 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Hybrid Camera Deblurring
Dec 20, 2023
Mobile cameras, despite their significant advancements, still face low-light challenges due to compact sensors and lenses, leading to longer exposures and motion blur. Traditional solutions like blind deconvolution and learning-based methods often fall short in handling ill-posedness of the deblurring problem. To address this, we propose a novel deblurring framework for multi-camera smartphones, utilizing a hybrid imaging technique. We simultaneously capture a long exposure wide-angle image and ultra-wide burst images from a smartphone, and use the sharp burst to estimate blur kernels for deblurring the wide-angle image. For learning and evaluation of our network, we introduce the HCBlur dataset, which includes pairs of blurry wide-angle and sharp ultra-wide burst images, and their sharp wide-angle counterparts. We extensively evaluate our method, and the result shows the state-of-the-art quality.
Radar Fields: An Extension of Radiance Fields to SAR
Dec 20, 2023Radiance fields have been a major breakthrough in the field of inverse rendering, novel view synthesis and 3D modeling of complex scenes from multi-view image collections. Since their introduction, it was shown that they could be extended to other modalities such as LiDAR, radio frequencies, X-ray or ultrasound. In this paper, we show that, despite the important difference between optical and synthetic aperture radar (SAR) image formation models, it is possible to extend radiance fields to radar images thus presenting the first "radar fields". This allows us to learn surface models using only collections of radar images, similar to how regular radiance fields are learned and with the same computational complexity on average. Thanks to similarities in how both fields are defined, this work also shows a potential for hybrid methods combining both optical and SAR images.
FedSODA: Federated Cross-assessment and Dynamic Aggregation for Histopathology Segmentation
Dec 20, 2023Federated learning (FL) for histopathology image segmentation involving multiple medical sites plays a crucial role in advancing the field of accurate disease diagnosis and treatment. However, it is still a task of great challenges due to the sample imbalance across clients and large data heterogeneity from disparate organs, variable segmentation tasks, and diverse distribution. Thus, we propose a novel FL approach for histopathology nuclei and tissue segmentation, FedSODA, via synthetic-driven cross-assessment operation (SO) and dynamic stratified-layer aggregation (DA). Our SO constructs a cross-assessment strategy to connect clients and mitigate the representation bias under sample imbalance. Our DA utilizes layer-wise interaction and dynamic aggregation to diminish heterogeneity and enhance generalization. The effectiveness of our FedSODA has been evaluated on the most extensive histopathology image segmentation dataset from 7 independent datasets. The code is available at https://github.com/yuanzhang7/FedSODA.
Fix-Con: Automatic Fault Localization and Repair of Deep Learning Model Conversions
Dec 22, 2023Converting deep learning models between frameworks is a common step to maximize model compatibility across devices and leverage optimization features that may be exclusively provided in one deep learning framework. However, this conversion process may be riddled with bugs, making the converted models either undeployable or problematic, considerably degrading their prediction correctness. We propose an automated approach for fault localization and repair, Fix-Con, during model conversion between deep learning frameworks. Fix-Con is capable of detecting and fixing faults introduced in model input, parameters, hyperparameters, and the model graph during conversion. Fix-Con uses a set of fault types mined from surveying conversion issues raised to localize potential conversion faults in the converted target model, and then repairs them appropriately, e.g. replacing the parameters of the target model with those from the source model. This is done iteratively for every image in the dataset with output label differences between the source model and the converted target model until all differences are resolved. We evaluate the effectiveness of Fix-Con in fixing model conversion bugs of three widely used image recognition models converted across four different deep learning frameworks. Overall, Fix-Con was able to either completely repair, or significantly improve the performance of 14 out of the 15 erroneous conversion cases.
RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing
Dec 21, 2023Although large-scale text-to-image generative models have shown promising performance in synthesizing high-quality images, directly applying these models to image editing remains a significant challenge. This challenge is further amplified in video editing due to the additional dimension of time. Especially for editing real videos as it necessitates maintaining a stable semantic layout across the frames while executing localized edits precisely without disrupting the existing backgrounds. In this paper, we propose RealCraft, an attention-control-based method for zero-shot editing in real videos. By employing the object-centric manipulation of cross-attention between prompts and frames and spatial-temporal attention within the frames, we achieve precise shape-wise editing along with enhanced consistency. Our model can be used directly with Stable Diffusion and operates without the need for additional localized information. We showcase our zero-shot attention-control-based method across a range of videos, demonstrating localized, high-fidelity, shape-precise and time-consistent editing in videos of various lengths, up to 64 frames.
