 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepIM: Deep Iterative Matching for 6D Pose Estimation
Mar 14, 2019
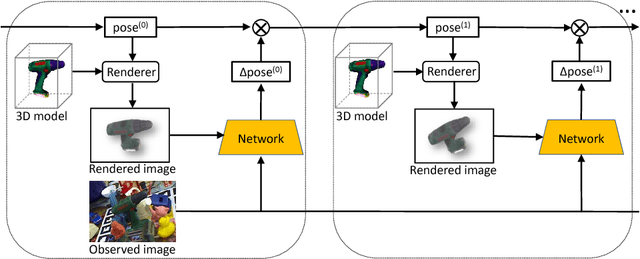
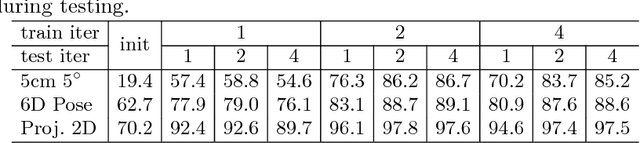
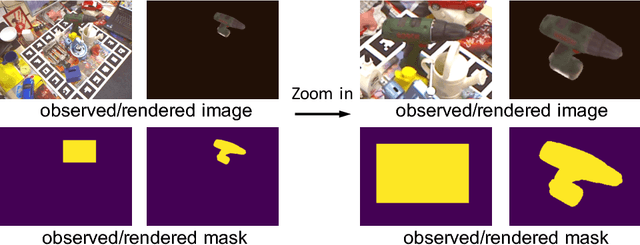
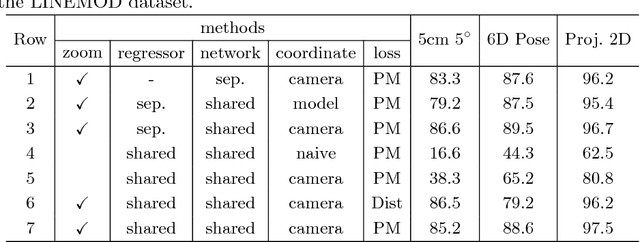
Estimating the 6D pose of objects from images is an important problem in various applications such as robot manipulation and virtual reality. While direct regression of images to object poses has limited accuracy, matching rendered images of an object against the observed image can produce accurate results. In this work, we propose a novel deep neural network for 6D pose matching named DeepIM. Given an initial pose estimation, our network is able to iteratively refine the pose by matching the rendered image against the observed image. The network is trained to predict a relative pose transformation using an untangled representation of 3D location and 3D orientation and an iterative training process. Experiments on two commonly used benchmarks for 6D pose estimation demonstrate that DeepIM achieves large improvements over state-of-the-art methods. We furthermore show that DeepIM is able to match previously unseen objects.
Bi-directional Dermoscopic Feature Learning and Multi-scale Consistent Decision Fusion for Skin Lesion Segmentation
Feb 20, 2020



Accurate segmentation of skin lesion from dermoscopic images is a crucial part of computer-aided diagnosis of melanoma. It is challenging due to the fact that dermoscopic images from different patients have non-negligible lesion variation, which causes difficulties in anatomical structure learning and consistent skin lesion delineation. In this paper, we propose a novel bi-directional dermoscopic feature learning (biDFL) framework to model the complex correlation between skin lesions and their informative context. By controlling feature information passing through two complementary directions, a substantially rich and discriminative feature representation is achieved. Specifically, we place biDFL module on the top of a CNN network to enhance high-level parsing performance. Furthermore, we propose a multi-scale consistent decision fusion (mCDF) that is capable of selectively focusing on the informative decisions generated from multiple classification layers. By analysis of the consistency of the decision at each position, mCDF automatically adjusts the reliability of decisions and thus allows a more insightful skin lesion delineation. The comprehensive experimental results show the effectiveness of the proposed method on skin lesion segmentation, achieving state-of-the-art performance consistently on two publicly available dermoscopic image databases.
