 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Fast Adaptation for Denoising via Meta-Learning
Jan 09, 2020




Under certain statistical assumptions of noise, recent self-supervised approaches for denoising have been introduced to learn network parameters without true clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet combined with conventional supervised denoising methods which train the denoising networks with a large number of external training samples. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting their network parameters to the given input through selfsupervision without changing the networks architectures. Moreover, we propose a meta-learning algorithm to enable quick adaptation of parameters to the specific input at test time. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous benchmark datasets.
ICface: Interpretable and Controllable Face Reenactment Using GANs
Apr 03, 2019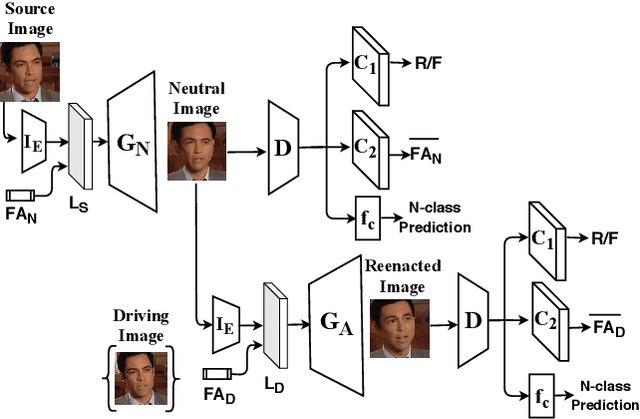



This paper presents a generic face animator that is able to control the pose and expressions of a given face image. The animation is driven by human interpretable control signals consisting of head pose angles and the Action Unit (AU) values. The control information can be obtained from multiple sources including external driving videos and manual controls. Due to the interpretable nature of the driving signal, one can easily mix the information between multiple sources (e.g. pose from one image and expression from another) and apply selective post-production editing. The proposed face animator is implemented as a two stage neural network model that is learned in self-supervised manner using a large video collection. The proposed Interpretable and Controllable face reenactment network (ICface) is compared to the state-of-the-art neural network based face animation techniques in multiple tasks. The results indicate that ICface produces better visual quality, while being more versatile than most of the comparison methods. The introduced model could provide a lightweight and easy to use tool for multitude of advanced image and video editing tasks.
A Cross-Stitch Architecture for Joint Registration and Segmentation in Adaptive Radiotherapy
Apr 17, 2020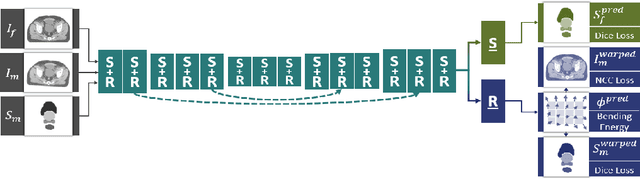
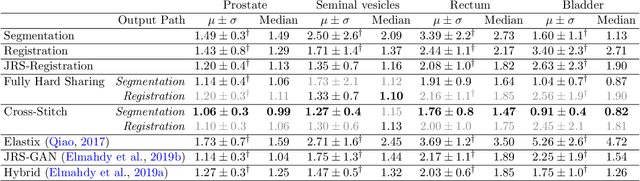
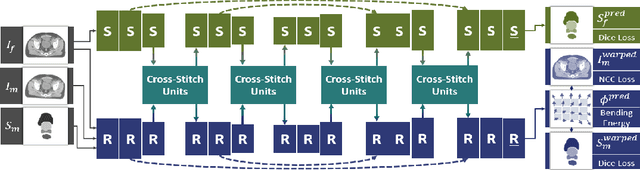
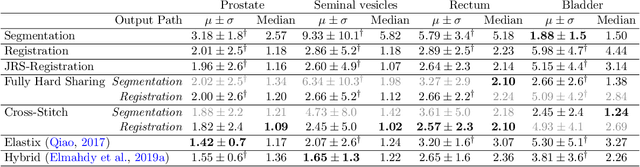
