 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scalable and Practical Natural Gradient for Large-Scale Deep Learning
Feb 13, 2020
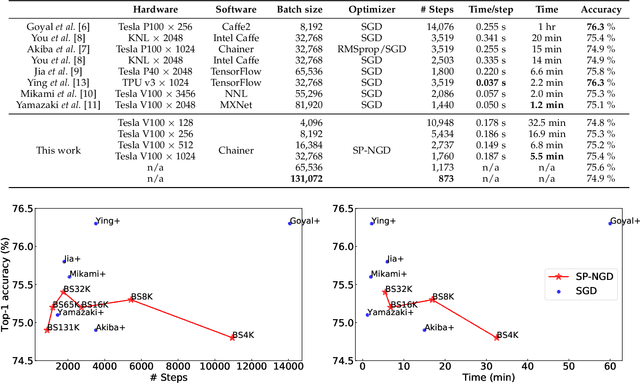
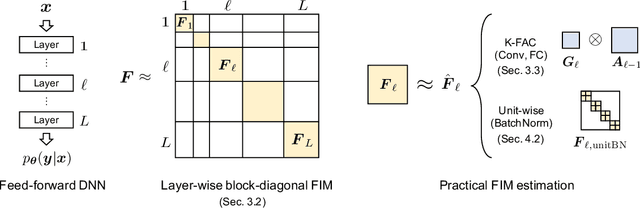

Large-scale distributed training of deep neural networks results in models with worse generalization performance as a result of the increase in the effective mini-batch size. Previous approaches attempt to address this problem by varying the learning rate and batch size over epochs and layers, or ad hoc modifications of batch normalization. We propose Scalable and Practical Natural Gradient Descent (SP-NGD), a principled approach for training models that allows them to attain similar generalization performance to models trained with first-order optimization methods, but with accelerated convergence. Furthermore, SP-NGD scales to large mini-batch sizes with a negligible computational overhead as compared to first-order methods. We evaluated SP-NGD on a benchmark task where highly optimized first-order methods are available as references: training a ResNet-50 model for image classification on ImageNet. We demonstrate convergence to a top-1 validation accuracy of 75.4% in 5.5 minutes using a mini-batch size of 32,768 with 1,024 GPUs, as well as an accuracy of 74.9% with an extremely large mini-batch size of 131,072 in 873 steps of SP-NGD.
Robust Image Descriptors for Real-Time Inter-Examination Retargeting in Gastrointestinal Endoscopy
Oct 30, 2016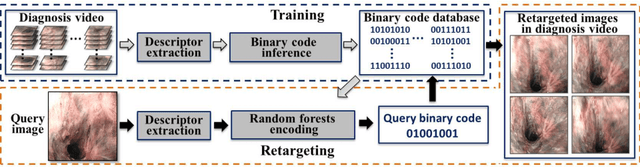

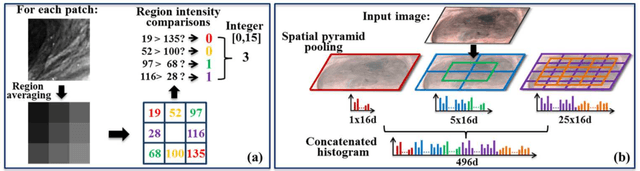
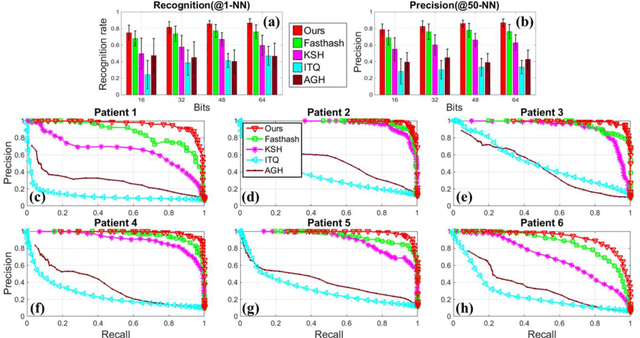
For early diagnosis of malignancies in the gastrointestinal tract, surveillance endoscopy is increasingly used to monitor abnormal tissue changes in serial examinations of the same patient. Despite successes with optical biopsy for in vivo and in situ tissue characterisation, biopsy retargeting for serial examinations is challenging because tissue may change in appearance between examinations. In this paper, we propose an inter-examination retargeting framework for optical biopsy, based on an image descriptor designed for matching between endoscopic scenes over significant time intervals. Each scene is described by a hierarchy of regional intensity comparisons at various scales, offering tolerance to long-term change in tissue appearance whilst remaining discriminative. Binary coding is then used to compress the descriptor via a novel random forests approach, providing fast comparisons in Hamming space and real-time retargeting. Extensive validation conducted on 13 in vivo gastrointestinal videos, collected from six patients, show that our approach outperforms state-of-the-art methods.
