 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning?
Jun 02, 2017
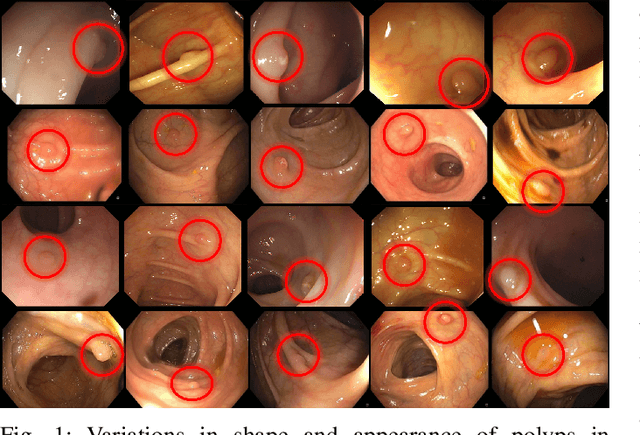
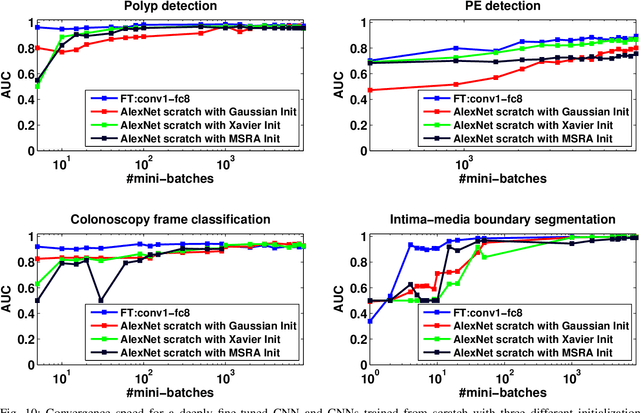
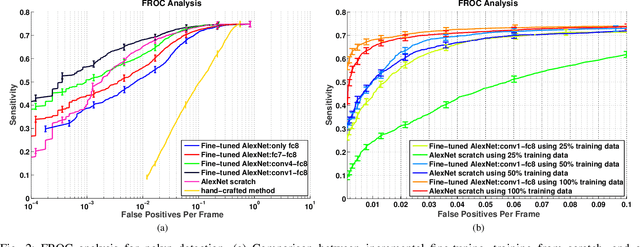
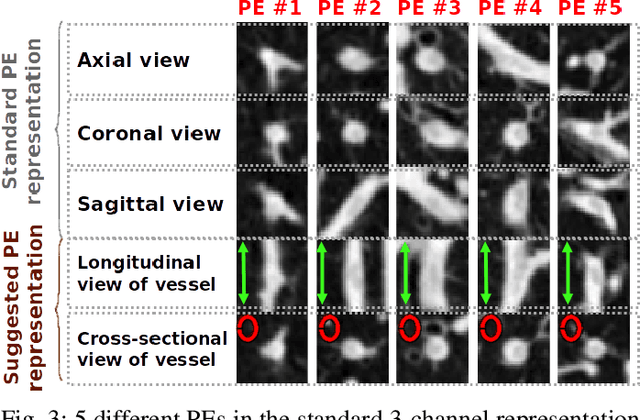
Training a deep convolutional neural network (CNN) from scratch is difficult because it requires a large amount of labeled training data and a great deal of expertise to ensure proper convergence. A promising alternative is to fine-tune a CNN that has been pre-trained using, for instance, a large set of labeled natural images. However, the substantial differences between natural and medical images may advise against such knowledge transfer. In this paper, we seek to answer the following central question in the context of medical image analysis: \emph{Can the use of pre-trained deep CNNs with sufficient fine-tuning eliminate the need for training a deep CNN from scratch?} To address this question, we considered 4 distinct medical imaging applications in 3 specialties (radiology, cardiology, and gastroenterology) involving classification, detection, and segmentation from 3 different imaging modalities, and investigated how the performance of deep CNNs trained from scratch compared with the pre-trained CNNs fine-tuned in a layer-wise manner. Our experiments consistently demonstrated that (1) the use of a pre-trained CNN with adequate fine-tuning outperformed or, in the worst case, performed as well as a CNN trained from scratch; (2) fine-tuned CNNs were more robust to the size of training sets than CNNs trained from scratch; (3) neither shallow tuning nor deep tuning was the optimal choice for a particular application; and (4) our layer-wise fine-tuning scheme could offer a practical way to reach the best performance for the application at hand based on the amount of available data.
