 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the interaction between supervision and self-play in emergent communication
Feb 04, 2020
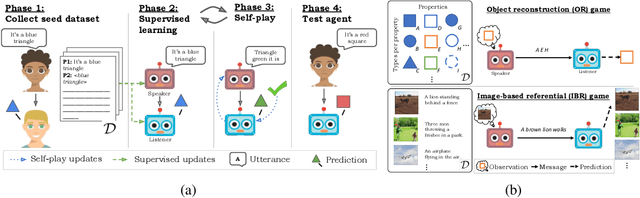
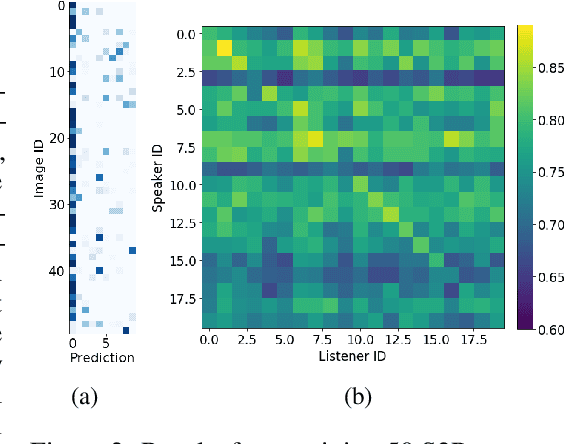
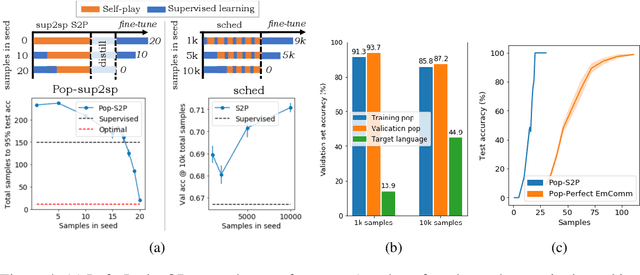
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.
Bi-directional Dermoscopic Feature Learning and Multi-scale Consistent Decision Fusion for Skin Lesion Segmentation
Feb 20, 2020



Accurate segmentation of skin lesion from dermoscopic images is a crucial part of computer-aided diagnosis of melanoma. It is challenging due to the fact that dermoscopic images from different patients have non-negligible lesion variation, which causes difficulties in anatomical structure learning and consistent skin lesion delineation. In this paper, we propose a novel bi-directional dermoscopic feature learning (biDFL) framework to model the complex correlation between skin lesions and their informative context. By controlling feature information passing through two complementary directions, a substantially rich and discriminative feature representation is achieved. Specifically, we place biDFL module on the top of a CNN network to enhance high-level parsing performance. Furthermore, we propose a multi-scale consistent decision fusion (mCDF) that is capable of selectively focusing on the informative decisions generated from multiple classification layers. By analysis of the consistency of the decision at each position, mCDF automatically adjusts the reliability of decisions and thus allows a more insightful skin lesion delineation. The comprehensive experimental results show the effectiveness of the proposed method on skin lesion segmentation, achieving state-of-the-art performance consistently on two publicly available dermoscopic image databases.
