 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep neural network models for computational histopathology: A survey
Dec 28, 2019
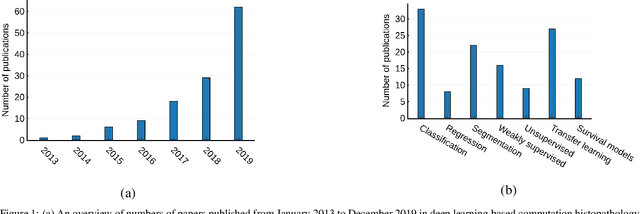
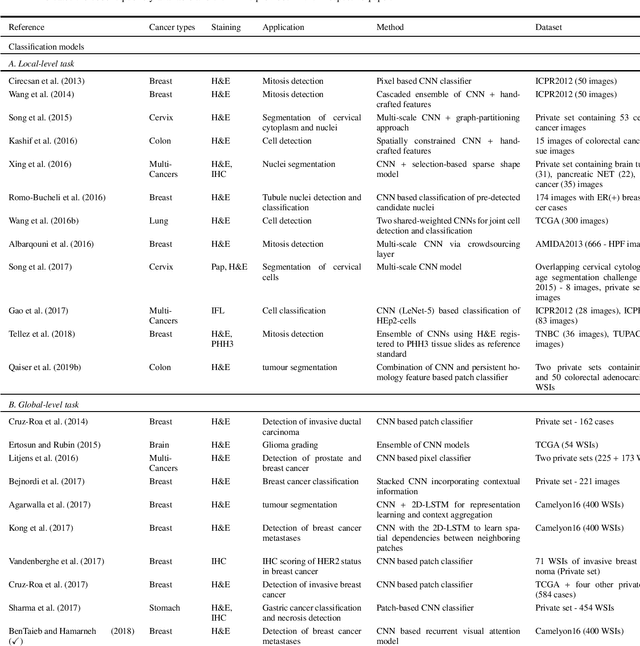
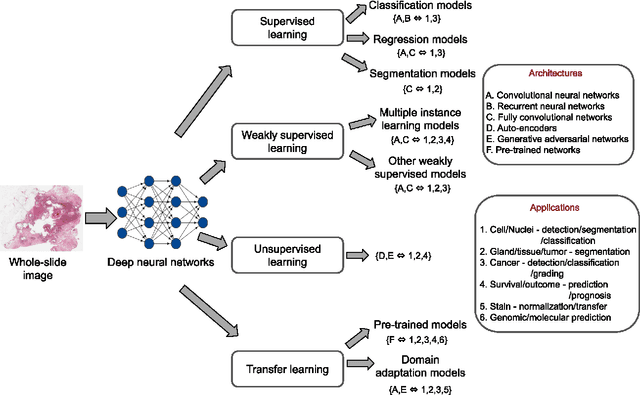
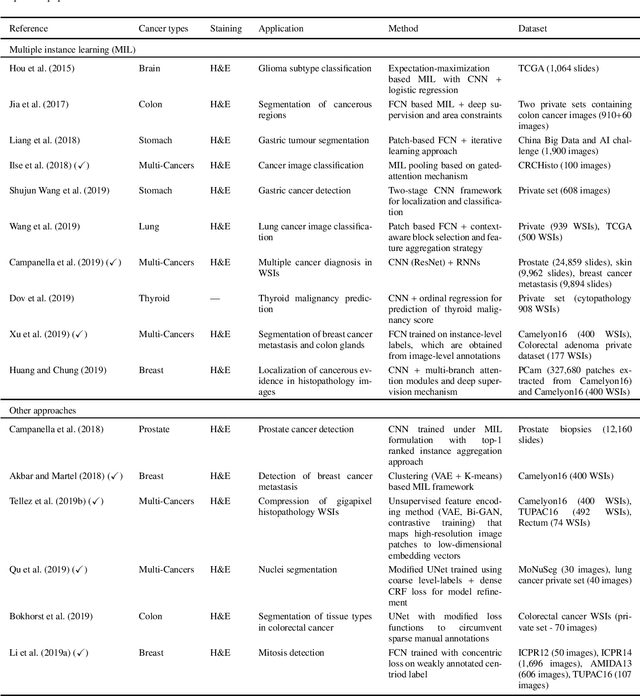
Histopathological images contain rich phenotypic information that can be used to monitor underlying mechanisms contributing to diseases progression and patient survival outcomes. Recently, deep learning has become the mainstream methodological choice for analyzing and interpreting cancer histology images. In this paper, we present a comprehensive review of state-of-the-art deep learning approaches that have been used in the context of histopathological image analysis. From the survey of over 130 papers, we review the fields progress based on the methodological aspect of different machine learning strategies such as supervised, weakly supervised, unsupervised, transfer learning and various other sub-variants of these methods. We also provide an overview of deep learning based survival models that are applicable for disease-specific prognosis tasks. Finally, we summarize several existing open datasets and highlight critical challenges and limitations with current deep learning approaches, along with possible avenues for future research.