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 01, 2020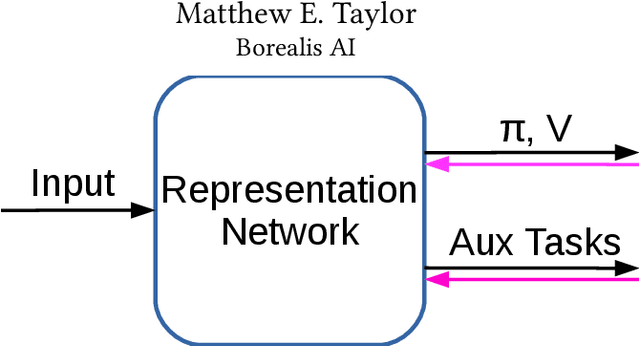

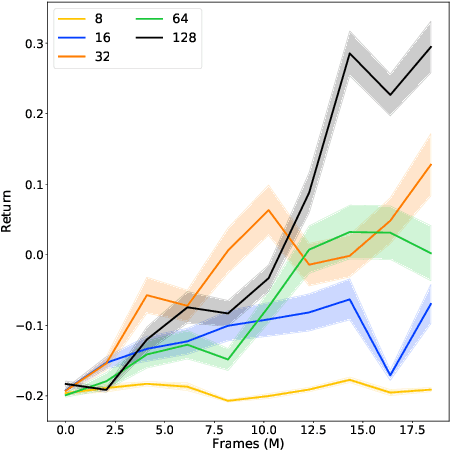
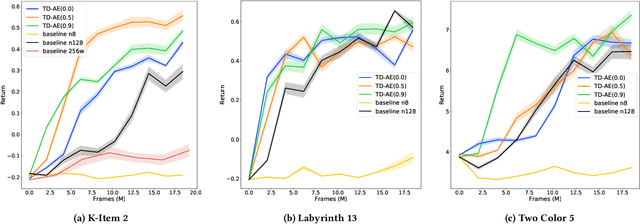
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
FaceFeat-GAN: a Two-Stage Approach for Identity-Preserving Face Synthesis
Dec 04, 2018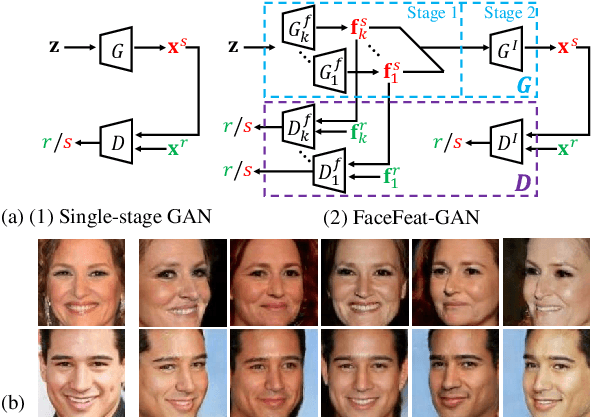

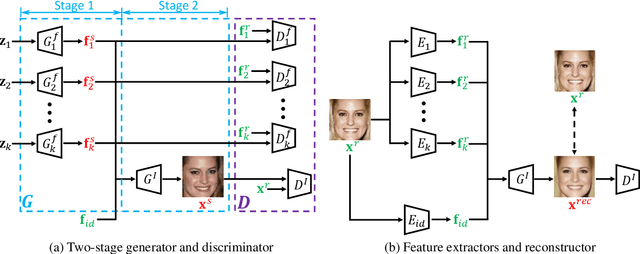
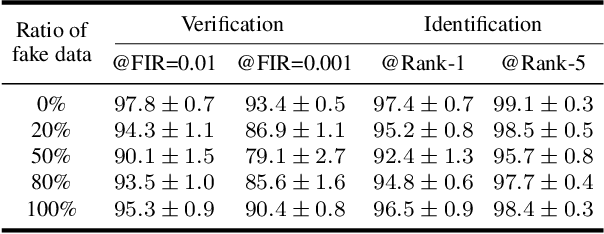
The advance of Generative Adversarial Networks (GANs) enables realistic face image synthesis. However, synthesizing face images that preserve facial identity as well as have high diversity within each identity remains challenging. To address this problem, we present FaceFeat-GAN, a novel generative model that improves both image quality and diversity by using two stages. Unlike existing single-stage models that map random noise to image directly, our two-stage synthesis includes the first stage of diverse feature generation and the second stage of feature-to-image rendering. The competitions between generators and discriminators are carefully designed in both stages with different objective functions. Specially, in the first stage, they compete in the feature domain to synthesize various facial features rather than images. In the second stage, they compete in the image domain to render photo-realistic images that contain high diversity but preserve identity. Extensive experiments show that FaceFeat-GAN generates images that not only retain identity information but also have high diversity and quality, significantly outperforming previous methods.
Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning?