Recently, joint registration and segmentation has been formulated in a deep learning setting, by the definition of joint loss functions. In this work, we investigate joining these tasks at the architectural level. We propose a registration network that integrates segmentation propagation between images, and a segmentation network to predict the segmentation directly. These networks are connected into a single joint architecture via so-called cross-stitch units, allowing information to be exchanged between the tasks in a learnable manner. The proposed method is evaluated in the context of adaptive image-guided radiotherapy, using daily prostate CT imaging. Two datasets from different institutes and manufacturers were involved in the study. The first dataset was used for training (12 patients) and validation (6 patients), while the second dataset was used as an independent test set (14 patients). In terms of mean surface distance, our approach achieved $1.06 \pm 0.3$ mm, $0.91 \pm 0.4$ mm, $1.27 \pm 0.4$ mm, and $1.76 \pm 0.8$ mm on the validation set and $1.82 \pm 2.4$ mm, $2.45 \pm 2.4$ mm, $2.45 \pm 5.0$ mm, and $2.57 \pm 2.3$ mm on the test set for the prostate, bladder, seminal vesicles, and rectum, respectively. The proposed multi-task network outperformed single-task networks, as well as a network only joined through the loss function, thus demonstrating the capability to leverage the individual strengths of the segmentation and registration tasks. The obtained performance as well as the inference speed make this a promising candidate for daily re-contouring in adaptive radiotherapy, potentially reducing treatment-related side effects and improving quality-of-life after treatment.
A Deep Learning Based Fast Image Saliency Detection Algorithm
Feb 01, 2016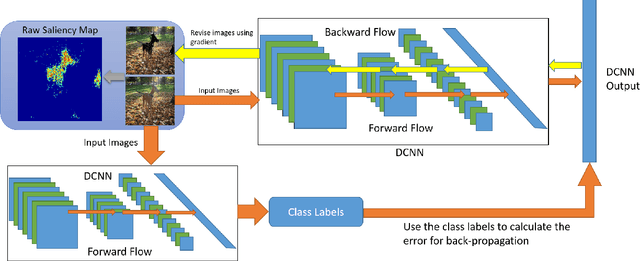

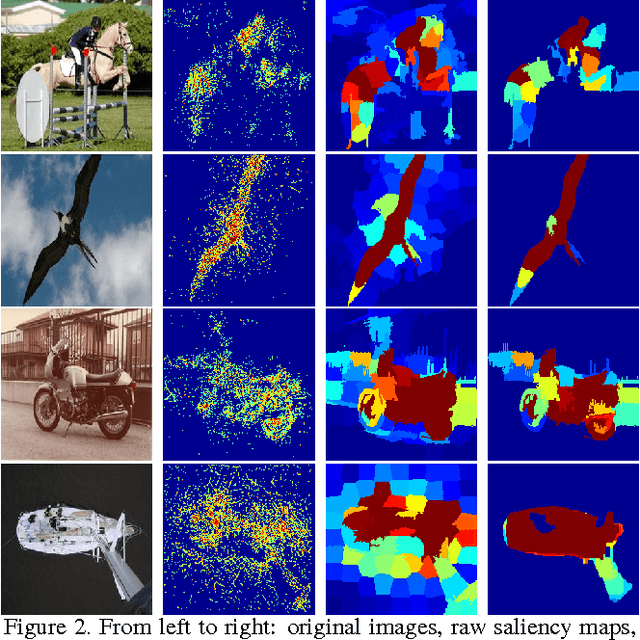

In this paper, we propose a fast deep learning method for object saliency detection using convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify the input images based on the pixel-wise gradients to reduce a pre-defined cost function, which is defined to measure the class-specific objectness and clamp the class-irrelevant outputs to maintain image background. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. We further apply SLIC superpixels and LAB color based low level saliency features to smooth and refine the gradients. Our methods are quite computationally efficient, much faster than other deep learning based saliency methods. Experimental results on two benchmark tasks, namely Pascal VOC 2012 and MSRA10k, have shown that our proposed methods can generate high-quality salience maps, at least comparable with many slow and complicated deep learning methods. Comparing with the pure low-level methods, our approach excels in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.
