 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Species to Cultivar: Soybean Cultivar Recognition using Multiscale Sliding Chord Matching of Leaf Images
Oct 11, 2019
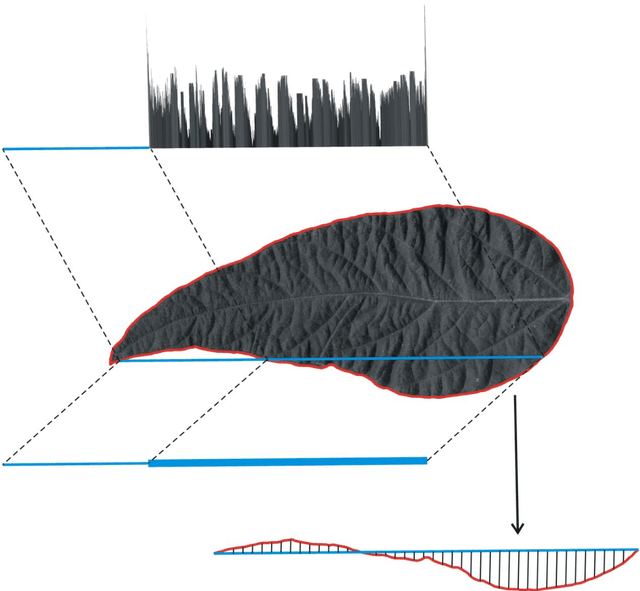
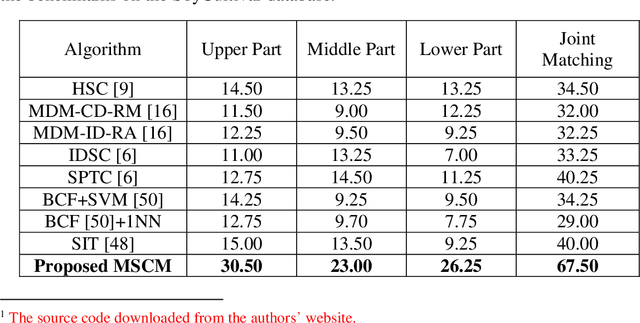
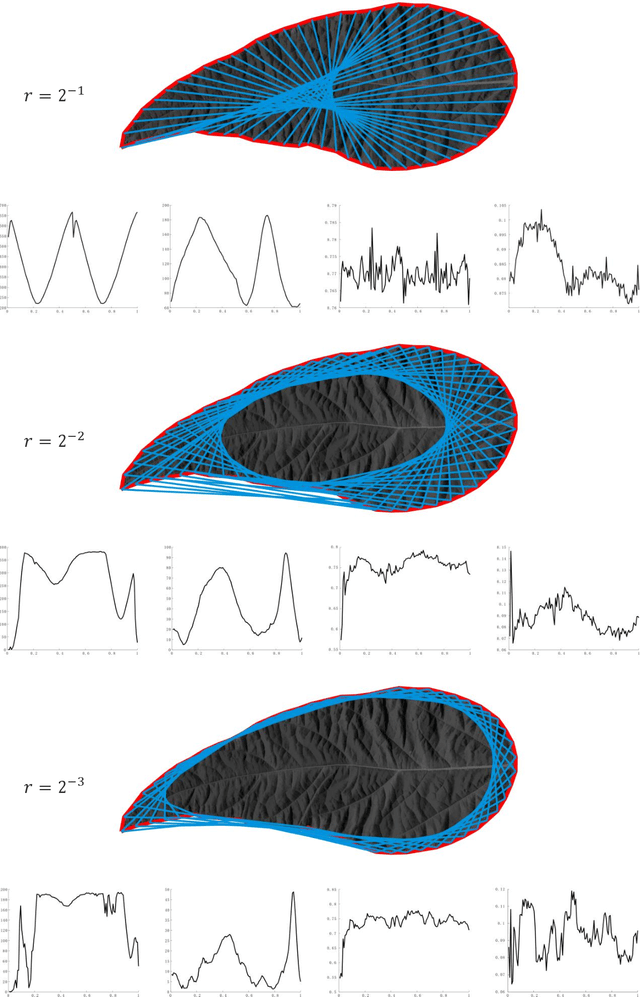
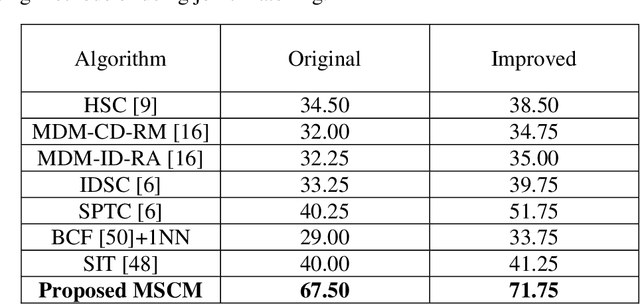
Leaf image recognition techniques have been actively researched for plant species identification. However it remains unclear whether leaf patterns can provide sufficient information for cultivar recognition. This paper reports the first attempt on soybean cultivar recognition from plant leaves which is not only a challenging research problem but also important for soybean cultivar evaluation, selection and production in agriculture. In this paper, we propose a novel multiscale sliding chord matching (MSCM) approach to extract leaf patterns that are distinctive for soybean cultivar identification. A chord is defined to slide along the contour for measuring the synchronised patterns of exterior shape and interior appearance of soybean leaf images. A multiscale sliding chord strategy is developed to extract features in a coarse-to-fine hierarchical order. A joint description that integrates the leaf descriptors from different parts of a soybean plant is proposed for further enhancing the discriminative power of cultivar description. We built a cultivar leaf image database, SoyCultivar, consisting of 1200 sample leaf images from 200 soybean cultivars for performance evaluation. Encouraging experimental results of the proposed method in comparison to the state-of-the-art leaf species recognition methods demonstrate the availability of cultivar information in soybean leaves and effectiveness of the proposed MSCM for soybean cultivar identification, which may advance the research in leaf recognition from species to cultivar.
In Defense of Graph Inference Algorithms for Weakly Supervised Object Localization
Mar 18, 2020
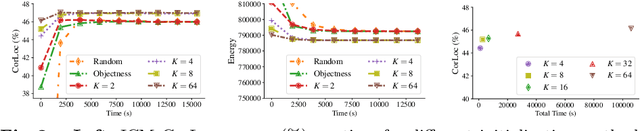


