 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UnionDet: Union-Level Detector Towards Real-Time Human-Object Interaction Detection
Dec 19, 2023
Recent advances in deep neural networks have achieved significant progress in detecting individual objects from an image. However, object detection is not sufficient to fully understand a visual scene. Towards a deeper visual understanding, the interactions between objects, especially humans and objects are essential. Most prior works have obtained this information with a bottom-up approach, where the objects are first detected and the interactions are predicted sequentially by pairing the objects. This is a major bottleneck in HOI detection inference time. To tackle this problem, we propose UnionDet, a one-stage meta-architecture for HOI detection powered by a novel union-level detector that eliminates this additional inference stage by directly capturing the region of interaction. Our one-stage detector for human-object interaction shows a significant reduction in interaction prediction time 4x~14x while outperforming state-of-the-art methods on two public datasets: V-COCO and HICO-DET.
DMT: Comprehensive Distillation with Multiple Self-supervised Teachers
Dec 19, 2023Numerous self-supervised learning paradigms, such as contrastive learning and masked image modeling, have been proposed to acquire powerful and general representations from unlabeled data. However, these models are commonly pretrained within their specific framework alone, failing to consider the complementary nature of visual representations. To tackle this issue, we introduce Comprehensive Distillation with Multiple Self-supervised Teachers (DMT) for pretrained model compression, which leverages the strengths of multiple off-the-shelf self-supervised models. Our experimental results on prominent benchmark datasets exhibit that the proposed method significantly surpasses state-of-the-art competitors while retaining favorable efficiency metrics. On classification tasks, our DMT framework utilizing three different self-supervised ViT-Base teachers enhances the performance of both small/tiny models and the base model itself. For dense tasks, DMT elevates the AP/mIoU of standard SSL models on MS-COCO and ADE20K datasets by 4.0%.
Enhancing Instance-Level Image Classification with Set-Level Labels
Nov 09, 2023Instance-level image classification tasks have traditionally relied on single-instance labels to train models, e.g., few-shot learning and transfer learning. However, set-level coarse-grained labels that capture relationships among instances can provide richer information in real-world scenarios. In this paper, we present a novel approach to enhance instance-level image classification by leveraging set-level labels. We provide a theoretical analysis of the proposed method, including recognition conditions for fast excess risk rate, shedding light on the theoretical foundations of our approach. We conducted experiments on two distinct categories of datasets: natural image datasets and histopathology image datasets. Our experimental results demonstrate the effectiveness of our approach, showcasing improved classification performance compared to traditional single-instance label-based methods. Notably, our algorithm achieves 13% improvement in classification accuracy compared to the strongest baseline on the histopathology image classification benchmarks. Importantly, our experimental findings align with the theoretical analysis, reinforcing the robustness and reliability of our proposed method. This work bridges the gap between instance-level and set-level image classification, offering a promising avenue for advancing the capabilities of image classification models with set-level coarse-grained labels.
A Relay System for Semantic Image Transmission based on Shared Feature Extraction and Hyperprior Entropy Compression
Nov 17, 2023Nowadays, the need for high-quality image reconstruction and restoration is more and more urgent. However, most image transmission systems may suffer from image quality degradation or transmission interruption in the face of interference such as channel noise and link fading. To solve this problem, a relay communication network for semantic image transmission based on shared feature extraction and hyperprior entropy compression (HEC) is proposed, where the shared feature extraction technology based on Pearson correlation is proposed to eliminate partial shared feature of extracted semantic latent feature. In addition, the HEC technology is used to resist the effect of channel noise and link fading and carried out respectively at the source node and the relay node. Experimental results demonstrate that compared with other recent research methods, the proposed system has lower transmission overhead and higher semantic image transmission performance. Particularly, under the same conditions, the multi-scale structural similarity (MS-SSIM) of this system is superior to the comparison method by approximately 0.2.
MonoLSS: Learnable Sample Selection For Monocular 3D Detection
Dec 22, 2023In the field of autonomous driving, monocular 3D detection is a critical task which estimates 3D properties (depth, dimension, and orientation) of objects in a single RGB image. Previous works have used features in a heuristic way to learn 3D properties, without considering that inappropriate features could have adverse effects. In this paper, sample selection is introduced that only suitable samples should be trained to regress the 3D properties. To select samples adaptively, we propose a Learnable Sample Selection (LSS) module, which is based on Gumbel-Softmax and a relative-distance sample divider. The LSS module works under a warm-up strategy leading to an improvement in training stability. Additionally, since the LSS module dedicated to 3D property sample selection relies on object-level features, we further develop a data augmentation method named MixUp3D to enrich 3D property samples which conforms to imaging principles without introducing ambiguity. As two orthogonal methods, the LSS module and MixUp3D can be utilized independently or in conjunction. Sufficient experiments have shown that their combined use can lead to synergistic effects, yielding improvements that transcend the mere sum of their individual applications. Leveraging the LSS module and the MixUp3D, without any extra data, our method named MonoLSS ranks 1st in all three categories (Car, Cyclist, and Pedestrian) on KITTI 3D object detection benchmark, and achieves competitive results on both the Waymo dataset and KITTI-nuScenes cross-dataset evaluation. The code is included in the supplementary material and will be released to facilitate related academic and industrial studies.