Orthogonal Convolutional Neural Networks
Nov 27, 2019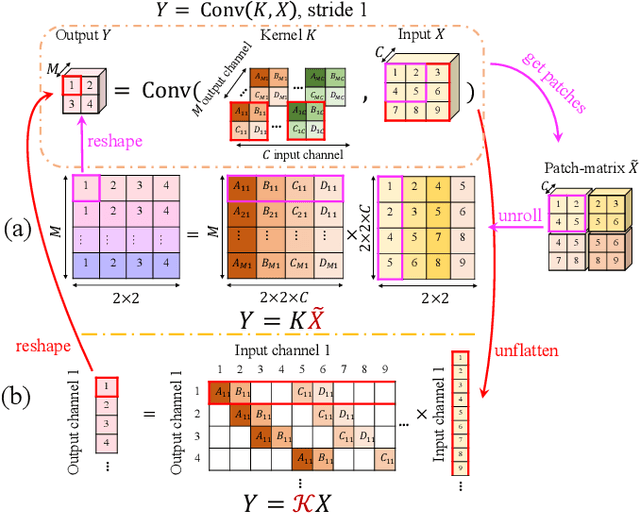
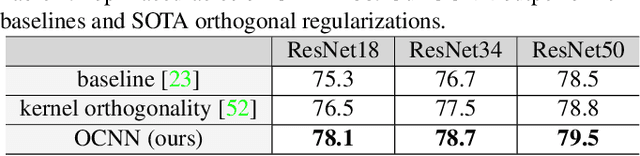
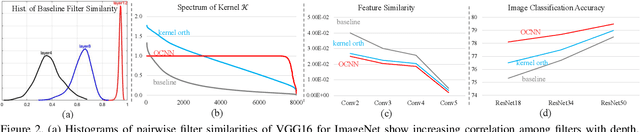

The instability and feature redundancy in CNNs hinders further performance improvement. Using orthogonality as a regularizer has shown success in alleviating these issues. Previous works however only considered the kernel orthogonality in the convolution layers of CNNs, which is a necessary but not sufficient condition for orthogonal convolutions in general. We propose orthogonal convolutions as regularizations in CNNs and benchmark its effect on various tasks. We observe up to 3% gain for CIFAR100 and up to 1% gain for ImageNet classification. Our experiments also demonstrate improved performance on image retrieval, inpainting and generation, which suggests orthogonal convolution improves the feature expressiveness. Empirically, we show that the uniform spectrum and reduced feature redundancy may account for the gain in performance and robustness under adversarial attacks.
Minimal Solvers for Rectifying from Radially-Distorted Scales and Change of Scales
Jul 25, 2019

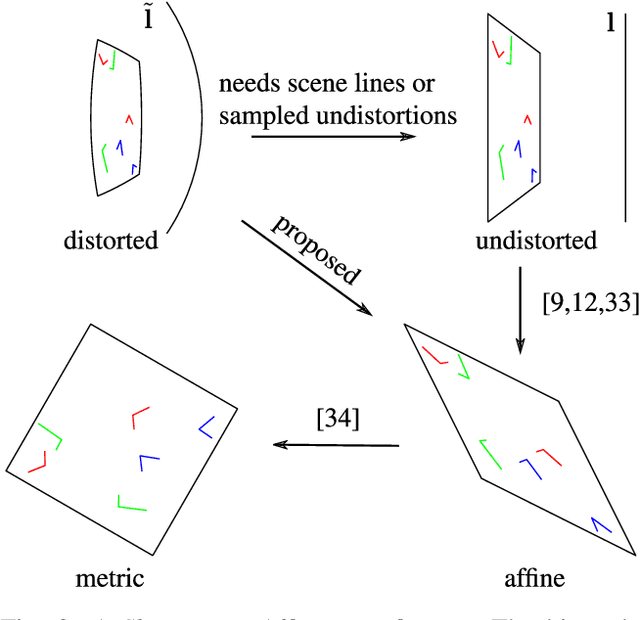

This paper introduces the first minimal solvers that jointly estimate lens distortion and affine rectification from the image of rigidly-transformed coplanar features. The solvers work on scenes without straight lines and, in general, relax strong assumptions about scene content made by the state of the art. The proposed solvers use the affine invariant that coplanar repeats have the same scale in rectified space. The solvers are separated into two groups that differ by how the equal scale invariant of rectified space is used to place constraints on the lens undistortion and rectification parameters. We demonstrate a principled approach for generating stable minimal solvers by the Gr\"obner basis method, which is accomplished by sampling feasible monomial bases to maximize numerical stability. Synthetic and real-image experiments confirm that the proposed solvers demonstrate superior robustness to noise compared to the state of the art. Accurate rectifications on imagery taken with narrow to fisheye field-of-view lenses demonstrate the wide applicability of the proposed method. The method is fully automatic.