Calibration of fisheye camera using entrance pupil
Jul 03, 2019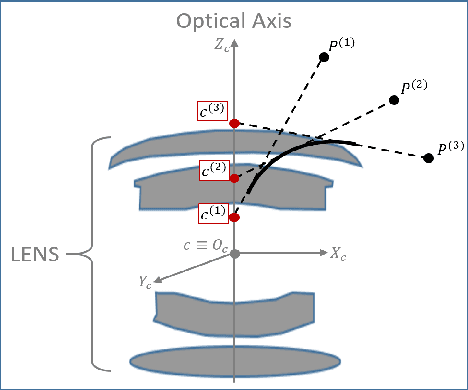
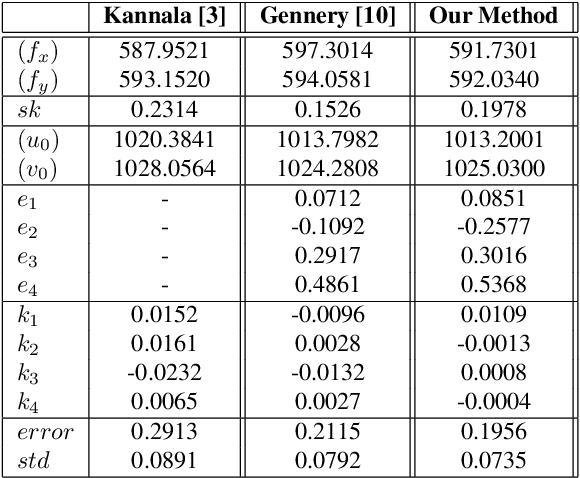
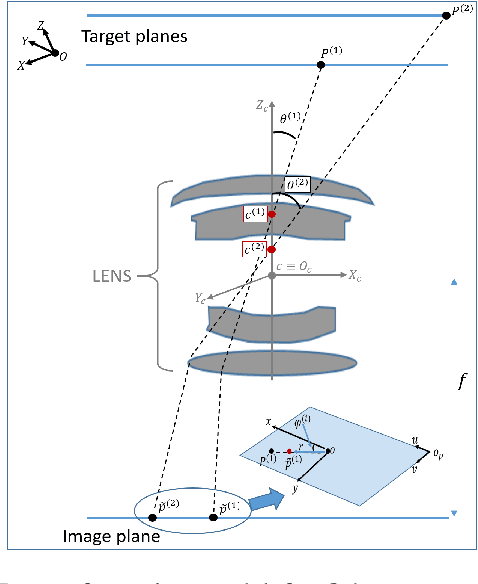
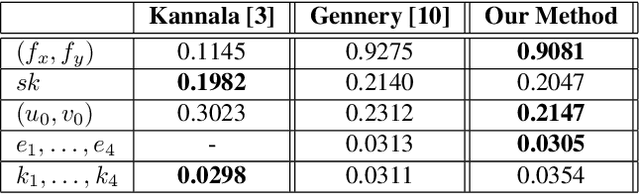
Most conventional camera calibration algorithms assume that the imaging device has a Single Viewpoint (SVP). This is not necessarily true for special imaging device such as fisheye lenses. As a consequence, the intrinsic camera calibration result is not always reliable. In this paper, we propose a new formation model that tends to relax this assumption so that a Non-Single Viewpoint (NSVP) system is corrected to always maintain a SVP, by taking into account the variation of the Entrance Pupil (EP) using thin lens modeling. In addition, we present a calibration procedure for the image formation to estimate these EP parameters using non linear optimization procedure with bundle adjustment. From experiments, we are able to obtain slightly better re-projection error than traditional methods, and the camera parameters are better estimated. The proposed calibration procedure is simple and can easily be integrated to any other thin lens image formation model.
