 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On
Jun 10, 2019
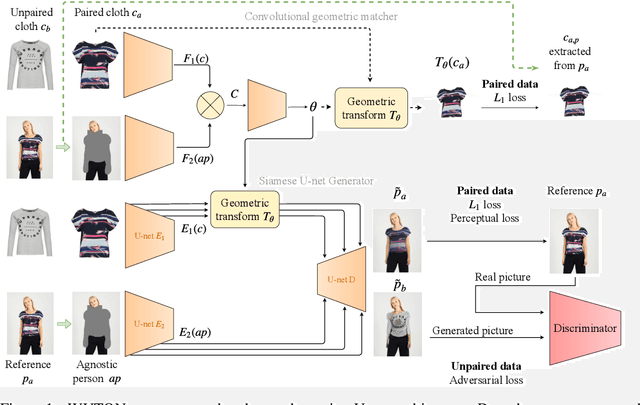



The 2D virtual try-on task has recently attracted a lot of interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires to fit an in-shop cloth image on the image of a person. It is highly challenging because it requires to warp the cloth on the target person while preserving its patterns and characteristics, and to compose the item with the person in a realistic manner. Current state-of-the-art models generate images with visible artifacts, due either to a pixel-level composition step or to the geometric transformation. In this paper, we propose WUTON: a Warping U-net for a Virtual Try-On system. It is a siamese U-net generator whose skip connections are geometrically transformed by a convolutional geometric matcher. The whole architecture is trained end-to-end with a multi-task loss including an adversarial one. This enables our network to generate and use realistic spatial transformations of the cloth to synthesize images of high visual quality. The proposed architecture can be trained end-to-end and allows us to advance towards a detail-preserving and photo-realistic 2D virtual try-on system. Our method outperforms the current state-of-the-art with visual results as well as with the Learned Perceptual Image Similarity (LPIPS) metric.
An Overview of Perception and Decision-Making in Autonomous Systems in the Era of Learning
Feb 24, 2020Autonomous systems possess the features of inferring their own ego-motion, autonomously understanding their surroundings, and planning trajectories. With the applications of deep learning and reinforcement learning, the perception and decision-making abilities of autonomous systems are being efficiently addressed, and many new learning-based algorithms have surfaced with respect to autonomous perception and decision-making. In this review, we focus on the applications of learning-based approaches in perception and decision-making in autonomous systems, which is different from previous reviews that discussed traditional methods. First, we delineate the existing classical simultaneous localization and mapping (SLAM) solutions and review the environmental perception and understanding methods based on deep learning, including deep learning-based monocular depth estimation, ego-motion prediction, image enhancement, object detection, semantic segmentation, and their combinations with traditional SLAM frameworks. Second, we briefly summarize the existing motion planning techniques, such as path planning and trajectory planning methods, and discuss the navigation methods based on reinforcement learning. Finally, we examine the several challenges and promising directions discussed and concluded in related research for future works in the era of computer science, automatic control, and robotics.
Linking Art through Human Poses
Jul 08, 2019



We address the discovery of composition transfer in artworks based on their visual content. Automated analysis of large art collections, which are growing as a result of art digitization among museums and galleries, is an important tool for art history and assists cultural heritage preservation. Modern image retrieval systems offer good performance on visually similar artworks, but fail in the cases of more abstract composition transfer. The proposed approach links artworks through a pose similarity of human figures depicted in images. Human figures are the subject of a large fraction of visual art from middle ages to modernity and their distinctive poses were often a source of inspiration among artists. The method consists of two steps -- fast pose matching and robust spatial verification. We experimentally show that explicit human pose matching is superior to standard content-based image retrieval methods on a manually annotated art composition transfer dataset.