ClearGrasp: 3D Shape Estimation of Transparent Objects for Manipulation
Oct 06, 2019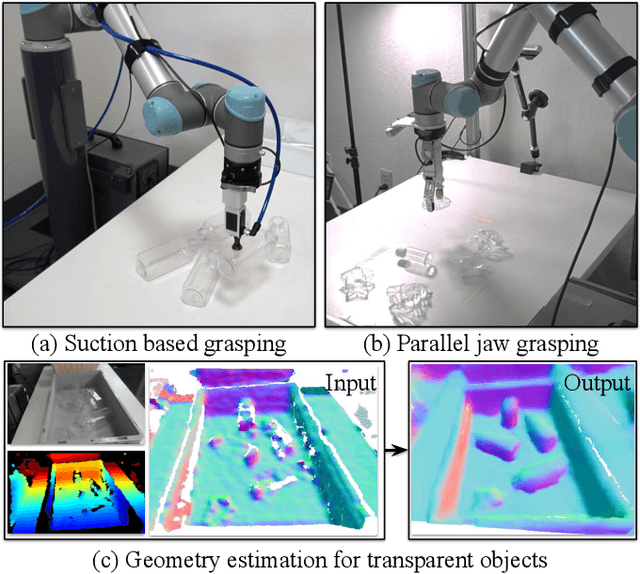

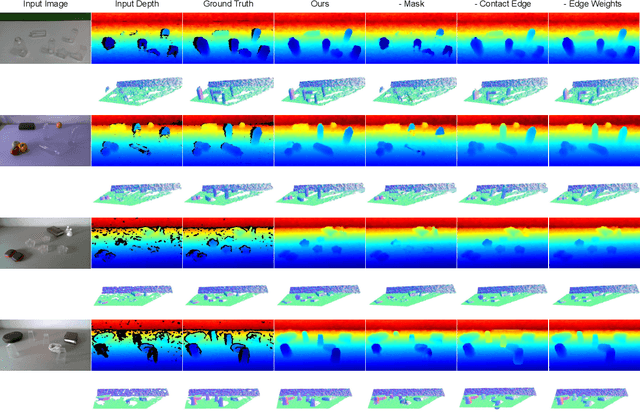
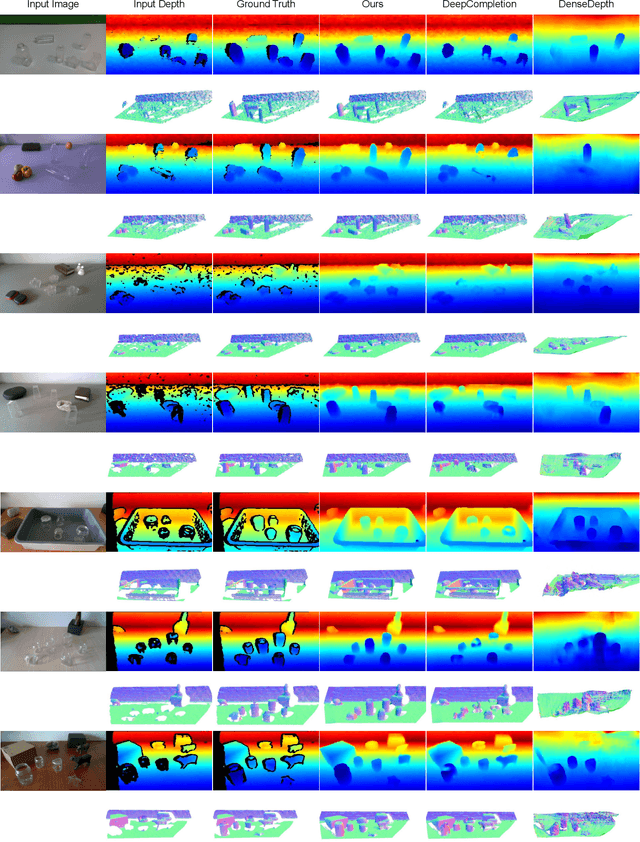
Transparent objects are a common part of everyday life, yet they possess unique visual properties that make them incredibly difficult for standard 3D sensors to produce accurate depth estimates for. In many cases, they often appear as noisy or distorted approximations of the surfaces that lie behind them. To address these challenges, we present ClearGrasp -- a deep learning approach for estimating accurate 3D geometry of transparent objects from a single RGB-D image for robotic manipulation. Given a single RGB-D image of transparent objects, ClearGrasp uses deep convolutional networks to infer surface normals, masks of transparent surfaces, and occlusion boundaries. It then uses these outputs to refine the initial depth estimates for all transparent surfaces in the scene. To train and test ClearGrasp, we construct a large-scale synthetic dataset of over 50,000 RGB-D images, as well as a real-world test benchmark with 286 RGB-D images of transparent objects and their ground truth geometries. The experiments demonstrate that ClearGrasp is substantially better than monocular depth estimation baselines and is capable of generalizing to real-world images and novel objects. We also demonstrate that ClearGrasp can be applied out-of-the-box to improve grasping algorithms' performance on transparent objects. Code, data, and benchmarks will be released. Supplementary materials available on the project website: $\href{https://sites.google.com/view/cleargrasp}{sites.google.com/view/cleargrasp}$