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 01, 2020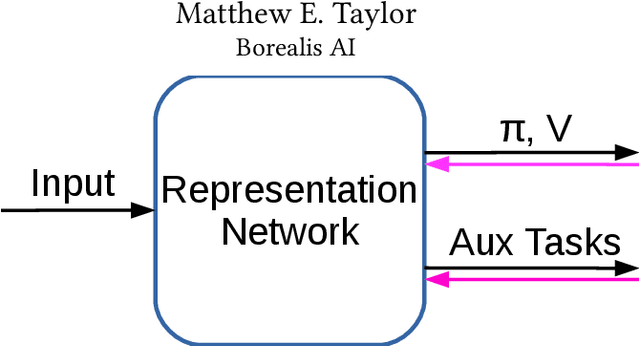

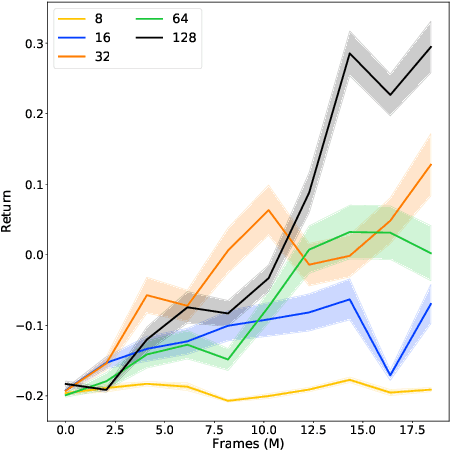
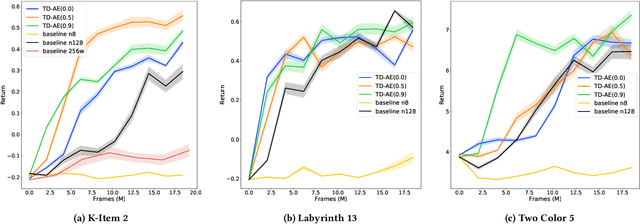
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
CURE: Curvature Regularization For Missing Data Recovery
Jan 28, 2019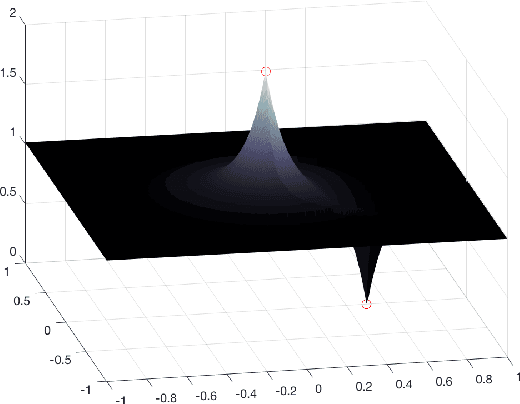
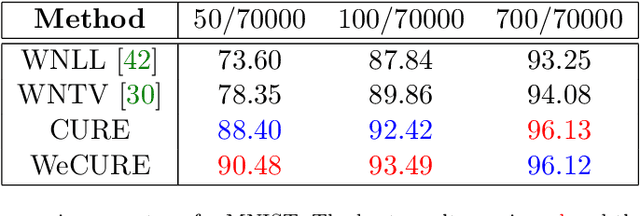

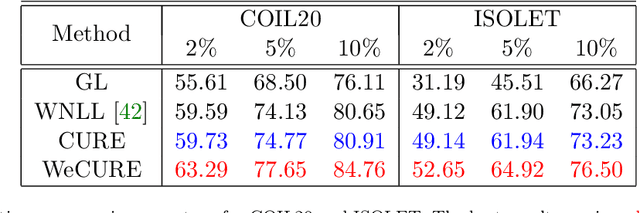
Missing data recovery is an important and yet challenging problem in imaging and data science. Successful models often adopt certain carefully chosen regularization. Recently, the low dimension manifold model (LDMM) was introduced by S.Osher et al. and shown effective in image inpainting. They observed that enforcing low dimensionality on image patch manifold serves as a good image regularizer. In this paper, we observe that having only the low dimension manifold regularization is not enough sometimes, and we need smoothness as well. For that, we introduce a new regularization by combining the low dimension manifold regularization with a higher order Curvature Regularization, and we call this new regularization CURE for short. The key step of solving CURE is to solve a biharmonic equation on a manifold. We further introduce a weighted version of CURE, called WeCURE, in a similar manner as the weighted nonlocal Laplacian (WNLL) method. Numerical experiments for image inpainting and semi-supervised learning show that the proposed CURE and WeCURE significantly outperform LDMM and WNLL respectively.
