and accurate pose estimation from a single image. TopoTag uses topological and geometrical information in marker detection to achieve higher robustness. Without sacrificing bits for higher recall and precision like previous systems, TopoTag can use full bits for ID encoding and supports tens of thousands unique IDs and easily extends to millions and more by adding more bits, thus achieves perfect scalability. We collect a large dataset including in total 169,713 images for evaluation, involving in-plane and out-of-plane rotation, image blur, different distances and various backgrounds, etc. Experiments show that TopoTag significantly outperforms previous fiducial marker systems in terms of various metrics, including detection accuracy, vertex jitter, pose jitter and accuracy, etc. In addition, TopoTag supports occlusion as long as main tag topological structure is maintained and flexible shape design where users can customize inter and outer marker shapes. Our dataset, marker design and detection algorithm are public to the community.
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
Mar 28, 2020
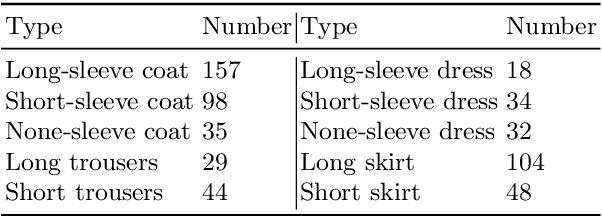

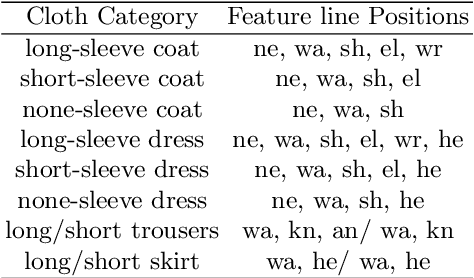
High-fidelity clothing reconstruction is the key to achieving photorealism in a wide range of applications including human digitization, virtual try-on, etc. Recent advances in learning-based approaches have accomplished unprecedented accuracy in recovering unclothed human shape and pose from single images, thanks to the availability of powerful statistical models, e.g. SMPL, learned from a large number of body scans. In contrast, modeling and recovering clothed human and 3D garments remains notoriously difficult, mostly due to the lack of large-scale clothing models available for the research community. We propose to fill this gap by introducing Deep Fashion3D, the largest collection to date of 3D garment models, with the goal of establishing a novel benchmark and dataset for the evaluation of image-based garment reconstruction systems. Deep Fashion3D contains 2078 models reconstructed from real garments, which covers 10 different categories and 563 garment instances. It provides rich annotations including 3D feature lines, 3D body pose and the corresponded multi-view real images. In addition, each garment is randomly posed to enhance the variety of real clothing deformations. To demonstrate the advantage of Deep Fashion3D, we propose a novel baseline approach for single-view garment reconstruction, which leverages the merits of both mesh and implicit representations. A novel adaptable template is proposed to enable the learning of all types of clothing in a single network. Extensive experiments have been conducted on the proposed dataset to verify its significance and usefulness. We will make Deep Fashion3D publicly available upon publication.
