 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GSA-DenseNet121-COVID-19: a Hybrid Deep Learning Architecture for the Diagnosis of COVID-19 Disease based on Gravitational Search Optimization Algorithm
Apr 09, 2020
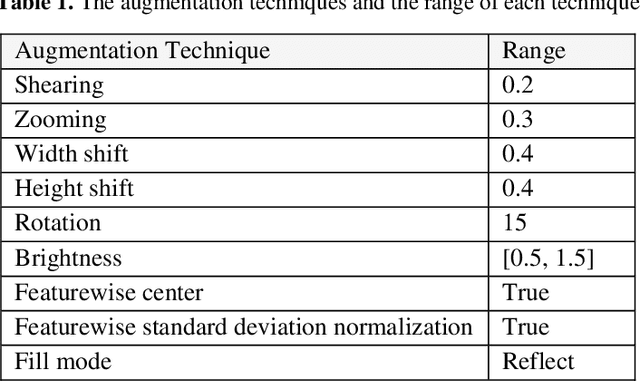
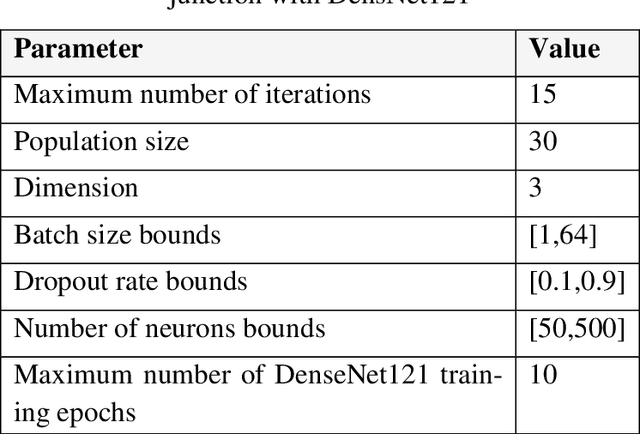

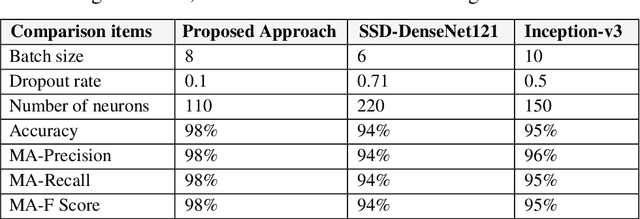
In this paper, a novel approach called GSA-DenseNet121-COVID-19 based on a hybrid convolutional neural network (CNN) architecture is proposed using an optimization algorithm. The CNN architecture that was used is called DenseNet121 and the optimization algorithm that was used is called the gravitational search algorithm (GSA). The GSA is adapted to determine the best values for the hyperparameters of the DenseNet121 architecture, and to achieve a high level of accuracy in diagnosing COVID-19 disease through chest x-ray image analysis. The obtained results showed that the proposed approach was able to correctly classify 98% of the test set. To test the efficacy of the GSA in setting the optimum values for the hyperparameters of DenseNet121, it was compared to another optimization algorithm called social ski driver (SSD). The comparison results demonstrated the efficacy of the proposed GSA-DenseNet121-COVID-19 and its ability to better diagnose COVID-19 disease than the SSD-DenseNet121 as the second was able to diagnose only 94% of the test set. As well as, the proposed approach was compared to an approach based on a CNN architecture called Inception-v3 and the manual search method for determining the values of the hyperparameters. The results of the comparison showed that the GSA-DenseNet121 was able to beat the other approach, as the second was able to classify only 95% of the test set samples.
