 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hierarchical Expert Networks for Meta-Learning
Nov 14, 2019
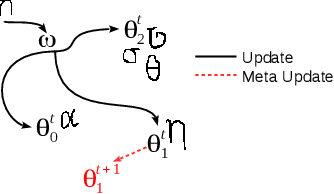

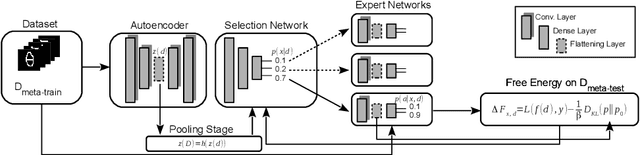
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
Detecting Vanishing Points using Global Image Context in a Non-Manhattan World
Aug 19, 2016

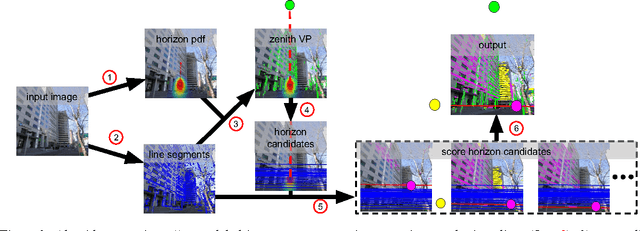
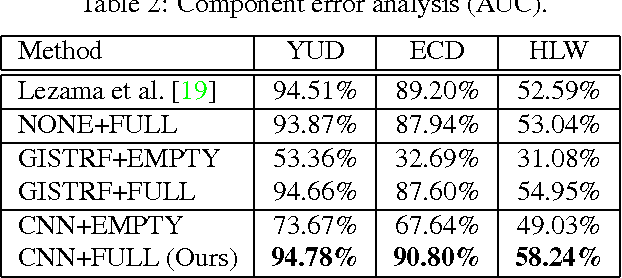
We propose a novel method for detecting horizontal vanishing points and the zenith vanishing point in man-made environments. The dominant trend in existing methods is to first find candidate vanishing points, then remove outliers by enforcing mutual orthogonality. Our method reverses this process: we propose a set of horizon line candidates and score each based on the vanishing points it contains. A key element of our approach is the use of global image context, extracted with a deep convolutional network, to constrain the set of candidates under consideration. Our method does not make a Manhattan-world assumption and can operate effectively on scenes with only a single horizontal vanishing point. We evaluate our approach on three benchmark datasets and achieve state-of-the-art performance on each. In addition, our approach is significantly faster than the previous best method.
Real-Time Style Transfer With Strength Control
Apr 18, 2019

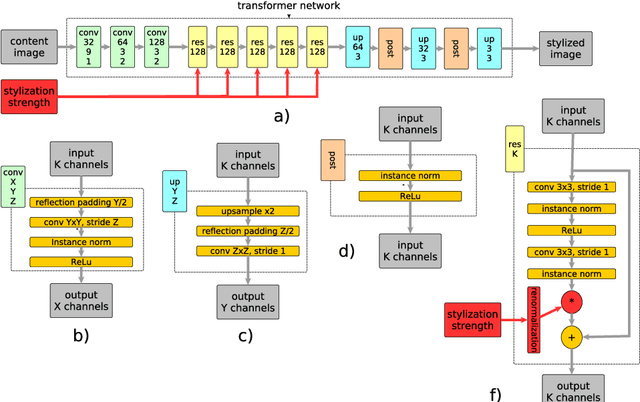

Style transfer is a problem of rendering a content image in the style of another style image. A natural and common practical task in applications of style transfer is to adjust the strength of stylization. Algorithm of Gatys et al. (2016) provides this ability by changing the weighting factors of content and style losses but is computationally inefficient. Real-time style transfer introduced by Johnson et al. (2016) enables fast stylization of any image by passing it through a pre-trained transformer network. Although fast, this architecture is not able to continuously adjust style strength. We propose an extension to real-time style transfer that allows direct control of style strength at inference, still requiring only a single transformer