Deep Cerebellar Nuclei Segmentation via Semi-Supervised Deep Context-Aware Learning from 7T Diffusion MRI
Apr 21, 2020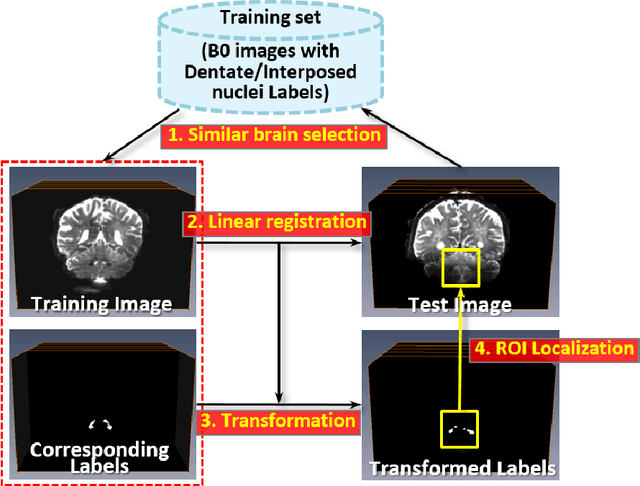
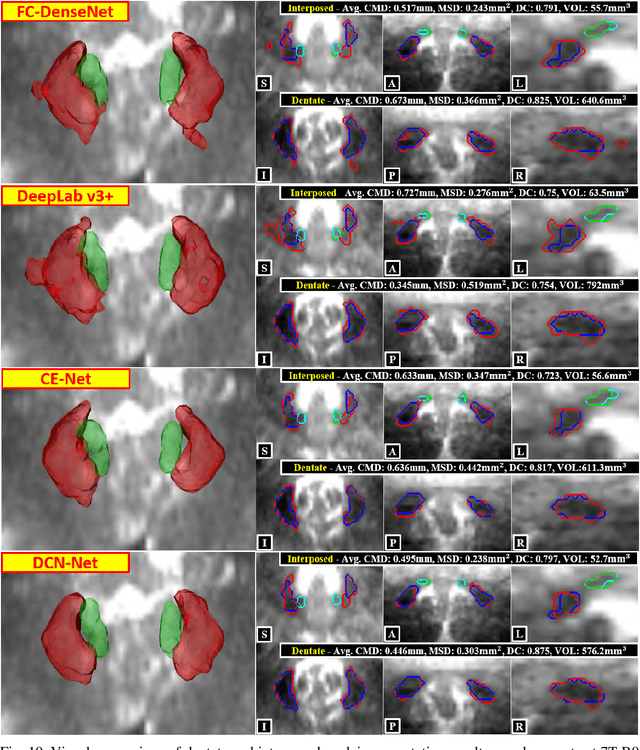
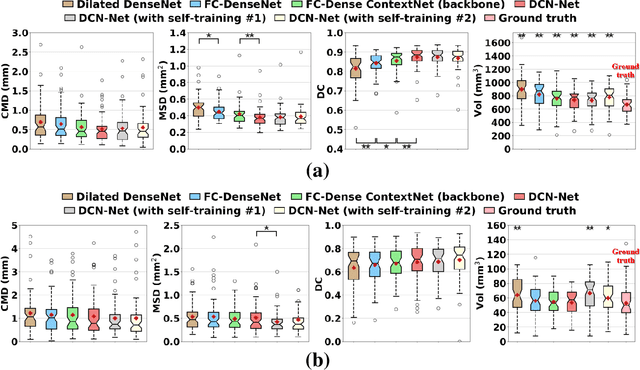
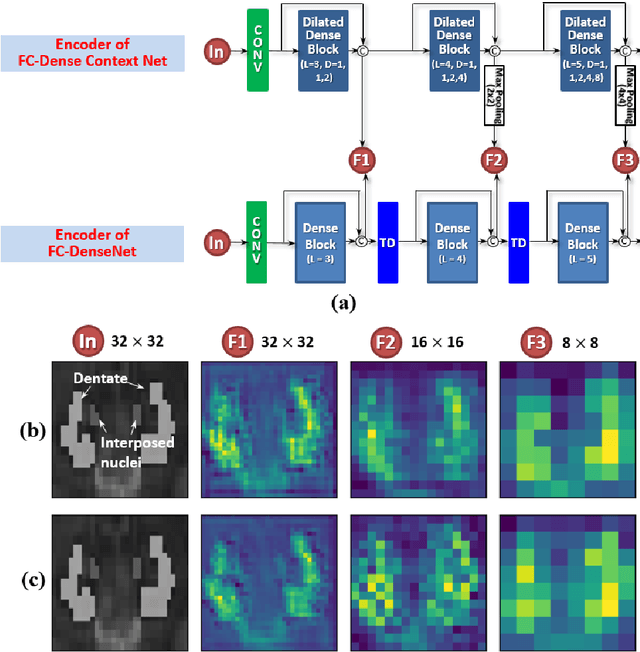
Deep cerebellar nuclei are a key structure of the cerebellum that are involved in processing motor and sensory information. It is thus a crucial step to precisely segment deep cerebellar nuclei for the understanding of the cerebellum system and its utility in deep brain stimulation treatment. However, it is challenging to clearly visualize such small nuclei under standard clinical magnetic resonance imaging (MRI) protocols and therefore an automatic patient-specific segmentation is not feasible. Recent advances in 7 Tesla (T) MRI technology and great potential of deep neural networks facilitate automatic, fast, and accurate segmentation. In this paper, we propose a novel deep learning framework (referred to as DCN-Net) for the segmentation of deep cerebellar dentate and interposed nuclei on 7T diffusion MRI. DCN-Net effectively encodes contextual information on the image patches without consecutive pooling operations and adding complexity via proposed dilated dense blocks. During the end-to-end training, label probabilities of dentate and interposed nuclei are independently learned with a hybrid loss, handling highly imbalanced data. Finally, we utilize self-training strategies to cope with the problem of limited labeled data. To this end, auxiliary dentate and interposed nuclei labels are created on unlabeled data by using DCN-Net trained on manual labels. We validate the proposed framework using 7T B0 MRIs from 60 subjects. Experimental results demonstrate that DCN-Net provides better