A Deep Learning Based Fast Image Saliency Detection Algorithm
Feb 01, 2016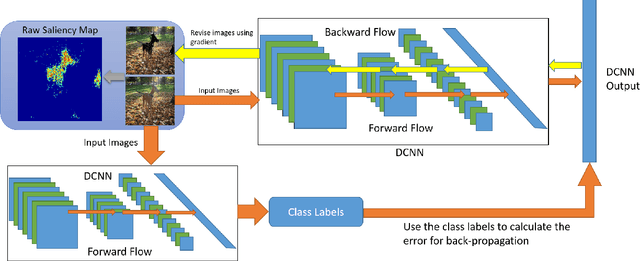

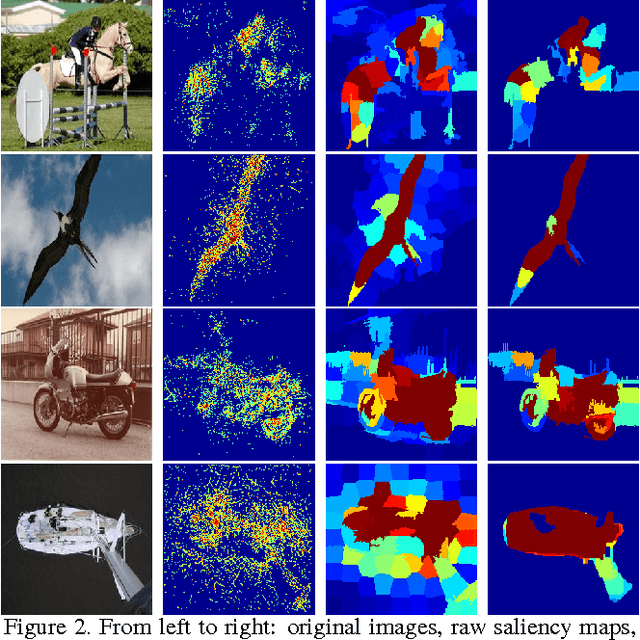

In this paper, we propose a fast deep learning method for object saliency detection using convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify the input images based on the pixel-wise gradients to reduce a pre-defined cost function, which is defined to measure the class-specific objectness and clamp the class-irrelevant outputs to maintain image background. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. We further apply SLIC superpixels and LAB color based low level saliency features to smooth and refine the gradients. Our methods are quite computationally efficient, much faster than other deep learning based saliency methods. Experimental results on two benchmark tasks, namely Pascal VOC 2012 and MSRA10k, have shown that our proposed methods can generate high-quality salience maps, at least comparable with many slow and complicated deep learning methods. Comparing with the pure low-level methods, our approach excels in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.
SoftAdapt: Techniques for Adaptive Loss Weighting of Neural Networks with Multi-Part Loss Functions
Dec 27, 2019
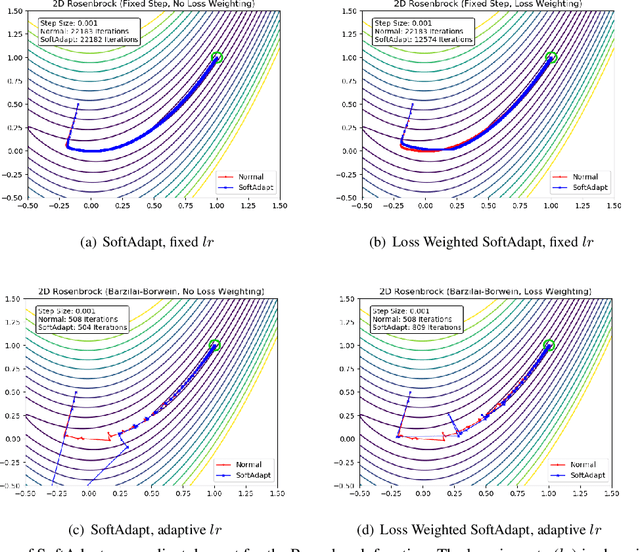


Adaptive loss function formulation is an active area of research and has gained a great deal of popularity in recent years, following the success of deep learning. However, existing frameworks of adaptive loss functions often suffer from slow convergence and poor choice of weights for the loss components. Traditionally, the elements of a multi-part loss function are weighted equally or their weights are determined through heuristic approaches that yield near-optimal (or sub-optimal) results. To address this problem, we propose a family of methods, called SoftAdapt, that dynamically change function weights for multi-part loss functions based on live performance statistics of the component losses. SoftAdapt is mathematically intuitive, computationally efficient and straightforward to implement. In this paper, we present the mathematical formulation and pseudocode for SoftAdapt, along with results from applying our methods to image reconstruction (Sparse Autoencoders) and synthetic data generation (Introspective Variational Autoencoders).