network. We conduct qualitative and quantitative experiments that demonstrate that the proposed method is capable of smooth stylization strength control and removes certain stylization artifacts appearing in the original real-time style transfer method. Comparisons with alternative real-time style transfer algorithms, capable of adjusting stylization strength, show that our method reproduces style with more details.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Mar 23, 2020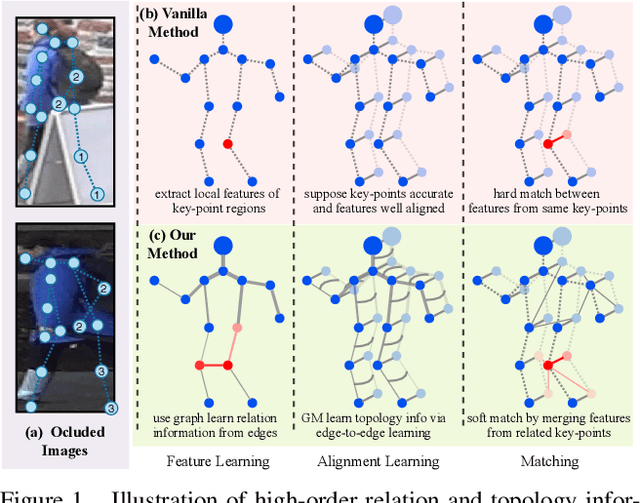
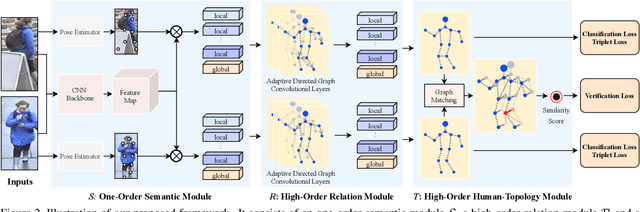
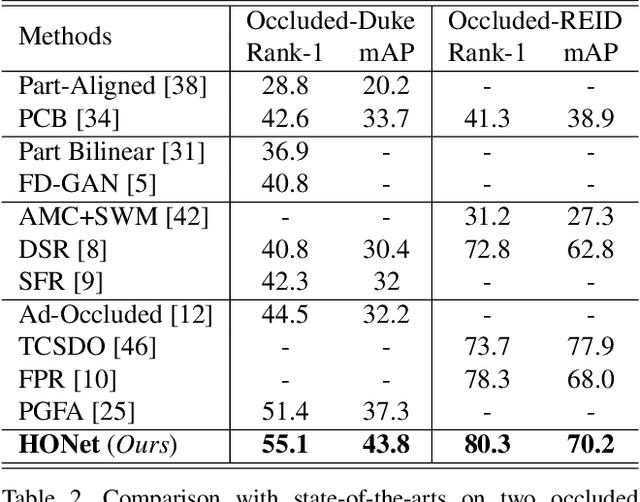
Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Finding Significant Subregions in Large Image Databases
Jun 19, 2009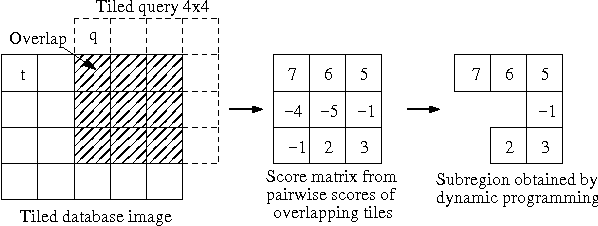

Images have become an important data source in many scientific and commercial domains. Analysis and exploration of image collections often requires the retrieval of the best subregions matching a given query. The support of such content-based retrieval requires not only the formulation of an appropriate scoring function for defining relevant subregions but also the design of new access methods that can scale to large databases. In this paper, we propose a solution to this problem of querying significant image subregions. We design a scoring scheme to measure the similarity of subregions. Our similarity measure extends to any image descriptor. All the images are tiled and each alignment of the query and a database image produces a tile score matrix. We show that the problem of finding the best connected subregion from this matrix is NP-hard and develop a dynamic programming heuristic. With this heuristic, we develop two index based scalable search strategies, TARS and SPARS, to query patterns in a large image repository. These strategies are general enough to work with other scoring schemes and heuristics. Experimental results on real image datasets show that TARS saves more than 87% query time on small queries, and SPARS saves up to 52% query time on large queries as compared to linear search. Qualitative tests on synthetic and real datasets achieve precision of more than 80%.
