 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-scale GANs for Memory-efficient Generation of High Resolution Medical Images
Jul 08, 2019

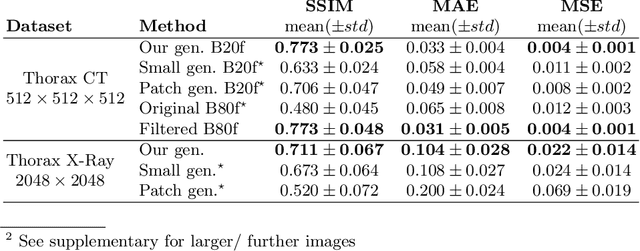
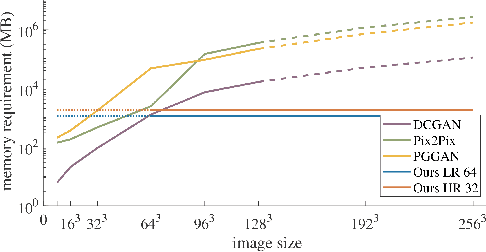
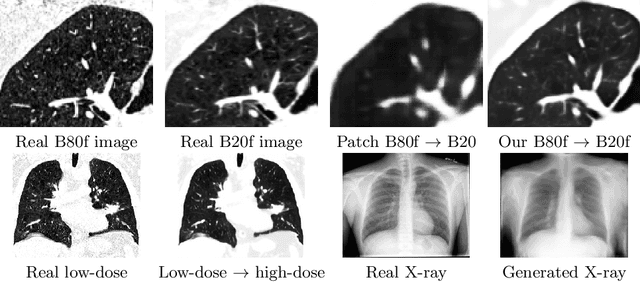
Currently generative adversarial networks (GANs) are rarely applied to medical images of large sizes, especially 3D volumes, due to their large computational demand. We propose a novel multi-scale patch-based GAN approach to generate large high resolution 2D and 3D images. Our key idea is to first learn a low-resolution version of the image and then generate patches of successively growing resolutions conditioned on previous scales. In a domain translation use-case scenario, 3D thorax CTs of size 512x512x512 and thorax X-rays of size 2048x2048 are generated and we show that, due to the constant GPU memory demand of our method, arbitrarily large images of high resolution can be generated. Moreover, compared to common patch-based approaches, our multi-resolution scheme enables better image quality and prevents patch artifacts.
Stereoscopic Dark Flash for Low-light Photography
Jan 09, 2019
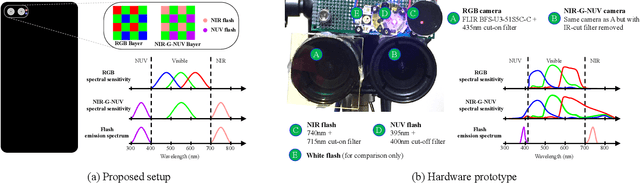
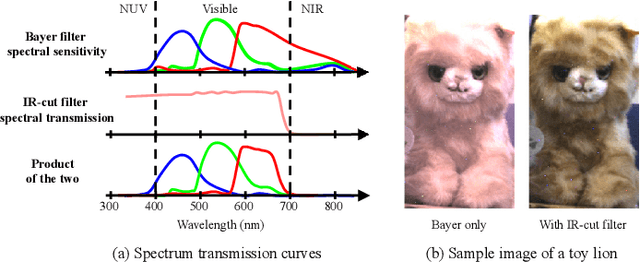
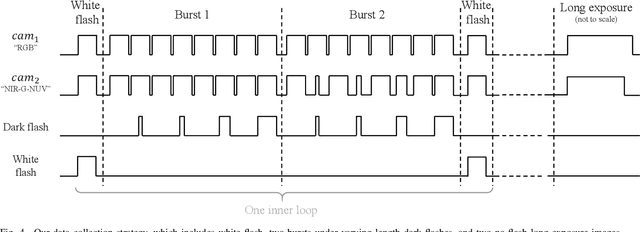
In this work, we present a camera configuration for acquiring "stereoscopic dark flash" images: a simultaneous stereo pair in which one camera is a conventional RGB sensor, but the other camera is sensitive to near-infrared and near-ultraviolet instead of R and B. When paired with a "dark" flash (i.e., one having near-infrared and near-ultraviolet light, but no visible light) this camera allows us to capture the two images in a flash/no-flash image pair at the same time, all while not disturbing any human subjects or onlookers with a dazzling visible flash. We present a hardware prototype of this camera that approximates an idealized camera, and we present an imaging procedure that let us acquire dark flash stereo pairs that closely resemble those we would get from that idealized camera. We then present a technique for fusing these stereo pairs, first by performing registration and warping, and then by using recent advances in hyperspectral image fusion and deep learning to produce a final image. Because our camera configuration and our data acquisition process allow us to capture true low-noise long exposure RGB images alongside our dark flash stereo pairs, our learned model can be trained end-to-end to produce a fused image that retains the color and tone of a real RGB image while having the low-noise properties of a flash image.