Deep Direct Visual Odometry
Dec 11, 2019
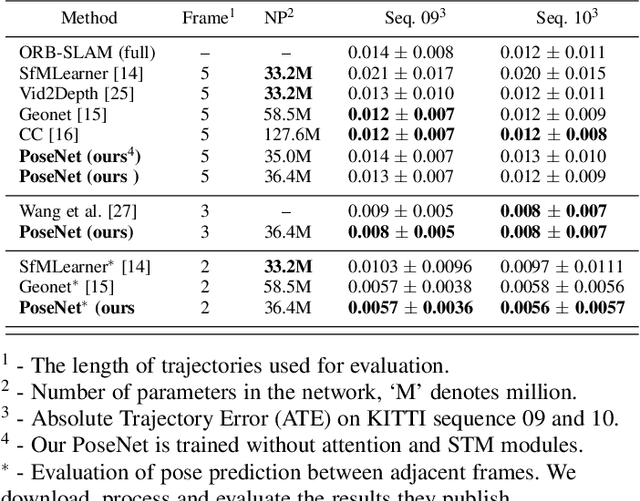
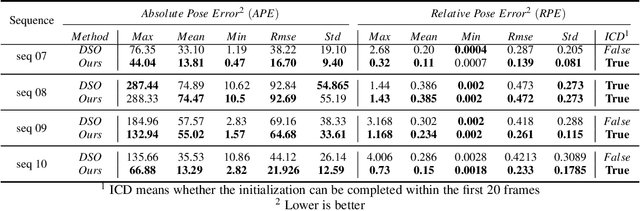
Monocular direct visual odometry (DVO) relies heavily on high-quality images and good initial pose estimation for accuracy tracking process, which means that DVO may fail if the image quality is poor or the initial value is incorrect. In this study, we present a new architecture to overcome the above limitations by embedding deep learning into DVO. A novel self-supervised network architecture for effectively predicting 6-DOF pose is proposed in this paper, and we incorporate the pose prediction into Direct Sparse Odometry (DSO) for robust initialization and tracking process. Furthermore, the attention mechanism is included to select useful features for accurate pose regression. The experiments on the KITTI dataset show that the proposed network achieves an outstanding performance compared with previous self-supervised methods, and the integration with pose network makes the initialization and tracking of DSO more robust and accurate.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Mar 16, 2020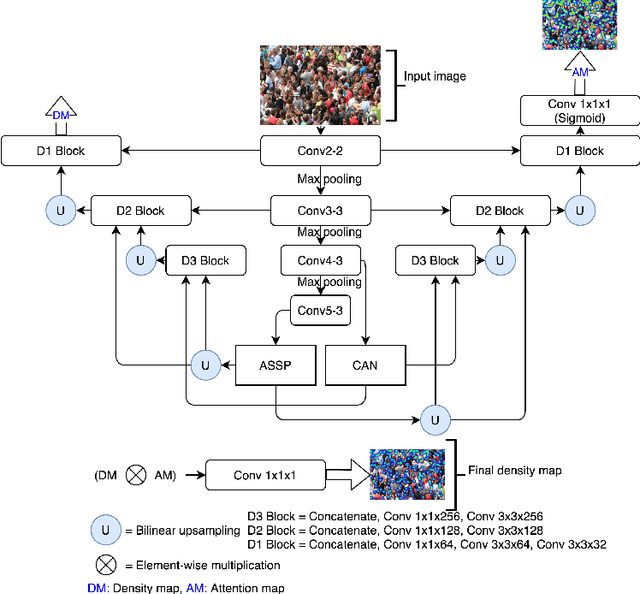
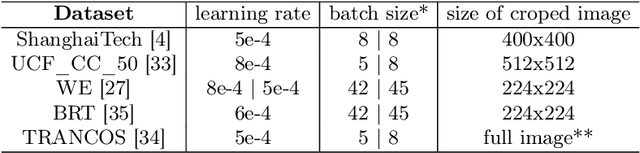
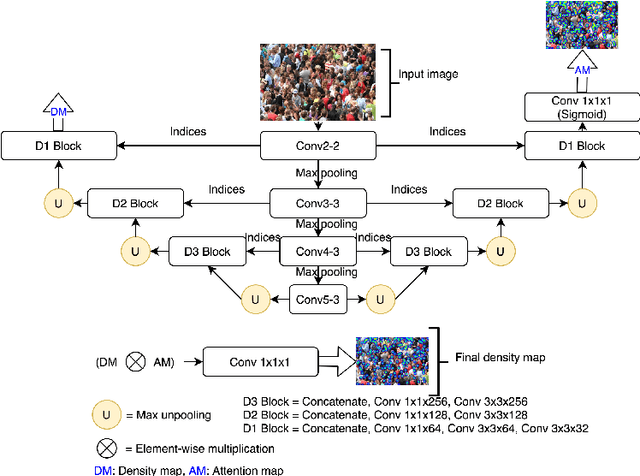
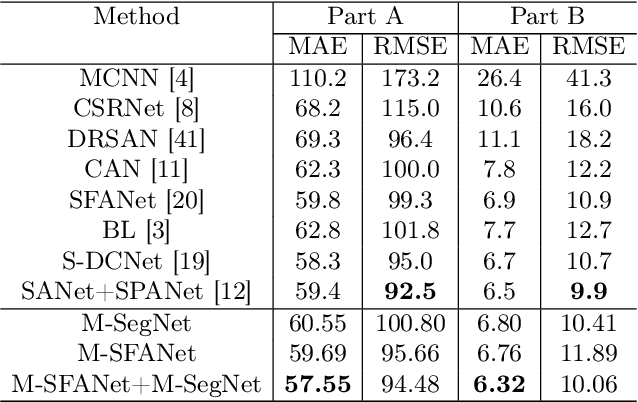
In this paper, we proposed two modified neural network architectures based on SFANet and SegNet respectively for accurate and efficient crowd counting. Inspired by SFANet, the first model is attached with two novel multi-scale-aware modules, called ASSP and CAN. This model is called M-SFANet. The encoder of M-SFANet is enhanced with ASSP containing parallel atrous convolution with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage contextual module called CAN which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet's decoder structure, M-SFANet's decoder has dual paths, for density map generation and attention map generation. The second model is called M-SegNet. For M-SegNet, we simply change bilinear upsampling used in SFANet to max unpooling originally from SegNet and propose the faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and end-to-end trainable. We also conduct extensive experiments on four crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could outperform some state-of-the-art crowd counting methods.
