 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explanatory Masks for Neural Network Interpretability
Nov 15, 2019

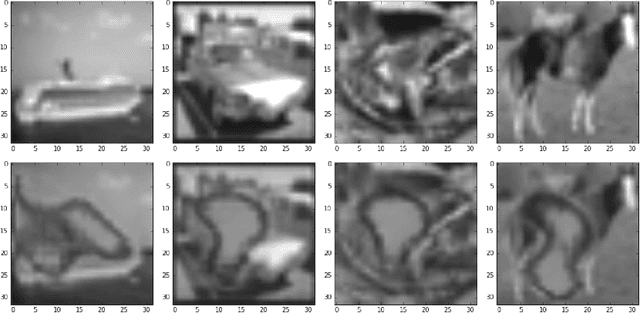

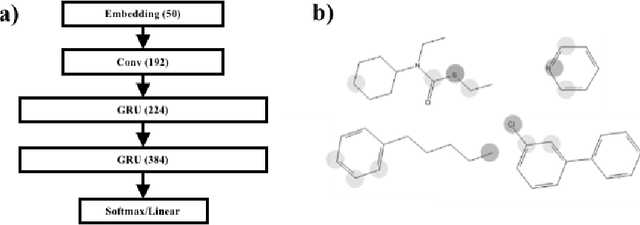
Neural network interpretability is a vital component for applications across a wide variety of domains. In such cases it is often useful to analyze a network which has already been trained for its specific purpose. In this work, we develop a method to produce explanation masks for pre-trained networks. The mask localizes the most important aspects of each input for prediction of the original network. Masks are created by a secondary network whose goal is to create as small an explanation as possible while still preserving the predictive accuracy of the original network. We demonstrate the applicability of our method for image classification with CNNs, sentiment analysis with RNNs, and chemical property prediction with mixed CNN/RNN architectures.
Calibrationless Parallel MRI using Model based Deep Learning (C-MODL)
Nov 27, 2019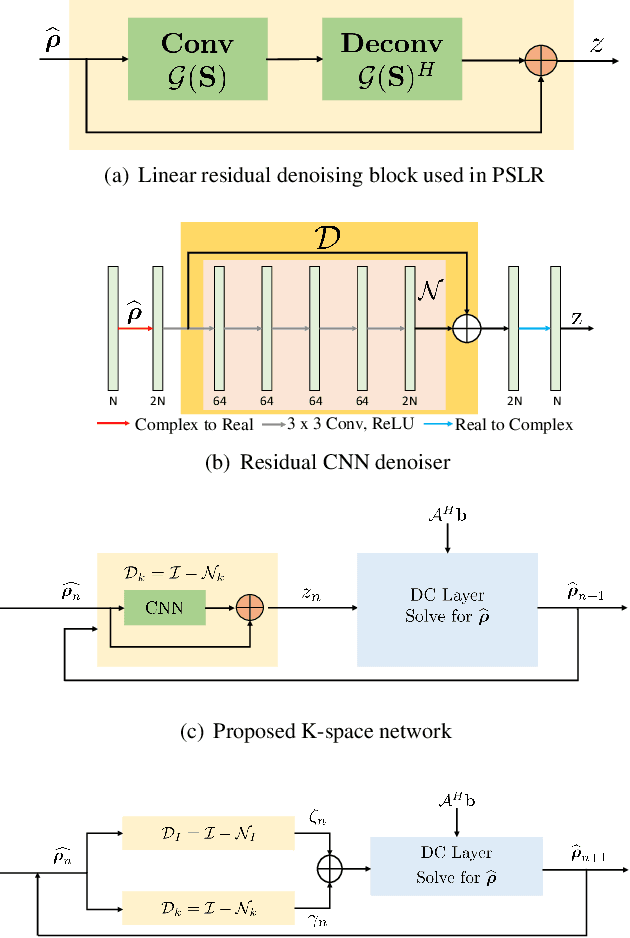
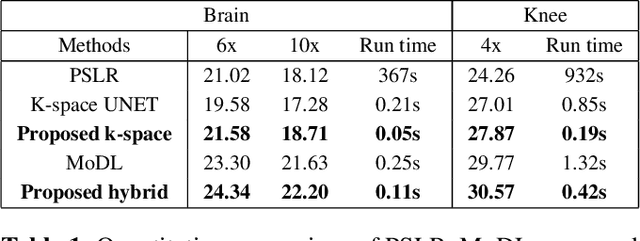
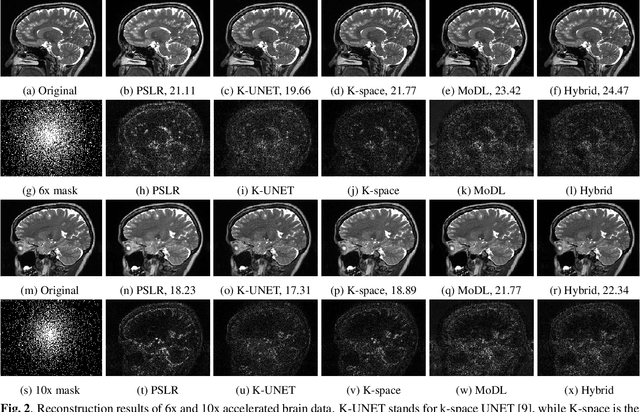
We introduce a fast model based deep learning approach for calibrationless parallel MRI reconstruction. The proposed scheme is a non-linear generalization of structured low rank (SLR) methods that self learn linear annihilation filters from the same subject. It pre-learns non-linear annihilation relations in the Fourier domain from exemplar data. The pre-learning strategy significantly reduces the computational complexity, making the proposed scheme three orders of magnitude faster than SLR schemes. The proposed framework also allows the use of a complementary spatial domain prior; the hybrid regularization scheme offers improved performance over calibrated image domain MoDL approach. The calibrationless strategy minimizes potential mismatches between calibration data and the main scan, while eliminating the need for a fully sampled calibration region.