segmentation than atlas-based deep cerebellar nuclei segmentation tools and other state-of-the-art deep neural networks in terms of accuracy and consistency. We further prove the effectiveness of the proposed components within DCN-Net in dentate and interposed nuclei segmentation.
Finding Significant Subregions in Large Image Databases
Jun 19, 2009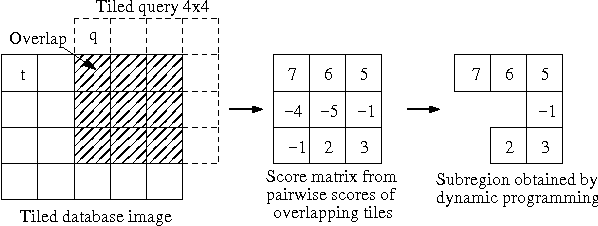

Images have become an important data source in many scientific and commercial domains. Analysis and exploration of image collections often requires the retrieval of the best subregions matching a given query. The support of such content-based retrieval requires not only the formulation of an appropriate scoring function for defining relevant subregions but also the design of new access methods that can scale to large databases. In this paper, we propose a solution to this problem of querying significant image subregions. We design a scoring scheme to measure the similarity of subregions. Our similarity measure extends to any image descriptor. All the images are tiled and each alignment of the query and a database image produces a tile score matrix. We show that the problem of finding the best connected subregion from this matrix is NP-hard and develop a dynamic programming heuristic. With this heuristic, we develop two index based scalable search strategies, TARS and SPARS, to query patterns in a large image repository. These strategies are general enough to work with other scoring schemes and heuristics. Experimental results on real image datasets show that TARS saves more than 87% query time on small queries, and SPARS saves up to 52% query time on large queries as compared to linear search. Qualitative tests on synthetic and real datasets achieve precision of more than 80%.