A Guided Upsampling Network for Short Wave Infrared Images Using Graph Regularization
Dec 14, 2023Exploiting the infrared area of the spectrum for classification problems is getting increasingly popular, because many materials have characteristic absorption bands in this area. However, sensors in the short wave infrared (SWIR) area and even higher wavelengths have a very low spatial resolution in comparison to classical cameras that operate in the visible wavelength area. Thus, in this paper an upsampling method for SWIR images guided by a visible image is presented. For that, the proposed guided upsampling network (GUNet) uses a graph-regularized optimization problem based on learned affinities is presented. The evaluation is based on a novel synthetic near-field visible-SWIR stereo database. Different guided upsampling methods are evaluated, which shows an improvement of nearly 1 dB on this database for the proposed upsampling method in comparison to the second best guided upsampling network. Furthermore, a visual example of an upsampled SWIR image of a real-world scene is depicted for showing real-world applicability.
VideoLCM: Video Latent Consistency Model
Dec 14, 2023
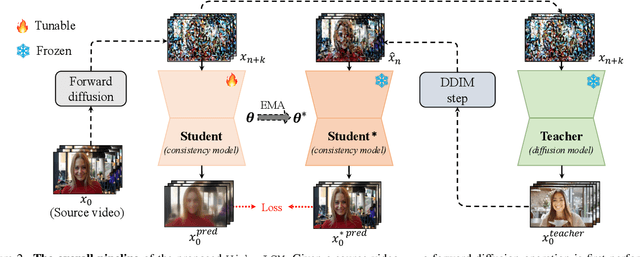

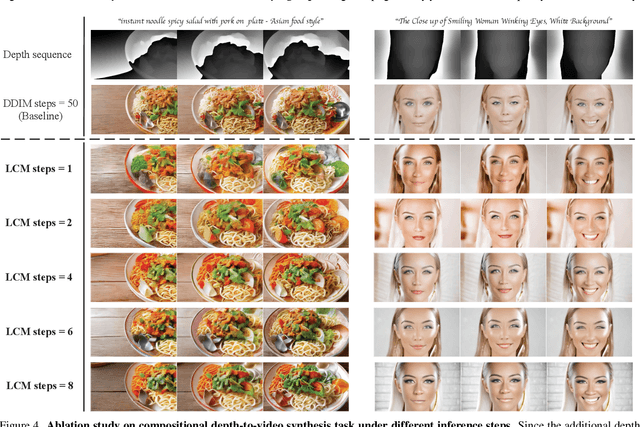
Consistency models have demonstrated powerful capability in efficient image generation and allowed synthesis within a few sampling steps, alleviating the high computational cost in diffusion models. However, the consistency model in the more challenging and resource-consuming video generation is still less explored. In this report, we present the VideoLCM framework to fill this gap, which leverages the concept of consistency models from image generation to efficiently synthesize videos with minimal steps while maintaining high quality. VideoLCM builds upon existing latent video diffusion models and incorporates consistency distillation techniques for training the latent consistency model. Experimental results reveal the effectiveness of our VideoLCM in terms of computational efficiency, fidelity and temporal consistency. Notably, VideoLCM achieves high-fidelity and smooth video synthesis with only four sampling steps, showcasing the potential for real-time synthesis. We hope that VideoLCM can serve as a simple yet effective baseline for subsequent research. The source code and models will be publicly available.
