 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Breast lesion segmentation in ultrasound images with limited annotated data
Jan 21, 2020
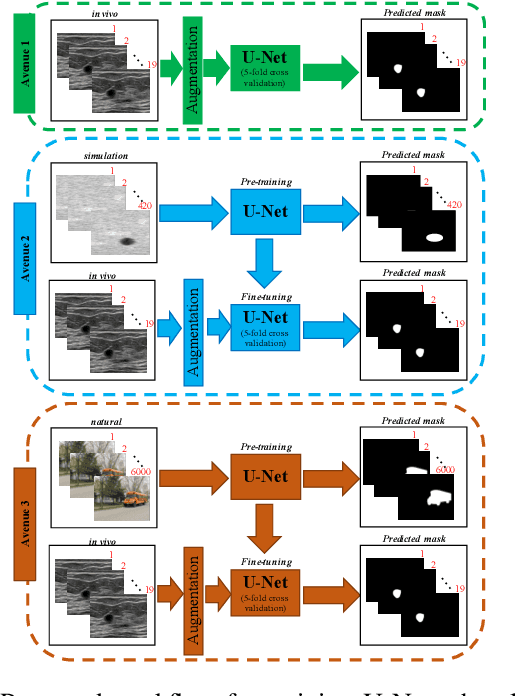

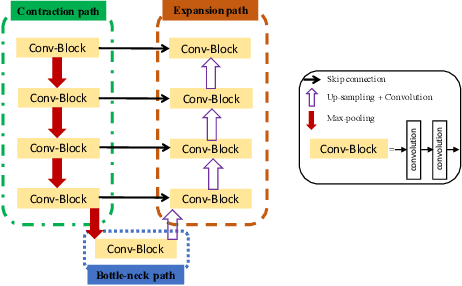

Ultrasound (US) is one of the most commonly used imaging modalities in both diagnosis and surgical interventions due to its low-cost, safety, and non-invasive characteristic. US image segmentation is currently a unique challenge because of the presence of speckle noise. As manual segmentation requires considerable efforts and time, the development of automatic segmentation algorithms has attracted researchers attention. Although recent methodologies based on convolutional neural networks have shown promising performances, their success relies on the availability of a large number of training data, which is prohibitively difficult for many applications. Therefore, in this study we propose the use of simulated US images and natural images as auxiliary datasets in order to pre-train our segmentation network, and then to fine-tune with limited in vivo data. We show that with as little as 19 in vivo images, fine-tuning the pre-trained network improves the dice score by 21% compared to training from scratch. We also demonstrate that if the same number of natural and simulation US images is available, pre-training on simulation data is preferable.
Spoofing PRNU Patterns of Iris Sensors while Preserving Iris Recognition
Aug 31, 2018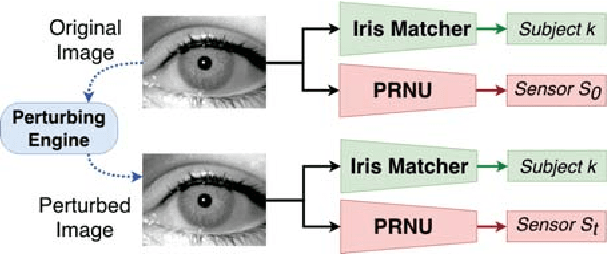
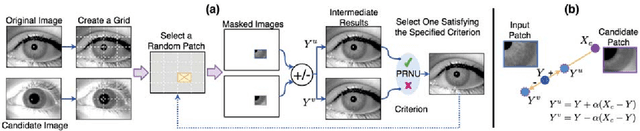
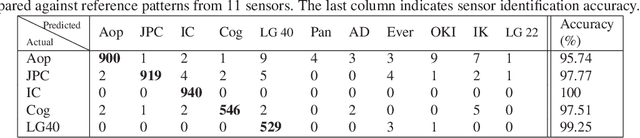
The principle of Photo Response Non-Uniformity (PRNU) is used to link an image with its source, i.e., the sensor that produced it. In this work, we investigate if it is possible to modify an iris image acquired using one sensor in order to spoof the PRNU noise pattern of a different sensor. In this regard, we develop an image perturbation routine that iteratively modifies blocks of pixels in the original iris image such that its PRNU pattern approaches that of a target sensor. Experiments indicate the efficacy of the proposed perturbation method in spoofing PRNU patterns present in an iris image whilst still retaining its biometric content.