* 16 pages, 48 figures
ImagineNet: Restyling Apps Using Neural Style Transfer
Jan 14, 2020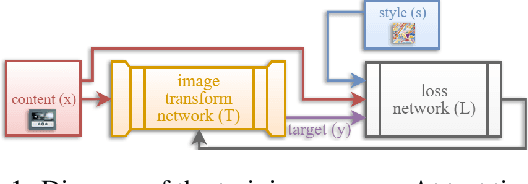

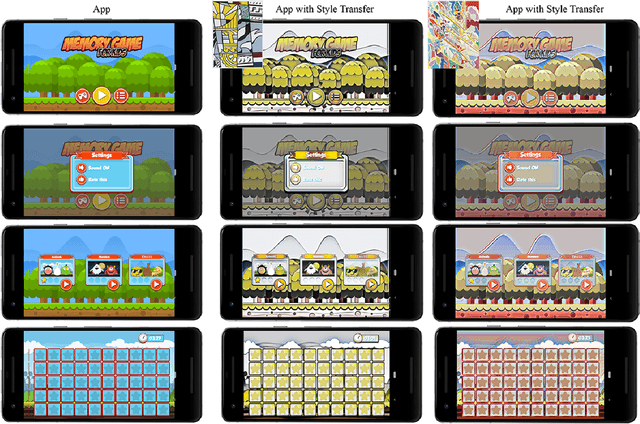
This paper presents ImagineNet, a tool that uses a novel neural style transfer model to enable end-users and app developers to restyle GUIs using an image of their choice. Former neural style transfer techniques are inadequate for this application because they produce GUIs that are illegible and hence nonfunctional. We propose a neural solution by adding a new loss term to the original formulation, which minimizes the squared error in the uncentered cross-covariance of features from different levels in a CNN between the style and output images. ImagineNet retains the details of GUIs, while transferring the colors and textures of the art. We presented GUIs restyled with ImagineNet as well as other style transfer techniques to 50 evaluators and all preferred those of ImagineNet. We show how ImagineNet can be used to restyle (1) the graphical assets of an app, (2) an app with user-supplied content, and (3) an app with dynamically generated GUIs.
SiamSNN: Spike-based Siamese Network for Energy-Efficient and Real-time Object Tracking
Mar 17, 2020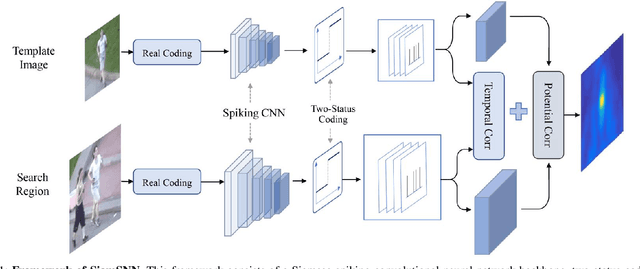
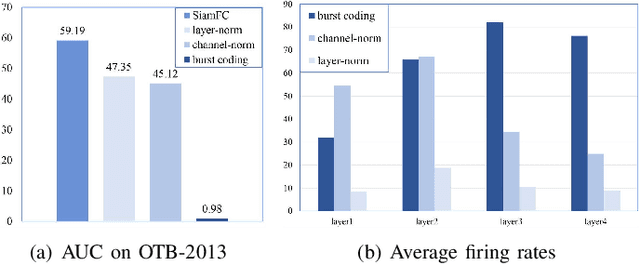
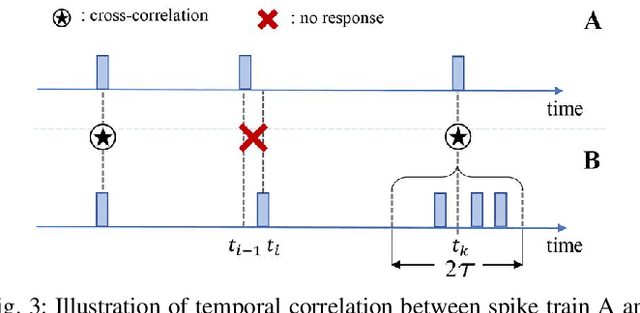
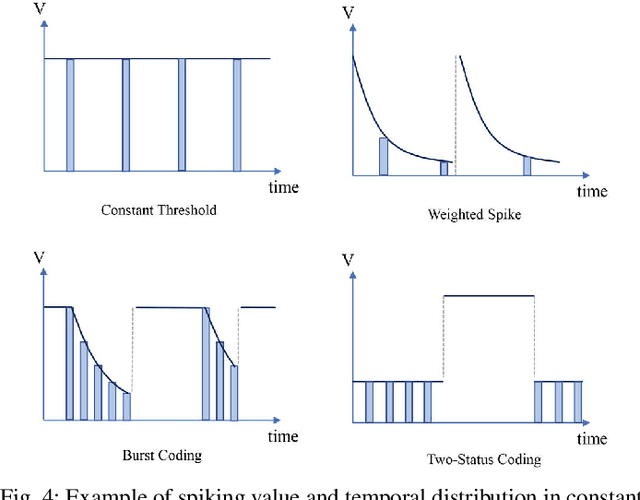
Although deep neural networks (DNNs) have achieved fantastic success in various scenarios, it's difficult to employ DNNs on many systems with limited resources due to their high energy consumption. It's well known that spiking neural networks (SNNs) are attracting more attention due to the capability of energy-efficient computing. Recently many works focus on converting DNNs into SNNs with little accuracy degradation in image classification on MNIST, CIFAR-10/100. However, few studies on shortening latency, and spike-based modules of more challenging tasks on complex