Style Decomposition for Improved Neural Style Transfer
Nov 30, 2018
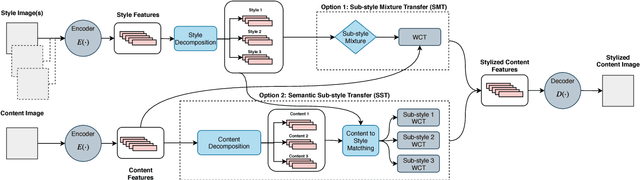


Universal Neural Style Transfer (NST) methods are capable of performing style transfer of arbitrary styles in a style-agnostic manner via feature transforms in (almost) real-time. Even though their unimodal parametric style modeling approach has been proven adequate to transfer a single style from relatively simple images, they are usually not capable of effectively handling more complex styles, producing significant artifacts, as well as reducing the quality of the synthesized textures in the stylized image. To overcome these limitations, in this paper we propose a novel universal NST approach that separately models each sub-style that exists in a given style image (or a collection of style images). This allows for better modeling the subtle style differences within the same style image and then using the most appropriate sub-style (or mixtures of different sub-styles) to stylize the content image. The ability of the proposed approach to a) perform a wide range of different stylizations using the sub-styles that exist in one style image, while giving the ability to the user to appropriate mix the different sub-styles, b) automatically match the most appropriate sub-style to different semantic regions of the content image, improving existing state-of-the-art universal NST approaches, and c) detecting and transferring the sub-styles from collections of images are demonstrated through extensive experiments.