Weakly Supervised Object Localization (WSOL) methods have become increasingly popular since they only require image level labels as opposed to expensive bounding box annotations required by fully supervised algorithms. Typically, a WSOL model is first trained to predict class generic objectness scores on an off-the-shelf fully supervised source dataset and then it is progressively adapted to learn the objects in the weakly supervised target dataset. In this work, we argue that learning only an objectness function is a weak form of knowledge transfer and propose to learn a classwise pairwise similarity function that directly compares two input proposals as well. The combined localization model and the estimated object annotations are jointly learned in an alternating optimization paradigm as is typically done in standard WSOL methods. In contrast to the existing work that learns pairwise similarities, our proposed approach optimizes a unified objective with convergence guarantee and it is computationally efficient for large-scale applications. Experiments on the COCO and ILSVRC 2013 detection datasets show that the performance of the localization model improves significantly with the inclusion of pairwise similarity function. For instance, in the ILSVRC dataset, the Correct Localization (CorLoc) performance improves from 72.7% to 78.2% which is a new state-of-the-art for weakly supervised object localization task.
Using panoramic videos for multi-person localization and tracking in a 3D panoramic coordinate
Nov 24, 2019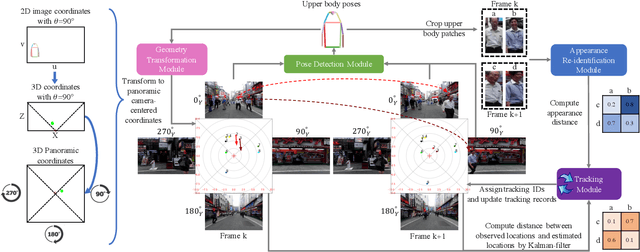
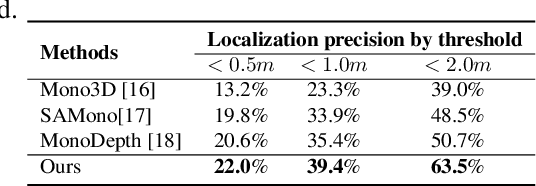
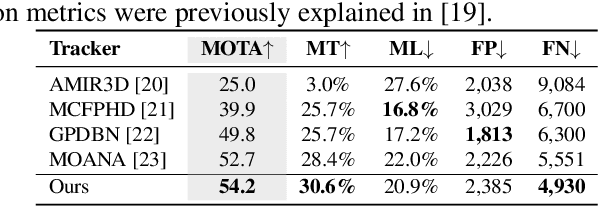
This work proposes a new human-related video processing task named 3D panoramic multi-person localization and tracking. With the first benchmark dataset and a simple yet effective solution, it establishes a new paradigm for multi-person tracking systems and related applications. Unlike existing methods that can only work on a 2D coordinate or a narrow-angle-view 3D coordinate, our proposal can maximally explore the 3D trajectory information of tracking targets. This is approached by applying camera geometry to transform human locations from 2D panoramic image coordinates to a 3D panoramic camera coordinate, and then by applying a tracking algorithm that associates human appearance and 3D trajectory together.