* 16 pages, 48 figures
Multi-Adversarial Variational Autoencoder Networks
Jun 14, 2019
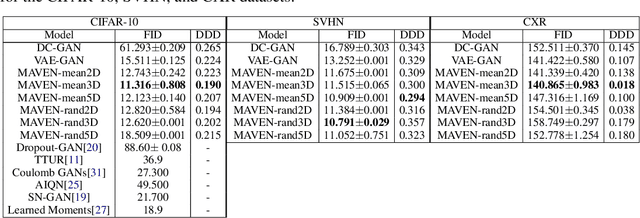
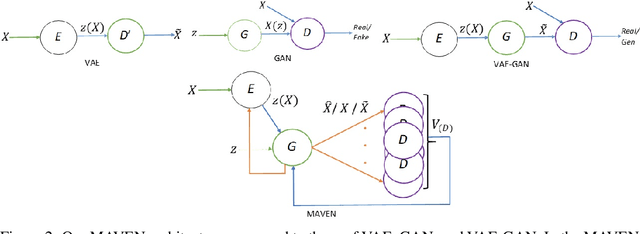
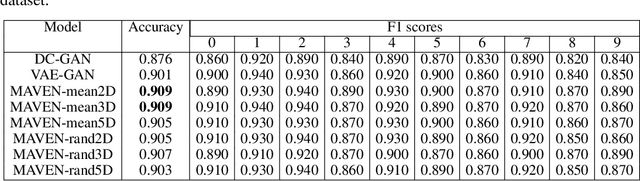
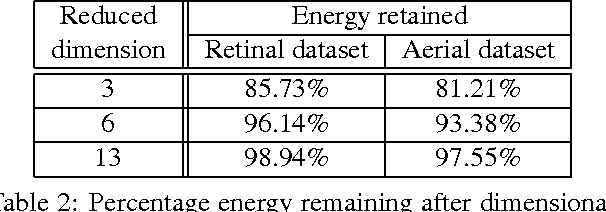
The unsupervised training of GANs and VAEs has enabled them to generate realistic images mimicking real-world distributions and perform image-based unsupervised clustering or semi-supervised classification. Combining the power of these two generative models, we introduce Multi-Adversarial Variational autoEncoder Networks (MAVENs), a novel network architecture that incorporates an ensemble of discriminators in a VAE-GAN network, with simultaneous adversarial learning and variational inference. We apply MAVENs to the generation of synthetic images and propose a new distribution measure to quantify the quality of the generated images. Our experimental results using datasets from the computer vision and medical imaging domains---Street View House Numbers, CIFAR-10, and Chest X-Ray datasets---demonstrate competitive performance against state-of-the-art semi-supervised models both in image generation and classification tasks.
An Object Detection by using Adaptive Structural Learning of Deep Belief Network
Sep 30, 2019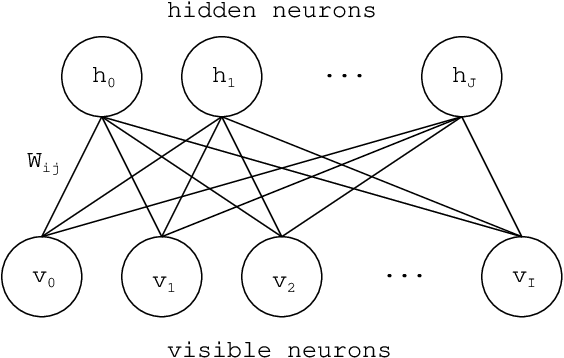
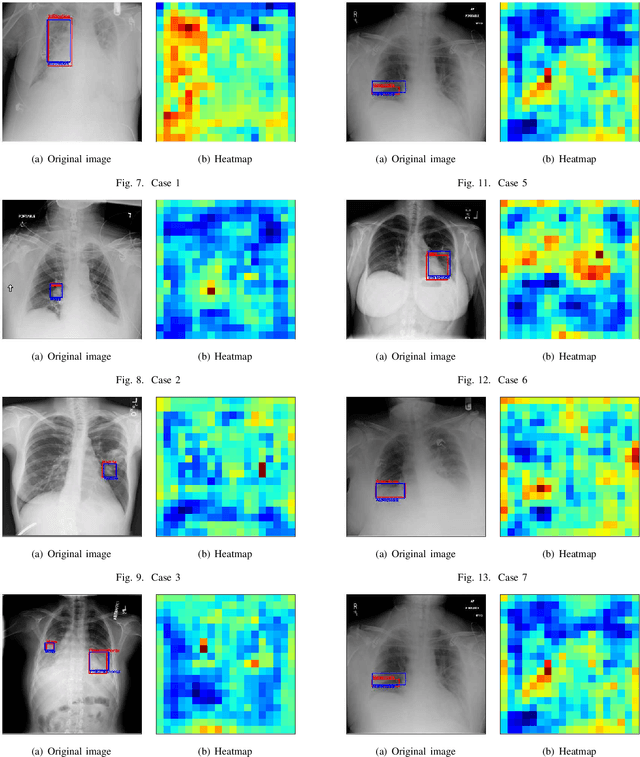
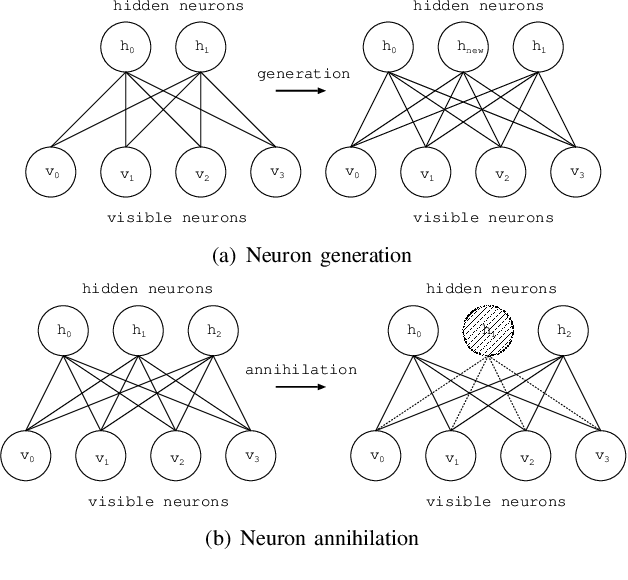
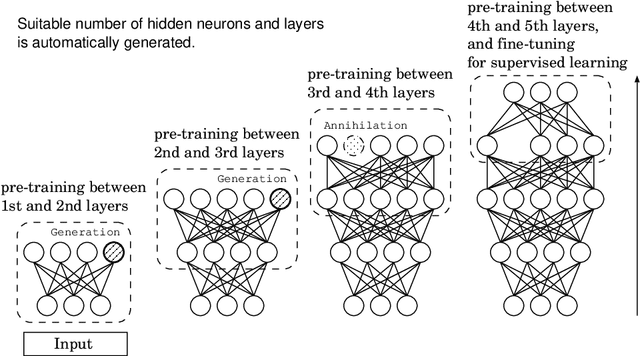
Deep learning forms a hierarchical network structure for representation of multiple input features. The adaptive structural learning method of Deep Belief Network (DBN) can realize a high classification capability while searching the optimal network structure during the training. The method can find the optimal number of hidden neurons for given input data in a Restricted Boltzmann Machine (RBM) by neuron generation-annihilation algorithm. Moreover, it can generate a new hidden layer in DBN by the layer generation algorithm to actualize a deep data representation. The proposed method showed higher classification accuracy for image benchmark data sets than several deep learning methods including well-known CNN methods. In this paper, a new object detection method for the DBN architecture is proposed for localization and category of objects. The method is a task for finding semantic objects in images as Bounding Box (B-Box). To investigate the effectiveness of the proposed method, the adaptive structural learning of DBN and the object detection were evaluated on the Chest X-ray image benchmark data set (CXR8), which is one of the most commonly accessible radio-logical examination for many lung diseases. The proposed method showed higher performance for both classification (more than 94.5% classification for test data) and localization (more than 90.4% detection for test data) than the other CNN methods.