Joint Face Completion and Super-resolution using Multi-scale Feature Relation Learning
Feb 29, 2020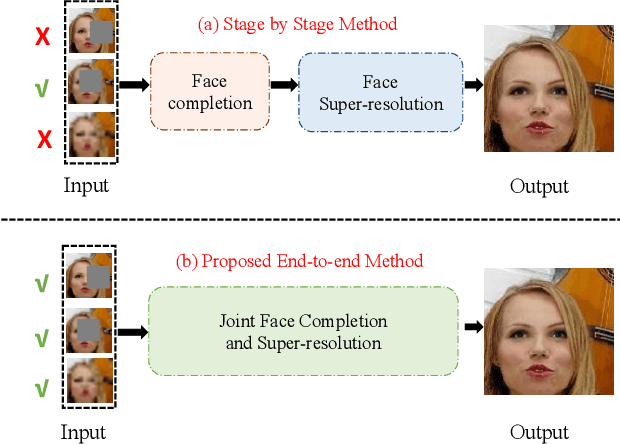
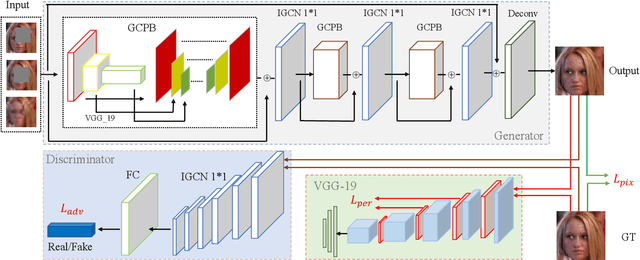
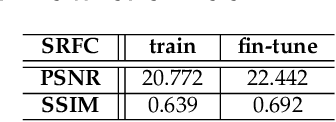
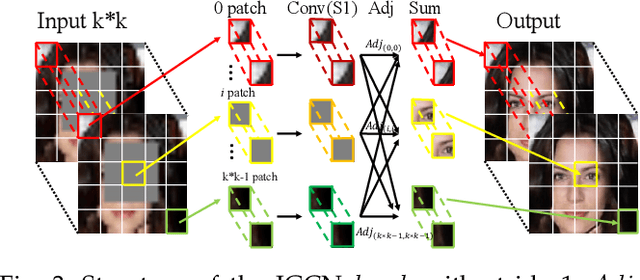
Previous research on face restoration often focused on repairing a specific type of low-quality facial images such as low-resolution (LR) or occluded facial images. However, in the real world, both the above-mentioned forms of image degradation often coexist. Therefore, it is important to design a model that can repair LR occluded images simultaneously. This paper proposes a multi-scale feature graph generative adversarial network (MFG-GAN) to implement the face restoration of images in which both degradation modes coexist, and also to repair images with a single type of degradation. Based on the GAN, the MFG-GAN integrates the graph convolution and feature pyramid network to restore occluded low-resolution face images to non-occluded high-resolution face images. The MFG-GAN uses a set of customized losses to ensure that high-quality images are generated. In addition, we designed the network in an end-to-end format. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms state-of-the-art methods in performing face super-resolution (up to 4x or 8x) and face completion simultaneously. Cross-database testing also revealed that the proposed approach has good generalizability.
