 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adapting Object Detectors with Conditional Domain Normalization
Mar 16, 2020
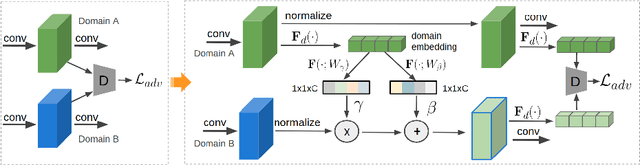
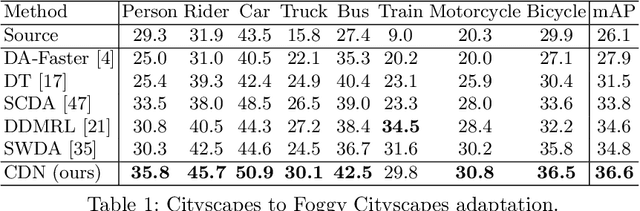
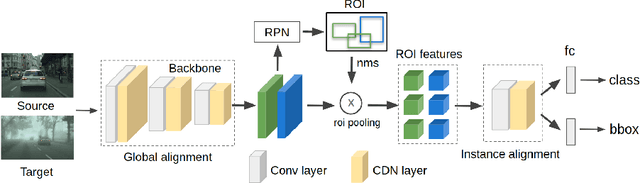
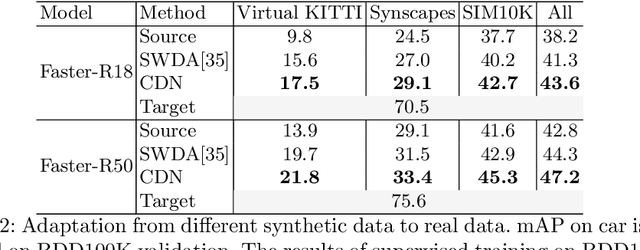
Real-world object detectors are often challenged by the domain gaps between different datasets. In this work, we present the Conditional Domain Normalization (CDN) to bridge the domain gap. CDN is designed to encode different domain inputs into a shared latent space, where the features from different domains carry the same domain attribute. To achieve this, we first disentangle the domain-specific attribute out of the semantic features from one domain via a domain embedding module, which learns a domain-vector to characterize the corresponding domain attribute information. Then this domain-vector is used to encode the features from another domain through a conditional normalization, resulting in different domains' features carrying the same domain attribute. We incorporate CDN into various convolution stages of an object detector to adaptively address the domain shifts of different level's representation. In contrast to existing adaptation works that conduct domain confusion learning on semantic features to remove domain-specific factors, CDN aligns different domain distributions by modulating the semantic features of one domain conditioned on the learned domain-vector of another domain. Extensive experiments show that CDN outperforms existing methods remarkably on both real-to-real and synthetic-to-real adaptation benchmarks, including 2D image detection and 3D point cloud detection.
Test-Time Training for Out-of-Distribution Generalization
Oct 25, 2019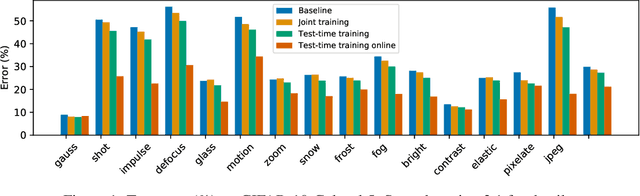
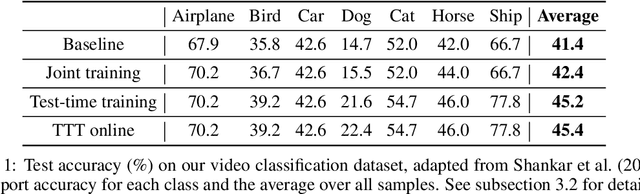
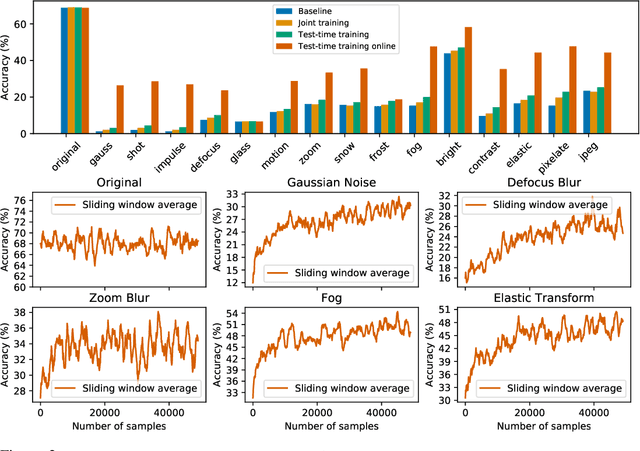
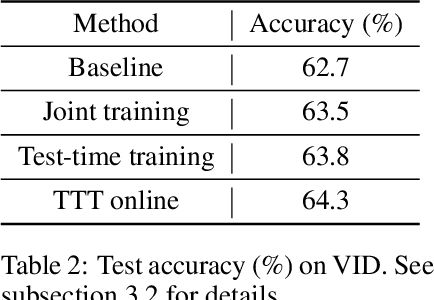