OmniNet: A unified architecture for multi-modal multi-task learning
Jul 17, 2019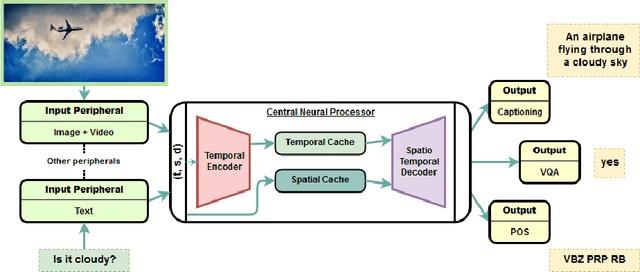

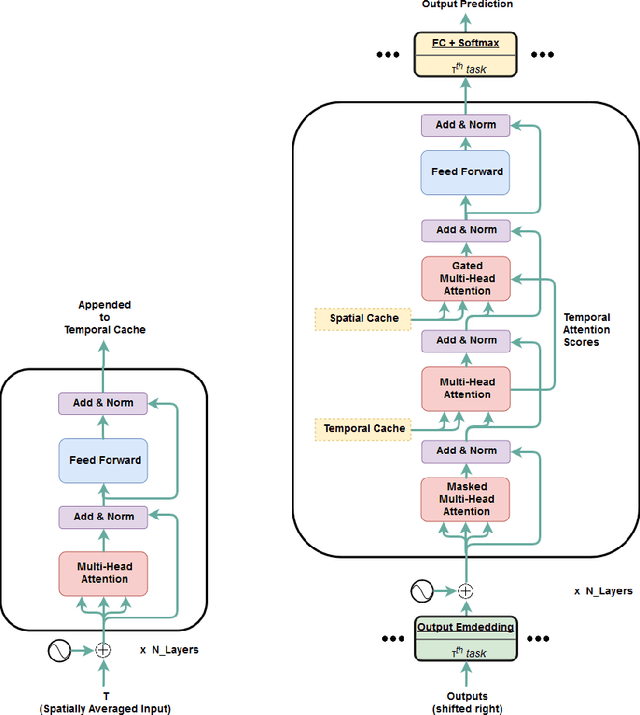
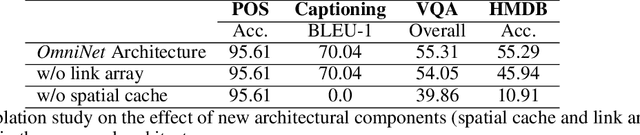
Transformer is a popularly used neural network architecture, especially for language understanding. We introduce an extended and unified architecture which can be used for tasks involving a variety of modalities like image, text, videos, etc. We propose a spatio-temporal cache mechanism that enables learning spatial dimension of the input in addition to the hidden states corresponding to the temporal input sequence. The proposed architecture further enables a single model to support tasks with multiple input modalities as well as asynchronous multi-task learning, thus we refer to it as OmniNet. For example, a single instance of OmniNet can concurrently learn to perform the tasks of part-of-speech tagging, image captioning, visual question answering and video activity recognition. We demonstrate that training these four tasks together results in about three times compressed model while retaining the performance in comparison to training them individually. We also show that using this neural network pre-trained on some modalities assists in learning an unseen task. This illustrates the generalization capacity of the self-attention mechanism on the spatio-temporal cache present in OmniNet.