Design and implementation of image processing system for Lumen social robot-humanoid as an exhibition guide for Electrical Engineering Days 2015
Jul 16, 2016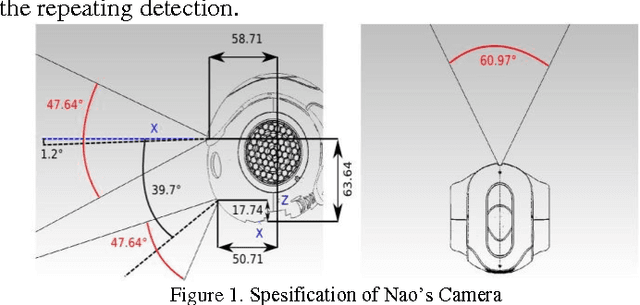
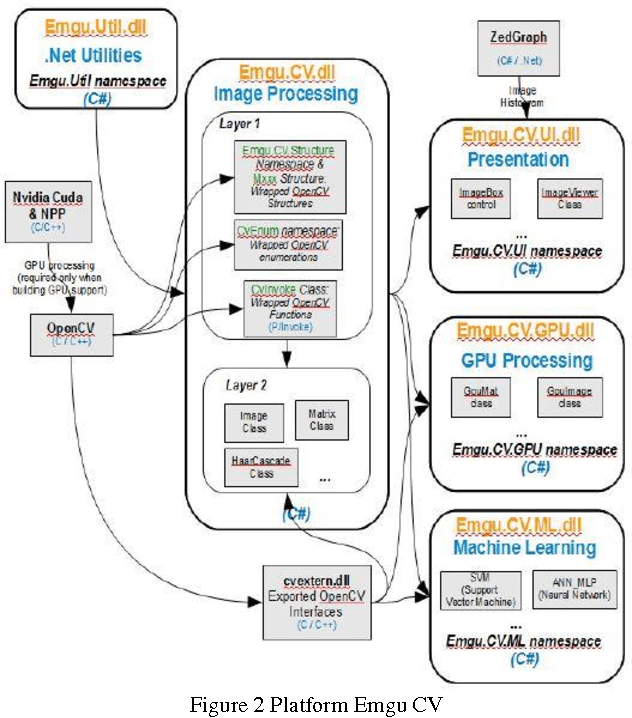
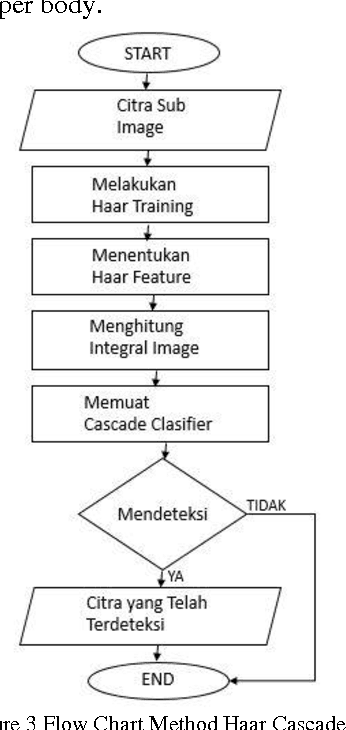
Lumen Social Robot is a humanoid robot development with the purpose that it could be a good friend to all people. In this year, the Lumen Social Robot is being developed into a guide in the exhibition and in the seminar of the Final Exam of undergraduate and graduate students in Electrical Engineering ITB, named Electrical Engineering Days 2015. In order to be the guide in that occasion, Lumen is supported by several things. They are Nao robot components, servers, and multiple processor systems. The image processing system is a processing application system that allows Lumen to recognize and determine an object from the image taken from the camera eye. The image processing system is provided with four modules. They are face detection module to detect a person's face, face recognition module to recognize a person's face, face tracking module to follow a person's face, and human detection module to detect humans based on the upper parts of person's body. Face detection module and human detection module are implemented by using the library harcascade.xml on EMGU CV. Face recognition module is implemented by adding the database for the face that has been detected and store it in that database. Face tracking module is implemented by using the Smooth Gaussian filter to the image. ----- Lumen Sosial Robot merupakan sebuah pengembangan robot humanoid agar dapat menjadi teman bagi banyak orang. Sistem pengolahan citra merupakan sistem aplikasi pengolah yang bertujuan Lumen dapat mengenali dan mengetahui suatu objek pada citra yang diambil dari camera mata Lumen. System pengolahan citra dilengkapi