Using Deep Learning to Count Albatrosses from Space
Jul 03, 2019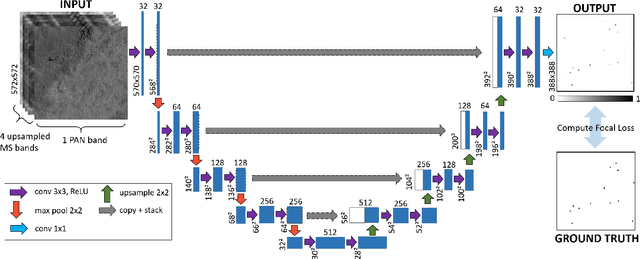
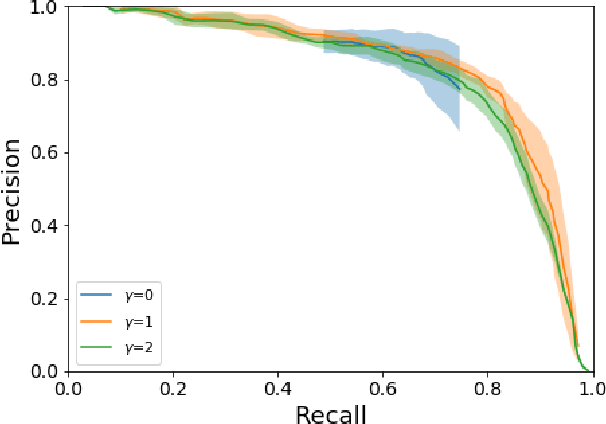

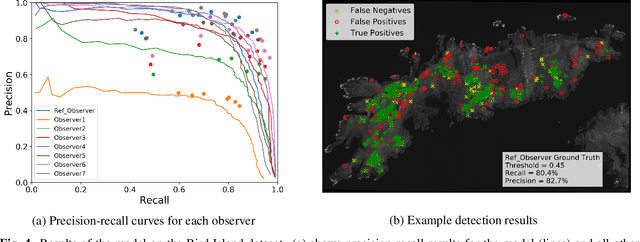
In this paper we test the use of a deep learning approach to automatically count Wandering Albatrosses in Very High Resolution (VHR) satellite imagery. We use a dataset of manually labelled imagery provided by the British Antarctic Survey to train and develop our methods. We employ a U-Net architecture, designed for image segmentation, to simultaneously classify and localise potential albatrosses. We aid training with the use of the Focal Loss criterion, to deal with extreme class imbalance in the dataset. Initial results achieve peak precision and recall values of approximately 80%. Finally we assess the model's performance in relation to inter-observer variation, by comparing errors against an image labelled by multiple observers. We conclude model accuracy falls within the range of human counters. We hope that the methods will streamline the analysis of VHR satellite images, enabling more frequent monitoring of a species which is of high conservation concern.
DeepIM: Deep Iterative Matching for 6D Pose Estimation
Mar 14, 2019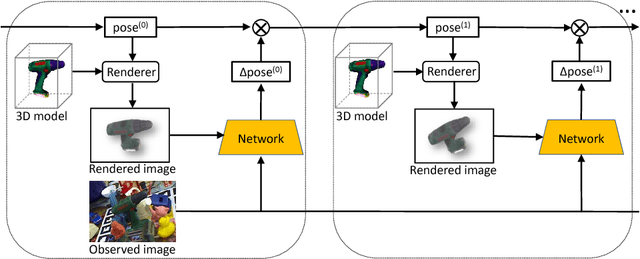
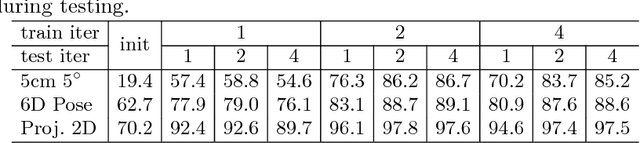
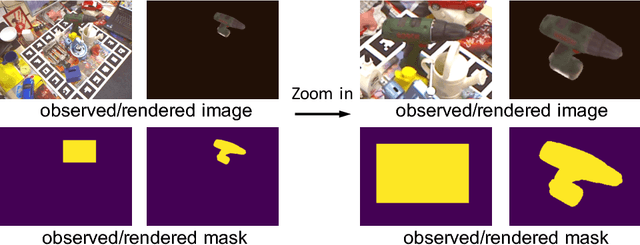
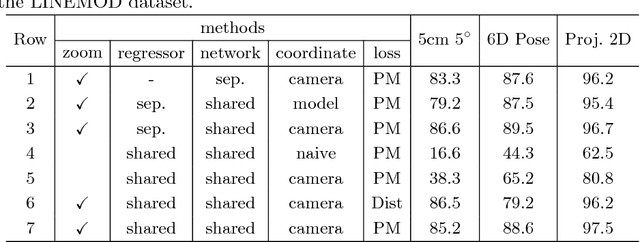
Estimating the 6D pose of objects from images is an important problem in various applications such as robot manipulation and virtual reality. While direct regression of images to object poses has limited accuracy, matching rendered images of an object against the observed image can produce accurate results. In this work, we propose a novel deep neural network for 6D pose matching named DeepIM. Given an initial pose estimation, our network is able to iteratively refine the pose by matching the rendered image against the observed image. The network is trained to predict a relative pose transformation using an untangled representation of 3D location and 3D orientation and an iterative training process. Experiments on two commonly used benchmarks for 6D pose estimation demonstrate that DeepIM achieves large improvements over state-of-the-art methods. We furthermore show that DeepIM is able to match previously unseen objects.