We introduce a general approach, called test-time training, for improving the performance of predictive models when test and training data come from different distributions. Test-time training turns a single unlabeled test instance into a self-supervised learning problem, on which we update the model parameters before making a prediction on this instance. We show that this simple idea leads to surprising improvements on diverse image classification benchmarks aimed at evaluating robustness to distribution shifts. Theoretical investigations on a convex model reveal helpful intuitions for when we can expect our approach to help.
Sky pixel detection in outdoor imagery using an adaptive algorithm and machine learning
Oct 08, 2019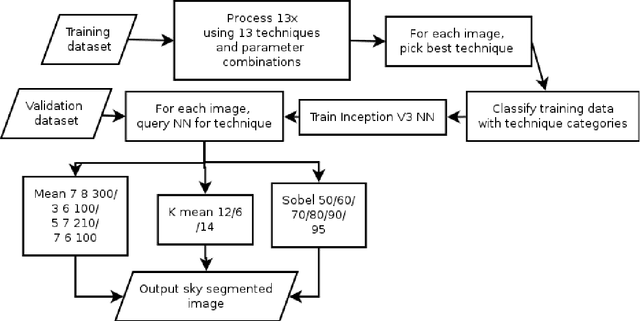



Computer vision techniques allow automated detection of sky pixels in outdoor imagery. Multiple applications exist for this information across a large number of research areas. In urban climate, sky detection is an important first step in gathering information about urban morphology and sky view factors. However, capturing accurate results remains challenging and becomes even more complex using imagery captured under a variety of lighting and weather conditions. To address this problem, we present a new sky pixel detection system demonstrated to produce accurate results using a wide range of outdoor imagery types. Images are processed using a selection of mean-shift segmentation, K-means clustering, and Sobel filters to mark sky pixels in the scene. The algorithm for a specific image is chosen by a convolutional neural network, trained with 25,000 images from the Skyfinder data set, reaching 82% accuracy with the top three classes. This selection step allows the sky marking to follow an adaptive process and to use different techniques and parameters to best suit a particular image. An evaluation of fourteen different techniques and parameter sets shows that no single technique can perform with high accuracy across varied Skyfinder and Google Street View data sets. However, by using our adaptive process, large increases in accuracy are observed. The resulting system is shown to perform better than other published techniques.
Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images
Apr 11, 2020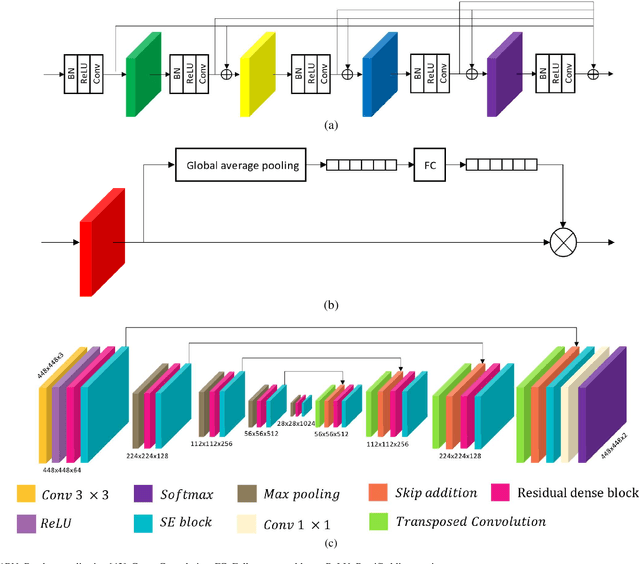



Semantic segmentation models based on convolutional neural networks (CNNs) have gained much attention in relation to remote sensing and have achieved remarkable performance for the extraction of buildings from high-resolution aerial images. However, the issue of limited generalization for unseen images remains. When there is a domain gap between the training and test datasets, CNN-based segmentation models trained by a training dataset fail to segment buildings for the test dataset. In this paper, we propose segmentation networks based on a domain adaptive transfer attack (DATA) scheme for building extraction from aerial images. The proposed system combines the domain transfer and adversarial attack concepts. Based on the DATA scheme, the distribution of the input images can be shifted to that of the target images while turning images into adversarial examples against a target network. Defending adversarial examples adapted to the target domain can overcome the performance degradation due to the domain gap and increase the robustness of the segmentation model. Cross-dataset experiments and the ablation study are conducted for the three different datasets: the Inria aerial image labeling dataset, the Massachusetts building dataset, and the WHU East Asia dataset. Compared to the performance of the segmentation network without the DATA scheme, the proposed method shows improvements in the overall IoU. Moreover, it is verified that the proposed method outperforms even when compared to feature adaptation (FA) and output space adaptation (OSA).
A Pixel-Based Framework for Data-Driven Clothing
Dec 03, 2018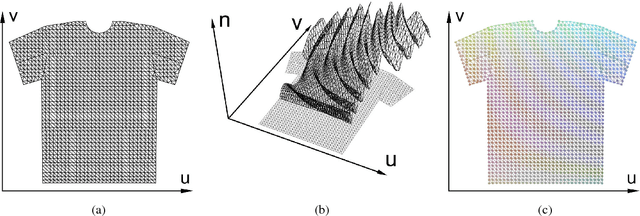
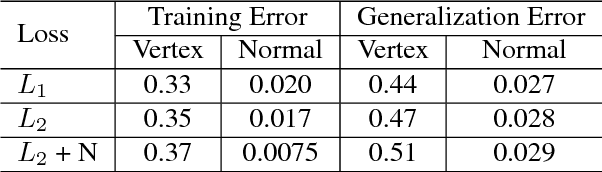
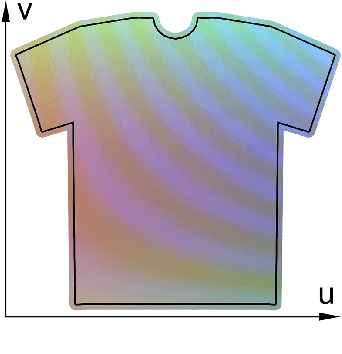
With the aim of creating virtual cloth deformations more similar to real world clothing, we propose a new computational framework that recasts three dimensional cloth deformation as an RGB image in a two dimensional pattern space. Then a three dimensional animation of cloth is equivalent to a sequence of two dimensional RGB images, which in turn are driven/choreographed via animation parameters such as joint angles. This allows us to leverage popular CNNs to learn cloth deformations in image space. The two dimensional cloth pixels are extended into the real world via standard body skinning techniques, after which the RGB values are interpreted as texture offsets and displacement maps. Notably, we illustrate that our approach does not require accurate unclothed body shapes or robust skinning techniques. Additionally, we discuss how standard image based techniques such as image partitioning for higher resolution, GANs for merging partitioned image regions back together, etc., can readily be incorporated into our framework.
RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles
May 15, 2019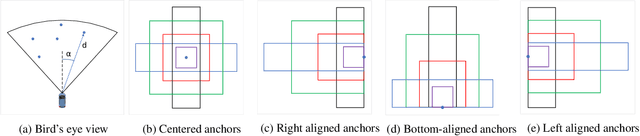

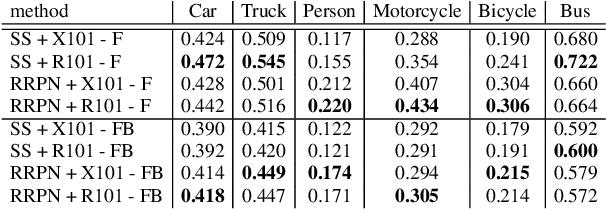
Region proposal algorithms play an important role in most state-of-the-art two-stage object detection networks by hypothesizing object locations in the image. Nonetheless, region proposal algorithms are known to be the bottleneck in most two-stage object detection networks, increasing the processing time for each image and resulting in slow networks not suitable for real-time applications such as autonomous driving vehicles. In this paper we introduce RRPN, a Radar-based real-time region proposal algorithm for object detection in autonomous driving vehicles. RRPN generates object proposals by mapping Radar detections to the image coordinate system and generating pre-defined anchor boxes for each mapped Radar detection point. These anchor boxes are then transformed and scaled based on the object's distance from the vehicle, to provide more accurate proposals for the detected objects. We evaluate our method on the newly released NuScenes dataset [1] using the Fast R-CNN object detection network [2]. Compared to the Selective Search object proposal algorithm [3], our model operates more than 100x faster while at the same time achieves higher detection precision and recall. Code has been made publicly available at https://github.com/mrnabati/RRPN .
Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
May 16, 2019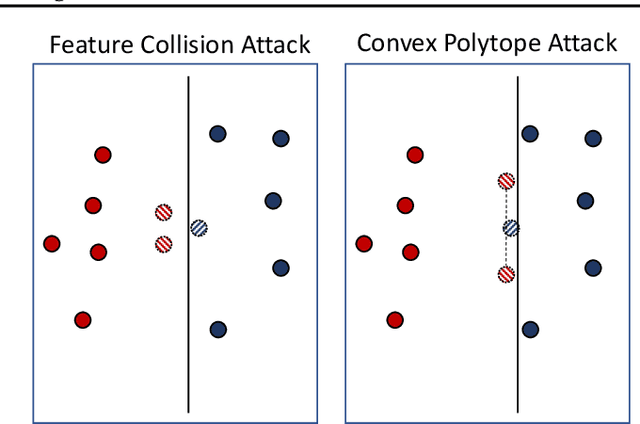

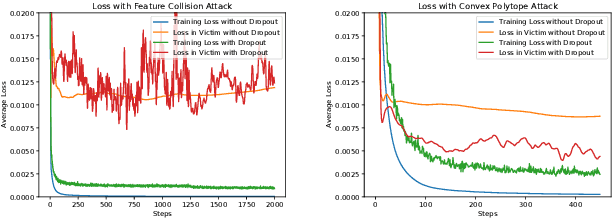

Clean-label poisoning attacks inject innocuous looking (and "correctly" labeled) poison images into training data, causing a model to misclassify a targeted image after being trained on this data. We consider transferable poisoning attacks that succeed without access to the victim network's outputs, architecture, or (in some cases) training data. To achieve this, we propose a new "polytope attack" in which poison images are designed to surround the targeted image in feature space. We also demonstrate that using Dropout during poison creation helps to enhance transferability of this attack. We achieve transferable attack success rates of over 50% while poisoning only 1% of the training set.