Your GAN is Secretly an Energy-based Model and You Should use Discriminator Driven Latent Sampling
Mar 12, 2020
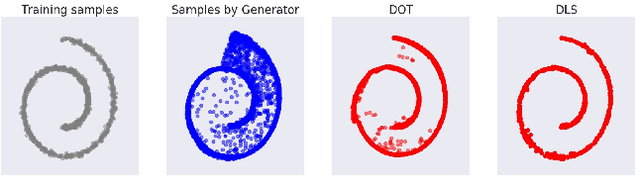
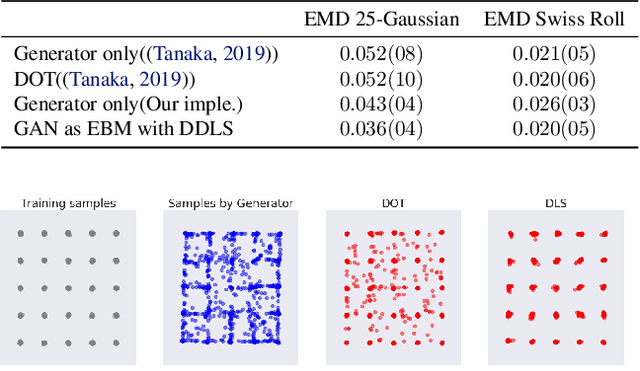

We show that the sum of the implicit generator log-density $\log p_g$ of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator (with implicit density $p_g$). To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling~(DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN~\citep{sngan} from $8.22$ to $9.09$ which is even comparable to the class-conditional BigGAN~\citep{biggan} model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.
Neural Style Transfer for Point Clouds
Mar 14, 2019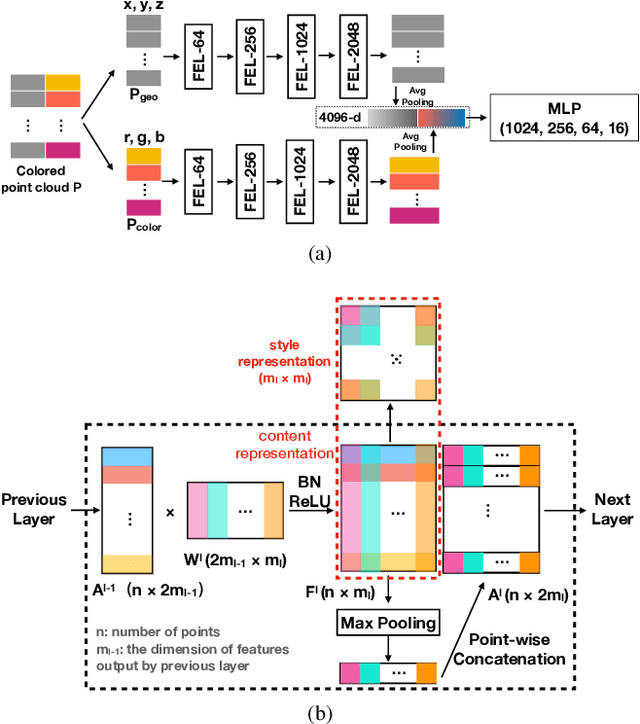
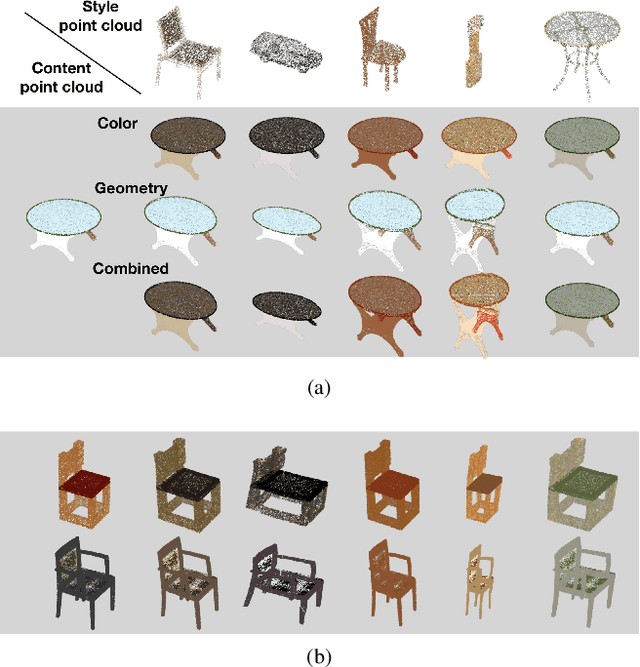
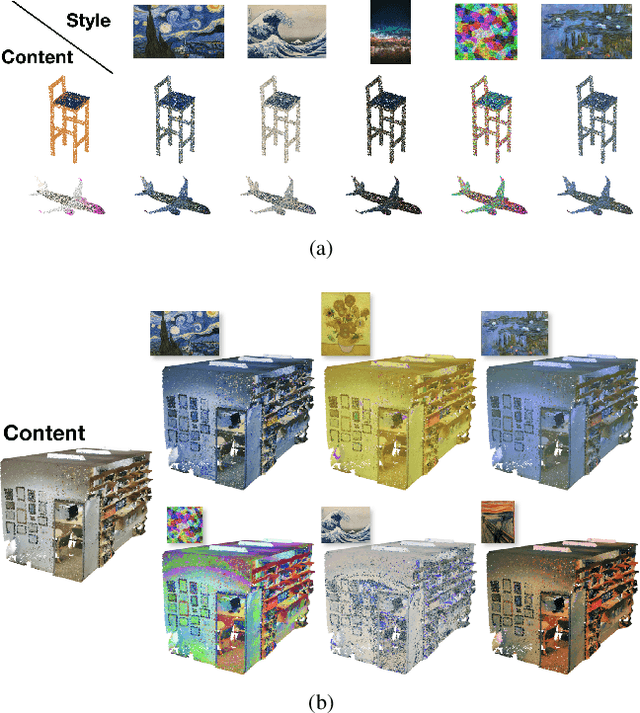
How can we edit or transform the geometric or color property of a point cloud? In this study, we propose a neural style transfer method for point clouds which allows us to transfer the style of geometry or color from one point cloud either independently or simultaneously to another. This transfer is achieved by manipulating the content representations and Gram-based style representations extracted from a pre-trained PointNet-based classification network for colored point clouds. As Gram-based style representation is invariant to the number or the order of points, the same method can be extended to transfer the style extracted from an image to the color expression of a point cloud by merely treating the image as a set of pixels. Experimental results demonstrate the capability of the proposed method for transferring style from either an image or a point cloud to another point cloud of a single object or even an indoor scene.