Multiple Discrimination and Pairwise CNN for View-based 3D Object Retrieval
Feb 27, 2020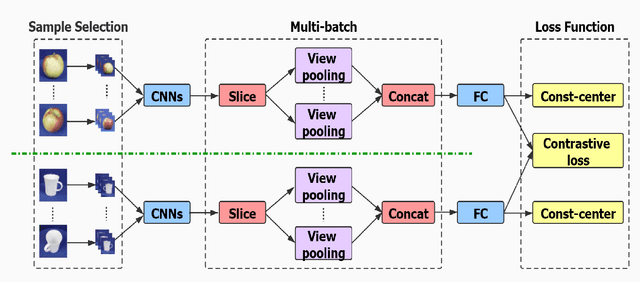
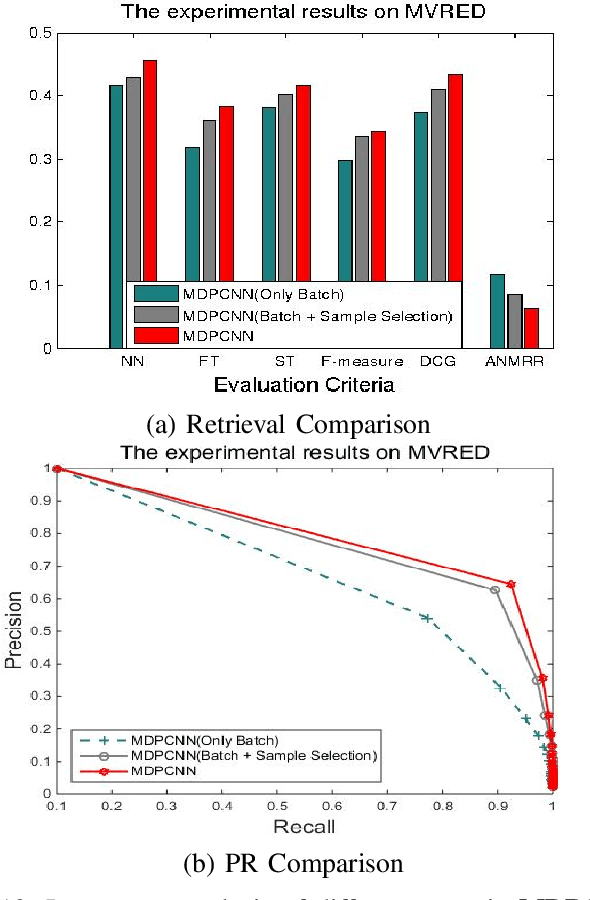
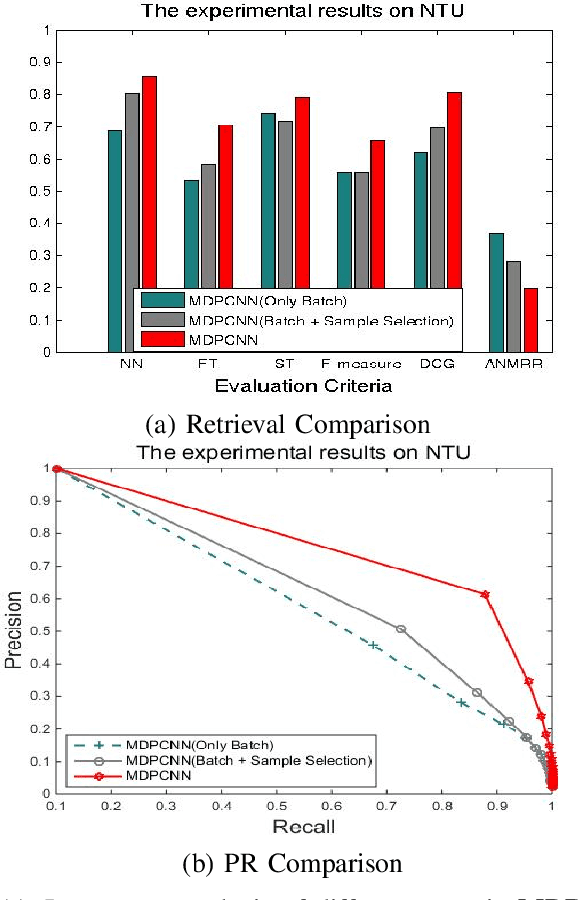
With the rapid development and wide application of computer, camera device, network and hardware technology, 3D object (or model) retrieval has attracted widespread attention and it has become a hot research topic in the computer vision domain. Deep learning features already available in 3D object retrieval have been proven to be better than the retrieval performance of hand-crafted features. However, most existing networks do not take into account the impact of multi-view image selection on network training, and the use of contrastive loss alone only forcing the same-class samples to be as close as possible. In this work, a novel solution named Multi-view Discrimination and Pairwise CNN (MDPCNN) for 3D object retrieval is proposed to tackle these issues. It can simultaneously input of multiple batches and multiple views by adding the Slice layer and the Concat layer. Furthermore, a highly discriminative network is obtained by training samples that are not easy to be classified by clustering. Lastly, we deploy the contrastive-center loss and contrastive loss as the optimization objective that has better intra-class compactness and inter-class separability. Large-scale experiments show that the proposed MDPCNN can achieve a significant performance over the state-of-the-art algorithms in 3D object retrieval.
On the Sampling Strategy for Evaluation of Spectral-spatial Methods in Hyperspectral Image Classification
May 19, 2016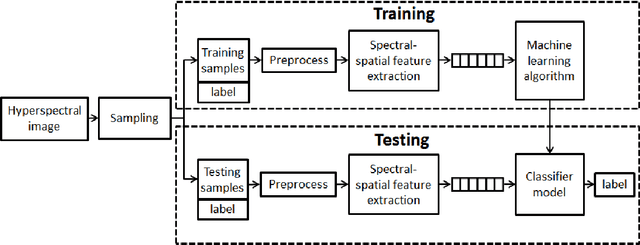
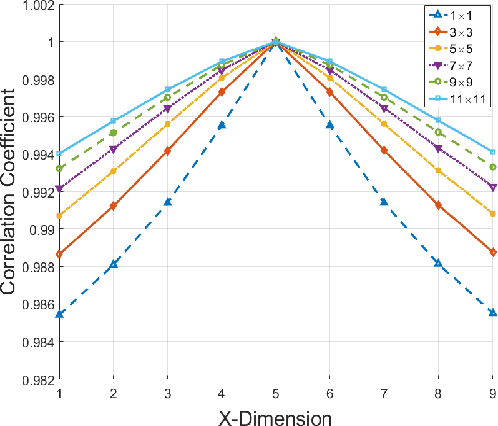