A Document Skew Detection Method Using Fast Hough Transform
Dec 05, 2019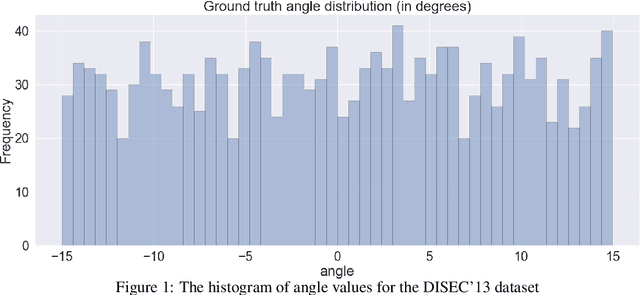
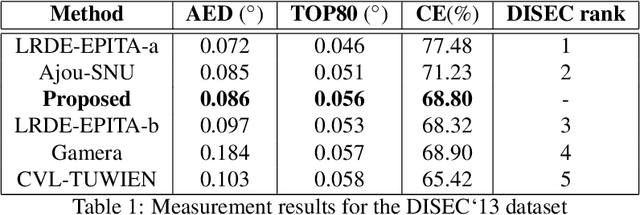
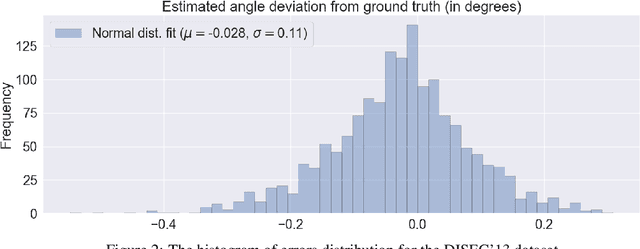
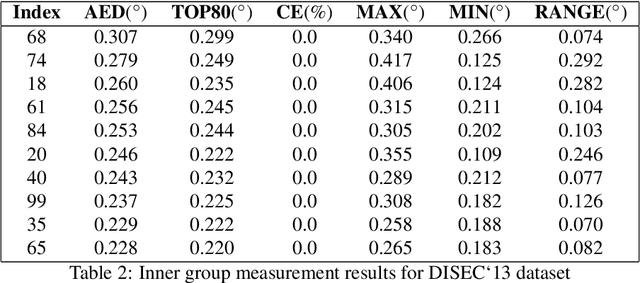
The majority of document image analysis systems use a document skew detection algorithm to simplify all its further processing stages. A huge amount of such algorithms based on Hough transform (HT) analysis has already been proposed. Despite this, we managed to find only one work where the Fast Hough Transform (FHT) usage was suggested to solve the indicated problem. Unfortunately, no study of that method was provided. In this work, we propose and study a skew detection algorithm for the document images which relies on FHT analysis. To measure this algorithm quality we use the dataset from the problem oriented DISEC'13 contest and its evaluation methodology. Obtained values for AED, TOP80, and CE criteria are equal to 0.086, 0.056, 68.80 respectively.
Implementation of the VBM3D Video Denoising Method and Some Variants
Jan 06, 2020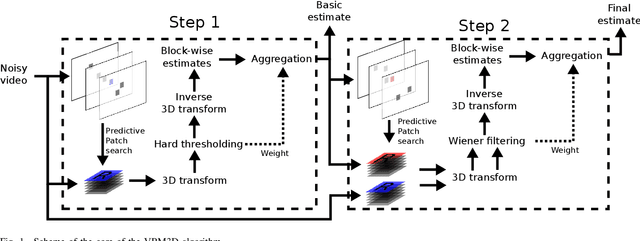
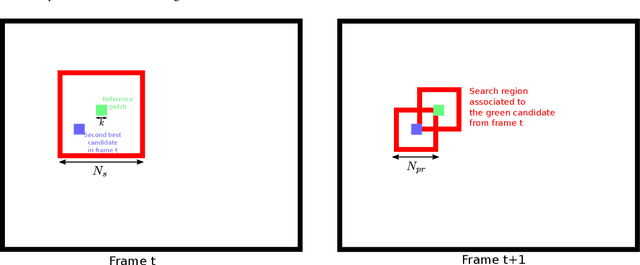


VBM3D is an extension to video of the well known image denoising algorithm BM3D, which takes advantage of the sparse representation of stacks of similar patches in a transform domain. The extension is rather straightforward: the similar 2D patches are taken from a spatio-temporal neighborhood which includes neighboring frames. In spite of its simplicity, the algorithm offers a good trade-off between denoising performance and computational complexity. In this work we revisit this method, providing an open-source C++ implementation reproducing the results. A detailed description is given and the choice of parameters is thoroughly discussed. Furthermore, we discuss several extensions of the original algorithm: (1) a multi-scale implementation, (2) the use of 3D patches, (3) the use of optical flow to guide the patch search. These extensions allow to obtain results which are competitive with even the most recent state of the art.