An Artificial Intelligence-Based System to Assess Nutrient Intake for Hospitalised Patients
Mar 18, 2020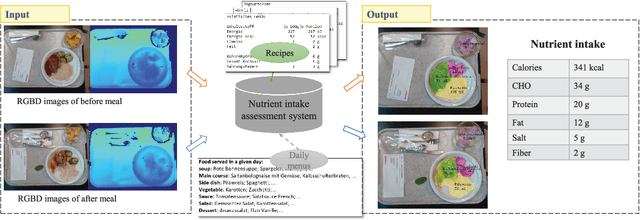
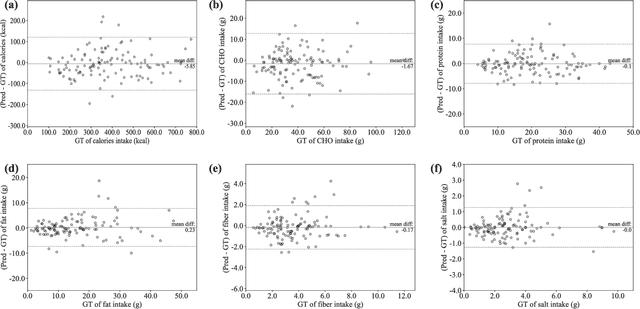
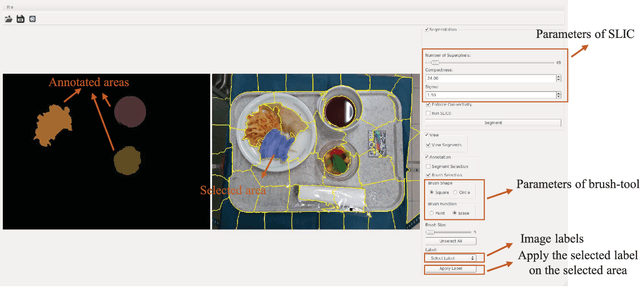
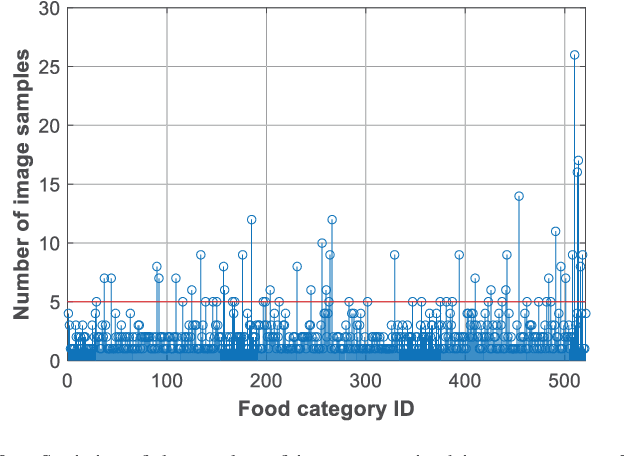
Regular monitoring of nutrient intake in hospitalised patients plays a critical role in reducing the risk of disease-related malnutrition. Although several methods to estimate nutrient intake have been developed, there is still a clear demand for a more reliable and fully automated technique, as this could improve data accuracy and reduce both the burden on participants and health costs. In this paper, we propose a novel system based on artificial intelligence (AI) to accurately estimate nutrient intake, by simply processing RGB Depth (RGB-D) image pairs captured before and after meal consumption. The system includes a novel multi-task contextual network for food segmentation, a few-shot learning-based classifier built by limited training samples for food recognition, and an algorithm for 3D surface construction. This allows sequential food segmentation, recognition, and estimation of the consumed food volume, permitting fully automatic estimation of the nutrient intake for each meal. For the development and evaluation of the system, a dedicated new database containing images and nutrient recipes of 322 meals is assembled, coupled to data annotation using innovative strategies. Experimental results demonstrate that the estimated nutrient intake is highly correlated (> 0.91) to the ground truth and shows very small mean relative errors (< 20%), outperforming existing techniques proposed for nutrient intake assessment.