Ponymation: Learning 3D Animal Motions from Unlabeled Online Videos
Dec 21, 2023We introduce Ponymation, a new method for learning a generative model of articulated 3D animal motions from raw, unlabeled online videos. Unlike existing approaches for motion synthesis, our model does not require any pose annotations or parametric shape models for training, and is learned purely from a collection of raw video clips obtained from the Internet. We build upon a recent work, MagicPony, which learns articulated 3D animal shapes purely from single image collections, and extend it on two fronts. First, instead of training on static images, we augment the framework with a video training pipeline that incorporates temporal regularizations, achieving more accurate and temporally consistent reconstructions. Second, we learn a generative model of the underlying articulated 3D motion sequences via a spatio-temporal transformer VAE, simply using 2D reconstruction losses without relying on any explicit pose annotations. At inference time, given a single 2D image of a new animal instance, our model reconstructs an articulated, textured 3D mesh, and generates plausible 3D animations by sampling from the learned motion latent space.
Rotational Augmented Noise2Inverse for Low-dose Computed Tomography Reconstruction
Dec 19, 2023In this work, we present a novel self-supervised method for Low Dose Computed Tomography (LDCT) reconstruction. Reducing the radiation dose to patients during a CT scan is a crucial challenge since the quality of the reconstruction highly degrades because of low photons or limited measurements. Supervised deep learning methods have shown the ability to remove noise in images but require accurate ground truth which can be obtained only by performing additional high-radiation CT scans. Therefore, we propose a novel self-supervised framework for LDCT, in which ground truth is not required for training the convolutional neural network (CNN). Based on the Noise2Inverse (N2I) method, we enforce in the training loss the equivariant property of rotation transformation, which is induced by the CT imaging system, to improve the quality of the CT image in a lower dose. Numerical and experimental results show that the reconstruction accuracy of N2I with sparse views is degrading while the proposed rotational augmented Noise2Inverse (RAN2I) method keeps better image quality over a different range of sampling angles. Finally, the quantitative results demonstrate that RAN2I achieves higher image quality compared to N2I, and experimental results of RAN2I on real projection data show comparable performance to supervised learning.
One Model to Rule them All: Towards Universal Segmentation for Medical Images with Text Prompts
Dec 28, 2023In this study, we focus on building up a model that can Segment Anything in medical scenarios, driven by Text prompts, termed as SAT. Our main contributions are three folds: (i) on data construction, we combine multiple knowledge sources to construct a multi-modal medical knowledge tree; Then we build up a large-scale segmentation dataset for training, by collecting over 11K 3D medical image scans from 31 segmentation datasets with careful standardization on both visual scans and label space; (ii) on model training, we formulate a universal segmentation model, that can be prompted by inputting medical terminologies in text form. We present a knowledge-enhanced representation learning framework, and a series of strategies for effectively training on the combination of a large number of datasets; (iii) on model evaluation, we train a SAT-Nano with only 107M parameters, to segment 31 different segmentation datasets with text prompt, resulting in 362 categories. We thoroughly evaluate the model from three aspects: averaged by body regions, averaged by classes, and average by datasets, demonstrating comparable performance to 36 specialist nnUNets, i.e., we train nnUNet models on each dataset/subset, resulting in 36 nnUNets with around 1000M parameters for the 31 datasets. We will release all the codes, and models used in this report, i.e., SAT-Nano. Moreover, we will offer SAT-Ultra in the near future, which is trained with model of larger size, on more diverse datasets. Webpage URL: https://zhaoziheng.github.io/MedUniSeg.