Learned Spectral Computed Tomography
Mar 09, 2020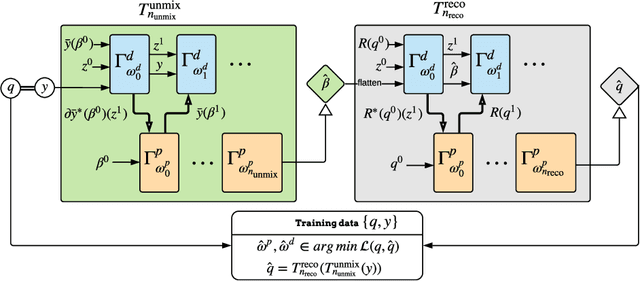
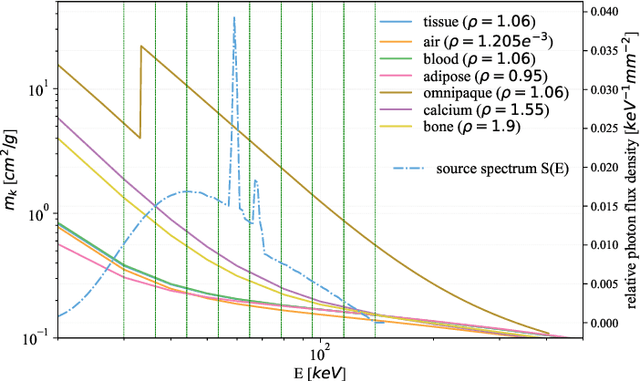

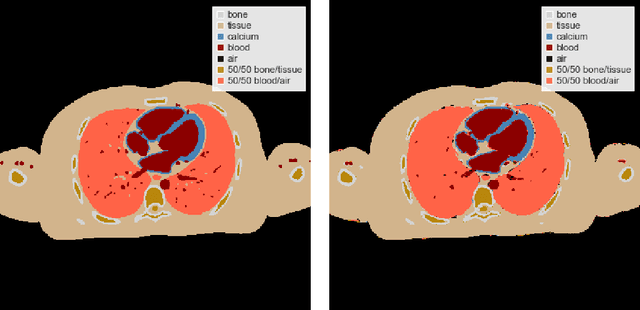
Spectral Photon-Counting Computed Tomography (SPCCT) is a promising technology that has shown a number of advantages over conventional X-ray Computed Tomography (CT) in the form of material separation, artefact removal and enhanced image quality. However, due to the increased complexity and non-linearity of the SPCCT governing equations, model-based reconstruction algorithms typically require handcrafted regularisation terms and meticulous tuning of hyperparameters making them impractical to calibrate in variable conditions. Additionally, they typically incur high computational costs and in cases of limited-angle data, their imaging capability deteriorates significantly. Recently, Deep Learning has proven to provide state-of-the-art reconstruction performance in medical imaging applications while circumventing most of these challenges. Inspired by these advances, we propose a Deep Learning imaging method for SPCCT that exploits the expressive power of Neural Networks while also incorporating model knowledge. The method takes the form of a two-step learned primal-dual algorithm that is trained using case-specific data. The proposed approach is characterised by fast reconstruction capability and high imaging performance, even in limited-data cases, while avoiding the hand-tuning that is required by other optimisation approaches. We demonstrate the performance of the method in terms of reconstructed images and quality metrics via numerical examples inspired by the application of cardiovascular imaging.