Self-supervised Monocular Trained Depth Estimation using Self-attention and Discrete Disparity Volume
Mar 31, 2020
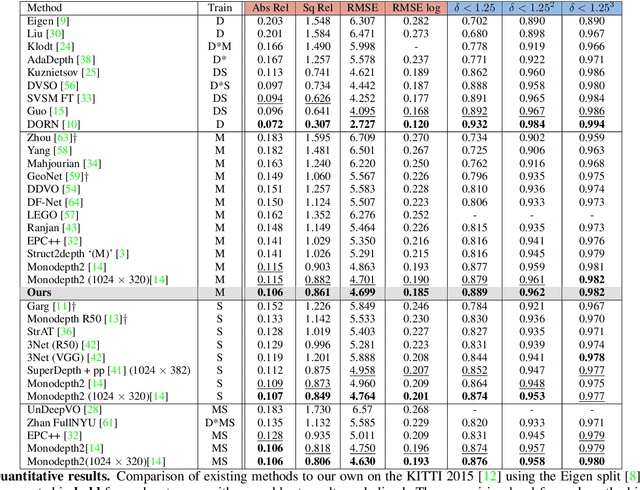
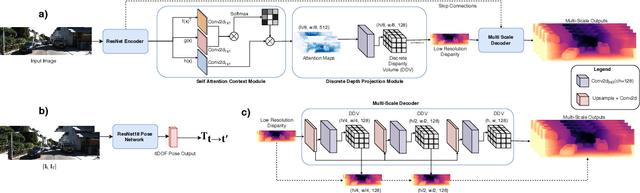
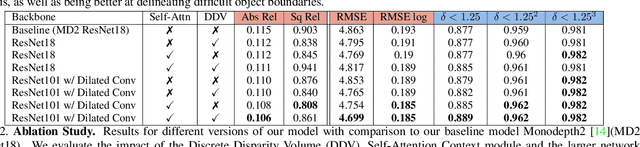
Monocular depth estimation has become one of the most studied applications in computer vision, where the most accurate approaches are based on fully supervised learning models. However, the acquisition of accurate and large ground truth data sets to model these fully supervised methods is a major challenge for the further development of the area. Self-supervised methods trained with monocular videos constitute one the most promising approaches to mitigate the challenge mentioned above due to the wide-spread availability of training data. Consequently, they have been intensively studied, where the main ideas explored consist of different types of model architectures, loss functions, and occlusion masks to address non-rigid motion. In this paper, we propose two new ideas to improve self-supervised monocular trained depth estimation: 1) self-attention, and 2) discrete disparity prediction. Compared with the usual localised convolution operation, self-attention can explore a more general contextual information that allows the inference of similar disparity values at non-contiguous regions of the image. Discrete disparity prediction has been shown by fully supervised methods to provide a more robust and sharper depth estimation than the more common continuous disparity prediction, besides enabling the estimation of depth uncertainty. We show that the extension of the state-of-the-art self-supervised monocular trained depth estimator Monodepth2 with these two ideas allows us to design a model that produces the best results in the field in KITTI 2015 and Make3D, closing the gap with respect self-supervised stereo training and fully supervised approaches.
Dynamic Neural Network Decoupling
Jun 04, 2019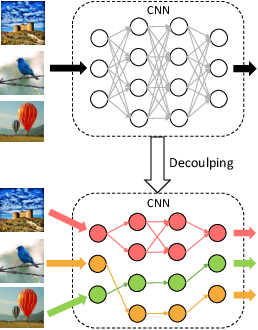
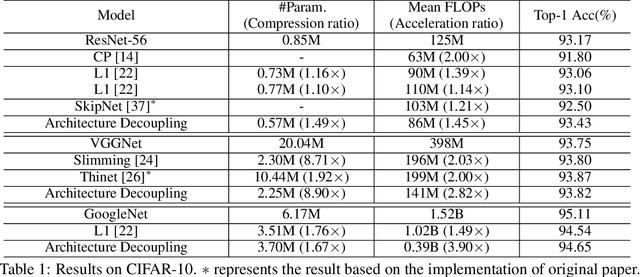
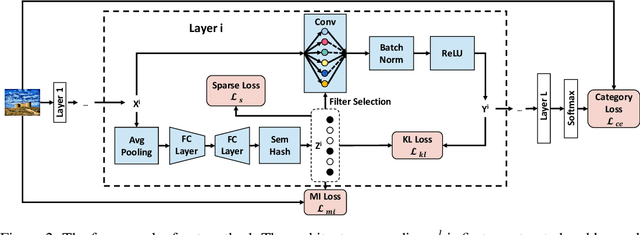
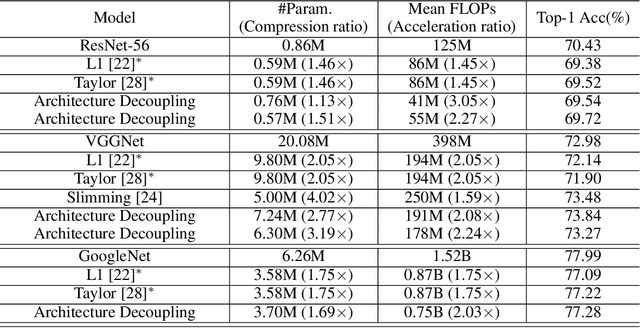
Convolutional neural networks (CNNs) have achieved a superior performance by taking advantages of the complex network architectures and huge numbers of parameters, which however become uninterpretable and challenge their full potential to practical applications. Towards better understand the rationale behind the network decisions, we propose a novel architecture decoupling method, which dynamically discovers the hierarchical path consisting of activated filters for each input image. In particular, architecture controlling module is introduced in each layer to encode the network architecture and identify the activated filters corresponding to the specific input. Then, mutual information between architecture encoding and the attribute of input image is maximized to decouple the network architecture, and subsequently disentangles the filters by limiting the outputs of filter during training. Extensive experiments show that several merits have been achieved based on the proposed architecture decoupling, i.e., interpretation, acceleration and adversarial attacking.