Jun 02, 2017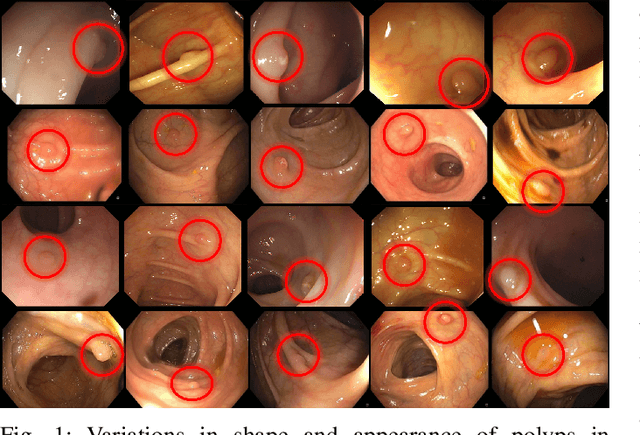
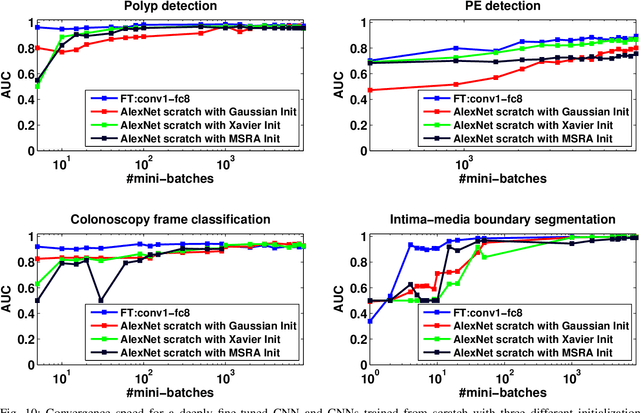
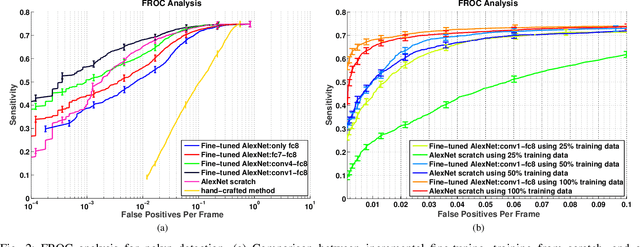
Training a deep convolutional neural network (CNN) from scratch is difficult because it requires a large amount of labeled training data and a great deal of expertise to ensure proper convergence. A promising alternative is to fine-tune a CNN that has been pre-trained using, for instance, a large set of labeled natural images. However, the substantial differences between natural and medical images may advise against such knowledge transfer. In this paper, we seek to answer the following central question in the context of medical image analysis: \emph{Can the use of pre-trained deep CNNs with sufficient fine-tuning eliminate the need for training a deep CNN from scratch?} To address this question, we considered 4 distinct medical imaging applications in 3 specialties (radiology, cardiology, and gastroenterology) involving classification, detection, and segmentation from 3 different imaging modalities, and investigated how the performance of deep CNNs trained from scratch compared with the pre-trained CNNs fine-tuned in a layer-wise manner. Our experiments consistently demonstrated that (1) the use of a pre-trained CNN with adequate fine-tuning outperformed or, in the worst case, performed as well as a CNN trained from scratch; (2) fine-tuned CNNs were more robust to the size of training sets than CNNs trained from scratch; (3) neither shallow tuning nor deep tuning was the optimal choice for a particular application; and (4) our layer-wise fine-tuning scheme could offer a practical way to reach the best performance for the application at hand based on the amount of available data.