Towards Generalizing Sensorimotor Control Across Weather Conditions
Jul 25, 2019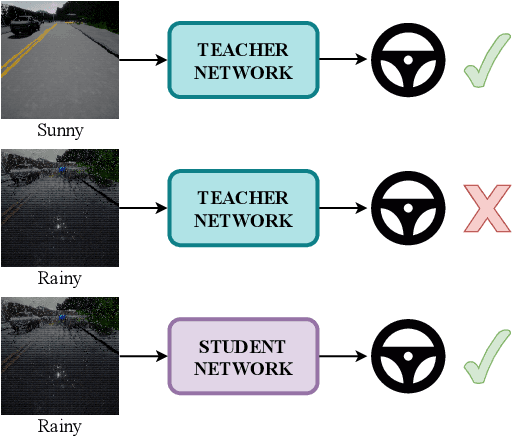
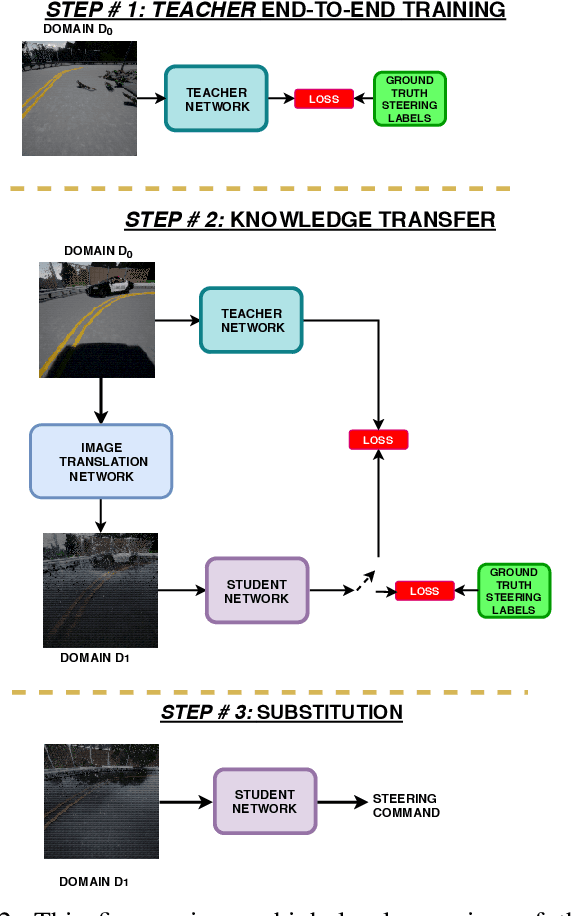
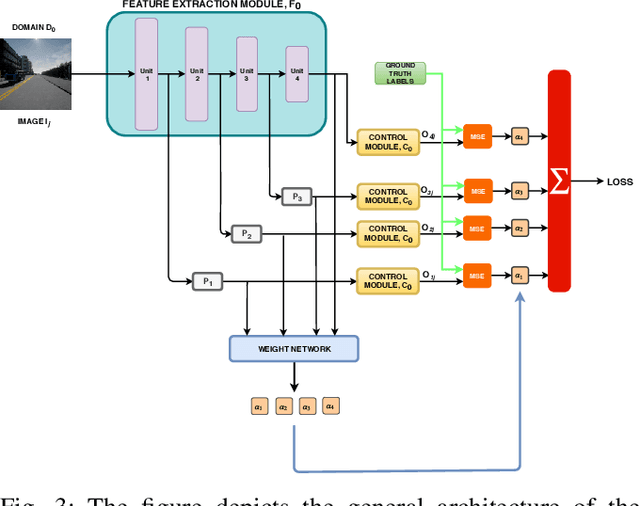
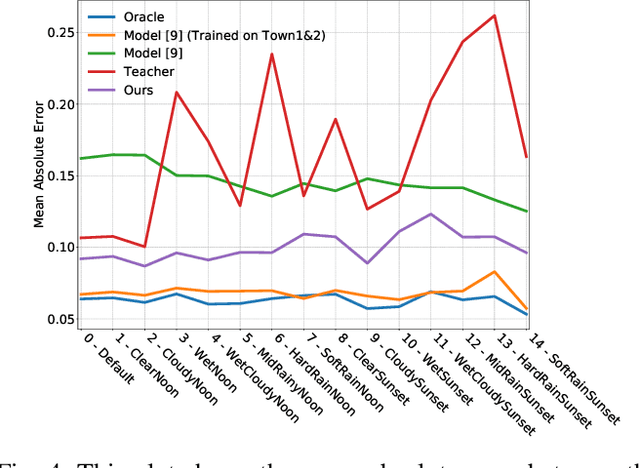
The ability of deep learning models to generalize well across different scenarios depends primarily on the quality and quantity of annotated data. Labeling large amounts of data for all possible scenarios that a model may encounter would not be feasible; if even possible. We propose a framework to deal with limited labeled training data and demonstrate it on the application of vision-based vehicle control. We show how limited steering angle data available for only one condition can be transferred to multiple different weather scenarios. This is done by leveraging unlabeled images in a teacher-student learning paradigm complemented with an image-to-image translation network. The translation network transfers the images to a new domain, whereas the teacher provides soft supervised targets to train the student on this domain. Furthermore, we demonstrate how utilization of auxiliary networks can reduce the size of a model at inference time, without affecting the accuracy. The experiments show that our approach generalizes well across multiple different weather conditions using only ground truth labels from one domain.