Individualized Deepfake Detection Exploiting Traces Due to Double Neural-Network Operations
Dec 13, 2023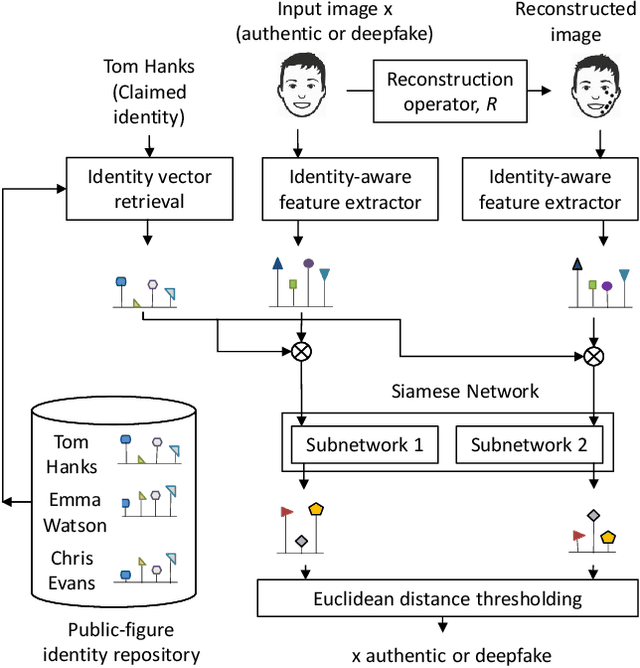
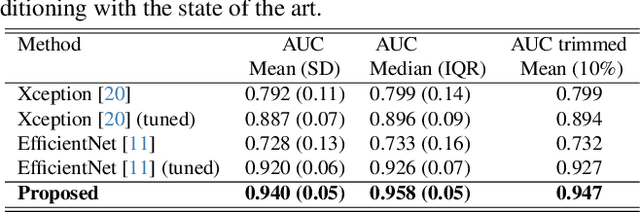
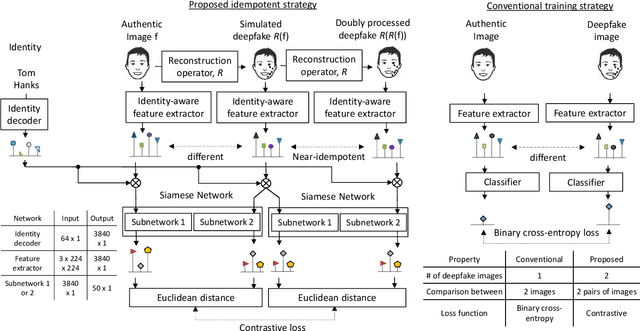
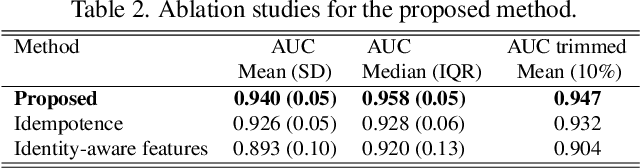
In today's digital landscape, journalists urgently require tools to verify the authenticity of facial images and videos depicting specific public figures before incorporating them into news stories. Existing deepfake detectors are not optimized for this detection task when an image is associated with a specific and identifiable individual. This study focuses on the deepfake detection of facial images of individual public figures. We propose to condition the proposed detector on the identity of the identified individual given the advantages revealed by our theory-driven simulations. While most detectors in the literature rely on perceptible or imperceptible artifacts present in deepfake facial images, we demonstrate that the detection performance can be improved by exploiting the idempotency property of neural networks. In our approach, the training process involves double neural-network operations where we pass an authentic image through a deepfake simulating network twice. Experimental results show that the proposed method improves the area under the curve (AUC) from 0.92 to 0.94 and reduces its standard deviation by 17\%. For evaluating the detection performance of individual public figures, a facial image dataset with individuals' names is required, a criterion not met by the current deepfake datasets. To address this, we curated a dataset comprising 32k images featuring 45 public figures, which we intend to release to the public after the paper is published.
Kandinsky 3.0 Technical Report
Dec 11, 2023We present Kandinsky 3.0, a large-scale text-to-image generation model based on latent diffusion, continuing the series of text-to-image Kandinsky models and reflecting our progress to achieve higher quality and realism of image generation. Compared to previous versions of Kandinsky 2.x, Kandinsky 3.0 leverages a two times larger U-Net backbone, a ten times larger text encoder and removes diffusion mapping. We describe the architecture of the model, the data collection procedure, the training technique, and the production system of user interaction. We focus on the key components that, as we have identified as a result of a large number of experiments, had the most significant impact on improving the quality of our model compared to the others. By our side-by-side comparisons, Kandinsky becomes better in text understanding and works better on specific domains. Project page: https://ai-forever.github.io/Kandinsky-3
RetailKLIP : Finetuning OpenCLIP backbone using metric learning on a single GPU for Zero-shot retail product image classification
Dec 16, 2023Retail product or packaged grocery goods images need to classified in various computer vision applications like self checkout stores, supply chain automation and retail execution evaluation. Previous works explore ways to finetune deep models for this purpose. But because of the fact that finetuning a large model or even linear layer for a pretrained backbone requires to run at least a few epochs of gradient descent for every new retail product added in classification range, frequent retrainings are needed in a real world scenario. In this work, we propose finetuning the vision encoder of a CLIP model in a way that its embeddings can be easily used for nearest neighbor based classification, while also getting accuracy close to or exceeding full finetuning. A nearest neighbor based classifier needs no incremental training for new products, thus saving resources and wait time.