Predicting Sharp and Accurate Occlusion Boundaries in Monocular Depth Estimation Using Displacement Fields
Feb 28, 2020
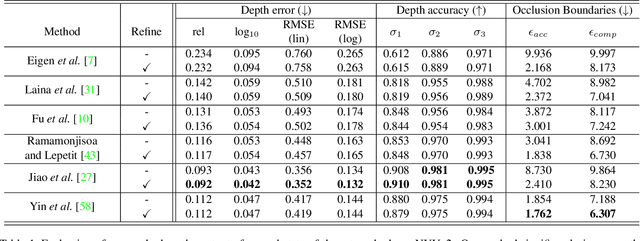

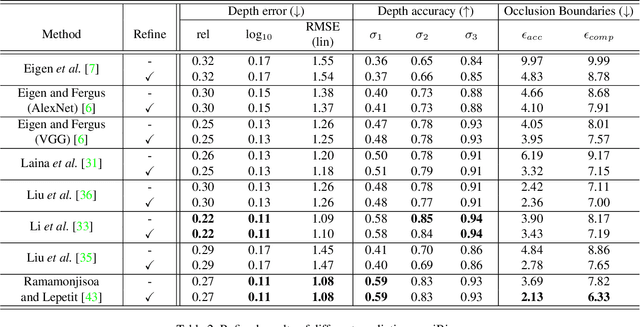
Current methods for depth map prediction from monocular images tend to predict smooth, poorly localized contours for the occlusion boundaries in the input image. This is unfortunate as occlusion boundaries are important cues to recognize objects, and as we show, may lead to a way to discover new objects from scene reconstruction. To improve predicted depth maps, recent methods rely on various forms of filtering or predict an additive residual depth map to refine a first estimate. We instead learn to predict, given a depth map predicted by some reconstruction method, a 2D displacement field able to re-sample pixels around the occlusion boundaries into sharper reconstructions. Our method can be applied to the output of any depth estimation method, in an end-to-end trainable fashion. For evaluation, we manually annotated the occlusion boundaries in all the images in the test split of popular NYUv2-Depth dataset. We show that our approach improves the localization of occlusion boundaries for all state-of-the-art monocular depth estimation methods that we could evaluate, without degrading the depth accuracy for the rest of the images.
Uniform Interpolation Constrained Geodesic Learning on Data Manifold
Feb 12, 2020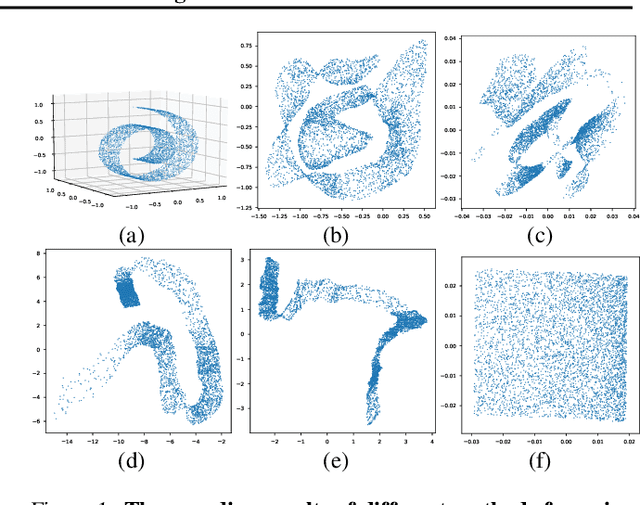
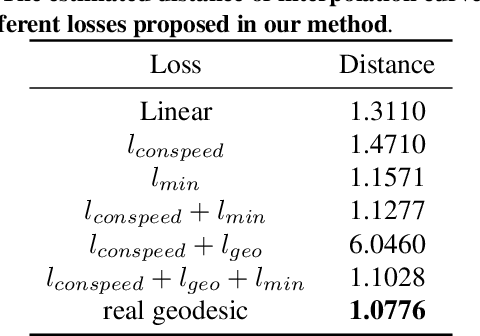
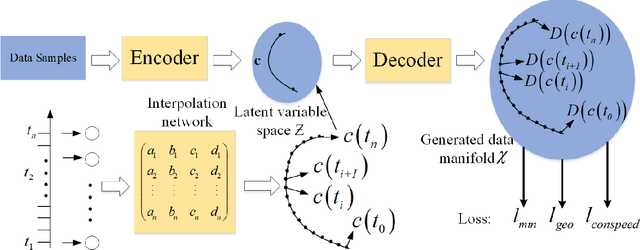
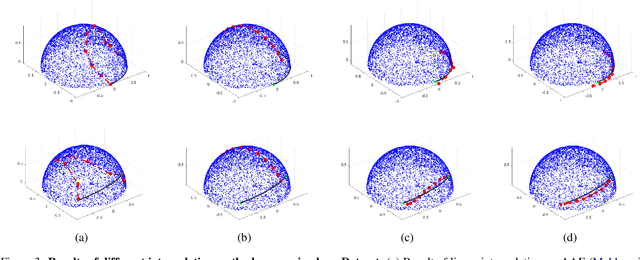