DeepSD: Generating High Resolution Climate Change Projections through Single Image Super-Resolution
Mar 09, 2017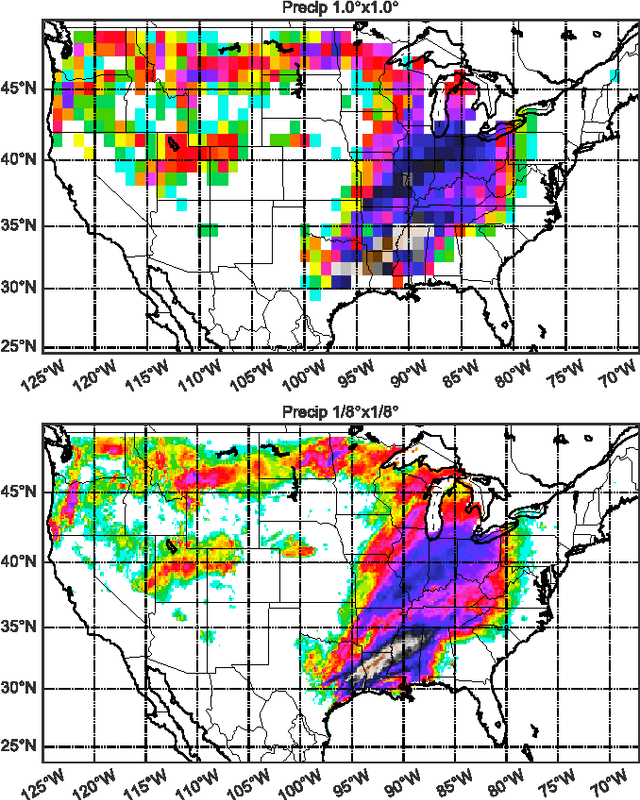
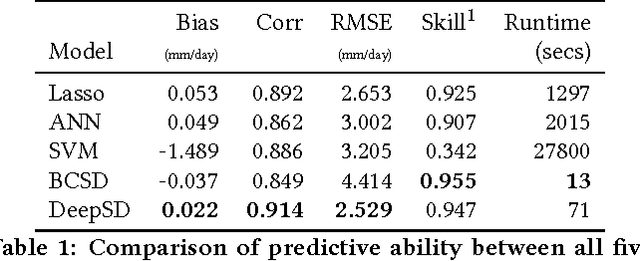

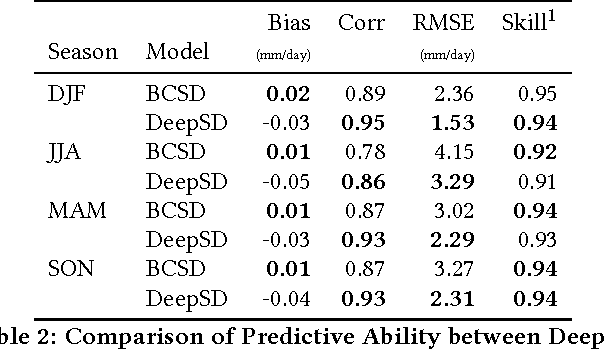
The impacts of climate change are felt by most critical systems, such as infrastructure, ecological systems, and power-plants. However, contemporary Earth System Models (ESM) are run at spatial resolutions too coarse for assessing effects this localized. Local scale projections can be obtained using statistical downscaling, a technique which uses historical climate observations to learn a low-resolution to high-resolution mapping. Depending on statistical modeling choices, downscaled projections have been shown to vary significantly terms of accuracy and reliability. The spatio-temporal nature of the climate system motivates the adaptation of super-resolution image processing techniques to statistical downscaling. In our work, we present DeepSD, a generalized stacked super resolution convolutional neural network (SRCNN) framework for statistical downscaling of climate variables. DeepSD augments SRCNN with multi-scale input channels to maximize predictability in statistical downscaling. We provide a comparison with Bias Correction Spatial Disaggregation as well as three Automated-Statistical Downscaling approaches in downscaling daily precipitation from 1 degree (~100km) to 1/8 degrees (~12.5km) over the Continental United States. Furthermore, a framework using the NASA Earth Exchange (NEX) platform is discussed for downscaling more than 20 ESM models with multiple emission scenarios.