Robust copy-move forgery detection by false alarms control
Jun 03, 2019
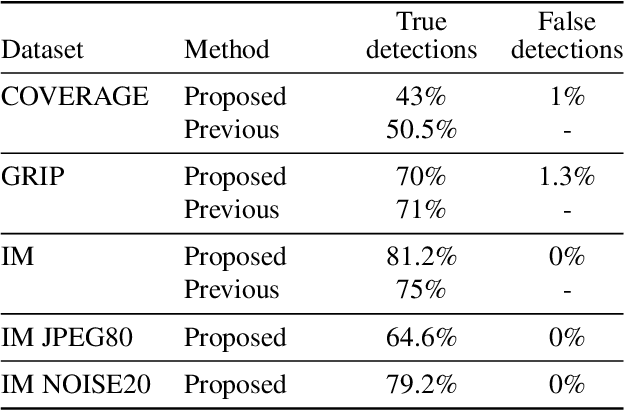


Detecting reliably copy-move forgeries is difficult because images do contain similar objects. The question is: how to discard natural image self-similarities while still detecting copy-moved parts as being "unnaturally similar"? Copy-move may have been performed after a rotation, a change of scale and followed by JPEG compression or the addition of noise. For this reason, we base our method on SIFT, which provides sparse keypoints with scale, rotation and illumination invariant descriptors. To discriminate natural descriptor matches from artificial ones, we introduce an a contrario method which gives theoretical guarantees on the number of false alarms. We validate our method on several databases. Being fully unsupervised it can be integrated into any generic automated image tampering detection pipeline.
Non-rigid Registration Method between 3D CT Liver Data and 2D Ultrasonic Images based on Demons Model
Dec 31, 2019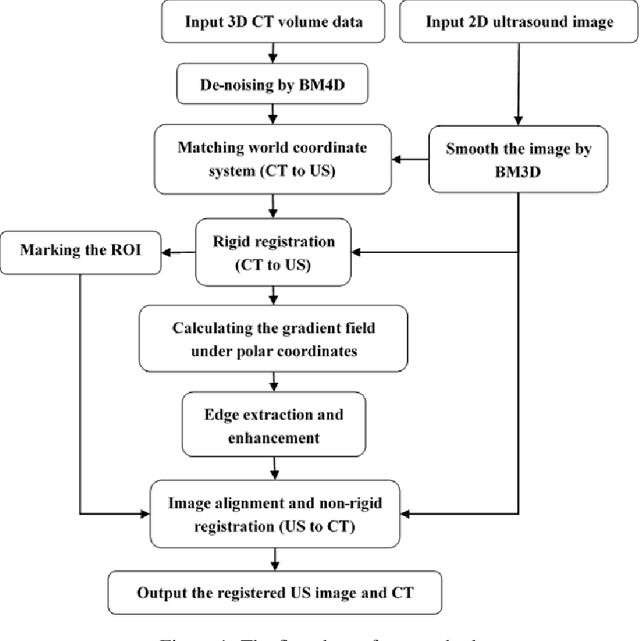

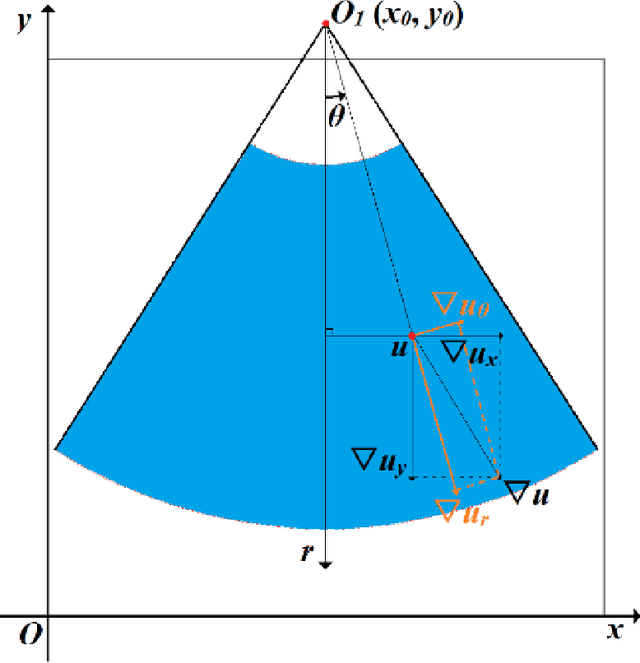
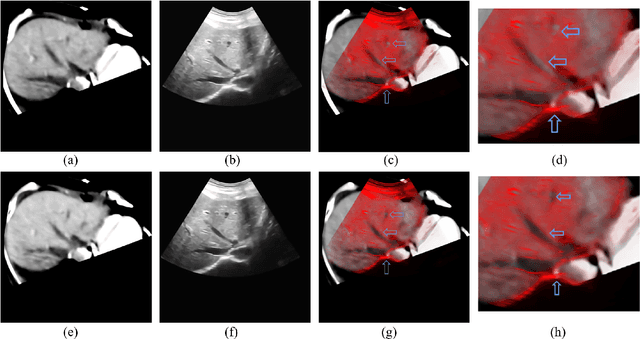
The non-rigid registration between CT data and ultrasonic images of liver can facilitate the diagnosis and treatment, which has been widely studied in recent years. To improve the registration accuracy of the Demons model on the non-rigid registration between 3D CT liver data and 2D ultrasonic images, a novel boundary extraction and enhancement method based on radial directional local intuitionistic fuzzy entropy in the polar coordinates has been put forward, and a new registration workflow has been provided. Experiments show that our method can acquire high-accuracy registration results. Experiments also show that the accuracy of the results of our method is higher than that of the original Demons method and the Demons method using simulated ultrasonic image by Field II. The operation time of our registration workflow is about 30 seconds, and it can be used in the surgery.