Detection of small changes in medical and random-dot images comparing self-organizing map performance to human detection
Jun 26, 2019
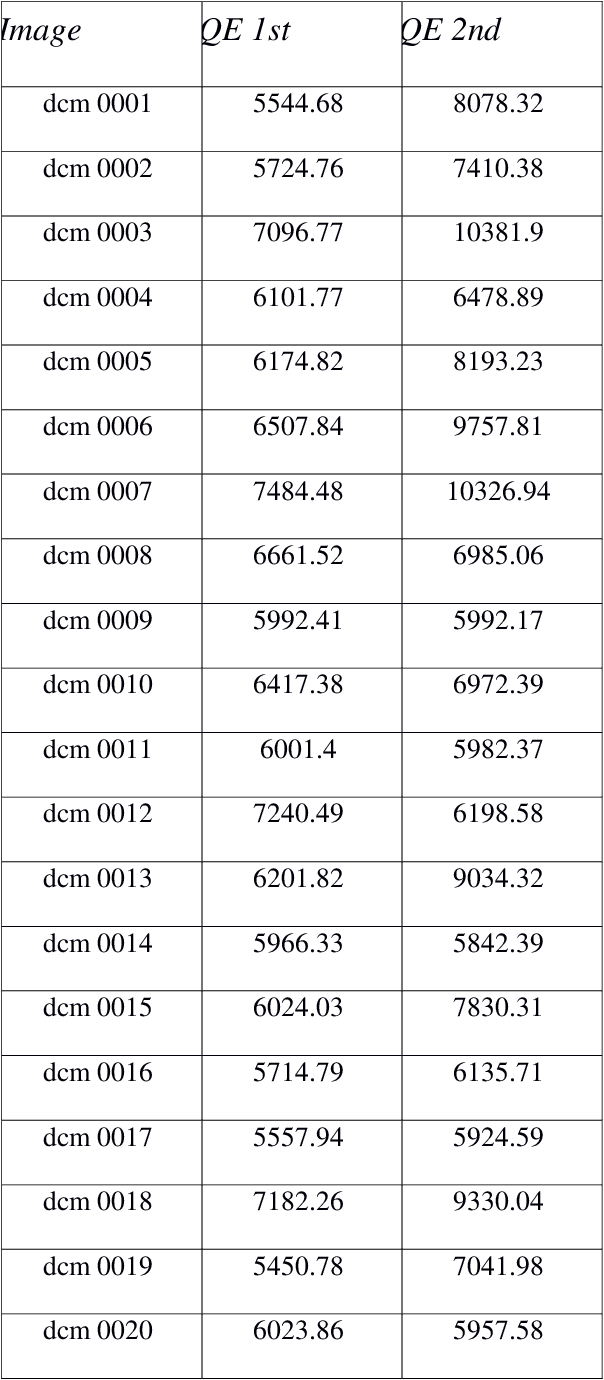
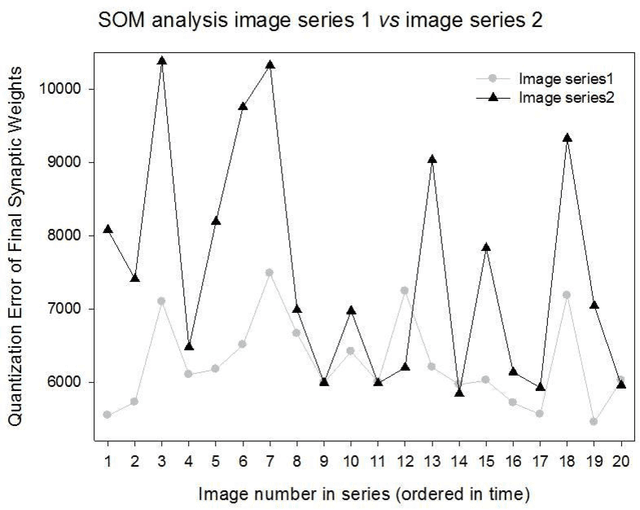
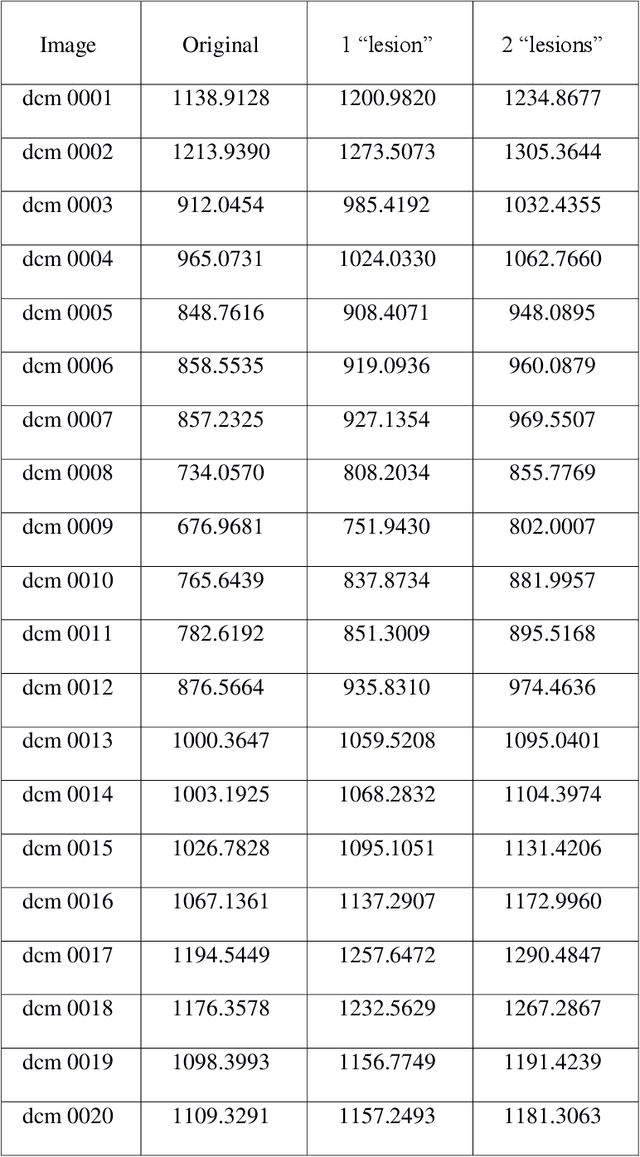
Radiologists use time series of medical images to monitor the progression of a patient condition. They compare information gleaned from sequences of images to gain insight on progression or remission of the lesions, thus evaluating the progress of a patient condition or response to therapy. Visual methods of determining differences between one series of images to another can be subjective or fail to detect very small differences. We propose the use of quantization errors obtained from Self Organizing Maps for image content analysis. We tested this technique with MRI images to which we progressively added synthetic lesions. We have used a global approach that considers changes on the entire image as opposed to changes in segmented lesion regions only. We claim that this approach does not suffer from the limitations imposed by segmentation, which may compromise the results. Results show quantization errors increased with the increase in lesions on the images. The results are also consistent with previous studies using alternative approaches. We then compared the detectability ability of our method to that of human novice observers having to detect very small local differences in random-dot images. The quantization errors of the SOM outputs compared with correct positive rates, after subtraction of false positive rates (guess rates), increased noticeably and consistently with small increases in local dot size that were not detectable by humans. We conclude that our method detects very small changes in complex images and suggest that it could be implemented to assist human operators in image based decision making.
* arXiv admin note: substantial text overlap with arXiv:1709.02292