Jacobian Adversarially Regularized Networks for Robustness
Jan 29, 2020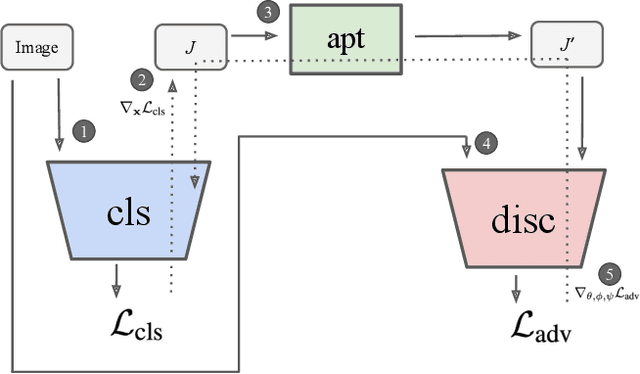
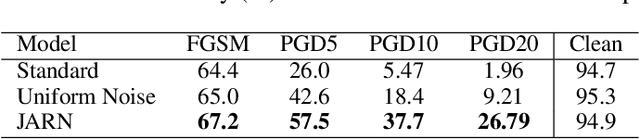
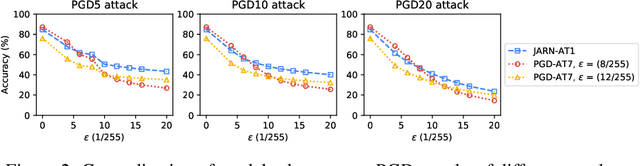
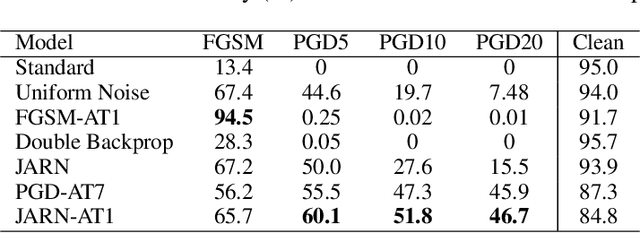
Adversarial examples are crafted with imperceptible perturbations with the intent to fool neural networks. Against such attacks, adversarial training and its variants stand as the strongest defense to date. Previous studies have pointed out that robust models that have undergone adversarial training tend to produce more salient and interpretable Jacobian matrices than their non-robust counterparts. A natural question is whether a model trained with an objective to produce salient Jacobian can result in better robustness. This paper answers this question with affirmative empirical results. We propose Jacobian Adversarially Regularized Networks (JARN) as a method to optimize the saliency of a classifier's Jacobian by adversarially regularizing the model's Jacobian to resemble natural training images. Image classifiers trained with JARN show improved robust accuracy compared to standard models on the MNIST, SVHN and CIFAR-10 datasets, uncovering a new angle to boost robustness without using adversarial training examples.