Clustering based on Point-Set Kernel
Feb 14, 2020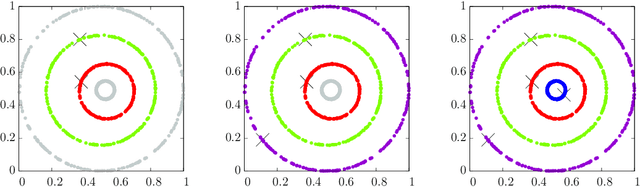
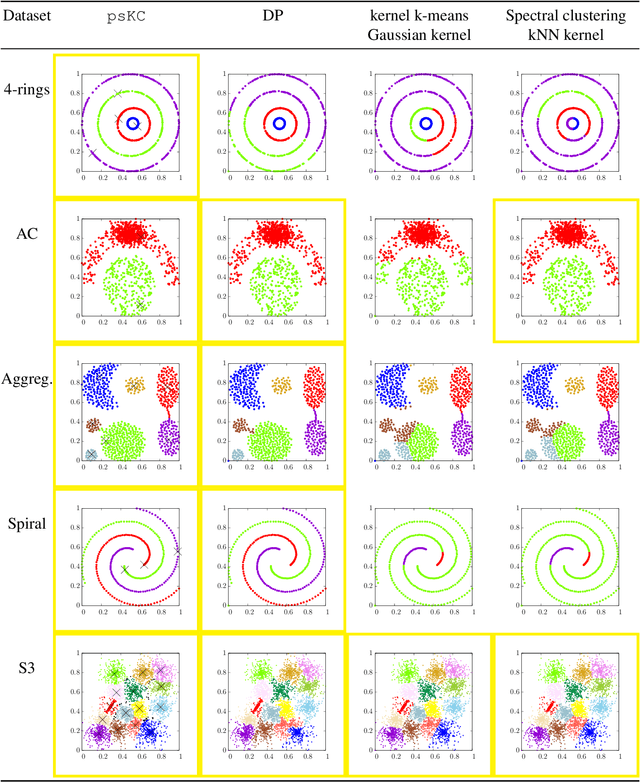

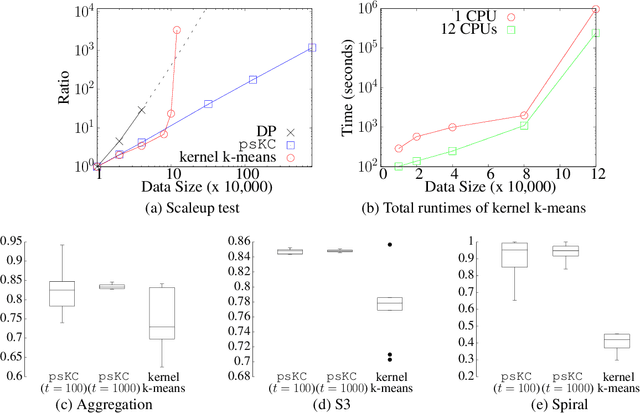
Measuring similarity between two objects is the core operation in existing cluster analyses in grouping similar objects into clusters. Cluster analyses have been applied to a number of applications, including image segmentation, social network analysis, and computational biology. This paper introduces a new similarity measure called point-set kernel which computes the similarity between an object and a sample of objects generated from an unknown distribution. The proposed clustering procedure utilizes this new measure to characterize both the typical point of every cluster and the cluster grown from the typical point. We show that the new clustering procedure is both effective and efficient such that it can deal with large scale datasets. In contrast, existing clustering algorithms are either efficient or effective; and even efficient ones have difficulty dealing with large scale datasets without special hardware. We show that the proposed algorithm is more effective and runs orders of magnitude faster than the state-of-the-art density-peak clustering and scalable kernel k-means clustering when applying to datasets of millions of data points, on commonly used computing machines.
Deep Learning for Automatic Tracking of Tongue Surface in Real-time Ultrasound Videos, Landmarks instead of Contours
Mar 16, 2020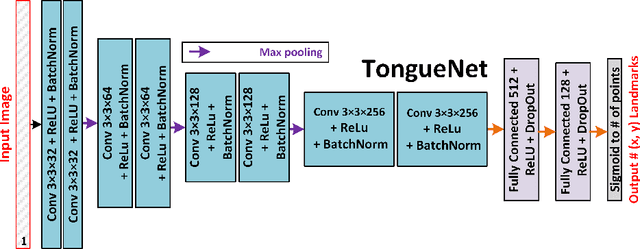

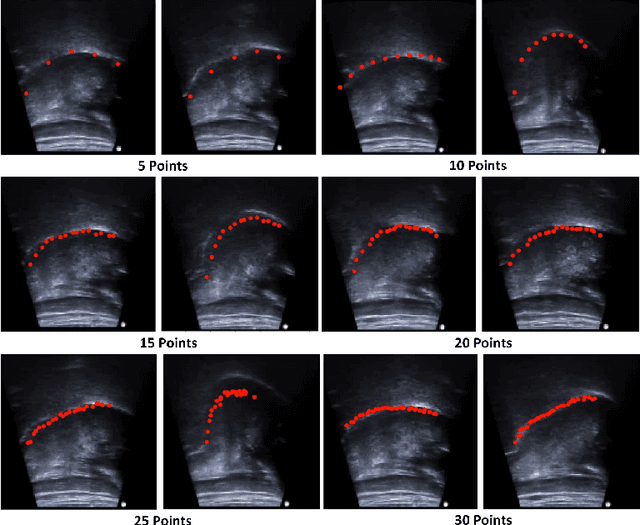
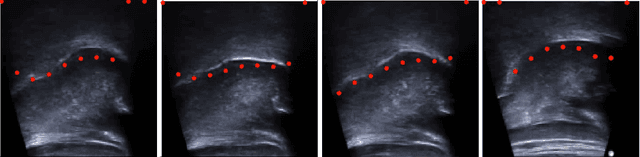
One usage of medical ultrasound imaging is to visualize and characterize human tongue shape and motion during a real-time speech to study healthy or impaired speech production. Due to the low-contrast characteristic and noisy nature of ultrasound images, it might require expertise for non-expert users to recognize tongue gestures in applications such as visual training of a second language. Moreover, quantitative analysis of tongue motion needs the tongue dorsum contour to be