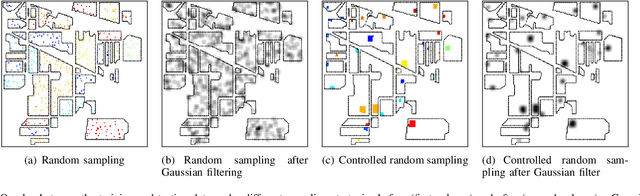

Spectral-spatial processing has been increasingly explored in remote sensing hyperspectral image classification. While extensive studies have focused on developing methods to improve the classification accuracy, experimental setting and design for method evaluation have drawn little attention. In the scope of supervised classification, we find that traditional experimental designs for spectral processing are often improperly used in the spectral-spatial processing context, leading to unfair or biased performance evaluation. This is especially the case when training and testing samples are randomly drawn from the same image - a practice that has been commonly adopted in the experiments. Under such setting, the dependence caused by overlap between the training and testing samples may be artificially enhanced by some spatial information processing methods such as spatial filtering and morphological operation. Such interaction between training and testing sets has violated data independence assumption that is abided by supervised learning theory and performance evaluation mechanism. Therefore, the widely adopted pixel-based random sampling strategy is not always suitable to evaluate spectral-spatial classification algorithms because it is difficult to determine whether the improvement of classification accuracy is caused by incorporating spatial information into classifier or by increasing the overlap between training and testing samples. To partially solve this problem, we propose a novel controlled random sampling strategy for spectral-spatial methods. It can greatly reduce the overlap between training and testing samples and provides more objective and accurate evaluation.