Improved inter-scanner MS lesion segmentation by adversarial training on longitudinal data
Feb 03, 2020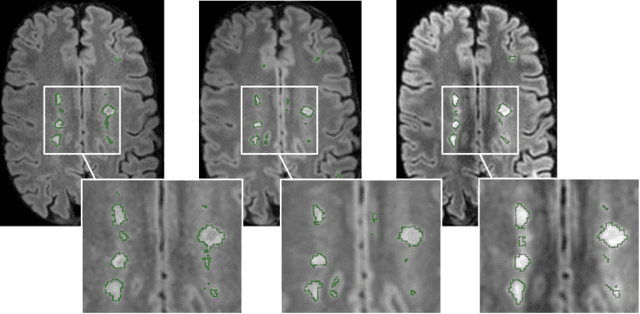
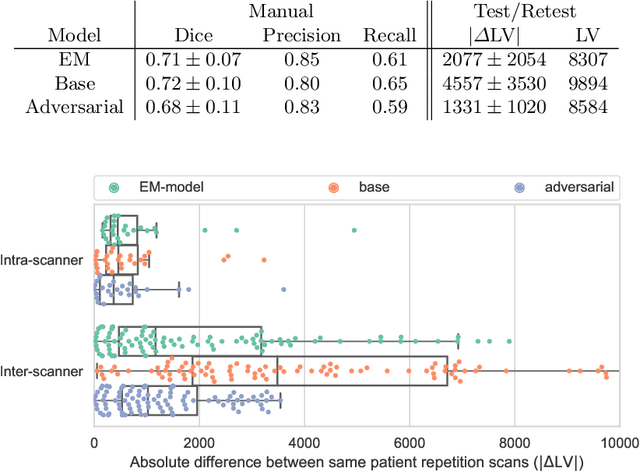
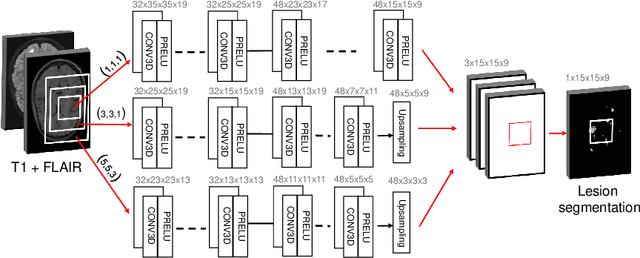
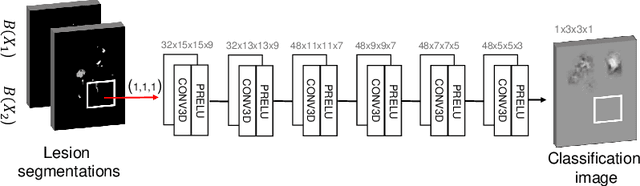
The evaluation of white matter lesion progression is an important biomarker in the follow-up of MS patients and plays a crucial role when deciding the course of treatment. Current automated lesion segmentation algorithms are susceptible to variability in image characteristics related to MRI scanner or protocol differences. We propose a model that improves the consistency of MS lesion segmentations in inter-scanner studies. First, we train a CNN base model to approximate the performance of icobrain, an FDA-approved clinically available lesion segmentation software. A discriminator model is then trained to predict if two lesion segmentations are based on scans acquired using the same scanner type or not, achieving a 78% accuracy in this task. Finally, the base model and the discriminator are trained adversarially on multi-scanner longitudinal data to improve the inter-scanner consistency of the base model. The performance of the models is evaluated on an unseen dataset containing manual delineations. The inter-scanner variability is evaluated on test-retest data, where the adversarial network produces improved results over the base model and the FDA-approved solution.