The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification
Jul 03, 2019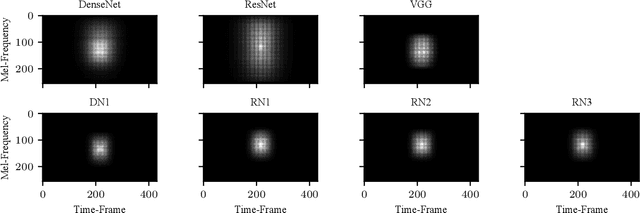
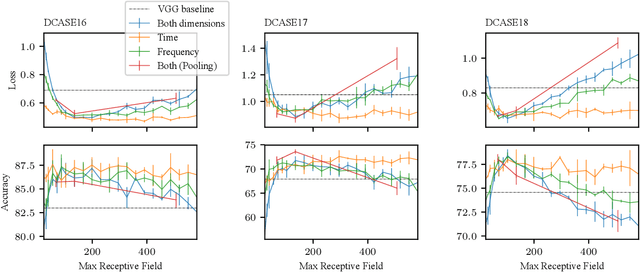
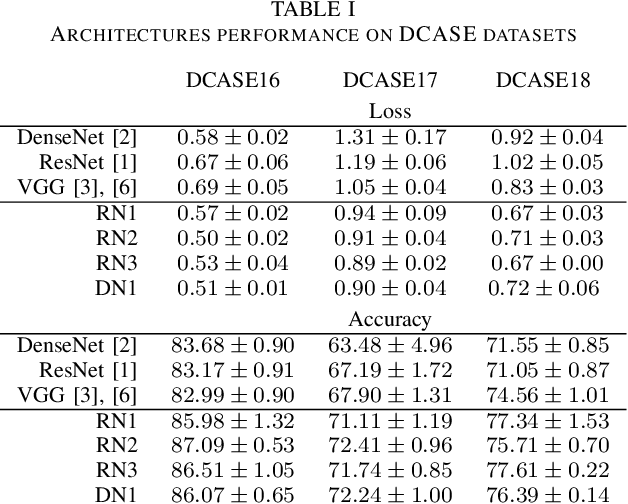

Convolutional Neural Networks (CNNs) have had great success in many machine vision as well as machine audition tasks. Many image recognition network architectures have consequently been adapted for audio processing tasks. However, despite some successes, the performance of many of these did not translate from the image to the audio domain. For example, very deep architectures such as ResNet and DenseNet, which significantly outperform VGG in image recognition, do not perform better in audio processing tasks such as Acoustic Scene Classification (ASC). In this paper, we investigate the reasons why such powerful architectures perform worse in ASC compared to simpler models (e.g., VGG). To this end, we analyse the receptive field (RF) of these CNNs and demonstrate the importance of the RF to the generalization capability of the models. Using our receptive field analysis, we adapt both ResNet and DenseNet, achieving state-of-the-art performance and eventually outperforming the VGG-based models. We introduce systematic ways of adapting the RF in CNNs, and present results on three data sets that show how changing the RF over the time and frequency dimensions affects a model's performance. Our experimental results show that very small or very large RFs can cause performance degradation, but deep models can be made to generalize well by carefully choosing an appropriate RF size within a certain range.
Handwriting-Based Gender Classification Using End-to-End Deep Neural Networks
Dec 04, 2019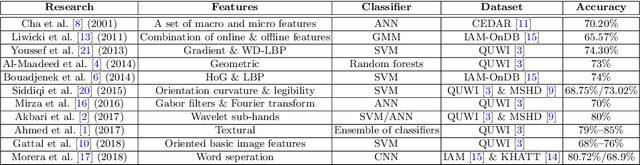
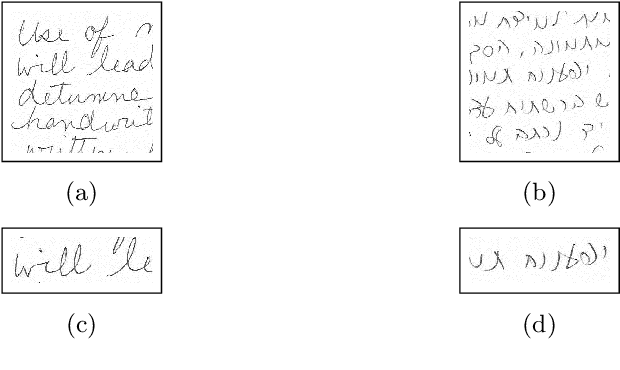
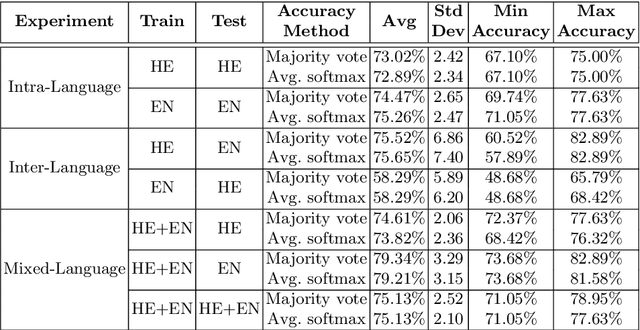
Handwriting-based gender classification is a well-researched problem that has been approached mainly by traditional machine learning techniques. In this paper, we propose a novel deep learning-based approach for this task. Specifically, we present a convolutional neural network (CNN), which performs automatic feature extraction from a given handwritten image, followed by classification of the writer's gender. Also, we introduce a new dataset of labeled handwritten samples, in Hebrew and English, of 405 participants. Comparing the gender classification accuracy on this dataset against human examiners, our results show that the proposed deep learning-based approach is substantially more accurate than that of humans.