Pose Neural Fabrics Search
Sep 24, 2019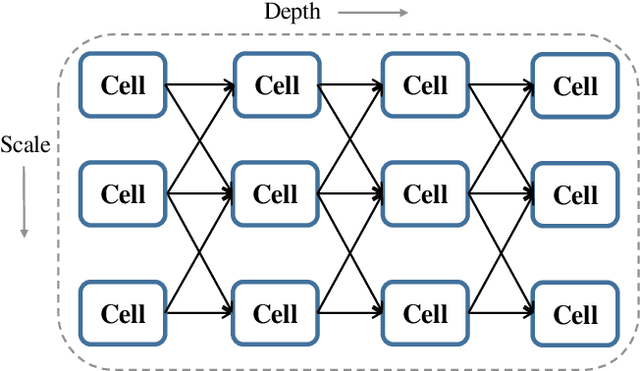
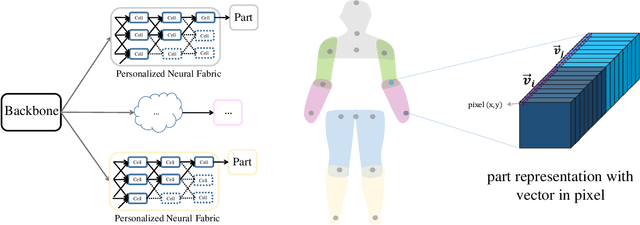
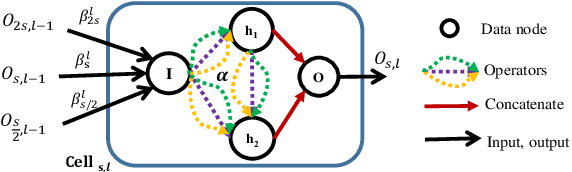
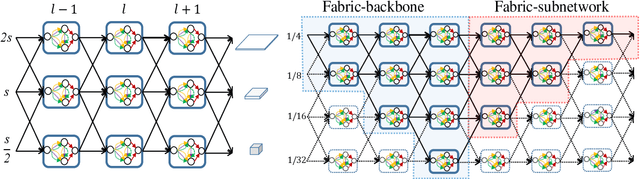
Neural Architecture Search (NAS) technologies have been successfully performed for efficient neural architectures for tasks such as image classification and semantic segmentation. However, existing works implement NAS for target tasks independently of domain knowledge and focus only on searching for an architecture to replace the human-designed network in a common pipeline. \emph{Can we exploit human prior knowledge to guide NAS?} To address it, we propose a framework, named Pose Neural Fabrics Search (PNFS), introducing prior knowledge of body structure into NAS for human pose estimation. We lead a new neural architecture search space, by parameterizing cell-based neural fabric, to learn micro as well as macro neural architecture using a differentiable search strategy. To take advantage of part-based structural knowledge of the human body and learning capability of NAS, global pose constraint relationships are modeled as multiple part representations, each of which is predicted by a personalized cell-based neural fabric. In part representation, we view human skeleton keypoints as entities by representing them as vectors at image locations, expecting it to capture keypoint's feature in a relaxed vector space. The experiments on MPII and MS-COCO datasets demonstrate that PNFS can achieve comparable performance to state-of-the-art methods, with fewer parameters and lower computational complexity.
Weakly Supervised Object Detection with 2D and 3D Regression Neural Networks
Jun 05, 2019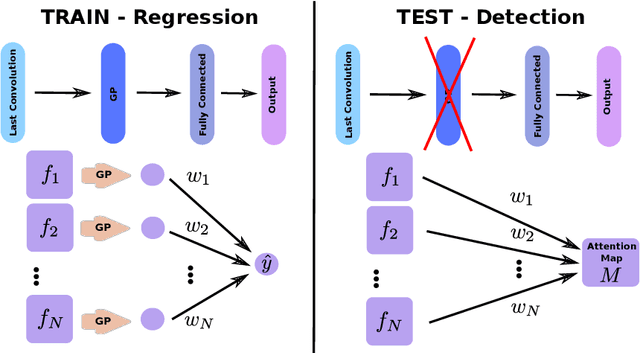


Weakly supervised detection methods can infer the location of target objects in an image without requiring location or appearance information during training. We propose a weakly supervised deep learning method for the detection of objects that appear at multiple locations in an image. The method computes attention maps using the last feature maps of an encoder-decoder network optimized only with global labels: the number of occurrences of the target object in an image. In contrast with previous approaches, attention maps are generated at full input resolution thanks to the decoder part. The proposed approach is compared to multiple state-of-the-art methods in two tasks: the detection of digits in MNIST-based datasets, and the real life application of detection of enlarged perivascular spaces -- a type of brain lesion -- in four brain regions in a dataset of 2202 3D brain MRI scans. In MNIST-based datasets, the proposed method outperforms the other methods. In the brain dataset, several weakly supervised detection methods come close to the human intrarater agreement in each region. The proposed method reaches the lowest number of false positive detections in all brain regions at the operating point, while its average sensitivity is similar to that of the other best methods.