Hierarchical Expert Networks for Meta-Learning
Nov 14, 2019

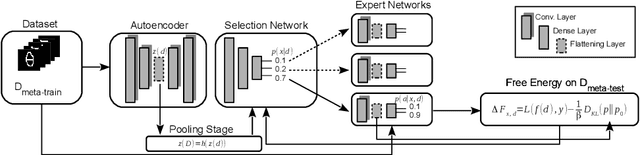
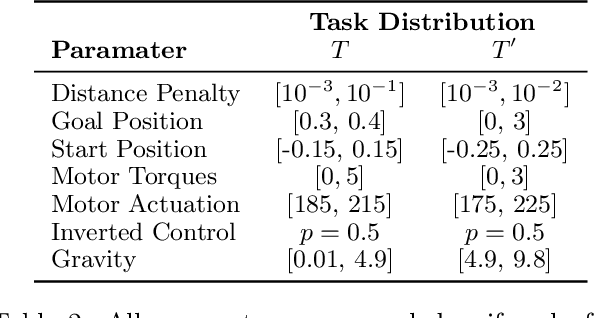
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
Sparse Modeling for Image and Vision Processing
Dec 06, 2014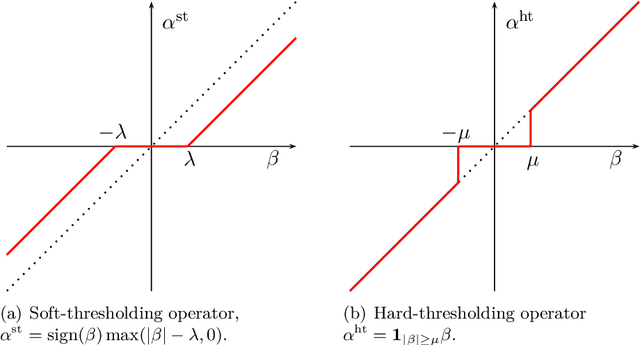
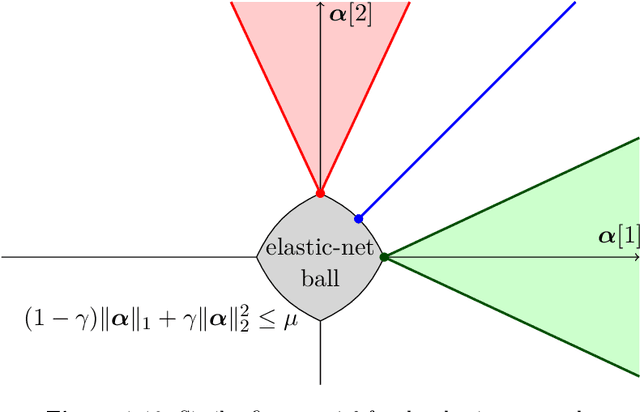
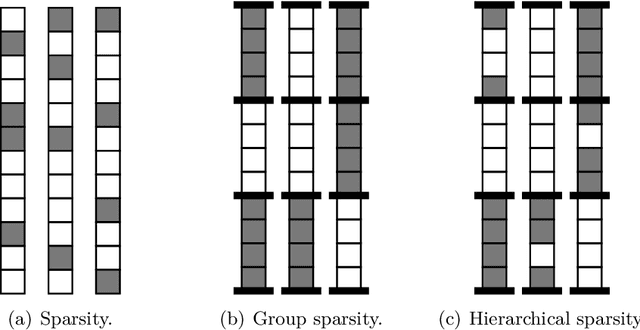
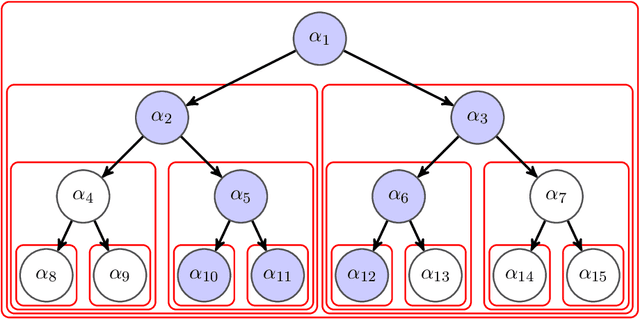
In recent years, a large amount of multi-disciplinary research has been conducted on sparse models and their applications. In statistics and machine learning, the sparsity principle is used to perform model selection---that is, automatically selecting a simple model among a large collection of them. In signal processing, sparse coding consists of representing data with linear combinations of a few dictionary elements. Subsequently, the corresponding tools have been widely adopted by several scientific communities such as neuroscience, bioinformatics, or computer vision. The goal of this monograph is to offer a self-contained view of sparse modeling for visual recognition and image processing. More specifically, we focus on applications where the dictionary is learned and adapted to data, yielding a compact representation that has been successful in various contexts.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Mar 23, 2020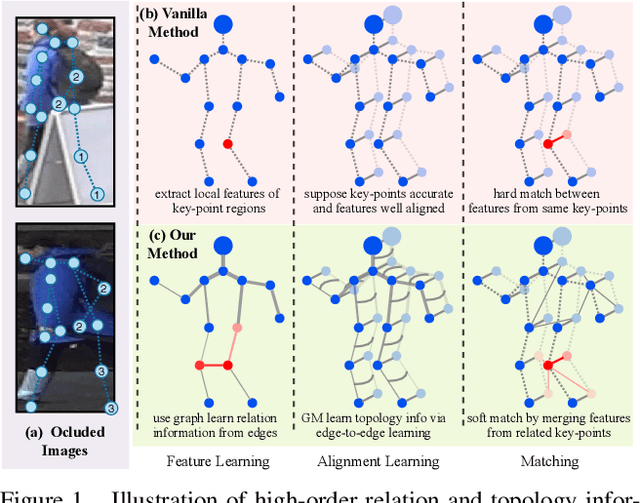
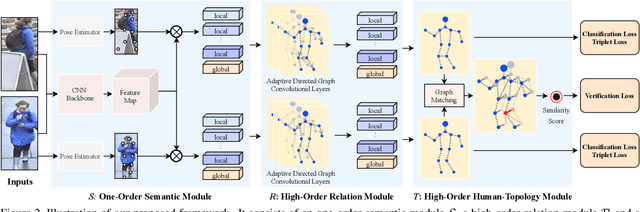
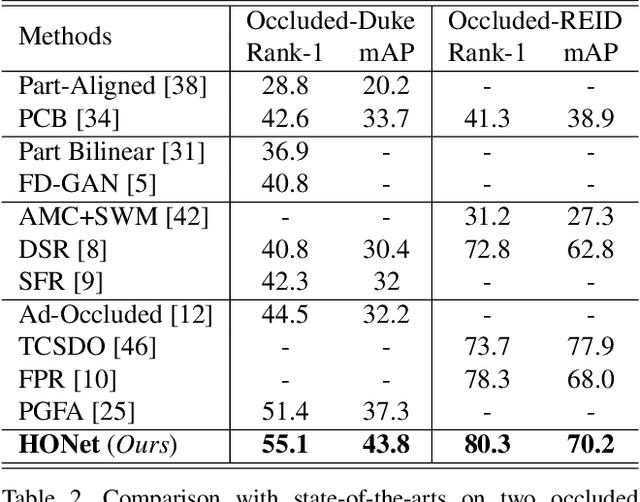
Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Learned Spectral Computed Tomography
Mar 09, 2020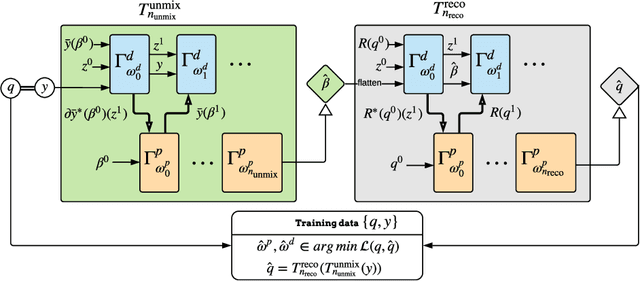
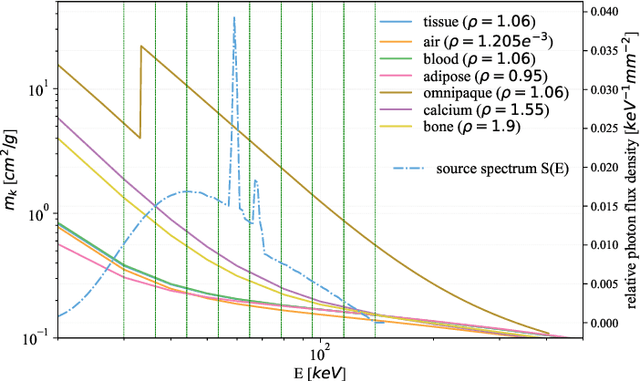

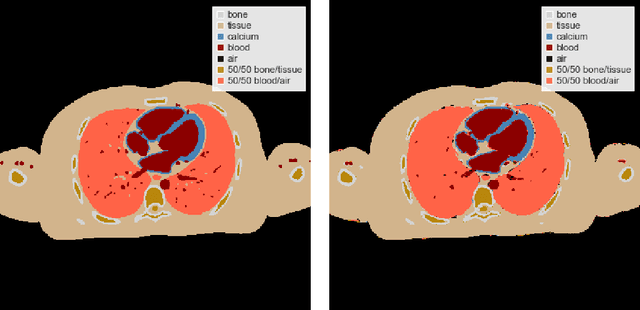
Spectral Photon-Counting Computed Tomography (SPCCT) is a promising technology that has shown a number of advantages over conventional X-ray Computed Tomography (CT) in the form of material separation, artefact removal and enhanced image quality. However, due to the increased complexity and non-linearity of the SPCCT governing equations, model-based reconstruction algorithms typically require handcrafted regularisation terms and meticulous tuning of hyperparameters making them impractical to calibrate in variable conditions. Additionally, they typically incur high computational costs and in cases of limited-angle data, their imaging capability deteriorates significantly. Recently, Deep Learning has proven to provide state-of-the-art reconstruction performance in medical imaging applications while circumventing most of these challenges. Inspired by these advances, we propose a Deep Learning imaging method for SPCCT that exploits the expressive power of Neural Networks while also incorporating model knowledge. The method takes the form of a two-step learned primal-dual algorithm that is trained using case-specific data. The proposed approach is characterised by fast reconstruction capability and high imaging performance, even in limited-data cases, while avoiding the hand-tuning