EMPIR: Ensembles of Mixed Precision Deep Networks for Increased Robustness against Adversarial Attacks
Apr 21, 2020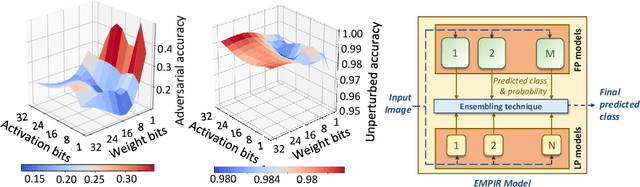

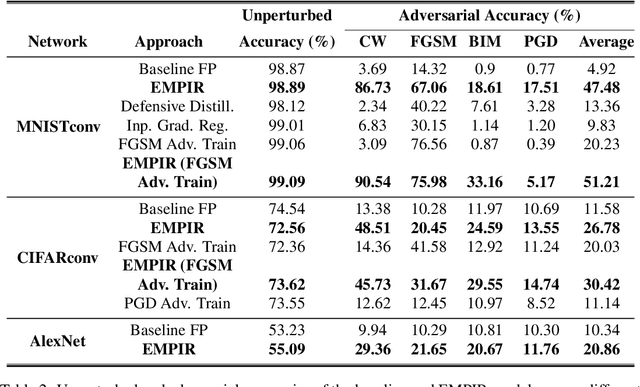
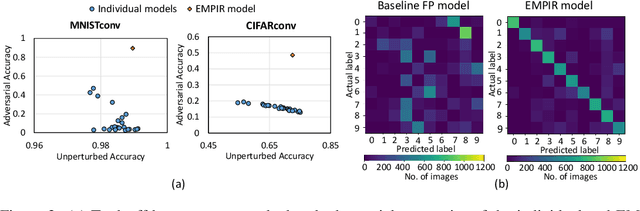
Ensuring robustness of Deep Neural Networks (DNNs) is crucial to their adoption in safety-critical applications such as self-driving cars, drones, and healthcare. Notably, DNNs are vulnerable to adversarial attacks in which small input perturbations can produce catastrophic misclassifications. In this work, we propose EMPIR, ensembles of quantized DNN models with different numerical precisions, as a new approach to increase robustness against adversarial attacks. EMPIR is based on the observation that quantized neural networks often demonstrate much higher robustness to adversarial attacks than full precision networks, but at the cost of a substantial loss in accuracy on the original (unperturbed) inputs. EMPIR overcomes this limitation to achieve the 'best of both worlds', i.e., the higher unperturbed accuracies of the full precision models combined with the higher robustness of the low precision models, by composing them in an ensemble. Further, as low precision DNN models have significantly lower computational and storage requirements than full precision models, EMPIR models only incur modest compute and memory overheads compared to a single full-precision model (<25% in our evaluations). We evaluate EMPIR across a suite of DNNs for 3 different image recognition tasks (MNIST, CIFAR-10 and ImageNet) and under 4 different adversarial attacks. Our results indicate that EMPIR boosts the average adversarial accuracies by 42.6%, 15.2% and 10.5% for the DNN models trained on the MNIST, CIFAR-10 and ImageNet datasets respectively, when compared to single full-precision models, without sacrificing accuracy on the unperturbed inputs.