Joint Denoising / Compression of Image Contours via Shape Prior and Context Tree
Apr 30, 2017
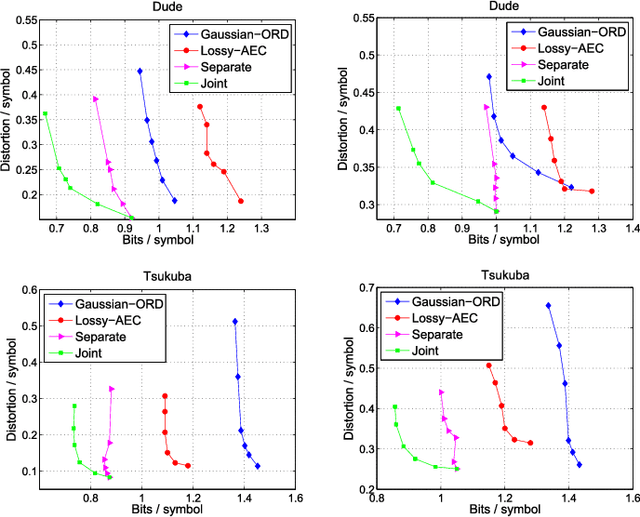
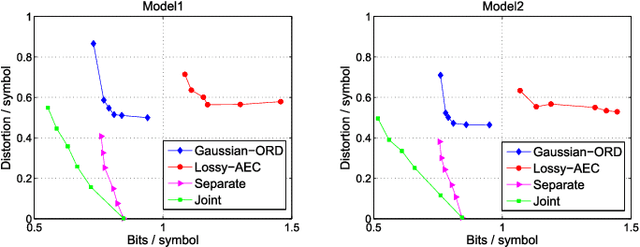
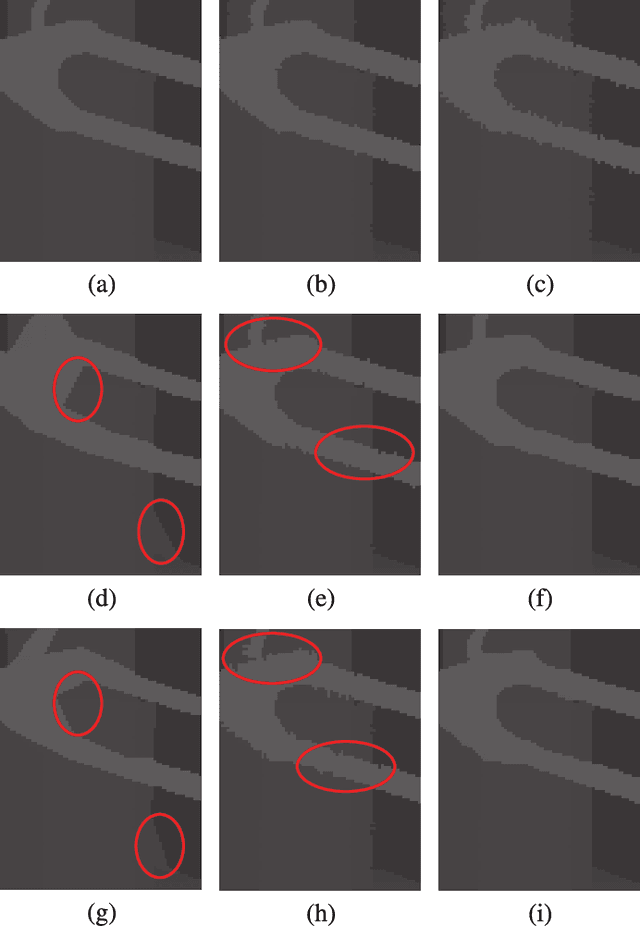
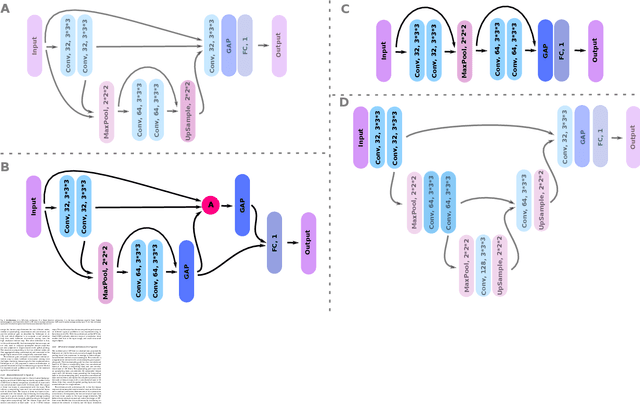
With the advent of depth sensing technologies, the extraction of object contours in images---a common and important pre-processing step for later higher-level computer vision tasks like object detection and human action recognition---has become easier. However, acquisition noise in captured depth images means that detected contours suffer from unavoidable errors. In this paper, we propose to jointly denoise and compress detected contours in an image for bandwidth-constrained transmission to a client, who can then carry out aforementioned application-specific tasks using the decoded contours as input. We first prove theoretically that in general a joint denoising / compression approach can outperform a separate two-stage approach that first denoises then encodes contours lossily. Adopting a joint approach, we first propose a burst error model that models typical errors encountered in an observed string y of directional edges. We then formulate a rate-constrained maximum a posteriori (MAP) problem that trades off the posterior probability p(x'|y) of an estimated string x' given y with its code rate R(x'). We design a dynamic programming (DP) algorithm that solves the posed problem optimally, and propose a compact context representation called total suffix tree (TST) that can reduce complexity of the algorithm dramatically. Experimental results show that our joint denoising / compression scheme outperformed a competing separate scheme in rate-distortion performance noticeably.
Convex Shape Prior for Deep Neural Convolution Network based Eye Fundus Images Segmentation