Neural Style Transfer for Point Clouds
Mar 14, 2019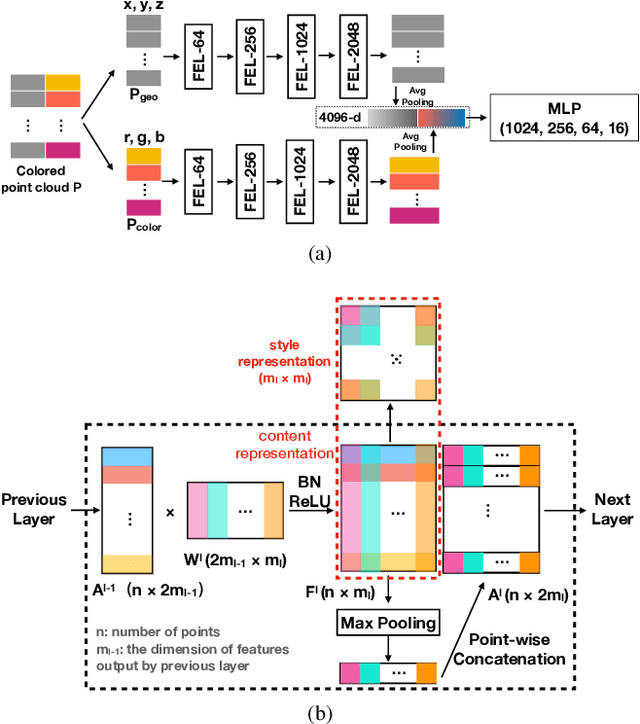
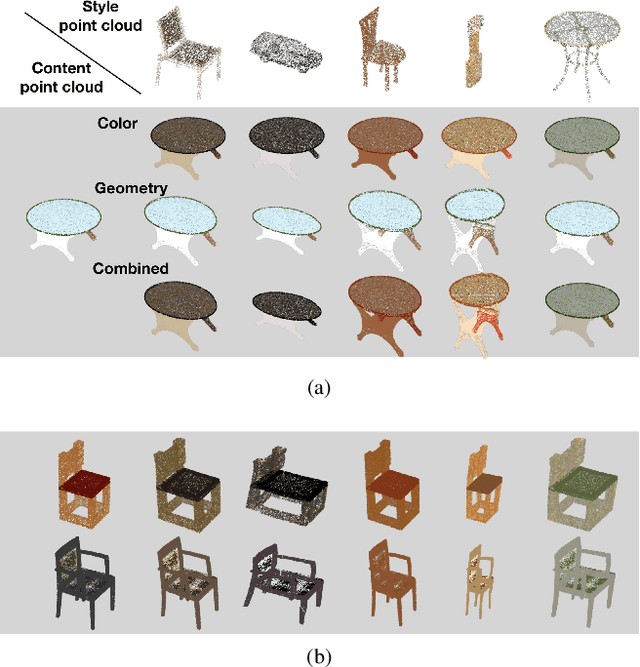
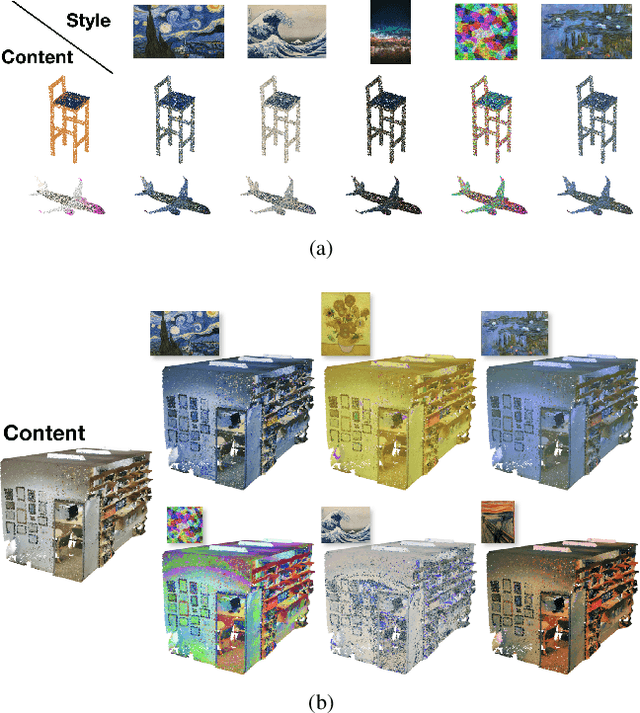
How can we edit or transform the geometric or color property of a point cloud? In this study, we propose a neural style transfer method for point clouds which allows us to transfer the style of geometry or color from one point cloud either independently or simultaneously to another. This transfer is achieved by manipulating the content representations and Gram-based style representations extracted from a pre-trained PointNet-based classification network for colored point clouds. As Gram-based style representation is invariant to the number or the order of points, the same method can be extended to transfer the style extracted from an image to the color expression of a point cloud by merely treating the image as a set of pixels. Experimental results demonstrate the capability of the proposed method for transferring style from either an image or a point cloud to another point cloud of a single object or even an indoor scene.
HA-CCN: Hierarchical Attention-based Crowd Counting Network
Jul 24, 2019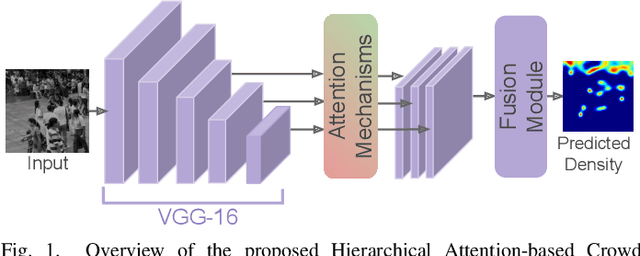