dengan empat buah modul, yaitu modul face detection untuk mendeteksi wajah seseorang, modul face recognition untuk mengenali wajah orang tersebut, modul face tracking untuk mengikuti wajah seseorang, dan modul human detection untuk mendeteksi manusia berdasarkan bagian tubuh atas orang
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
Sep 23, 2016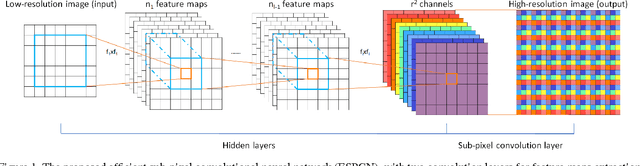

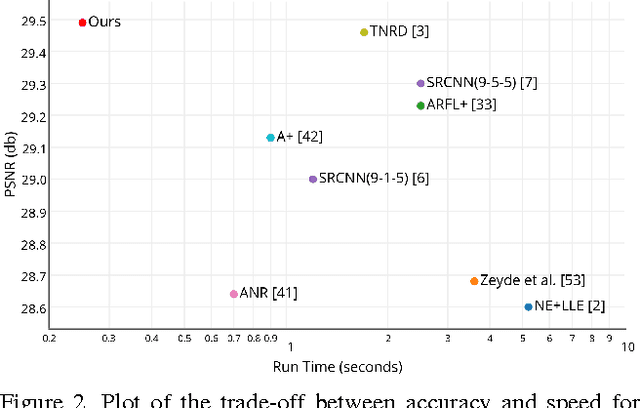
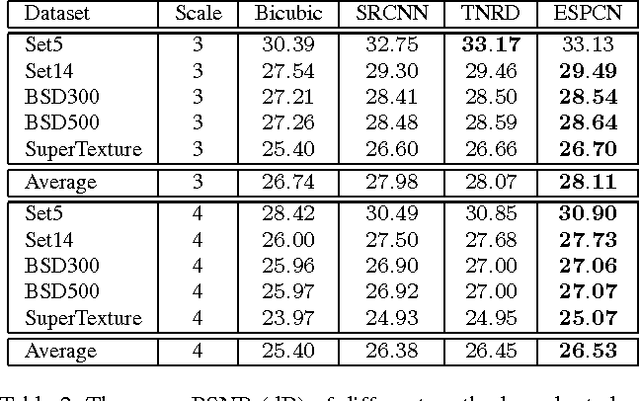
Recently, several models based on deep neural networks have achieved great success in terms of both reconstruction accuracy and computational performance for single image super-resolution. In these methods, the low resolution (LR) input image is upscaled to the high resolution (HR) space using a single filter, commonly bicubic interpolation, before reconstruction. This means that the super-resolution (SR) operation is performed in HR space. We demonstrate that this is sub-optimal and adds computational complexity. In this paper, we present the first convolutional neural network (CNN) capable of real-time SR of 1080p videos on a single K2 GPU. To achieve this, we propose a novel CNN architecture where the feature maps are extracted in the LR space. In addition, we introduce an efficient sub-pixel convolution layer which learns an array of upscaling filters to upscale the final LR feature maps into the HR output. By doing so, we effectively replace the handcrafted bicubic filter in the SR pipeline with more complex upscaling filters specifically trained for each feature map, whilst also reducing the computational complexity of the overall SR operation. We evaluate the proposed approach using images and videos from publicly available datasets and show that it performs significantly better (+0.15dB on Images and +0.39dB on Videos) and is an order of magnitude faster than previous CNN-based methods.