May 15, 2020
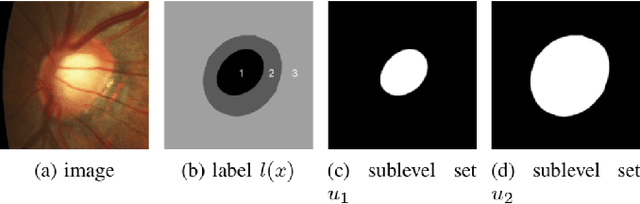
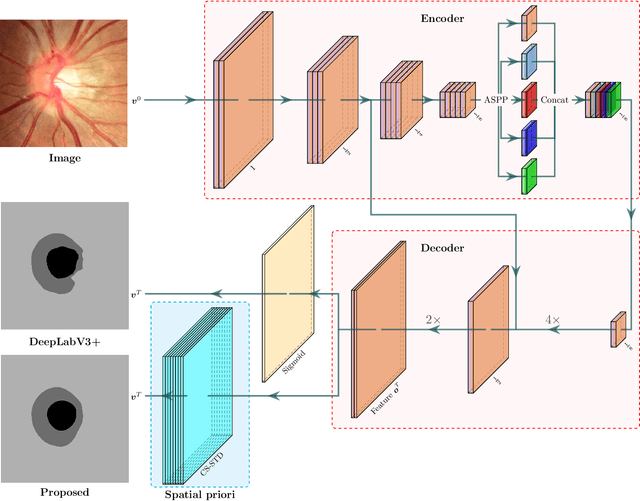

Convex Shapes (CS) are common priors for optic disc and cup segmentation in eye fundus images. It is important to design proper techniques to represent convex shapes. So far, it is still a problem to guarantee that the output objects from a Deep Neural Convolution Networks (DCNN) are convex shapes. In this work, we propose a technique which can be easily integrated into the commonly used DCNNs for image segmentation and guarantee that outputs are convex shapes. This method is flexible and it can handle multiple objects and allow some of the objects to be convex. Our method is based on the dual representation of the sigmoid activation function in DCNNs. In the dual space, the convex shape prior can be guaranteed by a simple quadratic constraint on a binary representation of the shapes. Moreover, our method can also integrate spatial regularization and some other shape prior using a soft thresholding dynamics (STD) method. The regularization can make the boundary curves of the segmentation objects to be simultaneously smooth and convex. We design a very stable active set projection algorithm to numerically solve our model. This algorithm can form a new plug-and-play DCNN layer called CS-STD whose outputs must be a nearly binary segmentation of convex objects. In the CS-STD block, the convexity information can be propagated to guide the DCNN in both forward and backward propagation during training and prediction process. As an application example, we apply the convexity prior layer to the retinal fundus images segmentation by taking the popular DeepLabV3+ as a backbone network. Experimental results on several public datasets show that our method is efficient and outperforms the classical DCNN segmentation methods.