Unsupervised Domain-Specific Deblurring via Disentangled Representations
Mar 05, 2019
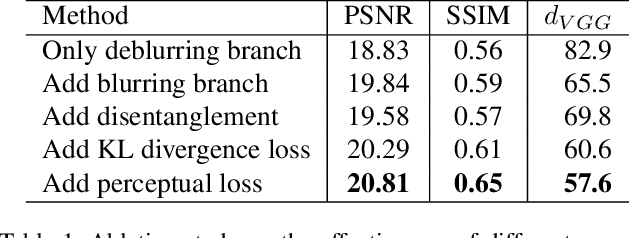
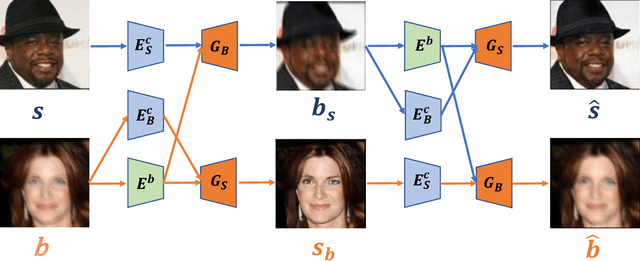
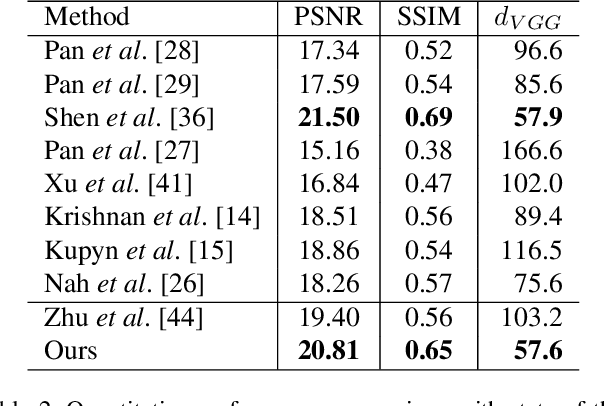
Image deblurring aims to restore the latent sharp images from the corresponding blurred ones. In this paper, we present an unsupervised method for domain-specific single-image deblurring based on disentangled representations. The disentanglement is achieved by splitting the content and blur features in a blurred image using content encoders and blur encoders. We enforce a KL divergence loss to regularize the distribution range of extracted blur attributes such that little content information is contained. Meanwhile, to handle the unpaired training data, a blurring branch and the cycle-consistency loss are added to guarantee that the content structures of the deblurred results match the original images. We also add an adversarial loss on deblurred results to generate visually realistic images and a perceptual loss to further mitigate the artifacts. We perform extensive experiments on the tasks of face and text deblurring using both synthetic datasets and real images, and achieve improved results compared to recent state-of-the-art deblurring methods.