AutoCorrect: Deep Inductive Alignment of Noisy Geometric Annotations
Aug 14, 2019
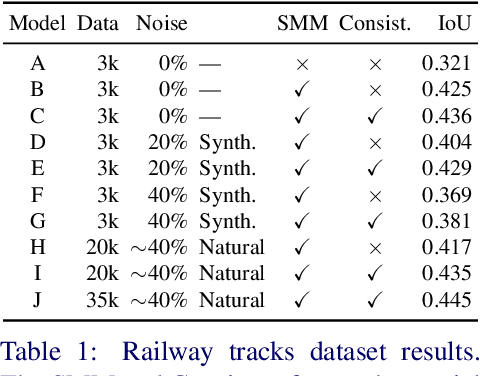
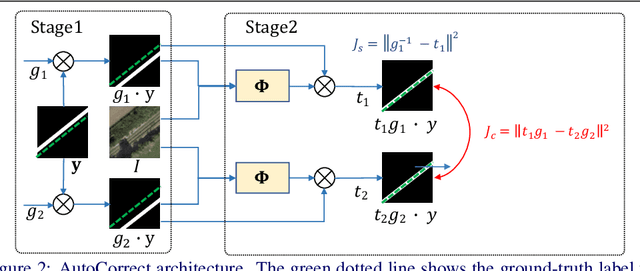
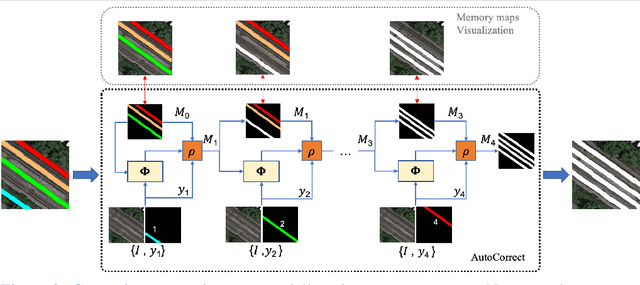
We propose AutoCorrect, a method to automatically learn object-annotation alignments from a dataset with annotations affected by geometric noise. The method is based on a consistency loss that enables deep neural networks to be trained, given only noisy annotations as input, to correct the annotations. When some noise-free annotations are available, we show that the consistency loss reduces to a stricter self-supervised loss. We also show that the method can implicitly leverage object symmetries to reduce the ambiguity arising in correcting noisy annotations. When multiple object-annotation pairs are present in an image, we introduce a spatial memory map that allows the network to correct annotations sequentially, one at a time, while accounting for all other annotations in the image and corrections performed so far. Through ablation, we show the benefit of these contributions, demonstrating excellent results on geo-spatial imagery. Specifically, we show results using a new Railway tracks dataset as well as the public INRIA Buildings benchmarks, achieving new state-of-the-art results for the latter.
Convolutional Neural Networks on Randomized Data
Jul 25, 2019
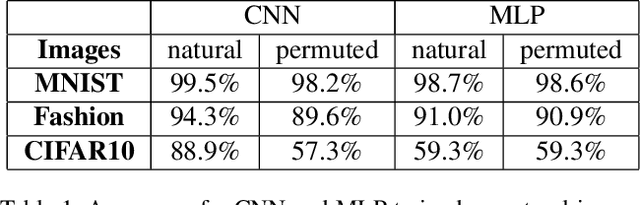
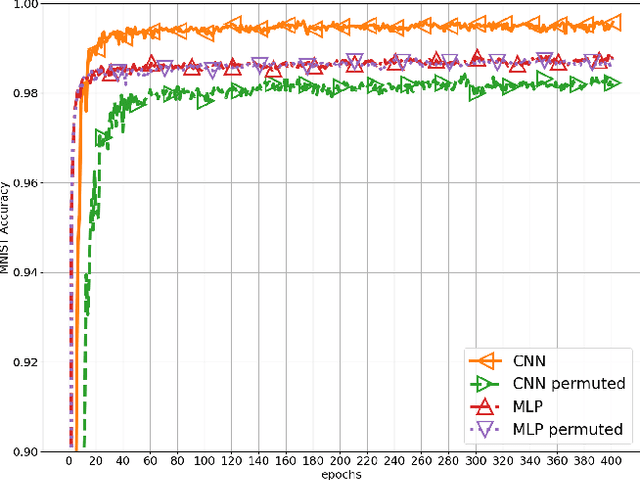
Convolutional Neural Networks (CNNs) are build specifically for computer vision tasks for which it is known that the input data is a hierarchical structure based on locally correlated elements. The question that naturally arises is what happens with the performance of CNNs if one of the basic properties of the data is removed, e.g. what happens if the image pixels are randomly permuted? Intuitively one expects that the convolutional network performs poorly in these circumstances in contrast to a multilayer perceptron (MLPs) whose classification accuracy should not be affected by the pixel randomization. This work shows that by randomizing image pixels the hierarchical structure of the data is destroyed and long range correlations are introduced which standard CNNs are not able to capture. We show that their classification accuracy is heavily dependent on the class similarities as well as the pixel randomization process. We also indicate that dilated convolutions are able to recover some of the pixel correlations and improve the performance.