Learning for Video Compression with Hierarchical Quality and Recurrent Enhancement
Mar 19, 2020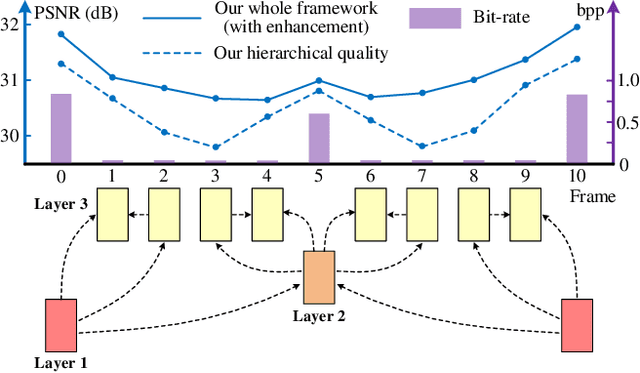
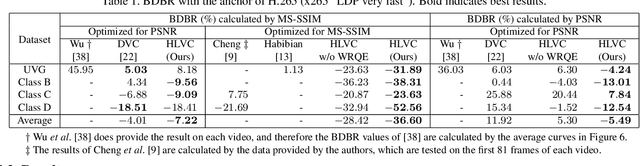
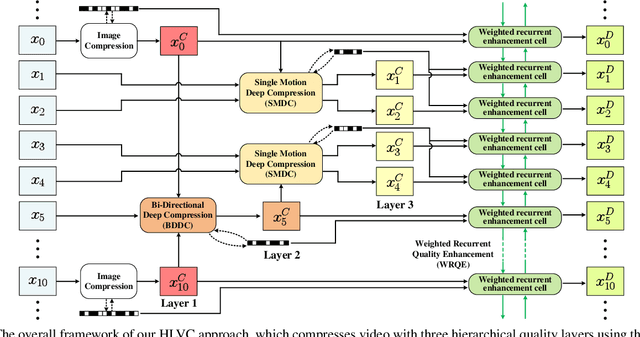
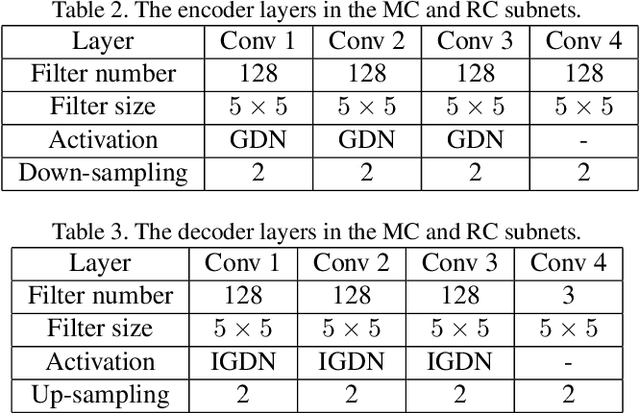
In this paper, we propose a Hierarchical Learned Video Compression (HLVC) method with three hierarchical quality layers and a recurrent enhancement network. The frames in the first layer are compressed by an image compression method with the highest quality. Using these frames as references, we propose the Bi-Directional Deep Compression (BDDC) network to compress the second layer with relatively high quality. Then, the third layer frames are compressed with the lowest quality, by the proposed Single Motion Deep Compression (SMDC) network, which adopts a single motion map to estimate the motions of multiple frames, thus saving bits for motion information. In our deep decoder, we develop the Weighted Recurrent Quality Enhancement (WRQE) network, which takes both compressed frames and the bit stream as inputs. In the recurrent cell of WRQE, the memory and update signal are weighted by quality features to reasonably leverage multi-frame information for enhancement. In our HLVC approach, the hierarchical quality benefits the coding efficiency, since the high quality information facilitates the compression and enhancement of low quality frames at encoder and decoder sides, respectively. Finally, the experiments validate that our HLVC approach advances the state-of-the-art of deep video compression methods, and outperforms the "Low-Delay P (LDP) very fast" mode of x265 in terms of both PSNR and MS-SSIM. The project page is at https://github.com/RenYang-home/HLVC.