Spatio-spectral deep learning methods for in-vivo hyperspectral laryngeal cancer detection
Apr 21, 2020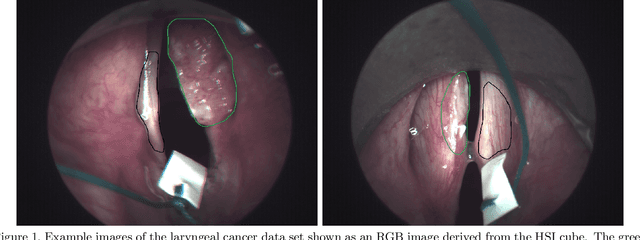

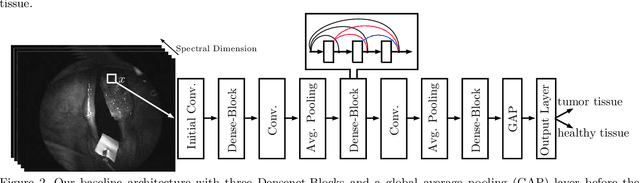
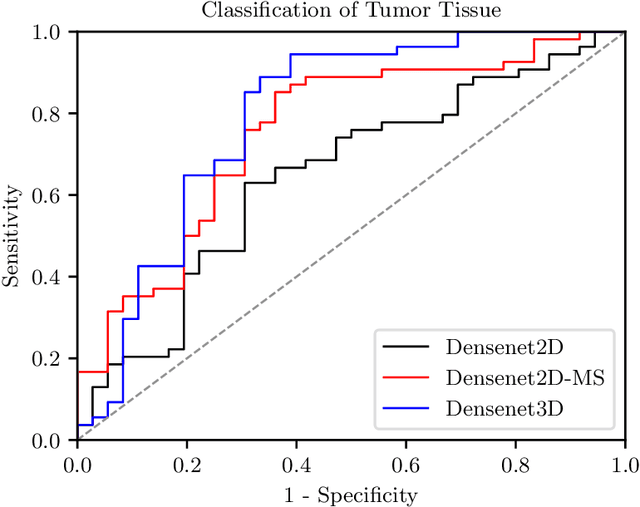
Early detection of head and neck tumors is crucial for patient survival. Often, diagnoses are made based on endoscopic examination of the larynx followed by biopsy and histological analysis, leading to a high inter-observer variability due to subjective assessment. In this regard, early non-invasive diagnostics independent of the clinician would be a valuable tool. A recent study has shown that hyperspectral imaging (HSI) can be used for non-invasive detection of head and neck tumors, as precancerous or cancerous lesions show specific spectral signatures that distinguish them from healthy tissue. However, HSI data processing is challenging due to high spectral variations, various image interferences, and the high dimensionality of the data. Therefore, performance of automatic HSI analysis has been limited and so far, mostly ex-vivo studies have been presented with deep learning. In this work, we analyze deep learning techniques for in-vivo hyperspectral laryngeal cancer detection. For this purpose we design and evaluate convolutional neural networks (CNNs) with 2D spatial or 3D spatio-spectral convolutions combined with a state-of-the-art Densenet architecture. For evaluation, we use an in-vivo data set with HSI of the oral cavity or oropharynx. Overall, we present multiple deep learning techniques for in-vivo laryngeal cancer detection based on HSI and we show that jointly learning from the spatial and spectral domain improves classification accuracy notably. Our 3D spatio-spectral Densenet achieves an average accuracy of 81%.