In this paper, we propose a method to learn a minimizing geodesic within a data manifold. Along the learned geodesic, our method can generate high-quality interpolations between two given data samples. Specifically, we use an autoencoder network to map data samples into latent space and perform interpolation via an interpolation net-work. We add prior geometric information to regularize our autoencoder for the convexity of representations so that for any given interpolation approach, the generated interpolations remain within the distribution of the data manifold. Before the learning of a geodesic, a proper Riemannianmetric should be defined. Therefore, we induce a Riemannian metric by the canonical metric in the Euclidean space which the data manifold is isometrically immersed in. Based on this defined Riemannian metric, we introduce a constant speed loss and a minimizing geodesic loss to regularize the interpolation network to generate uniform interpolation along the learned geodesic on the manifold. We provide a theoretical analysis of our model and use image translation as an example to demonstrate the effectiveness of our method.
Optimizing Convolutional Neural Networks for Embedded Systems by Means of Neuroevolution
Oct 15, 2019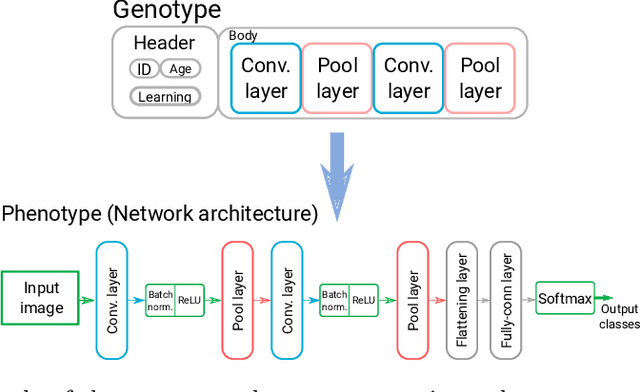

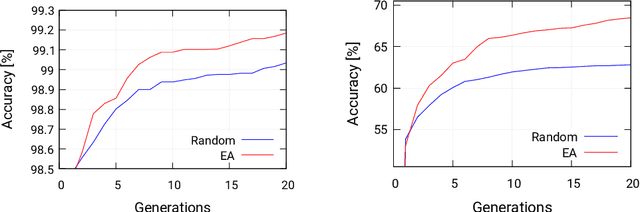
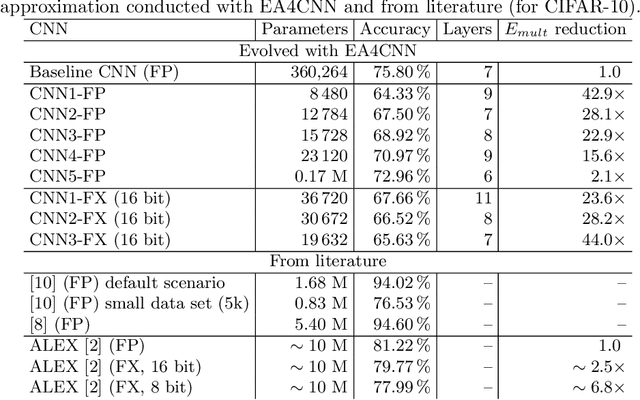
Automated design methods for convolutional neural networks (CNNs) have recently been developed in order to increase the design productivity. We propose a neuroevolution method capable of evolving and optimizing CNNs with respect to the classification error and CNN complexity (expressed as the number of tunable CNN parameters), in which the inference phase can partly be executed using fixed point operations to further reduce power consumption. Experimental results are obtained with TinyDNN framework and presented using two common image classification benchmark problems -- MNIST and CIFAR-10.