DASGAN -- Joint Domain Adaptation and Segmentation for the Analysis of Epithelial Regions in Histopathology PD-L1 Images
Jun 26, 2019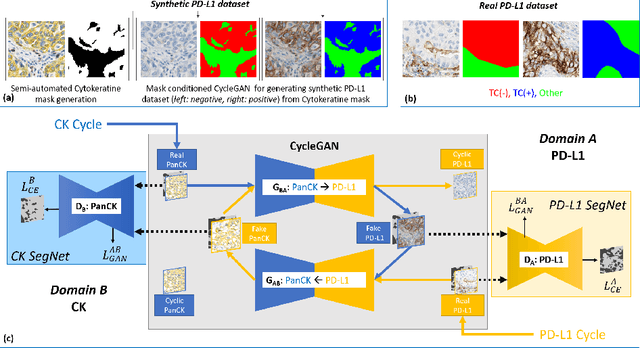

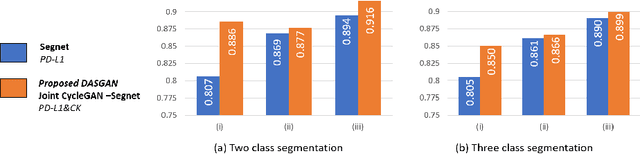
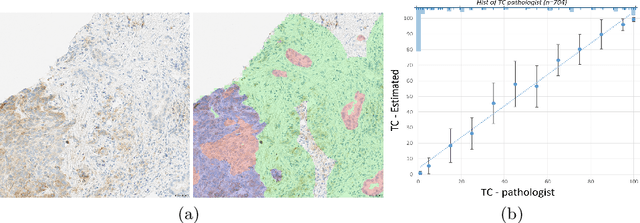
The analysis of the tumor environment on digital histopathology slides is becoming key for the understanding of the immune response against cancer, supporting the development of novel immuno-therapies. We introduce here a novel deep learning solution to the related problem of tumor epithelium segmentation. While most existing deep learning segmentation approaches are trained on time-consuming and costly manual annotation on single stain domain (PD-L1), we leverage here semi-automatically labeled images from a second stain domain (Cytokeratin-CK). We introduce an end-to-end trainable network that jointly segment tumor epithelium on PD-L1 while leveraging unpaired image-to-image translation between CK and PD-L1, therefore completely bypassing the need for serial sections or re-staining of slides. Extending the method to differentiate between PD-L1 positive and negative tumor epithelium regions enables the automated estimation of the PD-L1 Tumor Cell (TC) score. Quantitative experimental results demonstrate the accuracy of our approach against state-of-the-art segmentation methods.
To believe or not to believe: Validating explanation fidelity for dynamic malware analysis
Apr 30, 2019


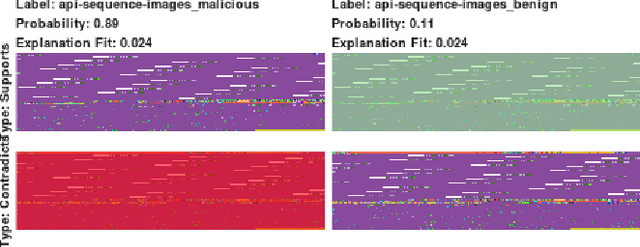
Converting malware into images followed by vision-based deep learning algorithms has shown superior threat detection efficacy compared with classical machine learning algorithms. When malware are visualized as images, visual-based interpretation schemes can also be applied to extract insights of why individual samples are classified as malicious. In this work, via two case studies of dynamic malware classification, we extend the local interpretable model-agnostic explanation algorithm to explain image-based dynamic malware classification and examine its interpretation fidelity. For both case studies, we first train deep learning models via transfer learning on malware images, demonstrate high classification effectiveness, apply an explanation method on the images, and correlate the results back to the samples to validate whether the algorithmic insights are consistent with security domain expertise. In our first case study, the interpretation framework identifies indirect calls that uniquely characterize the underlying exploit behavior of a malware family. In our second case study, the interpretation framework extracts insightful information such as cryptography-related APIs when applied on images created from API existence, but generate ambiguous interpretation on images created from API sequences and frequencies. Our findings indicate that current image-based interpretation techniques are promising for explaining vision-based malware classification. We continue to develop image-based interpretation schemes specifically for security applications.