datasets. In this paper, we focus on the similarity matching method of deep spike features and present a first spike-based Siamese network for object tracking called SiamSNN. Specifically, we propose a hybrid spiking similarity matching method with membrane potential and time step to evaluate the response map between exemplar and candidate images, with the same function as correlation layer in SiamFC. Then we present a coding scheme for utilizing temporal information of spike trains, and implement it in output spiking layers to improve the performance and shorten the latency. Our experiments show that SiamSNN achieves short latency and low precision loss of the original SiamFC on the tracking datasets OTB-2013, OTB-2015 and VOT2016. Moreover, SiamSNN achieves real-time (50 FPS) and extremely low energy consumption on TrueNorth.
Automatic vehicle tracking and recognition from aerial image sequences
Jun 23, 2015

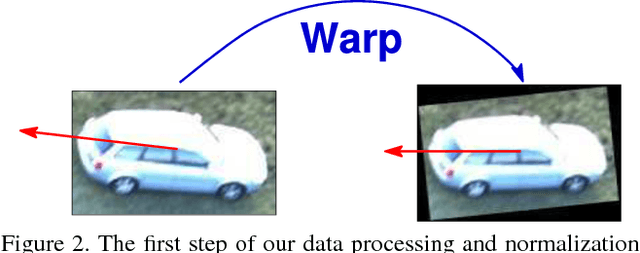
This paper addresses the problem of automated vehicle tracking and recognition from aerial image sequences. Motivated by its successes in the existing literature focus on the use of linear appearance subspaces to describe multi-view object appearance and highlight the challenges involved in their application as a part of a practical system. A working solution which includes steps for data extraction and normalization is described. In experiments on real-world data the proposed methodology achieved promising results with a high correct recognition rate and few, meaningful errors (type II errors whereby genuinely similar targets are sometimes being confused with one another). Directions for future research and possible improvements of the proposed method are discussed.
Online Normalization for Training Neural Networks
May 28, 2019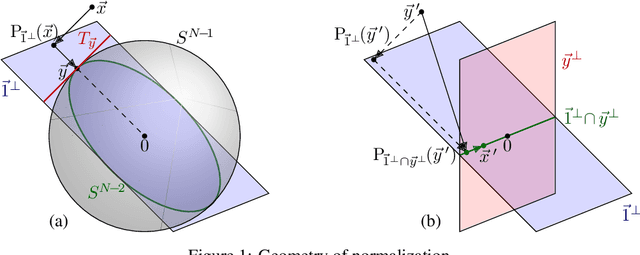
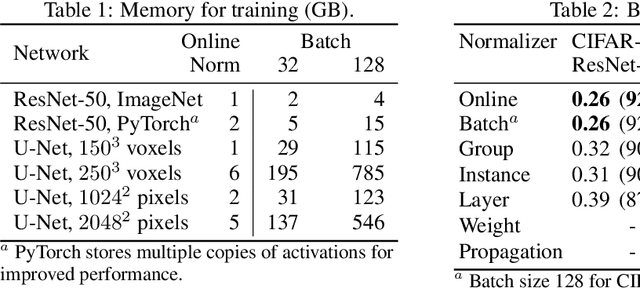
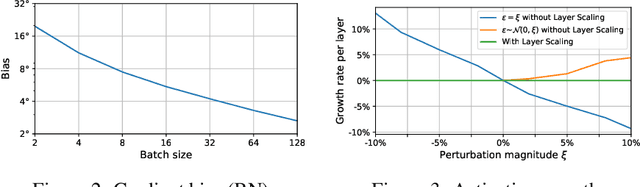
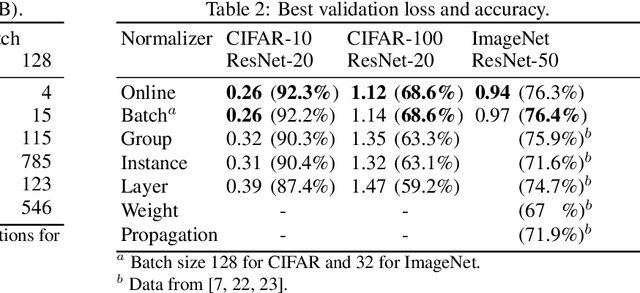