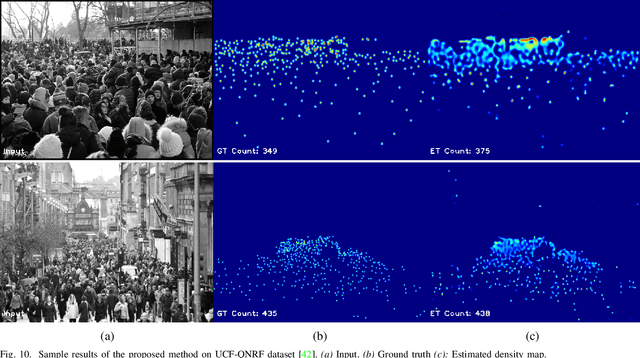

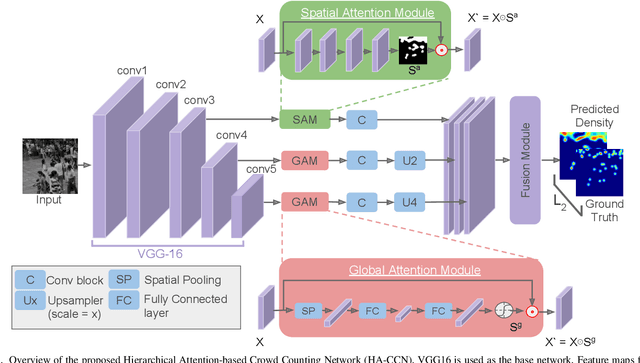
Single image-based crowd counting has recently witnessed increased focus, but many leading methods are far from optimal, especially in highly congested scenes. In this paper, we present Hierarchical Attention-based Crowd Counting Network (HA-CCN) that employs attention mechanisms at various levels to selectively enhance the features of the network. The proposed method, which is based on the VGG16 network, consists of a spatial attention module (SAM) and a set of global attention modules (GAM). SAM enhances low-level features in the network by infusing spatial segmentation information, whereas the GAM focuses on enhancing channel-wise information in the higher level layers. The proposed method is a single-step training framework, simple to implement and achieves state-of-the-art results on different datasets. Furthermore, we extend the proposed counting network by introducing a novel set-up to adapt the network to different scenes and datasets via weak supervision using image-level labels. This new set up reduces the burden of acquiring labour intensive point-wise annotations for new datasets while improving the cross-dataset performance.