* 8 pages, 17 figures, presented at Deep-Vision workshop, CVPR 2019
Learning to Super Resolve Intensity Images from Events
Dec 03, 2019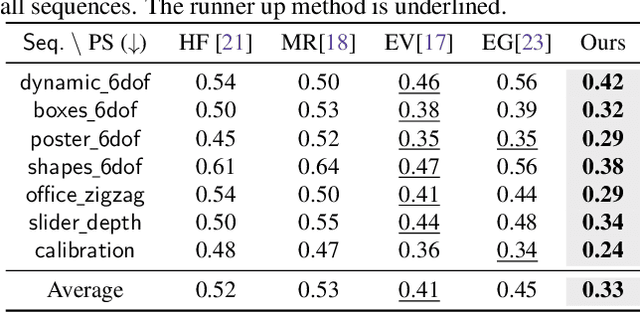
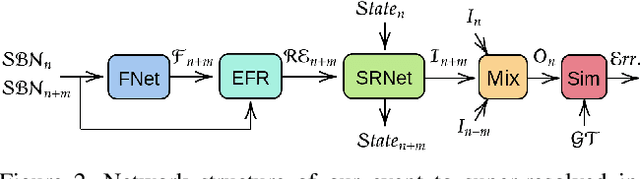
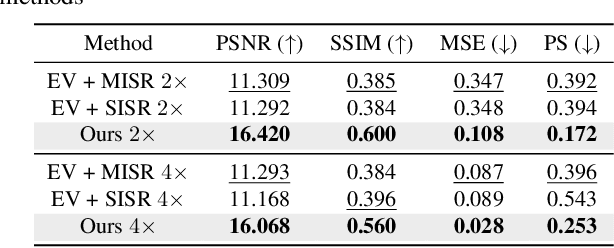
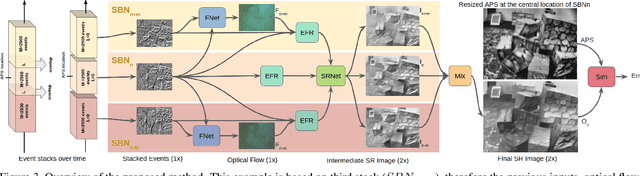
An event camera detects per-pixel intensity difference and produces asynchronous event stream with low latency, high dynamic sensing range, and low power consumption. As a trade-off, the event camera has low spatial resolution. We propose an end-to-end network to reconstruct high resolution, high dynamic range (HDR) images from the event streams. The reconstructed images using the proposed method is in better quality than the combination of state-of-the-art intensity image reconstruction algorithms and the state-of-the-art super resolution schemes. We further evaluate our algorithm on multiple real-world sequences showing the ability to generate high quality images in the zero-shot cross dataset transfer setting.