AGE Challenge: Angle Closure Glaucoma Evaluation in Anterior Segment Optical Coherence Tomography
May 05, 2020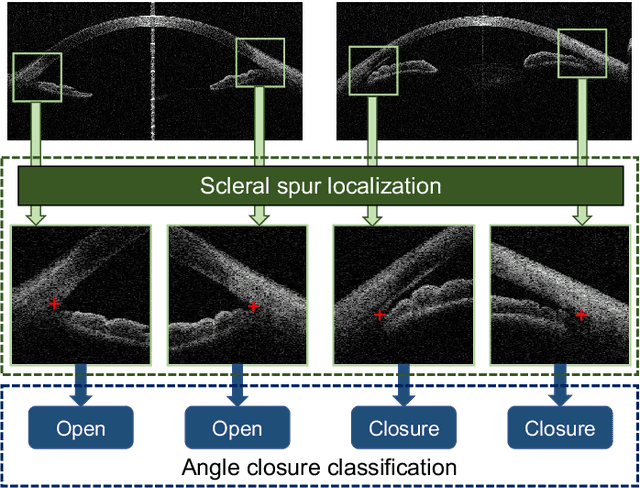
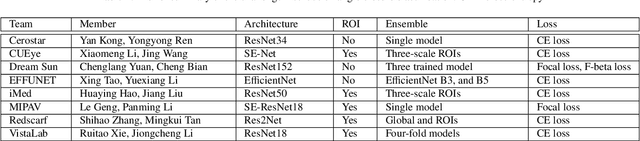
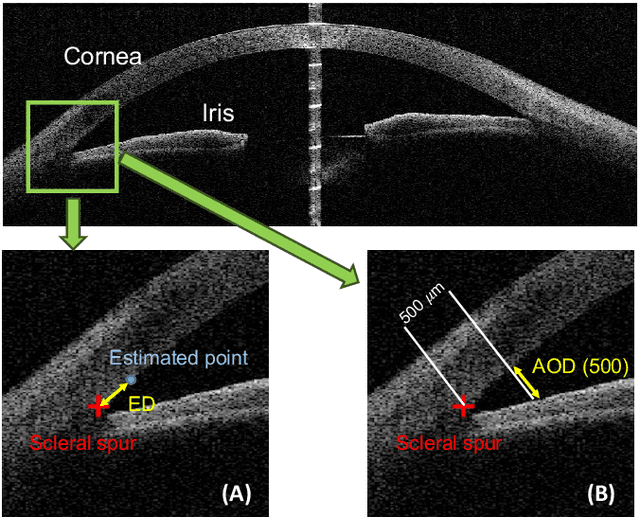
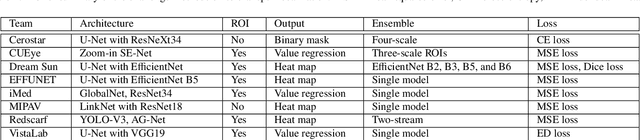
Angle closure glaucoma (ACG) is a more aggressive disease than open-angle glaucoma, where the abnormal anatomical structures of the anterior chamber angle (ACA) may cause an elevated intraocular pressure and gradually leads to glaucomatous optic neuropathy and eventually to visual impairment and blindness. Anterior Segment Optical Coherence Tomography (AS-OCT) imaging provides a fast and contactless way to discriminate angle closure from open angle. Although many medical image analysis algorithms have been developed for glaucoma diagnosis, only a few studies have focused on AS-OCT imaging. In particular, there is no public AS-OCT dataset available for evaluating the existing methods in a uniform way, which limits the progress in the development of automated techniques for angle closure detection and assessment. To address this, we organized the Angle closure Glaucoma Evaluation challenge (AGE), held in conjunction with MICCAI 2019. The AGE challenge consisted of two tasks: scleral spur localization and angle closure classification. For this challenge, we released a large data of 4800 annotated AS-OCT images from 199 patients, and also proposed an evaluation framework to benchmark and compare different models. During the AGE challenge, over 200 teams registered online, and more than 1100 results were submitted for online evaluation. Finally, eight teams participated in the onsite challenge. In this paper, we summarize these eight onsite challenge methods and analyze their corresponding results in the two tasks. We further discuss limitations and future directions. In the AGE challenge, the top-performing approach had an average Euclidean Distance of 10 pixel in scleral spur localization, while in the task of angle closure classification, all the algorithms achieved the satisfactory performances, especially, 100% accuracy rate for top-two performances.