State of the Art on Neural Rendering
Apr 08, 2020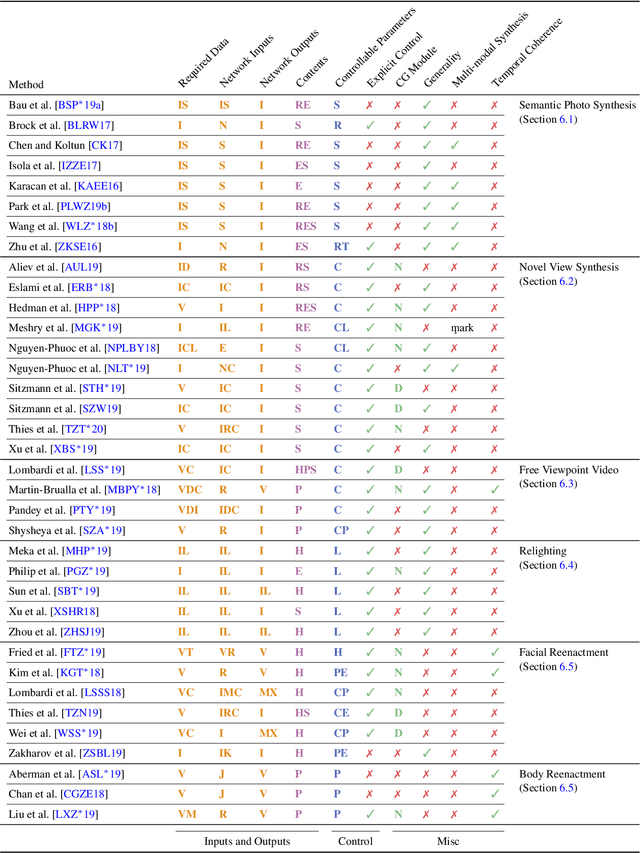



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Deep Face Quality Assessment
Nov 11, 2018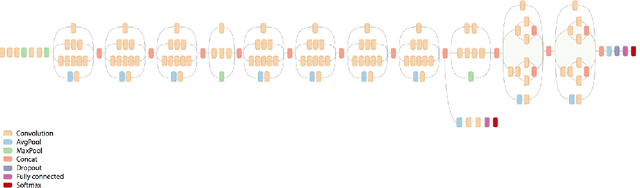


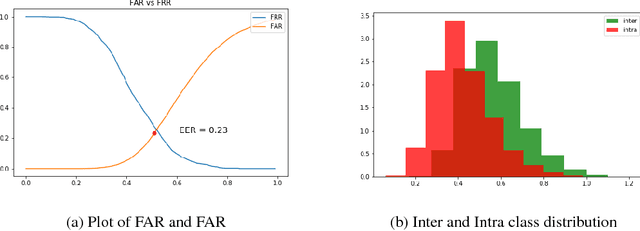
Face image quality is an important factor in facial recognition systems as its verification and recognition accuracy is highly dependent on the quality of image presented. Rejecting low quality images can significantly increase the accuracy of any facial recognition system. In this project, a simple approach is presented to train a deep convolutional neural network to perform end-to-end face image quality assessment. The work is done in 2 stages : First, generation of quality score label and secondly, training a deep convolutional neural network in a supervised manner to predict quality score between 0 and 1. The generation of quality labels is done by comparing the face image with a template of best quality images and then evaluating the normalized score based on the similarity.