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
Feb 29, 2020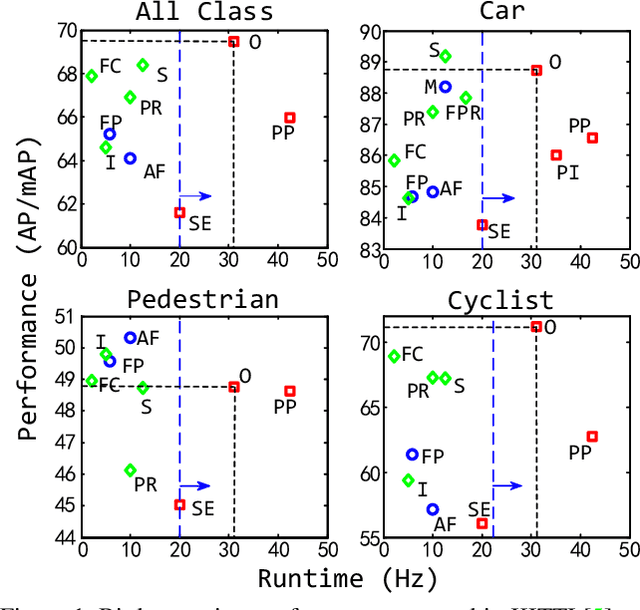
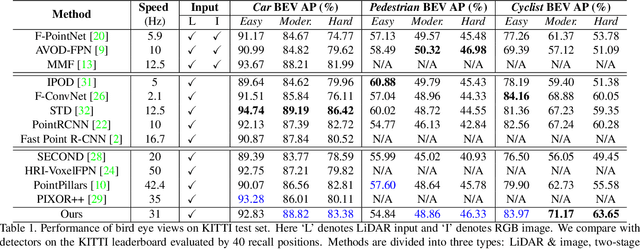
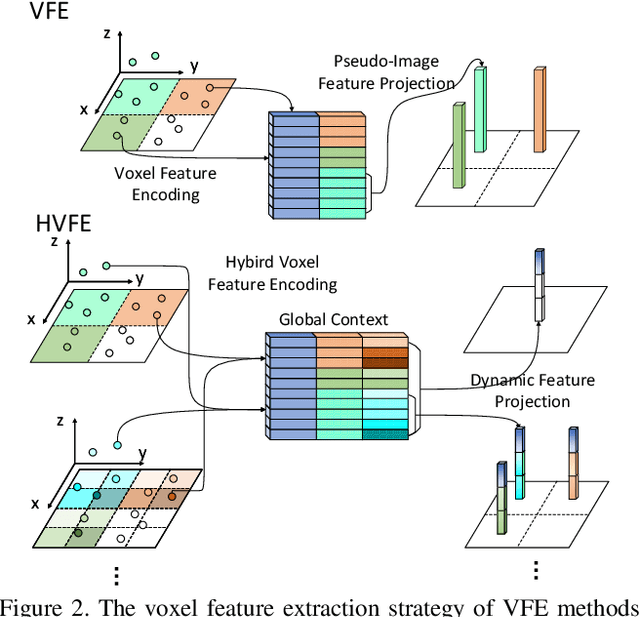
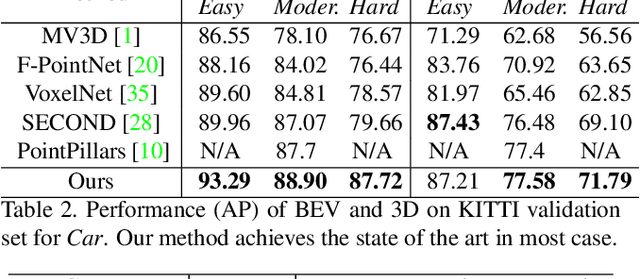
We present Hybrid Voxel Network (HVNet), a novel one-stage unified network for point cloud based 3D object detection for autonomous driving. Recent studies show that 2D voxelization with per voxel PointNet style feature extractor leads to accurate and efficient detector for large 3D scenes. Since the size of the feature map determines the computation and memory cost, the size of the voxel becomes a parameter that is hard to balance. A smaller voxel size gives a better performance, especially for small objects, but a longer inference time. A larger voxel can cover the same area with a smaller feature map, but fails to capture intricate features and accurate location for smaller objects. We present a Hybrid Voxel network that solves this problem by fusing voxel feature encoder (VFE) of different scales at point-wise level and project into multiple pseudo-image feature maps. We further propose an attentive voxel feature encoding that outperforms plain VFE and a feature fusion pyramid network to aggregate multi-scale information at feature map level. Experiments on the KITTI benchmark show that a single HVNet achieves the best mAP among all existing methods with a real time inference speed of 31Hz.