Texture Deformation Based Generative Adversarial Networks for Face Editing
Dec 24, 2018
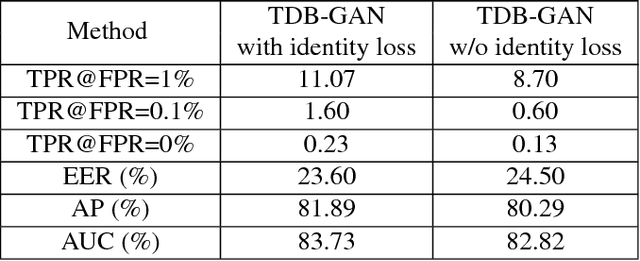
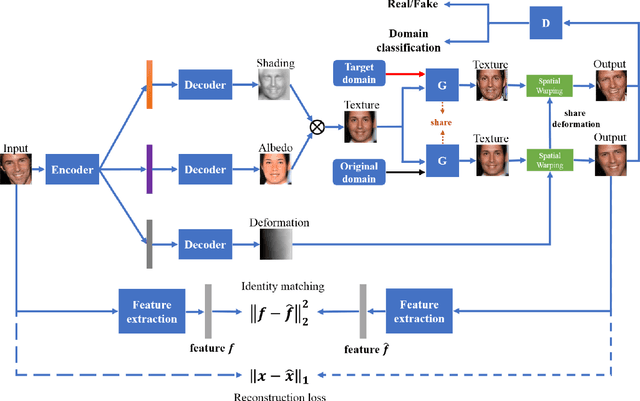
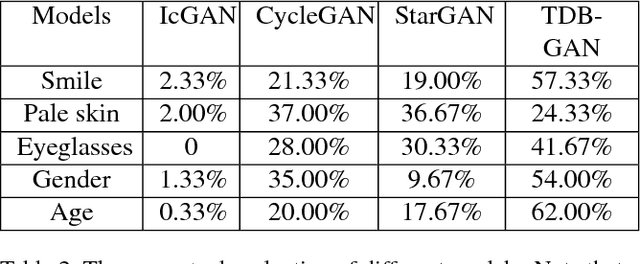
Despite the significant success in image-to-image translation and latent representation based facial attribute editing and expression synthesis, the existing approaches still have limitations in the sharpness of details, distinct image translation and identity preservation. To address these issues, we propose a Texture Deformation Based GAN, namely TDB-GAN, to disentangle texture from original image and transfers domains based on the extracted texture. The approach utilizes the texture to transfer facial attributes and expressions without the consideration of the object pose. This leads to shaper details and more distinct visual effect of the synthesized faces. In addition, it brings the faster convergence during training. The effectiveness of the proposed method is validated through extensive ablation studies. We also evaluate our approach qualitatively and quantitatively on facial attribute and facial expression synthesis. The results on both the CelebA and RaFD datasets suggest that Texture Deformation Based GAN achieves better performance.