Online Normalization is a new technique for normalizing the hidden activations of a neural network. Like Batch Normalization, it normalizes the sample dimension. While Online Normalization does not use batches, it is as accurate as Batch Normalization. We resolve a theoretical limitation of Batch Normalization by introducing an unbiased technique for computing the gradient of normalized activations. Online Normalization works with automatic differentiation by adding statistical normalization as a primitive. This technique can be used in cases not covered by some other normalizers, such as recurrent networks, fully connected networks, and networks with activation memory requirements prohibitive for batching. We show its applications to image classification, image segmentation, and language modeling. We present formal proofs and experimental results on ImageNet, CIFAR, and PTB datasets.
Robust Full-FoV Depth Estimation in Tele-wide Camera System
Sep 08, 2019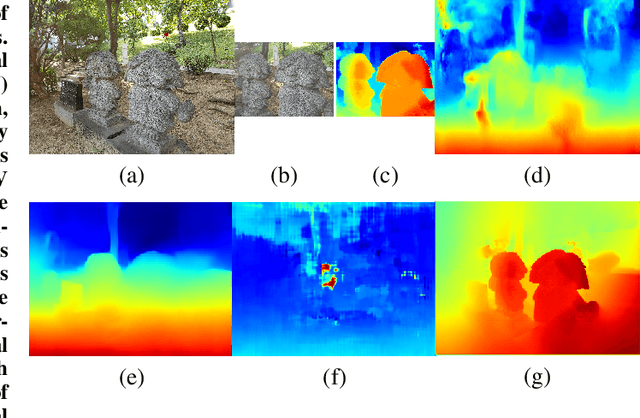
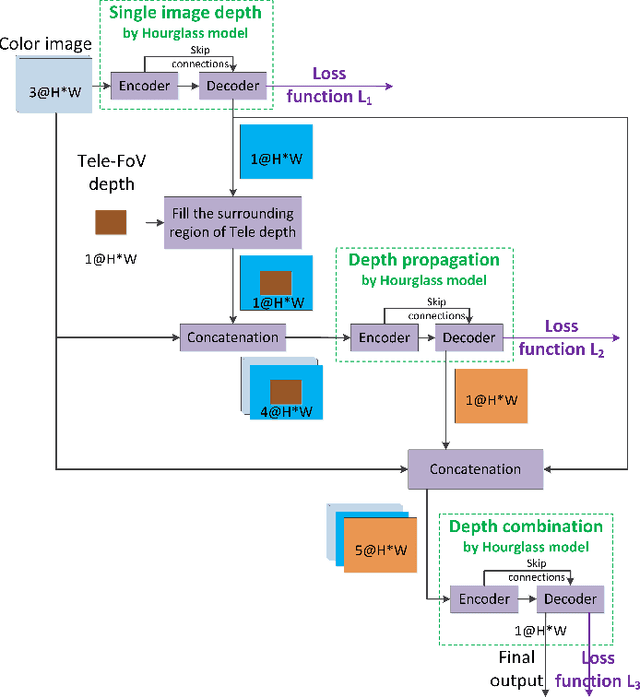
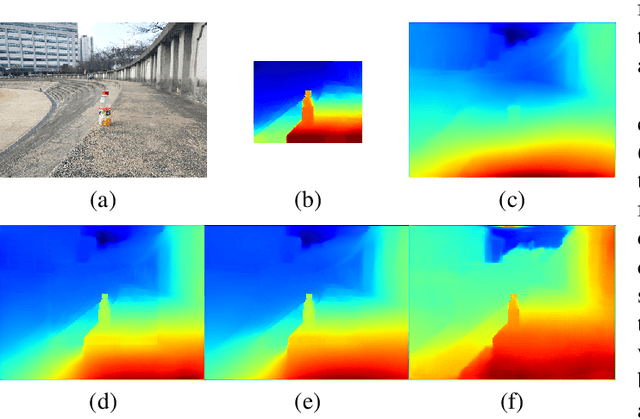
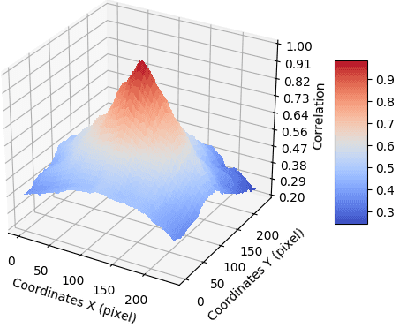
Tele-wide camera system with different Field of View (FoV) lenses becomes very popular in recent mobile devices. Usually it is difficult to obtain full-FoV depth based on traditional stereo-matching methods. Pure Deep Neural Network (DNN) based depth estimation methods could obtain full-FoV depth, but have low robustness for scenarios which are not covered by training dataset. In this paper, to address the above problems we propose a hierarchical hourglass network for robust full-FoV depth estimation in tele-wide camera system, which combines the robustness of traditional stereo-matching methods with the accuracy of DNN. More specifically, the proposed network comprises three major modules: single image depth prediction module infers initial depth from input color image, depth propagation module propagates traditional