Hierarchical Expert Networks for Meta-Learning
Oct 31, 2019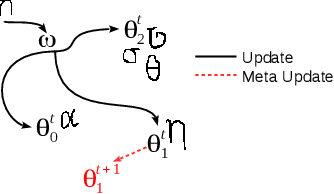

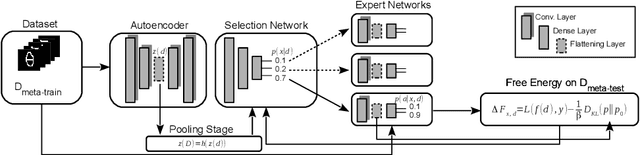
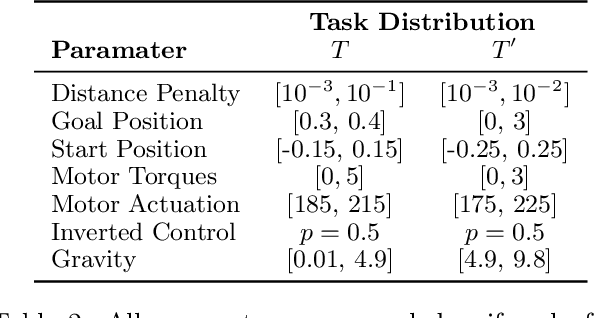
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
Scheduled Restart Momentum for Accelerated Stochastic Gradient Descent
Feb 24, 2020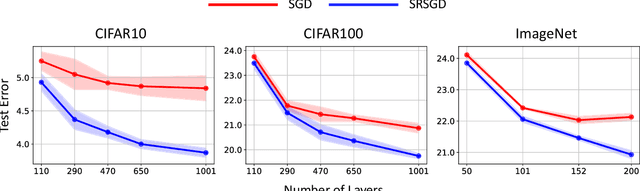

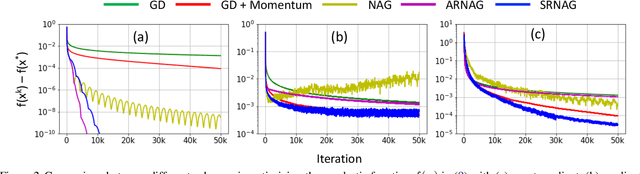
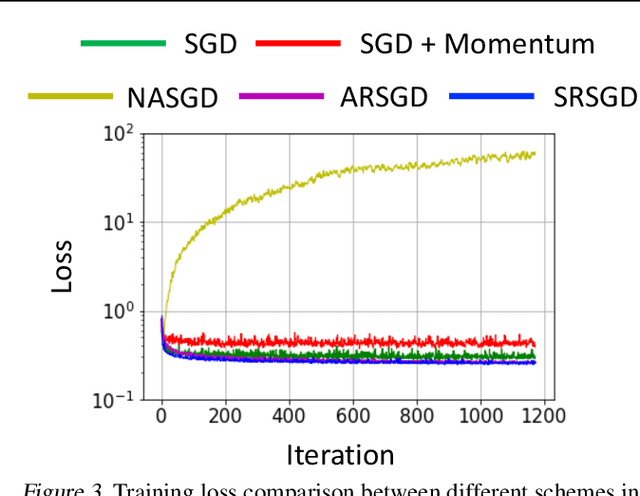
Stochastic gradient descent (SGD) with constant momentum and its variants such as Adam are the optimization algorithms of choice for training deep neural networks (DNNs). Since DNN training is incredibly computationally expensive, there is great interest in speeding up convergence. Nesterov accelerated gradient (NAG) improves the convergence rate of gradient descent (GD) for convex optimization using a specially designed momentum; however, it accumulates error when an inexact gradient is used (such as in SGD), slowing convergence at best and diverging at worst. In this paper, we propose Scheduled Restart SGD (SRSGD), a new NAG-style scheme for training DNNs. SRSGD replaces the constant momentum in SGD by the increasing momentum in NAG but stabilizes the iterations by resetting the momentum to zero according to a schedule. Using a variety of models and benchmarks for image classification, we demonstrate that, in training DNNs, SRSGD significantly improves convergence and generalization; for instance in training ResNet200 for ImageNet classification, SRSGD achieves an error rate of 20.93% vs. the benchmark of 22.13%. These improvements become more significant as the network grows deeper. Furthermore, on both CIFAR and ImageNet, SRSGD reaches similar or even better error rates with fewer training epochs compared to the SGD baseline. We provide code for SRSGD at https://github.com/minhtannguyen/SRSGD.