Federated Learning with Personalization Layers
Dec 02, 2019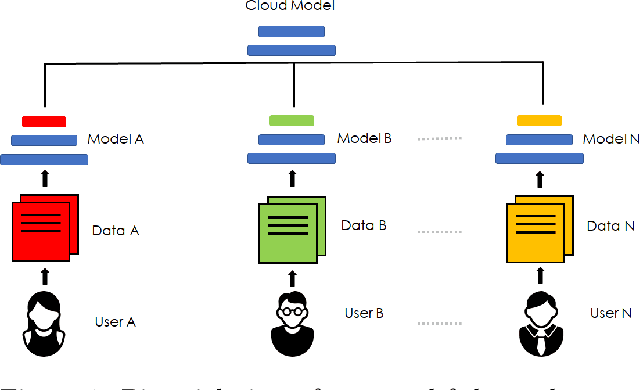
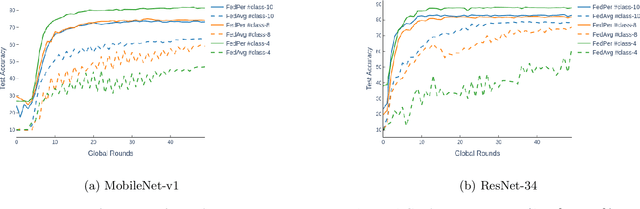
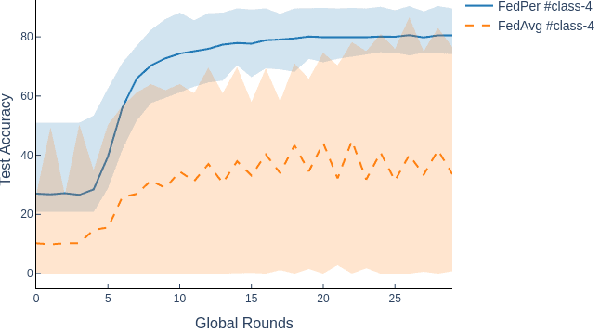
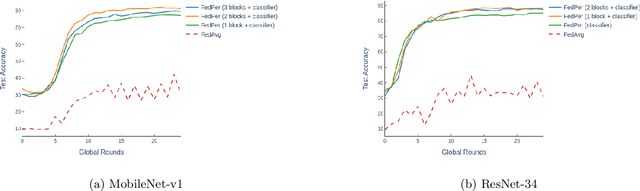
The emerging paradigm of federated learning strives to enable collaborative training of machine learning models on the network edge without centrally aggregating raw data and hence, improving data privacy. This sharply deviates from traditional machine learning and necessitates the design of algorithms robust to various sources of heterogeneity. Specifically, statistical heterogeneity of data across user devices can severely degrade the performance of standard federated averaging for traditional machine learning applications like personalization with deep learning. This paper pro-posesFedPer, a base + personalization layer approach for federated training of deep feedforward neural networks, which can combat the ill-effects of statistical heterogeneity. We demonstrate effectiveness ofFedPerfor non-identical data partitions ofCIFARdatasetsand on a personalized image aesthetics dataset from Flickr.