Bilateral Cyclic Constraint and Adaptive Regularization for Unsupervised Monocular Depth Prediction
Apr 06, 2019

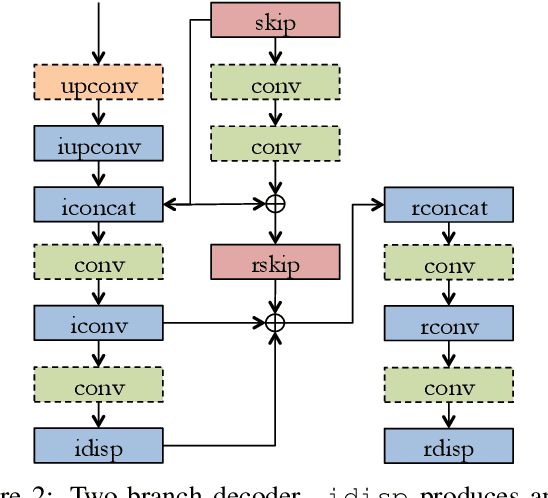
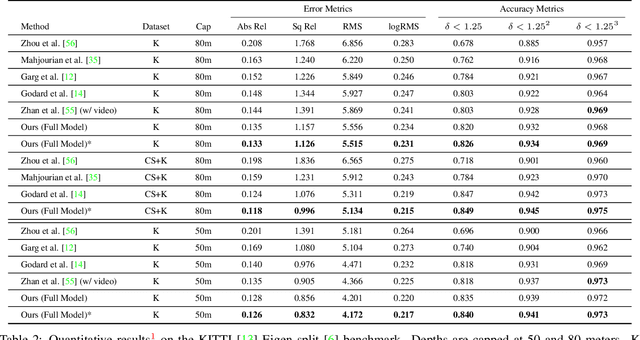
Supervised learning methods to infer (hypothesize) depth of a scene from a single image require costly per-pixel ground-truth. We follow a geometric approach that exploits abundant stereo imagery to learn a model to hypothesize scene structure without direct supervision. Although we train a network with stereo pairs, we only require a single image at test time to hypothesize disparity or depth. We propose a novel objective function that exploits the bilateral cyclic relationship between the left and right disparities and we introduce an adaptive regularization scheme that allows the network to handle both the co-visible and occluded regions in a stereo pair. This process ultimately produces a model to generate hypotheses for the 3-dimensional structure of the scene as viewed in a single image. When used to generate a single (most probable) estimate of depth, our method outperforms state-of-the-art unsupervised monocular depth prediction methods on the KITTI benchmarks. We show that our method generalizes well by applying our models trained on KITTI to the Make3d dataset.
Orthogonal Convolutional Neural Networks
Nov 27, 2019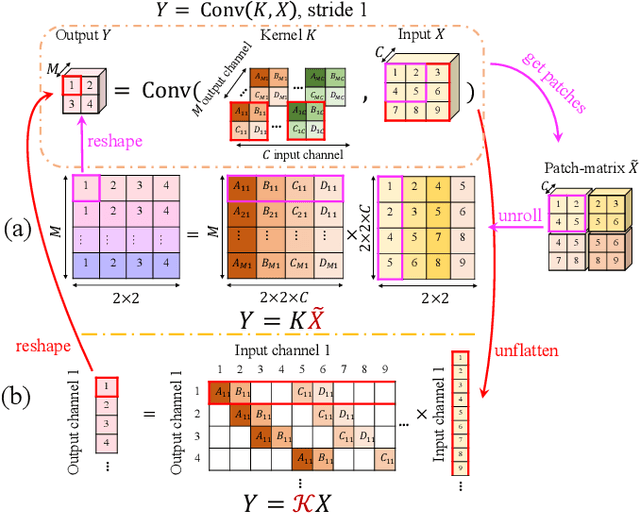
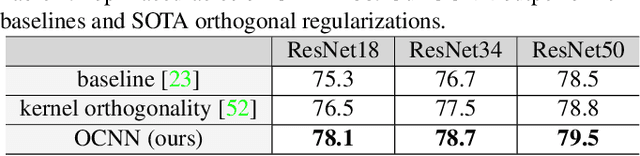
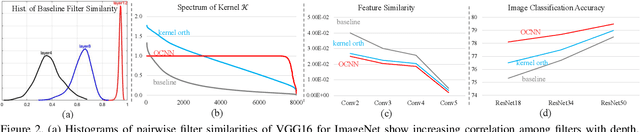

The instability and feature redundancy in CNNs hinders further performance improvement. Using orthogonality as a regularizer has shown success in alleviating these issues. Previous works however only considered the kernel orthogonality in the convolution layers of CNNs, which is a necessary but not sufficient condition for orthogonal convolutions in general. We propose orthogonal convolutions as regularizations in CNNs and benchmark its effect on various tasks. We observe up to 3% gain for CIFAR100 and up to 1% gain for ImageNet classification. Our experiments also demonstrate improved performance on image retrieval, inpainting and generation, which suggests orthogonal convolution improves the feature expressiveness. Empirically, we show that the uniform spectrum and reduced feature redundancy may account for the gain in performance and robustness under adversarial attacks.