TripletUNet: Multi-Task U-Net with Online Voxel-Wise Learning for Precise CT Prostate Segmentation
May 15, 2020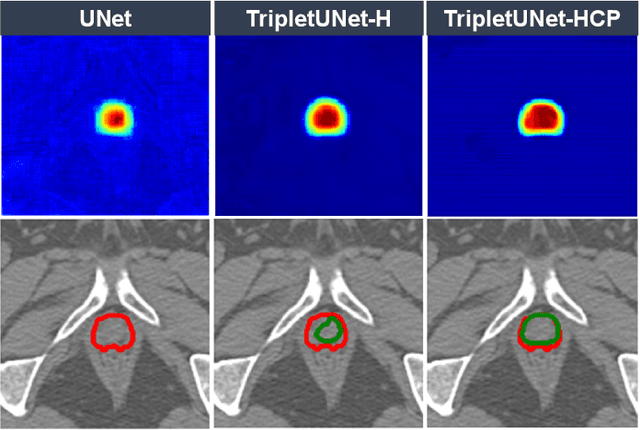
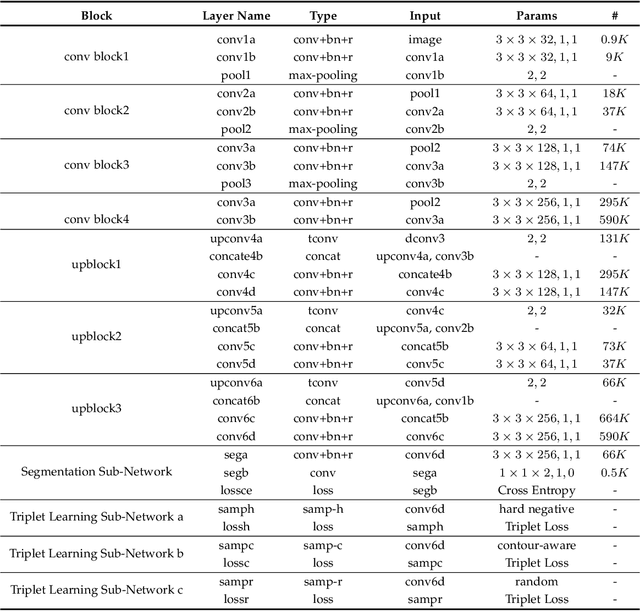
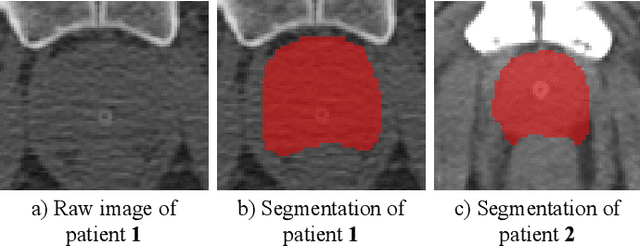
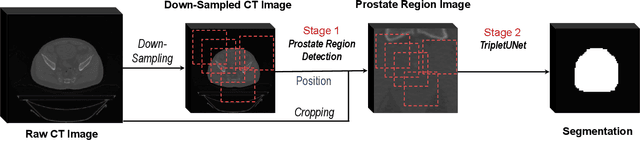
Fully convolutional networks (FCNs), including U-Net and V-Net, are widely-used network architecture for semantic segmentation in recent studies. However, conventional FCNs are typically trained by the cross-entropy loss or dice loss, in which the relationships among voxels are neglected. This often results in non-smooth neighborhoods in the output segmentation map. This problem becomes more serious in CT prostate segmentation as CT images are usually of low tissue contrast. To address this problem, we propose a two-stage framework. The first stage quickly localizes the prostate region. Then, the second stage precisely segments the prostate by a multi-task FCN-based on the U-Net architecture. We introduce a novel online voxel-triplet learning module through metric learning and voxel feature embeddings in the multi-task network. The proposed network has two branches guided by two tasks: 1) a segmentation sub-network aiming to generate prostate segmentation, and 2) a triplet learning sub-network aiming to improve the quality of the learned feature space supervised by a mixed of triplet and pair-wise loss function. The triplet learning sub-network samples triplets from the inter-mediate heatmap. Unlike conventional deep triplet learning methods that generate triplets before the training phase, our proposed voxel-triplets are sampled in an online manner and operates in an end-to-end fashion via multi-task learning. To evaluate the proposed method, we implement comprehensive experiments on a CT image dataset consisting of 339 patients. The ablation studies show that our method can effectively learn more representative voxel-level features compared with the conventional FCN network. And the comparisons show that the proposed method outperforms the state-of-the-art methods by a large margin.