Robust Image Descriptors for Real-Time Inter-Examination Retargeting in Gastrointestinal Endoscopy
Oct 30, 2016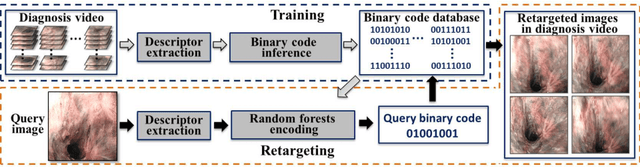

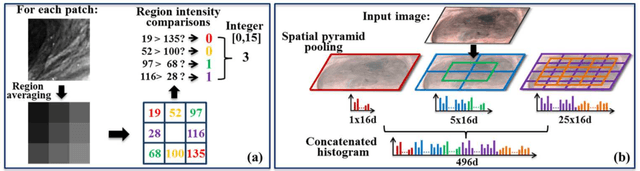
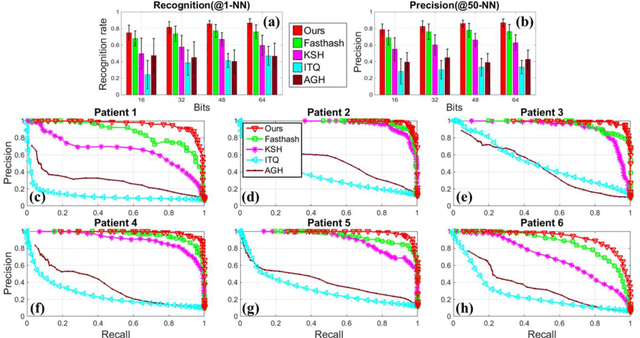
For early diagnosis of malignancies in the gastrointestinal tract, surveillance endoscopy is increasingly used to monitor abnormal tissue changes in serial examinations of the same patient. Despite successes with optical biopsy for in vivo and in situ tissue characterisation, biopsy retargeting for serial examinations is challenging because tissue may change in appearance between examinations. In this paper, we propose an inter-examination retargeting framework for optical biopsy, based on an image descriptor designed for matching between endoscopic scenes over significant time intervals. Each scene is described by a hierarchy of regional intensity comparisons at various scales, offering tolerance to long-term change in tissue appearance whilst remaining discriminative. Binary coding is then used to compress the descriptor via a novel random forests approach, providing fast comparisons in Hamming space and real-time retargeting. Extensive validation conducted on 13 in vivo gastrointestinal videos, collected from six patients, show that our approach outperforms state-of-the-art methods.
Uncertainty in Structured Prediction
Feb 28, 2020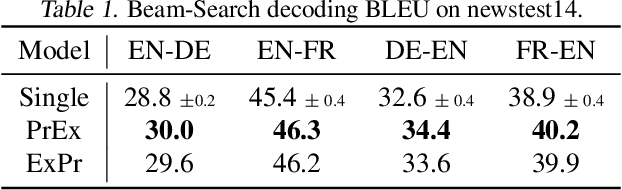
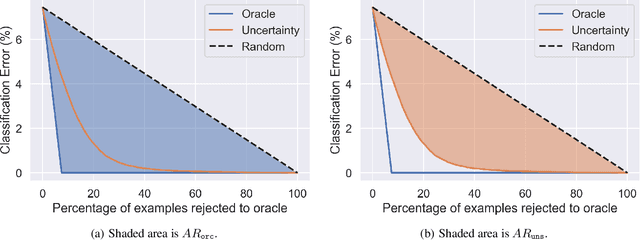
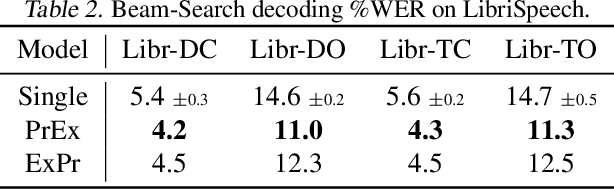
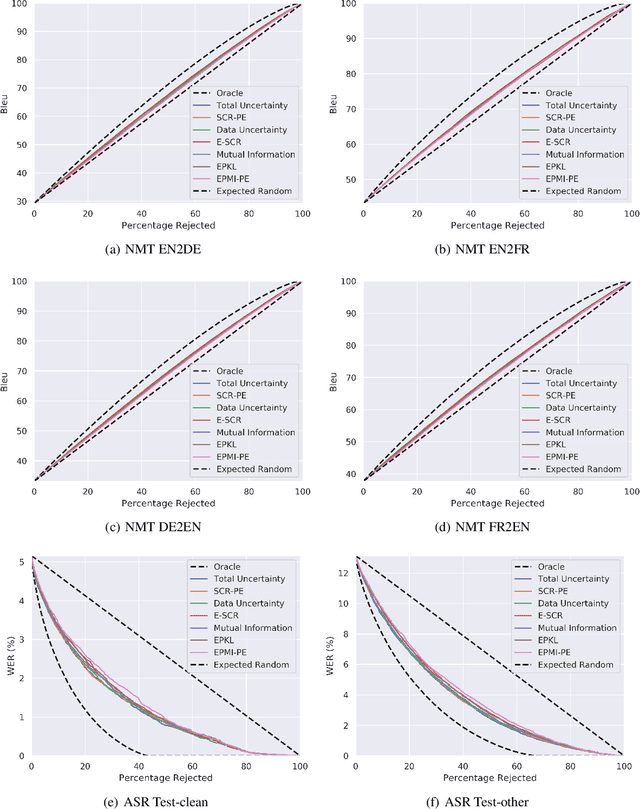
Uncertainty estimation is important for ensuring safety and robustness of AI systems, especially for high-risk applications. While much progress has recently been made in this area, most research has focused on un-structured prediction, such as image classification and regression tasks. However, while task-specific forms of confidence score estimation have been investigated by the speech and machine translation communities, limited work has investigated general uncertainty estimation approaches for structured prediction. Thus, this work aims to investigate uncertainty estimation for structured prediction tasks within a single unified and interpretable probabilistic