Quadtree Generating Networks: Efficient Hierarchical Scene Parsing with Sparse Convolutions
Jul 27, 2019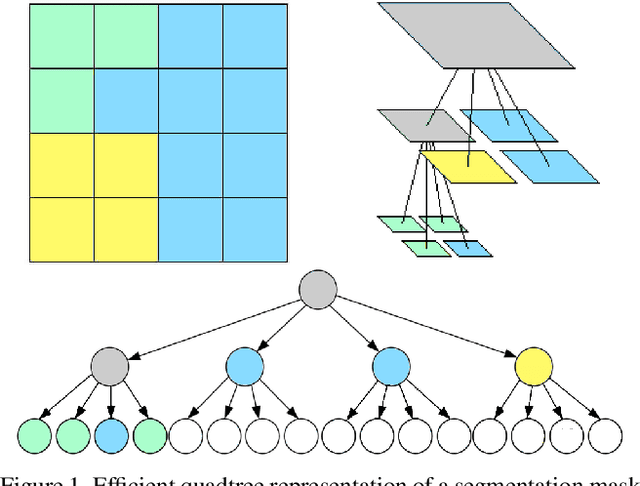
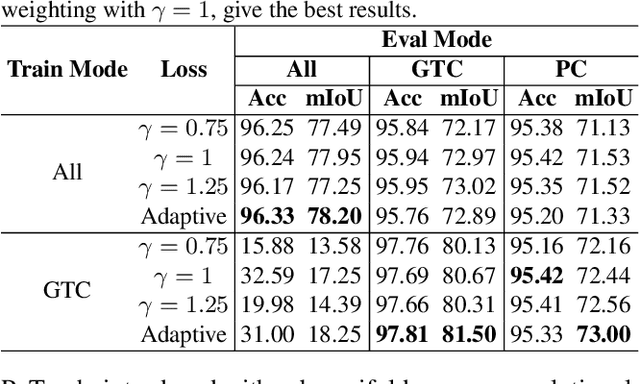
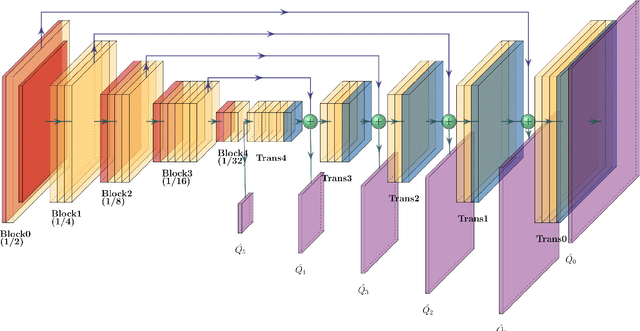
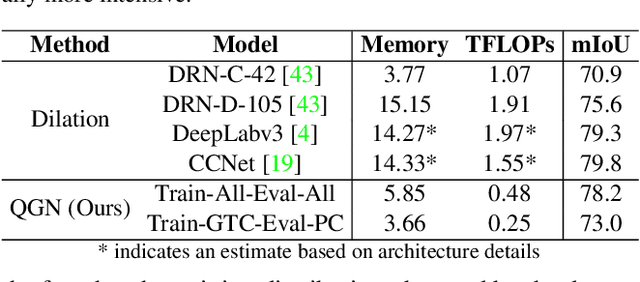
Semantic segmentation with Convolutional Neural Networks is a memory-intensive task due to the high spatial resolution of feature maps and output predictions. In this paper, we present Quadtree Generating Networks (QGNs), a novel approach able to drastically reduce the memory footprint of modern semantic segmentation networks. The key idea is to use quadtrees to represent the predictions and target segmentation masks instead of dense pixel grids. Our quadtree representation enables hierarchical processing of an input image, with the most computationally demanding layers only being used at regions in the image containing boundaries between classes. In addition, given a trained model, our representation enables flexible inference schemes to trade-off accuracy and computational cost, allowing the network to adapt in constrained situations such as embedded devices. We demonstrate the benefits of our approach on the Cityscapes, SUN-RGBD and ADE20k datasets. On Cityscapes, we obtain an relative 3% mIoU improvement compared to a dilated network with similar memory consumption; and only receive a 3% relative mIoU drop compared to a large dilated network, while reducing memory consumption by over 4$\times$.