Noisier2Noise: Learning to Denoise from Unpaired Noisy Data
Oct 25, 2019
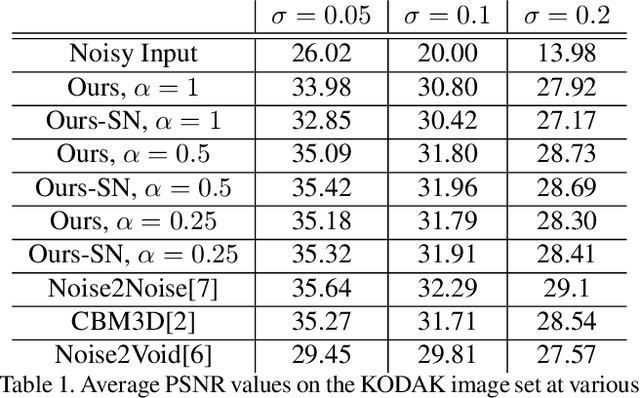


We present a method for training a neural network to perform image denoising without access to clean training examples or access to paired noisy training examples. Our method requires only a single noisy realization of each training example and a statistical model of the noise distribution, and is applicable to a wide variety of noise models, including spatially structured noise. Our model produces results which are competitive with other learned methods which require richer training data, and outperforms traditional non-learned denoising methods. We present derivations of our method for arbitrary additive noise, an improvement specific to Gaussian additive noise, and an extension to multiplicative Bernoulli noise.
Bioresorbable Scaffold Visualization in IVOCT Images Using CNNs and Weakly Supervised Localization
Oct 22, 2018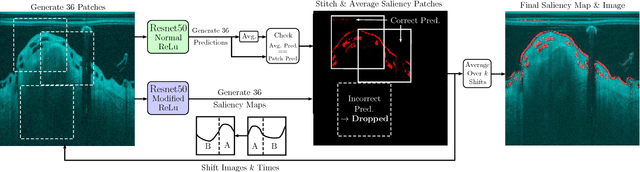

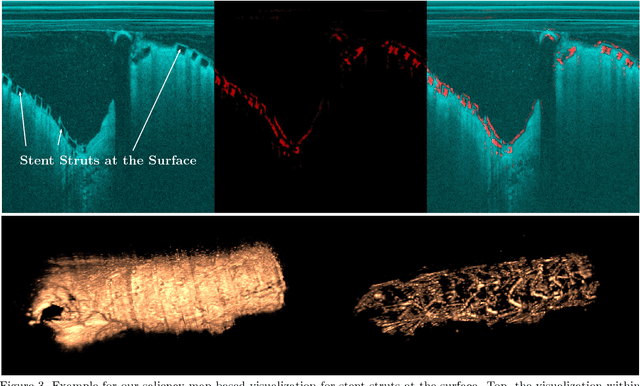
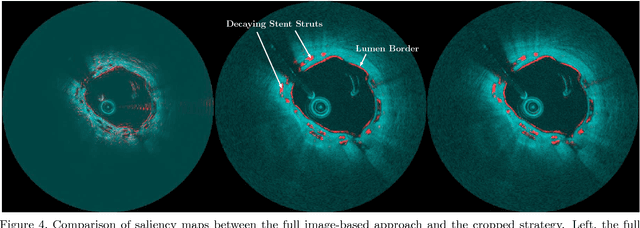
Bioresorbable scaffolds have become a popular choice for treatment of coronary heart disease, replacing traditional metal stents. Often, intravascular optical coherence tomography is used to assess potential malapposition after implantation and for follow-up examinations later on. Typically, the scaffold is manually reviewed by an expert, analyzing each of the hundreds of image slices. As this is time consuming, automatic stent detection and visualization approaches have been proposed, mostly for metal stent detection based on classic image processing. As bioresorbable scaffolds are harder to detect, recent approaches have used feature extraction and machine learning methods for automatic detection. However, these methods require detailed, pixel-level labels in each image slice and extensive feature engineering for the particular stent type which might limit the approaches' generalization capabilities. Therefore, we propose a deep learning-based method for bioresorbable scaffold visualization using only image-level labels. A convolutional neural network is trained to predict whether an image slice contains a metal stent, a bioresorbable scaffold, or no device. Then, we derive local stent strut information by employing weakly supervised localization using saliency maps with guided backpropagation. As saliency maps are generally diffuse and noisy, we propose a novel patch-based method with image shifting which allows for high resolution stent visualization. Our convolutional neural network model achieves a classification accuracy of 99.0 % for image-level stent classification which can be used for both high quality in-slice stent visualization and 3D rendering of the stent structure.