ensemble-based framework. We consider uncertainty estimation for sequence data at the token-level and complete sequence-level, provide interpretations for, and applications of, various measures of uncertainty and discuss the challenges associated with obtaining them. This work also explores the practical challenges associated with obtaining uncertainty estimates for structured predictions tasks and provides baselines for token-level error detection, sequence-level prediction rejection, and sequence-level out-of-domain input detection using ensembles of auto-regressive transformer models trained on the WMT'14 English-French and WMT'17 English-German translation and LibriSpeech speech recognition datasets.
4D Association Graph for Realtime Multi-person Motion Capture Using Multiple Video Cameras
Feb 28, 2020
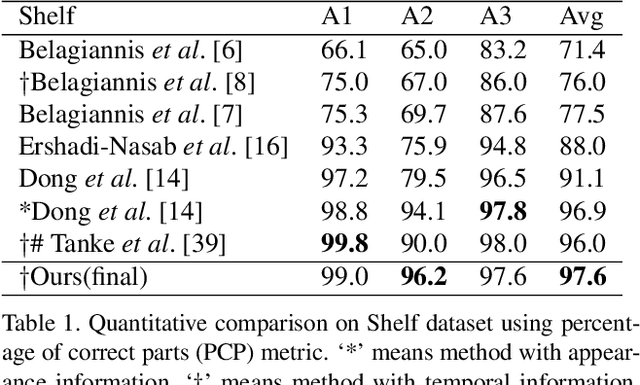
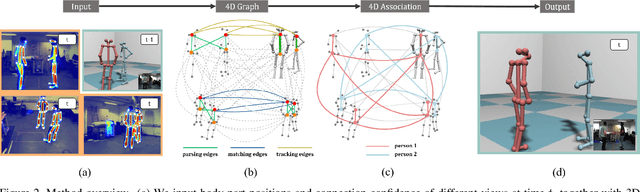

This paper contributes a novel realtime multi-person motion capture algorithm using multiview video inputs. Due to the heavy occlusions in each view, joint optimization on the multiview images and multiple temporal frames is indispensable, which brings up the essential challenge of realtime efficiency. To this end, for the first time, we unify per-view parsing, cross-view matching, and temporal tracking into a single optimization framework, i.e., a 4D association graph that each dimension (image space, viewpoint and time) can be treated equally and simultaneously. To solve the 4D association graph efficiently, we further contribute the idea of 4D limb bundle parsing based on heuristic searching, followed with limb bundle assembling by proposing a bundle Kruskal's algorithm. Our method enables a realtime online motion capture system running at 30fps using 5 cameras on a 5-person scene. Benefiting from the unified parsing, matching and tracking constraints, our method is robust to noisy detection, and achieves high-quality online pose reconstruction quality. The proposed method outperforms the state-of-the-art method quantitatively without using high-level appearance information. We also contribute a multiview video dataset synchronized with a marker-based motion capture system for scientific evaluation.