A Document Skew Detection Method Using Fast Hough Transform
Dec 05, 2019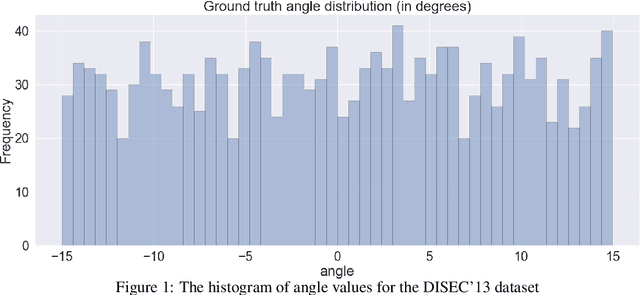
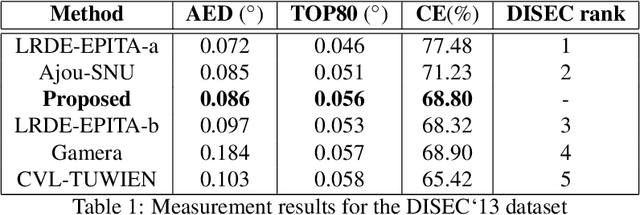
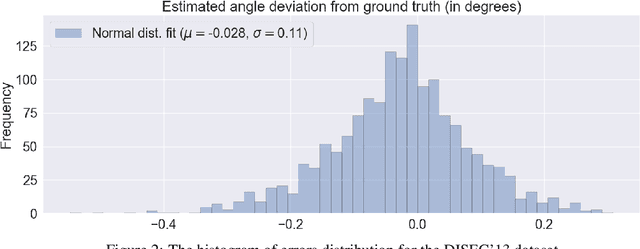
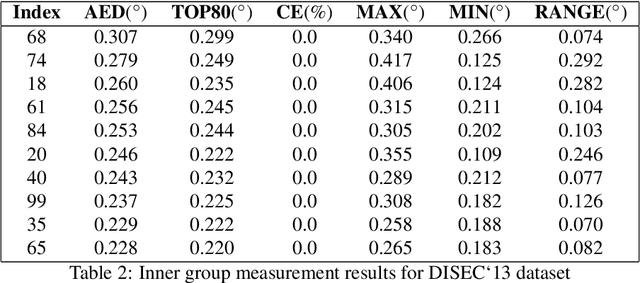
The majority of document image analysis systems use a document skew detection algorithm to simplify all its further processing stages. A huge amount of such algorithms based on Hough transform (HT) analysis has already been proposed. Despite this, we managed to find only one work where the Fast Hough Transform (FHT) usage was suggested to solve the indicated problem. Unfortunately, no study of that method was provided. In this work, we propose and study a skew detection algorithm for the document images which relies on FHT analysis. To measure this algorithm quality we use the dataset from the problem oriented DISEC'13 contest and its evaluation methodology. Obtained values for AED, TOP80, and CE criteria are equal to 0.086, 0.056, 68.80 respectively.
Calibration of fisheye camera using entrance pupil
Jul 03, 2019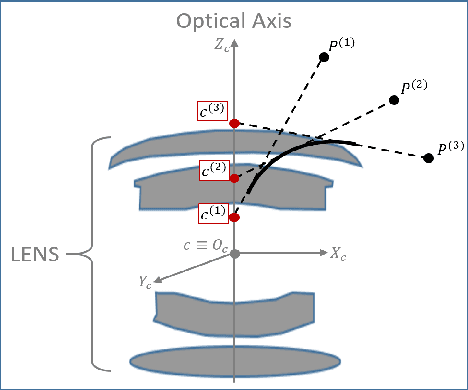
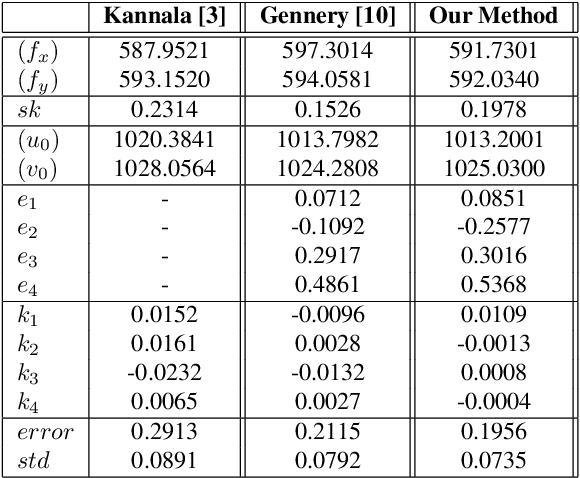
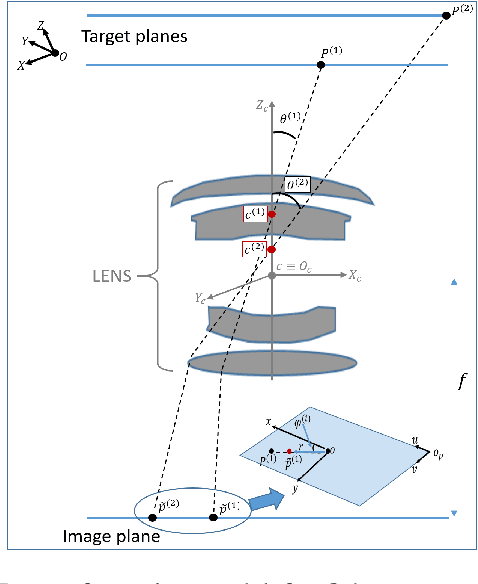
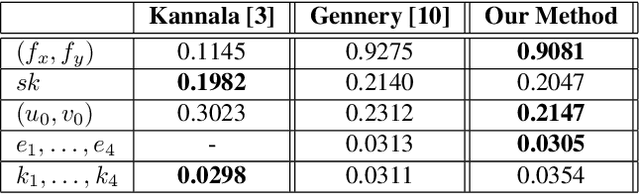
Most conventional camera calibration algorithms assume that the imaging device has a Single Viewpoint (SVP). This is not necessarily true for special imaging device such as fisheye lenses. As a consequence, the intrinsic camera calibration result is not always reliable. In this paper, we propose a new formation model that tends to relax this assumption so that a Non-Single Viewpoint (NSVP) system is corrected to always