SpatialSense: An Adversarially Crowdsourced Benchmark for Spatial Relation Recognition
Aug 29, 2019
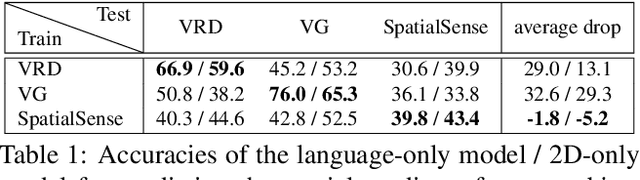
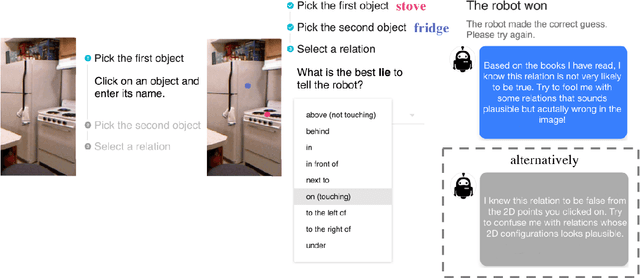
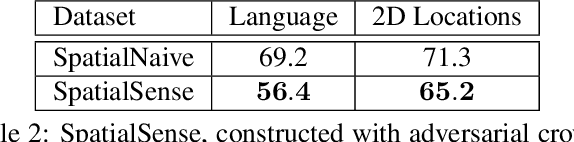
Understanding the spatial relations between objects in images is a surprisingly challenging task. A chair may be "behind" a person even if it appears to the left of the person in the image (depending on which way the person is facing). Two students that appear close to each other in the image may not in fact be "next to" each other if there is a third student between them. We introduce SpatialSense, a dataset specializing in spatial relation recognition which captures a broad spectrum of such challenges, allowing for proper benchmarking of computer vision techniques. SpatialSense is constructed through adversarial crowdsourcing, in which human annotators are tasked with finding spatial relations that are difficult to predict using simple cues such as 2D spatial configuration or language priors. Adversarial crowdsourcing significantly reduces dataset bias and samples more interesting relations in the long tail compared to existing datasets. On SpatialSense, state-of-the-art recognition models perform comparably to simple baselines, suggesting that they rely on straightforward cues instead of fully reasoning about this complex task. The SpatialSense benchmark provides a path forward to advancing the spatial reasoning capabilities of computer vision systems. The dataset and code are available at https://github.com/princeton-vl/SpatialSense.
Stage 4 validation of the Satellite Image Automatic Mapper lightweight computer program for Earth observation Level 2 product generation, Part 2 Validation
Jan 08, 2017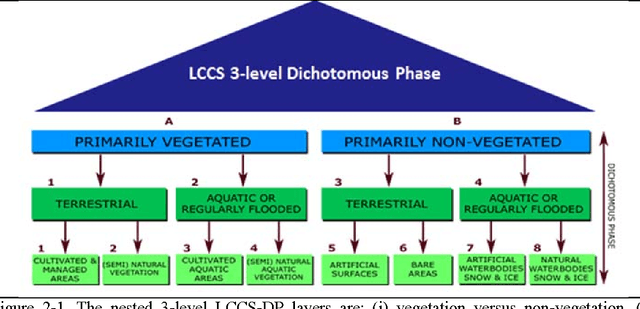
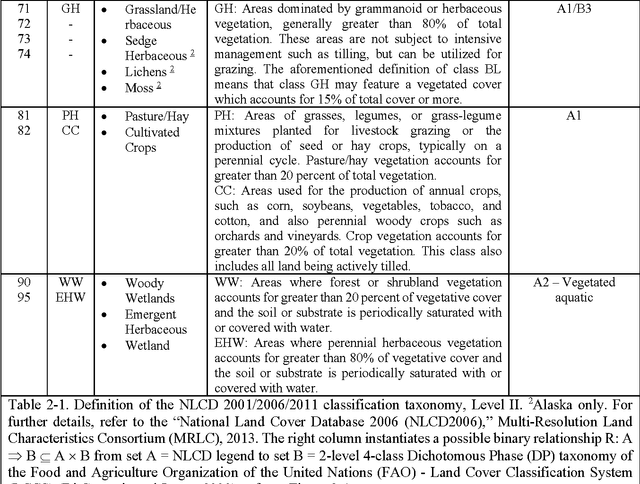
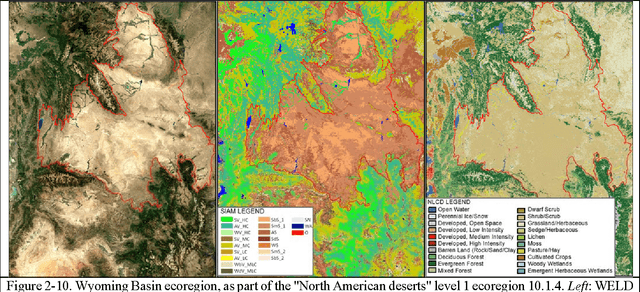