Covariance-free Partial Least Squares: An Incremental Dimensionality Reduction Method
Oct 05, 2019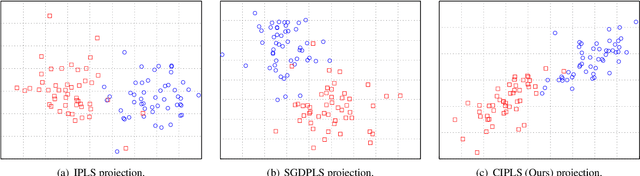
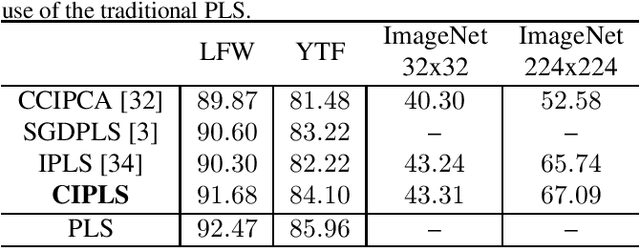
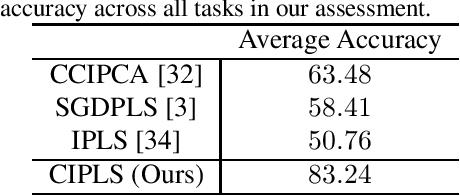
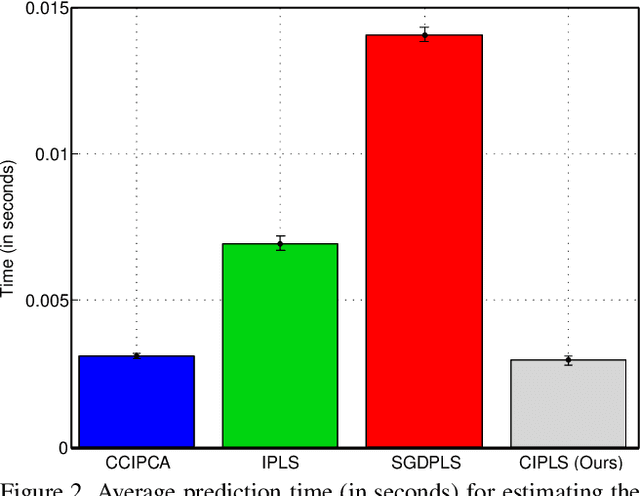
Dimensionality reduction plays an important role in computer vision problems since it reduces computational cost and is often capable of yielding more discriminative data representation. In this context, Partial Least Squares (PLS) has presented notable results in tasks such as image classification and neural network optimization. However, PLS is infeasible on large datasets (e.g., ImageNet) because it requires all the data to be in memory in advance, which is often impractical due to hardware limitations. Additionally, this requirement prevents us from employing PLS on streaming applications where the data are being continuously generated. Motivated by this, we propose a novel incremental PLS, named Covariance-free Incremental Partial Least Squares (CIPLS), which learns a low-dimensional representation of the data using a single sample at a time. In contrast to other state-of-the-art approaches, instead of adopting a partially-discriminative or SGD-based model, we extend Nonlinear Iterative Partial Least Squares (NIPALS) - the standard algorithm used to compute PLS - for incremental processing. Among the advantages of this approach are the preservation of discriminative information across all components, the possibility of employing its score matrices for feature selection, and its computational efficiency. We validate CIPLS on face verification and image classification tasks, where it outperforms several other incremental dimensionality reduction methods. In the context of feature selection, CIPLS achieves comparable results when compared to state-of-the-art techniques.