maintain a SVP, by taking into account the variation of the Entrance Pupil (EP) using thin lens modeling. In addition, we present a calibration procedure for the image formation to estimate these EP parameters using non linear optimization procedure with bundle adjustment. From experiments, we are able to obtain slightly better re-projection error than traditional methods, and the camera parameters are better estimated. The proposed calibration procedure is simple and can easily be integrated to any other thin lens image formation model.
Implementation of the VBM3D Video Denoising Method and Some Variants
Jan 06, 2020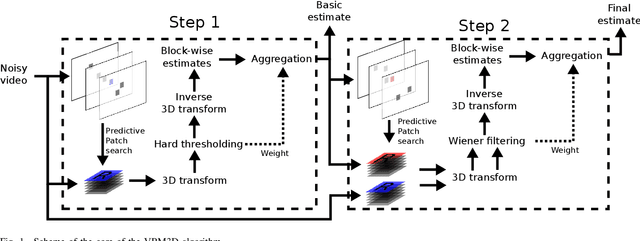
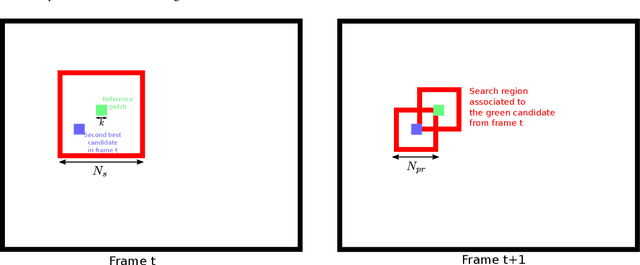


VBM3D is an extension to video of the well known image denoising algorithm BM3D, which takes advantage of the sparse representation of stacks of similar patches in a transform domain. The extension is rather straightforward: the similar 2D patches are taken from a spatio-temporal neighborhood which includes neighboring frames. In spite of its simplicity, the algorithm offers a good trade-off between denoising performance and computational complexity. In this work we revisit this method, providing an open-source C++ implementation reproducing the results. A detailed description is given and the choice of parameters is thoroughly discussed. Furthermore, we discuss several extensions of the original algorithm: (1) a multi-scale implementation, (2) the use of 3D patches, (3) the use of optical flow to guide the patch search. These extensions allow to obtain results which are competitive with even the most recent state of the art.