Efficient 2D neuron boundary segmentation with local topological constraints
Feb 03, 2020
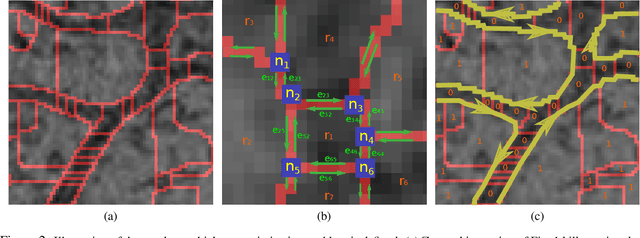
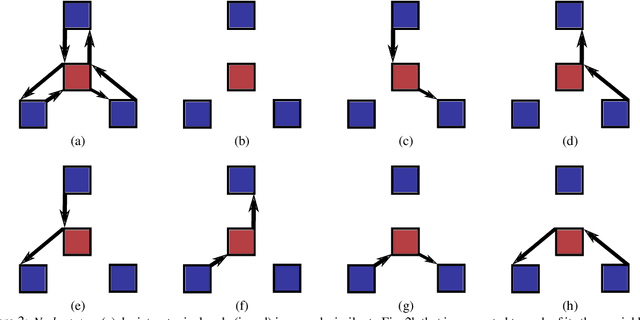

We present a method for segmenting neuron membranes in 2D electron microscopy imagery. This segmentation task has been a bottleneck to reconstruction efforts of the brain's synaptic circuits. One common problem is the misclassification of blurry membrane fragments as cell interior, which leads to merging of two adjacent neuron sections into one via the blurry membrane region. Human annotators can easily avoid such errors by implicitly performing gap completion, taking into account the continuity of membranes. Drawing inspiration from these human strategies, we formulate the segmentation task as an edge labeling problem on a graph with local topological constraints. We derive an integer linear program (ILP) that enforces membrane continuity, i.e. the absence of gaps. The cost function of the ILP is the pixel-wise deviation of the segmentation from a priori membrane probabilities derived from the data. Based on membrane probability maps obtained using random forest classifiers and convolutional neural networks, our method improves the neuron boundary segmentation accuracy compared to a variety of standard segmentation approaches. Our method successfully performs gap completion and leads to fewer topological errors. The method could potentially also be incorporated into other image segmentation pipelines with known topological constraints.
Optimization with soft Dice can lead to a volumetric bias
Nov 06, 2019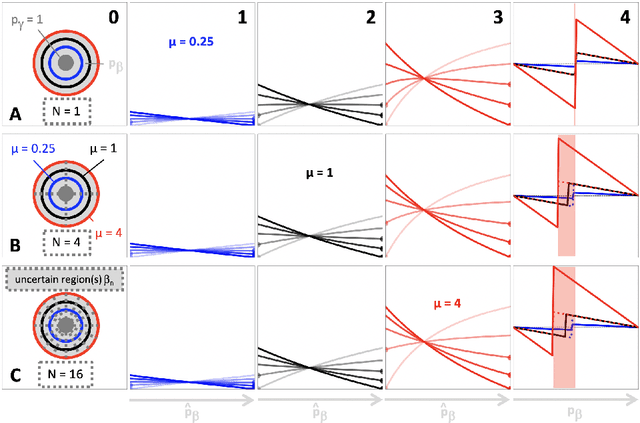

Segmentation is a fundamental task in medical image analysis. The clinical interest is often to measure the volume of a structure. To evaluate and compare segmentation methods, the similarity between a segmentation and a predefined ground truth is measured using metrics such as the Dice score. Recent segmentation methods based on convolutional neural networks use a differentiable surrogate of the Dice score, such as soft Dice, explicitly as the loss function during the learning phase. Even though this approach leads to improved Dice scores, we find that, both theoretically and empirically on four medical tasks, it can introduce a volumetric bias for tasks with high inherent uncertainty. As such, this may limit the method's clinical applicability.
Astronomical Image Denoising Using Dictionary Learning
Apr 12, 2013



Astronomical images suffer a constant presence of multiple defects that are consequences of the intrinsic properties of the acquisition equipments, and atmospheric conditions. One of the most frequent defects in astronomical imaging is the presence of additive noise which makes a denoising step mandatory before processing data. During the last decade, a particular modeling scheme, based on sparse representations, has drawn the attention of an ever growing community of researchers. Sparse representations offer a promising framework to many image and signal processing tasks, especially denoising and restoration applications. At first, the harmonics, wavelets, and similar bases and overcomplete representations have been considered as candidate domains to seek the sparsest representation. A new generation of algorithms, based on data-driven dictionaries, evolved rapidly and compete now with the off-the-shelf fixed dictionaries. While designing a dictionary beforehand leans on a guess of the most appropriate representative elementary forms and functions, the dictionary learning framework offers to construct the dictionary upon the data themselves, which provides us with a more flexible setup to sparse modeling and allows to build more sophisticated dictionaries. In this paper, we introduce the Centered Dictionary Learning (CDL) method and we study its performances for astronomical image denoising. We show how CDL outperforms wavelet or classic dictionary learning denoising techniques on astronomical images, and we give a comparison of the effect of these different algorithms on the photometry of the denoised images.