Design and implementation of image processing system for Lumen social robot-humanoid as an exhibition guide for Electrical Engineering Days 2015
Jul 16, 2016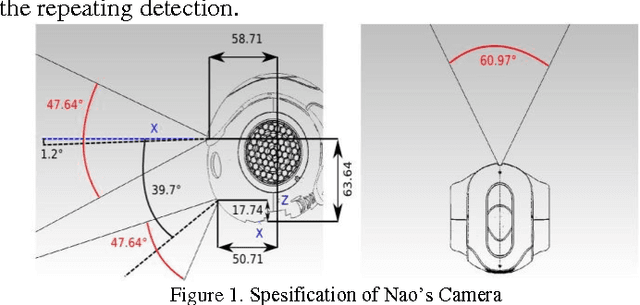
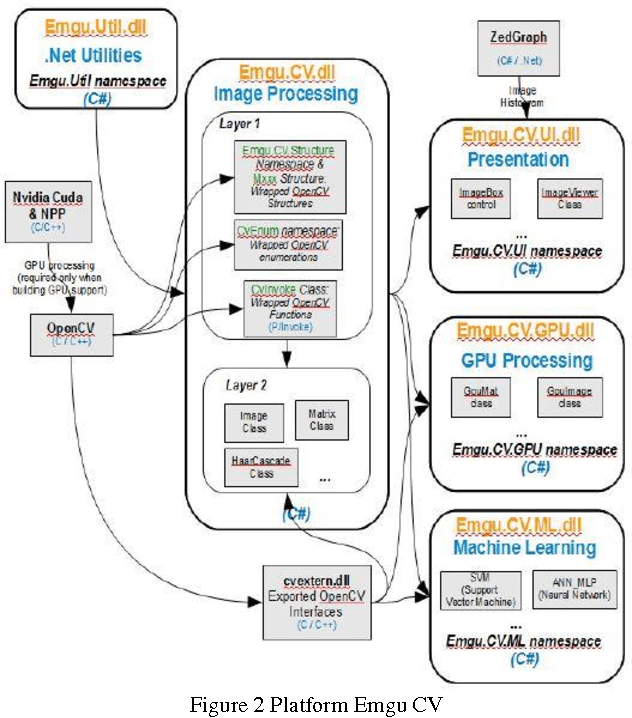
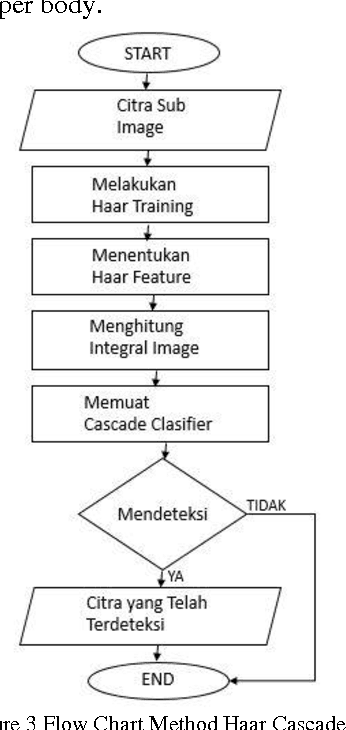
Lumen Social Robot is a humanoid robot development with the purpose that it could be a good friend to all people. In this year, the Lumen Social Robot is being developed into a guide in the exhibition and in the seminar of the Final Exam of undergraduate and graduate students in Electrical Engineering ITB, named Electrical Engineering Days 2015. In order to be the guide in that occasion, Lumen is supported by several things. They are Nao robot components, servers, and multiple processor systems. The image processing system is a processing application system that allows Lumen to recognize and determine an object from the image taken from the camera eye. The image processing system is provided with four modules. They are face detection module to detect a person's face, face recognition module to recognize a person's face, face tracking module to follow a person's face, and human detection module to detect humans based on the upper parts of person's body. Face detection module and human detection module are implemented by using the library harcascade.xml on EMGU CV. Face recognition module is implemented by adding the database for the face that has been detected and store it in that database. Face tracking module is implemented by using the Smooth Gaussian filter to the image. ----- Lumen Sosial Robot merupakan sebuah pengembangan robot humanoid agar dapat menjadi teman bagi banyak orang. Sistem pengolahan citra merupakan sistem aplikasi pengolah yang bertujuan Lumen dapat mengenali dan mengetahui suatu objek pada citra yang diambil dari camera mata Lumen. System pengolahan citra dilengkapi dengan empat buah modul, yaitu modul face detection untuk mendeteksi wajah seseorang, modul face recognition untuk mengenali wajah orang tersebut, modul face tracking untuk mengikuti wajah seseorang, dan modul human detection untuk mendeteksi manusia berdasarkan bagian tubuh atas orang