stereo-matching tele-FoV depth to surrounding regions, and depth combination module fuses the initial depth with the propagated depth to generate final output. Each of these modules employs an hourglass model, which is a kind of encoder-decoder structure with skip connections. Experimental results compared with state-of-the-art depth estimation methods demonstrate that our method can not only produce robust and better subjective depth quality on wild test images, but also obtain better quantitative results on standard datasets.
Signal2Image Modules in Deep Neural Networks for EEG Classification
May 01, 2019
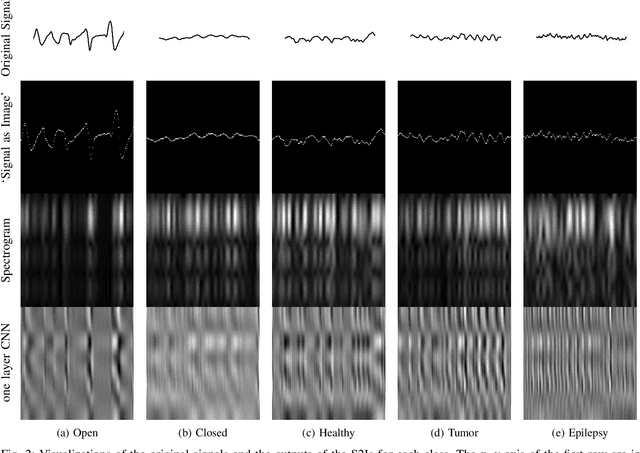
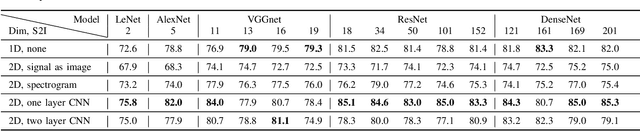
Deep learning has revolutionized computer vision utilizing the increased availability of big data and the power of parallel computational units such as graphical processing units. The vast majority of deep learning research is conducted using images as training data, however the biomedical domain is rich in physiological signals that are used for diagnosis and prediction problems. It is still an open research question how to best utilize signals to train deep neural networks. In this paper we define the term Signal2Image (S2Is) as trainable or non-trainable prefix modules that convert signals, such as Electroencephalography (EEG), to image-like representations making them suitable for training image-based deep neural networks defined as `base models'. We compare the accuracy and time performance of four S2Is (`signal as image', spectrogram, one and two layer Convolutional Neural Networks (CNNs)) combined with a set of `base models' (LeNet, AlexNet, VGGnet, ResNet, DenseNet) along with the depth-wise and 1D variations of the latter. We also provide empirical evidence that the one layer CNN S2I performs better in eleven out of fifteen tested models than non-trainable S2Is for classifying EEG signals and we present visual comparisons of the outputs of the S2Is.