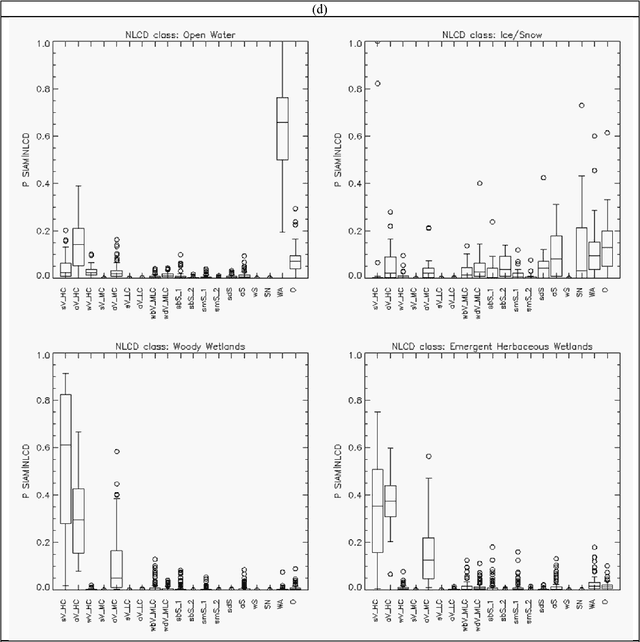
The European Space Agency (ESA) defines an Earth Observation (EO) Level 2 product as a multispectral (MS) image corrected for geometric, atmospheric, adjacency and topographic effects, stacked with its scene classification map (SCM) whose legend includes quality layers such as cloud and cloud-shadow. No ESA EO Level 2 product has ever been systematically generated at the ground segment. To contribute toward filling an information gap from EO big sensory data to the ESA EO Level 2 product, a Stage 4 validation (Val) of an off the shelf Satellite Image Automatic Mapper (SIAM) lightweight computer program for prior knowledge based MS color naming was conducted by independent means. A time-series of annual Web Enabled Landsat Data (WELD) image composites of the conterminous U.S. (CONUS) was selected as input dataset. The annual SIAM WELD maps of the CONUS were validated in comparison with the U.S. National Land Cover Data (NLCD) 2006 map. These test and reference maps share the same spatial resolution and spatial extent, but their map legends are not the same and must be harmonized. For the sake of readability this paper is split into two. The previous Part 1 Theory provided the multidisciplinary background of a priori color naming. The present Part 2 Validation presents and discusses Stage 4 Val results collected from the test SIAM WELD map time series and the reference NLCD map by an original protocol for wall to wall thematic map quality assessment without sampling, where the test and reference map legends can differ in agreement with the Part 1. Conclusions are that the SIAM-WELD maps instantiate a Level 2 SCM product whose legend is the FAO Land Cover Classification System (LCCS) taxonomy at the Dichotomous Phase (DP) Level 1 vegetation/nonvegetation, Level 2 terrestrial/aquatic or superior LCCS level.