Online Normalization for Training Neural Networks
May 28, 2019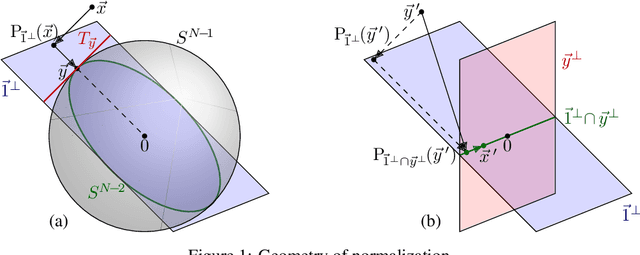
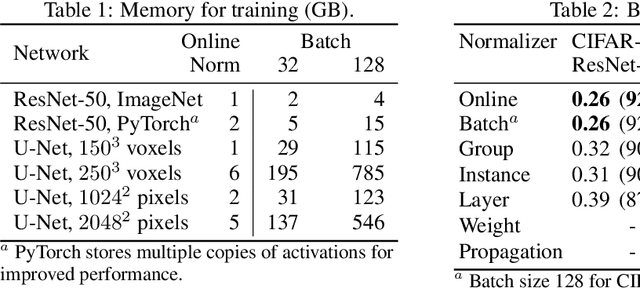
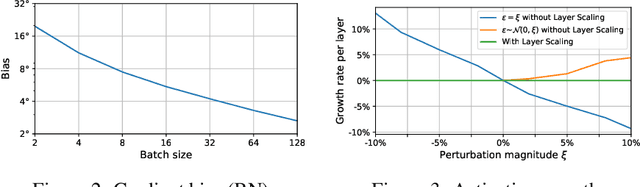
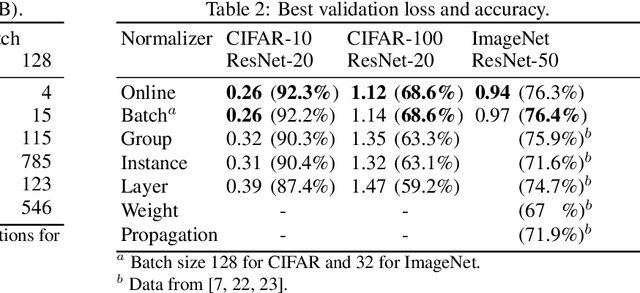
Online Normalization is a new technique for normalizing the hidden activations of a neural network. Like Batch Normalization, it normalizes the sample dimension. While Online Normalization does not use batches, it is as accurate as Batch Normalization. We resolve a theoretical limitation of Batch Normalization by introducing an unbiased technique for computing the gradient of normalized activations. Online Normalization works with automatic differentiation by adding statistical normalization as a primitive. This technique can be used in cases not covered by some other normalizers, such as recurrent networks, fully connected networks, and networks with activation memory requirements prohibitive for batching. We show its applications to image classification, image segmentation, and language modeling. We present formal proofs and experimental results on ImageNet, CIFAR, and PTB datasets.
Signal2Image Modules in Deep Neural Networks for EEG Classification
May 01, 2019
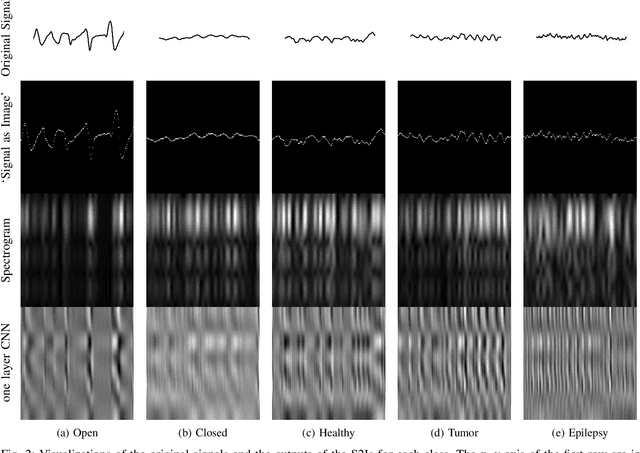
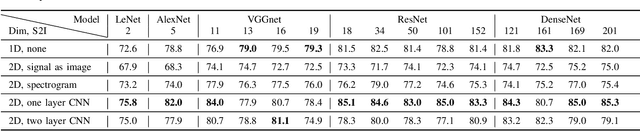
Deep learning has revolutionized computer vision utilizing the increased availability of big data and the power of parallel computational units such as graphical processing units. The vast majority of deep learning research is conducted using images as training data, however the biomedical domain is rich in physiological signals that are used for diagnosis and prediction problems. It is still an open research question how to best utilize signals to train deep neural networks. In this paper we define the term Signal2Image (S2Is) as trainable or non-trainable prefix modules that convert signals, such as Electroencephalography (EEG), to image-like representations making them suitable for training image-based deep neural networks defined as `base models'. We compare the accuracy and time performance of four S2Is (`signal as image', spectrogram, one and two layer Convolutional Neural Networks (CNNs)) combined with a set of `base models' (LeNet, AlexNet, VGGnet, ResNet, DenseNet) along with the depth-wise and 1D variations of the latter. We also provide empirical evidence that the one layer CNN S2I performs better in eleven out of fifteen tested models than non-trainable S2Is for classifying EEG signals and we present visual comparisons of the outputs of the S2Is.