that is required by other optimisation approaches. We demonstrate the performance of the method in terms of reconstructed images and quality metrics via numerical examples inspired by the application of cardiovascular imaging.
Real-Time Style Transfer With Strength Control
Apr 18, 2019

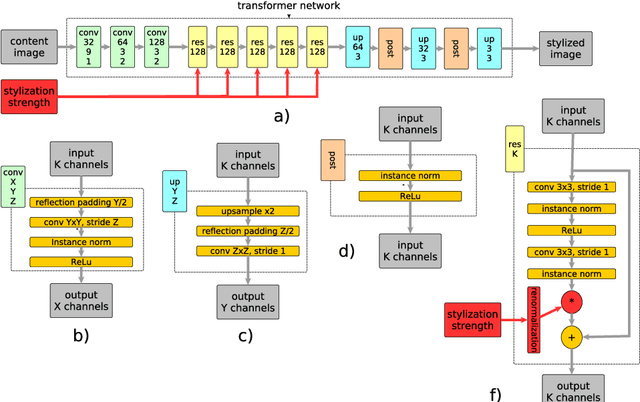

Style transfer is a problem of rendering a content image in the style of another style image. A natural and common practical task in applications of style transfer is to adjust the strength of stylization. Algorithm of Gatys et al. (2016) provides this ability by changing the weighting factors of content and style losses but is computationally inefficient. Real-time style transfer introduced by Johnson et al. (2016) enables fast stylization of any image by passing it through a pre-trained transformer network. Although fast, this architecture is not able to continuously adjust style strength. We propose an extension to real-time style transfer that allows direct control of style strength at inference, still requiring only a single transformer network. We conduct qualitative and quantitative experiments that demonstrate that the proposed method is capable of smooth stylization strength control and removes certain stylization artifacts appearing in the original real-time style transfer method. Comparisons with alternative real-time style transfer algorithms, capable of adjusting stylization strength, show that our method reproduces style with more details.