extracted, tracked, and visualized. Manual tongue contour extraction is a cumbersome, subjective, and error-prone task. Furthermore, it is not a feasible solution for real-time applications. The growth of deep learning has been vigorously exploited in various computer vision tasks, including ultrasound tongue contour tracking. In the current methods, the process of tongue contour extraction comprises two steps of image segmentation and post-processing. This paper presents a new novel approach of automatic and real-time tongue contour tracking using deep neural networks. In the proposed method, instead of the two-step procedure, landmarks of the tongue surface are tracked. This novel idea enables researchers in this filed to benefits from available previously annotated databases to achieve high accuracy results. Our experiment disclosed the outstanding performances of the proposed technique in terms of generalization, performance, and accuracy.
Real-Time Quality Assessment of Pediatric MRI via Semi-Supervised Deep Nonlocal Residual Neural Networks
Apr 07, 2019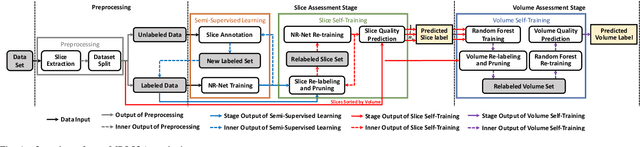
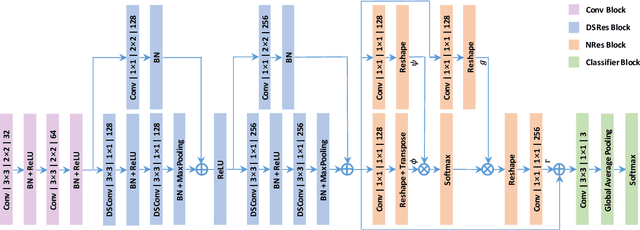
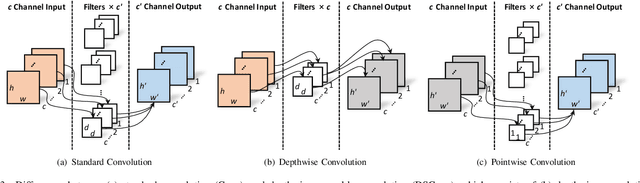
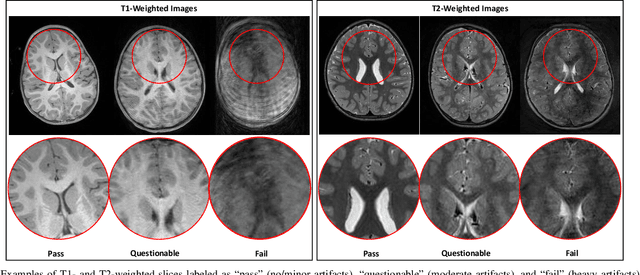
In this paper, we introduce an image quality assessment (IQA) method for pediatric T1- and T2-weighted MR images. IQA is first performed slice-wise using a nonlocal residual neural network (NR-Net) and then volume-wise by agglomerating the slice QA results using random forest. Our method requires only a small amount of quality-annotated images for training and is designed to be robust to annotation noise that might occur due to rater errors and the inevitable mix of good and bad slices in an image volume. Using a small set of quality-assessed images, we pre-train NR-Net to annotate each image slice with an initial quality rating (i.e., pass, questionable, fail), which we then refine by semi-supervised learning and iterative self-training. Experimental results demonstrate that our method, trained using only samples of modest size, exhibit great generalizability, capable of real-time (milliseconds per volume) large-scale IQA with near-perfect accuracy.