Disaster Feature Classification on Aerial Photography to Explain Typhoon Damaged Region using Grad-CAM
Apr 21, 2020
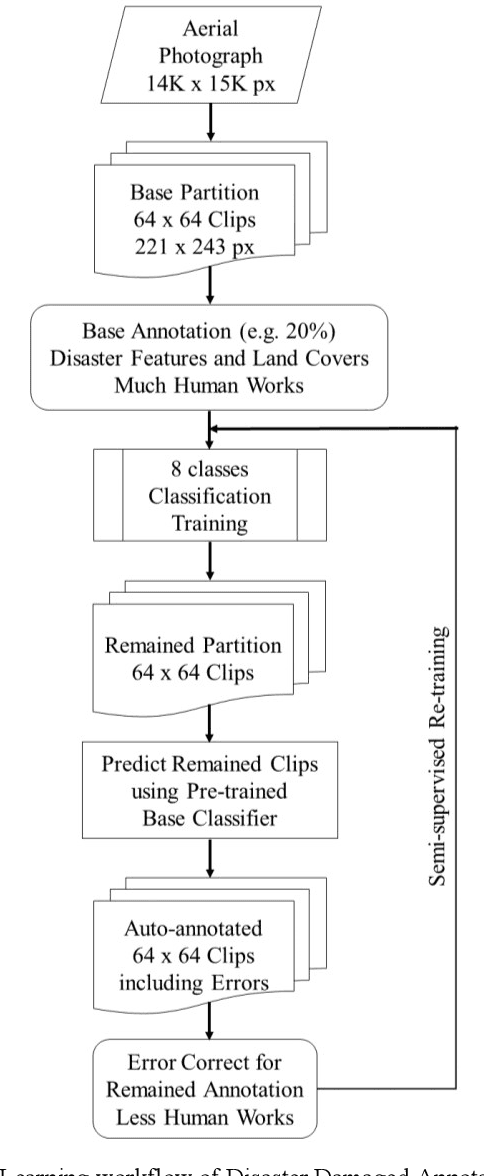
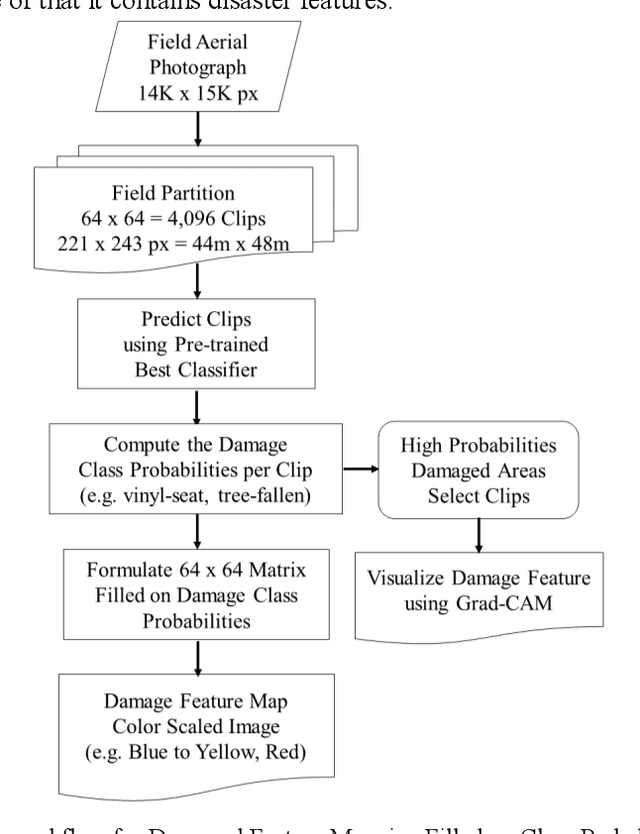
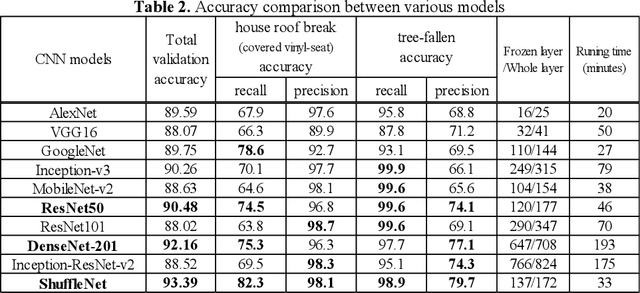
Recent years, typhoon damages has become social problem owing to climate change. Especially, 9 September 2019, Typhoon Faxai passed on the south Chiba prefecture in Japan, whose damages included with electric and water provision stop and house roof break because of strong wind recorded on the maximum 45 meter per second. A large amount of tree fell down, and the neighbor electric poles also fell down at the same time. These disaster features have caused that it took eighteen days for recovery longer than past ones. Initial responses are important for faster recovery. As long as we can, aerial survey for global screening of devastated region would be required for decision support to respond where to recover ahead. This paper proposes a practical method to visualize the damaged areas focused on the typhoon disaster features using aerial photography. This method can classify eight classes which contains land covers without damages and areas with disaster, where an aerial photograph is partitioned into 4,096 grids that is 64 by 64, with each unit image of 48 meter square. Using target feature class probabilities, we can visualize disaster features map to scale the color range from blue to red or yellow. Furthermore, we can realize disaster feature mapping on each unit grid images to compute the convolutional activation map using Grad-CAM based on deep neural network layers for classification. This paper demonstrates case studies applied to aerial photographs recorded at the south Chiba prefecture in Japan after typhoon disaster.