Stage 4 validation of the Satellite Image Automatic Mapper lightweight computer program for Earth observation Level 2 product generation, Part 1 Theory
Jan 08, 2017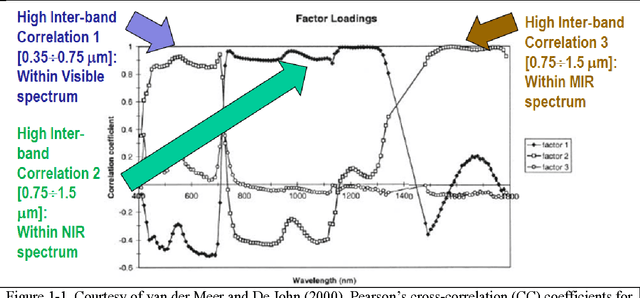
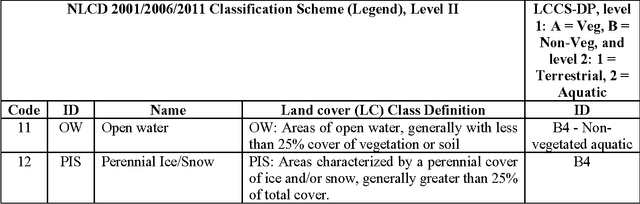
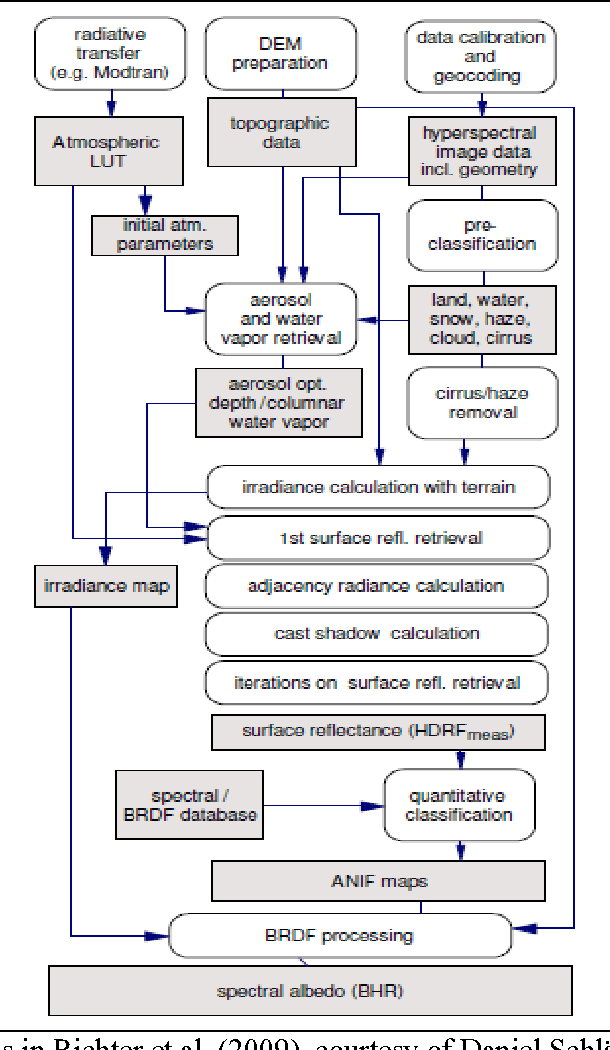
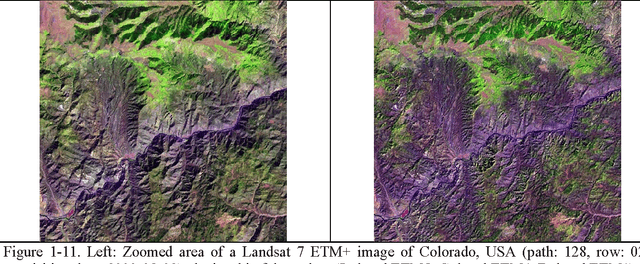
The European Space Agency (ESA) defines an Earth Observation (EO) Level 2 product as a multispectral (MS) image corrected for geometric, atmospheric, adjacency and topographic effects, stacked with its scene classification map (SCM), whose legend includes quality layers such as cloud and cloud-shadow. No ESA EO Level 2 product has ever been systematically generated at the ground segment. To contribute toward filling an information gap from EO big data to the ESA EO Level 2 product, an original Stage 4 validation (Val) of the Satellite Image Automatic Mapper (SIAM) lightweight computer program was conducted by independent means on an annual Web-Enabled Landsat Data (WELD) image composite time-series of the conterminous U.S. The core of SIAM is a one pass prior knowledge based decision tree for MS reflectance space hyperpolyhedralization into static color names presented in literature in recent years. For the sake of readability this paper is split into two. The present Part 1 Theory provides the multidisciplinary background of a priori color naming in cognitive science, from linguistics to computer vision. To cope with dictionaries of MS color names and land cover class names that do not coincide and must be harmonized, an original hybrid guideline is proposed to identify a categorical variable pair relationship. An original quantitative measure of categorical variable pair association is also proposed. The subsequent Part 2 Validation discusses Stage 4 Val results collected by an original protocol for wall-to-wall thematic map quality assessment without sampling where the test and reference map legends can differ. Conclusions are that the SIAM-WELD maps instantiate a Level 2 SCM product whose legend is the 4 class taxonomy of the FAO Land Cover Classification System at the Dichotomous Phase Level 1 vegetation/nonvegetation and Level 2 terrestrial/aquatic.