Replica Tree-based Federated Learning using Limited Data
Dec 28, 2023Learning from limited data has been extensively studied in machine learning, considering that deep neural networks achieve optimal performance when trained using a large amount of samples. Although various strategies have been proposed for centralized training, the topic of federated learning with small datasets remains largely unexplored. Moreover, in realistic scenarios, such as settings where medical institutions are involved, the number of participating clients is also constrained. In this work, we propose a novel federated learning framework, named RepTreeFL. At the core of the solution is the concept of a replica, where we replicate each participating client by copying its model architecture and perturbing its local data distribution. Our approach enables learning from limited data and a small number of clients by aggregating a larger number of models with diverse data distributions. Furthermore, we leverage the hierarchical structure of the client network (both original and virtual), alongside the model diversity across replicas, and introduce a diversity-based tree aggregation, where replicas are combined in a tree-like manner and the aggregation weights are dynamically updated based on the model discrepancy. We evaluated our method on two tasks and two types of data, graph generation and image classification (binary and multi-class), with both homogeneous and heterogeneous model architectures. Experimental results demonstrate the effectiveness and outperformance of RepTreeFL in settings where both data and clients are limited. Our code is available at https://github.com/basiralab/RepTreeFL.
Revisiting Single Image Reflection Removal In the Wild
Nov 29, 2023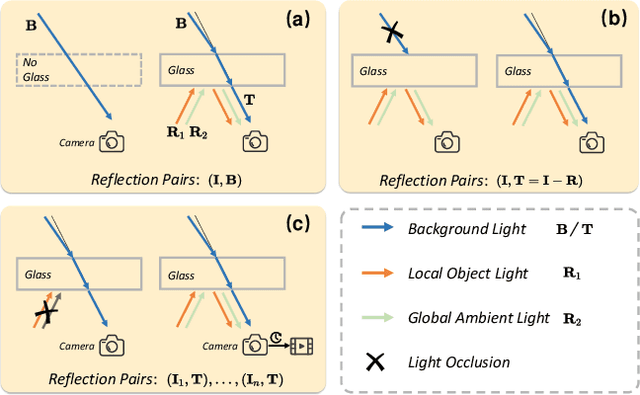
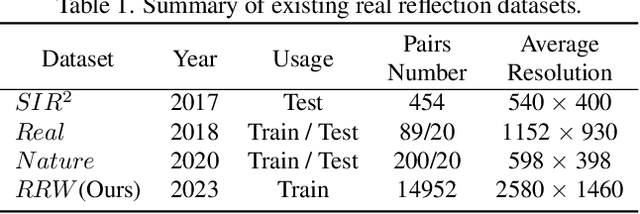

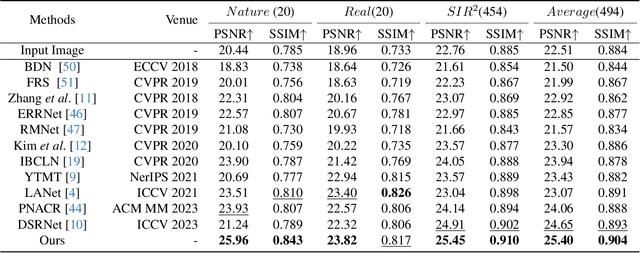
This research focuses on the issue of single-image reflection removal (SIRR) in real-world conditions, examining it from two angles: the collection pipeline of real reflection pairs and the perception of real reflection locations. We devise an advanced reflection collection pipeline that is highly adaptable to a wide range of real-world reflection scenarios and incurs reduced costs in collecting large-scale aligned reflection pairs. In the process, we develop a large-scale, high-quality reflection dataset named Reflection Removal in the Wild (RRW). RRW contains over 14,950 high-resolution real-world reflection pairs, a dataset forty-five times larger than its predecessors. Regarding perception of reflection locations, we identify that numerous virtual reflection objects visible in reflection images are not present in the corresponding ground-truth images. This observation, drawn from the aligned pairs, leads us to conceive the Maximum Reflection Filter (MaxRF). The MaxRF could accurately and explicitly characterize reflection locations from pairs of images. Building upon this, we design a reflection location-aware cascaded framework, specifically tailored for SIRR. Powered by these innovative techniques, our solution achieves superior performance than current leading methods across multiple real-world benchmarks. Codes and datasets will be publicly available.