Towards Analysis-friendly Face Representation with Scalable Feature and Texture Compression
Apr 21, 2020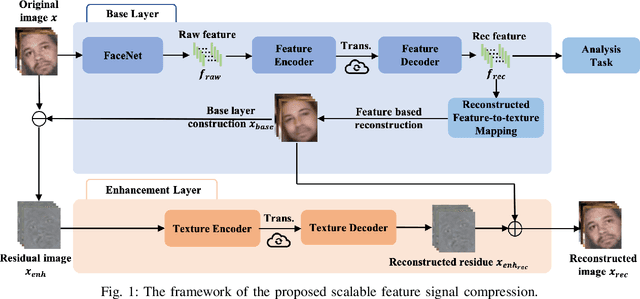
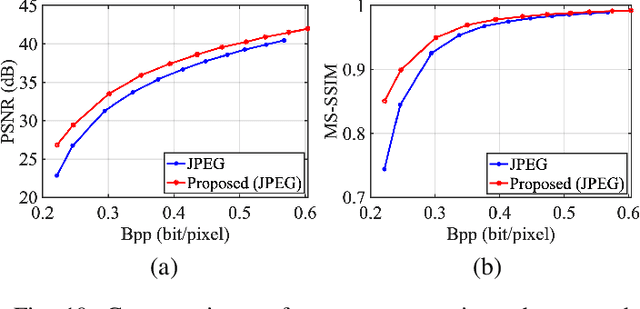
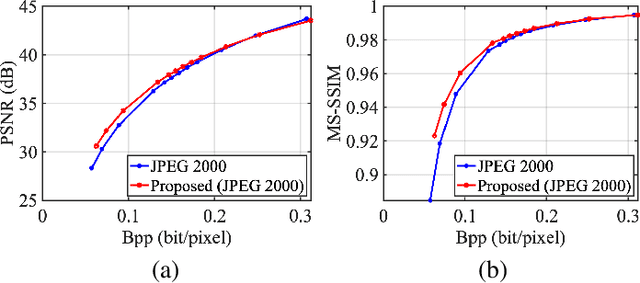
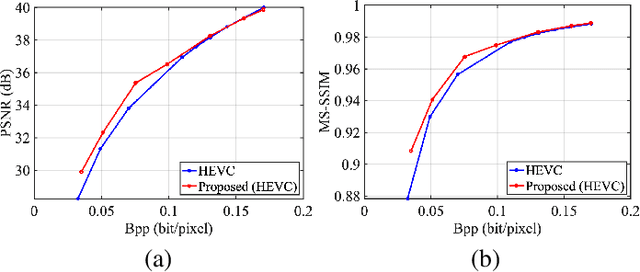
It plays a fundamental role to compactly represent the visual information towards the optimization of the ultimate utility in myriad visual data centered applications. With numerous approaches proposed to efficiently compress the texture and visual features serving human visual perception and machine intelligence respectively, much less work has been dedicated to studying the interactions between them. Here we investigate the integration of feature and texture compression, and show that a universal and collaborative visual information representation can be achieved in a hierarchical way. In particular, we study the feature and texture compression in a scalable coding framework, where the base layer serves as the deep learning feature and enhancement layer targets to perfectly reconstruct the texture. Based on the strong generative capability of deep neural networks, the gap between the base feature layer and enhancement layer is further filled with the feature level texture reconstruction, aiming to further construct texture representation from feature. As such, the residuals between the original and reconstructed texture could be further conveyed in the enhancement layer. To improve the efficiency of the proposed framework, the base layer neural network is trained in a multi-task manner such that the learned features enjoy both high quality reconstruction and high accuracy analysis. We further demonstrate the framework and optimization strategies in face image compression, and promising coding performance has been achieved in terms of both rate-fidelity and rate-accuracy.