Neural Design Network: Graphic Layout Generation with Constraints
Dec 19, 2019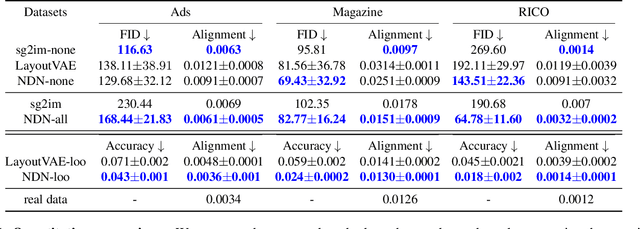
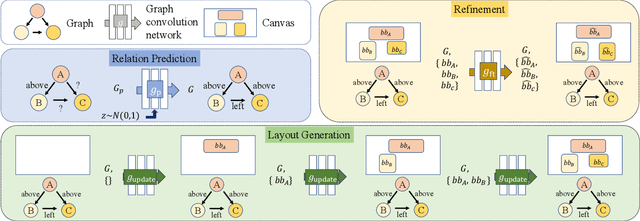
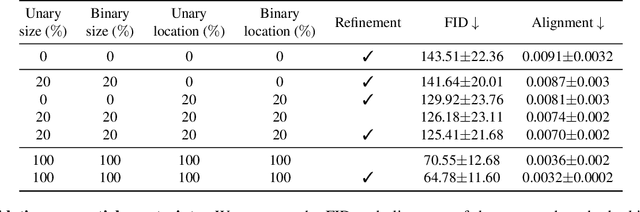
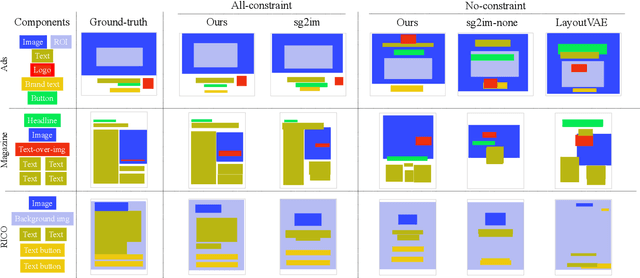
Graphic design is essential for visual communication with layouts being fundamental to composing attractive designs. Layout generation differs from pixel-level image synthesis and is unique in terms of the requirement of mutual relations among the desired components. We propose a method for design layout generation that can satisfy user-specified constraints. The proposed neural design network (NDN) consists of three modules. The first module predicts a graph with complete relations from a graph with user-specified relations. The second module generates a layout from the predicted graph. Finally, the third module fine-tunes the predicted layout. Quantitative and qualitative experiments demonstrate that the generated layouts are visually similar to real design layouts. We also construct real designs based on predicted layouts for a better understanding of the visual quality. Finally, we demonstrate a practical application on layout recommendation.