On the Texture Bias for Few-Shot CNN Segmentation
Mar 09, 2020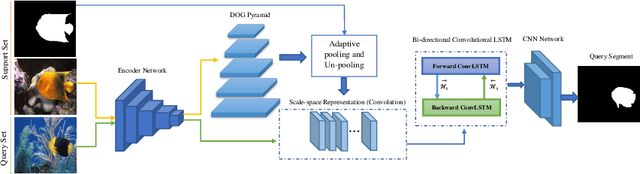


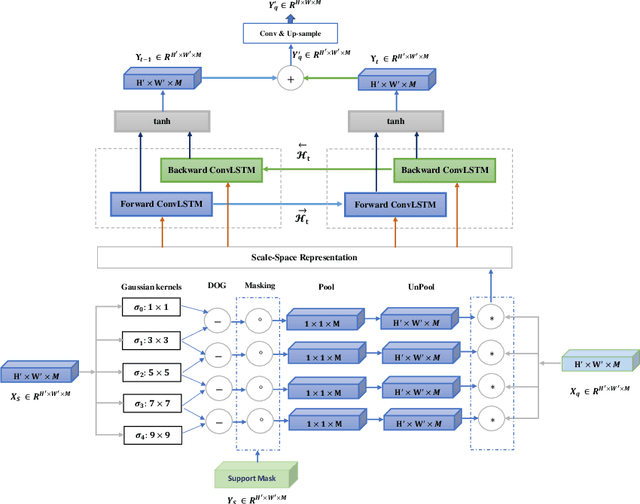
Despite the initial belief that Convolutional Neural Networks (CNNs) are driven by shapes to perform visual recognition tasks, recent evidence suggests that texture bias in CNNs provides higher performing and more robust models. This contrasts with the perceptual bias in the human visual cortex, which has a stronger preference towards shape components. Perceptual differences may explain why CNNs achieve human-level performance when large labeled datasets are available, but their performance significantly degrades in low-labeled data scenarios, such as few-shot semantic segmentation. To remove the texture bias in the context of few-shot learning, we propose a novel architecture that integrates a set of difference of Gaussians (DoG) to attenuate high-frequency local components in the feature space. This produces a set of modified feature maps, whose high-frequency components are diminished at different standard deviation values of the Gaussian distribution in the spatial domain. As this results in multiple feature maps for a single image, we employ a bi-directional convolutional long-short-term-memory to efficiently merge the multi scale-space representations. We perform extensive experiments on two well-known few-shot segmentation benchmarks -Pascal i5 and FSS-1000- and demonstrate that our method outperforms significantly state-of-the-art approaches. The code is available at: https://github.com/rezazad68/fewshot-segmentation
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
Jan 20, 2020
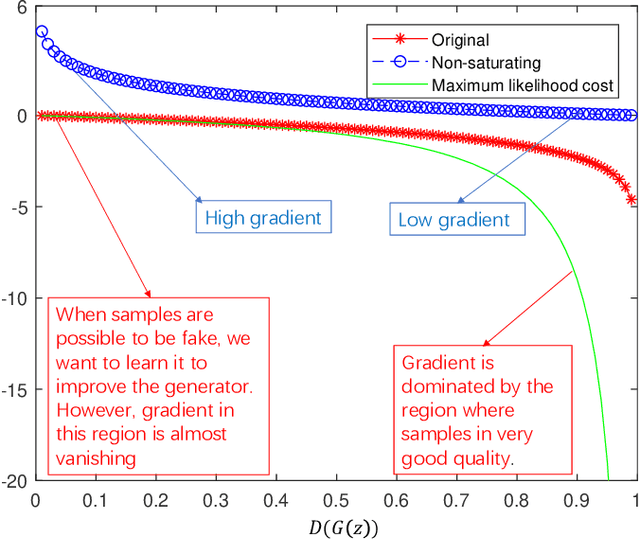

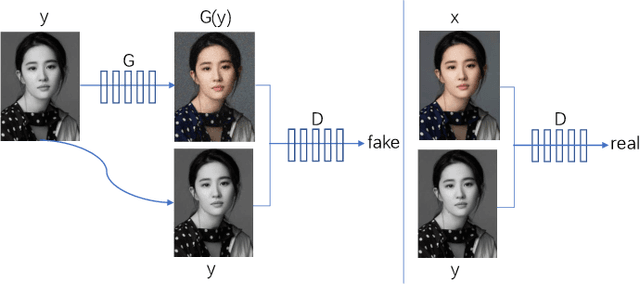
Generative adversarial networks (GANs) are a hot research topic recently. GANs have been widely studied since 2014, and a large number of algorithms have been proposed. However, there is few comprehensive study explaining the connections among different GANs variants, and how they have evolved. In this paper, we attempt to provide a review on various GANs methods from the perspectives of algorithms, theory, and applications. Firstly, the motivations, mathematical representations, and structure of most GANs algorithms are introduced in details. Furthermore, GANs have been combined with other machine learning algorithms for specific applications, such as semi-supervised learning, transfer learning, and reinforcement learning. This paper compares the commonalities and differences of these GANs methods. Secondly, theoretical issues related to GANs are investigated. Thirdly, typical applications of GANs in image processing and computer vision, natural language processing, music, speech and audio, medical field, and data science are illustrated. Finally, the future open research problems for GANs are pointed out.